实值形式背景下概念格的渐进式并行构造算法
- 格式:docx
- 大小:45.11 KB
- 文档页数:15

双向渐进式概念格生成算法双向渐进式概念格生成算法是一种用于数据挖掘和知识表示的算法,其目的是从给定的数据集中生成一个概念格,以便帮助我们理解数据集中事物之间的关系。
本文旨在介绍双向渐进式概念格生成算法的概念和应用。
双向渐进式概念格生成算法,简称BicP, 使用渐进式的方法生成概念格。
渐进式概念格生成是一种快速而有效的算法,它能够处理非常大的数据集,以及快速处理交互式查询。
算法最初由 Zhang 和 Chen 提出,它是单向的渐进生成算法的变体,在算法完成过程中,会在生成的结果中得到初始状态和终止状态的完全的概念格。
文章主要从以下几个方面进行介绍:1. 概念格的概念2. BicP生成算法3. 算法的优势和应用概念格的概念在谈论BicP的概念之前,我们需要了解概念格的概念。
在计算机科学和形式概念分析中,概念格是一个用于表示对象和关系的形式概念结构。
它通过将关系描述为对两个事物之间的“包含”关系来描述事物之间的关系,从而表示了一个有限集中事物之间的组织结构。
概念格在知识表示,信息检索和数据挖掘等领域具有广泛的应用。
在业务分析方面,它被广泛应用于文本分类、信息提取、基于语义标注的数据管理、Web搜索和推荐系统等方面。
BicP生成算法BicP生成算法可以被解释为一种增量概念格生成算法,它使用了两个方向的搜索。
该算法通过两个搜索过程来确定未知区域和缺失数据,从而对数据进行完整的覆盖。
其中一个搜索过程是开始于极小概念,即遍历完整个数据集的值集,另一个搜索过程是由极大概念开始,即逆序遍历完整个数据集的值集。
这两次搜索的结果组合起来,构成了完整的概念格。
BicP生成算法的具体步骤如下:1. 算法开始于极小概念,即以单元格为初始状态开展正向搜索2. 然后在这个单元格的基础上,从元素集合中选择一个属性,将单元格分裂成若干个子单元格3. 对于每个子单元格,从属性域中选择一个值,然后将其递归地纳入到生成的子概念格中4. 递归进行,直到搜索到所有单元格被分裂为极大的概念格为止。





从封建主义向资本主义过渡期间的欧洲政事形式1、相关定义1.1、”虚伪的形式”的概念余华在1986年提出”虚伪的形式”的文学理论,打破了传统的现实主义写作手法。
用他自己的话说”我开始使用一种‘虚伪的形式’,所谓虚伪,是针对人们被日常生活围困的经验而言,这种经验使人们沦陷在缺乏想象的环境里,我们的文学只能在缺乏想象的茅屋里度日如年,也因此无法期待文学会出现奇迹。
” 简单地说,余华开始创造一个与现实生活完全不同的的世界,在这世界里人们所认同的理性法则失效,联系人与人之间纽带是利益,亲情、友情、爱情早已丧失,人们缺乏对自我价值的认知,每一个人只不过是被命运安排到人世间,为达到某种目的的工具,最后任凭命运牵引走向早已安排好的结局中去。
与俄国形式主义思想家和克莱夫贝尔的”有意味的形式”相似的是,余华强调文学作品对现实生活的反叛,形式主义理论也认为艺术作品应保持独立性与超功利性,艺术品的创造应该是脱离现实生活与社会历史的制约的”纯形式”,反对将艺术作为某种政治的或道德目的的手段。
而克莱夫贝尔也提出只有脱离现实层面而上升到审美体验才能真正体会出作品中的审美情感。
余华曾经说过”生活是不真实的,生活事实上是真假杂乱和鱼目混珠”,他反对传统作家为了迎合当代社会需要而进行文学创作,认为这样的描写只是在翻译”生活给我提供的东西”,做出了一种看似荒诞的文学表达方式的创新,作为这种尝试的结果,余华也说”使我自由地接近真实”。
但是笔者认为余华所提出的”虚伪的形式”并不是完全意义上的单纯追求形式而忽略生活内涵的观点。
余华提到的”日常生活围困的经验”不过是浮于表面的人们肤浅的认识,余华要利用荒诞的笔法,为了毫不掩饰地撕开生活中看似稳固的逻辑秩序的虚假面具,将充满原始欲望的丑陋的非理性的真实暴露出来。
他关注的是人性深层次的追求,目的是为了”写出更广阔的意义”。
在余华”虚伪的形式”的观念主导下,暴力、血腥、死亡、苦难等在传统文学作品中极少出现的词语却成了余华作品的主题,也正是由于这种对于”形式”的重视使得余华早期作品体现出叙述方式的精心雕琢,把人物与事件当成符号,忽视人物的性格而更多地展现欲望,从根本上触及了在人们心里根深蒂固的致命要害,让我们对于理性世界里看似和谐稳定的生活产生怀疑,这便达到了余华利用这种特殊的叙述方式所期待的效果,”作为先锋小说家的余华就不仅是符号的单纯玩弄,更在于通过这种貌似混乱,不合逻辑手段来表现他关注世界的独特方式,这也是”虚伪的作品”与”另一种真实”达成的合一。
