第六章讲义异方差的性质
- 格式:ppt
- 大小:398.50 KB
- 文档页数:48


[计量经济学讲义] 第六章:异方差§1 含义异方差是相对于同方差而言的。
同方差:在经典线性回归模型的重要假定之一是,以解释变量的选定值为条件的每一随机扰动项u i 的方差是一个等于σ2的常数,即:var(u i )=σ2=常数,i=1,2,…,n (6.1.1)异方差:是指随机扰动项u i 随着解释变量X i 的变化而变化,即:var(i u )=2i σ=2σf(X i ) (6.1.2)§2 来源有一些理由说明为什么随机扰动项的方差有变化,其中的一些有如下述:一、按照边错边改学习模型(error-learning models ),人们在学习的过程中,其行为误差随时间而减少。
在这种情况下,预料的2i σ会减少。
例如,随着打字联系小时数的增加,不仅平均打错个数而且打错个数的方差都有所下降。
二、随着收入的增长,人们有更多的备用收入,从而如何支配他们的收入有更大的选择范围。
因此,在做储蓄对收入的回归时,很可能发现,由于人们对其储蓄行为有更多的选择,2i σ与收入俱增。
三、随着数据采集技术的改进,2i σ可能减少。
四、异方差还会因为异常值的出现而产生。
一个超越正常值范围的观测值或称异常值是指和其它观测值相比相差很多(非常小或非常大)的观测值。
五、回归模型的设定不正确也会造成异方差。
例如,在一个商品的需求函数中,若没有把有关的互补商品和替代商品的价格包括进来(忽略变量偏差),则回归残差就可能出现异方差。
注:异方差在横截面数据中比时间序列数据更为常见。
§3 影响一、参数的OLS 估计仍然是线性无偏的,但不是最小方差的估计量 以下以双变量线性回归模型为例 1、线性性∑∑=22ˆi i i x y x β=∑∑+22iii x u x β (6.2.1) 2、无偏性E(2ˆβ)=E(∑∑+22i i i x u x β)=∑∑+22)(ii i x u E x β=2β (6.2.2) 3、方差Var(2ˆβ)=Var(∑∑+22ii i x u x β)=222)()(∑∑i i i x u Var x =2222)(∑∑i ii x x σ (6.2.3) 在同方差时,Var(2ˆβ)=∑22ix σ (6.2.4) 二、t 检验失效用于参数显著性检验的统计量)ˆ(ˆ)ˆ(i i i se t βββ= 在同方差的假定下才被证明是服从t 分布的。

异方差异方差的性质● 经典回归的一个重要假定之一是:u i 的条件方差为常数, 即:E (2i u )= 2σ● 异方差(heterscedasticity ):E (2iu )=2i σ, 不同的(heter )分散程度(scedasticity )● (图)消费和收入, 消费随收入的增加而增加,但变异也在增加● u i 变动的几个理由:- 按照边错边改学习模型(error-learning models ),人们在学习的过程中,其行为误差随时间而减少,如:打字出错的个数- 随着收入的增长,人们有更多的备用收入,从而如何支配他们的收入有更大的选择范围- 随着数据采集技术的改进,2iσ可能减少- 异方差性还会因为异常值的出现而产生。
包括一个异常值,尤其样本较小时,会在很大程度上改变回归分析的结果- 异方差性的另一来源来自CLRM 的假定9的破坏,即:回归模型的设定是不正确的。
● 异方差常见于横截面数据中,因为观测范围大小不一● 异方差的后果:仍然是无偏的,但不是最有效的了(1) 无偏性βββ=+==-- )](')'[(]')'[()ˆ(11U X X X X E Y X X X E E(2) 非有效性1121111)'(')'()'()'(')'(]'')'][(')'[()'ˆ)(ˆ(------Φ==--=--X X X X X X X X X UU E X X X Y X X X Y X X X E E σββββββ● 同方差性时,βˆ的协方差矩阵为: 12)'(-X X σ,会夸大或缩小真实的方差和协方差● 由此会导致β的相关检验和置信区间失效,进而引起预测失效● 以双变量模型为例:i i i u X