15_尚硅谷大数据之MapReduce入门
- 格式:pdf
- 大小:223.25 KB
- 文档页数:8

MapReduce是一种大数据处理模型,用于并行处理大规模的数据集。
它由Google在2004年提出,并成为Apache Hadoop的核心组件之一。
MapReduce模型的设计目的是为了简化并行计算任务,使得开发人员可以在分布式系统上高效地处理大规模数据。
MapReduce模型的基本概念如下:1. 输入数据集:MapReduce将输入数据集分割成多个小数据块,并且每个数据块可以由一个或多个键值对组成。
2. 映射 Map)函数:映射函数是并行处理输入数据块的核心操作。
它将输入数据块的每个键值对进行处理,并生成一系列中间键值对。
映射函数可以根据需求进行自定义操作,比如提取关键词、计数等。
3. 中间数据集:MapReduce将映射函数生成的中间键值对根据键进行分组,将具有相同键的值组合在一起,形成中间数据集。
4. 归约 Reduce)函数:归约函数对每个中间键值对的值列表进行处理,并生成最终的输出结果。
归约函数通常是进行聚合操作,比如求和、求平均值等。
5. 输出数据集:MapReduce将归约函数处理后的结果保存在输出数据集中。
MapReduce模型的工作过程如下:1. 切分输入数据集:将大规模的输入数据集切分成多个小数据块,并分配给不同的计算节点。
2. 映射:每个计算节点将分配到的数据块使用映射函数进行处理,并生成中间键值对。
3. 分组:根据中间键的值,将相同键的中间值进行分组,以便后续的归约操作。
4. 归约:每个计算节点对分组后的中间值进行归约操作,生成最终的输出结果。
5. 合并输出结果:将所有计算节点的输出结果进行合并,形成最终的输出数据集。
MapReduce模型的优点包括:- 可扩展性:可以处理非常大规模的数据,并利用分布式计算资源进行并行处理,提高处理效率。
- 容错性:MapReduce具备容错机制,当某个计算节点发生故障时,可以重新分配任务到其他节点上。
- 灵活性:开发人员可以根据具体需求自定义映射和归约函数,实现各种数据处理操作。

mapreduce基础编程MapReduce是一种用于大规模数据处理的编程模型和软件框架。
它可以将大数据集分成多个小数据集,并通过多个计算节点并行处理,最后汇总处理结果。
MapReduce将数据处理过程分成两个阶段:Map阶段和Reduce阶段。
在Map阶段中,数据被分成多个小数据集,每个小数据集上运行相同的计算任务,然后产生中间结果。
在Reduce阶段中,中间结果被合并,最终产生处理结果。
MapReduce的基础编程模型可以分为以下几个步骤:1. 输入数据的读取:输入数据可以来自于Hadoop Distributed File System (HDFS)、本地文件系统或其他数据源。
2. Map阶段的编写:开发者需要编写Map函数,该函数将输入数据切分成多个小数据集,并在每个小数据集上运行相同的计算任务,生成中间结果。
Map函数的输出通常是一个键值对(key-value pair),其中键表示中间结果的类型,值表示中间结果的值。
3. Reduce阶段的编写:开发者需要编写Reduce函数,该函数将中间结果根据键值进行合并,生成最终的处理结果。
Reduce函数的输出通常是一个键值对(key-value pair),其中键表示最终处理结果的类型,值表示最终处理结果的值。
4. 输出数据的写入:最终处理结果可以写入到HDFS或其他数据源中。
MapReduce程序的开发需要掌握Java或其他编程语言。
除了基础编程模型外,还需要了解MapReduce的一些高级编程技术,如Combiner、Partitioner、InputFormat、OutputFormat等。
通过这些技术,可以进一步提高MapReduce程序的性能和可扩展性。
总之,MapReduce是一种强大的大数据处理工具,掌握基础编程模型是进行大数据分析和处理的必要条件。
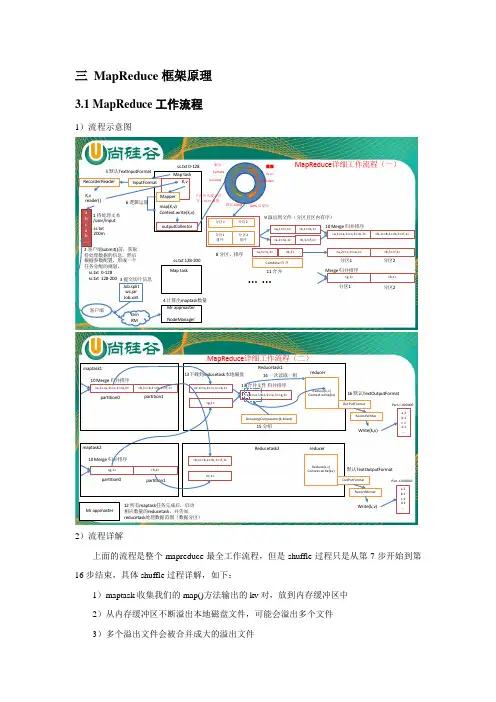

第四章分布式计算框架MapReduce4.1初识MapReduceMapReduce是一种面向大规模数据并行处理的编程模型,也一种并行分布式计算框架。
在Hadoop流行之前,分布式框架虽然也有,但是实现比较复杂,基本都是大公司的专利,小公司没有能力和人力来实现分布式系统的开发。
Hadoop的出现,使用MapReduce框架让分布式编程变得简单。
如名称所示,MapReduce主要由两个处理阶段:Map阶段和Reduce 阶段,每个阶段都以键值对作为输入和输出,键值对类型可由用户定义。
程序员只需要实现Map和Reduce两个函数,便可实现分布式计算,而其余的部分,如分布式实现、资源协调、内部通信等,都是由平台底层实现,无需开发者关心。
基于Hadoop开发项目相对简单,小公司也可以轻松的开发分布式处理软件。
4.1.1 MapReduce基本过程MapReduce是一种编程模型,用户在这个模型框架下编写自己的Map函数和Reduce函数来实现分布式数据处理。