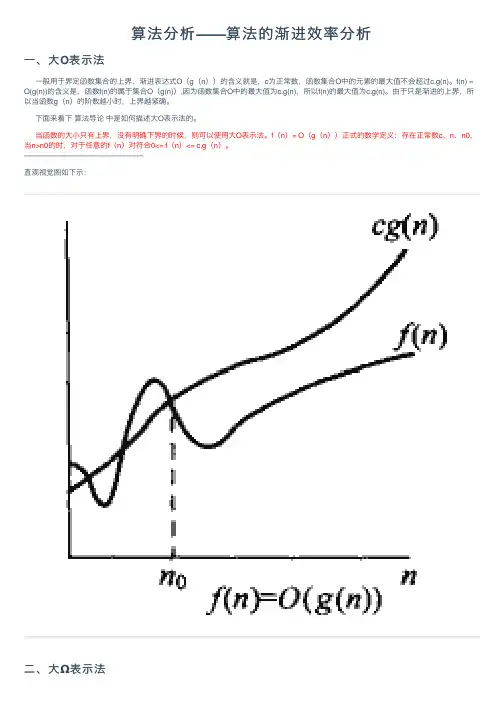
算法分析——算法的渐进效率分析⼀、⼤O表⽰法⼀般⽤于界定函数集合的上界,渐进表达式O(g(n))的含义就是,c为正常数,函数集合O中的元素的最⼤值不会超过c.g(n)。
f(n) = O(g(n))的含义是,函数f(n)的属于集合O(g(n)),因为函数集合O中的最⼤值为c.g(n),所以f(n)的最⼤值为c.g(n)。
由于只是渐进的上界,所以当函数g(n)的阶数越⼩时,上界越紧确。
下⾯来看下算法导论中是如何描述⼤O表⽰法的。
当函数的⼤⼩只有上界,没有明确下界的时候,则可以使⽤⼤O表⽰法。
f(n)= O(g(n))正式的数学定义:存在正常数c、n、n0,当n>n0的时,对于任意的f(n)对符合0<= f(n)<= c.g(n)。
————————————————直观视觉图如下⽰:⼆、⼤Ω表⽰法⼀般⽤于界定函数集合的下界,渐进表达式Ω(g(n))的含义就是,函数集合Ω中的元素的最⼩值不会低于c.g(n)。
f(n) = Ω(g(n))的含义是,函数f(n)的属于集合Ω(g(n)),因为函数集合Ω中的最⼩值为c.g(n),所以f(n)的最⼩值为c.g(n)。
算法导论中是如何描述⼤Ω表⽰法的。
当函数的⼤⼩只有下界,没有明确的上界的时候,可以使⽤⼤Ω表⽰法。
f(n)= Ω(g(n))正式的数学定义:存在正常数c、n、n0,当n>n0的时,对于任意的f(n)对符合0<= c.g(n)<= f(n)。
直观视觉图如下所⽰:三、⼤θ表⽰法⽤于界定函数的渐进上界和渐进下界。
当f(n)= θ(g(n))的时候,代表着g(n)为f(n)的渐进紧确界。
⽽θ渐进描述符在所有的渐进描述符中是最严格的⼀个,因为它既描述了函数的上界,有描述了函数的下界。
算法导论中是如何描述⼤θ表⽰法的。
f(n)= θ(c.g(n))正式的数学定义:存在正常数c1、c2、n、n0,当n>n0的时,对于任意的f(n)对符合c1.g(n)<= f(n)<= c2.g(n),c1.g(n)、c2.g(n)都是渐进正函数(当n趋于⽆穷⼤的时候,f(n)为正)。


模糊形式概念并行构造算法张卓;柴玉梅;王黎明;范明【期刊名称】《模式识别与人工智能》【年(卷),期】2013(26)3【摘要】Formal concept analysis ( FCA) is extensively applied in various fields of computer. Currently, constructing fuzzy concepts directly is still one of most important issues of the FCA field. However, the construction process is always with exponential time complexity. In order to improve the efficiency of building fuzzy concepts, a parallel algorithm called Parallel Fuzzy Next Closure (ParaFuNeC) is presented. It is parallel developed from the serial construction algorithm of fuzzy concepts. The proposed method maps the combination search space of fuzzy set into the natural number interval, so that search space is simply expressed, divided and traversed through natural number. Moreover, the algorithm produces balanced and independent sub-search spaces according to the number of CPU in present computing environment. It also avoids the time costs of synchronization and communication among parallel tasks. By the time complexity analysis and experimental evaluation of the proposed algorithm, it