卡方检验和非参数检验
- 格式:ppt
- 大小:877.50 KB
- 文档页数:41

SPSS非参数检验之一卡方检验一、卡方检验的概念和原理卡方检验是一种常用的非参数检验方法,用于检验两个或多个分类变量之间的关联性。
它利用实际观察频数与理论频数之间的差异,来判断两个变量是否独立。
卡方检验的原理基于卡方分布,在理论上,如果两个变量是独立的,那么它们的观测频数应该等于理论频数。
卡方检验通过计算卡方值来度量观察频数与理论频数之间的差异程度,进而判断两个变量是否独立。
卡方值的计算公式为:卡方值=Σ((观察频数-理论频数)²/理论频数)其中,观察频数为实际观察到的频数,理论频数为理论上计算得到的频数。
二、卡方检验的步骤卡方检验的步骤包括以下几个方面:1.建立假设:首先需要建立原假设和备择假设。
原假设(H0)是两个变量之间独立,备择假设(H1)是两个变量之间存在关联。
2.计算理论频数:根据原假设和已知数据,计算出各组的理论频数。
3.计算卡方值:利用卡方值的计算公式,计算观察频数与理论频数之间的差异。
4.计算自由度:自由度的计算公式为自由度=(行数-1)*(列数-1)。
5.查表或计算P值:根据卡方值和自由度,在卡方分布表中查找对应的临界值,或者利用计算机软件计算P值。
6.判断结果:判断P值与显著性水平的关系,如果P值小于显著性水平,则拒绝原假设,认为两个变量存在关联;如果P值大于显著性水平,则接受原假设,认为两个变量是独立的。
三、卡方检验在SPSS中的应用在SPSS软件中,进行卡方检验的操作相对简单。
下面以一个具体的案例来说明:假设我们有一份数据,包括了男性和女性在健康习惯(吸烟和不吸烟)方面的调查结果。
我们想要检验性别与吸烟习惯之间是否存在关联。
1.打开SPSS软件,导入数据。
2.选择"分析"菜单,点击"拟合度优度检验"。
3.在弹出的对话框中,将两个变量(性别和吸烟习惯)拖入"因子"栏目中。
4.点击"统计"按钮,勾选"卡方拟合度"。

卡方检验名词解释
卡方检验属于非参数检验,由于非参检验不存在具体参数和总体正态分布的假设,所以有时被称为自由分布检验。
参数和非参数检验最明显的区别是它们使用数据的类型。
非参检验通常将被试分类,如民主党和共和党,这些分类涉及名义量表或顺序量表,无法计算平均数和方差。
卡方检验分为拟合度的卡方检验和卡方独立性检验。
我们用几个例子来区分这两种卡方检验:
•对于可口可乐公司的两个领导品牌,大多数美国人喜欢哪一种?•公司采用了新的网页页面B,相较于旧版页面A,网民更喜欢哪一种页面?
以上两个例子属于拟合度的卡方检验,原因在于它们都是有关总体比例的问题。
我们只是将个体分类,并想知道每个类别中的总体比例。
它检验的内容仅涉及一个因素多项分类的计数资料,检验的是单一变量在多项分类中实际观察次数分布与某理论次数是否有显著差异。
拟合度的卡方检验定义:
主要使用样本数据检验总体分布形态或比例的假说。
测验决定所获得的的样本比例与虚无假设中的总体比例的拟合程度如何。
拟合度的卡方检验又叫最佳拟合度的卡方检验,为何取名“最佳拟合”?这是因为最佳拟合度的卡方检验的目的是比较数据(实际频数)与虚无假设。
确定数据如何拟合虚无假设指定的分布,因此取名“最佳拟合”。
关于拟合度的卡方检验有一些翻译上的区别,其实表达的是一个意思:
拟合度的卡方检验=卡方拟合优度检验=最佳拟合度卡方检验
以下统称:卡方拟合优度检验
卡方统计的公式:卡方卡方=χ2=Σ(fo−fe)2fe
公式中O代表observation,即实际频数;E代表Expectation,即期望频数。
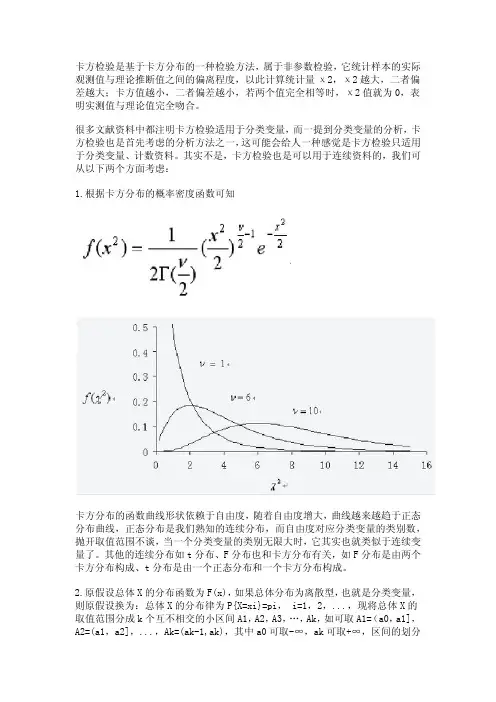
