藏汉翻译系统实验
- 格式:doc
- 大小:37.00 KB
- 文档页数:2
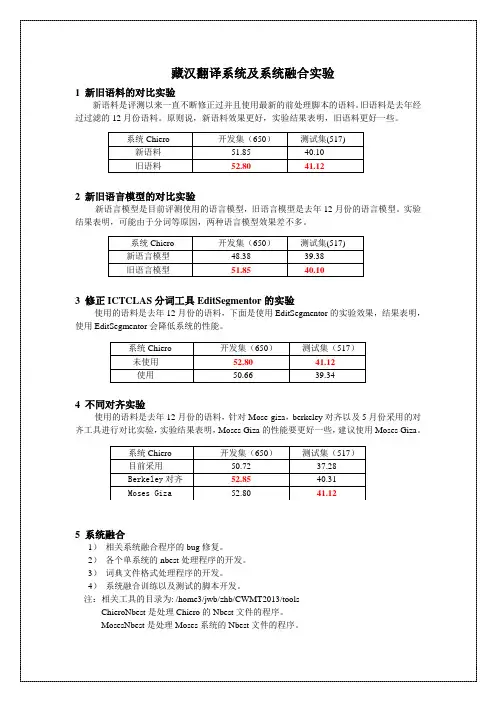
藏汉翻译系统及系统融合实验1 新旧语料的对比实验新语料是评测以来一直不断修正过并且使用最新的前处理脚本的语料。
旧语料是去年经过过滤的12月份语料。
原则说,新语料效果更好,实验结果表明,旧语料更好一些。
系统Chiero 开发集(650)测试集(517)新语料51.85 40.10旧语料52.80 41.122 新旧语言模型的对比实验新语言模型是目前评测使用的语言模型,旧语言模型是去年12月份的语言模型。
实验结果表明,可能由于分词等原因,两种语言模型效果差不多。
系统Chiero 开发集(650)测试集(517)新语言模型48.38 39.38旧语言模型51.85 40.103 修正ICTCLAS分词工具EditSegmentor的实验使用的语料是去年12月份的语料,下面是使用EditSegmentor的实验效果,结果表明,使用EditSegmentor会降低系统的性能。
系统Chiero 开发集(650)测试集(517)未使用52.80 41.12使用50.66 39.344 不同对齐实验使用的语料是去年12月份的语料,针对Mose-giza,berkeley对齐以及5月份采用的对齐工具进行对比实验,实验结果表明,Moses Giza的性能要更好一些,建议使用Moses Giza。
系统Chiero 开发集(650)测试集(517)目前采用50.72 37.28Berkeley对齐52.85 40.31Moses Giza 52.80 41.125 系统融合1)相关系统融合程序的bug修复。
2)各个单系统的nbest处理程序的开发。
3)词典文件格式处理程序的开发。
4)系统融合训练以及测试的脚本开发。
注:相关工具的目录为: /home3/jwb/zhb/CWMT2013/toolsChieroNbest是处理Chiero的Nbest文件的程序。
MosesNbest是处理Moses系统的Nbest文件的程序。

基于双语对齐句型库的藏汉机器翻译方法研究通过藏汉双语句子中词语序列异同点的比较,研究藏汉双语句型对齐方法,建立了一个小规模藏汉对齐句型库和对照词典库,在此基础上提出了基于藏汉双语对齐句型库的机器翻译算法。
标签:机器翻译藏语句型对照词典双语对齐句型库一、藏、汉句子中词语序列的对比分析藏汉两种语言在语法(包括词序、虚词的运用、动词的形态变化)上的区别,给藏汉双语对齐句型库的构建带来了一定的难度。
除了在句子的词序和词数上变化上有明显的区别外,在虚词的运用和动词的形态变化上也不同。
例如:5.汉语动词没有形态变化,而藏语动词具有形态变化在藏文文法中,对动词的形态变化、及物性及分类等方面的研究很丰富,是藏语动词的复杂性增强。
据统计,现代藏语动词1453个,其中,756个动词本身有形态变化,而汉语动词没有形态变化,这给藏汉对齐句型库的建设和规范化带来了汉语与藏语动词的比较。
例如:实例例6中的藏语动词以”/”分开的四个形态分别是动词的未来式、现在式、过去式、命令式。
在建立藏汉对齐字形库时,第1种对齐句型因词性、词序都相同,容易建立,但对第2、3、4、5、6种对齐句型的处理就变得相对复杂,将在后续内容中详细描述。
二、对照词典的设计与句型库的建设1.对照词典的设计与实现基于双语对齐句型库的藏汉机器翻译方法研究需要设计实现一个添加了详细词性标记的藏汉对照词典的设计与实现。
本文涉及的机器翻译方法,需要一个对照词典的支持,而这个对照词典不是一般意义上的简单对照词典,而是一个添加了词性标记的对照词典。
表3-1为其基本结构和功能:因页面大小,此处只列举了整个对照词典的一小部分内容,第一行中除”word”以外的其他英文标记表示词性,它们分别表示连词(cd)、及物动词现在式(vt)、动名词(nv)、及物动词过去式(vi)、随立名(nn)、指示代词(rz)、属格助词(gz)、使格助词(gx)、位格助词(gl),对照词典里的词性种类及数目远不止这些,总共有80余个词性。

