实验三 多次迭代滑动平均法程序设计
- 格式:doc
- 大小:107.00 KB
- 文档页数:9

滑动平均法matlab编程
滑动平均法matlab编程
滑动平均法是一种信号处理方法,经常被用来降低噪声和平滑数据。
它的实现方法是将一段时间内的数据平均起来,然后作为一个新数据点。
MATLAB中提供了使用滑动平均法的函数smooth。
使用滑动平均法的基本语法如下:
```matlab
y_new = smooth(y);
```
其中,y代表原始数据,y_new代表平滑后的数据。
如果需要更多的数据处理选项,也可以使用下列语法:
```matlab
y_new = smooth(y, span, method);
```
其中,span代表处理数据的时间段,method代表平滑数据使用的方法。
例如,对于一个长度为n的数据向量,如果我们想要对每个数据点的前m个数据进行平滑处理,可以通过以下代码实现:```matlab
y_new = smooth(y, m);
```
另外,如果我们想要使用移动平均法作为平滑的方法,可以通过以下代码实现:
```matlab
y_new = smooth(y, m, 'moving');
```
需要注意的是,虽然滑动平均法是一种简单和有效的信号处理方法,但是它也有其局限性。
当数据中包含大量突然变化时,滑动平均法的平滑效果可能不佳,因此需要根据具体数据进行判断是否使用该方法。
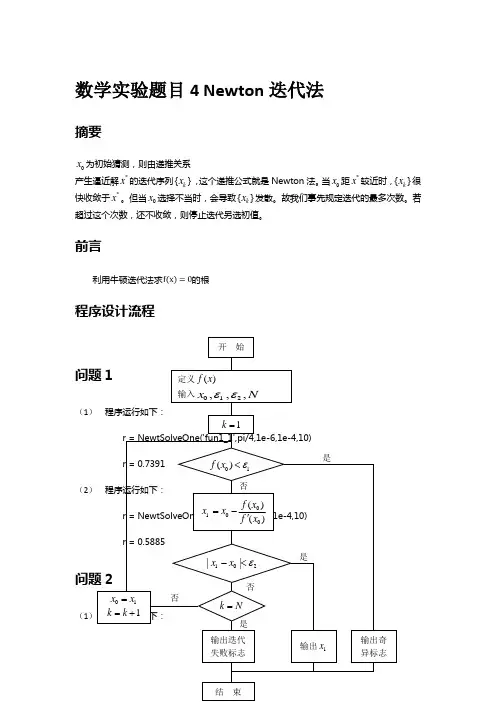
数学实验题目4 Newton 迭代法摘要0x 为初始猜测,则由递推关系产生逼近解*x 的迭代序列{}k x ,这个递推公式就是Newton 法。
当0x 距*x 较近时,{}k x 很快收敛于*x 。
但当0x 选择不当时,会导致{}k x 发散。
故我们事先规定迭代的最多次数。
若超过这个次数,还不收敛,则停止迭代另选初值。
前言利用牛顿迭代法求的根程序设计流程问题1(1 程序运行如下:r = NewtSolveOne('fun1_1',pi/4,1e-6,1e-4,10) r = 0.7391(2 程序运行如下:r = NewtSolveOne('fun1_2',0.6,1e-6,1e-4,10) r = 0.5885问题2(1 程序运行如下:否 是否是是定义()f x输入012,,,x N εε开 始1k =01()f x ε<0100()()f x x x f x =-'102||x x ε-<k N =输出迭代失败标志输出1x输出奇 异标志结 束01x x = 1k k =+ 否r = NewtSolveOne('fun2_1',0.5,1e-6,1e-4,10)r = 0.5671(2)程序运行如下:r = NewtSolveOne('fun2_2',0.5,1e-6,1e-4,20)r = 0.5669问题3(1)程序运行如下:①p = LegendreIter(2)p = 1.0000 0 -0.3333p = LegendreIter(3)p = 1.0000 0 -0.6000 0p = LegendreIter(4)p =1.0000 0 -0.8571 0 0.0857p = LegendreIter(5)p = 1.0000 0 -1.1111 0 0.2381 0②p = LegendreIter(6)p = 1.0000 0 -1.3636 0 0.4545 0 -0.0216r = roots(p)'r= -0.932469514203150 -0.6612 0.9324695142031530.6612 -0.238619186083197 0.238619186083197用二分法求根为:r = BinSolve('LegendreP6',-1,1,1e-6)r = -0.932470204878826 -0.661212531887755 -0.2386200573979590.2386 0.661192602040816 0.932467713647959(2)程序运行如下:①p = ChebyshevIter(2)p = 1.0000 0 -0.5000p = ChebyshevIter(3)p = 1.0000 0 -0.7500 0p = ChebyshevIter(4)p = 1.0000 0 -1.0000 0 0.1250p = ChebyshevIter(5)p = 1.0000 0 -1.2500 0 0.3125 0②p = ChebyshevIter(6)p = 1.0000 0 -1.5000 0 0.5625 0 -0.0313r = roots(p)'r = -0.965925826289067 -0.7548 0.9659258262890680.7547 -0.258819045102521 0.258819045102521用二分法求根为:r = BinSolve('ChebyshevT6',-1,1,1e-6)r = -0.965929926658163 -0.7755 -0.2588289221938780.2588 0.7020 0.965924944196429与下列代码结果基本一致,只是元素顺序稍有不同:j = 0:5;x = cos((2*j+1)*pi/2/(5+1))x =0.965925826289068 0.7548 0.258819045102521-0.258819045102521 -0.7547 -0.965925826289068(3)程序运行如下:①p = LaguerreIter(2)p = 1 -4 2p = LaguerreIter(3)p = 1 -9 18 -6p = LaguerreIter(4)p = 1 -16 72 -96 24p = LaguerreIter(5)p =1.0000 -25.0000 200.0000 -600.0000 600.0000 -120.000②p = LaguerreIter(5)p =1.0000 -25.0000 200.0000 -600.0000 600.0000 -120.000r = roots(p)'r =12.6432 7.8891 3.5964257710407111.4520 0.263560319718141用二分法求根为:r = BinSolve('LaguerreL5',0,13,1e-6)r = 0.263560314567722 1.4789 3.5964257656311507.0720 12.6490(4)程序运行如下:①p = HermiteIter(2)p = 1.0000 0 -0.5000p = HermiteIter(3)p = 1.0000 0 -1.5000 0p = HermiteIter(4)p = 1.0000 0 -3.0000 0 0.7500p = HermiteIter(5)p = 1.0000 0 -5.0000 0 3.7500 0②p = HermiteIter(6)p = 1.0000 0 -7.5000 0 11.2500 0 -1.8750r = roots(p)'r =-2.3587 2.3588 -1.3358490740136961.335849074013698 -0.4367 0.4366用二分法求根为:r = BinSolve('HermiteH6',-3,3,1e-6)r =-2.3516 -1.335849********* -0.43630.4366 1.335848983453244 2.3504所用到的函数function r = NewtSolveOne(fun, x0, ftol, dftol, maxit)% NewtSolveOne 用Newton法解方程f(x)=0在x0附近的一个根%% Synopsis: r = NewtSolveOne(fun, x0)% r = NewtSolveOne(fun, x0, ftol, dftol)%% Input: fun = (string) 需要求根的函数及其导数% x0 = 猜测根,Newton法迭代初始值% ftol = (optional)误差,默认为5e-9% dftol = (optional)导数容忍最小值,小于它表明Newton法失败,默认为5e-9 % maxit = (optional)迭代次数,默认为25%% Output: r = 在寻根区间内的根或奇点if nargin < 3ftol = 5e-9;endif nargin < 4dftol = 5e-9;endif nargin < 5maxit = 25;endx = x0; %设置初始迭代位置为x0k = 0; %初始化迭代次数为0while k <= maxitk = k + 1;[f,dfdx] = feval(fun,x); %fun返回f(x)和f'(x)的值if abs(dfdx) < dftol %如果导数小于dftol,Newton法失败,返回空值r = [];warning('dfdx is too small!');return;enddx = f/dfdx; %x(n+1) = x(n) - f( x(n) )/f'( x(n) ),这里设dx = f( x(n) )/f'( x(n) )x = x - dx;if abs(f) < ftol %如果误差小于ftol,返回当前x为根r = x;return;endendr = []; %如果牛顿法未收敛,返回空值function p = LegendreIter(n)% LegendreIter 用递推的方法计算n次勒让德多项式的系数向量Pn+2(x) = (2*i+3)/(i+2) * x*Pn+1(x) - (i+1)/(i+2) * Pn(x)%% Synopsis: p = LegendreIter(n)%% Input: n = 勒让德多项式的次数%% Output: p = n次勒让德多项式的系数向量if round(n) ~= n | n < 0error('n必须是一个非负整数');endif n == 0 %P0(x) = 1p = 1;return;elseif n == 1 %P1(x) = xp = [1 0];return;endpBk = 1; %初始化三项递推公式后项为P0pMid = [1 0]; %初始化三项递推公式中项为P1for i = 0:n-2pMidCal = zeros(1,i+3); %构造用于计算的x*Pn+1pMidCal(1:i+2) = pMid;pBkCal = zeros(1,i+3); %构造用于计算的PnpBkCal(3:i+3) = pBk;pFwd = (2*i+3)/(i+2) * pMidCal - (i+1)/(i+2) * pBkCal; %勒让德多项式三项递推公式Pn+2(x) = (2*i+3)/(i+2) * x*Pn+1(x) - (i+1)/(i+2) * Pn(x)pBk = pMid; %把中项变为后项进行下次迭代pMid = pFwd; %把前项变为中项进行下次迭代endp = pFwd/pFwd(1); %把勒让德多项式最高次项系数归一化function p = ChebyshevIter(n)% ChebyshevIter 用递推的方法计算n次勒让德-切比雪夫多项式的系数向量Tn+2(x) = 2*x*Tn+1(x) - Tn(x)%% Synopsis: p = ChebyshevIter(n)%% Input: n = 勒让德-切比雪夫多项式的次数%% Output: p = n次勒让德-切比雪夫多项式的系数向量if round(n) ~= n | n < 0error('n必须是一个非负整数');endif n == 0 %T0(x) = 1p = 1;return;elseif n == 1 %T1(x) = xp = [1 0];return;endpBk = 1; %初始化三项递推公式后项为T0pMid = [1 0]; %初始化三项递推公式中项为T1for i = 0:n-2pMidCal = zeros(1,i+3); %构造用于计算的x*Tn+1pMidCal(1:i+2) = pMid;pBkCal = zeros(1,i+3); %构造用于计算的PnpBkCal(3:i+3) = pBk;pFwd = 2*pMidCal - pBkCal; %勒让德-切比雪夫多项式三项递推公式Tn+2(x) = 2*x*Tn+1(x) - Tn(x)pBk = pMid; %把中项变为后项进行下次迭代pMid = pFwd; %把前项变为中项进行下次迭代endp = pFwd/pFwd(1); %把勒让德-切比雪夫多项式最高次项系数归一化function p = LaguerreIter(n)% LaguerreIter 用递推的方法计算n次拉盖尔多项式的系数向量Ln+2(x) = (2*n+3-x)*Ln+1(x) - (n+1)*Ln(x)%% Synopsis: p = LaguerreIter(n)%% Input: n = 拉盖尔多项式的次数%% Output: p = n次拉盖尔多项式的系数向量if round(n) ~= n | n < 0error('n必须是一个非负整数');endif n == 0 %L0(x) = 1p = 1;return;elseif n == 1 %L1(x) = -x+1p = [-1 1];return;endpBk = 1; %初始化三项递推公式后项为L0pMid = [-1 1]; %初始化三项递推公式中项为L1for i = 0:n-2pMidCal1 = zeros(1,i+3); %构造用于计算的x*Ln+1(x)pMidCal1(1:i+2) = pMid;pMidCal2 = zeros(1,i+3); %构造用于计算的Ln+1(x)pMidCal2(2:i+3) = pMid;pBkCal = zeros(1,i+3); %构造用于计算的Ln(x)pBkCal(3:i+3) = pBk;pFwd =( (2*i+3)*pMidCal2 - pMidCal1 - (i+1)*pBkCal )/ (i+2); %拉盖尔多项式三项递推公式Ln+2(x) = (2*n+3-x)*Ln+1(x) - (n+1)^2*Ln(x)pBk = pMid; %把中项变为后项进行下次迭代pMid = pFwd; %把前项变为中项进行下次迭代endp = pFwd/pFwd(1); %把拉盖尔多项式最高次项系数归一化function p = HermiteIter(n)% HermiteIter 用递推的方法计算n次埃尔米特多项式的系数向量Hn+2(x) = 2*x*Hn+1(x) - 2*(n+1)*Hn(x)%% Synopsis: p = HermiteIter(n)%% Input: n = 埃尔米特多项式的次数%% Output: p = n次埃尔米特多项式的系数向量if round(n) ~= n | n < 0error('n必须是一个非负整数');endif n == 0 %H0(x) = 1p = 1;return;elseif n == 1 %H1(x) = 2*xp = [2 0];return;endpBk = 1; %初始化三项递推公式后项为L0pMid = [2 0]; %初始化三项递推公式中项为L1for i = 0:n-2pMidCal = zeros(1,i+3); %构造用于计算的x*Hn+1(x)pMidCal(1:i+2) = pMid;pBkCal = zeros(1,i+3); %构造用于计算的Hn(x)pBkCal(3:i+3) = pBk;pFwd =2*pMidCal - 2*(i+1)*pBkCal; %埃尔米特多项式三项递推公式Hn+2(x) = 2*x*Hn+1(x) - 2*(n+1)*Hn(x)pBk = pMid; %把中项变为后项进行下次迭代pMid = pFwd; %把前项变为中项进行下次迭代endp = pFwd/pFwd(1); %把拉盖尔多项式最高次项系数归一化function r = BinSolve(fun, a, b, tol)% BinSolve 用二分法解方程f(x)=0在区间[a,b]的根%% Synopsis: r = BinSolve(fun, a, b)% r = BinSolve(fun, a, b, tol)%% Input: fun = (string) 需要求根的函数% a,b = 寻根区间上下限% tol = (optional)误差,默认为5e-9%% Output: r = 在寻根区间内的根if nargin < 4tol = 5e-9;endXb = RootBracket(fun, a, b); %粗略寻找含根区间[m,n] = size(Xb);r = [];nr = 1; %初始化找到的根的个数为1maxit = 50; %最大二分迭代次数为50for i = 1:ma = Xb(i,1); %初始化第i个寻根区间下限b = Xb(i,2); %初始化第i个寻根区间上限err = 1; %初始化误差k = 0;while k < maxitfa = feval(fun, a); %计算下限函数值fb = feval(fun, b); %计算上限函数值m = (a+b)/2;fm = feval(fun, m);err = abs(fm);if sign(fm) == sign(fb) %若中点处与右端点函数值同号,右端点赋值为中点b = m;else %若中点处与左端点函数值同号或为0,左端点赋值为中点a = m;endif err < tol %如果在a处函数值小于tolr(nr) = a; %一般奇点不符合该条件,这样可以去除奇点nr = nr + 1; %找到根的个数递增k = maxit; %改变k值跳出循环endk = k + 1; %二分迭代次数递增endendfunction X = powerX(x,a,b)% powerX 对给定向量(x1, x2,..., xn)返回增幂矩阵(x1^a, x2^a,..., xn^a; x1^a+1, x2^a+1,..., xn^a+1; ...; x1^b, x2^b,..., xn^b;)%% Synopsis: X = powerX(x,a,b)%% Input: x = 需要返回增幂矩阵的向量% a,b = 寻根区间上下限%% Output: X = 增幂矩阵(x1^a, x2^a,..., xn^a; x1^a+1, x2^a+1,..., xn^a+1; ...; x1^b, x2^b,..., xn^b;)if round(a) ~= a | round(b) ~= berror('a,b must be integers');elseif a >= berror('a must be smaller than b!');endx = x(:)';row = b-a+1;col = length(x);X = zeros(row, col);for i = b:-1:aX(b-i+1,:) = x.^i;Endfunction [f, dfdx] = fun1_1(x)f = cos(x) - x;dfdx = -sin(x) - 1;function [f, dfdx] = fun1_2(x)f = exp(-x) - sin(x);dfdx = -exp(-x) - cos(x);function [f, dfdx] = fun2_1(x)f = x - exp(-x);dfdx = 1 + exp(-x);function [f, dfdx] = fun2_2(x)f = x.^2 - 2*x*exp(-x) + exp(-2*x);dfdx = 2*x - 2*exp(-x) + 2*x*exp(-x) - 2*exp(-2*x);function y = LegendreP6(x)p = LegendreIter(6);X = powerX(x,0,6);y = p*X;function y = ChebyshevT6(x)p = ChebyshevIter(6);X = powerX(x,0,6);y = p*X;function y = LaguerreL5(x)p = LaguerreIter(5);X = powerX(x,0,5);y = p*X;function y = HermiteH6(x)p = HermiteIter(6);X = powerX(x,0,6);y = p*X;思考题(1)由于Newton法具有局部收敛性,所以在实际问题中,当实际问题本身能提供接近于根的初始近似值时,就可保证迭代序列收敛,但当初值难以确定时,迭代序列就不一定收敛。

实验三牛顿迭代法和牛顿下山法(2学时)
牛顿迭代法和牛顿下山法是求解非线性方程的有效方法,要求熟练掌握牛顿迭代公式和牛顿下山法,并能够针对不同的非线性方程构造其迭代公式。
一、实验目的
1 .能熟练掌握牛顿迭代法和牛顿迭代法。
2 .掌握迭代的收敛性。
二、实验要求
1 .上机前作好充分准备,比较不用的方法解决相同问题的不同。
2 .编写Fortran程序,记录调试过程及结果。
3 .程序调试完后,在机器上检查运行结果。
