Actel FPGA静态时序分析
- 格式:docx
- 大小:1.36 MB
- 文档页数:9

●专用集成电路的类型及特点分为三类:1全定制(Full Custom)全定制ASIC芯片的各层掩模都是按特定电路功能专门制造的. 2半定制(Semi-Custom)半定制ASIC芯片的单元电路是用预制的门阵(Gate Array)做成的,只有芯片的金属连线是按电路功能专门设计制造的。
一般称为MPGA,即:掩模可编程门阵。
3可编程(Programable )单元电路、金属连线和I/O引脚都是可编程的ASIC。
●可编程ASIC主要包括两大类:l CPLD(Complex programmable logic device):复杂可编程逻辑器件。
l FPGA(Field programmable Gate Array):现场可编程门阵列。
●集成电路设计和制造过程设计过程1制定规范(SPEC)2系统设计(System Design)3电路设计(Circuit Design)4版图设计(Layout Design)制造过程1制版2掩膜版制造(MASK)3流片(Fab) 4光刻、生长、扩散、掺杂、金属化,蒸铝等产生Pn结、NPN结构、MOS 电阻、电容等5 测试(Testing) 以Spec和Test Vector 为标准检测制造出的芯片是否满足设计要求6封装(Packaging) 7磨片划片(Sawing) 8键合(Wire Bonding) 9包封(Packaging)形式:DIP, QFP,PLCC,PGA,BGA,FCPGA 等●专用集成电路预测与发展SOC (System on a chip)1 工艺(Process)由0.35um,0.25um,0.18um进入0.13um,0.10um即高速,低压,低功耗2 EDA设计工具与设计方法必须变革以适应深亚微米工艺的发展(如Single Pass , Physical Synthesis 等)3 可编程器件向更高密度,更大规模和更广泛的领域发展(如Mixed Signal )4 Analog 电路-- 高速,高精度,低功耗,低电压●ASIC产品的发展动向内嵌式系统(Embeded System) (自动控制, 仪器仪表)计算机,通讯结合的系统芯片(Cable Modem, 1G )多媒体芯片(Mpeg Decoder Encoder, STB , IA )人工智能芯片光集成电路●设计过程分电路设计---前端设计版图设计---后端设计●设计流程(方法)分1.bottom-Up自底向上(Bottom-Up)设计是集成电路和PCB板的传统设计方法,该方法盛行于七、八十年设计从逻辑级开始,采用逻辑单元和少数行为级模块构成层次式模型进行层次设计,从门级开始逐级向上组成RTL级模块,再由若于RTL模块构成电路系统对于集成度在一万门以内的ASIC设计是行之有效的,无法完成十万门以上的设计设计效率低、周期长,一次设计成功率低2 Top-Downop-Down流程在EDA工具支持下逐步成为IC主要的设计方法从确定电路系统的性能指标开始,自系统级、寄存器传输级、逻辑级直到物理级逐级细化并逐级验证其功能和性能●Top-Down设计与Bottom-Up设计相比,具有以下优点:设计从行为到结构再到物理级,每一步部进都进行验证,提高了一次设计的成功率。
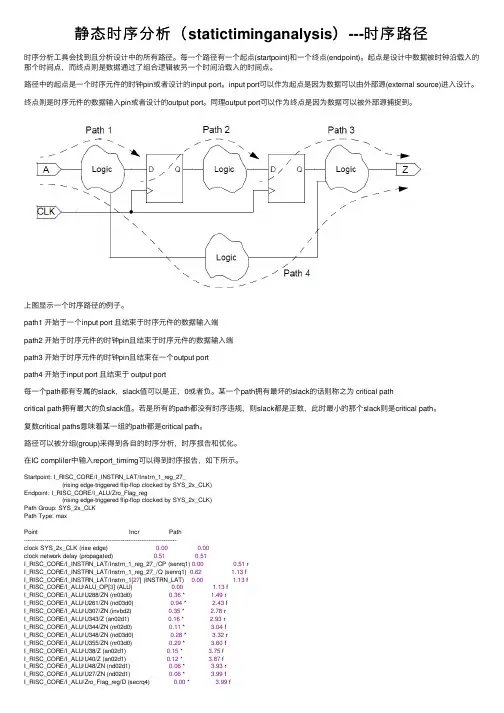
静态时序分析(statictiminganalysis)---时序路径时序分析⼯具会找到且分析设计中的所有路径。
每⼀个路径有⼀个起点(startpoint)和⼀个终点(endpoint)。
起点是设计中数据被时钟沿载⼊的那个时间点,⽽终点则是数据通过了组合逻辑被另⼀个时间沿载⼊的时间点。
路径中的起点是⼀个时序元件的时钟pin或者设计的input port。
input port可以作为起点是因为数据可以由外部源(external source)进⼊设计。
终点则是时序元件的数据输⼊pin或者设计的output port。
同理output port可以作为终点是因为数据可以被外部源捕捉到。
上图显⽰⼀个时序路径的例⼦。
path1 开始于⼀个input port 且结束于时序元件的数据输⼊端path2 开始于时序元件的时钟pin且结束于时序元件的数据输⼊端path3 开始于时序元件的时钟pin且结束在⼀个output portpath4 开始于input port 且结束于 output port每⼀个path都有专属的slack,slack值可以是正,0或者负。
某⼀个path拥有最坏的slack的话则称之为 critical pathcritical path拥有最⼤的负slack值。
若是所有的path都没有时序违规,则slack都是正数,此时最⼩的那个slack则是critical path。
复数critical paths意味着某⼀组的path都是critical path。
路径可以被分组(group)来得到各⾃的时序分析,时序报告和优化。
在IC compliler中输⼊report_timimg可以得到时序报告,如下所⽰。
