保持函数依赖的分解
- 格式:ppt
- 大小:212.00 KB
- 文档页数:12

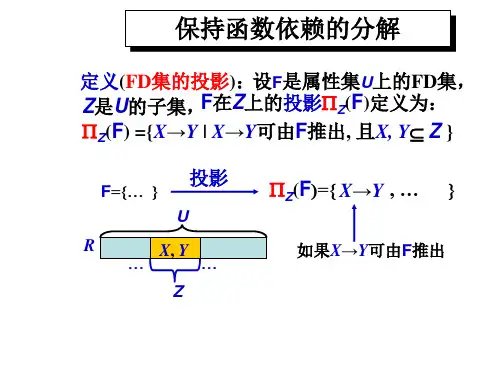
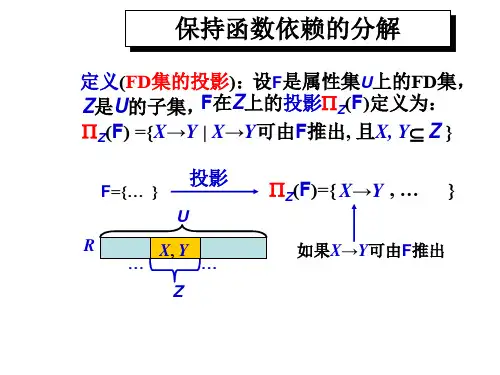
2.保持FD (函数依赖)的分解定义1:设F 是属性集U 上的FD 集,Z 是U 的子集,F 在Z 上的投影用πZ (F)表示,定义为πZ (F)={X →Y|X →Y ∈F +,且XY ⊆Z}定义2. 设},...{1K R R =ρ 是R 的一个分解,F 是R 上的FD 集,如果有)(1F R i ki π=Y ╞ F ,那么称分解ρ保持函数依赖集F 。
根据定义1,测试一个分解是否保持FD ,比较可行的方法是逐步验证F 中的每个FD 是否被)(1F R i ki π=Y 逻辑蕴涵。
如果F 的投影不蕴涵F ,而我们又用},...{1K R R =ρ表达R ,很可能会找到一个数据库实例σ 满足投影后的依赖,但不满足F 。
对σ的更新也有可能使r 违反FD 。
案例1:R (T#,TITLE ,SALARY )。
如果规定每个教师只有一个职称,并且每个职称只有 一个工资数目,那么R 上的FD 有T#→TITLE 和TITLE →SALARY 。
如果R 分解成ρ={R 1,R 2},其中R 1={T#,TITLE},R 2={T#,SALARY }。
则该分解具有无损连接性,但未保持函数依赖,丢失了依赖TITLE →SALARY 。
习题1:设关系模式R (ABC ),ρ={AB ,AC}是R 的一个分解。
试分析分别在F 1={A →B};F 2={A →C ,B →C},F 3={B →A},F 4={C→B,B→A}情况下, 是否具有无损分解和保持FD的分解特性。
算法1:分解成2NF模式集的算法设关系模式R(U),主码是W,R上还存在FD X→Z,并且Z是非主属性和X⊂W,那么W→Z就是非主属性对码的部分依赖。
此时,应把R分解成两个关系模式:R1(XZ),主码是X;R2(Y),其中Y=U-Z,主码仍为W,外码是X(参照R1)利用外码和主码的连接可以从R1和R2重新得到R。
如果R1和R2还不是2NF,则重复上述过程,一直到数据库模式中的每个关系模式都是2NF为止。

关系模式分解的无损连接和保持函数依赖一、引言关系模式是关系数据库中的核心元素之一,它描述了数据的结构和关系。
在设计关系数据库时,我们常常需要对关系模式进行分解,以满足数据库的需求。
本文将讨论关系模式分解的无损连接和保持函数依赖的相关概念和方法。
二、关系模式分解关系模式分解是将一个关系模式拆分成多个较小的关系模式的过程。
在分解关系模式时,我们需要考虑两个重要的性质:无损连接和保持函数依赖。
2.1 无损连接无损连接是指在关系模式分解后,通过对分解后的关系进行连接操作能够恢复原始关系模式。
换句话说,无损连接要求分解后的关系能够完整地保留原始关系中的所有信息。
2.2 保持函数依赖保持函数依赖是指在关系模式分解后,分解后的关系中依然能够保持原始关系中的函数依赖关系。
函数依赖是指一个属性或者属性集合的值决定了另一个属性或者属性集合的值。
三、关系模式分解的方法关系模式分解有多种方法,下面介绍三种常用的方法:自然连接、垂直分解和水平分解。
3.1 自然连接自然连接是指通过公共属性将两个或多个关系模式进行连接,得到一个具有完整信息的新关系模式。
自然连接的特点是能够保持原始关系中的所有信息和函数依赖。
3.2 垂直分解垂直分解是指根据属性集合的划分,将一个关系模式分解成多个关系模式。
垂直分解的优点是能够消除冗余数据,提高查询效率。
