Hadoop伪分布安装配置
- 格式:doc
- 大小:697.00 KB
- 文档页数:5

Mapreduce程序设计报告姓名:学号:题目:Hadoop系统伪分布搭建和运行1、实验环境联想pc机虚拟机:VM 10.0操作系统:Centos 6.4Hadoop版本:hadoop 1.2.1Jdk版本:jdk-7u252、系统安装步骤:2.1安装配置SSH在CentOs中,已经安装ssh与sshd,可用which命令查看打开终端,在终端中中键入:ssh -keygen -t rsa生成无密码密钥对,询问其保存路径时直接回车采用默认路径。
生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/home/hadoop/.ssh"目录下。
接着将id_rsa.pub追加到授权的key里面去cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys2.2 安装JDK:打开终端,输入命令mkdir /usr/java //建立java文件夹//复制JDK文件夹包cd /usr/java //进入jdk文件夹tar –zxvf jdk-7u25-linux-x64.tar.gz //解压jdk文件mv jdk1.7.0_25 jdk //重新命名jdk文件夹rm –rf jdk-7u25-linux-x64.tar.gz //删除jkd压缩包2.3配置JDK环境变量使用root权限进行操作,输入命令:vim /etc/profile按i进入编辑,在文件的最后,添加环境变量语句:按esc,接着按:wq保存退出,执行命令source /etc/profile 使环境变量生效使用命令java -version检测环境变量是否配置成功。
要是出现以上情况,说明jdk配置成功。
2.4安装Hadoop打开终端,输入命令cp /home/tzj/hadoop/hadoop-1.2.1.tar /usr #复制hadoop安装包到usr目录cd /usr #进入"/usr"目录tar –zxvf hadoop-1.2.1.tar.gz #解压"hadoop-1.2.1.tar.gz"安装包mv hadoop-1.2.1 hadoop #将"hadoop-1.2.1"文件夹重命名"hadoop"mkdir /usr/hadoop/tmp #在hadoop文件夹下创建tmp文件夹chown –R tzj:tzj hadoop #将文件夹"hadoop"读权限分配给hadoop用户rm –rf hadoop-1.0.0.tar.gz #删除"hadoop-1.0.0.tar.gz"安装包2.5hadoop配置(1)使用root权限进行操作,输入命令:vim /etc/profile按i进入编辑,在文件的最后,添加环境变量语句:按esc,接着按:wq保存退出,执行命令source /etc/profile 使环境变量生效(2)配置hadoop-env.sh在文本最后添加# set java environmentexport JAVA_HOME=/jdk1.7.0_25(3)配置core-site.xml在文本最后添加:<configuration><property><name>hadoop.tmp.dir</name><value>/usr/hadoop/tmp</value>(备注:请先在/usr/hadoop 目录下建立tmp 文件夹)<description>A base for other temporary directories.</description> </property><!-- file system properties --><property><name></name></property></configuration>(4)配置hdfs-site.xml在文本最后添加:<configuration><property><name>dfs.replication</name><value>1</value>(备注:replication 是数据副本数量,默认为3,salve少于3台就会报错) </property><configuration>(5)配置mapred-site.xml在文本最后添加:<configuration><property><name>mapred.job.tracker</name></property></configuration>2.6启动hadoop和验证(1)格式化hdfs文件系统hadoop namenode -format(2)启动hadoop2.7启动hadoopstart-all.sh启动守护程序,使用以下方式进行验证:(1)使用自带的JPS验证启动情况。

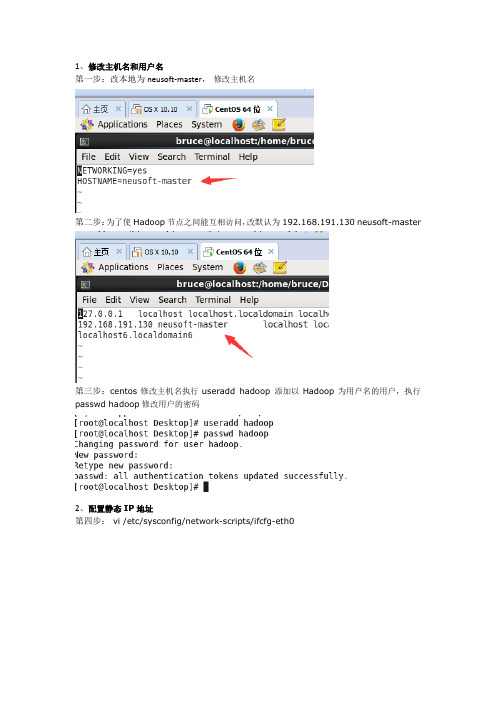
