关于无损分解和保持依赖的判断
- 格式:doc
- 大小:27.00 KB
- 文档页数:3
![[总结]关系数据库设计基础(函数依赖、无损连接性、保持函数依赖、范式、……)](https://uimg.taocdn.com/af34390811a6f524ccbff121dd36a32d7375c7be.webp)
[总结]关系数据库设计基础(函数依赖、⽆损连接性、保持函数依赖、范式、……)≏≎≟≗≖≍≭∼∽≁≃≂≅≊≈≉≇≳⪞⪆⋧⪊≵≲⪝⪅⋦⪉≴⊂ subset ⋐⊄⊊ ⊈⊃⊇ ⋑⊅⊋ ⊉≺⪯≼⋞≾⪷⋨⪵⪹⊀≻⪰≽⋟≿⪸⋩⪶⪺⊁ in ∋∉∌∝≬⊸函数依赖(Function Dependency)定义设关系模式R(U),属性集合U= {A1,A2,…,An},X,Y为属性集合U的⼦集,如果对于关系模式R(U)的任⼀可能的关系r,r中的任意两个元组u、v,若有 u[X]=v[X],就有u[Y]=v[Y],则称X函数决定Y,或称Y函数依赖于X。
⽤符号X→Y表⽰。
其中X为决定因素,Y为被决定因素。
若对于R(U)的任意⼀个可能的关系r,r中不可能存在两个元组在X上的属性值性等,⽽在Y上的属性值不等。
(1) 函数依赖是语义范畴的概念,只能根据语义来确定⼀个函数依赖关系。
(2) 函数依赖X→Y的定义要求关系模式R的任何可能的关系r中的元组都满⾜函数依赖条件。
术语 (1)若X→Y,则X称作决定因素(Determinant) (2)若X→Y,Y→X,称作X<->Y。
(3)若Y不函数依赖于X,称作X -/-> Y。
(4)X→Y,若Y不包含X,即X ⊄ Y,则称X→Y为⾮平凡的函数依赖。
正常讨论的都是⾮平凡的函数依赖。
(5)X→Y,若Y包含X,即X ⊂ Y,则称X→Y为平凡的函数依赖。
(6)完全函数依赖(full functional dependency):在R(U)中,设X、Y是关系模式R(U)中不同的属性⼦集(即X ⊂ U,Y ⊂ U), 若存在 X→Y,且不存在 X的任何真⼦集X'(即 X' ⊊ X),使得 X'→Y,则称Y完全函数依赖 ( full functional dependency ) 于X。
记作 X-F->Y。
(7)部分函数依赖:在关系模式R(U)中,X、Y是关系模式R(U)中不同的属性⼦集(即X ⊂ U,Y ⊂ U), 若X→Y成⽴,如果X中存在任何真⼦集X'(即 X' ⊊ X),⽽且有X'→Y也成⽴,则称Y对X是部分函数依赖,记作:X-P->Y。

关系模式分解的无损连接和保持函数依赖一、引言关系模式是关系数据库中的核心元素之一,它描述了数据的结构和关系。
在设计关系数据库时,我们常常需要对关系模式进行分解,以满足数据库的需求。
本文将讨论关系模式分解的无损连接和保持函数依赖的相关概念和方法。
二、关系模式分解关系模式分解是将一个关系模式拆分成多个较小的关系模式的过程。
在分解关系模式时,我们需要考虑两个重要的性质:无损连接和保持函数依赖。
2.1 无损连接无损连接是指在关系模式分解后,通过对分解后的关系进行连接操作能够恢复原始关系模式。
换句话说,无损连接要求分解后的关系能够完整地保留原始关系中的所有信息。
2.2 保持函数依赖保持函数依赖是指在关系模式分解后,分解后的关系中依然能够保持原始关系中的函数依赖关系。
函数依赖是指一个属性或者属性集合的值决定了另一个属性或者属性集合的值。
三、关系模式分解的方法关系模式分解有多种方法,下面介绍三种常用的方法:自然连接、垂直分解和水平分解。
3.1 自然连接自然连接是指通过公共属性将两个或多个关系模式进行连接,得到一个具有完整信息的新关系模式。
自然连接的特点是能够保持原始关系中的所有信息和函数依赖。
3.2 垂直分解垂直分解是指根据属性集合的划分,将一个关系模式分解成多个关系模式。
垂直分解的优点是能够消除冗余数据,提高查询效率。
但是需要注意的是,垂直分解可能会造成关系丢失或信息损失。