藏汉翻译技巧研究报告研究报告:藏汉翻译技巧一、引言藏汉翻译是将藏语文本转化为汉语文本的过程,涉及到语言、文化和认知等多个领域的知识。
本报告旨在探讨一些常用的藏汉翻译技巧,以帮助翻译人员在处理藏语文本时提高翻译质量。
二、上下文理解上下文理解是一项重要的技巧,对于准确翻译藏语文本至关重要。
通过仔细阅读和分析上下文,翻译人员可以更好地理解作者的意图,并准确传达信息。
此外,了解不同领域的专业术语和上下文背景也是提高翻译的关键。
三、等效表达在藏汉翻译过程中,翻译人员需要寻找汉语的等效表达,以准确传达原文的含义。
有时候,直译可能无法完全表达原文的意思,因此翻译人员需要动态调整语言表达方式,以达到最合适的翻译效果。
四、文化转换藏汉翻译涉及到两种不同的文化背景,因此在翻译过程中,翻译人员需要充分考虑目标文化的习惯和传统。
充分理解目标文化的背景可以帮助翻译人员选择更合适的词汇和表达方式,使翻译结果更易于被目标读者理解和接受。
五、平衡准确性与流畅性翻译的目标是准确传达原文的意思,但同时也需要保持译文的流畅性和自然性。
在藏汉翻译中,翻译人员需要权衡准确性和流畅性,尽可能地找到一个平衡点。
译文不应只是死板地堆砌单词和短语,而应具备自然流畅的汉语表达。
六、词语选择词语选择是翻译的核心环节之一。
在进行藏汉翻译时,翻译人员需要仔细选择适当的词语,以准确传达原文的语义。
对于涉及特定领域的文本,翻译人员还需要了解相关的术语和表达方式,从而提高翻译的准确性。
七、参考文献和工具在进行藏汉翻译时,翻译人员可以借助各种参考文献和工具,以提高翻译效率和质量。
这些参考文献和工具可以提供词汇、短语、句型等方面的帮助,同时也可以为翻译人员提供文化背景和专业知识的支持。
八、结论本报告主要探讨了一些常用的藏汉翻译技巧,包括上下文理解、等效表达、文化转换、平衡准确性与流畅性、词语选择以及参考文献和工具的使用。
这些技巧可以帮助翻译人员提高翻译质量,准确传达原文的意思,并使译文更加符合目标文化读者的习惯和要求。


藏文翻译系统的研发与实现随着中国与藏区交流的不断增加,对藏文翻译系统的需求也越来越大。
然而,由于汉藏语系的不同,藏文语法的复杂性以及字母的独特性,要实现高质量的藏文翻译并不容易。
因此,本文将探讨一下目前藏文翻译系统的研发与实现。
一、藏文基础知识要了解藏文翻译系统的研发,我们需要首先了解一些藏文的基础知识。
藏文是一种借用了梵文的字母表,一个字母通常代表一个音节。
藏文中还有表示词性和语法关系的后缀,这使得藏文的语法非常复杂。
藏文中还有很多词汇是由词根和后缀组成的,因此藏文单词的长度通常比较长。
此外,不同的字母组合在一起代表不同的音节,这也增加了藏文翻译系统的难度。
二、藏文翻译系统的研发由于藏文的特殊性,目前的翻译系统很难满足人们的需要。
因此,一些专家和学者正在研发新的藏文翻译系统,以提升翻译的质量和准确性。
目前的藏文翻译系统主要分为两种,即基于规则的系统和统计机器翻译系统。
基于规则的系统依靠人工编写的规则来进行翻译,这种方法需要大量的人工投入,但是可以比较好地解决藏文翻译中的一些语法和语义问题。
统计机器翻译系统是另一种常见的翻译方法,它利用大量的双语语料库进行训练,然后通过概率模型来估计最适合的翻译结果。
这种方法比较适合解决一些翻译中的词汇和单词组合问题。
三、实现藏文翻译系统的挑战实现藏文翻译系统面临很多挑战,其中最大的挑战是藏文的语法和词汇系统。
藏文的语法比较复杂,有很多种类型的词缀和语法现象需要处理。
这就要求翻译系统需要对语法和词汇系统有很好的了解,才能进行正确和合理的翻译。
此外,藏文单词的长度比较长,这也是困扰藏文翻译系统开发者的一大难题。
翻译系统需要能够分离一个长单词的词根和后缀,同时还要识别不同的字母组合代表的不同音节,才能进行正确的翻译。
四、未来的发展方向虽然藏文翻译系统还存在许多问题和挑战,但是我们相信在不久的将来,随着技术的不断进步和现有翻译系统的不断完善,藏文翻译质量会不断提高,为汉藏交流提供更好的帮助。