MapReduce程序的执行过程主要就是调用Map函数和Reduce函数,Hadoop把MapReduce程序的执行过程分为Map和Reduce两个大的阶段,如果细分可以为Map、Shuffle(洗牌)、Reduce三个阶段。
Map含义是映射,将要操作的每个元素映射成一对键和值,Reduce含义是归约,将要操作的元素按键做合并计算,Shuffle在第三节详细介绍。
下面以一个比较简单的示例,形象直观介绍一下Map、Reduce阶段是如何执行的。
有一组图形,包含三角形、圆形、正方形三种形状图形,要计算每种形状图形的个数,见下图4-1。
图:4-1 map/reduce计算不同形状的过程在Map阶段,将每个图形映射成形状(键Key)和数量(值Value),每个形状图形的数量值是“1”;Shuffle阶段的Combine(合并),相同的形状做归类;在Reduce阶段,对相同形状的值做求和计算。



mapreduce的介绍及工作流程MapReduce是一种用于大规模数据处理的编程模型和计算框架。
它可以有效地处理大规模数据集,提供了分布式计算的能力,以及自动化的数据分片、任务调度和容错机制。
本文将介绍MapReduce的基本概念、工作流程以及其在大数据处理中的应用。
一、MapReduce的基本概念MapReduce的基本概念分为两个部分:Map和Reduce。
Map用于对输入数据进行初步处理,将输入数据分解成若干个<key, value>对。
Reduce则对Map的输出进行聚合操作,生成最终的结果。
MapReduce的输入数据通常是一个大型数据集,可以是文件、数据库中的表或者其他形式的数据源。
输入数据被划分为若干个数据块,每个数据块由一个Map任务处理。
Map任务将输入数据块转化为若干个中间结果,每个中间结果都是一个<key, value>对。
Reduce任务负责对Map任务的输出进行进一步处理,将具有相同key的中间结果进行聚合操作,生成最终的结果。
Reduce任务的输出结果通常是一个<key, value>对的集合。
二、MapReduce的工作流程MapReduce的工作流程可以简单概括为以下几个步骤:输入数据的划分、Map任务的执行、中间结果的合并与排序、Reduce任务的执行、最终结果的输出。
1. 输入数据的划分:输入数据被划分成若干个数据块,在分布式环境下,每个数据块都会被分配到不同的节点上进行处理。
数据块的大小通常由系统自动设置,以保证每个Map任务的负载均衡。
2. Map任务的执行:每个Map任务独立地处理一个数据块,将输入数据转化为若干个中间结果。
Map任务可以并行执行,每个任务都在独立的节点上运行。
Map任务的输出中间结果被存储在本地磁盘上。
3. 中间结果的合并与排序:Map任务输出的中间结果需要在Reduce任务执行之前进行合并和排序。


mapreduce的介绍及工作流程MapReduce是一种用于处理大规模数据集的编程模型和软件框架。
它的设计目标是使得处理大数据集变得容易且高效,同时隐藏底层的分布式系统细节。
本文将介绍MapReduce的基本概念和工作流程。
MapReduce分为两个主要阶段:Map阶段和Reduce阶段。
在Map阶段,输入的数据被切分成多个小块,然后由多个Map任务并行处理。
每个Map任务将输入数据转换为键值对的形式,并生成一个中间结果集。
在Reduce阶段,中间结果集被合并和排序,然后由多个Reduce任务并行处理。
每个Reduce任务将相同键的值进行聚合操作,并生成最终的结果。
MapReduce的工作流程可以总结为以下几个步骤:1. 切分输入数据:输入数据被切分成多个小块,每个小块称为一个输入分片。
切分的目的是将数据分散到不同的Map任务上进行并行处理。
2. 执行Map任务:每个Map任务读取一个输入分片,并将其转换为键值对的形式。
Map函数是由用户自定义的,它接受输入键值对并产生中间结果键值对。
Map任务可以在不同的计算节点上并行执行。
3. 中间结果排序和合并:Map任务产生的中间结果键值对被发送到Reduce任务之前,需要进行排序和合并操作。
这样可以将具有相同键的中间结果聚合在一起,减少数据传输量。
4. 执行Reduce任务:每个Reduce任务接收一组具有相同键的中间结果,并将其进行聚合操作。
Reduce函数也是由用户自定义的,它接受键和一组值,并生成最终的结果。
Reduce任务可以在不同的计算节点上并行执行。
5. 输出最终结果:Reduce任务生成的最终结果被写入输出文件或存储系统中。
用户可以根据需要进行后续的分析或处理。
MapReduce的优点在于它的简单性和可扩展性。
用户只需要实现Map 和Reduce函数,而不需要关心底层的分布式系统细节。
此外,MapReduce可以在大规模集群上运行,从而处理大规模的数据集。
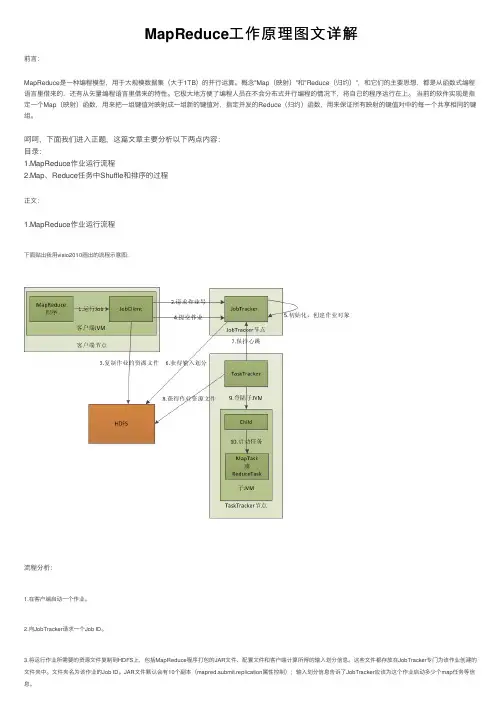