Y ++=10ββ进行显著性检验时,构造的t 统计量)ˆ(ˆ11ββS t =)ˆ(1βS 变动,所以1ˆβ的置信区间也不稳定异方差性的侦察● 侦破异方差性并没有严明的法则,只有少数的经验规则● 因为除非我们知道对应于选定的X 值的整个Y 总体,否则2i σ是无从获知的●大多数的方法都基于对我们所能观测到的OLS残差i uˆ的分析,而不是对干扰u i的分析非正式的方法●问题的性质:-往往根据所考虑的性质就能判别是否会遇到异方差性-例如:围绕消费对收入的回归,残差的方差随收入的增加而增加●图解法:-可先在无异方差性的假定下做回归分析,然后对残差的平方2ˆi u作一事后检查,看看这些2ˆi u是否呈现任何系统性的样式-(图)-2ˆi u是对应于i Yˆ而描绘的,除此之外,还可将他们对解释变量之一描点-当我们考虑2个或多个X变量的模型时,可将2ˆi u 相对于模型中的任一个变量描点正式方法(1)帕克(park )检验● 提出2i σ是解释变量X i 的某个函数,他建议的函数形式为:iv i ie X βσσ22=或:i i i v X ++=ln ln ln 22βσσ● 由于2iσ通常是未知的,帕克建议用2ˆi u 作为替代变量并作如下回归:ii i i v v X u++=++=i 22lnX ln ln ˆln βαβσ **● 如果β表现为统计上显著的,就表明数据中有异方差性● 帕克检验分两阶段:一是做回归,而不考虑异方差性问题,从这一回归获得i uˆ,然后在第二阶段作如** 的回归戈德菲尔德-匡特检验 (Goldfeld-Quandt test )● 适用于异方差性方差2i σ同回归模型中的解释变量之一有正相关的情形● 步骤一:从最小X 值开始,按X 值的大小顺序将观测值排列步骤二:略去居中的C 个观测值,其中C 是预定的,并将其余的(n-c )个观测值分成两组,每组(n-c)/2个步骤三:分别对头(n-c )/2个观测值和末(n-c)/2 个观测值各拟合一个回归,并分别获得残差平方和RSS 1 和RSS 2步骤四:计算比值:dfRSS dfRSS //12=λ, 如果假定i uˆ是正态分布的,并且如果同方差性假定真实,则λ遵循分子和分母自由度各为(n-c-2k )/2 的F 分布● C 个观测值是为了突出或激化小方差组(即RSS 1)与大方差组(即RSS 2 )之间的差异● 通常当n=30 时,取c =4, 当n=60 时,取c=10为宜● 当模型中有多于1个X 变量时,在检验的步骤一中,就可按任一个X 的大小顺序将观测值排列● 例:消费支出 – 收入, 30 观测值,略去居中4 个观测值后,对开头的13个和末尾的13个观测值分别作OLS 回归:17.377RS S 6968.04094.3ˆ1=+=i i X Y 8.1536RS S 7941.00272.28ˆ2=+-=i iX Y得:07.411/17.37711/8.1536//12===df RSS df RSS λ怀特(white )的一般异方差性检验● Goldfeld-Quandt 检验要求按照被认为是引起异方差性的X 变量把观测值重新排序● White 检验并不要求排序,而且易于付诸实施● 步骤一: 对给定的数据回归(两个解释变量),并获得残差i uˆ步骤二:再做如下(辅助)回归:ii i i i i i i v X X a X a X a X a X a a u ++++++=326235224332212ˆ从这个(辅助)回归中求得R 2步骤三:在无异方差性的虚拟假设下,2nR 渐进的遵循自由度等于辅助回归元(不包括常数项)个数的2χ分布步骤四:如果2χ值超过临界值,结论就是有异方差性,如果不超过,就没有,即:065432=====a a a a a● 例: Y= 贸易税收(进口与出口税收)与政府总收入之比,X 2 =进出口总和与GNP 之比,X 3 =人均GNP , 假设Y 与X 2 正相关,Y 与X 3 成反比White test :1148.0R ))(ln T rade 0.0015(ln )(ln 0491.0)(ln 4081.0 ln 6918.0ln 5629.28417.5ˆ2i 