卡方检验是基于卡方分布的一种检验方法,属于非参数检验,它统计样本的实际观测值与理论推断值之间的偏离程度,以此计算统计量χ2,χ2越大,二者偏差越大;卡方值越小,二者偏差越小,若两个值完全相等时,χ2值就为0,表明实测值与理论值完全吻合。
很多文献资料中都注明卡方检验适用于分类变量,而一提到分类变量的分析,卡方检验也是首先考虑的分析方法之一,这可能会给人一种感觉是卡方检验只适用于分类变量、计数资料。
其实不是,卡方检验也是可以用于连续资料的,我们可从以下两个方面考虑:1.根据卡方分布的概率密度函数可知卡方分布的函数曲线形状依赖于自由度,随着自由度增大,曲线越来越趋于正态分布曲线,正态分布是我们熟知的连续分布,而自由度对应分类变量的类别数,抛开取值范围不谈,当一个分类变量的类别无限大时,它其实也就类似于连续变量了。
其他的连续分布如t分布、F分布也和卡方分布有关,如F分布是由两个卡方分布构成、t分布是由一个正态分布和一个卡方分布构成。
2.原假设总体X的分布函数为F(x),如果总体分布为离散型,也就是分类变量,则原假设换为:总体X的分布律为P{X=xi}=pi, i=1,2,...,现将总体X的取值范围分成k个互不相交的小区间A1,A2,A3,…,Ak,如可取A1=(a0,a1],A2=(a1,a2],...,Ak=(ak-1,ak),其中a0可取-∞,ak可取+∞,区间的划分视具体情况而定,但要使每个小区间所含的样本值个数不小于5,而区间个数k 不要太大也不要太小。
把落入第i个小区间的Ai的样本值的个数记作fi,成为组频数(真实值),所有组频数之和f1+f2+...+fk等于样本容量n。
当原假设为真时,根据其总体理论分布,可算出总体X的值落入第i个小区间Ai的概率pi,于是,npi就是落入第i个小区间Ai的样本值的理论频数(理论值)。
若原假设为真,则n次试验中样本值落入第i个小区间Ai的频率fi/n与概率pi 应很接近,若原假设不为真,则fi/n与pi相差很大。



非参数卡方检验1.理论非参数检验是在总体分布未知或知道甚少的情况下,不依赖于总体布形态,在总体分布情况不明时,用来检验不同样本是否来自同一总体的统计方法进。
由于非参数检验方法在推断过程中不涉及有关总体分布的参数,因而得名为“非参数”检验。
非参数检验优势:检验条件宽松,适应性强。
针对,非正态、方差不等的已及分布形态未知的数据均适用。
检验方法灵活,用途广泛。
运用符号检验、符号秩检验解决不能直接进行四则运算的定类和定序数据。
非参数检验的计算相对简单,易于理解。
但非参数检验方法对总体分布假定不多,缺乏针对性,且使用的是等级或符号秩,而不是实际数值,容易失去较多信息。
非参数卡方检验:用于检验样本数据的分布是否与某种特定分布情况相同。
非参数卡方检验通过三步检验:1.卡方统计量:X2=B 其中K 是样本分类的个数,0表示实际观测的频数,B 表示理论分布下的频数。
2.拟合优度检验:A.对总体分布建立假设。
B.抽样并编制频率分布表。
C.以原假设为真,导出期望频率。
D.计算统计量。
E.确定自由度,并查x2表,得到临界值。
F.比较x2值与临界值,做出判断。
3.独立性检验A.对总体分布建立假设。
B.抽样并编制r*c 列联表。
C.计算理论频数。
D.计算检验统计量。
E.确定自由度,并查x2表,得到临界值。
F.比较x2值与临界值,做出判断。
2.非参数卡方检验操作步骤第一步:将需检验的数据导入spss中并进行赋值后,点击分析非参数检验、旧对话框、卡方。
图2操作步骤第一步第二步:进入图中对话框后点击,首先将需检验的数据放入检验变量列表中,后在期望值选项中所以类别相等或者值(值:需要手动输入具体的分布情况)。