MapReduce⼯作原理图⽂详解前⾔:MapReduce是⼀种编程模型,⽤于⼤规模数据集(⼤于1TB)的并⾏运算。
概念"Map(映射)"和"Reduce(归约)",和它们的主要思想,都是从函数式编程语⾔⾥借来的,还有从⽮量编程语⾔⾥借来的特性。
它极⼤地⽅便了编程⼈员在不会分布式并⾏编程的情况下,将⾃⼰的程序运⾏在上。
当前的软件实现是指定⼀个Map(映射)函数,⽤来把⼀组键值对映射成⼀组新的键值对,指定并发的Reduce(归约)函数,⽤来保证所有映射的键值对中的每⼀个共享相同的键组。
呵呵,下⾯我们进⼊正题,这篇⽂章主要分析以下两点内容:⽬录:1.MapReduce作业运⾏流程2.Map、Reduce任务中Shuffle和排序的过程正⽂:1.MapReduce作业运⾏流程下⾯贴出我⽤visio2010画出的流程⽰意图:流程分析:1.在客户端启动⼀个作业。
2.向JobTracker请求⼀个Job ID。
3.将运⾏作业所需要的资源⽂件复制到HDFS上,包括MapReduce程序打包的JAR⽂件、配置⽂件和客户端计算所得的输⼊划分信息。
这些⽂件都存放在JobTracker专门为该作业创建的⽂件夹中。
⽂件夹名为该作业的Job ID。
JAR⽂件默认会有10个副本(mapred.submit.replication属性控制);输⼊划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4.JobTracker接收到作业后,将其放在⼀个作业队列⾥,等待作业调度器对其进⾏调度(这⾥是不是很像微机中的进程调度呢,呵呵),当作业调度器根据⾃⼰的调度算法调度到该作业时,会根据输⼊划分信息为每个划分创建⼀个map任务,并将map任务分配给TaskTracker执⾏。
对于map和reduce任务,TaskTracker根据主机核的数量和内存的⼤⼩有固定数量的map 槽和reduce槽。

mapreduce基础知识MapReduce是一种分布式计算框架,由Google公司提出,用来解决大数据处理问题。
它是基于Map和Reduce两个操作实现的,可以支持海量数据的高效处理。
MapReduce基础知识1. Map阶段Map阶段是指数据输入时进行的映射处理,将输入数据转换为中间格式的键值对,以便于Reduce阶段进行处理。
具体来说,Map阶段将输入数据分割为若干个小块,每个小块交由一个Mapper进行处理。
Mapper将输入数据进行过滤、计算和转换,然后生成一系列中间结果的键值对。
2. Reduce阶段Reduce阶段是指对Map阶段中生成的中间结果进行合并和分析处理。
Reduce阶段包括若干个小的Reducer任务,每个Reducer任务对一个或多个Mapper任务生成的输出数据进行合并。
Reducer任务将相同的中间结果按照键值对聚合,执行用户自定义的Reduce函数对其中的值进行聚合计算,并将计算结果输出到文件系统中。
3. Combiner阶段Combiner阶段是Map阶段的一个可选部分,主要用于提高Map阶段的效率。
Combiner阶段是在每个Map任务本地执行的一个小的Reduce函数,用于对Map输出的键值对进行局部合并。
通过Combiner的合并操作可以减少数据传输量,提高Map阶段的效率。
4. Shuffle阶段Shuffle阶段是MapReduce框架的核心,主要用于对Map和Reduce阶段之间的数据进行排序和分发。
Shuffle阶段将Map任务的中间结果按照Key进行排序,然后将相同键值对的数据传输给同一个Reducer任务。
Shuffle阶段的实现对MapReduce的性能和扩展性有着重要的影响。
5. 总结MapReduce框架是一种分布式计算框架,实现了高效的大数据处理。
Map阶段通过Mapper函数将输入数据转换为中间结果的键值对,Reduce阶段通过Reducer函数对中间结果进行聚合计算,实现高效并行处理。
Hadoop大数据开发基础教案-MapReduce进阶编程教案一、MapReduce编程模型1.1 课程目标理解MapReduce编程模型的基本概念掌握MapReduce程序的编写和运行过程掌握MapReduce中的数据序列化和反序列化1.2 教学内容MapReduce编程模型概述Mapper和Reducer的编写和运行序列化和反序列化1.3 教学方法讲解MapReduce编程模型的基本概念通过示例演示Mapper和Reducer的编写和运行讲解序列化和反序列化的实现方法1.4 教学资源MapReduce编程模型PPT示例代码1.5 教学评估学生能理解MapReduce编程模型的基本概念学生能编写简单的MapReduce程序学生能实现序列化和反序列化功能二、MapReduce高级特性2.1 课程目标理解MapReduce高级特性的概念和作用掌握MapReduce中的数据分区、分片和合并掌握MapReduce中的数据压缩和溢出处理2.2 教学内容MapReduce高级特性概述数据分区和分片数据压缩和溢出处理2.3 