3.3 水平分解水平分解是指将一个关系模式的元组进行水平划分,得到多个关系模式。
水平分解的特点是能够提高并发性能和容错性。
但是需要注意的是,水平分解可能会造成查询的复杂性增加和数据的分布不均衡。
四、关系模式分解的应用关系模式分解在实际的数据库设计中有着广泛的应用。
下面介绍两个例子以说明关系模式分解的应用。
4.1 学生课程关系考虑一个学生选课系统,其中包含学生和课程两个关系模式。
学生关系模式包括学生ID、姓名和年龄等属性,课程关系模式包括课程ID、课程名称和教师名称等属性。

关系模式无损及保持函数依赖的判定在数据库的世界里,有一门课非常重要,听起来复杂,其实一旦了解了,就像喝水一样简单。
这门课就是关于关系模式无损及保持函数依赖的判定。
说实话,乍一听这名字,很多人都会觉得有点绕。
但是,咱们可以轻松搞定这事儿。
想象一下你家里的冰箱。
里面各种各样的食材,鱼、肉、蔬菜,真是五花八门。
每次打开冰箱门,看到那些东东,你就知道要做什么了。
可是,如果这些食材全乱七八糟地放在一起,那可就糟了,找个东西就得翻半天。
关系模式就有点像这个冰箱,食材(数据)得好好分门别类。
无损性在这里就相当于我们把冰箱整理得井井有条,随取随用,不会出错。
比如,牛肉和鸡肉放在一起,那你一不小心把牛肉用错了,哎呀,可就麻烦了。
再说说保持函数依赖,这就像家里的规矩。
比如,家里规定:晚饭前不可以玩手机。
这样一来,大家都得遵守这个规矩,才能和谐相处。
在数据库中,函数依赖就是指某些数据项之间的关系。
如果有一个函数依赖存在,就意味着一个数据项的值决定了另一个数据项的值。
比如,学生的学号决定了他的姓名,学号就是那个“规矩”,保证大家都能遵循。
咱们可不能随便乱来,要保持这些依赖关系,才能让数据的完整性得到保障。
再回到关系模式无损的事情上。
无损分解就像咱们把冰箱里的食材分类,保证每种食材都能用得上。
比如,先把鱼和肉分开,再把鸡蛋和蔬菜放在一边,这样无论你想做什么,都能很方便地找到需要的食材。
如果分解得不好,可能一分开,整个菜都做不好了。
要是你把肉和蔬菜分开,但在某个地方漏掉了牛肉,那你就可能做不出你想要的红烧肉了。
无损性就像是保证了这个分解过程的有效性,确保你分开了,但是每样东西还在,没丢。
这里再给大家讲一个小故事。
前几天我去朋友家做客,看到他家冰箱简直乱得像个战场,啧啧,根本找不到东西。
后来他跟我说,最近工作太忙,没时间整理。
于是,我就给他提议,不如一起分类一下,把常用的东西放在最上面,少用的放在下面。
你猜怎么着?他真的开始整理了,整理完之后,连我都觉得轻松多了。
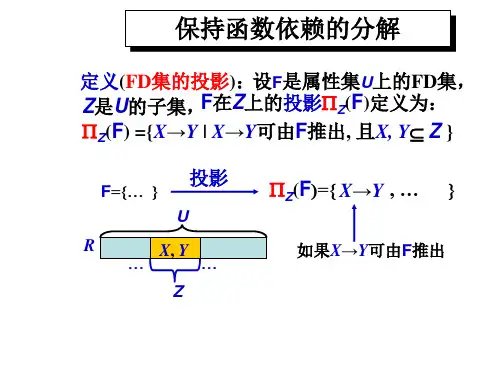





关于无损分解和保持依赖的判断,是系分和数工考试中每年基本上都会考的题,而且绝大部分是对一个关系模式分解成两个模式的考察,分解为三个以上模式时无损分解和保持依赖的判断比较复杂,考的可能性不大,因此我们只对“一个关系模式分解成两个模式”这种类型的题的相关判断做一个总结。
以下的论述都基于这样一个前提:R是具有函数依赖集F的关系模式,(R1 ,R2)是R的一个分解。
首先我们给出一个看似无关却非常重要的概念:属性集的闭包。
令α为一属性集。
我们称在函数依赖集F下由α函数确定的所有属性的集合为F下α的闭包,记为α+ 。
下面给出一个计算α+的算法,该算法的输入是函数依赖集F和属性集α,输出存储在变量result中。
算法一:result:=α;while(result发生变化)dofor each 函数依赖β→γ in F dobeginif β∈result then result:=result∪γ;end属性集闭包的计算有以下两个常用用途:·判断α是否为超码,通过计算α+(α在F下的闭包),看α+ 是否包含了R中的所有属性。
若是,则α为R的超码。
·通过检验是否β∈α+,来验证函数依赖是否成立。