4 .给出本实验的实验报告。
三、实验内容
1 .求解方程:f(x)=x3-x-1 的根。
2 .编写牛顿迭代法程序,取初值x0=1.3,迭代收敛的条件为前后迭代结果的差小于10—6。
3 .编写牛顿下山法程序,取初值0.6,迭代的收敛条件为前后迭代结果的差小于10—6。
4 .并用上述几种算法程序计算出上面方程的解。
四、实验步骤
•根据实验题目,给出解决问题的程序代码。
•上机输入和调试自己所编的程序。
•上机结束后,应整理出实验报告。
五、实验报告要求及记录、格式
按《数值计算方法》课程实验报告要求格式填写。

实验名称Java上机实验迭代循环法和位运算姓名:山水不言学号:xxxxxx一、实验内容1、编制程序,求出斐波拉契数列。
斐波拉契数列定义如下:Fibonacci(n)=n,(当n=0,1)Fibonacci(n)=fibonacci(n-1)+fibonacci(n-2),(当n>=2)分别用迭代循环法和递归法完成之。
实验思路:斐波那数列的第0项和第1项需要单独考虑,在迭代循环法中作为其他项的来源,在递归法中作为递归函数的出口。
实验源码:package fibonacci;import java.util.Scanner;public class fibonacci {public static void main(String[] args) {// TODO自动生成的方法存根int select=0,num=0;System.out.print("请输入数字");Scanner input=new Scanner(System.in);num=input.nextInt();System.out.print("迭代循环法输入1,递归法输入2/n");select=input.nextInt();if(select==1){fibon1(num);}else if(select==2){System.out.print("斐波拉契数列第"+num+"项为:"+fibon2(num));}}public static void fibon1(int num)//循环迭代{int []fibo=new int[num+1];if(num==0||num==1){System.out.print("斐波拉契数列第"+num+"项为:"+num);}else {fibo[0]=0;fibo[1]=1;int n=2;while(n<=num){fibo[n]=fibo[n-1]+fibo[n-2];n++;}System.out.print("斐波拉契数列第"+num+"项为:"+fibo[num]);}}public static int fibon2(int num)//递归{if(num==0||num==1)return num;elsereturn fibon2(num-1)+fibon2(num-2);}}2、用位运算将一个数扩大100倍实验思路:扩大100倍可以看做利用位运算取代乘法和加法。

泰克多次平均算法在数据处理和统计分析领域中,泰克多次平均算法是一种有效的方法,用于对一组数据进行平均处理。
它可以在去除异常值的同时,减小随机误差对结果的影响,提高数据的可靠性和准确性。
本文将对泰克多次平均算法进行详细介绍,并探讨其在数据处理中的应用。
一、泰克多次平均算法简介泰克多次平均算法,又称为TK算法,是一种通过多次迭代计算得到数据的平均值的方法。
其基本思想是在每次迭代中,去除数据中的一部分异常值,然后重新计算平均值,直至达到指定的迭代次数或满足收敛条件。
二、泰克多次平均算法的步骤1. 输入数据:首先,需要输入一组待处理的数据。
这些数据可以是实验测量数据、观测数据等。
2. 初次平均:对输入的数据进行首次平均处理,得到初始平均值。
3. 异常值检测:通过统计学方法或其他异常值检测算法,识别并去除数据中的异常值。
常用的方法包括标准差法、箱线图法等。
4. 剔除异常值:根据异常值检测的结果,将异常值从数据集中剔除。
5. 重新平均:对剔除异常值后的数据进行重新平均处理,得到新的平均值。
6. 判断收敛:判断新的平均值与之前的平均值之间的差异是否满足收敛条件。
如果满足条件,则停止迭代;如果不满足条件,则返回步骤3,继续进行异常值检测和剔除操作。
7. 输出结果:最终得到的平均值即为经过泰克多次平均算法处理后的结果。
三、泰克多次平均算法的应用场景1. 实验数据处理:在科学实验中,由于各种因素的干扰,得到的数据可能存在异常值。
使用泰克多次平均算法可以去除异常值,得到更可靠的实验结果。
2. 数据分析与挖掘:在大数据分析和挖掘中,泰克多次平均算法可以应用于异常值检测和数据清洗工作,提高数据的准确性和可信度。
3. 财务分析:在财务数据分析中,泰克多次平均算法可以用于去除财务报表中的异常值,提高财务数据的可靠性。
4. 生产过程控制:在工业生产过程中,通过对生产数据进行泰克多次平均算法处理,可以排除因设备故障等原因引起的异常值,提高生产过程的稳定性和可控性。

滑动平均法的基本原理滑动平均法的基本原理是通过对一段连续的数据进行平均运算,将每个数据点与其它一定范围内的数据点进行加权平均,从而得到平滑后的数值。
这个范围称为窗口(Window),也称为移动窗口(Moving Window),其大小通常由用户指定。
具体来说,滑动平均法的实现步骤如下:1.定义窗口大小:首先需要根据实际需求和数据特点,选择一个适当的窗口大小。
较小的窗口可以对数据更敏感,但同时也容易受到噪声和异常值的影响;较大的窗口可以平滑数据,但会导致更多的延迟和滞后。
2.计算窗口内数据的平均值:在滑动平均法中,窗口内的数据点被加权平均,得到当前的平均值。
常见的加权方式有简单平均、加权平均和指数平均。
简单平均是对窗口内的数据点直接进行平均运算。
加权平均是通过给不同的数据点分配不同的权重,再进行平均运算。
指数平均是给最近的数据点分配更高的权重,而较远的数据点分配较低的权重,以适应不同数据点的重要程度。
3.移动窗口:将窗口向前移动一个数据点,继续进行平均运算。
即将窗口内最早的数据点去除,加入最新的数据点。
这样就实现了数据的平滑处理。
通过滑动平均法,我们可以得到一系列平滑后的数据点,这些数据点在一定程度上去除了随机波动和异常值的影响,更能反映出数据的趋势和周期性。
滑动平均法广泛应用于金融领域、经济学、信号处理等。
例如,在金融交易中,滑动平均法可以用于识别价格趋势和判断买卖信号。
1.窗口大小的选择:窗口大小的选择需要根据实际需求和数据特点进行权衡。
较小的窗口可以更敏感地捕捉数据的变化,但也容易受到噪声和异常值的干扰;较大的窗口可以平滑数据,但会导致更多的延迟和滞后,难以快速捕捉数据的变化。
2.数据的平稳性:滑动平均法适用于平稳的时间序列数据。
如果数据存在趋势、周期性或者季节性等特点,滑动平均法可能无法准确捕捉到数据的变化。
3.异常值的处理:滑动平均法可以一定程度上平滑异常值,但也有可能将异常值模糊化成整体趋势。


滑动平均算法c语言什么是滑动平均算法滑动平均算法(Moving Average)是一种用于平滑时间序列数据的常用方法。
它通过计算一系列连续时间段内数据的均值,并将均值作为结果输出。
滑动平均算法对于去除噪音、平滑数据、降低波动等方面具有广泛的应用。
滑动平均算法的原理滑动平均算法的原理很简单,它通过维护一个固定大小的窗口(滑动窗口)来计算各个时间段内数据的均值。
在每个时间点,只需要更新窗口内的数据即可。
具体来说,滑动平均算法的计算过程如下:1.初始化一个长度为n的窗口,窗口内的初始数据为0。
2.每次输入一个新的数据,将其加入窗口,并将窗口最旧的数据移出窗口。
3.计算窗口内数据的均值,并将均值作为输出。
通过不断更新窗口内的数据,滑动平均算法可以平滑时间序列数据,使其更加稳定和可靠。
滑动平均算法的实现步骤滑动平均算法的实现步骤如下:1.定义一个长度为n的数组,用于存储窗口内的数据。
2.初始化数组中的元素为0。
3.定义变量sum,用于存储窗口内数据的和。
4.定义变量count,用于记录窗口内数据的个数。
5.定义变量index,用于记录当前窗口中最旧的数据的索引。
6.在每次输入新数据时,将新数据放入数组中的index位置,并更新sum和count值。
7.更新index的值,使其指向下一个最旧的数据。
8.如果count小于n,则count加1;否则,移除窗口中最旧的数据,并更新sum和count的值。
9.计算窗口内数据的均值,即sum除以count,并将均值作为输出。
滑动平均算法的C语言实现下面是使用C语言实现滑动平均算法的代码:#include <stdio.h>#define N 10float slidingAverage(float arr[], int n, float x) {static float window[N];static int count = 0;static float sum = 0;static int index = 0;// 更新窗口内数据的和sum = sum - window[index] + x;// 更新窗口内数据的个数count = (count < n) ? (count + 1) : n;// 更新窗口中最旧数据的索引index = (index + 1) % n;// 更新窗口内的数据window[index] = x;// 计算窗口内数据的均值return sum / count;}int main() {float data[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};int n = sizeof(data) / sizeof(data[0]);printf("滑动平均结果:\n");for (int i = 0; i < n; i++) {float average = slidingAverage(data, N, data[i]);printf("%.2f ", average);}printf("\n");return 0;}在上述代码中,我们使用了一个静态数组window用于存储窗口内的数据,使用count变量记录窗口内数据的个数,使用sum变量记录窗口内数据的和,使用index 变量记录窗口中最旧数据的索引。

Python滑动平均函数概述滑动平均(Moving Average)是一种常见的时间序列数据处理方法。
它通过计算一定时间窗口内的数据平均值来平滑数据,并能够减少数据中的噪声,使趋势更加明显。
在Python中,我们可以通过编写一个滑动平均函数来实现数据平滑处理。
本文将详细介绍如何编写一个滑动平均函数,以及如何使用它处理时间序列数据。