教学方法讲解MapReduce高级特性的概念和作用通过示例演示数据分区和分片的实现方法讲解数据压缩和溢出处理的实现方法2.4 教学资源MapReduce高级特性PPT示例代码2.5 教学评估学生能理解MapReduce高级特性的概念和作用学生能实现数据分区和分片功能学生能处理数据压缩和溢出问题三、MapReduce性能优化3.1 课程目标理解MapReduce性能优化的目标和原则掌握MapReduce中的任务调度和资源管理掌握MapReduce中的数据本地化和压缩策略3.2 教学内容MapReduce性能优化概述任务调度和资源管理数据本地化和压缩策略3.3 教学方法讲解MapReduce性能优化的目标和原则通过示例演示任务调度和资源管理的实现方法讲解数据本地化和压缩策略的实现方法3.4 教学资源MapReduce性能优化PPT示例代码3.5 教学评估学生能理解MapReduce性能优化的目标和原则学生能实现任务调度和资源管理功能学生能应用数据本地化和压缩策略进行性能优化四、MapReduce案例分析4.1 课程目标理解MapReduce在实际应用中的案例掌握MapReduce在文本处理、数据挖掘和图像处理等方面的应用掌握MapReduce在分布式文件系统上的数据处理能力4.2 教学内容MapReduce案例概述文本处理、数据挖掘和图像处理的MapReduce应用分布式文件系统上的数据处理4.3 教学方法讲解MapReduce在实际应用中的案例通过示例演示文本处理、数据挖掘和图像处理的MapReduce应用讲解分布式文件系统上的数据处理方法4.4 教学资源MapReduce案例分析PPT示例代码4.5 教学评估学生能理解MapReduce在实际应用中的案例学生能应用MapReduce进行文本处理、数据挖掘和图像处理学生能掌握MapReduce在分布式文件系统上的数据处理能力五、MapReduce编程实践5.1 课程目标掌握MapReduce编程实践的基本步骤能够编写并运行一个完整的MapReduce程序理解MapReduce编程实践中的常见问题和解决方法5.2 教学内容MapReduce编程实践概述编写MapReduce程序的基本步骤常见问题和解决方法六、Hadoop生态系统中的MapReduce6.1 课程目标理解Hadoop生态系统中MapReduce的位置和作用掌握Hadoop中MapReduce与其他组件的交互理解MapReduce在不同Hadoop发行版中的配置和使用6.2 教学内容Hadoop生态系统概述MapReduce在Hadoop中的角色MapReduce与HDFS、YARN等组件的交互不同Hadoop发行版的MapReduce配置6.3 教学方法讲解Hadoop生态系统的结构和组件通过图解和实例说明MapReduce在Hadoop中的作用比较不同Hadoop发行版中MapReduce的配置差异6.4 教学资源Hadoop生态系统PPTMapReduce在不同Hadoop发行版中的配置示例6.5 教学评估学生能理解Hadoop生态系统中MapReduce的位置和作用学生能描述MapReduce与HDFS、YARN等组件的交互过程学生能根据不同Hadoop发行版配置MapReduce七、使用MapReduce处理复杂数据类型7.1 课程目标理解复杂数据类型的概念和重要性掌握MapReduce中处理复杂数据类型的方法学会使用MapReduce处理序列文件、自定义对象等7.2 教学内容复杂数据类型的介绍序列文件的处理自定义对象的处理数据压缩技术7.3 教学方法讲解复杂数据类型的概念和应用场景通过示例演示如何使用MapReduce处理序列文件和自定义对象介绍数据压缩技术在MapReduce中的应用7.4 教学资源复杂数据类型PPT序列文件和自定义对象处理的示例代码数据压缩技术文档7.5 教学评估学生能理解复杂数据类型的概念和重要性学生能使用MapReduce处理序列文件和自定义对象学生能应用数据压缩技术优化MapReduce程序八、MapReduce中的数据流控制8.1 课程目标理解MapReduce中数据流控制的概念掌握MapReduce中shuffle和sort的过程学会使用MapReduce实现数据过滤和聚合8.2 教学内容数据流控制概述shuffle和sort过程数据过滤和聚合技术8.3 教学方法讲解数据流控制的概念和作用通过图解和示例说明shuffle和sort的过程介绍如何使用MapReduce实现数据过滤和聚合8.4 教学资源数据流控制PPTshuffle和sort过程的图解和示例代码数据过滤和聚合的示例代码8.5 教学评估学生能理解数据流控制的概念学生能描述shuffle和sort的过程学生能使用MapReduce实现数据过滤和聚合九、使用MapReduce进行数据分析9.1 课程目标理解MapReduce在数据分析中的应用掌握使用MapReduce进行词频统计、日志分析等常见数据分析任务学会设计适用于MapReduce的数据分析算法9.2 教学内容数据分析概述词频统计日志分析数据分析算法设计9.3 