Startpoint: I_RISC_CORE/I_INSTRN_LAT/Instrn_1_reg_27_ (rising edge-triggered flip-flop clocked by SYS_2x_CLK)Endpoint: I_RISC_CORE/I_ALU/Zro_Flag_reg (rising edge-triggered flip-flop clocked by SYS_2x_CLK)Path Group: SYS_2x_CLKPath Type: maxPoint Incr Path----------------------------------------------------------------------------------clock SYS_2x_CLK (rise edge) 0.000.00clock network delay (propagated) 0.510.51I_RISC_CORE/I_INSTRN_LAT/Instrn_1_reg_27_/CP (senrq1) 0.000.51 rI_RISC_CORE/I_INSTRN_LAT/Instrn_1_reg_27_/Q (senrq1) 0.62 1.13 fI_RISC_CORE/I_INSTRN_LAT/Instrn_1[27] (INSTRN_LAT) 0.00 1.13 fI_RISC_CORE/I_ALU/ALU_OP[3] (ALU) 0.00 1.13 fI_RISC_CORE/I_ALU/U288/ZN (nr03d0) 0.36 * 1.49 rI_RISC_CORE/I_ALU/U261/ZN (nd03d0) 0.94 * 2.43 fI_RISC_CORE/I_ALU/U307/ZN (invbd2) 0.35 * 2.78 rI_RISC_CORE/I_ALU/U343/Z (an02d1) 0.16 * 2.93 rI_RISC_CORE/I_ALU/U344/ZN (nr02d0) 0.11 * 3.04 fI_RISC_CORE/I_ALU/U348/ZN (nd03d0) 0.28 * 3.32 rI_RISC_CORE/I_ALU/U355/ZN (nr03d0) 0.29 * 3.60 fI_RISC_CORE/I_ALU/U38/Z (an02d1) 0.15 * 3.75 fI_RISC_CORE/I_ALU/U40/Z (an02d1) 0.12 * 3.87 fI_RISC_CORE/I_ALU/U48/ZN (nd02d1) 0.06 * 3.93 rI_RISC_CORE/I_ALU/U27/ZN (nd02d1) 0.06 * 3.99 fI_RISC_CORE/I_ALU/Zro_Flag_reg/D (secrq4) 0.00 * 3.99 fdata arrival time 3.99clock SYS_2x_CLK (rise edge) 4.00 4.00clock network delay (propagated) 0.47 4.47clock uncertainty -0.10 4.37I_RISC_CORE/I_ALU/Zro_Flag_reg/CP (secrq4) 0.00 4.37 rlibrary setup time -0.37 4.00data required time 4.00--------------------------------------------------------------------------------data required time 4.00data arrival time -3.99-------------------------------------------------------------------------------slack (MET) 0.01此例⼦的图如下:报告开始显⽰了路径的起点,路径终点,路径组名和路径检测的类型。

FPGA时序参数分析及输入延时对布线的影响FPGA(Field-Programmable Gate Array)是一种可编程逻辑器件,广泛应用于数字电路设计和实现。
在FPGA设计中,时序参数分析和输入延时对布线的影响是非常重要的。
时序参数分析是指对FPGA设计中各个时钟周期内的各个信号的到达时间和处理时间进行分析和优化的过程。
FPGA设计中的时序参数包括时钟频率、时钟延迟、最大延时等。
通过对时序参数的分析,可以保证FPGA设计在给定的时钟频率下正常工作,并优化设计以满足性能要求。
输入延时是指信号从输入端口到达FPGA内部逻辑电路的时间延迟。
输入延时可以分为外部输入延时和内部输入延时。
外部输入延时是指信号从FPGA器件引脚到达输入寄存器的延时。
内部输入延时是指信号从输入寄存器到达逻辑电路的延时。
输入延时对FPGA设计的布线有重要影响。
输入延时对布线的影响主要体现在以下几个方面:1.时序约束:输入延时决定了信号在FPGA内部的传播时间,而时序约束描述了这些信号到达和离开各个逻辑单元的时间关系。
因此,通过对输入延时的分析,可以确定适当的时序约束,并在布线过程中对信号路径进行约束,以满足时序要求。
2.时钟分配:输入延时还影响时钟信号在FPGA内部的分配方式。
时钟分配是指将时钟信号传递给各个逻辑单元的过程。
如果输入延时较大,可能需要采取更长的时钟路径,使时钟能够及时到达各个逻辑单元。
3.时钟域划分:输入延时也会对时钟域划分造成影响。
时钟域是指在不同时钟频率下工作的信号集合。
输入延时较大的信号可能要求在不同的时钟域中处理,进而需要将不同时钟域的逻辑电路进行分离,以避免时序问题。
对布线的影响主要可以从以下几方面进行分析:1.布线路径:输入延时较大的信号路径可能需要更长的线长,因而需要更多的布线资源。
布线路径决定了信号传播的延时和稳定性。
因此,在布线过程中,需要根据输入延时的要求合理规划布线路径,并进行资源分配和优化。

XilinxISE下的静态时序分析与时序优化单击Design Summary中的Static Timing就可以启动时序分析器(Timing Analyzer)。
在综合、布局布线阶段ISE就会估算时延,给出⼤概的时延和所能达到的最⼤时钟频率,经过PAR后,在Static Timing中给出的是准确的时延,给出的时序报告可以帮助我们找到关键路径,然后针对其进⾏优化,提⾼系统的时钟频率。
这⾥的Minimum period指的是最⼩的逻辑延迟;造成时序性能差的原因很多,主要缘由以下⼏种:1. 布局太差⼀般和代码本⾝没有关系。
解决⽅案:只能从软件⾃⾝的布局算法考虑(调整布局的努⼒程度)或者使⽤⾼端芯⽚2. 逻辑级数太多逻辑级数越多,资源的利⽤率越⾼,但是对⼯作频率的影响也越⼤。