如果特殊情况需要调整检验置信区间,点击精确,进入图中下方对话框后点击蒙特卡洛法框里收到填入。
点击继续、确定。
图3操作步骤第二步第三步:如果需要看描述统计结果和四分位数值可以点击选项、勾选描述、四分位数。
点击继续、确实。
图4操作步骤第二步3.非参数卡方检验结果然后非参数卡方检验的描述统计、卡方检验频率表、检验统计结果就出来了。

r语言3组非参数检验非参数检验在统计学中是一种重要的方法,用于比较两组或多组数据是否具有显著性差异。
在R语言中,我们可以使用多种非参数检验方法来处理三组数据。
下面我们将介绍三种常用的非参数检验方法:卡方检验、配对卡方检验和Fisher确切概率法。
一、卡方检验卡方检验是一种用于比较两个或多个样本率或构成比是否显著的统计方法。
在R语言中,我们可以使用`chisq.test()`函数来进行卡方检验。
对于三组数据,我们可以将每两组的数据进行比较。
首先,我们需要将三组数据分别存储在三个向量中,例如:`group1`、`group2`和`group3`。
然后,我们可以使用以下代码进行卡方检验:```r#导入R语言自带的数据集data(mtcars)#将三组数据分别存储在向量中group1<-mtcars$mpggroup2<-mtcars$hpgroup3<-mtcars$drat#进行卡方检验chisq.test(cbind(group1,group2,group3))```上述代码将输出每组数据之间的卡方统计量和对应的p值。
如果p值小于预设的显著性水平(通常为0.05),则我们可以拒绝原假设,认为两组数据之间存在显著差异。
二、配对卡方检验配对卡方检验是一种用于比较两个配对样本是否具有相似性的统计方法。
在R语言中,我们可以使用`paired.test()`函数来进行配对卡方检验。
对于三组数据,我们可以将每两组的数据进行配对比较。
首先,我们需要将每两组的数据配对存储在一个矩阵或数据框中,例如:`df`。
然后,我们可以使用以下代码进行配对卡方检验:```r#创建示例数据框df<-data.frame(group1=c(1,2,3,4),group2=c(5,6,7,8),group3=c(9,10,11,12))#进行配对卡方检验paired.test(df)```上述代码将输出每组数据的配对样本之间的卡方统计量和对应的p值。




卡方检验与非参数检验卡方检验与非参数检验是统计学中常用的两种假设检验方法。
它们在样本数据不满足正态分布或方差齐性等假设条件的情况下,仍可以进行假设检验,因此被称为非参数检验方法。
本文将详细介绍卡方检验与非参数检验的原理、应用以及比较。
一、卡方检验卡方检验是一种用于检验两个或多个分类变量之间是否存在相关性的统计方法。
它将实际观察到的频数与期望的频数进行比较,从而判断两个分类变量是否存在相关性。
卡方检验主要包括卡方拟合度检验、卡方独立性检验和卡方配对检验等。
1.卡方拟合度检验卡方拟合度检验适用于比较观察到的频数与理论上期望的频数是否有显著差异。
例如,我们可以通过卡方拟合度检验来判断一组骰子的点数是否是均匀分布的。
该方法首先根据理论假设计算每个类别的期望频数,然后计算观察频数与期望频数的差异,并根据差异的大小判断是否有显著差异。
2.卡方独立性检验卡方独立性检验适用于比较两个分类变量之间是否存在相关性。
例如,我们可以使用卡方独立性检验来判断性别与喜好类别之间是否存在相关性。
该方法首先根据理论假设计算每个类别的期望频数,然后计算观察频数与期望频数的差异,并根据差异的大小判断是否有显著差异。