班智达汉藏公文翻译系统中基于二分法的句法分析方法研究才藏太 李延福(青海师范大学藏文智能信息处理中心 中国 青海 西宁 810008)caizangt@摘要机器翻译系统是一种典型的自然语言处理系统,语言技术是机器翻译系统中居于核心地位的技术,实用化的机器翻译系统一般是采用自然限制的受限语言的翻译,且以基于规则的方法为主流方法。
本文结合863项目《班智达汉藏公文机器翻译系统》的研制实践,论述了词项信息同语法规则相结合的原则,提出了以动词为中心的句法分析二分法,从而在受限语言的范围内,为建立有较大适应性的机器翻译规则系统,有效地提高机器翻译语法分析的效率提供了有益的方法。
关键词:机器翻译二分法语句结构句法分析1、引言随着计算机技术的不断普及,如何将大量的汉语和外语的科技信息、教材、参考读物、科普读物等及时地翻译成藏语,进而为广大藏区科技、教育、文化事业服务已成为制约广大藏区社会经济发展的关键问题。
在汉藏科技翻译人员极端缺乏的今日,班智达汉藏机器翻译系统的研制和推广应用必将有助于促进这一问题的尽快解决。
在机器翻译系统中,语言技术是居于核心地位的技术,因而讨论机器翻译系统的句法分析问题便是一个重要的问题。
机器翻译的方法有多种,但基于规则和词典的方法仍然是到目前为止的一直采用的主流方法。
我们研制的863项目班智达汉藏公文机器翻译系统是采用基于规则的翻译系统。
机器翻译进行的是两个语言无限集之间的转换,在现有的科学水平之下,计算机科学还不能从理论上证明,用一个有限的机器翻译规则系统来进行原语和译语的无限集之间的转换的可能性,因此实践上比较可行的办法是采用自然限制的受限语言。
我们研制的班智达汉藏公文机器翻译系统就是一种受限语言的机器翻译系统。
2、系统结构班智达汉藏机器翻译系统由科技系统、公文系统和电子词典三部分组成,采用C++语言在Windows环境下实现。
考虑到实际应用中用户的需要,系统设有译前和译后编辑功能。


藏汉翻译中遇到的问题和措施探究摘要:语言是人与人之间进行沟通交流的重要桥梁,而所处不同地域,其地域语言同样存在明显差异,语言文化是联系各族各区人际关系的基础。
在当前交流密切的藏汉民族之间,随着愈发频繁的商业贸易交流,藏汉文化之间的沟通交流随之紧密。
因此,藏汉翻译工作对于两族文化的交流尤为重要,解决当前藏汉翻译上的问题至关重要。
关键词:语言文化;藏汉文化;藏汉翻译一、藏汉翻译的原则语言翻译是一种基于语文应用,并且由技术性和创造性两者相结合的脑力劳动,也是一种关于社会文化交流的活动。
翻译的目的是为了输入或输出一种新的文化,包括新的思想、新的技术等。
各民族或各国之间采取输入亦或是输出的交流模式,即文化交流,不但对社会的发展,而且对语言的发展,也会带来深远的影响。
在藏汉翻译的过程中,联系翻译理论,对藏汉翻译提出对应要求是必然的。
关于翻译的原则和标准,我国近代史上提出翻译标准而且影响最大的是严复。
他在译察《天演论》时所写的《译例言》中说:“事三难信达雅。
求其信已大难矣。
”严复提出的“信、达、雅”,虽然并未被列为具体的翻译标准,但长期以来,其已成为公认的翻译标准。
而当前人们在提到“信、达、雅”时,除了“信”的含义和严复提出的相同,即翻译内容“忠实”外,“达”和“雅”的含义往往已经改变或者作出了其他新的解释。
藏汉翻译应保持原作品的思想内容不变,针对译文阐述的中心思想,保证完整地将其运用另一语言进行翻译,这是藏汉翻译的第一个原则“内容忠实”。
在确保译文表现得思想内容并未改变得情况下,翻译工作者在藏汉翻译过程中,应认真分析观察译文得结构、语言风格以及行文笔调,译文工作的进行需要保证译文与原作品在风格、笔调上的统一性质,这是藏汉翻译的第二个原则“语言通顺”。
最后,在译文与原作平保持一致的思想、写作风格、用语笔调的同时,译文应对照原作品的表述,进行流畅地翻译表达,保证译文流畅自然地表述藏汉翻译的第三个原则“风格相当”。

