15个上市公司主要财务指标
- 格式:docx
- 大小:134.41 KB
- 文档页数:8

常用30个常用财务分析指标列表财务分析指标是通过对企业的财务数据进行计算和比较,评估其经营状况和财务稳定性的指标。
以下是常用的30个财务分析指标列表:1.总资产利润率(ROA):计算公司利用全部资产的盈利能力。
2.净利润率(ROE):衡量股东权益获得的回报率。
3.毛利润率:计算每单位销售额的毛利润。
4.负债比率:计算企业负债总额占总资产的比例。
5.流动比率:衡量企业用于偿付短期债务的流动资产能力。
6.速动比率:剔除库存后的流动资产比率。
7.资本周转率:评估企业利用资本进行营业活动的能力。
8.库存周转率:计算公司每年销售了多少次库存。
9.应收账款周转率:衡量企业向客户提供信贷额度的效率。
10.债务收益率:计算公司利润与借入资金之间的关系。
11.现金流量比率:衡量企业能否用现金偿付短期债务。
12.股东权益比率:计算股东权益的杠杆水平。
13.现金收入比率:计算现金流量与销售收入之间的关系。
14.经营现金流量比率:衡量企业经营活动所产生的现金流量。
15.长期负债比率:计算长期负债占全部资产的比例。
16.偿债能力比率:评估企业偿付债务的能力。
17.资本结构比率:衡量企业资本结构的合理性。
18.资本回报率:评估企业投资的回报率。
19.营运资本比率:衡量企业运营资金的效率。
20.每股现金流量:计算每股普通股权益中的现金流量。
21.销售增长率:评估公司销售额的增长速度。
22.股东权益增长率:计算股东权益的增长速度。
23.销售净利润率:计算每单位销售额的净利润率。
24.总资产增长率:评估公司总资产的增长速度。
25.经营性现金流量增长率:评估公司经营性现金流量的增长速度。
26.偿债能力增长率:计算企业偿付债务的能力的增长速度。
27.经营利润增长率:评估公司经营利润的增长速度。
28.总资本回报率:评估公司总资本的回报率。
29.现金流入比率:计算现金流入与销售收入之间的关系。
30.期间费用比率:计算公司期间费用与销售收入之间的比例。

十家上市公司的运营盈利、偿债和发展能力是了解一个公司的核心指标,可以通过分析这些指标来评估公司的财务状况和潜力。
以下是对十家上市公司的运营盈利、偿债和发展能力的分析。
首先,聚焦于运营盈利指标。
盈利能力是衡量一家公司赚取利润的能力,主要包括净利润、毛利率和净利润率等方面。
其次,偿债能力是判断公司有能力按时偿还债务的能力。
关键指标包括资产负债比率、流动比率和速动比率。
最后,发展能力指标能够揭示公司的成长潜力和市场表现。
重要指标包括营收增长率、资本回报率和市盈率等。
接下来具体分析:1.公司A在过去三年中,具有良好的运营盈利能力。
净利润保持稳定增长,毛利率和净利润率保持在同行业的较高水平。
2.公司B的运营盈利能力较强,净利润连续增长,毛利率高于同行业平均水平,净利润率也在上升。
3.公司C在过去三年中,运营盈利能力较一般,净利润增长缓慢,毛利率和净利润率相对较低。
4.公司D具有较强的偿债能力,资产负债比率保持在较低水平,流动比率和速动比率高于同行业平均水平。
5.公司E的偿债能力一般,资产负债比率持续上升,流动比率和速动比率低于同行业平均水平。
6.公司F在过去三年中,具有较为优秀的发展能力,营收增长率超过同行业平均增长率,资本回报率稳步增长,市盈率维持在较高水平。
7.公司G的发展能力较差,营收增长率低于同行业平均增长率,资本回报率下降,市盈率较低。
8.公司H的发展能力一般,营收增长率保持稳定,资本回报率较低,市盈率较高。
9.公司I在过去三年中,表现出较为出色的发展能力,营收增长率高于同行业平均增长率,资本回报率保持稳定,市盈率较高。