教学方法讲解数据分析的概念和MapReduce的应用场景通过示例演示如何使用MapReduce进行词频统计和日志分析介绍如何设计适用于MapReduce的数据分析算法9.4 教学资源数据分析PPT词频统计和日志分析的示例代码适用于MapReduce的数据分析算法设计文档9.5 教学评估学生能理解MapReduce在数据分析中的应用学生能使用MapReduce进行词频统计和日志分析学生能设计适用于MapReduce的数据分析算法十、MapReduce最佳实践和技巧10.1 课程十一、MapReduce调试和优化11.1 课程目标理解MapReduce程序调试的重要性掌握MapReduce程序的调试技巧学会优化MapReduce程序的性能11.2 教学内容MapReduce程序调试的重要性MapReduce程序调试技巧MapReduce程序性能优化11.3 教学方法讲解调试和优化MapReduce程序的重要性通过实例演示MapReduce程序的调试技巧介绍优化MapReduce程序性能的方法11.4 教学资源MapReduce程序调试和优化PPT MapReduce程序调试技巧实例代码MapReduce程序性能优化文档11.5 教学评估学生能理解调试MapReduce程序的重要性学生能掌握调试MapReduce程序的技巧学生能掌握优化MapReduce程序性能的方法十二、MapReduce在实际项目中的应用12.1 课程目标理解MapReduce在实际项目中的应用场景掌握MapReduce在数据处理、分析等实际项目中的应用学会将MapReduce应用到实际项目中12.2 教学内容MapReduce在实际项目中的应用场景MapReduce在数据处理、分析等实际项目中的应用将MapReduce应用到实际项目中的方法12.3 教学方法讲解MapReduce在实际项目中的应用场景通过实例演示MapReduce在数据处理、分析等实际项目中的应用介绍将MapReduce应用到实际项目中的方法12.4 教学资源MapReduce在实际项目中应用PPTMapReduce在数据处理、分析等实际项目中的应用实例代码将MapReduce应用到实际项目中的方法文档12.5 教学评估学生能理解MapReduce在实际项目中的应用场景学生能掌握MapReduce在数据处理、分析等实际项目中的应用学生能将MapReduce应用到实际项目中十三、Hadoop生态系统中的其他数据处理工具13.1 课程目标理解Hadoop生态系统中除MapReduce外的其他数据处理工具掌握Hadoop生态系统中其他数据处理工具的基本使用方法学会在Hadoop生态系统中选择合适的数据处理工具13.2 教学内容Hadoop生态系统中其他数据处理工具概述Hadoop生态系统中其他数据处理工具的基本使用方法在Hadoop生态系统中选择合适的数据处理工具的方法13.3 教学方法讲解Hadoop生态系统中其他数据处理工具的概念和作用通过实例演示Hadoop生态系统中其他数据处理工具的基本使用方法介绍在Hadoop生态系统中选择合适的数据处理工具的方法13.4 教学资源Hadoop生态系统中其他数据处理工具PPTHadoop生态系统中其他数据处理工具的基本使用方法实例代码在Hadoop生态系统中选择合适的数据处理工具的方法文档13.5 教学评估学生能理解Hadoop生态系统中除MapReduce外的其他数据处理工具学生能掌握Hadoop生态系统中其他数据处理工具的基本使用方法学生能在Hadoop生态系统中选择合适的数据处理工具十四、Hadoop集群管理和维护14.1 课程目标理解Hadoop集群管理和维护的重要性掌握Hadoop集群的配置、监控和故障排除方法学会Hadoop集群的日常管理和维护技巧14.2 教学内容Hadoop集群管理和维护的重要性Hadoop集群的配置、监控和故障排除方法Hadoop集群的日常管理和维护技巧14.3 教学方法讲解Hadoop集群管理和维护的重要性通过实例演示Hadoop集群的配置、监控和故障排除方法介绍Hadoop集群的日常管理和维护技巧14.4 教学资源Hadoop集群管理和维护PPTHadoop集群的配置、监控和故障排除方法实例代码Hadoop集群的日常管理和维护技巧文档重点和难点解析本文主要介绍了Hadoop大数据开发基础中的MapReduce进阶编程教案,内容包括MapReduce编程模型、高级特性、性能优化、案例分析、编程实践、数据流控制、数据分析、最佳实践和技巧、实际项目中的应用、Hadoop生态系统中的其他数据处理工具以及Hadoop集群管理和维护。
mapreduce基础编程MapReduce是一种分布式计算模型,主要用于处理大规模数据集。
在大数据时代,MapReduce已经成为了大数据处理的重要工具之一。
本文将介绍MapReduce的基础编程,包括程序结构、Mapper、Reducer、Partitioner等概念。
1. MapReduce程序结构MapReduce程序由两个部分组成:Map函数和Reduce函数。