1、修改主机名和用户名第一步:改本地为neusoft-master,修改主机名第二步:为了使Hadoop节点之间能互相访问,改默认为192.168.191.130 neusoft-master第三步:centos修改主机名执行useradd hadoop 添加以Hadoop为用户名的用户,执行passwd hadoop修改用户的密码2、配置静态IP地址第四步: vi /etc/sysconfig/network-scripts/ifcfg-eth0或图形界面配置:点击设置[root@neusoft-master ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0TYPE=EthernetUUID=02eb9342-c828-49a5-9e23-64e8c2d5e05eONBOOT=yesNM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.191.130NETMASK=255.255.255.0GATEWAY=192.168.191.2PREFIX=24DNS1=8.8.8.8HWADDR=00:50:56:2C:72:E9DEFROUTE=yesIPV4_FAILURE_FATAL=yesIPV6INIT=noNAME="System eth0"LAST_CONNECT=14828518173、配置SSH无密码连接目录:1.修改主机名和用户名2.配置静态IP地址3.配置SSH无密码连接4.安装JDK1.75.配置Hadoop6.安装Mysql7.安装Hive8.安装Hbase9.安装Sqoop********************1.修改主机名和用户名修改主机名:Centos中通过vi /etc/sysconfig/network 修改HOSTNAME=∙为了使Hadoop节点之间能互相访问,需要修改hosts文件,root用户执行并且所有节点均需执行vi /etc/hosts∙ centos修改主机名执行useradd hadoop 添加以Hadoop为用户名的用户,执行passwd hadoop修改用户的密码2. 配置静态IP地址[root@neusoft-master ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0TYPE=EthernetUUID=02eb9342-c828-49a5-9e23-64e8c2d5e05eONBOOT=yesNM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.191.130NETMASK=255.255.255.0GATEWAY=192.168.191.2PREFIX=24DNS1=8.8.8.8HWADDR=00:50:56:2C:72:E9DEFROUTE=yesIPV4_FAILURE_FATAL=yesIPV6INIT=noNAME="System eth0"LAST_CONNECT=1482851817注意:如果多台虚拟机复制会有问题,我罗列了遇到的问题,如果没有图形界面网络配置更简单,如果沒有問題請跳过方法1:利用图形界面解决(1)图形界面找见图标,编辑(2)删除所有网络(3)根据虚拟机配置ip,网管等解决Error:No suitable device found: no device found for connection "System eth0"注意:VM的虚拟网卡VMnet8一定需要在windows操作系统的网络中开启,同时在虚拟机中配置正确的子网掩码及网关存在的问题点1:windows上的网络配置存在的问题点2:VM软件配置方法2:问题复述:复制好的虚拟机,启动登陆进去(用户名和密码跟之前那台是一样的),修改好IPADDR,然后网卡重启出现问题?#service network restart出现问题:Error:No suitable device found: no device found for connection "System eth0" 如图所示:#ifup eth0出现: eth0: unknown interface: No such device 这样的问题,网卡都启动不了,出现问题.解决:(1)我们在界面点击Network Adapter Remove删除网卡,如图所示:(2)添加一个新的网卡,就是点击add,这时跟前面一台的MAC Address 就不一样,如图所示:(3)复制地址(4)重新启动虚拟机,然后进入到/etc/udev/rules.d/目录#cat 70-persistent-net.rules里面的信息跟我们Network Adapter的MAC Address地址一样,如图所示:(5)进入/etc/sysconfig/network-scripts/目录#vi ifcfg-eth0把HWADDR修改成Network Adapter的MAC Address地址一样,如图所示:(6)重启网卡,这时就能正常启动,如图所示:3.配置SSH无密码连接在Centos中首先关闭防火墙service iptables stop 查看防火墙:chkconfig iptables off(1)检查ssh是否安装yum install sshyum install rsync #远程同步数据的工具(2)启动SSH服务命令service sshd restart检查SSH是否已经安装成功rpm -qa | grep openssh rpm -qa | grep rsync 出现相应信息即可(3)生成SSH公钥对于伪分布式环境只需要本机链接本机即可:主节点执行:ssh-keygen -t rsa一路回车即可,最后显示的图形是公钥的指纹加密。

1.安装JDK,配置环境变量(步骤省略)2.解压hadoop-2.2.0.tar.gz。
3.配置core-site.xml core-site.xml(必须配置)如果这个没有配置或者配置错误(我将hdfs写成hffs)将出现下面错误(见问题2)4.配置hdfs-site.xml hdfs-site.xml(可以不配置,采用默认)可以不设置上面3个相关目录,不设置的话,将采用默认的目录。