10.公司J的发展能力一般,营收增长率低于同行业平均增长率,资本回报率下降,市盈率较低。
总结起来,十家上市公司中有些公司在运营盈利、偿债和发展能力方面表现出色,如公司B、公司D和公司F。
而有些公司则显示出运营盈利和发展能力较弱的迹象,如公司C、公司G和公司J。
综合考虑这些指标可以帮助投资者更好地评估公司的财务状况和潜力,并做出相应的投资决策。

上市公司财务指标在股市投资中,了解和分析上市公司的财务指标是非常重要的。
财务指标可以提供关于公司财务状况和经营绩效的关键信息,帮助投资者做出明智的投资决策。
本文将介绍几个常见的上市公司财务指标,并解释它们的意义和用途。
1. 资产负债率(Asset-Liability Ratio)资产负债率是一个衡量公司债务水平的指标,它反映了公司使用债权人资金相对于股权人资金的比例。
资产负债率越高,意味着公司使用了更多的债务融资,风险可能更高。
然而,如果资产负债率过低,也可能意味着公司没有充分利用债务资金的潜力。
投资者通常希望看到一个合理的资产负债率,既能保证公司的稳定性,又能最大限度地利用债务资金的优势。
2. 流动比率(Current Ratio)流动比率是一个衡量公司偿债能力的指标,它比较了公司流动资产与流动负债之间的关系。
流动比率越高,意味着公司具有更强的偿债能力,能够更容易地偿还到期债务。
然而,如果流动比率过高,可能表明公司资金未充分利用,而是闲置在流动资产中。
投资者通常希望看到一个适度的流动比率,既能保证公司的稳定,又能最大限度地利用现金流。
3. 净利润率(Net Profit Margin)净利润率是一个衡量公司盈利能力的指标,它表示每一销售额的利润占比。
净利润率越高,意味着公司能够以较高的效率将销售额转化为利润。
然而,净利润率过低可能表明公司的经营成本过高或销售收入不足。
投资者通常希望看到一个稳定且相对较高的净利润率,以确保公司具有良好的盈利能力。
4. 市盈率(Price-Earnings Ratio)市盈率是一个衡量公司股价相对于每股盈利的指标,它表示投资者愿意为每一单位盈利支付多少倍的股价。
市盈率越高,意味着投资者对公司未来的盈利增长有更高的期望值。
然而,市盈率过高可能意味着市场过度投资,使得股价可能过度膨胀。
投资者通常需要比较市盈率与行业平均值或相似公司的市盈率来评估公司的估值水平。
5. 股息收益率(Dividend Yield)股息收益率是一个衡量公司每股股息相对于股票当前价格的指标,它表示投资者每年可获得的股息收益占投资金额的比例。

上市公司主要财务主标分析一:每股收益每股收益(Earning Per Share,简称EPS),又称每股税后利润、每股盈余,指税后利润与股本总数的比率。
它是测定股票投资价值的重要指标之一,是分析每股价值的一个基础性指标,是综合反映公司获利能力的重要指标,它是公司某一时期净收益与股份数的比率。
该比率反映了每股创造的税后利润, 比率越高, 表明所创造的利润越多。
若公司只有普通股时,净收益是税后净利,股份数是指流通在外的普通股股数。
如果公司还有优先股,应从税后净利中扣除分派给优先股东的利息。
每股收益=利润/总股数并不是每股盈利越高越好,因为每股有股价利润100W,股数100W股10元/股,总资产1000W利润率=100/1000*100%=10%每股收益=100W/100W=1元利润100W,股数50W股40元/股,总资产2000W利润率=100/2000*100%=5%每股收益=100W/50W=2元传统的每股收益指标计算公式为:每股收益=(本期净利润- 优先股股利)/期末流通在外的普通股股一般的投资者在使用该财务指标时有以下几种方式:一、通过每股收益指标排序,是用来寻找所谓“绩优股”和“垃圾股”;二、横向比较同行业的每股收益来选择龙头企业;三、纵向比较个股的每股收益来判断该公司的成长性。