什么是滑动平均函数滑动平均函数是对时间序列数据进行平滑处理的一种方法。
它通过计算一定时间窗口内的数据平均值来平滑数据,并减少噪声的影响。
滑动平均函数的计算方法如下: 1. 选择一个固定大小的时间窗口,例如10个数据点。
2. 在初始窗口内,计算数据点的平均值作为第一个平滑值。
3. 将窗口向右滑动一个数据点,去掉最旧的数据点,加入最新的数据点。
4. 重复步骤3,计算新窗口内的数据平均值,作为新的平滑值。
通过不断滑动时间窗口并重新计算平均值,滑动平均函数可以平滑时间序列数据,并去除极端值和噪声,使数据更加平稳和可靠。
编写滑动平均函数的步骤根据滑动平均函数的定义,我们可以按照以下步骤编写一个滑动平均函数:步骤1:定义函数和输入参数首先,我们需要定义一个函数,用于计算滑动平均值。
函数的输入参数应该包括时间序列数据和时间窗口的大小。
def moving_average(data, window_size):# 在这里编写代码pass步骤2:处理边界条件在计算滑动平均值时,对于窗口内的数据点数量不足的情况,我们需要考虑边界条件。
当窗口内的数据点不足时,可以使用以下方法处理: - 对于初始时期的数据点,可以将窗口内的数据点数量不足的部分补零或者使用其他方法进行填充。
-对于结束时期的数据点,可以剔除较短的时间窗口,或者使用其他方法进行处理。
步骤3:计算滑动平均值在满足边界条件后,我们可以按照步骤3中描述的方法,计算滑动平均值。
def moving_average(data, window_size):moving_averages = []for i in range(len(data) - window_size + 1):window = data[i:i + window_size]average = sum(window) / window_sizemoving_averages.append(average)return moving_averages步骤4:测试函数编写完滑动平均函数后,我们可以编写一些测试用例来验证函数的正确性。

python滑动平均函数Python滑动平均函数滑动平均是一种常见的时间序列数据处理方法,可以用来平滑数据并去除噪声。
在Python中,我们可以使用NumPy和Pandas库来实现滑动平均。
1. NumPy实现滑动平均NumPy是一个用于科学计算的Python库,它提供了各种数学函数和数组操作功能。
我们可以使用NumPy中的convolve函数来实现滑动平均。
1.1 convolve函数介绍convolve函数是NumPy中的一个数组函数,用于计算两个一维数组之间的卷积。
语法:numpy.convolve(a, v, mode='full')参数说明:a:一维输入数组。
v:一维输入数组。
mode:可选参数,默认为'full'。
表示输出形状的模式。
有三个可选值:'full':输出结果的长度为len(a)+len(v)-1(默认)。
'same':输出结果的长度为max(len(a), len(v))。
'valid':输出结果的长度为max(len(a), len(v))-min(len(a), len(v))+1。
返回值:返回与a形状相同的一维数组,表示a和v之间的卷积结果。
1.2 实现滑动平均下面是使用NumPy实现滑动平均的代码:```pythonimport numpy as npdef moving_average(x, w):return np.convolve(x, np.ones(w), 'valid') / w```代码解释:moving_average函数接受两个参数:x和w。
x:一维输入数组。
w:窗口大小,即滑动窗口的长度。
np.ones(w)创建一个长度为w的全1数组,表示滑动窗口的权重。
np.convolve(x, np.ones(w), 'valid')计算x和全1数组之间的卷积,并返回与x形状相同的一维数组。
![滑动平均法讲解[资料]](https://uimg.taocdn.com/220ead3f657d27284b73f242336c1eb91a3733ca.webp)
1.1滑动平均法的基本原理动态测试数据y(t) 由确定性成分f(t) 和随机性成分x(t) 组成, 且前者为所需的测量结果或有效信号, 后者即随机起伏的测试误差或噪声, 即x(t)=e(t),经离散化采样后, 可相应地将动态测试数据写成e fyj jj+=j=1,2,…,N (1)为了更精确地表示测量结果, 抑制随机误差{e j }的影响, 常对动态测试数据{yj}作平滑和滤波处理。
具体地说, 就是对非平稳的数据{y j},在适当的小区间上视为接近平稳的, 而作某种局部平均, 以减小{e j }所造成的随机起伏。
这样沿全长N 个数据逐一小区间上进行不断的局部平均, 即可得出较平滑的测量结果{fj},而滤掉频繁起伏的随机误差。
例如, 对于N 个非平稳数据{yj} , 视之为每m 个相邻数据的小区间内是接近平稳的, 即其均值接近于常量。
于是可取每m 个相邻数据的平均值, 来表示该m 个数据中任一个的取值, 并视其为抑制了随机误差的测量结果或消除了噪声的信号。
通常多用该均值来表示其中点数据或端点数据的测量结果或信号。
例如取m 等于5,并用均值代替这5个点最中间的一个就有下式y3=1/5(y1+y2+y3+y4+y5)同理, y4=1/5(y2+y3+y4+y5+y6)即yf44=。
依此类推, 可得一般表达式为y fkk==∑-=+nnk y n 121k+1 k=n+1,n+2,…,N-n (2)式中,2n+1=m, 显然, 这样所得到的{yfkk=}, 其随机起伏因平均作用而比原来数据{yk}减小了, 即更加平滑了, 故称之为平滑数据。
由此也可得出对随机误差或噪声的估计, 即取其残差为fyekkk==k=n+1,n+2,…,N-n (3)上述动态测试数据的平滑与滤波方法就称为滑动平均。
通过滑动平均后,可滤掉数据中频繁随机起伏,显示出平滑的变化趋势,同时还可得出随机误差的变化过程,从而可以估计出其统计特征量。
滑动平均算法c语言滑动平均算法(Moving Average Algorithm)是一种常用的数据平滑处理方法,可以用于数据滤波,信号降噪等多种领域。
在本文中,我们将讲解滑动平均算法的原理、实现和应用。
一、滑动平均算法的原理滑动平均算法的原理很简单,就是通过取样窗口内的数据的平均值作为当前值,并将窗口平移一个采样周期。
这个过程类似于在数据流上滑动一个固定大小的窗口,每次窗口移动一个位置,计算窗口内数据的平均值。
假设我们有一组数据序列 x1,x2,x3,x4,x5,x6…xn。
我们希望得到平滑后的序列 y1,y2,y3,y4,y5…yn。
我们可以通过以下步骤完成滑动平均算法。
1.取样窗口的大小 n2.从起始点开始,将窗口内的数据 x1到 xn 求平均值 Y1,得到第一个平滑值 y1=Y13.将取样窗口向右平移一个位置,包含x2到xn+14.重新计算窗口内的平均值 Y2,得到第二个平滑值y2=Y25.重复以上步骤,直到窗口包含了所有的输入数据。
此时,y1,y2…yn 就是平滑后的序列。
滑动平均算法的实现非常简单,只需要在代码中定义一个缓存区或者数组,用来存储窗口内的数据,然后根据窗口大小 n,动态调整缓存区或者数组的大小,实时计算平均值。
以下是一个 C 语言实现滑动平均算法的例子:```cfloat moving_average(float new_data, float* data, int n){float sum = 0;int i;for (i = 0; i < n-1; i++) {data[i] = data[i+1];sum += data[i];}data[n-1] = new_data;sum += new_data;return sum / n;}```该函数使用了一个大小为 n 的缓存区 data 来存储窗口内的数据,每次新的数据new_data进来,都将原来最早读入的数据舍弃,并将新的数据添加到缓存区末尾,然后重新计算平均值并返回。
PROGRAM HDPJCHARACTER *(100) CMDFILE,INFILE,REGIONFILE,LOCALFILE,FILETYPEREAL EIGVALINTEGER ITERATIONWRITE(*,*)'INPUT CMDFILE-NAME: 'READ(*,*) CMDFILECALL READCMD(CMDFILE,FILETYPE,INFILE,REGIONFILE,LOCALFILE,MLINE, * NLINE,RADX,RADY,ITERATION,EPS,EIGVAL)IF((FILETYPE.EQ.'GRD').OR.(FILETYPE.EQ.'GRD'))THENCALL PROCESSGRD(INFILE,REGIONFILE,LOCALFILE,MLINE,NLINE,RADX, * RADY,ITERATION,EPS,EIGVAL)ELSE IF((FILETYPE.EQ.'BLN').OR.(FILETYPE.EQ.'BLN'))THENCALL PROCESSBLN(INFILE,REGIONFILE,LOCALFILE,MLINE,RADX, * ITERATION,EPS,EIGVAL)ELSE IF((FILETYPE.EQ.'XYZ').OR.(FILETYPE.EQ.'XYZ'))THENCALL PROCESSXYZ(INFILE,REGIONFILE,LOCALFILE,MLINE,RADX,* RADY,ITERATION,EPS,EIGVAL)ELSEWRITE(*,*)'无此类型'END IFEND PROGRAM!参数输入子程序SUBROUTINE READCMD(CMDFILE,FILETYPE,INFILE,REGIONFILE,LOCALFILE, * MLINE,NLINE,RADX,RADY,ITERATION,EPS,EIGVAL)CHARACTER *(*)CMDFILE,FILETYPE,INFILE,REGIONFILE,LOCALFILEOPEN(10,FILE=CMDFILE,STATUS='OLD',* ACCESS='SEQUENTIAL',FORM='FORMATTED')READ(10,*) FILETYPEREAD(10,*) INFILEREAD(10,*) REGIONFILEREAD(10,*) LOCALFILEREAD(10,*) RADX,RADYREAD(10,*) ITERATIONREAD(10,*) EPSREAD(10,*) EIGVALCLOSE(10)IF((FILETYPE.EQ.'GRD').OR.