5.拷贝mapred-site.xml.template mapred-site.xml mapred-site.xml并配置yarn-site.xml6.配置yarn-site.xml7.修改slaves(可以不修改,采用默认)8.初始化Hadoophadoop namenode –format(已过时)hadoop-2.2.0/bin/hdfs namenode -format成功提示:9.启动start-dfs.shstart-yarn.sh共5个:NodeManager,DataNode,ResourceManager,NameNode,SecondaryNameNode 10.启动完成后运行示例:hadoop-2.2.0/bin/hadoop jar hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarrandomwriter out执行结果:http://localhost:8088http://localhost:50070http://localhost:50090问题:1.启动时,报没有设置JAVA_HOME修改$hadoop_home/etc/hdoop/hadoop-env.sh2.启动时,报Incorrect configuration:node.servicerpc ornode.rpc-address is not configured,没有设置对core-site.xml3.运行hadoop jar$HADOOP_PREFIX/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarrandomwriter out 报如下错误:java.io.IOException: Cannot initialize Cluster. Please check your configuration for and the correspond server addresses.at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:120) 原因是在mapred-site.xml(配置第5步)中配置把yarn写成了Yarn。

1、安装ubuntu10.10wubi的傻瓜式安装应该不用我多说了吧,在win下用虚拟光驱载入,然后执行.......另外补充下,安装时最好断开网络连接(我们是直接拔的网线),因为ubuntu安装过程中需要更新一些语言包之类的东西,那些东西与我们要做的事没什么关系,下载时间又长,所以建议不更新。
2、安装jdk1.6.0_23有多种方法,此处只介绍一种1、在usr下面新建一个文件夹Java,然后将jdk复制过来(也可直接mv过来)sudo mkdir /usr/Javasudo cp jdk的路径/usr/Java2、进入到Java目录下,改变文件权限为可执行cd /usr/Javasudo chmod u+x jdk1.6.0_23.bin3、执行安装sudo ./jdk1.6.0_23.bin(现象为Unpacking....加一连串解压信息)3、安装hadoop0.21.01、将hadoop0.21.0.tar.gz复制到usr下面的local文件夹内(也可mv)sudo cp hadoop的路径/usr/local2、进入到local目录下,解压hadoop0.21.0.tar.gzcd /usr/localsudo tar -xzf hadoop0.21.0.tar.gz3、为了方便管理,将解压后的文件夹名改为hadoopsudo mv hadoop0.21.0 hadoop4、创建一个名为hadoop的用户和用户组1、创建一个名为hadoop的用户组sudo addgroup hadoop2、创建一个名为hadoop的用户,归到hadoop用户组下sudo adduser --ingroup hadoop hadoop(注1:前一个hadoop为用户组名,后面的是用户名,之所以名字一样是为了方便统一管理注2:执行后会有一些信息需要填写,可以不填,都敲回车,用系统默认的即可,大概5个吧)3、用gedit打开etc下的sudoers文件sudo gedit /etc/sudoers4、在root ALL=(ALL:ALL) ALL 下面添加如下一行,然后保存关闭gedithadoop ALL=(ALL:ALL) ALL(注1:网上有文档上是说先切换到root用户,然后修改sudoers的权限,再打开添加hadoop ALL=(ALL) ALL ,然后再将权限改回为只读,这样就要特别注意一定要将权限改回为只读,不然“sudo”命令就无法使用了,很悲剧的说注2:添加hadoop ALL=(ALL) ALL 的意义在于能让hadoop用户使用“sudo”命令)配置阶段:1、配置环境变量1、用gedit打开etc下的profile文件sudo gedit /etc/profile2、在文件最后加入如下几行export CLASSPATH=.:/usr/Java/jdk1.6.0_23/lib:/usr/Java/jdk1.6.0_23/jre/lib:$CLASSPATHexport PATH=.:/usr/Java/jdk1.6.0_23/bin:/usr/Java/jdk1.6.0_23/jre/bin:/usr/local/hadoop/bin:$PATH (注1:以上所有jre项都不是必需的,可以不要注2:在win中环境变量的值是以“;”号隔开的,而这里是“:”注3:等号后面有个“.”