每股收益仅仅代表的是某年每股的收益情况,基本不具备延续性,因此不能够将它单独作为作为判断公司成长性的指标。
我国的上市公司很少分红利,大多数时候是送股,同时为了融资会选择增发和配股或者发行可转换公司债券,所有这些行为均会改变总股本。
由每股收益的计算公式我们可以看出,如果总股本发生变化每股收益也会发生相反的变化。
这个时候我们再纵向比较每股收益的增长率你会发现,很多公司都没有很高的增长率,甚至是负增长。
G宇通就是这样的典型代表。
每股收益在逐年递减的同时,净利润却一直保持在以10%以上的增长率。
二:基本每股收益股份公司中的每股利润(Earnings Per Share,缩写EPS)是指普通股每股税后利润。

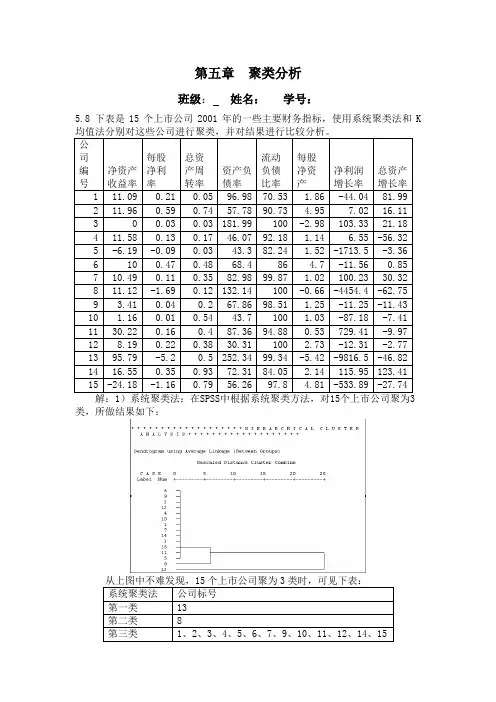
题目:下表是15个上市公司2001年的一些主要财务指标,使用系统聚类法和K-均值法分别对这些公司进行聚类,并对结果进行比较分析。
解:令净资产收益率为X1,每股净利润X2,总资产周转率为X3,资产负债率为X4,流动负债比率为X5,每股净资产为X6,净利润增长率为X7,总资产增长率为X8,用spss对公司聚类分析的步骤如下:a)系统聚类法:1. 在SPSS窗口中选择Analyze→Classify→Hierachical Cluster,调出系统聚类分析主界面,并将变量X8-X1移入Variables框中。
在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择V ariables,则对变量进行聚类)。
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
2.点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。
我们选择Agglomeration schedule与Cluster Membership中的Range of solution 2-4,如图5.2所示,点击Continue按钮,返回主界面。
(其中,Agglomeration schedule表示在结果中给出聚类过程表,显示系统聚类的详细步骤;Proximity matrix 表示输出各个体之间的距离矩阵;Cluster Membership 表示在结果中输出一个表,表中显示每个个体被分配到的类别,Range of solution 2-4即将所有个体分为2至4类。
)3.点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。
选中Dendrogram 复选框和Icicle栏中的None单选按钮,如图5.3,即只给出聚类树形图,而不给出冰柱图。
单击Continue按钮,返回主界面。
4.点击Method按钮,设置系统聚类的方法选项。
Cluster Method下拉列表用于指定聚类的方法,这里选择Between-group inkage(组间平均数连接距离);Measure栏用于选择对距离和相似性的测度方法,选择Squared Euclidean distance(欧氏距离);单击Continue按钮,返回主界面。

引言:财务分析是企业管理和投资决策中不可或缺的重要工具。
在上一篇文章中,我们已经介绍了财务分析的前五个基本指标,本文将继续探讨接下来的十个基本指标,帮助投资者和企业管理者更全面地评估公司的财务状况。
概述:正文内容:1. 资产负债率资产负债率是用来衡量公司资产负债状况的指标,计算公式为:负债总额/资产总额。