面向自然语言处理的大规模汉藏(藏汉)双语语料库构建技术研究才让加【摘要】双语语料库建设及其自动对齐研究对计算语言学的发展具有重要的意义.目前国内外已建立了各类汉荚双语语料库以及服务于汉英机器翻译的双语对齐语料库和短语库.为了少数民族语言的机器翻译的研究从一开始就从较高起点起步,需要对汉藏双语文本的篇章级、段落级、句子级自动对齐技术进行研究,为开发和研究汉藏机器翻译奠定基础.主要研究汉藏双语语料库对齐、汉藏双语词典抽取、双语语料的收集、整理、存储以及检索等关键技术.最终研究结果是藏文编码的自动识别与转换技术,藏语语料库构建技术、汉藏双语词典抽取技术、汉藏平行语料库句子和词语对齐技术,并建立面向汉藏机器翻译的大规模汉藏双语对齐语料库.%The obstruction of bilingual Corpus and its automatic alignment research are of vital importance for the development of the computational linguistics. So far various types of Chinese-English bilingual corpus, including substantial sentnece aligned corpus for MT, have been developed both in China and abroad. In order to start the MT research involving minority with the state-of-arts technology, the research on the automatic alignments at the discourse level, paragraph level and sentence level between the Chinese and Tibetan vi-texts are necessary. This paper introduces a project on the Sino-Tibetanbilingual corpus alignments, the Chinese -Tibetan bilingual dictionary extraction, and the key technologies in the corpus collection, storage and retrieval. The project has accomplished such technologies as the Tibetan coding identification and conversion, thTibetan corpus construction, the Sino-Tibetan bilingual dictionary extraction, the Sino-Tibetan sentence alignment and word alignments, and finally achieving a large-scale aligned Sino-Tibetan bilingual corpus for Chinese-Tibetan machine translation.【期刊名称】《中文信息学报》【年(卷),期】2011(025)006【总页数】5页(P157-161)【关键词】汉藏机器翻译;汉藏双语语料库;编码;对齐技术【作者】才让加【作者单位】青海师范大学计算机学院青海师范大学藏文信息处理省部共建教育部重点实验室青海省藏文信息研究中心,青海西宁810008【正文语种】中文【中图分类】FP3911 序言近年来,语料库资源对于自然语言处理研究的巨大价值已经得到越来越多学者的认可。

多注意力机制的藏汉机器翻译方法研究刘赛虎,珠杰*(西藏大学信息科学技术学院,西藏拉萨850000)摘要:互联互通时代了解和掌握不同语言的区域文化和信息十分重要,机器翻译是目前广泛应用的交流媒介。
本文以藏汉机器翻译为研究对象,利用Transformer框架和模型,研究了基于Transformer多注意力机制的藏汉机器翻译方法。
经过实验,评估了多语料融合实验、语料双切分实验对比效果,得到了BLEU值32.6的实验结果。