也就是说,用属性闭包计算α+,看它是否包含β。
(请原谅我用∈符号来表示两个集合之间的包含关系,那个表示包含的符号我找不到,大家知道是什么意思就行了。
)看一个例子吧,2005年11月系分上午37题:● 给定关系R(A1,A2,A3,A4)上的函数依赖集F={A1→A2,A3→A2,A2→A3,A2→A4},R的候选关键字为________。
(37)A. A1 B. A1A3 C. A1A3A4 D. A1A2A3首先我们按照上面的算法计算A1+ 。
result=A1,由于A1→A2,A1∈result,所以result=result∪A2=A1A2由于A2→A3,A2∈result,所以result=result∪A3=A1A2A3由于A2→A4,A2∈result,所以result=result∪A3=A1A2A3A4由于A3→A2,A3∈result,所以result=result∪A2=A1A2A3A4通过计算我们看到,A1+ =result={A1A2A3A4},所以A1是R的超码,理所当然是R的候选关键字。

关系模式分解的无损连接和保持函数依赖一、关系模式分解的概念关系模式分解是指将一个复杂的关系模式分解为若干个简单的关系模式的过程。
在实际应用中,由于某些原因(如性能、数据冗余等),需要将一个大型的关系模式分解成多个小型的关系模式,从而提高数据库系统的效率和可维护性。
二、无损连接和保持函数依赖在进行关系模式分解时,有两种重要的约束条件:无损连接和保持函数依赖。
无损连接是指在进行关系模式分解后,仍然能够通过连接操作得到原始数据集合。
保持函数依赖是指在进行关系模式分解后,仍然能够维护原始数据集合中所有函数依赖。
三、无损连接和保持函数依赖的定义1. 无损连接假设R是一个关系模式,R1和R2是R的两个投影。
如果存在一个连接操作J(R1,R2),使得J(R1,R2)中包含了所有R中元组,则称R1和R2对于R具有无损连接。
2. 保持函数依赖假设R是一个关系模式,F是R上的一组函数依赖集合。
如果对于F中任何一个函数依赖X→Y,都存在一个关系模式R1和R2,使得R=R1⋈R2,且X和Y分别属于R1和R2的属性集合,则称关系模式分解后,仍然能够维护原始数据集合中所有函数依赖。
四、无损连接和保持函数依赖的算法在进行关系模式分解时,需要考虑如何保证无损连接和保持函数依赖。
以下是两种常用的算法。
1. 剖析算法剖析算法是一种自顶向下的分解方法。
该方法首先将原始关系模式拆分成两个投影,并检查它们是否具有无损连接。
如果没有,则再次拆分,并重复该过程直到满足无损连接为止。
剖析算法的优点是简单易懂,容易实现。
但是缺点也很明显,即可能会产生大量冗余数据。
2. 合成算法合成算法是一种自底向上的分解方法。
该方法首先将原始关系模式拆分为多个小型关系模式,并检查它们是否能够维护原始数据集合中所有函数依赖。
如果不能,则将两个小型关系模式合并,并重复该过程直到满足保持函数依赖为止。
合成算法的优点是能够保证数据的最小化,减少数据冗余。
但是缺点也很明显,即实现难度较大。

例1:设有关系模式R(A,B,C,D,E),其上的函数依赖集:F= {A→BC,CD→E,B→D,E→A}计算B+和CD+解B+ = BDCD+ = ABCDE例2:设有依赖集F={AB→C, C→A, BC→D,ACD→B,D→EG,BE→C,CG→BD,CE→AG} 计算最小等价依赖集。