较低的资产负债率意味着公司负债相对较少,更稳健,具有更好的偿债能力。
在不同行业中,合适的资产负债率可能会有所不同。
2. 权益乘数权益乘数是用来衡量公司资金杠杆使用情况的指标,计算公式为:资产总额/净资产总额。
较高的权益乘数表示公司使用了较高比例的债务融资,可能会增加财务风险,需要进一步评估公司的偿债能力。
3. 流动比率流动比率是用来衡量公司短期偿债能力的指标,计算公式为:流动资产/流动负债。
较高的流动比率表示公司具有更好的偿债能力,可以及时偿付到期债务。
4. 速动比率速动比率是用来衡量公司短期偿债能力的指标,计算公式为:(流动资产-存货)/流动负债。
速动比率剔除了存货,更加准确地评估公司能够迅速偿还到期债务的能力。
5. 存货周转率存货周转率是用来衡量公司存货资产利用效率的指标,计算公式为:销售成本/平均存货。
较高的存货周转率表示公司能够有效地管理和利用存货资产,减少滞销和过期存货的风险。
6. 应收账款周转率应收账款周转率是用来衡量公司应收账款管理和收款效率的指标,计算公式为:销售收入/平均应收账款。
较高的应收账款周转率表示公司能够及时收回应收账款,减少坏账风险。
7. 应付账款周转率应付账款周转率是用来衡量公司应付账款管理和付款效率的指标,计算公式为:采购成本/平均应付账款。
较高的应付账款周转率表示公司能够及时支付应付账款,维护良好的供应商关系。
8. 总资产周转率总资产周转率是用来衡量公司总资产的利用效率的指标,计算公式为:销售收入/平均总资产。
较高的总资产周转率表示公司能够有效地利用资产产生销售收入。

本文由梁老师精心编辑整理(营改增后知识点),学知识,抓紧了!
上市公司主要财务指标解释、分析
一:每股收益
每股收益(EarningPerShare,简称EPS),又称每股税后利润、每股盈余,指税后利润与股本总数的比率。
它是测定股票投资价值的重要指标之一,是分析每股价值的一个基础性指标,是综合反映公司获利能力的重要指标,它是公司某一时期净收益与股份数的比率。
该比率反映了每股创造的税后利润,比率越高,表明所创造的利润越多。
若公司只有普通股时,净收益是税后净利,股份数是指流通在外的普通股股数。
如果公司还有优先股,应从税后净利中扣除分派给优先股东的利息。
每股收益=利润/总股数
并不是每股盈利越高越好,因为每股有股价。
传统的每股收益指标计算公式为:
每股收益=(本期净利润-优先股股利)/期末流通在外的普通股股
一般的投资者在使用该财务指标时有以下几种方式:
一、通过每股收益指标排序,是用来寻找所谓“绩优股”和“垃圾股”;
二、横向比较同行业的每股收益来选择龙头企业;
三、纵向比较个股的每股收益来判断该公司的成长性。
每股收益仅仅代表的是某年每股的收益情况,基本不具备延续性,因此不能够将它单独作为作为判断公司成长性的指标。
我国的上市公司很少分红利,大多数时候是送股,同时为了融资会选择增发和配股或者发行可转换公司债券,所有这些行为均会改变
1。
第五章聚类分析
班级:姓名:学号:
5.8 下表是15个上市公司2001年的一些主要财务指标,使用系统聚类法和K
类,所做结果如下:
2)K均值法:在SPSS4类,所做结果如下:
公司分为3类时,分类相同。
5.9 下表是某年我国16个地区农民支出情况的抽样调差数据,每个地区调查了反应每个人平局生活消费支出情况的六个经济指标,试通过统计分析软件用不同
择了以下四个方法,进行系统聚类分析,将16个地区分为4类: 1)组间连接法:
3)最近距离法:
4)最远距离法:
类,但是结果不同。
5.10 根据上题数据通过SPSS 统计分析软件进行快速聚类运算,并与系统聚类分析结果进行比较。