解决⽅案:1.使⽤流⽔线技术;2.如果是多周期路径,添加多周期约束;3.良好的编码习惯,不要过多嵌套if-else,尽量使⽤case代替if语句。
3. 信号扇出过⾼⾼扇出会造成信号传输路径过长,从⽽降低时序性能。
解决⽅案:1.逻辑复制;2.区域约束,想过逻辑放置在⼀起。
4. 不要同时使⽤双边沿触发FPGA的底层⼯艺都是单向的同步电路,所以本⾝不⽀持统⼀信号的双边沿触发,ISE在实际处理的时候,会⾃动将该信号2倍频,然后利⽤第⼀个沿处理上升沿,第⼆个沿处理下降沿。
这样在分析时序时,⾃动把约束升级为ucf⽂件中的两倍。
5. Xilinx最优时序解决⽅案1.I/O约束 根据Xilinx器件的特点,控制信号置于器件的顶部或底部,且垂直布置;数据总线的I/O置于器件的左右两侧,且⽔平布置,这样可以最⼤程度的利⽤芯⽚底层结构。
2.ISE实现⼯具 ISE中的⼯具具备不同的努⼒程度,直接使⽤最⾼级别的可以提⾼时序性能,但是会耗费很多时间,所以应该逐步调整努⼒程度。
第⼀遍使⽤默认的参数选项,如果不满⾜再调整综合、映射、布局布线的参数。
时序优化的若⼲策略优化⽅向⼀:合理使⽤Blcok RAM和Distributed RAM1. 均衡Block RAM和Distributed RAM的使⽤。

【第⼋章时序检查下】静态时序分析圣经翻译计划8.9 举例在本节中,我们将介绍发起和捕获时钟的不同情况,并分别说明如何执⾏建⽴时间和保持时间检查。
图8-28为所举例⼦的⽰意图:半周期路径——情况1在此⽰例中,两个时钟具有相同的周期,但相位相反。
以下是时钟定义,其波形如图8-29所⽰。
create_clock -name CLKM -period 20 -waveform {0 10} [get_ports CLKM]create_clock -name CLKP -period 20 -waveform {10 20} [get_ports CLKP]建⽴时间检查是从发起沿(0ns)到下⼀个捕获沿(10ns)的。
半个时钟周期的裕量可⽤于保持时间检查,以验证在20ns处发起的数据是否在10ns处未被捕获沿所捕获。
以下是建⽴时间检查的路径报告:以下是保持时间检查的路径报告:半周期路径——情况2此⽰例与情况1类似,不过发起时钟和捕获时钟的相位相反。
以下是时钟定义,其波形如图8-30所⽰。
create_clock -name CLKM -period 10 -waveform {5 10} [get_ports CLKM]create_clock -name CLKP -period 10 -waveform {0 5} [get_ports CLKP]建⽴时间检查从5ns的发起时钟沿到10ns的下⼀个捕获时钟沿。
保持时间检查从5ns的发起时钟沿到0ns的捕获时钟沿。
以下是建⽴时间检查的路径报告:以下是保持时间检查的路径报告:快速时钟域到慢速时钟域在此⽰例中,捕获时钟是发起时钟的⼆分频。
以下是时钟定义:create_clock -name CLKM -period 10 -waveform {0 5} [get_ports CLKM]create_clock -name CLKP -period 20 -waveform {0 10} [get_ports CLKP]波形如图8-31所⽰。
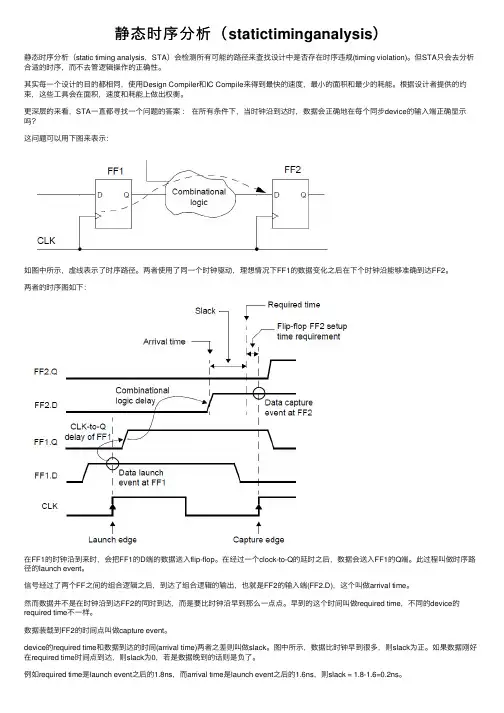
静态时序分析(statictiminganalysis)静态时序分析(static timing analysis,STA)会检测所有可能的路径来查找设计中是否存在时序违规(timing violation)。
但STA只会去分析合适的时序,⽽不去管逻辑操作的正确性。
其实每⼀个设计的⽬的都相同,使⽤Design Compiler和IC Compile来得到最快的速度,最⼩的⾯积和最少的耗能。
根据设计者提供的约束,这些⼯具会在⾯积,速度和耗能上做出权衡。
更深层的来看,STA⼀直都寻找⼀个问题的答案:在所有条件下,当时钟沿到达时,数据会正确地在每个同步device的输⼊端正确显⽰吗?这问题可以⽤下图来表⽰:如图中所⽰,虚线表⽰了时序路径。
两者使⽤了同⼀个时钟驱动,理想情况下FF1的数据变化之后在下个时钟沿能够准确到达FF2。
两者的时序图如下:在FF1的时钟沿到来时,会把FF1的D端的数据送⼊flip-flop。
在经过⼀个clock-to-Q的延时之后,数据会送⼊FF1的Q端。
此过程叫做时序路径的launch event。
信号经过了两个FF之间的组合逻辑之后,到达了组合逻辑的输出,也就是FF2的输⼊端(FF2.D),这个叫做arrival time。
然⽽数据并不是在时钟沿到达FF2的同时到达,⽽是要⽐时钟沿早到那么⼀点点。
早到的这个时间叫做required time,不同的device的required time不⼀样。
数据装载到FF2的时间点叫做capture event。
device的required time和数据到达的时间(arrival time)两者之差则叫做slack。
图中所⽰,数据⽐时钟早到很多,则slack为正。
如果数据刚好在required time时间点到达,则slack为0,若是数据晚到的话则是负了。
例如required time是launch event之后的1.8ns,⽽arrival time是launch event之后的1.6ns,则slack = 1.8-1.6=0.2ns。

《IC芯片设计中的静态时序分析实践》读书记录一、内容概览本书详细介绍了静态时序分析的基本概念、原理、方法及其在IC芯片设计中的应用。
在阅读本书的过程中,我形成了一些对该书的理解和内容概览。
该书从静态时序分析的基本原理入手,讲解了静态时序分析在IC芯片设计流程中的地位和作用。
静态时序分析是一种通过静态的方法来分析电路时序的过程,它在芯片设计的验证阶段起到至关重要的作用,确保芯片在规定的时序约束下正确运行。