解:(1). 右边属性单一化F1= {AB→C BE→CC→A CG→BBC→D CG→DACD→B CE→AD→E CE→GD→G }(2).去掉F1中的左部多余属性F2= {AB→C BE→CC→A CG→BBC→D CG→DCD→B CE→GD→ED→G }(3). 去掉F2中的多余的依赖F3= {AB→C BE→CC→A CG→DBC→D CE→GCD→BD→ED→G }或者F3= {AB→C BE→CC→A CG→BBC→D CE→GD→ED→G }侯选码求解理论和算法(两种情况)(F min)对于给定的关系R和函数依赖集F,可将其属性分为4类:L类:仅出现在F min的函数依赖左部的属性;R类:仅出现在F min的函数依赖右部的属性;N类:在F min中函数依赖的左右两边均未出现的属性;LR类:在F min中函数依赖的左右两边均出现过的属性;定理:对于给定的关系模式R及其函数依赖集F,若X是L和N类属性,则X 必为R的任一候选码的成员。
算法1:单属性依赖集图论求解法。
(1).求F的最小依赖集F min;(2).构造函数依赖图;(3).从图中找出关键属性集X(L、N类属性);(4).查看图中有无独立回路,若无,则输出X即为R的唯一候选码,转6;若有,则转5;(5).从各独立回路中各取一结点对应的属性与X组合成一候选码,并重复这一过程,取尽可能所有的组合,即为R的全部候选码。
(6).结束。
例3:设有R=(O, B, I, S, Q, D), F={S→D, D→S, I→B, B→I, B→O, O→B, I→O }, 求R的所有候选码。
求最小函数依赖集分三步:1.将F中的所有依赖右边化为单一元素此题fd={abd->e,ab->g,b->f,c->j,cj->i,g->h};已经满足2.去掉F中的所有依赖左边的冗余属性.作法是属性中去掉其中的一个,看看是否依然可以推导此题:abd->e,去掉a,则(bd)+不含e,故不能去掉,同理b,d都不是冗余属性ab->g,也没有cj->i,因为c+={c,j,i}其中包含i所以j是冗余的.cj->i将成为c->iF={abd->e,ab->g,b->f,c->j,c->i,g->h};3.去掉F中所有冗余依赖关系.做法为从F中去掉某关系,如去掉(X->Y),然后在F中求X+,如果Y在X+中,则表明x->是多余的.需要去掉.此题如果F去掉abd->e,F将等于{ab->g,b->f,c->j,c->i,g->h},而(abd)+={a,d,b,f,g,h},其中不包含e.所有不是多余的.同理(ab)+={a,b,f}也不包含g,故不是多余的.b+={b}不多余,c+={c,i}不多余c->i,g->h多不能去掉.所以所求最小函数依赖集为F={abd->e,ab->g,b->f,c->j,c->i,g->h};转换为3NF既具有无损连接性又保持函数依赖的分解算法:第一步:首先用算法1求出R的保持函数依赖的3NF分解,设为q={R1,R2,…,Rk}(这步完成后分解已经是保持函数依赖,但不一定具有保持无损连接)第二步:设X是R的码,求出p=q {R(X)}第三步:若X是q中某个Ri的子集,则在p中去掉R(X)第四步:得到的p就是最终结果例题:R(S#,SN,P,C,S,Z)F={S#→SN,S#→P,S#→C,S#→S,S#→Z,{P,C,S}→Z,Z→P,Z→C}∙第一步:求出最小FD集:F={S# →SN, S# →P,S# →C, S#→S, {P,C,S→Z, Z →P,Z →C} // S# →Z冗余,FD:最小函数依赖按具有相同左部分组:q={R1(S#,SN,P,C,S), R2(P,C,S,Z), R3(Z,P,C)}R3是R2的子集,所以去掉R3q={R1(S#,SN,P,C,S), R2(P,C,S,Z)}∙第二步:R的主码为S#,于是p=q {R(X)}={R1(S#,SN,P,C,S), R2(P,C,S,Z), R(S#)}∙第三步:因为{S#}是R1的子集,所以从p中去掉R(S#)∙第四步:p ={R1(S#,SN,P,C,S), R2(P,C,S,Z)}即最终结果判别一个分解的无损连接性举例2:已知R<U,F>,U={A,B,C,D,E},F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有无损连接性。
习题