is proved that the speedup ratio of the proposed algorithm increases proportionally to the number of CPU in the case of large-scale computing tasks. Besides, the criterion of serial fraction is used to analyze the scalability of the proposed algorithm in experiments. The results showthat the algorithm ParaFuNeC also has better scalability in the case of large-scale computing tasks.% 形式概念分析理论已经广泛地应用于计算机诸多领域。


概念格构造算法(综述)
概念格⾃理论提出⾄今发展了近30年,已经成功应⽤于多个研究领域,如数据挖掘、机器学习、知识发现、软件⼯程、知识⼯程以及信息检索等。
概念格的构造算法是基于概念格的应⽤的关键。
现有的构造算法可以分为三类:批处理算法、渐进式算法和分布式算法,其中前两类是单机构造算法。
批处理算法是出现较早的⼀类构造算法,根据构造格的不同⽅式,可分为三类,即⾃顶向下、⾃底向上和枚举。
⾃顶向下类算法⾸先构造格的最上层节点,再逐层向下,较经典的算法有Bordat算法;⾃底向上算法则相反,⾸先构造最底层的节点,再向上扩展,如Chein算法;枚举算法是根据给定数据集,按照⼀定的顺序枚举出所有的节点,然后再⽣成节点间的关系,代表算法有Ganter算法等。
这类算法都需要多遍扫描数据库。
渐进式算法,⼜称增量式算法。
这类算法的基本思想都是将当前要插⼊的记录和格中概念进⾏交运算,根据结果采取不同的处理⽅法,主要区别在连接边的⽅法。
经典的有Godin算法,T. B. Ho算法等。
由于时间性能优越,现有的⼤多数概念格系统都是基于这类算法搭建的。
随着数据规模的迅速增长,概念格的分布式构造成为重要的研究内容。
⽬前我正在做相关研究,过段时间,我会把我的⽅法和现⾏的其他分布式⽅法做个对⽐,⼀起介绍给⼤家。
基于同层节点集划分的模糊概念格并行构造算法孙佳;柴玉梅【摘要】形式概念分析理论在诸多计算机领域得到广泛应用.模糊概念格的构造仍是其在应用过程中的一个主要问题.为提高模糊概念格的构造效率,对串行算法进行并行化改造,提出模糊概念格的并行构造算法.该算法对节点进行层次划分,给出了同层节点的定义,得出同层节点构造任务相互独立的重要性质,并引入映射函数简化搜索空间的遍历,提高搜索模糊概念格的效率,并行构造模糊概念格,达到了提高构造效率的目的.实验表明该算法在面对大规模的构造任务时,具有良好的性能.【期刊名称】《计算机应用与软件》【年(卷),期】2016(033)007【总页数】6页(P261-265,286)【关键词】模糊概念格构造;模糊集;节点分层;并行算法【作者】孙佳;柴玉梅【作者单位】郑州大学信息工程学院河南郑州450001;郑州大学信息工程学院河南郑州450001【正文语种】中文【中图分类】TP311形式概念分析FCA(Formal Concept Analysis)由德国学者Wille提出的一种基于形式背景表示形式概念的模型,即概念格[1]。
这种概念层次结构是数据分析及规则提取的有效工具,已被广泛应用于文本处理,知识表达,知识挖掘,专家系统等领域[2-6]。
但是在许多应用中,大多数信息都是模糊的、复杂的,传统的形式概念分析很难表达这些模糊的、不确定的信息。
为解决这个问题,Burusco等人提出了L-模糊形式背景[7],并将Zadeh的模糊集合理论与形式概念分析相结合,构造模糊形式概念分析FFCA(Fuzzy formal concept analysis),这一新研究领域[7,8]。
在L-模糊形式背景规模较大时,从L-模糊形式背景构造模糊概念格通常会引起组合爆炸,模糊概念格的构造效率是其在应用过程中的一个主要问题。
对基本算法的并行化改造被用来作为提高构造效率的有效途径,多名研究人员通过这种方法取得了并行构造算法的研究成果。