书中详细阐述了静态时序分析的具体实践方法,包括建立有效的时序分析环境、设置合理的时序约束、进行静态时序分析的工具使用等。
还介绍了静态时序分析中常见的优化技巧,如降低时序违规的风险、提高分析效率等。
在深入理解了静态时序分析的基本原理和方法后,书中还探讨了现代IC芯片设计中的挑战和问题。
随着工艺技术的发展,IC芯片的设计复杂度不断提高,静态时序分析面临着更高的挑战。
书中通过实例分析,展示了如何运用静态时序分析技术来解决这些挑战。
本书还强调了团队合作在IC芯片设计中的重要性,特别是在静态时序分析过程中。
有效的团队协作和沟通能够大大提高分析效率,减少错误的发生。
书中通过实际案例,展示了团队合作在静态时序分析中的具体应用和优势。
本书总结了静态时序分析在IC芯片设计中的应用价值和实践经验。
通过学习和实践本书中的知识和方法,读者能够掌握静态时序分析的核心技能,为未来的IC芯片设计领域做出贡献。
在阅读本书的过程中,我不仅了解了静态时序分析的基本原理和方法,还深入理解了其在现代IC芯片设计中的应用和实践。
通过对书中内容的梳理和总结,我对静态时序分析有了更加全面和深入的认识,为今后的学习和工作打下了坚实的基础。
1. 书籍简介《IC芯片设计中的静态时序分析实践》是一本专注于集成电路(IC)芯片设计领域静态时序分析的权威指南。
本书旨在帮助读者理解并掌握静态时序分析的基本原理、方法与实践应用。
静态时序分析是IC芯片设计过程中的关键环节,对于确保芯片性能、优化功耗以及避免设计缺陷具有重要意义。
1. 适用范围本文档理论适用于Actel FPGA并且采用Libero软件进行静态时序分析(寄存器到寄存器)。
2. 应用背景静态时序分析简称STA,它是一种穷尽的分析方法,它按照同步电路设计的要求,根据电路网表的拓扑结构,计算并检查电路中每一个DFF(触发器)的建立和保持时间以及其他基于路径的时延要求是否满足。
STA作为FPGA设计的主要验证手段之一,不需要设计者编写测试向量,由软件自动完成分析,验证时间大大缩短,测试覆盖率可达100%。
静态时序分析的前提就是设计者先提出要求,然后时序分析工具才会根据特定的时序模型进行分析,给出正确是时序报告。
进行静态时序分析,主要目的就是为了提高系统工作主频以及增加系统的稳定性。
对很多数字电路设计来说,提高工作频率非常重要,因为高工作频率意味着高处理能力。
通过附加约束可以控制逻辑的综合、映射、布局和布线,以减小逻辑和布线延时,从而提高工作频率。
3. 理论分析3.1 静态时序分析的理论基础知识在进行正确的时序分析前,我们必须具备基本的静态时序的基本知识点,不然看着编译器给出的时序分析报告犹如天书。
如图3.1所示,为libero软件给出的寄存器到寄存器模型的时序分析报告的截取,接下来我们会弄清楚每个栏目的数据变量的含义,以及计算方法。
图3.1 libero静态时序分析报告3.1.1 固定参数launch edge、latch edge、Tsu、Th、Tco概念1. launch edge时序分析起点(launch edge):第一级寄存器数据变化的时钟边沿,也是静态时序分析的起点。
2. latch edge时序分析终点(latch edge):数据锁存的时钟边沿,也是静态时序分析的终点。
3. Clock Setup Time (Tsu)建立时间(Tsu):是指在时钟沿到来之前数据从不稳定到稳定所需的时间,如果建立的时间不满足要求那么数据将不能在这个时钟上升沿被稳定的打入触发器。

静态时序分析基本原理和时序分析模型静态时序分析是指对程序在其编译阶段或者运行阶段进行的一种分析方法,通过对程序的代码进行解析和推理,从而分析出程序执行的正确性、性能、资源消耗等方面的信息。
静态时序分析可以帮助开发人员在代码实现阶段尽早发现和解决问题,提高代码的可靠性和可维护性。
1.控制流分析:静态时序分析首先通过控制流分析,构建程序的控制流图。
控制流图由程序中的所有语句和它们之间的控制流关系构成,用来描述程序的执行路径和顺序。
静态时序分析可以通过控制流图来寻找潜在的执行路径问题,如死循环、无法到达的代码等。
2.数据流分析:静态时序分析还可以进行数据流分析,通过对程序中变量的定义和使用关系进行分析,确定变量在不同的执行路径上的值。
数据流分析可以帮助发现未初始化变量、未使用变量等问题。
3.依赖分析:静态时序分析可以进行依赖分析,分析程序中不同语句之间的依赖关系,确定一些语句执行的前提条件。
依赖分析可以帮助发现多线程竞争、资源争用等问题。
静态时序分析的依赖分析可以通过指针分析、函数调用分析等方式实现。
4.前向分析和后向分析:静态时序分析可以进行前向分析和后向分析。
前向分析从程序的入口点开始,根据程序的控制流图,逐个语句地分析程序的执行路径。
后向分析从程序的出口点开始,反向分析程序的执行路径。
通过前向分析和后向分析,可以找到程序的执行路径,帮助发现执行路径上的问题。
时序分析模型是静态时序分析的抽象表示,可以用来描述程序的执行顺序和时序约束。
常见的时序分析模型包括Petri网、有限状态机等。
1. Petri网:Petri网是一种常用的时序分析模型,它可以描述系统中不同活动之间的顺序和并发关系。
Petri网由节点和有向弧组成,节点表示活动,弧表示活动之间的关系。
通过对Petri网的分析,可以推理出系统的行为和时序约束。
2.有限状态机:有限状态机是描述系统行为的一种抽象模型,它可以把系统的执行顺序表示为一个状态转移图。