(FILETYPE.EQ.'GRD'))THENCALL MNGRD(INFILE,MLINE,NLINE)ELSE IF((FILETYPE.EQ.'BLN').OR.(FILETYPE.EQ.'BLN'))THENCALL MNBLN(INFILE,MLINE)ELSE IF((FILETYPE.EQ.'XYZ').OR.(FILETYPE.EQ.'XYZ'))THENCALL MNXYZ(INFILE,MLINE)ELSEEND IFEND SUBROUTINE!*******************************************GRD************************************************** !个数输入子程序SUBROUTINE MNGRD(INFILE,MLINE,NLINE)CHARACTER *(*)INFILEOPEN(10,FILE=INFILE,STATUS='OLD',ACCESS='SEQUENTIAL',* FORM='FORMATTED')READ(10,*)READ(10,*) MLINE,NLINECLOSE(10)END SUBROUTINE!GRD类型数据处理子程序SUBROUTINE PROCESSGRD(INFILE,REGIONFILE,LOCALFILE,MLINE,NLINE, * RADX,RADY,ITERATION,EPS,EIGVAL)CHARACTER *(*)INFILE,REGIONFILE,LOCALFILEREAL,ALLOCATABLE::FIRST(:,:),REGION(:,:),LOCAL(:,:),* REFIRST(:,:)ALLOCATE(FIRST(MLINE,NLINE),REGION(MLINE,NLINE),* LOCAL(MLINE,NLINE),REFIRST(MLINE,NLINE))CALL READGRD(INFILE,MLINE,NLINE,XMIN,XMAX,YMIN,* YMAX,FIRST)DX=(XMAX-XMIN)/(MLINE-1)DY=(YMAX-YMIN)/(NLINE-1)MR=INT(RADX/DX+0.5)NR=INT(RADY/DY+0.5)CALL ITERATION_GRD(MLINE,NLINE,MR,NR,ITERATION,EPS,EIGVAL,* FIRST,REFIRST,REGION,LOCAL)CALL WRITEGRD(REGIONFILE,MLINE,NLINE,XMIN,XMAX,* YMIN,YMAX,EIGVAL,REGION)CALL WRITEGRD(LOCALFILE,MLINE,NLINE,XMIN,XMAX,* YMIN,YMAX,EIGVAL,LOCAL)DEALLOCATE(FIRST,REGION,LOCAL,REFIRST)END SUBROUTINE!读入GRD文件SUBROUTINE READGRD(INFILE,MLINE,NLINE,XMIN,XMAX,YMIN,* YMAX,FIRST)CHARACTER *(*)INFILEREAL FIRST(MLINE,NLINE)OPEN(10,FILE=INFILE,STATUS='OLD',ACCESS='SEQUENTIAL',* FORM='FORMATTED')READ(10,*)READ(10,*)READ(10,*) XMIN,XMAXREAD(10,*) YMIN,YMAXREAD(10,*)READ(10,*) (((FIRST(I,J)),I=1,MLINE),J=1,NLINE)CLOSE(10)END SUBROUTINE!输出GRD文件SUBROUTINE WRITEGRD(OUTFILE,MLINE,NLINE,XMIN,XMAX,* YMIN,YMAX,EIGVAL,OUTGRD)CHARACTER *(*)OUTFILEREAL OUTGRD(MLINE,NLINE)ZMIN=HUGE(ZMIN)ZMAX=-HUGE(ZMAX)DO J=1,NLINE,1DO I=1,MLINE,1IF(OUTGRD(I,J).LT.0.5*EIGVAL)THENZMIN=MIN(ZMIN,OUTGRD(I,J))ZMAX=MAX(ZMAX,OUTGRD(I,J))END IFEND DOEND DOOPEN(11,FILE=OUTFILE,STATUS='UNKNOWN',* ACCESS='SEQUENTIAL',FORM='FORMATTED')WRITE(11,'(A)')'DSAA'WRITE(11,*) MLINE,NLINEWRITE(11,*) XMIN,XMAXWRITE(11,*) YMIN,YMAXWRITE(11,*) ZMIN,ZMAXDO J=1,NLINEWRITE(11,*) (OUTGRD(I,J),I=1,MLINE)END DOCLOSE(11)END SUBROUTINE!滑动平均法(GRD)SUBROUTINE ITERATION_GRD(MLINE,NLINE,MR,NR,ITERATION,EPS,EIGVAL, * FIRST,REFIRST,REGION,LOCAL)REAL FIRST(MLINE,NLINE),REGION(MLINE,NLINE),* LOCAL(MLINE,NLINE),REFIRST(MLINE,NLINE)EPSG=0.;ITE=1;REFIRST=FIRSTDO WHILE(EPSG>EPS.OR.ITE<=ITERATION)EPSG=0.ITE=ITE+1DO I=1,MLINE,1MRMIN=MAX(I-MR,1)MRMAX=MIN(I+MR,MLINE)DO J=1,NLINE,1IF(REFIRST(I,J)<0.5*EIGVAL) THENNRMIN=MAX(J-NR,1)NRMAX=MIN(J+NR,NLINE)SUM=0.NUM=0DO K=MRMIN,MRMAX,1DO L=NRMIN,NRMAX,1IF(REFIRST(K,L)<0.5*EIGVAL) THENSUM=SUM+REFIRST(K,L)NUM=NUM+1ENDIFENDDOENDDOREGION(I,J)=SUM/NUMEPSG=MAX(EPSG,ABS(REFIRST(I,J)-REGION(I,J)))ELSEREGION(I,J)=REFIRST(I,J)ENDIFENDDOENDDOREFIRST=REGIONENDDODO J=1,NLINE,1DO I=1,MLINE,1IF(FIRST(I,J)<0.5*EIGVAL) THENLOCAL(I,J)=FIRST(I,J)-REGION(I,J)ELSELOCAL(I,J)=FIRST(I,J)ENDIFENDDOENDDOENDSUBROUTINE!*******************************************BLN************************************************** !BLN个数输入程序SUBROUTINE MNBLN(INFILE,MLINE)CHARACTER *(*)INFILEOPEN(10,FILE=INFILE,STATUS='OLD',ACCESS='SEQUENTIAL',* FORM='FORMATTED')READ(10,*) MLINECLOSE(10)END SUBROUTINE!BLN文件处理子程序SUBROUTINE PROCESSBLN(INFILE,REGIONFILE,LOCALFILE,MLINE,RADX, * ITERATION,EPS,EIGVAL)CHARACTER *(*)INFILE,REGIONFILE,LOCALFILEREAL,ALLOCATABLE::FIRST(:),REGION(:),LOCAL(:),* REFIRST(:),X(:)ALLOCATE(FIRST(MLINE),REGION(MLINE),* LOCAL(MLINE),REFIRST(MLINE),X(MLINE))CALL READBLN(INFILE,MLINE,X,FIRST)CALL ORDER_BLN(X,FIRST,MLINE)CALL ITERATION_BLN(MLINE,RADX,ITERATION,EPS,EIGVAL,X,* FIRST,REFIRST,REGION,LOCAL)CALL WRITEBLN(INFILE,MLINE,X,FIRST)CALL WRITEBLN(REGIONFILE,MLINE,X,REGION)CALL WRITEBLN(LOCALFILE,MLINE,X,LOCAL)DEALLOCATE(X,FIRST,REGION,LOCAL,REFIRST)END SUBROUTINE!读取BLN文件SUBROUTINE READBLN(INFILE,MLINE,X,FIRST)CHARACTER *(*)INFILEREAL X(MLINE),FIRST(MLINE)OPEN(10,FILE=INFILE,STATUS='OLD',ACCESS='SEQUENTIAL',* FORM='FORMATTED')READ(10,*)READ(10,*) ((X(I),FIRST(I)),I=1,MLINE)CLOSE(10)END SUBROUTINE!对BLN文件排序SUBROUTINE ORDER_BLN(X,FIRST,MLINE)REAL X(MLINE),FIRST(MLINE)INTEGER FLAGFLAG=1DO WHILE(FLAG==1)FLAG=0DO I=1,MLINE-1,1IF(X(I+1)<X(I)) THENFLAG=1TEMP=X(I)X(I)=X(I+1)X(I+1)=TEMPTEMP=FIRST(I)FIRST(I)=FIRST(I+1)FIRST(I+1)=TEMPENDIFENDDOENDDOEND SUBROUTINE!