第28卷第l期2012年1月苏州大学学报(自然科学版)J O U R N A L0F S00C H O W U N I V E R SI TY(N A T U R A L SC IE N C E ED I‘兀O N)V ol28N o.1Ja l l.2012一种基于资格迹的并行强化学习算法杨旭东,刘全,李瑾(苏州大学计算机科学与技术学院,江苏苏州215006)摘要:强化学习是一种重要的机器学习方法,然而在实际应用中,收敛速度缓慢是其主要不足之一.为了提高强化学习的效率,提出了一种基于资格迹的并行强化学习算法,并给出了算法实现的框架模型和一些可行的优化方法.由于使用资格迹的算法具有内在的并行性,可以使用多个计算结点分摊值函数表和资格迹表的更新工作,从而实现提高整个系统学习效率的目的.实验结果表明该方法与当前两种主要的并行强化学习算法相比具有一定的优势.关键词:并行算法;强化学习;s ar B a(A)学习;T i c—t a c-t oe中图分类号:TP309文献标识码:A文章编号:1000一2073(2012)01—0026—08Pa r al l e l r ei nf orcem ent l e ar I I i ng训t l l eli西bi l i ty t r ace s,、Y ang X udong,L i u Q uan,L i J i n(Sch00l of C om p ut er Sci ence and T ech nol o料,S00chow U n i ver吕i Iy,S uzho u215006,C hi n a)A bs t r a ct:R ei nf or c em ent l ea m i ng is an i m port a nt m ach i ne l ea m i ng m e t hod.H ow eV er,s l ow c o nV e r-genc ehas been one of t he m a i n cha U enges i n t he a r ea of r ei nfor c em e nt l eanI i ng.T o i m pm V e t he em-c i e ncy of exi st i ng r ei nf orcem ent l eam i ng al gor i t hm s,a par al l el r ei nf orcem ent l eam i ng a l gor i t hmf hm e w or k w i山el i gi bi l i t y t m ces i s pr opos e d.T o t a ke adV an t age of t he i nhe re nt par aI l e Ji sm f曲nd i nr ei nfor c em e nt1ea m i ng a l gor i t hm s w i t h el i gi bi l i t y t m ces,m ul t i pl e com pu t i ng nodes ar e us ed t oget he rt o t ake cha唱e of山e val ue f unct i on t a bl e and el i gi bi l i t y t r a ce t abl e.Som e opt i m i z at i ons of t lle algo—r i t hm f r am ew or k ar e gi ven.T he exp er i m ent al r e sul t s sh ow t ha t t he p加pos ed m et h od has ce r t ai n a d-van t ag es com par ed t o t w o ot her exi st i ng pam l l el r ei nf orcem ent l ea m i ngm et hods.K ey w or ds:p唧1l el al g or i t hm s;r ei nf orcem ent l eam i ng;Sar8a(A)一l eam i ng;T¨ac—t oeO引言强化学习是一种重要的机器学习和智能优化方法.在强化学习中,学习A gent通过与环境的交互来改进自身的行为.马尔科夫决策过程(M D P)模型是一种通用的对强化学习问题建模的方法,它把强化学习问题描述为一个四元组<5,A,r,R>,其中s表示环境的状态集合,A表示A gent的动作集合,丁:s×A—PD(s)表示状态转移函数,R:.s×A—R表示奖赏函数.强化学习系统通过A gent选择动作作用于环境,引起环境状态发生迁移,并从伴随着状态的迁移过程产生的反馈信息中学习,不断累积经验,提高系统的决策能力.强化学习涉及到两个困难问题…:一个是结构信度分配问题,当问题空间太大而无法完全搜索时,智能系统必须有能力根据相似环境下的经验推测出新的环境;另一个是时间信度分配问题,设想一个智能系统执收稿日期:2011—10—3l基金项目:国家自然科学基金(60873116,61070223);江苏省自然科学基金(B l(2008161);江苏省高校自然科学基金(09K J A520002)作者简介:杨旭东(1987一),男,江苏盐城人,硕士研究生,主要研究向为机器学习、挖掘.