library IEEE;use IEEE.std_logic_1164.all;USE IEEE.STD_LOGIC_TEXTIO.ALL;USE STD.TEXTIO.ALL;entity testbench isend entity testbench;architecture test_reg of testbench iscomponent mydesign isport( POWERDOWN : in std_logic;CLKA : in std_logic;LOCK : out std_logic;GLA : out std_logic);end component;signal POWERDOWN : std_logic;signal CLKA : std_logic:='0';signal LOCK, GLA : std_logic;constant ClockPeriod : TIME := 100 ns;beginUUT : mydesign port map (POWERDOWN=>POWERDOWN,CLKA=>CLKA,LOCK=>LOCK, GLA=>GLA);generate_clock : PROCESS (CLKA)BEGIN -- processCLKA <= NOT CLKA AFTER ClockPeriod/2;END PROCESS;process beginPOWERDOWN<='0';wait for 2000 ns;POWERDOWN<='1';wait for 100 ns;wait;end process;end architecture test_reg;测试结果如下图所示:由图可见,锁相环在lock信号变为高电平时生成了符合要求的输出时钟信号。
2.采用Clock & Management下的PLL-Static模块来实现输入时钟信号的相移功能(通过SmartDesign入口),Static PLL配置如下:采用上面的testbench,将其中的被调用模块名修改为此处PLL的模块名,在modelsim 环境下进行仿真,获得结果如下:从上图可见,在lock信号置高电平后,gla信号准确地在迟延90度后跟踪给定信号。

FPGA设计之——时序设计FPGA设计一个很重要的设计是时序设计,而时序设计的实质就是满足每一个触发器的建立(Setup)/保持(Hold)时间的要求。
建立时间(Setup Time):是指在触发器的时钟信号上升沿到来以前,数据稳定不变的时间,如果建立时间不够,数据将不能在这个时钟上升沿被打入触发器;保持时间(Hold Time):是指在触发器的时钟信号上升沿到来以后,数据稳定不变的时间,如果保持时间不够,数据同样不能被打入触发器。
FPGA设计分为异步电路设计和同步电路设计,然而很多异步电路设计都可以转化为同步电路设计,在设计时尽量采用同步电路进行设计。
对于同步电路可以转化的逻辑必须转化,不能转化的逻辑,应将异步的部分减到最小,而其前后级仍然应该采用同步设计。
为了让同步电路可靠地运行,就要对时钟偏差进行控制,以使时钟偏差减小到可用的范围。
影响时钟偏差的主要有以下几个因素:o用于连接时钟树的连线o钟树的拓扑结构o时钟的驱动o时钟线的负载o时钟的上升及下降时间在通常的FPGA设计中对时钟偏差的控制主要有以下几种方法:o控制时钟信号尽量走可编程器件的的全局时钟网络。
在可编程器件中一般都有专门的时钟驱动器及全局时钟网络,不同种类、型号的可编程器件,它们中的全局时钟网络数量不同,因此要根据不同的设计需要选择含有合适数量全局时钟网络的可编程器件。
一般来说,走全局时钟网络的时钟信号到各使用端的延时小,时钟偏差很小,基本可以忽略不计。
o若设计中时钟信号数量很多,无法让所有的信号都走全局时钟网络,那么可以通过在设计中加约束的方法,控制不能走全局时钟网络的时钟信号的时钟偏差。
o异步接口时序裕度要足够大。
局部同步电路之间接口都可以看成是异步接口,比较典型的是设计中的高低频电路接口、I/O接口,那么接口电路中后一级触发器的建立-保持时间要满足要求,时序裕度要足够大。
o在系统时钟大于30MHz时,设计难度有所加大,建议采用流水线等设计方法。
1.1 概述在高速系统中FPGA时序约束不止包括内部时钟约束,还应包括完整的IO时序约束和时序例外约束才能实现PCB板级的时序收敛。
因此,FPGA时序约束中IO 口时序约束也是一个重点。
只有约束正确才能在高速情况下保证FPGA和外部器件通信正确。
1.2 FPGA整体概念由于IO口时序约束分析是针对于电路板整个系统进行时序分析,所以FPGA需要作为一个整体分析,其中包括FPGA的建立时间、保持时间以及传输延时。
传统的建立时间、保持时间以及传输延时都是针对寄存器形式的分析。
但是针对整个系统FPGA的建立时间保持时间可以简化。
图1.1 FPGA整体时序图如图1.1所示,为分解的FPGA内部寄存器的性能参数:(1)Tdin为从FPGA的IO口到FPGA内部寄存器输入端的延时;(2)Tclk为从FPGA的IO口到FPGA内部寄存器时钟端的延时;(3)Tus/Th为FPGA内部寄存器的建立时间和保持时间;(4)Tco为FPGA内部寄存器传输时间;(5)Tout为从FPGA寄存器输出到IO口输出的延时;对于整个FPGA系统分析,可以重新定义这些参数:FPGA建立时间可以定义为:(1)FPGA建立时间:FTsu = Tdin + Tsu – Tclk;(2)FPGA保持时间:FTh = Th + Tclk;(3)FPGA数据传输时间:FTco = Tclk + Tco + Tout;由上分析当FPGA成为一个系统后即可进行IO时序分析了。
FPGA模型变为如图1.2所示。
图1.2 FPGA系统参数1.3 输入最大最小延时外部器件发送数据到FPGA系统模型如图1.3所示。
对FPGA的IO口进行输入最大最小延时约束是为了让FPGA设计工具能够尽可能的优化从输入端口到第一级寄存器之间的路径延迟,使其能够保证系统时钟可靠的采到从外部芯片到FPGA的信号。
图1.3 FPGA数据输入模型输入延时即为从外部器件发出数据到FPGA输入端口的延时时间。
静态时序分析电子科技大学詹璨铭什么是静态时序分析⏹静态时序分析STA(static timing analysis)⏹定义⏹与动态时序分析的差异怎样做静态时序分析⏹使用工具primetime (简称pt)与DC ⏹两者的兼容性⏹为什么使用primetime?Primetime与DC的兼容性⏹使用同样的工艺库和设计文件⏹许多指令一样⏹相同的算法,很多结果也一样⏹从一个synthesizable subcircuit 中,pt能捕获一个时序环境,并写成一系列的dc指令,在dc中用其为这个subcircuit定义时间约束和时序优化--值得关注⏹为dc写的dcsh格式的脚本可以翻译成在pt上用的格式。