Map 函数将输入数据划分为若干个子集,每个子集进行单独处理并输出一个键值对;Reduce函数将Map函数输出的键值对进行合并,得到最终的结果。
2. MapperMapper是MapReduce程序中的一个重要组成部分。
Mapper将输入数据分块,每个分块生成一组键值对。
Mapper的主要任务是将输入数据处理为键值对,并将这些键值对传递给Reducer。
3. ReducerReducer是MapReduce程序中的另一个重要组成部分。
Reducer 将Mapper输出的键值对进行合并,得到最终的结果。
Reducer的主要任务是对Mapper输出的键值对进行合并和聚合操作。
4. PartitionerPartitioner是MapReduce程序中的另一个重要组成部分。
Partitioner将Reducer的输入键值对进行分组,将相同的键值对分配到同一个Reducer中。
Partitioner的主要任务是保证相同的键值对进入同一个Reducer中进行合并操作,从而保证MapReduce程序的正确性。
总之,MapReduce是一种分布式计算模型,主要用于处理大规模数据集。
MapReduce程序由Map函数和Reduce函数组成,Mapper将输入数据分块,每个分块生成一组键值对,Reducer将Mapper输出的键值对进行合并,得到最终的结果。
Partitioner将Reducer的输入键值对进行分组,保证相同的键值对进入同一个Reducer中进行合并操作。
文章标题:深入探讨MapReduce的基础运用和原理一、引言MapReduce是一种用于处理和生成大规模数据集的分布式计算框架,它能够有效地处理海量数据,提高数据处理的效率和速度。
本文将深入探讨MapReduce的基础运用和原理,帮助读者更深入地理解和掌握这一重要的数据处理技术。
二、MapReduce的基本概念1. Map阶段:在MapReduce中,Map阶段是数据处理的第一步,它将输入的数据集合拆分成若干个独立的任务,并将这些任务分配给不同的计算节点进行并行处理。
在Map阶段,我们需要编写Map函数来对输入的数据进行处理,通常是将数据进行分割和映射。
2. Shuffle阶段:Shuffle阶段是MapReduce中非常重要的一部分,它负责将Map阶段输出的结果进行分区和排序,然后将相同key的数据进行分组,以便于后续Reduce阶段的处理。
3. Reduce阶段:Reduce阶段是MapReduce的最后一步,它接收Shuffle阶段输出的数据,并将具有相同key的数据进行合并和聚合,最终输出最终的处理结果。
三、MapReduce的基础运用1. 数据处理:MapReduce可以高效地处理海量数据,如日志文件、文本数据等,通过Map和Reduce两个阶段的处理,可以实现对数据的分析和计算,例如词频统计、数据过滤等。
2. 分布式计算:MapReduce能够将数据集分解成多个小的任务,分配给多个计算节点进行并行处理,因此可以充分利用集群的计算资源,提高数据处理的速度和效率。
3. 容错性:MapReduce具有很强的容错性,当集群中的某个计算节点发生故障时,系统能够自动将任务重新分配给其他正常的节点进行处理,保证任务的顺利完成。
四、MapReduce的原理分析1. 并行计算模型:MapReduce采用了流水线式的并行计算模型,将数据处理划分成不同的阶段,每个阶段都可以并行执行,从而充分利用集群的计算资源。
Hadoop大数据开发基础2021/12/271MapReduce原理与编程目录下载和安装Eclipse2实践操作31.下载Eclipse安装包“Eclipse IDE for Java EE Developers”2. 将Eclipse安装包解压到本地的安装目录3.将插件hadoop-eclipse-plugin-2.6.0jar拷贝到Eclipse安装目录下的dropins目录4. 双击解压文件下Eclipse文件夹中的图标打开Eclipse增加Map/Reduce功能区增加Hadoop集群的连接增加Hadoop集群的连接增加Hadoop集群的连接导入MapReduce运行依赖的相关Jar包下载和安装Eclipse12MapReduce 原理与编程3实践操作目录•MapReduce,在名称上就表现出了它的核心原理,它是由两个阶段组成的。
•Map,表示“映射”,在map阶段进行的一系列数据处理任务被称为Mapper模块。
•Reduce,表示“归约”,同样,在reduce阶段进行的一系列数据处理任务也被称为Reducer模块。
•MapReduce通常也被简称为MR(1)Mapper:映射器。
(2)Mapper助理InputFormat:输入文件读取器。
(3)Shuffle:运输队。
(4)Shuffle助理Sorter:排序器。
(5)Reducer:归约器。
(6)Reducer助理OutputFormat :输出结果写入器。
•数据分片。