第1期杨旭东,等:一种基于资格迹的并行强化学习算法行了一系列动作,最后得到一个结果,它必须解决如何对每个状态或状态一动作对给予奖励或惩罚,以调整它的决策,改善它的性能.强化学习中的资格迹为解决时间信度分配问题提供了有效的方法.目前,收敛速度慢是强化学习算法的主要不足之一.通过并行学习的方式可以提高强化学习算法的性能.目前对于并行强化学习的研究,主要集中在两个方面.第一个方面是从“功能分解”的角度出发,尝试用多个共享信息的同质A gent并行学习来加速学习过程¨1.在这种方法下,每个A gent独立地学习相同的任务,并周期性地与其他A gent s共享学习经验,其学习步骤如图1所示.虽然该方法可以在一定程度上提高算法的收敛速度,但是在这种并行方式下,某些A gent s的学习经验可能会被丢弃或浪费,因为其他A gent s也在学习同样的事情.同时,该方法需要较大的存储空间和较高的通信带宽.由于上述重复学习过程和通信开销的存在,采用这种方式的并行算法难以获得线性加速比(n个计算结点只需要1A的计算时间).第二个方面是从“域分解”的角度出发,把大规模学习问题分解为多个规模较小的子问题,这些分解得到的子问题可以并行求解,最后通过融合每个子问题的学习结果得到整个问题的解.文献[3]提出的算法就属于这一范畴.这种方式的并行学习算法的难点在于如何消除子问题间的相互依赖关系,使得每个子问题可以相对独立地学习,以及如何让子问题间不需要频繁地相互通信.该方法的一个缺陷就是,子问题问缺乏高效的通信方式以及子问题的调度顺序难以确定.步骤l步骤2图1多A ge nt并行学习本文同时从“域分解”和“功能分解”两个角度出发,利用多个计算结点来并行处理基于资格迹的学习算法.由于计算过程被多个计算结点分摊,A gent的决策时间大大缩短,响应速度有所提高,因而该方法适合应用于对实时性要求较高的在线学习任务,同时由于资格迹的使用,该方法能够很好地处理延时学习任务.1资格迹与强化学习资格迹这一概念最初是由K l opf从认知科学的角度提出的,现已成为一种重要的强化学习基本机制.Sut.t on和s i ngh最早把资格迹应用于强化学习.对这一问题比较系统的研究体现在s ut t on的博士论文中H o.从认知记忆的角度出发,资格迹模拟了一个短期记忆过程,比如当一个状态被访问或一个动作被执行时,资格迹表示对该事情的一个随时间逐渐衰减的记忆,这个迹标志这个状态或动作对于学习是有资格的.当迹不为零时,如果一个不可预测的好或坏的事件发生了,那么该状态或动作就要赋予一定的信度.在强化学习中引入资格迹,使得学习算法更有效率和更快收敛.使用资格迹的强化学习A gent不仅需要维护值函数表,而且还需要维护一个相应的资格迹表,表中的每个元素表示相应的状态(或状态一动作对)对于当前事情的信度或资格.A gent根据当前探索获得的反馈(奖赏值r),计算当前状态(或状态一动作对)的值函数的新的估计和旧的估计的误差6,即TD Er r or.在TD(A)算法中,6=r+yy(s’)一y(s);在Q(A)算法中,6=r+yQ(s’,Ⅱ’)一Q(s,o).学习算法根据6的值更新所有具有资格的状态(或状态一动作对)的值函数,通常状态值的更新形式如下:y(s)一y(s)+d&(s),其中y(s)表示状态s的值函数,e(s)表示状态s的资格,即其对于产生占的贡献度,a是学习率.资格大小的不同会导致不同的更新幅度,具有较大资格的状态(或状态一动作对)将会获得较大的更新,即其分配到较大的时间信度;相应地,资格小的状态(或状态动作对)将会获得较小的时间信度,表示它从当前事情中获得的奖励或惩罚较小.资格迹就是用来追踪每个状态(或状态一动作对)的资格大小,它通过一些启发信息来把刚刚收到的强化信息分配到以前的状态或行为.可以考虑两种启发信息,即频度和渐新度¨1.频度启发信息是根记录过去的状态或行为所发生的次来进行苏州大学学报(自然科学版)第28卷信度分配,发生次数高的状态或行为应该赋予较高的信度.渐新度启发信息根据动作产生的时效性来分配信度,所分配的信度是产生状态或动作和产生强化信息的时间间隔的单调下降函数,即越早产生的状态或动作分配到的信度就越小,而最近产生的状态或动作分配到的信度就越大,当时间间隔为无穷时信度为零.通常,资格迹根据折扣因子’,(0≤y≤1)和衰减因子A(0≤A≤1)的乘积指数衰减.衰减因子是实现渐新度启发思想的一种通用方法.而频度启发思想体现在资格迹的更新公式中(如公式(1)).资格迹一般分为累加迹和替换迹两种.用e。