解:K 均值法:在SPSS 中根据K 均值法法,对16个城市为4类,所做结果如下:
出水平较接近,天津、辽宁、吉林等城市农民支出水平较接近。
5.11 表是2003年我国省会城市和计价单列市的主要经济指标:人均GDPX1(元)、人均工业产值X2(元)、客运总量X3(万人)、货运总量X4(万吨)、地方财政预算内收入X5(亿元)、固定资产投资总额X6(亿元)、在岗职工占总人口的比例X7(%)、在岗职工人均收入X8(元)、城乡居民年底储蓄余额X9(亿元)。
试通统计分析软件进行系统聚类分析,并比较何种方法与人们观察到得实际情况较接
37个城市分为3类:
1)组间连接法:
由上可以看出,将37个城市根据农民支出聚为3类时,可见下表
由上可以看出,应用组间连接法将37个城市根据农民支出聚为3类时,可见
由上可以看出,应用组内连接法将16个城市根据农民支出聚为3类时,可见
解:。

引言概述:财务分析是企业经营管理中的重要环节,它用来评估和分析企业的财务状况和经营能力。
在财务分析中,基本指标是评估企业财务状况最常用的工具之一。
本文将深入探讨财务分析中的15个基本指标,包括资产负债率、流动比率、速动比率、应收账款周转率、应付账款周转率、总资产周转率、资产周转率、利润率、净利润率、成本费用利润率、应收账款占营业收入比例、流动资产周转率、应付账款占营业成本比例、现金比率、现金流量比率。
1.资产负债率资产负债率是衡量企业财务风险和偿债能力的指标之一。
它表示企业资产通过负债融资的比例。
高资产负债率表明企业存在较高的财务风险,而低资产负债率则表明企业较稳健。
2.流动比率流动比率是衡量企业短期偿债能力的指标。
它表示企业流动资产能否足够偿还流动负债。
流动比率越高,表明企业具备更强的偿债能力。
3.速动比率速动比率是衡量企业真实偿债能力的指标。
它去除了存货后,仅考虑与流动负债有关的资产。
速动比率更接近1表明企业偿债能力更强。
4.应收账款周转率应收账款周转率反映企业收取应收账款的效率。
它表示企业销售收入与平均应收账款的关系。
较高的应收账款周转率表明企业能够更快速地收回应收账款,从而改善流动资金状况。
5.应付账款周转率应付账款周转率衡量企业支付应付账款的效率。
它表示企业采购成本与平均应付账款的关系。
较高的应付账款周转率表明企业能够更长时间地推迟支付应付账款,从而延长资金周转周期。
6.总资产周转率总资产周转率是衡量企业资产利用效率的指标。
它表示企业销售收入与平均总资产的关系。
较高的总资产周转率表明企业能更好地利用资产实现销售收入。
7.资产周转率资产周转率是衡量企业固定资产利用效率的指标。
它表示企业销售收入与平均固定资产的关系。
较高的资产周转率表明企业能更好地利用固定资产实现销售收入。
8.利润率利润率是衡量企业盈利能力的指标。
它表示净利润与销售收入的比例。
较高的利润率表明企业盈利能力较强。
9.净利润率净利润率是衡量企业净利润与销售收入的比例。

上市公司财务指标第一,盈利能力指标。
盈利能力是衡量上市公司利润水平和经营能力的重要指标。
常用的盈利能力指标包括销售净利润率、毛利率和净资产收益率等。
销售净利润率是净利润与营业收入的比率,反映了企业在利润上的获得能力。
毛利率是销售毛利与销售收入的比率,反映了企业在产品或服务的生产过程中的盈利能力。
净资产收益率是净利润与净资产的比率,反映了上市公司利润分配给股东的能力。
通过对这些指标的分析,投资者能够判断上市公司的盈利情况和盈利能力是否可持续。
第二,财务结构指标。
财务结构是指上市公司在资本结构上的组成和比例。
常用的财务结构指标包括资产负债率、长期负债与股东权益比例等。
资产负债率是总负债与总资产的比率,反映了上市公司使用债务融资的程度。