滑动平均法(BLN)SUBROUTINE ITERATION_BLN(MLINE,RADX,ITERATION,EPS,EIGVAL,X, * FIRST,REFIRST,REGION,LOCAL)REAL X(MLINE),FIRST(MLINE),REGION(MLINE),* LOCAL(MLINE),REFIRST(MLINE)EPSG=0.;ITE=1;REFIRST=FIRSTDO WHILE(EPSG>EPS.OR.ITE<=ITERATION)EPSG=0.ITE=ITE+1DO I=1,MLINE,1IF(REFIRST(I)<0.5*EIGVAL)THENJ=I;SUM=0;NUM=0DO WHILE( (X(J)+RADX)>=X(I) .AND. J>=1)IF(REFIRST(J)<0.5*EIGVAL) THENSUM=SUM+REFIRST(J)NUM=NUM+1ENDIFJ=J-1ENDDOJ=I+1DO WHILE( (X(I)+RADX)>=X(J) .AND. J<=MLINE)IF(REFIRST(J)<0.5*EIGVAL) THENSUM=SUM+REFIRST(J)NUM=NUM+1ENDIFJ=J+1ENDDOREGION(I)=SUM/NUMEPSG=MAX(EPSG,ABS(REFIRST(I)-REGION(I)))ELSEREGION(I)=REFIRST(I)ENDIFENDDOREFIRST=REGIONENDDODO I=1,MLINE,1IF(FIRST(I)<0.5*EIGVAL) THENLOCAL(I)=FIRST(I)-REGION(I)ELSELOCAL(I)=FIRST(I)ENDIFENDDOENDSUBROUTINE!输出BLN文件SUBROUTINE WRITEBLN(OUTFILE,MLINE,X,OUTBLN)CHARACTER *(*)OUTFILEREAL OUTBLN(MLINE),X(MLINE)OPEN(11,FILE=OUTFILE,STATUS='UNKNOWN',* ACCESS='SEQUENTIAL',FORM='FORMATTED')WRITE(11,*) MLINEDO I=1,MLINE,1WRITE(11,*) X(I),OUTBLN(I)ENDDOCLOSE(11)END SUBROUTINE!*******************************************XYZ************************************************** !XYZ个数检测程序SUBROUTINE MNXYZ(FILENAME,NUMBER)CHARACTER*(*)FILENAMELOGICAL UNIT_OPEN,FILE_EXISTINTEGER NUNIT_INNUNIT_IN=11UNIT_OPEN=.TRUE.DO WHILE (UNIT_OPEN)NUNIT_IN=NUNIT_IN+1INQUIRE(UNIT=NUNIT_IN,OPENED=UNIT_OPEN)END DOINQUIRE(FILE=FILENAME,EXIST=FILE_EXIST)IF (FILE_EXIST) THENOPEN(UNIT= NUNIT_IN,FILE=FILENAME,STATUS='OLD')NUMBER=0DO WHILE (.NOT.EOF(NUNIT_IN))READ(NUNIT_IN,*,END=200,ERR=200)X,FNUMBER=NUMBER+1200 END DOCLOSE(UNIT=NUNIT_IN)ELSEWRITE(*,'(A,A,A)') '文件:',TRIM(FILENAME),' 不存在!'END IFEND SUBROUTINE!XYZ文件处理子程序SUBROUTINE PROCESSXYZ(INFILE,REGIONFILE,LOCALFILE,MLINE, * RADX,RADY,ITERATION,EPS,EIGVAL)CHARACTER *(*)INFILE,REGIONFILE,LOCALFILEREAL,ALLOCATABLE::FIRST(:),REGION(:),LOCAL(:),* REFIRST(:),XY(:,:)ALLOCATE(FIRST(MLINE),REGION(MLINE),* LOCAL(MLINE),REFIRST(MLINE),XY(2,MLINE))CALL READXYZ(INFILE,MLINE,XY,FIRST)CALL ORDER_XYZ(XY,FIRST,MLINE)CALL ITERATION_XYZ(MLINE,RADX,RADY,ITERATION,EPS,EIGVAL,XY, * FIRST,REFIRST,REGION,LOCAL)CALL WRITEXYZ(REGIONFILE,MLINE,XY,REGION)CALL WRITEXYZ(LOCALFILE,MLINE,XY,LOCAL)DEALLOCATE(XY,FIRST,REGION,LOCAL,REFIRST)END SUBROUTINE!读取XYZ文件SUBROUTINE READXYZ(INFILE,MLINE,XY,FIRST)CHARACTER *(*)INFILEREAL FIRST(MLINE),XY(2,MLINE)OPEN(10,FILE=INFILE,STATUS='OLD',ACCESS='SEQUENTIAL',* FORM='FORMATTED')DO I=1,MLINE,1READ(10,*) XY(1,I),XY(2,I),FIRST(I)ENDDOCLOSE(10)ENDSUBROUTINE!对XYZ文件排序SUBROUTINE ORDER_XYZ(XY,FIRST,MLINE)REAL XY(2,MLINE),FIRST(MLINE)INTEGER FLAGFLAG=1DO WHILE(FLAG==1)FLAG=0DO I=1,MLINE-1,1IF(XY(1,I+1)<XY(1,I)) THENFLAG=1TEMP=XY(1,I)XY(1,I)=XY(1,I+1)XY(1,I+1)=TEMPTEMP=XY(2,I)XY(2,I)=XY(2,I+1)XY(2,I+1)=TEMPTEMP=FIRST(I)FIRST(I)=FIRST(I+1)FIRST(I+1)=TEMPELSEIF(XY(1,I+1)==XY(1,I) .AND. XY(2,I+1)<XY(2,I)) THENFLAG=1TEMP=XY(2,I)XY(2,I)=XY(2,I+1)XY(2,I+1)=TEMPTEMP=FIRST(I)FIRST(I)=FIRST(I+1)FIRST(I+1)=TEMPENDIFENDDOENDDOEND SUBROUTINE!滑动平均法(XYZ)SUBROUTINE ITERATION_XYZ(MLINE,RADX,RADY,ITERATION,EPS,EIGVAL,XY, * FIRST,REFIRST,REGION,LOCAL)REAL XY(2,MLINE),FIRST(MLINE),REGION(MLINE),* LOCAL(MLINE),REFIRST(MLINE)EPSG=0.;ITE=1;REFIRST=FIRSTDO WHILE(EPSG>EPS.OR.ITE<=ITERATION)EPSG=0.ITE=ITE+1DO I=1,MLINE,1IF(REFIRST(I)<0.5*EIGVAL)THENJ=I;SUM=0;NUM=0DO WHILE( (XY(1,J)+RADX)>=XY(1,I) .AND. J>=1)IF(ABS(XY(2,J)-XY(2,I))<=RADY .AND.* REFIRST(J)<0.5*EIGVAL ) THENSUM=SUM+REFIRST(J)NUM=NUM+1ENDIFJ=J-1ENDDOJ=I+1DO WHILE( (XY(1,I)+RADX)>=XY(1,J) .AND. J<=MLINE)IF(ABS(XY(2,J)-XY(2,I))<=RADY .AND.* REFIRST(J)<0.5*EIGVAL) THENSUM=SUM+REFIRST(J)NUM=NUM+1ENDIFJ=J+1ENDDOREGION(I)=SUM/NUMEPSG=MAX(EPSG,ABS(REFIRST(I)-REGION(I)))ELSEREGION(I)=REFIRST(I)ENDIFENDDOREFIRST=REGIONENDDODO I=1,MLINE,1IF(FIRST(I)<0.5*EIGVAL) THENLOCAL(I)=FIRST(I)-REGION(I)ELSELOCAL(I)=FIRST(I)ENDIFENDDOENDSUBROUTINE!输出XYZ文件SUBROUTINE WRITEXYZ(OUTFILE,MLINE,XY,OUTZ)CHARACTER *(*)OUTFILEREAL OUTZ(MLINE),XY(2,MLINE)OPEN(11,FILE=OUTFILE,STATUS='UNKNOWN',* ACCESS='SEQUENTIAL',FORM='FORMATTED')DO I=1,MLINE,1WRITE(11,*) XY(1,I),XY(2,I),OUTZ(I)ENDDOCLOSE(11)END SUBROUTINE[文档可能无法思考全面,请浏览后下载,另外祝您生活愉快,工作顺利,万事如意!]。
java 实现cumulative moving average算法累积移动平均(Cumulative Moving Average,简称CMA)算法是一种在时间序列分析中常用的技术,它可以用于平滑数据、检测异常值等。
下面是一个使用Java实现CMA算法的简单示例:javapublic class CumulativeMovingAverage {private double[] window;private int windowSize;private int currentIndex = 0;private double sum = 0;public CumulativeMovingAverage(int windowSize) {this.windowSize = windowSize;window = new double[windowSize];}public void add(double value) {window[currentIndex] = value;sum += value;currentIndex++;if (currentIndex >= windowSize) {sum -= window[0];currentIndex = 0;}}public double getAverage() {if (windowSize == 0) {return 0; // 防止除以零的错误}return sum / windowSize;}}使用这个类的方式如下:javapublic class Main {public static void main(String[] args) {CumulativeMovingAverage cma = new CumulativeMovingAverage(3);// 创建长度为3的CMA对象cma.add(1.0); // 添加第一个值cma.add(2.0); // 添加第二个值System.out.println("Average: " + cma.getAverage()); // 输出平均值,应为(1+2)/2 = 1.5cma.add(3.0); // 添加第三个值System.out.println("Average: " + cma.getAverage()); // 输出平均值,应为(2+3)/2 = 2.5,因为原来的第一个值已经移出了窗口}}以上代码是一个基本的CMA实现,只处理了添加值和获取平均值的功能。