概念三元格渐进式构造算法
三元格渐进式构造算法(Tripelet Progressive Construction Algorithm,简称TPCA)是一种设计机器学习模型的优化算法。
三元格渐进式构造算法的思想是将模型的每一步都当作一个精细的建模任务,并为不同阶段的模型提出针对性的建模策略。
它有三个阶段:
1.增量构造:在此阶段,优化算法从一个简单的模型开始,然后对模型逐步构造,以达到最优。
2.集中式构造:在此阶段,优化算法通过特征选择、正则化和特征聚类来尽量减少模型的复杂性,以最大化模型的预测评估数据。
3.迁移构造:在此阶段,优化算法根据数据集的类形态分析,迁移模型的不同结构。
通过迁移,最优模型能够更有效地模拟真实的场景。
三元格渐进式构造算法优势明显,它降低了模型复杂度,显著提升了预测准确性。
得益于它多步构造的特性,增量构造部分保证了模型的稳定性和准确性,使模型所使用的代价更加小;集中式构造部分解决了模型过度训练和设计复杂度高的问题;迁移构造部分更好地模拟真实场景并满足数据集的多样性要求。
此外,三元格渐进式构造算法也有一些缺点。
它的构造过程较长,需
要额外的时间消耗和空间占用;同时,三元格构造算法较为依赖数据,在没有足够数据的情况下会受到影响。
总的来说,三元格渐进式构造算法是一种构建机器学习模型的有效算法,其优势明显,有助于提高模型的预测准确性及稳定性,同时也有
一些缺点。
面向多尺度拓扑优化的渐进均匀化GPU并行算法研究随着计算机技术的不断发展,GPU并行计算已经成为目前各个领域中广泛应用的一种计算方式。
在许多科学和工程应用中,拓扑优化是一项非常重要的任务,例如在网络分析、物理建模、图像处理等领域都有广泛的应用。
然而,传统的拓扑优化算法在大规模问题上的计算效率并不高,在面对多尺度问题时更是存在许多挑战。
本文将介绍一种面向多尺度拓扑优化的渐进均匀化GPU并行算法,该算法可以有效地提高拓扑优化问题在大规模和多尺度情况下的计算效率。
一、引言拓扑优化是一种通过改变物体的形状、尺寸和拓扑结构来提高其性能的方法。
在传统的拓扑优化算法中,通常使用迭代的方式,通过改变设计的参数来优化结构。
然而,面对大规模和多尺度的问题,传统的算法往往需要消耗大量的计算资源和时间。
因此,寻找一种高效的并行算法来解决这些问题是非常有意义的。
二、渐进均匀化GPU并行算法的原理渐进均匀化GPU并行算法是一种利用GPU并行计算能力来加速拓扑优化的算法。
该算法通过将拓扑优化问题划分为多个子问题,并使用GPU并行计算来加速求解过程。
具体而言,算法首先将原始问题划分为多个较小的规模相同的子问题,然后使用GPU并行计算来求解这些子问题。
之后,通过迭代的方式逐步增加子问题的规模,直到达到原始问题的规模。
这样可以有效地利用GPU的并行计算能力,提高计算效率。
三、渐进均匀化GPU并行算法的实现在实现渐进均匀化GPU并行算法时,需要考虑以下几个关键问题:1. 子问题划分:合理划分子问题是算法成功实现的关键。
基于多尺度的特点,可以使用自适应方法来划分子问题的规模。
2. 数据传输:由于GPU和CPU之间的数据传输速度较慢,因此需要合理设计数据传输的方法,以减少数据传输的时间。
3. 并行计算:在GPU上同时处理多个子问题需要合理设计并行计算的方法,以充分利用GPU的并行计算能力。
四、实验与结果分析为了验证渐进均匀化GPU并行算法的有效性,我们在多个拓扑优化问题上进行了实验。
实值形式背景下概念格的渐进式并行构造算法郭泽蔚;姜麟;李金海【摘要】经典的形式概念分析主要应用于属性值为布尔值的形式背景中,然而在很多实际应用领域,由于问题的复杂性,更多的形式背景中属性值为普通实值.这种实值虽然更为适合用来刻画实际问题的不确定性,但由于算法的复杂性大,当数据背景比较大时,传统意义上的算法并不能有效地解决概念的抽取问题.随着高性能并行技术的发展与成熟,并行计算机的成本与费用越来越低,通过适当的并行化手段,将其应用于形式概念分析领域可以显著提高算法的效率.文中基于实值形式背景,提出了一种构造实值概念格的渐进式算法,且通过对渐进式构造过程的分析,将算法并行化.通过数值实验对比了串行与并行算法的运算时间,给出了该算法并行化的加速效率.