222=+--++-=i i i i i i GNP GNP Trade GNP Trade u7068.4)1148.0(41.2==R n● 如果模型有多个回归元,回归元的平方(或更高次方)项以及它们的交叉项就会耗掉许多的自由度● 遇到统计量显著的情形,原因也许不一定是异方差性异方差的修正方法 – 加权最小二乘法(广义最小二乘法)● 以消费-收入为例,消费异方差,设计一种估计方案:对来自变异较大的总体的观测值作较小的加权,而对来自较小的总体的观测值作较大的加权● OLS 方法对每一观测之同样重视或同等加权● 广义最小二乘法(generalized least square-GLS )利用了异方差的信息,因而能产生BLUE估计量● 利用双变量模型:i i i i u X X Y ++=201ββ其中对每个i, X0i=1● 假定相异的方差2i σ已知,用σ通除上式得:)()()(201iiiiiiiiu X X Y σσβσβσ++=为了易于阐述,将它写为:i i i i u X X Y ******201++=ββ● 转换原始模型中,转换干扰项i u *的方差,现在有了同方差性1)(1)(1)()*()*var(2222i22=====iiiiii i u E u E u E u σσσσ● OLS应用到转换模型将产生BLUE估计量● GLS是对满足标准最小二乘假定的转换变量的OLS● 21*ˆ*ˆββ和的估计步骤是最小化: 220112)**ˆ**ˆ*(*ˆii i X X Y u ββ--=∑∑● *ˆ2β的GLS 估计量为: ∑∑∑∑∑∑∑--=222)())(())(())((*ˆi i i i i i i i i i i i i X w X w w Y w X w Y X w w β 其中2/1i i w σ=● OLS和GLS 的差别:OLS要求最小化:2212)ˆˆ(ˆii i X Y u ββ--=∑∑ GLS要求最小化:2212)ˆˆ(ˆii i i i X Y w u w ββ--=∑∑● GLS中最小化一个以2/1i i w σ=为权的加权残差平方和,而在OLS中最小化一个无权或等权的残差平方和● 这种形式的GLS 被称为加权最小二乘法(weighted least square – WLS )● 若i σ是已知的,异方差的问题似乎已经得到了解决,但大多数情况下,方差是未知的●加权最小二乘法至多只能用于未知方差容易被描述的那些情况●看一下课本中的例子。


(2)X-~e i2的散点图进行判断异方差性1、定义:如果出现即对于不同的样本点,随机误差项的方差不再是常数,而互不相同,则认为出现了异方差性。
同方差性:σi2 = 常数 ≠ f(Xi)异方差时:σi2 = f(Xi) 2、后果:参数估计量非有效OLS 估计量仍然具有无偏性,但不具有有效性 因为在有效性证明中利用了 E(μμ’)=σ2I而且,在大样本情况下,尽管参数估计量具有一致性,但仍然不具有渐近有效性。
变量的显著性检验失去意义变量的显著性检验中,构造了t 统计量如果出现了异方差性,估计的S 出现偏误则t 检验失去意义。
其他检验也是如此。
模型的预测失效一方面,由于上述后果,使得模型不具有良好的统计性质;另一方面在预测的置信区间中,同样包含参数方差的估计量。
所以,当模型出现异方差性时,参数OLS 估计值的变异程度增大,从而造成对Y 的预测误差变大,降低预测精度,预测功能失效。
3、检验:检验随机误差项的方差与解释变量观测值之间的相关性及其相关的“形式”。
图示法(1)用X-Y 的散点图进行判断,看是否存在明显的散点扩大、缩小或复杂型趋势(即不在一个固定的带型域中)看是否形成一斜率为零的直线 帕克(Park)检验与戈里瑟(Gleiser)检验偿试建立方程:i ji i X f e ε+=)(~2Var i i ()μσ=2i ji i X e εασ++=ln ln )~ln(22i e X X f jiji εασ2)(=)12,12(~)12(~)12(~2122------------=∑∑k c n k c n F k c n e k c n e F i i 选择关于变量X 的不同的函数形式,对方程进行估计并进行显著性检验,如果存在某一种函数形式,使得方程显著成立,则说明原模型存在异方差性。