(判定无损连接性和保持函数依赖)
1、设有关系模式R<U,F>,U={X,Y,Z,S,W},F={X→S,W→S,S→Y,YZ→S,SZ→XY},设R 分解成P={R1(WS),R2(YZS),R3(XZS)},判断该分解是否保持函数依赖,并判断此分解是否具有无损连接性。
解:求出F的最小函数依赖集F’={X→S,W→S,S→Y,YZ→S,ZS→X}
若R分解为={R1(WS),R2(YZS),R3(XZS)},
)+,则R<U,F>的分解р={R1,R2,R3}保持函数依赖。
因为: F’+ =( F
i
所以,该分解能保持函数依赖关系。
(5分)
所以,可以得到没有一行全为a,所以该分解为有损分解。
2.设有关系模式R(ABCDEG),其函数依赖集为:
F={E→D,C→B,CE→G,B→A}
判断R的一个分解ρ={R1(AB),R2(BC),R3(ED),R4(EAG)}是否无损连接和保持函数依赖。
证:
(1)判断无损连接
A1A2A3A4A5A6,该分解有损
(2)判断是否保持函数依赖(5分)
从F={E→D,C→B,CE→G,B→A}得到:
R1(AB),其F1={ B→A }
R2(BC),其F2={C→B}
R3(ED),其F3={E→D}
R4(EAG),其F4={EAG→EAG }
G=F1∪F2∪F3∪F4={ B→A ,C→B ,E→D ,EAG→EAG }
由于CEG+={CEBA},即CE→G不能由G根据Armstrong公理推导出来故F+!=(F1∪F2∪F3∪F4)+,故不保持函数依赖。
系统架构设计师-试题7(总分:62.00,做题时间:90分钟)一、{{B}}单项选择题{{/B}}(总题数:14,分数:62.00)设关系模式R(U,F),其中R上的属性集U={A,B,C,D,E},R上的函数依赖集F={A→B,DE→B,CB→E,E→A,B→D)。
______为关系R的候选关键字。
分解______是无损连接,并保持函数依赖的。
(分数:4.00)(1).∙ A.AB∙ B.DE∙ C.CE∙ D.CB(分数:1.00)A.B.C. √D.解析:(2).∙ A.p={R1(AC),R2(ED),R3(B)}∙ B.p={R1(AC),R2(E),R3(DB)}∙ C.p={R1(AC),R2(ED),R3(AB)}∙ D.p={R1,(ABC),R2(ED),R3(ACE)}(分数:1.00)A.B.C.D. √解析:候选关键字使用规范化理论中的图示法进行求解,对R关系模式画图如图所示。
[*]图中C结点为0度结点,所以它必然被包含在候选关键字中,但仅有C结点并不能遍历全图,所以需要加入其他中间结点。
若加入B结点,则BC→E,E→A,B→D,能遍历全图。
与此同时,加入A、E都能起到同样的效果。
所以关系R有三个候选键:BC、EC,AC。
接下来是判断模式分解过程中的无损连接与保持函数依赖的问题。
这个问题相对来说比较复杂。
如果逐个判断每个选项的无损连接与保持函数依赖,无疑工作量是很大的。
所以我们可以先观察这些选项有什么特点,通过观察发现A与B选项都存在单字段的分解。
在进行模式分解时,如果出现单字段,同时该字段未在其他分解的子关系模式中出现,并且函数依赖中有此字段的依赖关系,则说明此分解没有保持函数依赖。
原因很简单,关于该字段的那个函数依赖,必然在分解中丢失了。
所以A与B选项可以先排除。
然后判断C与D是否为无损连接。
对选项C构造初始的判定表如表所示。
模式分解C选项初始判定表分解的关系模式A B C D ER 1(AC) a1b12a3b14b15R 2(ED) b21b22b23a4a5R 3(AB) a1a2b33b34b35由于A→B,属性A的第1行和第3行相同,可以将第1行b12改为a2;又由于B→D,属性B的第1行和第3行相同,所以需要将属性D第1行b14和第3行b34,改为同一符号,即取行号值最小的b14。