在pt中定义为抄本(transcript)格式⏹这两个都支持用SDC(synopsys design constraints)格式指定设计规则,包括时间面积约束。
为什么用pt⏹更快效率更高⏹占用更少的内存⏹具有高级的芯片级的分析能力和高级的建模能力。
STA中的对象⏹Design -完整的设计⏹Cell(instance)-设计中使用的一个元件⏹Net -金属连线⏹Port -design 的I/O口⏹Pin -cell 的I/O口⏹Reference -是元件的参考的源定义⏹Clock -创建的时钟信号时序弧(timing arc)⏹定义:如果把电路看作是一张很大的拓扑图,那么图中的结点就是电路中的引脚(pin)。
结点与结点之间的部分,我们称作是时序弧(timing arc)。
他定义了任意两个结点之间的时序关系。
⏹最直观基本的理解:cell delay与net delay。
这两个也是计算下面时序弧的基础。
每段时序弧的延时就是把这两个值不断相加时序弧分类一:时序的延时⏹组合时序弧(combinational timing arc)⏹边沿时序弧(edge timing arc)⏹重置和清除时序弧(preset and clear timing arc)⏹三态使能/无效时序弧(three state enable/disable timing arc)时序弧分类二:时序约束⏹建立时序弧(setup timing arc)⏹保持时序弧(hold timing arc)⏹恢复时序弧(recovery timing arc)⏹清除时序弧(removal timing arc)⏹宽度时序弧(width timing arc)组合时序弧(combinationaltiming arc)⏹负函数(negative unate)⏹正函数(positive unate)⏹非函数(non-unate)calculation)--cell delay⏹是从一个逻辑门的输入到输出的延迟量⏹通过工艺库(technology library)来查找的⏹这是个2维表,查找项是输入的过渡时间(input transition),输出的电容负载(output load capacitance)没有对应的值,做一个线性的推导,计算出相应的值。
静态时序分析综述报告——孙声震1.静态时序分析静态时序分析(STA)就是套用特定的时序模型(Timing Model),针对特定电路分析其是否违反设计者给定的时序限制(Timing Constraint)。
1.1 背景仿真技术是ASIC设计过程中应用最多的验证手段,然而,现在的单片集成系统设计正在将仿真时间推向无法容忍的极限。
在最后的门级仿真阶段,针对的是几十乃至几百万门的电路,对仿真器第一位的要求是速度和容量,因此,性能(仿真速度)和容量(能够仿真的设计规模)是验证中的关键因素。
传统上采用逻辑仿真器验证功能时序,即在验证功能的同时验证时序,它以逻辑模拟方式运行,需要输入向量作为激励。
随着规模增大,所需要的向量数量以指数增长,验证所需时间占到整个设计周期的50%,而最大的问题是难以保证足够的覆盖率。
鉴于此,这种方法已经越来越少地用于时序验证,取而代之的是静态时序分析技术。
1.2 分类静态时序分析以分析的方式区分,可分为Path-Based及Block-Based两种。
图1如图1所示,为Path-Based这种分析方式。
信号从A点及B点输入,经过中间的逻辑单元,从Y端输出。
套用的Timing Model标示在各逻辑器件上,对于所有输入端到输出端都可以找到相对应的延迟时间。
而使用者给定的TimingConstraint为:1. 信号A到达电路输入端的时间点为2(AT=2,AT为Arrival Time)。
2. 信号B到达电路输入端的时间点为5(AT=5)。
3. 信号必须在时间点10之前到达输出端Y(RT=10,RT为Required Time)。
针对P1及P2 两条路径(Path)来做分析。
P1的起始点为A,信号到达时间点为2。
经过第1个逻辑器件之后,由于有2单位的延迟时间,所以信号到达这个器件输出的时间点为4(2+2)。
依此类推,信号经由P1到达输出Y的时间点为7(2+2+3)。
在和上述第三项Timing Constraint比对之后,我们可以得知对P1这个路径而言,时序(Timing)是满足使用者要求的。
静态时序分析的三种分析模式(简述)经过跟行业前辈的探讨和参考一些书籍,本文中的“个人理解”部分有误,即:(个人理解:)在一个库中,尽管电路器件单元已经被综合映射,但是工具可以通过改变周围的环境来得到不同的单元延时,所以即使是同一个库,调用工艺参数不一样的情况下,其单元延时是不同的,因此就有了最快路径和最慢路径。
(这里有误)。
对于一个综合好的电路网表,在一个确定的pvt环境下(即只读入一个库的情况下)、约束好了端口的transition和load,那么电路网表中的某个器件的延时是唯一确定的(从库查表得到)。
ovc模式下一个器件才有两个延时值。
因此下面的库分析(延时分析)过程中,存在认识错误,请读者们注意以后我会专门写一篇文章来更正的。
学习数字设计(数字IC设计、FPGA设计)都必须学习静态时序分析(Static Timing Analysis ,STA)。
然而静态时序时序分析是一个比较大的方向,涉及到的内容也比较多,如果要系统得学习,那得花费不少的心思。
这里来记录一下关于静态时序分析的三种分析模式,这里的记录只是记录一下学习笔记,或者说是随笔,而不是系统地学习STA。
本文是来自于前天遇到了一道静态时序分析的题目,感觉有点疑惑,于是发到群里请求解答。
经过一番讨论、查找资料之后,真相渐渐露出水面。