如: 帕克检验常用的函数形式:若α在统计上是显著的,表明存在异方差性。
戈德菲尔德-奎恩特(Goldfeld-Quandt)检验①将n 对样本观察值(Xi,Yi)按观察值Xi 的大小排队②将序列中间的c=n/4个观察值除去,并将剩下的观察值划分为较小与较大的相同的两个子样本,每个子样样本容量均为(n-c)/2,即3n/8③对每个子样分别进行OLS 回归,并计算各自的残差平方和④在同方差性假定下,构造如下满足F 分布的统计量⑤给定显著性水平α,确定临界值F α(v1,v2),若F> F α(v1,v2), 则拒绝同方差性假设,表明存在异方差。





Econometrics第六章异方差(教材第九章)第六章异方差6.1 异方差的涵义6.2 异方差的后果6.3 异方差的诊断6.4 补救措施学习要点异方差及其产生的后果,诊断及消除其影响的措施6.1 异方差的涵义异方差(Heteroscedasticity )f 古典线性回归模型(CLRM )的对u i 的假定其中,称为同方差(Homoscedasticity )假定。
f 若,则称存在异方差(Heteroscedasticity )。
12233i i i iY B B X B X u =+++2()0()(,)0i i i j E u Var u Cov u u σ=⎧⎪=⎨⎪=⎩2()i Var u σ=22()i i Var u σσ=≠6.1 异方差的涵义异方差(Heteroscedasticity)f例,个人储蓄的方差随个人可支配收入增加而变大。
6.1 异方差的涵义异方差(Heteroscedasticity )f 异方差用符号表示为:(注意下标)表明u i 的方差随观察值的不同而变化。
f存在异方差问题的实际背景多存在于横截面数据(cross-sectional data)由于存在规模效应测量误差f 例如,使用横截面数据估计中国总量消费函数。
22()i iE u σ=()()2()i i i Var u E u E u =−=2i σ6.1 异方差的涵义异方差(Heteroscedasticity )f 例,523个工人的工资:123i i i iWage B B Edu B Exper u =+++6.1 异方差的涵义异方差(Heteroscedasticity )f 例,523个工人的工资:123i i i iWage B B Edu B Exper u =+++6.2 异方差的后果异方差的后果(证明从略)f OLS OLS6.3 异方差的诊断异方差的一些诊断工具f问题的性质:在横截面数据中常有异方差问题f帕克检验(Park test)f格莱泽检验(Glejser test)Heteroscedasticity Test)f异方差的其他检验方法6.3 异方差的诊断异方差的一些诊断工具f 残差的图形检验:用对一个或多个解释变量作图2i e6.3 异方差的诊断异方差的一些诊断工具f 残差的图形检验:多个解释变量时可用对作图2ieˆiY6.3 异方差的诊断异方差的一些诊断工具f 帕克检验(Park test ):做对一个或多个的回归f 例如,一元模型中f 实际估计中以代替,如何获得?f 检验零假设B 2=0,即不存在异方差。
异方差知识点总结异方差的存在可能会导致回归模型下列问题:1. 预测的不确定性增加:当异方差存在时,回归模型的预测区间可能会变得更宽,因为方差的不稳定性会使得预测更加不确定。
2. 参数估计的失真:在存在异方差的情况下,最小二乘法(OLS)回归的方法可能会导致参数估计的偏误。
3. 统计推断的失真:在存在异方差时,通常使用的标准误差可能被低估或高估,从而影响统计推断的结果。
因此,我们有必要了解异方差的特征、检验方法和处理方法。
本文将从以下几个方面对异方差进行总结。
一、异方差的特征和识别方法二、检验异方差的统计方法三、处理异方差的方法一、异方差的特征和识别方法1. 异方差的特征异方差的特征主要包括两个方面:方差的不稳定性和误差项的相关性。
首先是方差的不稳定性,即随着自变量的变化,因变量的方差也会跟着变化。