假设原始文件中8000万行记录被系统分配给100个Mapper来处理,那么每个Mapper处理80万行数据。
相当于MapReduce通过数据分片的方式,把数据分发给多个单元来进行处理,这就是分布式计算的第一步。
•数据映射。
在数据分片完成后,由Mapper助理InputFormat从文件的输入目录中读取这些记录,然后由Mapper负责对记录进行解析,并重新组织成新的格式。
一、MapReduce简介1.1 课程目标理解MapReduce的概念和原理掌握MapReduce编程模型了解MapReduce在Hadoop中的作用1.2 教学内容MapReduce定义MapReduce编程模型(Map、Shuffle、Reduce阶段)MapReduce的优势和局限性Hadoop中的MapReduce运行机制1.3 教学方法理论讲解实例演示学生实操1.4 教学资源PPT课件Hadoop环境MapReduce实例代码1.5 课后作业分析一个大数据问题,尝试设计一个简单的MapReduce解决方案二、Hadoop环境搭建与配置2.1 课程目标学会在本地环境搭建Hadoop掌握Hadoop配置文件的基本配置理解Hadoop文件系统(HDFS)的存储机制2.2 教学内容Hadoop架构简介Hadoop环境搭建步骤Hadoop配置文件介绍(如:core-site.xml、hdfs-site.xml、mapred-site.xml)HDFS命令行操作2.3 教学方法讲解与实操相结合学生分组讨论问答互动2.4 教学资源PPT课件Hadoop安装包Hadoop配置文件模板HDFS命令行操作指南2.5 课后作业搭建本地Hadoop环境,并配置Hadoop文件系统三、MapReduce编程基础3.1 课程目标掌握MapReduce编程的基本概念理解MapReduce的运行原理3.2 教学内容MapReduce编程入口(Java)MapReduce关键组件(Job, Configuration, Reporter等)MapReduce编程实践(WordCount案例)MapReduce运行流程解析3.3 教学方法理论讲解与实操演示代码解析学生实践与讨论3.4 教学资源PPT课件MapReduce编程教程WordCount案例代码编程环境(Eclipse/IntelliJ IDEA)3.5 课后作业完成WordCount案例的编写与运行分析MapReduce运行过程中的各个阶段四、MapReduce高级特性4.1 课程目标掌握MapReduce的高级特性了解MapReduce在复杂数据处理中的应用4.2 教学内容MapReduce高级数据处理(如:排序、分组合并等)MapReduce性能优化策略(如:数据分区、序列化等)复杂场景下的MapReduce应用(如:多层嵌套、自定义分区等)4.3 教学方法理论讲解与实操演示代码解析与优化学生实践与讨论4.4 教学资源PPT课件MapReduce高级特性教程性能优化案例代码编程环境(Eclipse/IntelliJ IDEA)4.5 课后作业优化WordCount程序的性能分析复杂场景下的MapReduce应用案例5.1 课程目标了解MapReduce在大数据处理领域的应用趋势掌握进一步学习MapReduce的途径5.2 教学内容MapReduce编程要点回顾MapReduce在实际项目中的应用案例大数据处理领域的新技术与发展趋势(如:Spark、Flink等)5.3 教学方法知识点梳理与讲解案例分享学生提问与讨论5.4 教学资源PPT课件实际项目案例相关技术资料5.5 课后作业结合实际项目,分析MapReduce的应用场景六、MapReduce编程实战(一)6.1 课程目标掌握MapReduce编程的实战技巧学会分析并解决实际问题理解MapReduce在不同场景下的应用6.2 教学内容实战案例介绍:倒排索引构建MapReduce编程实战:倒排索引的MapReduce实现案例分析:倒排索引在搜索引擎中的应用6.3 教学方法实操演示与讲解学生跟随实操案例分析与讨论6.4 教学资源PPT课件实战案例代码搜索引擎原理资料6.5 课后作业完成倒排索引的MapReduce实现分析MapReduce在搜索引擎中的应用七、MapReduce编程实战(二)7.1 课程目标进一步掌握MapReduce编程的实战技巧学会分析并解决复杂问题了解MapReduce在不同行业的应用7.2 教学内容实战案例介绍:网页爬虫数据处理MapReduce编程实战:网页爬虫数据的抓取与解析案例分析:MapReduce在网络爬虫领域的应用7.3 教学方法实操演示与讲解学生跟随实操案例分析与讨论7.4 教学资源PPT课件实战案例代码网络爬虫原理资料7.5 课后作业完成网页爬虫数据的MapReduce实现分析MapReduce在网络爬虫领域的应用八、MapReduce性能优化8.1 课程目标掌握MapReduce性能优化的方法与技巧学会分析并提升MapReduce程序的性能理解MapReduce性能优化的意义8.2 