先看一下题目:一、时序路径分析模式及相关概念1.最快路径和最慢路径在求解这道题目之前,先来介绍一下时序路径分析模式及相关概念。
①最快路径(early- path):指在信号传播延时计算中调用最快工艺参数的路径;根据信号的分类可以分为最快时钟路径和最快数据路径。
②最慢路径(late path):指在信号传播延附计算中调用最慢工艺参数的路径;分为最慢时钟路径和最慢数据路径。
(个人理解:)在一个库中,尽管电路器件单元已经被综合映射,但是工具可以通过改变周围的环境来得到不同的单元延时,所以即使是同一个库,调用工艺参数不一样的情况下,其单元延时是不同的,因此就有了最快路径和最慢路径。
§1.1 What is STA ?一般来说,要分析或检验一个电路设计的时序方面的特征有两种主要手段:动态时序仿真(Dynamic Timing Simulation)和静态时序分析(Static Timing Analysis)。
§1.2When to do STA ?§1.3PrimeTime Inputs and Outputs ?§1.4 Three main steps for STA⏹将设计打散成路径的集合(design > path group > path)⏹对于集合中的每条路径分别计算路径延时长度⏹检查所有路径是否满足约束1.Step 1 – Timing Path(Path Group:路径根据末端触发器的时钟不同分为不同的Clock Path Group;不为时钟所约束的路径为default Path Group对于Clock Gating Setup/Hold check的路径为clock_gating_default Path Group) 2.Step 2– Cell Delay Calculation3.Step 3– Constraints1)时钟约束DC中对路径的时序slack进行计算,完全基于对clock的约束来模拟真实布线之后的clock network.所以需要对clock 的source_latency、network_latency、clock_uncertainty、transition_time都进行设置并set_ideal_network来禁止DC由于fanout的问题修改时钟网络。
然而PT在进行时序分析的时候采用的是布局布线之后的设计,可以从SDF文件中读入时钟树信息,可以直接set_propagated_clock来计算时钟路径上的latency.2)Interface Paths的约束Set_input_delay 0.60 –clock Clk [get_ports A]Set_output_delay 0.40 –clock Clk [get_ports M]3)工作条件的约束诸如design的输入信号transition、输出负载、线载模型、PVT情况。
1. 适用范围
本文档理论适用于Actel FPGA并且采用Libero软件进行静态时序分析(寄存器到寄存器)。
2. 应用背景
静态时序分析简称STA,它是一种穷尽的分析方法,它按照同步电路设计的要求,根据电路网表的拓扑结构,计算并检查电路中每一个DFF(触发器)的建立和保持时间以及其他基于路径的时延要求是否满足。
STA作为FPGA设计的主要验证手段之一,不需要设计者编写测试向量,由软件自动完成分析,验证时间大大缩短,测试覆盖率可达100%。
静态时序分析的前提就是设计者先提出要求,然后时序分析工具才会根据特定的时序模型进行分析,给出正确是时序报告。
进行静态时序分析,主要目的就是为了提高系统工作主频以及增加系统的稳定性。
对很多数字电路设计来说,提高工作频率非常重要,因为高工作频率意味着高处理能力。
通过附加约束可以控制逻辑的综合、映射、布局和布线,以减小逻辑和布线延时,从而提高工作频率。
3. 理论分析
3.1 静态时序分析的理论基础知识
在进行正确的时序分析前,我们必须具备基本的静态时序的基本知识点,不然看着编译器给出的时序分析报告犹如天书。
如图3.1所示,为libero软件给出的寄存器到寄存器模型的时序分析报告的截取,接下来我们会弄清楚每个栏目的数据变量的含义,以及计算方法。
图3.1 libero静态时序分析报告
3.1.1 固定参数launch edge、latch edge、Tsu、Th、Tco概念
1. launch edge
时序分析起点(launch edge):第一级寄存器数据变化的时钟边沿,也是静态时序分析的起点。
2. latch edge
时序分析终点(latch edge):数据锁存的时钟边沿,也是静态时序分析的终点。
3. Clock Setup Time (Tsu)
建立时间(Tsu):是指在时钟沿到来之前数据从不稳定到稳定所需的时间,如果建立的时间不满足要求那么数据将不能在这个时钟上升沿被稳定的打入触发器。
如图3.2所示:
图3.2 建立时间图解
4. Clock Hold Time (Th)
保持时间(Th):是指数据稳定后保持的时间,如果保持时间不满足要求那么数据同样也不能被稳定的打入触发器。
保持时间示意图如图3.3所示:
图3.3 保持时间图解
5. Clock-to-Output Delay(tco)
数据输出延时(Tco):这个时间指的是当时钟有效沿变化后,数据从输入端到输出端的最小时间间隔。
3.1.2 Clock skew
时钟偏斜(clock skew):是指一个时钟源到达两个不同寄存器时钟端的时间偏移,如图3.4所示:
图3.4 时钟偏斜
时钟偏斜计算公式如下:
Tskew = Tclk2 - Tclk1(公式3-1)3.1.3 Data Arrival Time
数据到达时间(Data Arrival Time):输入数据在有效时钟沿后到达所需要的时间。
主要分为三部分:时钟到达寄存器时间(Tclk1),寄存器输出延时(Tco)和数据传输延时(Tdata),如图3.5所示
图3.5 数据到达时间
数据到达时间计算公式如下:
Data Arrival Time = Launch edge + Tclk1 +Tco + Tdata(公式3-2)3.1.4 Clock Arrival Time
时钟到达时间(Clock Arrival Time):时钟从latch边沿到达锁存寄存器时钟输入端所消耗的时间为时钟到达时间,如图3.6所示
图3.6 时钟到达时间
时钟到达时间计算公式如下:
Clock Arrival Time = Lacth edge + Tclk2(公式3-3)
3.1.5 Data Required Time(setup/hold)
数据需求时间(Data Required Time):在时钟锁存的建立时间和保持时间之间数据必须稳定,从源时钟起点达到这种稳定状态需要的时间即为数据需求时间。
如图3.7所示:
图3.7 数据需求时间
(建立)数据需求时间计算公式如下:
Data Required Time = Clock Arrival Time - Tsu(公式3-4)(保持)数据需求时间计算公式如下:
Data Required Time = Clock Arrival Time + Th(公式3-5)3.1.6 Setup slack
建立时间余量(setup slack):当数据需求时间大于数据到达时间时,就说时间有余量,Slack是表示设计是否满足时序的一个称谓。
图3.8 建立时间余量
如图3.8所示,建立时间余量的计算公式如下:
Setup slack = Data Required Time - Data Arrival Time(公式3-6)由公式可知,正的slack表示数据需求时间大于数据到达时间,满足时序(时序的余量),负的slack表示数据需求时间小于数据到达时间,不满足时序(时序的欠缺量)。
3.1.7 时钟最小周期
时钟最小周期:系统时钟能运行的最高频率。
1.当数据需求时间大于数据到达时间时,时钟具有余量;
2. 当数据需求时间小于数据到达时间时,不满足时序要求,寄存器经历亚稳态或者不能正确获得数据;
3. 当数据需求时间等于数据到达时间时,这是最小时钟运行频率,刚好满足时序。
从以上三点可以得出最小时钟周期为数据到达时间等于数据需求时间,的运算公式如下:Data Required Time = Data Arrival Time(公式3-7)由上式推出如下公式:
Tmin + Latch edge + Tclk2 - Tsu = Launch edge + Tclk1 + Tco + Tdata
最终推出最小时钟周期为:
Tmin = Tco + Tdata + Tsu - Tskew(公式3-8)4. 应用分析
4.1 设置时钟主频约束
所有的静态时序分析都是在有约束的情况下编译器才给出分析报告,所以进行时序分析的第一步就是设置约束。
Libero软件设置时钟约束的途径三种,单时钟约束,多时钟约束和在Designer里面进行约束。
4.1.1 单时钟约束
有时我们系统所有模块都采用同一个时钟,这种方式最为简单,直接在Synplify主界面上有个设置时钟约束的,如图4.1中红框所示:
图4.1 单时钟设置
设置完成后,编译,通过Synplify时钟报告看初步时钟运行频率能否达到要求,时钟报告如图4.2所示,设定100Mhz,能运行102.7Mhz,满足时序。
图4.2 时序报告
4.2 多时钟约束
当系统内部模块采用了多个时钟时,那就需要进行多时钟约束了。
首先需要打开设置界面,在Synplify中选择:File->New->Constraint File建立SDC文件,选择时钟约束如图4.3所示:
图4.3 多时钟约束
对时钟进行如下约束后保存SDC文件,约束如图4.4所示
图4.4 多时钟约束完成
4.3 Designer SmartTime时钟约束
时钟约束除了在Synplify中可以约束外,还可以在Designer SmartTime中设置时钟约束,打开Designer Constraint,选择Clock进行针对每个使用时钟的设置,如图4.5所示:
图4.5 Designer时序约束
4.4 时序报告分析
4.4.1 Synplify时序报告
当约束了时序后,需要观察时序报告,看时钟能否达到我们需要的时钟,首先观察Synplify 综合报告。
以多时钟约束为例子,从Synplify得到的时序报告如图4.6所示:
图4.6 多时钟约束时序报告
由上图可知时序都满足约束,未出现违规,可以在下面的报告中查看最差路径,如图4.7所示是clk2的最差路径。
图4.7 最差路径
4.4.2 Designer SmartTime时序分析报告
当设计经过Synplify综合给出网表文件后,还需要Designer进行布局布线,通过布局布线优化后的时序会有变化,因此,还需要分析布局布线后的时序,打开Designer->Timing Analyzer查阅整体时序分析报告如图4.8所示:
图4.8 布局布线后时序报告
由Synplify综合后的报告和Designer进行布局布线后的报告可以看出,布局布线后优化了一些时序,特别是clk2时钟,通过布局布线后优化到了184Mhz,完全满足时序。
4.4.3 详细时序报告图
通过Synplify综合后的和Designer进行布局布线都只是看到了一个大体的时序报告,当我们需要分析时序时候必须观察仔细的时序报告,在SmartTime中提供这种报告功能,以clk2分析为例,在Timing Analyzer找到如下区域。
图4.9 时序报告选择
如图4.9所示,选择寄存器到寄存器进行分析时钟主频。
图4.10 寄存器到寄存器分析
如图4.10所示,时序报告中给出了数据延时,时序余量,数据到达时间,数据需求时间,数据建立时间,以及最小周期和时钟偏斜等信息,有了上一节的时序分析基础知识,我们完全能看懂这些数据代表的意义,这样对我们时序分析就知己知彼,进一步双击其中一条路径,还会给出这条路径的硬件电路图,如图4.11所示,有了这些详细的时序报告,对设计进行调整更加清晰。
图4.11 硬件路径。