关键词:藏汉;Transformer;机器翻译;注意力机制;多语料中图分类号:TP399文献标识码:A文章编号:1009-3044(2021)10-0004-04开放科学(资源服务)标识码(OSID):Research on Tibetan-Chinese Machine Translation Method Based on Multi-Attention MechanismLIU Sai-hu,ZHU Jie*(Tibet University School of Information Science and Technology,Lhasa850000,China)Abstract:It is very important to understand and master regional culture and information in different languages in the age of inter⁃connection.Machine translation is a widely used communication medium.This paper takes Tibetan-Chinese machine translation as the research object,and uses the Transformer framework and model to study the Tibetan-Chinese machine translation method based on Transformermechanism.Through experiments,the comparison effect of multi-corpus fusion experiment and corpus dou⁃ble-segmentation experiment was evaluated,and the experimental results of BLEU32.6were obtained.Key words:Tibetan-Chinese;Transformer;machine translation;attention mechanism;multilingual corpus机器翻译(Machine Translation,MT)是借助机器的高计算能力,自动地将一种自然语言(源语言)翻译为另外一种自然语言(目标语言)[1]。

汉藏翻译的起源与理论研究作者:公保杰来源:《大经贸》2018年第04期【摘要】不同文化之间想要实现传播,首先应该具有统一的文字意义,其中翻译是传播不同文化的关键载体,在我们的生活中,翻译也有着重要的作用,与此同时,翻译是需要根据本土文化进行的,任何语言的翻译都需要建立在文化因素之上,如果离开了文化因素进行翻译,那么其准确度就会大大折扣。
在不同文化之间的翻译需要相互了解彼此的文化,这样才能让翻译更加的准确,本文对汉藏翻译进行了研究,对汉藏文化的传播有着重要的意义。
【关键词】汉藏文化翻译理论研究前言藏族是我国五十六个民族中不可缺少的一员,在经过不断的发展之后其文化和历史都是非常深厚的,但是因为很多客观因素的影响,汉族和藏族之间的交流有着很大的障碍,其中有民族文化的差异,在翻译的过程中是非常的困难的,因此本文对汉藏翻译进行了研究,让更多的汉藏文化研究者能够克服翻译的难题,从而达到文化交流的目的。
1.汉藏翻译的起源与发展在两种文化之间翻译是最大的困难,尤其是在藏族和汉族文化之间的翻译,更是极为困难,在汉藏翻译的过超过中因为不同文化的存在,因此在翻译的过程中经常会出现各种各样的问题,如果忽略了文化的差异,那么翻译是非常失败的,由此可见文化因素在汉藏翻译中的地位。
1.1 汉藏翻译的发展历史汉藏之间的交流应该是从唐朝开始的,在盛唐时期,汉藏两族之间经常交流和来往,为了加深对彼此的了解,开始了相互的学习,因此翻译工作也是必不可少的,而在汉藏翻译上,两族的上层领导者做出了巨大的贡献,而两族的百姓之间也是经常进行一些贸易,经常可以见到在汉族和藏族出现两族人民的出现,这也极大的促进了汉族文化的交流,更是让汉藏翻译工作能够顺利进行。