迭代法实验报告迭代法实验报告引言:迭代法是一种常见的数值计算方法,通过反复迭代逼近解的过程,来解决一些复杂的数学问题。
本实验旨在通过实际操作,深入理解迭代法的原理和应用,并通过实验数据验证其有效性。
一、实验目的本实验的主要目的有以下几点:1. 掌握迭代法的基本原理和步骤;2. 熟悉迭代法在数值计算中的应用;3. 理解迭代法的收敛性和稳定性;4. 验证迭代法在实际问题中的有效性。
二、实验原理迭代法是一种通过不断逼近解的方法,其基本原理可概括为以下几步:1. 选择一个初始值作为迭代的起点;2. 根据问题的特点和要求,构造一个递推公式;3. 通过不断迭代计算,逐步逼近解;4. 判断迭代过程是否收敛,并确定最终的解。
三、实验步骤1. 选择合适的初始值。
初始值的选择对迭代的结果有重要影响,通常需要根据问题的特点进行合理选取。
2. 构造递推公式。
根据问题的数学模型,建立递推公式,将问题转化为迭代求解的形式。
3. 进行迭代计算。
根据递推公式,进行迭代计算,直到满足收敛条件或达到预定的迭代次数。
4. 判断迭代结果。
根据实际问题的要求,判断迭代结果是否满足精度要求,并进行相应的调整和优化。
四、实验结果与分析通过实验操作,我们得到了一组迭代计算的结果。
根据实验数据,我们可以进行以下分析:1. 收敛性分析。
通过观察迭代过程中的数值变化,我们可以判断迭代法的收敛性。
如果数值逐渐趋于稳定,且与理论解的误差在可接受范围内,说明迭代法收敛。
2. 稳定性分析。
迭代法的稳定性是指在初始值变化时,迭代结果是否保持稳定。
通过改变初始值,我们可以观察迭代结果的变化情况,从而评估迭代法的稳定性。
3. 精度分析。
迭代法的精度取决于迭代过程中的误差累积情况。
通过与理论解的比较,我们可以评估迭代法的精度,并对迭代过程进行优化。
五、实验结论通过本次实验,我们深入了解了迭代法的原理和应用,通过实际操作验证了迭代法在数值计算中的有效性。
实验结果表明,迭代法在解决复杂数学问题中具有较高的准确性和稳定性,能够满足实际应用的需求。
滑动平均滤波c语言_常用滤波算法及c语言程序实现滑动平均滤波是一种常用的信号处理算法,用于平滑噪声信号,降低信号的噪声干扰。
C语言是一种广泛应用于嵌入式系统和信号处理领域的编程语言。
本文将以中括号为主题,详细介绍滑动平均滤波算法以及如何使用C语言来实现该算法。
第一部分:什么是滑动平均滤波算法?滑动平均滤波算法是一种基本的数字信号处理技术,用于平滑噪声信号。
该算法通过计算信号的移动平均值,将噪声信号的高频部分滤波掉,从而得到平滑的输出信号。
滑动平均滤波算法基于以下原理:将最近N个采样值的平均值作为当前的输出值,其中N是滑动窗口的大小。
随着新的采样值的输入,最早的采样值将被抛弃,而新的采样值将被加入到滑动窗口中。
滑动平均滤波算法主要有两种实现方式:简单滑动平均滤波和指数滑动平均滤波。
简单滑动平均滤波将滑动窗口中的所有采样值进行相加,然后除以窗口大小得到平均值。
指数滑动平均滤波则使用加权平均值,新的采样值会根据一定的权重比例与旧的滑动平均值相结合。
第二部分:C语言实现简单滑动平均滤波算法下面将介绍如何使用C语言来实现简单滑动平均滤波算法。
假设我们有一个长度为N的数组来存储输入信号的采样值,我们需要计算每个采样值的滑动平均值。
首先,我们需要定义一个指向输入信号数组的指针,并初始化滑动窗口的大小N。
c#define N 10 滑动窗口大小float input[N]; 输入信号数组float simpleMovingAverage(float *input, int windowSize){int i;float sum = 0;计算滑动窗口中所有采样值的和for (i = 0; i < windowSize; i++) {sum += input[i];}返回平均值return sum / windowSize;}在上述代码中,我们定义了一个简单滑动平均滤波函数`simpleMovingAverage()`,该函数接受输入信号数组和滑动窗口的大小作为参数,并返回滑动平均值。
实验三多次迭代滑动平均法程序设计姓名:专业:勘查技术与工程学号:指导教师:纪新林一. 基本原理:1.多次迭代法的计算公式:⎪⎪⎩⎪⎪⎨⎧⋅++==∑∑∑∑-=-=-=-=+Nr Nr l Mr Mr l Nr Nr l Mr Mr k P P l i k i G j i G j i G j i G 1),(),(),(),()()1()0( 式中:),1;,1)(,(n j m i j i G ⋅⋅⋅=⋅⋅⋅=为总场值; ),1;,1)(,()0(n j m i j i G ⋅⋅⋅=⋅⋅⋅=为迭代的初始值;P 为迭代次数,Nr 为窗口沿y 轴的半径,Mr 为窗口沿x 轴的半径。
2.多次迭代法可解决的问题:可以进行场的分离,得到深部区域场和剩余场,同时也可以消除随机异常。
二.输入输出数据格式设计:X 方向窗口半径:MradiusY 方向窗口半径:Nradius迭代次数:Interationmax输入总场文件名:Totalfilename 输出区域场文件名:Regfilename 输出剩余场文件名:Resfilename 总场值:G区域场值:GReg 剩余场值:GRes 点数:mpoint 线数:nline点坐标的最小值:Xmin 点坐标的最大值:Xmax 线坐标的最小值:Ymin 线坐标的最大值:Ymax三.总体设计I :输入有关参数:文件名,迭代次数,窗口半径输入点线数,X ,Y 坐标的最大值和最小值 输入总场P :循环进行滑动平均计算 O :输出区域场和剩余场四.测试结果1.测试参数如下:(1)网格数据保存在Totalfilename.grd 中。
网格数据按grd 格式保存,有27条线、27个点,点(线)坐标从-26m~26m ,点线距为2m 。
(2) 迭代次数3,窗口半径为6m ,相关参数保存在CMD.txt 文件中:Totalfilename.grd Regfilename.grd Resfilename.grd 3 6 62.测试结果:得到区域场和剩余场的两个网格化文件:Regfilename.grd ,Resfilename.grd 用Surfer 8 分别绘制等值线图:分别得到总场等值线图,区域场等值线图,剩余场等值线图:-25-20-15-10-5510152025-25-20-15-10-55101520250.020.040.060.080.10.120.140.160.180.20.220.240.260.280.30.320.340.360.38总场等值线图-25-20-15-10-5510152025-25-20-15-10-55101520250.030.0350.040.0450.050.0550.060.0650.070.0750.080.0850.090.0950.1区域场等值线图-25-20-15-10-5510152025-25-20-15-10-5510152025-0.06-0.04-0.0200.020.040.060.080.10.120.140.160.180.20.220.240.260.28剩余场等值线五.结论及建议:多次迭代滑动平均法可以进行场的分离,将一个重力异常分离为深部的区域异常和剩余场,同时能够消除随机虚假异常。
实验三多次迭代滑动平均法程序设计姓名:专业:勘查技术与工程学号:指导教师:纪新林一. 基本原理:1.多次迭代法的计算公式:⎪⎪⎩⎪⎪⎨⎧⋅++==∑∑∑∑-=-=-=-=+Nr Nr l Mr Mr l Nr Nr l Mr Mr k P P l i k i G j i G j i G j i G 1),(),(),(),()()1()0( 式中:),1;,1)(,(n j m i j i G ⋅⋅⋅=⋅⋅⋅=为总场值; ),1;,1)(,()0(n j m i j i G ⋅⋅⋅=⋅⋅⋅=为迭代的初始值;P 为迭代次数,Nr 为窗口沿y 轴的半径,Mr 为窗口沿x 轴的半径。
2.多次迭代法可解决的问题:可以进行场的分离,得到深部区域场和剩余场,同时也可以消除随机异常。
二.输入输出数据格式设计:X 方向窗口半径:MradiusY 方向窗口半径:Nradius迭代次数:Interationmax输入总场文件名:Totalfilename 输出区域场文件名:Regfilename 输出剩余场文件名:Resfilename 总场值:G区域场值:GReg 剩余场值:GRes 点数:mpoint 线数:nline点坐标的最小值:Xmin 点坐标的最大值:Xmax 线坐标的最小值:Ymin 线坐标的最大值:Ymax三.总体设计I :输入有关参数:文件名,迭代次数,窗口半径输入点线数,X ,Y 坐标的最大值和最小值 输入总场P :循环进行滑动平均计算 O :输出区域场和剩余场四.测试结果1.测试参数如下:(1)网格数据保存在Totalfilename.grd 中。
网格数据按grd 格式保存,有27条线、27个点,点(线)坐标从-26m~26m ,点线距为2m 。
(2) 迭代次数3,窗口半径为6m ,相关参数保存在CMD.txt 文件中:Totalfilename.grd Regfilename.grd Resfilename.grd 3 6 62.测试结果:得到区域场和剩余场的两个网格化文件:Regfilename.grd ,Resfilename.grd 用Surfer 8 分别绘制等值线图:分别得到总场等值线图,区域场等值线图,剩余场等值线图:-25-20-15-10-5510152025-25-20-15-10-55101520250.020.040.060.080.10.120.140.160.180.20.220.240.260.280.30.320.340.360.38总场等值线图-25-20-15-10-5510152025-25-20-15-10-55101520250.030.0350.040.0450.050.0550.060.0650.070.0750.080.0850.090.0950.1区域场等值线图-25-20-15-10-5510152025-25-20-15-10-5510152025-0.06-0.04-0.0200.020.040.060.080.10.120.140.160.180.20.220.240.260.28剩余场等值线五.结论及建议:多次迭代滑动平均法可以进行场的分离,将一个重力异常分离为深部的区域异常和剩余场,同时能够消除随机虚假异常。