%Classical formal concept analysis is mainly used in the formal context whose attributes are Booleanvalued.However,in many fields of practical applications,due to the complexity of the problem,attributes are ordinary real-valued in more backgrounds.Although this kind of attributes are more appropriate for describing the uncertainty of practical problem,the high complexity makes traditional algorithms less effective in extracting concepts when the data under consideration is relatively large.With the development and maturity of high-performance parallel technology,the expense and cost of parallel computers become less and less,so it deserves to apply parallel technology in formal concept analysis for improving the efficiency of mining concepts.Based on the real formal context,this paper puts forward an incremental algorithm which is used to extract real-valued concept lattice.And then through analyzing the process of incrementallyupdating,the algorithm is parallelized.Finally,numerical experiments are conducted to compare serial and parallel algorithms,which verifies the acceleration efficiency of the proposed parallel algorithm.【期刊名称】《西北大学学报(自然科学版)》【年(卷),期】2018(048)003【总页数】8页(P335-342)【关键词】实值形式背景;概念格构造;渐进式算法;并行化【作者】郭泽蔚;姜麟;李金海【作者单位】昆明理工大学理学院,云南昆明650500;昆明理工大学理学院,云南昆明650500;昆明理工大学数据科学研究中心,云南昆明650500【正文语种】中文【中图分类】TP18形式概念分析(Formal concept analysis)是20世纪80年代初期由德国教授R.Wille提出的一种用于发现知识的理论。
形式概念分析通过构造概念格来进行数据的处理,也称概念格理论[1]。
以往关于概念格的研究主要集中于经典的形式背景,即属性值为Boolean值,然而,由于现实中数据的复杂性,更多的形式背景中的属性值是区间形式的普通实值。
经典的概念格主要应用于发现二值(或多值)形式背景的概念构造,因此,传统形式背景中概念格的构造方法并不适用于实值形式背景[3-4]。
而实值形式背景概念格的构造存在算法复杂性大等缺陷,现阶段围绕这一类问题的研究也缺少较好的普适性,故进一步讨论实值概念格的构造具有一定的意义。
Matlab已成为数值计算领域的主流工具,其拥有的并行计算工具箱(Parallel computing toolbox,PCT)和并行计算服务(Distributed computing server,DCS)可以实现基于多处理器平台和集群平台的多种并行计算任务,利用PCT和DCS,用户无需关心多核、多处理器之间以及集群之间的底层数据通信,可以将更多的精力放在并行算法的设计,充分利用Matlab提供的数值计算模块和数据显示功能,高效便捷的完成并行计算任务[5]。
经典形式背景下的建格算法并不适用于处理实值形式背景下的概念格,而串行算法在数据规模较大的情况下计算效率较低。
针对实值形式背景的特点,结合经典概念格的渐进式构造思想,本文首先给出了计算实值概念格的方法;然后提出了一种实值概念格计算的渐进式构造算法,并对其进行改进,得到并行算法,应用Matlab对串、并算法进行程序的实现;最后通过数值实验对该算法的串行与并行运行效率作了对比,对该算法在特定实值条件下的并行化可行性进行了评估。
1 实值形式背景与实概念格1.1 实集定义1[6] 设R为实数集。