通过查阅资料得知,在盛唐时期,吐蕃与唐朝的来往有数百年之久,其中正式的官方来往就达到了300次,有一些对汉语和藏语比较熟悉的人,对于两族之间的文化也是非常的了解,这对于汉藏翻译工作的进行提供了重要的帮助。
关于汉藏翻译中的文化差异研究汉藏翻译是一项重要的跨文化交流工作,涉及到汉藏两个文化体系之间的语言、文字、文化传统等方面的交流和翻译。
在进行汉藏翻译的过程中,不可避免地会遇到文化差异的问题。
本文将从文化差异的角度探讨汉藏翻译中的相关问题,并提出相应的研究和解决方法。
一、文化差异对汉藏翻译的影响1.1 语言和文字语言是文化的载体,不同的文化背景会造成语言的差异。
在汉藏翻译中,很多时候单词和词语的直译并不能完全表达原文的意思,因为原文所蕴含的文化内涵在汉藏两种语言和文化中可能并不相同。
“天堂”一词在汉语中指代众神居住的地方,而在藏语中指代幸福快乐的境地。
在汉藏翻译中,需要结合原文的文化内涵来选择合适的词语,而不是简单地进行直译。
汉藏两种文字系统也存在着很大的差异。
汉字是象形文字,每个汉字都具有独特的意义,而藏文则是一种拼音文字,需要通过组合字母来表达意义。
这种文字系统的差异在翻译过程中会造成一定的困难,需要翻译人员有一定的文字学和文化背景知识。
1.2 文化传统在进行汉藏翻译时,还需要考虑到汉藏两个文化传统之间的差异。
比如在中文中,立春是中国二十四节气中的第一个节气。
而在藏文中,也有自己的传统节日和习俗。
在翻译立春这个词语时,需要考虑到这种文化差异,不能简单地进行直译,而是要结合藏文的传统习俗和文化内涵来进行翻译。
二、解决方法2.1 加强文化意识在进行汉藏翻译时,翻译人员需要加强文化意识,深入了解汉藏两个文化的差异和共同点,了解两种文化背后的历史、宗教、习俗等方面的知识。
只有具备了足够的文化背景知识,才能够更准确地理解原文的文化内涵,选择合适的词语进行翻译。
2.2 掌握专业知识在进行汉藏翻译时,翻译人员需要具备一定的专业知识,尤其是文字学和文化传统方面的知识。
只有具备了足够的专业知识,才能够更好地理解原文的意义,准确地表达出来。
2.3 与当地人员合作在进行汉藏翻译时,可以和当地的文化专家合作,了解当地的文化传统和习俗,获取更准确的信息。
青海师范大学藏文智能信息处理省级重点实验室简介扳档︽才稗︽拜扁︽涤邦︽蝶搬︽惭稗︽捶拜︽翟罢︽地罢︽忱稗︽搬郴︽伴窗稗︽败罢︽罢采拜︽尝︽罢稗邦﹀青海师范大学藏文信息处理与机器翻译实验室是依托国家高技术“863”计划项目建立起来的。
1994筹建,2001年经青海省教育厅评估验收,正式命名为“省级重点实验室”,被评为“优秀实验室”。
是集科研和教学为一体的计算机藏文信息处理与汉藏机器翻译方面的省级重点实验室。
实验室承担了1986年以来,青海省获得的第一个“863”项目——《汉藏科技机器翻译系统》,于1998年8月通过国家级鉴定,该项目填补了国内汉藏英语言文字机器翻译领域的空白,技术上处于国际先进水平,并于2001年获青海省科技进步二等奖;1999年承担了第二个“863”项目,—《实用化汉藏科技机器翻译系统》,是青海省获得的第二个“863”项目,于2000年通过了“863”计划智能计算机系统主题专家组的验收;另外还承担了《藏文自动分词系统》、《科技藏文名称术语翻译方法与标准研究》、《藏文视窗平台研究》和《藏文属性统计研究》等国家和省级项目。
2003年9月通过了《藏汉西文计算机操作平台设计与实现》省级鉴定,该项目填补了藏文词组输入法的国内空白,处于国际先进水平,同时鉴定了《藏汉英三语互译电子词典》的研制开发,填补了藏汉英三语互译电子词典的国内空白,处于国际领先水平,对于足进汉藏英文化交流,加速藏区的发展以及藏语言文字信息化建设具有重要意义。
《班智达汉藏翻译系统》分为科技翻译系统和公文翻译系统。
汉藏科技机器翻译系统经青海省科委组织的专家组测试表明:该系统对科技领域内封闭语料句子和文章的翻译可读性可达95%以上,对开放语料的翻译可读性可达80%以上。
同时,为提高翻译的正确性和加强规则的针对性,整个科技系统分为以下四个子系统:汉藏物理翻译系统、汉藏数学翻译系统、汉藏化学翻译系统、汉藏计算机翻译系统,从而使系统的翻译可读性在原有基础上有了很大的提高。