但是需要注意的是,垂直分解可能会造成关系丢失或信息损失。
3.3 水平分解水平分解是指将一个关系模式的元组进行水平划分,得到多个关系模式。
水平分解的特点是能够提高并发性能和容错性。
但是需要注意的是,水平分解可能会造成查询的复杂性增加和数据的分布不均衡。
四、关系模式分解的应用关系模式分解在实际的数据库设计中有着广泛的应用。
下面介绍两个例子以说明关系模式分解的应用。
4.1 学生课程关系考虑一个学生选课系统,其中包含学生和课程两个关系模式。
学生关系模式包括学生ID、姓名和年龄等属性,课程关系模式包括课程ID、课程名称和教师名称等属性。



关系模式分解的两种主要准则关系模式分解是数据库设计中非常重要的一个环节,它可以将一个复杂的关系模式分解成若干个更简单的关系模式,从而提高数据库的性能和可维护性。
在进行关系模式分解时,需要遵循一些准则,本文将介绍其中的两种主要准则。
一、函数依赖分解准则函数依赖是指一个或多个属性的值决定另一个属性的值。
在关系模式中,函数依赖是关系模式中数据之间的约束关系,也是关系模式分解的重要依据。
在进行函数依赖分解时,可以根据以下准则进行分解:1.不产生冗余数据:分解后的新关系模式不能产生冗余数据,即不能存在同一条数据在不同的关系模式中重复出现的情况。
2.保持原有的函数依赖关系:分解后的新关系模式应该能够与原有的函数依赖关系对应,保证数据的完整性和一致性。
3.尽可能保持关系模式的最小性:在函数依赖分解时,应该尽可能降低关系模式的冗余度,保持关系模式的最小性。
二、多值依赖分解准则多值依赖是指一个或多个属性的值决定另一组属性的值,这与函数依赖有所不同。
在进行多值依赖分解时,需要遵循以下准则:1.保持原有的多值依赖关系:分解后的新关系模式应该能够与原有的多值依赖关系对应,保证数据的完整性和一致性。
2.不产生冗余数据:分解后的新关系模式不能产生冗余数据,即不能出现同一条数据在不同的关系模式中重复出现的情况。
3.保留原有的关系模式属性:分解后的新关系模式应该保留原有的关系模式属性,且数据应该可以通过新关系模式及相应的联结操作还原到原有的关系模式中。
总结:以上是关系模式分解的两种主要准则,无论是进行函数依赖分解还是多值依赖分解,都需要遵循不产生冗余数据、保持原有的依赖关系以及保留原有属性的原则。
在分解过程中,不同的准则可能会产生冲突,此时需要根据实际情况进行权衡,选择最优的方案。
分解结果必须保证数据的完整性和一致性,还可以提高数据库的性能和可维护性。

关系模式分解的无损连接和保持函数依赖一、关系模式分解的概念关系模式分解是指将一个复杂的关系模式分解为若干个简单的关系模式的过程。
在实际应用中,由于某些原因(如性能、数据冗余等),需要将一个大型的关系模式分解成多个小型的关系模式,从而提高数据库系统的效率和可维护性。
二、无损连接和保持函数依赖在进行关系模式分解时,有两种重要的约束条件:无损连接和保持函数依赖。
无损连接是指在进行关系模式分解后,仍然能够通过连接操作得到原始数据集合。
保持函数依赖是指在进行关系模式分解后,仍然能够维护原始数据集合中所有函数依赖。
三、无损连接和保持函数依赖的定义1. 无损连接假设R是一个关系模式,R1和R2是R的两个投影。
如果存在一个连接操作J(R1,R2),使得J(R1,R2)中包含了所有R中元组,则称R1和R2对于R具有无损连接。
2. 保持函数依赖假设R是一个关系模式,F是R上的一组函数依赖集合。
如果对于F中任何一个函数依赖X→Y,都存在一个关系模式R1和R2,使得R=R1⋈R2,且X和Y分别属于R1和R2的属性集合,则称关系模式分解后,仍然能够维护原始数据集合中所有函数依赖。