这种不稳定性可能出现在回归模型的残差中,表现为残差的离散程度随着自变量的变化而变化。
其次是误差项的相关性,即自变量与误差项之间存在相关性。
这种相关性可能是由于遗漏变量、测量误差或其他未知因素导致的,而这种相关性可能会影响到回归模型的假设前提,从而影响到参数的估计和统计推断的结果。
2. 异方差的识别方法在实际应用中,我们可以通过以下几种方法来识别是否存在异方差:(1)绘制残差图:同时绘制残差与预测值的散点图和残差与自变量的散点图,观察残差的离散程度是否与自变量相关。
(2)利用统计检验:利用统计学中的异方差检验方法,如BP检验、White检验等。
(3)利用经验判断:在经验分析中,我们也可以通过观察实际数据的特征,来判断是否存在异方差。
比如,如果数据中存在明显的带状结构或呈现出明显的异方差现象,那么可能存在异方差问题。
二、检验异方差的统计方法1. BP检验BP检验是一种常用的异方差检验方法,它的原假设是误差的方差是恒定的,备择假设是误差的方差是非恒定的。
BP检验的具体步骤为:(1)先对相关变量进行回归分析,得到残差eˆ2;(2)在残差的平方的基础上,增加自变量的平方和自变量与自变量的乘积,得到新的残差变量;(3)利用新的残差变量进行正态性检验,判断残差是否服从正态分布;(4)最后,利用新的残差变量进行F检验,检验自变量的平方及其交叉项是否显著。
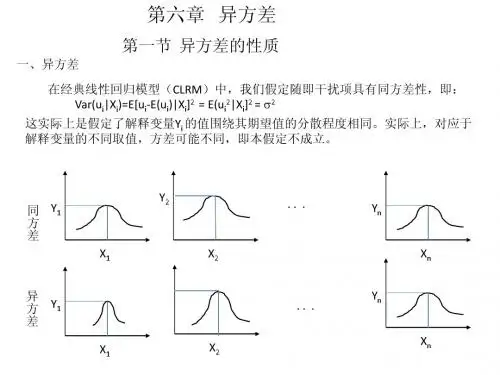
异方差§1 异方差的含义一、异方差的定义设模型为01122i i i k ki i Y X X X u ββββ=+++++如果扰动项的方差随着ji X 的变动而变动,即2()i i Var u σ=则称随机扰动项i u 存在异方差。
二、异方差的两种常见模式⒈方差随着某个解释变量的增加而增加⒉方差随着某个解释变量的增加而下降§2 异方差的产生原因和后果一、异方差的产生原因(一)设定偏误——解释变量的缺失,函数形式不正确 例:真实模型:01122i i i i Y X X u βββ=+++错误模型:011i i i Y X v ββ=++则 22i i i v X u β=+()i Var v 会随着2i X 的变化而变化(二)样本数据的观测误差随着时间的推移 () () i i Var u Var u ⎧↑⎪⎨↓⎪⎩观测误差累积观测技术提高 三、异方差的影响(以一元线性回归为例)(一)参数估计量仍然是线性无偏的(二)参数估计量不再具有最小方差性(OLS 低估真实方差)(三)解释变量显著性检验失效11111ˆˆ ()()ˆt t ˆ ()Var Se t Se ββββ⇒⇒⇒=⇒⇒低估真实方差被低估被低估检验显著性检验被高估被夸大失效 §3 异方差的判断一、直观判断――残差的图形检验222X X X i i i e e e ⎧⎪⎨⎪⎩用对作图与之间存在有规律的变化---异方差与之间不存在有规律的变化--同方差二、残差分段对比――Goldfeld-Quant 检验更正:22222211(1)2[(1),(1)]22(1)2ii i i e k e n c n c F F k k e e n c k -+--==-+-+--+∑∑∑∑三、用残差绝对值或残差平方为因变量作辅助回归(一)Glejser 检验用残差绝对值对解释变量或解释变量的函数回归(二)White 检验用残差平方对解释变量的函数回归(三)ARCH 检验用残差平方对其滞后值回归2112222ˆˆˆˆˆ()()t t t p t p e e e e n p R p ααααχ---=++++-§3 异方差的修正2WLS 2.WLS i i i i e e X e X e w e e ⎧→→⎪⎪⎪⎨⎪→→⎪⎪⎩→⎫⎧→⎨⎬→⎩⎭∑i i i i i 一、异方差的修正(一)加权最小二乘法(,weighted least squares)1.OLS 法的缺陷对每个赋予相同的重要性提供的较小时应加大信息量信息量小提供的较大时应减小信息量信息量大的思路较大的权重较小的使最小化较大的较小的权重i WLS WLS (二)估计量及其性质二、为未知时的变换三、模型的对数变换。