别丢了,它表示当前目录)3、保存后关闭gedit,并重启机器sudo reboot(注:网上也有说用source命令使环境变量立即生效的,但是本人在实际操作时出了几次问题,所以建议重启机器最保险)4、重启后用hadoop用户登录,验证配置是否成功java -version (此语句执行后如显示了jdk版本的话说明配置成功,如果没有则需检查profile中路径是否正确)(注:最好是用hadoop用户登录,因为以下步骤都是以此为前提的)2、创建ssh-key1、确保网络通畅,然后装载ssh服务sudo apt-get install openssh-server(注:如果此语句执行失败且结果为“....包被占用”的话,那么应该是ubuntu的“更新管理器”正在后台更新,你可以选择等待或者关闭更新,更新管理器在“系统”菜单中,具体位置忘了.....)2、创建ssh-key,为rsa (网上文档中也有dsa的)ssh-keygen -t rsa --P(注1:此语句网上文档为ssh-keygen -t rsa -P "" ,效果一样注2:此语句执行后会要你填写key的保存位置,直接照着系统给出的那个默认位置填,也就是括号里的那个路径,如果全都照此文档操作的话那么括号中路径应该为"/home/hadoop/.ssh/id_rsa")3、将此ssh-key添加到信任列表中,并启用此ssh-keycat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keyssudo /etc/init.d/ssh reload3、配置hadoop1、进入到hadoop目录下,配置conf目录下的hadoop-env.sh中的JAVA_HOMEcd /usr/local/hadoopsudo gedit conf/hadoop-env.sh(打开后在文档的上部某行有“#export JAVA_HOME=...”字样的地方,去掉“#”,然后在等号后面填写你的jdk路径,完全按此文档来的话应改为"exportJAVA_HOME=/usr/Java/jdk1.6.0_23" )2、配置conf目录下的core-site.xmlsudo gedit conf/core-site.xml(打开后标签<configuration> </configuration>中是空的,所以在空的地方加入如下配置)Xml代码1.<property>2.<name></name>3.<value>hdfs://localhost:9000</value>4.</property>5.6.<property>7.<name>dfs.replication</name>8.<value>1</value>9.</property>10.11.<property>12.<name>hadoop.tmp.dir</name>13.<value>/home/hadoop/tmp</value>14.</property>3、配置conf目录下的mapred-site.xmlsudo gedit conf/mapred-site.xml(打开后标签<configuration> </configuration>中也是空的,添加如下配置)Xml代码1.<property>2.<name>mapred.job.tracker</name>3.<value>localhost:9001</value>4.</property>运行测试阶段:1、格式化namenode (首次运行必需滴)1、保证此时在hadoop目录下,如不在请先进入hadoop目录cd /usr/local/hadoop2、格式化namenodehadoop namenode -format2、启动hadoop1、修改hadoop文件夹的权限,保证hadoop用户能正常访问其中的文件sudo chown -hR hadoop /usr/local/hadoop2、启动hadoopbin/start-all.sh3、验证hadoop是否正常启动jps(此语句执行后会列出已启动的东西NameNode,JobTracker,SecondaryNameNode...如果NameNode没有成功启动的话就要先执行"bin/stop-all.sh"停掉所有东西,然后重新格式化namenode,再启动)3、跑wordcount1、准备需要进行wordcount的文件sudo gedit /tmp/test.txt(打开后随便输入一些内容,如"mu ha ha ni da ye da ye da",然后保存退出)2、将准备的测试文件上传到dfs文件系统中的firstTest目录下hadoop dfs -copyFromLocal /tmp/test.txt firstTest(注:如dfs中不包含firstTest目录的话就会自动创建一个,关于查看dfs文件系统中已有目录的指令为"hadoop dfs -ls")3、执行wordcounthadoop jar hadoop-mapred-example0.21.0.jar wordcount firstTest result(注:此语句意为“对firstTest下的所有文件执行wordcount,将统计结果输出到result文件夹中”,若result文件夹不存在则会自动创建一个)4、查看结果hadoop dfs -cat result/part-r-00000(注:结果文件默认是输出到一个名为“part-r-*****”的文件中的,可用指令“hadoop dfs -ls result”查看result目录下包含哪些文件)。