四、无损连接和保持函数依赖的算法在进行关系模式分解时,需要考虑如何保证无损连接和保持函数依赖。
以下是两种常用的算法。
1. 剖析算法剖析算法是一种自顶向下的分解方法。
该方法首先将原始关系模式拆分成两个投影,并检查它们是否具有无损连接。
如果没有,则再次拆分,并重复该过程直到满足无损连接为止。
剖析算法的优点是简单易懂,容易实现。
但是缺点也很明显,即可能会产生大量冗余数据。
2. 合成算法合成算法是一种自底向上的分解方法。
该方法首先将原始关系模式拆分为多个小型关系模式,并检查它们是否能够维护原始数据集合中所有函数依赖。
如果不能,则将两个小型关系模式合并,并重复该过程直到满足保持函数依赖为止。
合成算法的优点是能够保证数据的最小化,减少数据冗余。
但是缺点也很明显,即实现难度较大。

求最小函数依赖集分三步:1.将F中的所有依赖右边化为单一元素此题fd={abd->e,ab->g,b->f,c->j,cj->i,g->h};已经满足2.去掉F中的所有依赖左边的冗余属性.作法是属性中去掉其中的一个,看看是否依然可以推导此题:abd->e,去掉a,则(bd)+不含e,故不能去掉,同理b,d都不是冗余属性ab->g,也没有cj->i,因为c+={c,j,i}其中包含i所以j是冗余的.cj->i将成为c->iF={abd->e,ab->g,b->f,c->j,c->i,g->h};3.去掉F中所有冗余依赖关系.做法为从F中去掉某关系,如去掉(X->Y),然后在F中求X+,如果Y在X+中,则表明x->是多余的.需要去掉.此题如果F去掉abd->e,F将等于{ab->g,b->f,c->j,c->i,g->h},而(abd)+={a,d,b,f,g,h},其中不包含e.所有不是多余的.同理(ab)+={a,b,f}也不包含g,故不是多余的.b+={b}不多余,c+={c,i}不多余c->i,g->h多不能去掉.所以所求最小函数依赖集为F={abd->e,ab->g,b->f,c->j,c->i,g->h};转换为3NF既具有无损连接性又保持函数依赖的分解算法:第一步:首先用算法1求出R的保持函数依赖的3NF分解,设为q={R1,R2,…,Rk}(这步完成后分解已经是保持函数依赖,但不一定具有保持无损连接)第二步:设X是R的码,求出p=q {R(X)}第三步:若X是q中某个Ri的子集,则在p中去掉R(X)第四步:得到的p就是最终结果例题:R(S#,SN,P,C,S,Z)F={S#→SN,S#→P,S#→C,S#→S,S#→Z,{P,C,S}→Z,Z→P,Z→C}∙第一步:求出最小FD集:F={S# →SN, S# →P,S# →C, S#→S, {P,C,S→Z, Z →P,Z →C} // S# →Z冗余,FD:最小函数依赖按具有相同左部分组:q={R1(S#,SN,P,C,S), R2(P,C,S,Z), R3(Z,P,C)}R3是R2的子集,所以去掉R3q={R1(S#,SN,P,C,S), R2(P,C,S,Z)}∙第二步:R的主码为S#,于是p=q {R(X)}={R1(S#,SN,P,C,S), R2(P,C,S,Z), R(S#)}∙第三步:因为{S#}是R1的子集,所以从p中去掉R(S#)∙第四步:p ={R1(S#,SN,P,C,S), R2(P,C,S,Z)}即最终结果判别一个分解的无损连接性举例2:已知R<U,F>,U={A,B,C,D,E},F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有无损连接性。

3NF既具有无损连接性又保持函数依赖的分解算法3NF (Third Normal Form) 是关系数据库设计的一个最常用的范式。