3NF的⽆损连接和保持函数依赖的分解总结:先求最⼩覆盖,再求码,然后根据左部相同原则划分关系,将上述划分的再根据是否有包含关系进⾏合并,最后若关系中包含之前求的码,那么这个关系就是要求的分解,否则再加上⼀个关系,将码放⼊其中。
例⼀:设关系模式R(A,B,C,D,E)上的函数依赖集F是{A->BC,ABD->CE,E->D}1:计算F的最⼩覆盖。
⾸先将右部不唯⼀的依赖分解。
得到{A->B,A->C,ABD->C,ABD->E,E->D}然后对每⼀个依赖判断:对A->B,令G=F-{A->B},查看B是否属于A关于G的闭包。
即A是否能从G推导出B。
经推,不能。
所以,保留A->B。
同理 A->C 保留;ABD->C 删除(因为A->C);ABD->E 保留;E->D 保留第⼆步,对左部不唯⼀的依赖进⾏判断:对ABD->E,依次去掉A/B/D,查看(ABD-A/B/D)关于F的闭包是否包含E,是则⽤其取代原依赖。
经推,发现AD->E满⾜条件。
所以,综上所述。
F的最⼩覆盖为{A->B,A->C,AD->E,E->D}2:直接写出R的所有关键字。
易知,码为(A,D) (A,E)3:直接将R分解到3NF,且满⾜⽆损连接性和依赖保持性。
对F的最⼩覆盖进⾏处理:⾸先,按左部相同原则分组 A->B,A->C为R1({ABC},{A->B,A->C}) AD->E为R2({A,D},{AD->E}) E->D为R3({E,D},{E->D})然后,将具有包含关系的元组进⾏合并 R2包含R3,所以将R2,R3合并为新的R2({A,D,E},{AD->E,E->D})最后,判断分解后的关系模式中是否含有码,若含有则为⽆损连接且保持依赖的3NF否则,则是保持依赖但不是⽆损连接的3NF,此时需要新建⼀个关系模式,将码放⼊其中(若此题不含,则加R3({A,D},{∅}))。
关于无损分解和保持依赖的判断,是系分和数工考试中每年基本上都会考的题,而且绝大部分是对一个关系模式分解成两个模式的考察,分解为三个以上模式时无损分解和保持依赖的判断比较复杂,考的可能性不大,因此我们只对“一个关系模式分解成两个模式”这种类型的题的相关判断做一个总结。
以下的论述都基于这样一个前提:
R是具有函数依赖集F的关系模式,(R1 ,R2)是R的一个分解。
首先我们给出一个看似无关却非常重要的概念:属性集的闭包。
令α为一属性集。
我们称在函数依赖集F下由α函数确定的所有属性的集合为F下α的闭包,记为α+ 。
下面给出一个计算α+的算法,该算法的输入是函数依赖集F和属性集α,输出存储在变量result中。
算法一:
result:=α;
while(result发生变化)do
for each 函数依赖β→γ in F do
begin
if β∈result then result:=result∪γ;
end
属性集闭包的计算有以下两个常用用途:
·判断α是否为超码,通过计算α+(α在F下的闭包),看α+ 是否包含了R中的所有属性。
若是,则α为R的超码。
·通过检验是否β∈α+,来验证函数依赖是否成立。
也就是说,用属性闭包计算α+,看它是否包含β。
(请原谅我用∈符号来表示两个集合之间的包含关系,那个表示包含的符号我找不到,大家知道是什么意思就行了。
)
看一个例子吧,2005年11月系分上午37题:
● 给定关系R(A1,A2,A3,A4)上的函数依赖集F={A1→A2,A3→A2,A2→A3,A2→A4},R的候选关键字为________。
(37)A. A1 B. A1A3 C. A1A3A4 D. A1A2A3
首先我们按照上面的算法计算A1+ 。
result=A1,
由于A1→A2,A1∈result,所以result=result∪A2=A1A2
由于A2→A3,A2∈result,所以result=result∪A3=A1A2A3