教学内容性能优化概述:MapReduce性能瓶颈分析优化方法与技巧:数据划分、序列化、并行度等性能优化案例:WordCount的性能提升8.3 教学方法理论讲解与实操演示代码解析与优化学生实践与讨论8.4 教学资源PPT课件性能优化教程性能优化案例代码编程环境(Eclipse/IntelliJ IDEA)8.5 课后作业分析并优化WordCount程序的性能研究其他MapReduce性能优化案例九、MapReduce在大数据处理中的应用9.1 课程目标理解MapReduce在大数据处理中的应用场景学会分析并解决实际问题掌握MapReduce与其他大数据处理技术的比较9.2 教学内容大数据处理场景:日志分析、分布式文件处理等MapReduce应用案例:日志数据分析MapReduce与其他大数据处理技术的比较9.3 教学方法理论讲解与实操演示案例分析与讨论学生提问与互动9.4 教学资源PPT课件大数据处理案例资料MapReduce与其他技术比较资料9.5 课后作业分析MapReduce在日志数据分析中的应用研究MapReduce与其他大数据处理技术的优缺点10.1 课程目标了解MapReduce技术的发展趋势掌握进一步学习MapReduce的途径10.2 教学内容MapReduce编程要点回顾MapReduce技术的发展趋势:YARN、Spark等拓展学习资源与推荐10.3 教学方法知识点梳理与讲解技术发展趋势分享学生提问与讨论10.4 教学资源PPT课件技术发展趋势资料拓展学习资源列表10.5 课后作业制定个人拓展学习计划重点和难点解析:一、MapReduce简介理解MapReduce的概念和原理掌握MapReduce编程模型了解MapReduce在Hadoop中的作用二、Hadoop环境搭建与配置学会在本地环境搭建Hadoop掌握Hadoop配置文件的基本配置理解Hadoop文件系统(HDFS)的存储机制三、MapReduce编程基础掌握MapReduce编程的基本概念学会编写MapReduce应用程序理解MapReduce的运行原理四、MapReduce高级特性掌握MapReduce的高级特性学会优化MapReduce程序性能了解MapReduce在复杂数据处理中的应用六、MapReduce编程实战(一)掌握MapReduce编程的实战技巧学会分析并解决实际问题理解MapReduce在不同场景下的应用七、MapReduce编程实战(二)进一步掌握MapReduce编程的实战技巧学会分析并解决复杂问题了解MapReduce在不同行业的应用八、MapReduce性能优化掌握MapReduce性能优化的方法与技巧学会分析并提升MapReduce程序的性能理解MapReduce性能优化的意义九、MapReduce在大数据处理中的应用理解MapReduce在大数据处理中的应用场景学会分析并解决实际问题掌握MapReduce与其他大数据处理技术的比较了解MapReduce技术的发展趋势掌握进一步学习MapReduce的途径本教案主要涵盖了MapReduce编程的基础知识、Hadoop环境搭建、编程实战、高级特性、性能优化以及应用场景等内容。
Hadoop Map/Reduce教程[一]今天浏览了下hadoop的 map/reduce文档,初步感觉这东西太牛逼了,听我在这里给你吹吹。
你可以这样理解,假设你有很多台烂机器(假设1000台)1.利用hadoop他会帮你组装成一台超级计算机(集群),你的这台计算机是超多核的(很多个CPU),一个超级大的硬盘,而且容错和写入速度都很快。
2.如果你的计算任务可以拆分,那么通过map/Reduce,他可以统一指挥你的那一帮烂机器,让一堆机器帮你一起干活(并行计算),谁干什么,负责什么,他来管理,通常处理个几T的数据,只要你有机器那就小CASE。
3.hadoop要分析的数据通常都是巨大的(T级),网络I/O开销不可忽视,但分析程序通常不会很大,所以他传递的是计算方法(程序),而不是数据文件,所以每次计算在物理上都是在相近的节点上进行(同一台机器或同局域网),大大降低的IO消耗,而且计算程序如果要经常使用的话也是可以做缓存的。
4.hadoop是一个分布式的文件系统,他就像一个管家,管理你数据的存放,在物理上较远的地方会分别存放(这样一是不同的地方读取数据都很快,也起到了异地容灾的作用),他会动态管理和调动你的数据节点,高强的容错处理,最大程度的降低数据丢失的风险。
比较著名的应用:nutch搜索引擎的蜘蛛抓取程序,数据的存储以及pageRank(网页重要程序)计算。
QQ空间的日志分析处理(PV,UV)咋样,给他吹的够牛了吧。
下面是别人翻译的官方文档,经常做日志分析处理的同学可以研究下。
目的这篇教程从用户的角度出发,全面地介绍了Hadoop Map/Reduce框架的各个方面。
先决条件请先确认Hadoop被正确安装、配置和正常运行中。
更多信息见:∙Hadoop快速入门对初次使用者。
∙Hadoop集群搭建对大规模分布式集群。
概述Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。