它是在满足2NF (Second Normal Form) 的基础上进一步消除了非关键字对主键的传递依赖。
在进行3NF分解算法时,我们需要遵循以下步骤:1.对关系模式进行分析,找出主键和所有函数依赖。
2.检查关系模式是否满足2NF。
如果关系模式满足2NF,转到步骤43.找出所有非关键字的传递依赖,并进行分解。
4.对所有非主属性进行冗余消除分解。
下面将详细描述3NF分解算法的具体步骤:1.对关系模式进行分析:对于给定的关系模式R,我们需要找出其主键和所有函数依赖。
主键是可以唯一标识关系中的每条记录的那个属性或属性组合。
函数依赖是属性间的关系,其中一个或一组属性的值确定另一个或一组属性的值。
2.检查关系模式是否满足2NF:2NF要求关系模式R的所有非主属性都完全函数依赖于主键,即不能存在部分依赖。
如果关系模式已经满足2NF的要求,则可以跳过步骤3,直接进行步骤43.分解传递依赖:针对存在传递依赖的关系模式,我们需要进行分解。
传递依赖是指当一个非关键字属性依赖于另一个非关键字属性时,在关系模式中存在传递依赖。
首先,我们需要找出所有的传递依赖关系。
通常,我们可以通过观察属性之间的函数依赖来找出传递依赖。
如果存在函数依赖X→Y和Y→Z,那么我们可以推断出X→Z为传递依赖。
其次,对于每个传递依赖关系X→Z,我们需要创建一个新的关系模式XZ,并将X和Z以及它们的函数依赖复制到新的模式中。
然后,我们需要从原来的关系模式R中删除属性Z,创建一个新的关系模式YZ,并将Y和Z的函数依赖复制到新的模式中。
最后,我们需检查新的关系模式是否满足2NF,并重复这个过程,直到所有的传递依赖都被消除。
4.冗余消除分解:在消除传递依赖之后,我们需要对所有非主属性进行冗余消除分解。
对于每个非主属性A,我们创建一个新的关系模式A,并将A以及它所决定的所有属性复制到新的模式中。

3NF的⽆损连接和保持函数依赖的分解总结:先求最⼩覆盖,再求码,然后根据左部相同原则划分关系,将上述划分的再根据是否有包含关系进⾏合并,最后若关系中包含之前求的码,那么这个关系就是要求的分解,否则再加上⼀个关系,将码放⼊其中。
例⼀:设关系模式R(A,B,C,D,E)上的函数依赖集F是{A->BC,ABD->CE,E->D}1:计算F的最⼩覆盖。
⾸先将右部不唯⼀的依赖分解。
得到{A->B,A->C,ABD->C,ABD->E,E->D}然后对每⼀个依赖判断:对A->B,令G=F-{A->B},查看B是否属于A关于G的闭包。
即A是否能从G推导出B。
经推,不能。
所以,保留A->B。
同理 A->C 保留;ABD->C 删除(因为A->C);ABD->E 保留;E->D 保留第⼆步,对左部不唯⼀的依赖进⾏判断:对ABD->E,依次去掉A/B/D,查看(ABD-A/B/D)关于F的闭包是否包含E,是则⽤其取代原依赖。
经推,发现AD->E满⾜条件。
所以,综上所述。
F的最⼩覆盖为{A->B,A->C,AD->E,E->D}2:直接写出R的所有关键字。
易知,码为(A,D) (A,E)3:直接将R分解到3NF,且满⾜⽆损连接性和依赖保持性。
对F的最⼩覆盖进⾏处理:⾸先,按左部相同原则分组 A->B,A->C为R1({ABC},{A->B,A->C}) AD->E为R2({A,D},{AD->E}) E->D为R3({E,D},{E->D})然后,将具有包含关系的元组进⾏合并 R2包含R3,所以将R2,R3合并为新的R2({A,D,E},{AD->E,E->D})最后,判断分解后的关系模式中是否含有码,若含有则为⽆损连接且保持依赖的3NF否则,则是保持依赖但不是⽆损连接的3NF,此时需要新建⼀个关系模式,将码放⼊其中(若此题不含,则加R3({A,D},{∅}))。