3.卡方配对检验卡方配对检验适用于比较同一组体在两个时间点或处理条件下的观测值是否有差异。
例如,我们可以使用卡方配对检验来判断一种药物在服药前后对疾病症状的治疗效果。
该方法通过比较观察值和期望值之间的差异来判断是否有显著差异。
非参数检验是一种不依赖于总体分布的统计方法,它不对总体的分布形态做出任何假设,因此适用于任何类型的数据。
常见的非参数检验方法包括Wilcoxon符号秩检验、Mann-Whitney U检验、Kruskal-Wallis H检验等。
1. Wilcoxon符号秩检验Wilcoxon符号秩检验适用于比较两组配对样本数据是否存在差异。
例如,我们可以使用Wilcoxon符号秩检验来判断一种药物在服药前后对患者血压的影响。
样本数据的分布检验方法1.参数检验参数检验是基于对总体参数的假设进行检验的方法。
它假定总体数据服从特定的分布,并且以该分布的参数进行统计推断。
常见的参数检验方法有正态分布检验和t检验。
正态分布检验:用于检验样本数据是否来自正态分布。
常用的正态分布检验方法有Kolmogorov-Smirnov检验、Shapiro-Wilk检验和Anderson-Darling检验等。
t检验:用于比较两个样本均值是否有显著差异。
常用的t检验包括单样本t检验、独立样本t检验和配对样本t检验等。
2.非参数检验非参数检验是不依赖总体分布形式的统计检验方法,适用于总体分布未知或不满足正态分布的情况。
这些方法使用的是样本数据的排序信息,而不是直接使用数据的具体值。
常见的非参数检验方法有Wilcoxon秩和检验、Kruskal-Wallis单因素方差分析、Mann-Whitney U检验和卡方检验等。
Wilcoxon秩和检验:用于比较两个相关样本的差异,通过对样本差值的秩和进行统计推断。
Kruskal-Wallis单因素方差分析:用于比较多个独立样本的差异,通过对各个样本的秩和进行统计推断。
Mann-Whitney U检验:用于比较两个独立样本的差异,通过对样本秩和进行统计推断。
卡方检验:用于比较观察值与理论值之间的偏离程度,适用于分类变量的比较。
除了参数检验和非参数检验,还有其他的分布检验方法,如拟合优度检验和残差分析等。
拟合优度检验:用于比较样本数据的分布是否与理论分布相吻合。
常用的拟合优度检验有卡方拟合优度检验和Kolmogorov-Smirnov拟合优度检验等。
在实际应用中,我们需要根据数据的特点和问题的需求来选择合适的分布检验方法。
需要注意的是,分布检验方法只能提供样本数据是否可能来自其中一特定分布或分布类型的判断,不能肯定地证明分布的真实性。
因此,在进行分布检验时,还需要综合考虑多个指标和实际情况,并结合领域知识来进行判断和分析。
检验三维列联表独立性非参数检验方法
三维列联表独立性非参数检验方法常用的是卡方检验。
卡方检验是一种用于分析分类资料的检验方法,常用于检验两个或多个分类变量之间是否存在关联。
对于三维列联表,如果变量之间独立,则行与列的分布应该是相互独立的。
卡方检验可以评估观察值与期望值之间的偏离程度,从而判断分类变量之间是否存在统计学上的显著差异。
进行卡方检验的步骤如下:
1. 建立原假设(H0)和备择假设(H1),其中原假设假设变量之间独立,备择假设则相反。
2. 计算观察频数与期望频数之间的差异,可以利用统计软件进行计算。
3. 计算卡方统计量,用于衡量观察频数与期望频数之间的差异程度。
4. 根据自由度和显著性水平,查找卡方分布的临界值。
5. 比较计算得到的卡方统计量与临界值,判断是否拒绝原假设。
需要注意的是,卡方检验的结果只能用于判断变量之间是否存在关联,不能确定具体的关联类型或者因果关系。