由于A2→A4,A2∈result,所以result=result∪A3=A1A2A3A4
由于A3→A2,A3∈result,所以result=result∪A2=A1A2A3A4
通过计算我们看到,A1+ =result={A1A2A3A4},所以A1是R的超码,理所当然是R的候
选关键字。
此题选A 。
好了,有了前面的铺垫,我们进入正题。
无损分解的判断。
如果R1∩R2是R1或R2的超码,则R上的分解(R1,R2)是无损分解。
这是一个充分条件,当所有的约束都是函数依赖时它才是必要条件(例如多值依赖就是一种非函数依赖的约束),不过这已经足够了。
保持依赖的判断。
如果F上的每一个函数依赖都在其分解后的某一个关系上成立,则这个分解是保持依赖的(这是一个充分条件)。
如果上述判断失败,并不能断言分解不是保持依赖的,还要使用下面的通用方法来做进一步判断。
该方法的表述如下:
算法二:
对F上的每一个α→β使用下面的过程:
result:=α;
while(result发生变化)do
for each 分解后的Ri
t=(result∩Ri)+ ∩Ri //(result∩Ri)+表示result∩Ri的闭包
result=result∪t
这里的属性闭包是在函数依赖集F下计算出来的。
如果result中包含了β的所有属性,则函数依赖α→β。
分解是保持依赖的当且仅当上述过程中F的所有依赖都被保持。
下面给出一个例题,2006年5月系分上午43题:
●设关系模式R<U, F>,其中U={A, B, C, D, E},F={A→BC,C→D,BC→E,E→A},则分解ρ={R1(ABCE),R2(CD)}满足(43)。
(43)A.具有无损连接性、保持函数依赖
B.不具有无损连接性、保持函数依赖
C.具有无损连接性、不保持函数依赖
D.不具有无损连接性、不保持函数依赖
先做无损链接的判断。
R1∩R2={C},计算C+。
Result=C
由于C→D,C∈result,所以result=result∪D=CD
可见C是R2的超码,该分解是一个无损分解。
再做保持依赖的判断。
A→BC,BC→E,E→A都在R1上成立(也就是说每一个函数依赖左右两边的属性都在R1中),C→D在R2上成立,因此给分解是保持依赖的。
选A。
再看一个复杂点的例题。
2007年5月数工40-41题。
●给定关系模式R<U, F>,U={A, B, C, D, E},F={B→A,D→A,A→E,AC→B},其候选关键字为
(40),则分解ρ={R1(ABCE),R2(CD)}满足(41)。
(40)A.ABD
B.ABE
C.ACD
D.CD
(41)A.具有无损连接性、保持函数依赖
B.不具有无损连接性、保持函数依赖
C.具有无损连接性、不保持函数依赖
D.不具有无损连接性、不保持函数依赖
看见了吧,和前面一题多么的相像!
对于第一问,分别计算ABCD四个选项的闭包,
(ABD)+ = { ABDE }
(ABE)+ = { ABE }
(ACD)+ = { ABCDE }
(CD)+ = { ABCDE }
选D。
再看第二问。
先做无损链接的判断。
R1∩R2={C},计算C+。
result=C
因此C既不是R1也不是R2的超码,该分解不具有无损分解性。
再做保持依赖的判断。
B→A,A→E,AC→B在R1上成立,D→A在R1和R2上都不成立,因此需做进一步判断。
由于B→A,A→E,AC→B都是被保持的(因为它们的元素都在R1中),因此我们要判断的是D→A是不是也被保持。
对于D→A应用算法二:
result=D
对R1,result∩R1=ф(空集,找不到空集的符号,就用这个表示吧),t=ф,result=D
再对R2,result∩R2=D,D+ =ADE ,t=D+ ∩R2=D
一个循环后result未发生变化,因此最后result=D,并未包含A,所以D→A未被保持,该分解不是保持依赖的。
选D。