保持函数依赖的分解
保持函数依赖的分解是指在关系型数据库的规范化过程中,将一个关系(或表)分解为多个较小的关系,同时保持这些关系满足函数依赖。
这样做可以消除数据冗余,减少数据插入、更新和删除操作时的异常问题,提高数据的一致性和完整性。
保持函数依赖的分解通常遵循以下几个步骤:
1. 识别函数依赖:首先需要确定关系中的所有函数依赖。
函数依赖是指一个或多个属性的值可以决定另一个属性的值。
例如,在“学生”表中,如果“学号”和“课程号”可以决定“成绩”,那么“学号”和“课程号”就决定了“成绩”。
2. 确定范式:在确定了所有的函数依赖后,需要确定当前的范式级别。
范式是数据库设计的规范,用于消除数据冗余和提高数据一致性。
常见的范式有第一范式(1NF)、第二范式(2NF)、第三范式(3NF)等。
3. 规范化:如果当前关系不满足某个范式的要求,就需要将其分解为多个较小的关系,直到满足该范式的要求。
这个过程就是规范化。
例如,如果一个关系不满足第二范式的要求,就需要将其分解为两个关系,其中一个关系满足第二范式的要求,另一个关系满足第一范式的要求。
4. 检查函数依赖:在分解后,需要检查新的关系是否仍然满足所有
的函数依赖。
如果某个函数依赖在新的关系中不再成立,就需要重新设计该关系。
5. 实施分解:如果所有的函数依赖都得到满足,就可以将原来的关系替换为新的关系。
通过以上步骤,可以保持函数依赖的分解,并实现数据库的规范化设计。
这种设计有助于提高数据的一致性和完整性,减少数据冗余和异常问题。
数据库保持依赖且无损地分解成3NF算法数据库的设计是数据管理的重要步骤,一个良好设计的数据库可以提高数据的存储和检索的效率。
在数据库设计中,一个常见的目标是将关系数据库保持依赖且无损地分解至第三范式(Third Normal Form, 3NF),本文将介绍一种用于实现这一目标的算法。
在介绍算法之前,我们先了解一下数据库范式的概念。
关系数据库的范式是一套用于规范化数据库设计的规则。
3NF是最常用的范式之一,它要求一个关系模式中的所有非主属性都只能依赖于候选键,而不能依赖于其他非主属性。
现在,我们来介绍一种算法实现将数据库分解至3NF。
以下是算法的步骤:步骤一:识别候选键首先,我们需要识别出关系模式的候选键(Candidate Key)。
候选键是可以唯一标识关系模式中的每个元组的属性或属性集合。
在关系模式中,可能会存在多个候选键。
步骤二:识别函数依赖接下来,我们需要分析关系模式中的属性之间的函数依赖关系。
函数依赖是指一个或多个属性的值(非主属性)决定其他属性的值(主属性)。
通过识别函数依赖,我们可以确定模式中的非主属性和主属性。
步骤三:分解关系模式在识别出候选键和函数依赖之后,我们可以开始将关系模式分解成多个子模式。
分解的目的是消除冗余和数据重复,并满足3NF的要求。
首先,我们将函数依赖中的非主属性提取出来,作为子模式的主属性。
例如,如果一个函数依赖是A->B,其中A和B都是关系模式的属性,那么我们可以将B作为一个新的子模式的主属性。
其次,我们需要考虑不同子模式之间的关系。
如果多个子模式有相同的候选键,那么它们之间应该通过外键来建立关联。
外键将一个子模式的候选键作为另一个子模式的主属性,建立起它们之间的关系。
最后,我们需要检查子模式是否满足3NF的要求。
如果出现了非平凡的传递依赖(Transitive Dependency),则需要继续分解子模式,直到达到3NF。
步骤四:验证并进行优化在算法执行结束后,我们需要验证所得到的子模式是否满足3NF要求。