对于μ,v∈R,称I=[μ,v]为R上的一个实区间,其中μ和v 分别称为实区间I的上界和下界。
如果μ>v,则称实区间I是空的,记为[,]。
显然,当I=[μ,v]非空时,I就是由μ到v之间的全部实数构成的集合。
对于两个实区间I1=[μ1,v1]和I2=[μ2,v2],它们的交Inter(I1,I2)满足:Inter(I1,I2)=[max(μ1,μ2),min(ν1,ν2)]定义{I1,I2}的闭包为Closure({I1,I2})=n个实区间的闭包算子可表示如下:Closure({I1,I2,…,In})=Closure({Closure({I1,I2}),…,In})在此基础上,定义两个实区间集D={I1,I2,…,Ir}和的并运算和交运算分别为定义2[6] 设U={x1,x2,…,xn}是一个维度为n的对象集,A是R上所有实区间组成的集合,P(A)是A的幂集。
U上的一个实集通过其特征函数来定义,即均为实区间集,每个表明了元素xi在实集中的所有可能的取值。
则可表示为并记U上所有实值构成的集合为R(U)。
一般地,假设每个中的实区间均两两不相交。
为了简洁起见,与记为等价,并把U上的实空集表示为:集合中的交运算和并运算也同样适用于实集,实集中有两种交(并)运算,分别为L-交(并)和S-交(并)。
下面给出定义[7]。
设为U={x1,x2,…,xn}上的两个实集,称主要小于记为如果对任意的存在使得μ′≤μ且ν′≥ν;称主要包含于记作如果对任意的xi∈U,有成立和的L-交,L-并分别定义为其次,介绍S-交和S-并。
称严格小于记为如果对任意的存在使得μ≤μ′且ν≥ν′;称严格包含于记作如果对任意的xi∈U,有成立和的S-交,S-并分别定义为1.2 实值形式背景与实概念格设U={x1,x2,…,xn}为一个非空有限对象集,A={a1,a2,…,am}为一个非空有限属性集。
定义在笛卡尔积U×A上的一个实二元关系是指它的每个关系值均为实区间集,即对任意的是一个实区间集。
定义3[8] 称三元组为一个实值形式背景,如果是U×A上的一个实二元关系。
例1 表1给出了一个实值形式背景。
表1 实值形式背景abcd x1{[5,7],[8,9]}{[10,11]}{[7,9],[11,14]}{[5,8]}x2{[6,8]}{[7,9],[11,12]}{[9,12],[14,17]}{[4,4],[7,8]}x3{[9,11]}{[8,10]}{[10,12]}{[1,5]} x4{[10,11]}{[9,10]}{[9,10]}{[1,5]}设为实值形式背景,X⊆U。
对任意的a∈A,记:可以看出,f(a)是由取并得到的一个实区间集,即f(a)包含且仅包含a属性下所有对象对应的实区间;g(a)是由取交得到的一个实区间集,即g(a)包含且仅包含a属性下所有对象对应实区间的交集。
定义4[6] 设为实值形式背景,P(U)是U的幂集。
算子∧,↑:P(U)→R(A)和∨,↓:R(A)→P(U)定义为:(∀X∈P(U))∀(∀(∀X∈P(U))∀(∀从上式中可以看出,X∧是A上的一个实集,它的每个特征函数值为是使得每个均主要小于的对象x全体构成的集合。
X↑和B↓可类似地进行解释。
利用上述4个算子,可以定义两种实概念[3]:L-实概念和S-实概念。
具体地,对于如果有且则称序对为的一个L-实概念;如果有且则称序对为的一个S-实概念。
与传统的概念格相似,这里不论是L-实概念还是S-实概念,都称X为的外延,为的内涵[6]。
继而,根据上述判断条件,可以得到表1中实值形式背景的所有满足条件的L-实概念:根据前面的讨论,对于实值形式背景,可构造两类实概念格:L-实概念格和S-实概念格。
然而,这两种概念格框架的构建及相关讨论是类似的,故在此只给出基于L-实概念格构建的背景属性框架。
需要指出的是,只要将该约简框架的中所有与L-实概念格相关的符号都替换为S-实概念格中相应的符号,就可以得到基于S-实概念格构建的实值形式属性背景框架。
1.3 概念格的构造算法概念格的构造过程实际上就是概念聚类的过程,概念格一个重要的属性就是其完备性使得对于同样的一个数据集,每次生成的格都是唯一的,即对象、属性的排列顺序和格构造算法均不会影响其构造的结果。
因此,现有的关于概念格的构造算法都是为了提高建格的效率,减少建格的复杂度而设计的[9]。
经典形式背景概念格的串行构造算法大致可分为两类:批处理算法、渐进式算法。
批处理算法主要思想:首先要生成所有的格节点,即原形式背景中所有的概念的集合,然后根据它们之间的前驱-后继关系生成边,完成格的构造。
比较经典的有Bordat算法[10-11]。