一般来说,窗口越大,滑动平均值反映的区域异常越深;迭代次数越多,得到的区域场越平滑,得到的剩余场越明显,反复迭代基本上可以消除随机异常和假异常,达到压制干扰的效果。
本次测试迭代了三次,由以上图可知,迭代得到的区域异常比总异常平滑了很多,而剩余场基本上与总场一致,有细微的差别。
总体来说得到了实验要求的效果,基本上反映了多次迭代滑动平均法进行场的分离的规律。
为了使结果更加明显,可以增加迭代次数。
附录:源程序代码!ccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccc !ccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccc ! 程序说明!! 程序功能:mulfi_iter_mean --- 重力异常数据的多次迭代滑动平均处理!! 输入参数: Mradius --- X方向窗口半径mpoint --- 点数! Nradius --- Y方向窗口半径nline --- 线数! Interationmax --- 迭代次数Xmin --- X测线最小值! Totalfilename --- 输入总场文件名Xmax --- X测线最大值! Regfilename --- 输出区域场文件名Ymin --- Y测线最小值! Resfilename --- 输出剩余场文件名Ymax --- Y测线最大值! G --- 总场值!! 所用文件:CMD.txt --- 输入相关参数! Totalfilename.grd --- 总场输入文件! Regfilename.grd --- 区域场输出文件! Resfilename.grd --- 剩余场输出文件!! 中间变量:number --- 中间整型变量GReg --- 区域场值! sum --- 中间实型变量GRes --- 剩余场值! Gmax --- 网格点处异常数据的最大值! Gmax --- 网格点处异常数据的最小值!! 输出参数:Regfilename.grd --- 区域场输出文件! Resfilename.grd --- 剩余场输出文件!! 所用子程序:input_CMD --- 输入相关文件名和数据! read_mpointnline --- 从输入文件中读入点线个数! 和X,Y测线最大值最小值! inputGRD --- 输入总场值到数组G! mulfi_iter_mea --- 滑动平均法! mean_sub --- 迭代过程! outputGRD --- 输出网格化文件!!! 作者:韩自强!ccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccc !ccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccccc!滑动平均法的主程序~~~PROGRAM mulfi_iter_meanCHARACTER*80 Totalfilename,Regfilename,ResfilenameINTEGER mrradius,nradiusINTEGER interationmaxINTEGER mpoint,nlineREAL xmin,xmax,ymin,ymaxREAL,ALLOCATABLE:: G(:,:),GReg(:,:),GRes(:,:)CALL input_CMD(Totalfilename,Regfilename,Resfilename,* interationmax,mradius,nradius)CALL read_mpointnline(Totalfilename,mpoint,nline,* xmin,xmax,ymin,ymax)ALLOCATE(G(1:mpoint,1:nline),GReg(1:mpoint,1:nline),* GRes(1:mpoint,1:nline))CALL inputGRD(Totalfilename,mpoint,nline,G)CALL mulfi_iter_mea(mpoint,nline,G,mradius,nradius,* interationmax,GReg,GRes)CALL outputGRD(Regfilename,mpoint,nline,GReg,xmin,xmax,ymin,ymax) CALL outputGRD(Resfilename,mpoint,nline,GRes,xmin,xmax,ymin,ymax) DEALLOCATE(G,GReg,GRes)END PROGRAM mulfi_iter_mean!输入相关文件名和数据~~~SUBROUTINE input_CMD(Totalfilename,Regfilename,Resfilename,* interationmax,mradius,nradius)CHARACTER*80 Totalfilename,Regfilename,ResfilenameINTEGER interationmax,mrradius,nradiusOPEN(20,file='CMD.txt')READ(20,*) TotalfilenameREAD(20,*) RegfilenameREAD(20,*) ResfilenameREAD(20,*) interationmaxREAD(20,*) mradiusREAD(20,*) nradiusclose(20)END SUBROUTINE input_CMD!从输入文件中读入点线个数和X,Y测线最大值最小值~~~SUBROUTINE read_mpointnline(Totalfilename,mpoint,nline, xmin,xmax, * ymin,ymax)CHARACTER*80 TotalfilenameINTEGER mpoint,nlineREAL xmin,xmax,ymin,ymaxOPEN(20,file=Totalfilename)READ(20,*)READ(20,*) mpoint,nlineREAD(20,*) xmin,xmaxREAD(20,*) ymin,ymaxCLOSE(20)END SUBROUTINE read_mpointnline!输入总场值到数组G~~~SUBROUTINE inputGRD(Totalfilename,mpoint,nline,G)CHARACTER*80 TotalfilenameINTEGER mpoint,nlineREAL G(1:mpoint,1:nline)OPEN(20,file=Totalfilename)READ(20,*)READ(20,*) mpoint,nlineREAD(20,*)READ(20,*)READ(20,*)READ(20,*) (((G(I,J)),I=1,mpoint),J=1,nline)CLOSE(20)END SUBROUTINE inputGRD!滑动平均法~~~SUBROUTINE mulfi_iter_mea(mpoint,nline,G,mradius,nradius,* interationmax,GReg,GRes)INTEGER mrradius,nradiusINTEGER interationmaxINTEGER mpoint,nlineREAL G(1:mpoint,1:nline),GReg(1:mpoint,1:nline),* GRes(1:mpoint,1:nline)GRes=GDO K=1,interationmaxCALL mean_sub(mpoint,nline,mradius,nradius,GReg,GRes)GRes=GRegEND DOGRes=G-GRegEND SUBROUTINE mulfi_iter_mea!迭代过程~~~SUBROUTINE mean_sub(mpoint,nline,mradius,nradius,GReg,GRes) INTEGER mpoint,nlineREAL GReg(1:mpoint,1:nline),GRes(1:mpoint,1:nline)DO J=1,nlineDO I=1,mpointsum=0.0number=0DO K=MAX(1,I-mradius),MIN(mpoint,I+mradius)DO L=MAX(1,J-nradius),MIN(nline,J+nradius)number=number+1sum=sum+GRes(K,L)END DOEND DOGReg(I,J)=sum/numberEND DOEND DOEND SUBROUTINE mean_sub!输出网格化文件~~~SUBROUTINE outputGRD(Regfilename,mpoint,nline,GReg,xmin,xmax, * ymin,ymax)CHARACTER*80 RegfilenameINTEGER mpoint,nlineREAL xmin,xmax,ymin,ymaxREAL GReg(1:mpoint,1:nline)Gmax=GReg(1,1)Gmin=GReg(1,1)DO I=1,mpointDO J=1,nlineIF(Gmax<=GReg(I,J)) THENGmax=GReg(I,J)END IFIF(Gmin>=GReg(I,J)) THENGmin=GReg(I,J)END IFEND DOEND DOOPEN(20,file=Regfilename)WRITE(20,'(A)') 'DSAA'WRITE(20,*) mpoint,nlineWRITE(20,*) xmin,xmaxWRITE(20,*) ymin,xmaxWRITE(20,*) Gmin,GmaxWRITE(20,*) (((GReg(I,J)),I=1,mpoint),J=1,nline)CLOSE(20)END SUBROUTINE outputGRD。