超详细解说Hadoop伪分布式搭建单节点伪分布式Hadoop配置(声明:文档里面需要用户输入的均已斜体表示)第一步:安装JDK因为 Hadoop 运行必须安装 JDK 环境,因此在安装好 Linux 后进入系统的第一步便是安装 JDK ,安装过程和在 Windows 环境中的安装步骤很类似,首先去Oracle 官网去下载安装包,然后直接进行解压。
我自己解压在路径 /usr/jvm 下面,假如你的安装包现在已经下载在 jvm 文件夹下面,然后按 Ctrl+Alt+t 进去命令行,然后输入cd /usr/jvm进入到jvm文件夹下面,然后再输入如下命令进行解压:sudo tar -zxvf jdk-7u40-linux-i586.tar.gz第二步:配置环境变量解压结束以后,像在Windows 系统中一样,需要配置环境变量,在 Ubuntu 中设置环境变量的过程为打开文件 /etc/profile ,因为权限的问题,因此在命令行需要输入的是sudo gedit /etc/profile然后在根据提示输入用户密码即可,然后在文件最下面添加如下:export JAVA_HOME=/usr/jvm/jdk1.7.0_40export CLASSPATH=".:$JAVA_HOME/lib:$JAVA_HOME/jre/lib $CLASSPATH"export PATH="$JAVA_HOME/bin:$JAVA_HOME/jre/bin:/usr/ hadoop/hadoop-1.2.1/bin:$PATH"上面这三个以单词export 开始的三个语句就类似于我们在Windows 中的环境变量中设置一样,而且在这个里面和 Windows 中不同的是,在Windows 中使用“;” 号来表示分隔,但是在Ubuntu 中是以“:” 号来表示分隔。
还需要注意的是,上面的路径都是我自己配置的时候的路径,因为我的JDK 解压在/usr/jvm 中,所以我的 JAVA_HOME 设置的是那个路径,而且如果安装的 JDK 版本不同那么后面的也不一样。
Hadoop:Hadoop单机伪分布式的安装和配置因为lz的Linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏。
之前是在Docker中配置的Hadoop单机伪分布式[Hadoop:Hadoop单机伪分布式的安装和配置],并且在docker只有root用户,所有没有权限问题存在。
这里直接在linux下配置,主要是为了能用netbeans ide调试hadoop程序,并且使用的用户就是开机时登录的用户pika。
本教程配置环境:ubuntu14.04(Ubuntu 12.04 /32位、64位都ok! lz是直接使用的双系统中的linux)hadoop 2.6.4 (原生 Hadoop 2都ok!)jdk1.7.0_101(应该1.6+应该都ok!)皮皮blog基本环境配置安装和配置Java环境在主机上从Oracle官方网站下载对应版本的JDK安装包$ sudo vim ~/.bashrc 或者/etc/profile第一行“...”的path末尾加上:${JAVA_HOME}/bin,后面export路径PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"export JAVA_HOME=/opt/jdk1.8.0_73export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=$PATH:${JAVA_HOME}/bin$ sudo update-alternatives --install /usr/bin/java java /opt/jdk1.8.0_73/bin/java 300;sudo update-alternatives --install /usr/bin/javac javac /opt/jdk1.8.0_73/bin/javac 300;sudo update-alternatives --install /usr/bin/javah javah/opt/jdk1.8.0_73/bin/javah 300;sudo update-alternatives --install /usr/bin/jar jar /opt/jdk1.8.0_73/bin/jar 300. ~/.bashrc 或者/etc/profile测试是否安装成功root@f26f7d459863:/#Java -version[java环境配置:安装jdk、eclipse]安装SSH、配置SSH无密码登陆集群、单节点模式都需要用到 SSH (ssh must be installed and sshd must be running to use the Hadoop scripts that manage remote Hadoop daemons,而这并没有说一定要ssh localhost登录lz亲测,运行hadoop不需要ssh localhost登录,只要安装并运行了sshd就可以了),Ubuntu 默认已安装了 SSH client,还需要安装 SSH server:pika:~$sudo apt-get install -y openssh-server编辑sshd的配置文件pika:~$sudo vim /etc/ssh/sshd_config,将其中大概88行,UsePAM参数设置成“no”启动sshd服务pika:~$sudo /etc/init.d/ssh start#每次重启都要重新启动,所以要加入到profile中开机自启pika:~$sudo vim /etc/profile其中加入一行/etc/init.d/ssh start查看ssh服务状态 pika:~$ps -e | grep ssh29856 ? 00:00:00 sshd安装后设置ssh可以使用如下命令登陆本机:ssh localhost此时会有SSH首次登陆提示,输入 no,(如果输入yes再输入密码,这样就登陆到本机了,但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便,如果进去了首先退出刚才的 ssh)。