基于藏语语义分析的机器翻译技术研究何向真;万福成;于洪志;吴玺宏【摘要】Tibetan-Chinese machine translation is different from Chinese-English machine translation. One important rea-son, Tibetan is more dependent on the role of function word like the case-auxiliary word in the sentences. Classes of case-auxiliary words are various and the use of them is extremely different. This paper is to analyze the Tibetan case-auxil-iary words, integrate the semantic cues on the basis of Tibetan syntax tree, form the method of Tibetan-Chinese machine translation which is based on semantic cues. Through the experiment between the model of phrase and semantic, this method can be useful for Tibetan-Chinese machine translation.%藏汉机器翻译技术跟汉英机器翻译技术有所不同,其中,很重要的一个方面,藏语更依赖于格助词等虚词在句子中的作用,格助词种类繁多,用法差异很大。
针对藏语格助词进行分析,在藏语短语句法树库的基础上,加入了藏语本体特征的语义信息,形成融合藏语语义信息的藏汉机器翻译方法。
机器翻译用藏文自动分词探究官却多杰【摘要】According to the Tibetan and Chinese Machine Translation pretreatment process, put forward phrases as segmentation unit, so as to reduce the complexity of the Tibetan word segmentation algorithm. The test can improve the effect of Tibetan and Chinese Machine Translation effectively, meet Tibetan and Chinese Machine Translation source text pretreatment requirements.%针对藏汉机器翻译过程中的藏文预处理,提出切分单元尽可能短语化,从而降低藏文分词算法的复杂度。
经测试能有效提高藏汉机器翻译的效果,符合藏汉机器翻译源文预处理的需求。
【期刊名称】《电子测试》【年(卷),期】2015(000)022【总页数】3页(P46-48)【关键词】机器翻译;藏文;自动分词【作者】官却多杰【作者单位】青海师范大学民族师范学院,青海共和,813000【正文语种】中文【中图分类】TP391在藏汉机器翻译过程中,首先要对源文藏文部分进行分词预处理。
源文切分粒度直接影响分词算法的复杂度,单纯意义的分词算法将会以词为单位进行自动切分,尽可能切分到最细小的词语单元。
但在藏汉机器翻译时,切分粒度太小则翻译单元随之增加,并且需要进一步考虑这些细小的翻译单元在目标语言中的位置。
由此可知,采用纯粹的分词算法进行藏汉机器翻译源文预处理,既增加了分词算法的复杂度,又降低了藏汉机器翻译的效率。
本文提出在藏汉机器翻译源文预处理时,藏文分词粒度尽可能短语化,与翻译词典中最长的词条匹配,减少翻译单元和语序调整等额外的开销,从而缩短预处理时间并有效提高藏汉机器翻译的效率和质量。