Hadoop环境配置以及Hadoop伪分布式安装是用于学习和实践大数据处理和分析的重要步骤。
下面将详细解释配置Hadoop环境以及安装Hadoop伪分布式的目的。
一、Hadoop环境配置配置Hadoop环境是为了在实际的硬件或虚拟机环境中搭建Hadoop集群,包括安装和配置Hadoop的各个组件,如HDFS(Hadoop分布式文件系统)、MapReduce(一种编程模型和运行环境)等。
这个过程涉及到网络设置、操作系统配置、软件安装和配置等步骤。
通过这个过程,用户可以了解Hadoop的基本架构和工作原理,为后续的学习和实践打下基础。
二、Hadoop伪分布式安装Hadoop伪分布式安装是一种模拟分布式环境的方法,它可以在一台或多台机器上模拟多个节点,从而在单机上测试Hadoop的各个组件。
通过这种方式,用户可以更好地理解Hadoop 如何在多台机器上协同工作,以及如何处理大规模数据。
安装Hadoop伪分布式的主要目的如下:1. 理解Hadoop的工作原理:通过在单机上模拟多个节点,用户可以更好地理解Hadoop如何在多台机器上处理数据,以及如何使用MapReduce模型进行数据处理。
2. 练习Hadoop编程:通过在单机上模拟多个节点,用户可以编写和测试Hadoop的MapReduce程序,并理解这些程序如何在单机上运行,从而更好地理解和学习Hadoop编程模型。
3. 开发和调试Hadoop应用程序:通过在单机上模拟分布式环境,用户可以在没有真实数据的情况下开发和调试Hadoop应用程序,从而提高开发和调试效率。
4. 为真实环境做准备:一旦熟悉了Hadoop的伪分布式环境,用户就可以逐渐将知识应用到真实环境中,例如添加更多的实际节点,并开始处理实际的大规模数据。
总的来说,学习和实践Hadoop环境配置以及Hadoop伪分布式安装,对于学习和实践大数据处理和分析具有重要意义。
它可以帮助用户更好地理解和学习Hadoop的工作原理和编程模型,为将来在实际环境中应用和优化Hadoop打下坚实的基础。
Hadoop伪分布式安装配置过程在进行Hadoop伪分布式安装配置之前,首先需要确保系统环境符合安装要求。
Hadoop的安装需要在Linux系统下进行,并且需要安装好Java环境。
以下将详细介绍Hadoop伪分布式安装配置的步骤。
一、准备工作1. 确保系统为Linux系统,并且已经安装好Java环境。
2. 下载Hadoop安装包,并解压至指定目录。
二、配置Hadoop环境变量1. 打开.bashrc文件,添加以下内容:```bashexport HADOOP_HOME=/path/to/hadoopexport PATH=$PATH:$HADOOP_HOME/binexport HADOOP_CONF_DIR=/path/to/hadoop/etc/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOME```2. 执行以下命令使环境变量生效:```bashsource ~/.bashrc```三、配置Hadoop1. 编辑hadoop-env.sh文件,设置JAVA_HOME变量:```bashexport JAVA_HOME=/path/to/java```2. 编辑core-site.xml文件,添加以下内容:```xml<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>```3. 编辑hdfs-site.xml文件,添加以下内容:```xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>```4. 编辑mapred-site.xml.template文件,添加以下内容并保存为mapred-site.xml:```xml<configuration><property><name></name><value>yarn</value></property></configuration>```5. 编辑yarn-site.xml文件,添加以下内容:```xml<configuration><property><name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name> <value>localhost</value></property></configuration>```四、格式化HDFS执行以下命令格式化HDFS:```bashhdfs namenode -format```五、启动Hadoop1. 启动HDFS:```bashstart-dfs.sh```2. 启动YARN:```bashstart-yarn.sh```六、验证Hadoop安装通过浏览器访问xxx,确认Hadoop是否成功启动。