长期负债与股东权益比例是长期负债与股东权益的比率,反映了上市公司负债与股东权益之间的比例关系。
通过对这些指标的比较,投资者可以了解上市公司的财务风险和财务稳定性。
第三,运营能力指标。
运营能力是衡量上市公司经营管理水平和运营效率的重要指标。
常用的运营能力指标包括存货周转率、账款周转率和总资产周转率等。
存货周转率是销售成本与平均存货的比率,反映了企业存货的周转速度。
账款周转率是销售收入与平均应收账款的比率,反映了企业收款能力和风险。
总资产周转率是销售收入与平均总资产的比率,反映了上市公司利用资产运营的效率。
通过对这些指标的分析,投资者可以了解上市公司的运营效率和运营质量。
第四,市场竞争力指标。
市场竞争力是指上市公司在市场中的地位和竞争优势。
常用的市场竞争力指标包括市盈率、市净率和市销率等。
市盈率是市值与净利润的比率,反映了投资者对上市公司未来盈利的期望和预期。
市净率是市值与净资产的比率,反映了投资者对上市公司资产质量和价值的认可。
市销率是市值与营业收入的比率,反映了投资者对上市公司销售能力和成长潜力的估计。
通过对这些指标的比较,投资者可以评估上市公司的投资价值和竞争优势。
总之,上市公司财务指标是评估上市公司财务状况和业绩的重要工具。
教你看上市公司财务指标上市公司的财务指标是衡量公司经营状况和财务健康的重要工具。
投资者和分析师可以通过分析这些指标来评估公司的风险和回报潜力。
本文将介绍几个常见的上市公司财务指标,并解释它们的意义和如何应用。
1.资产负债表指标:-总资产:反映公司所有资产的总值,包括流动资产和固定资产。
这个指标可以告诉我们公司的规模和资本投入。
-总负债:表示公司的债务总额,包括短期债务和长期债务。
该指标可以显示公司的财务稳定性和风险承担能力。
-股东权益:等于总资产减去总负债,是所有者的投资价值。
这个指标可以告诉我们公司的净值。
2.利润表指标:-营业收入:表示公司从经营活动中获得的总收入。
这个指标可以显示公司的销售能力和市场份额。
-净利润:表示公司经营活动后的盈利金额,是计算公司盈亏的核心指标。
这个指标可以衡量公司的盈利能力和效率。
-毛利率:等于营业收入减去销售成本后的利润与营业收入的比率。
这个指标可以揭示公司产品销售的盈利潜力。
3.现金流量表指标:-经营活动现金流量:表示公司经营活动的现金流入和流出情况。
这个指标可以告诉我们公司的经营活动是否盈利并有足够的现金流。
-投资活动现金流量:表示公司投资活动的现金流入和流出情况。
这个指标可以显示公司进行重大投资或出售资产的能力。
-筹资活动现金流量:表示公司筹资活动的现金流入和流出情况。
这个指标可以显示公司从债务和股权融资中获得的资金数量。
4.盈利能力指标:-每股收益(EPS):表示每股普通股份的盈利金额。
这个指标可以帮助投资者评估公司在每股投资上的回报。
-毛利率和净利率:已在利润表指标中解释,可以显示公司产品销售的盈利潜力。
-资产回报率(ROA)和股东权益回报率(ROE):分别表示公司利润与总资产和股东权益的比率。
这些指标可以告诉我们公司有效利用资产和股东投资的能力。
以上仅为常见的财务指标,每个行业可能会有特定的指标用于衡量财务状况。
投资者和分析师应该结合行业特点选择适当的指标进行分析。
上市公司财务分析的关键指标
一、营运状况指标
2.营业成本:营业成本是指公司经营活动产生的原材料、劳务成本,尤其是能量、材料和加工劳务等所造成的实际费用,是影响公司盈利运营能力最重要的成本指标。
3.营业利润:营业利润是指公司在营业收入中扣除营业成本后所剩余的收入,反映公司营业状况的关键指标。
4.三项费用比重:三项费用比重指的是公司的销售费用、管理费用和财务费用,三项费用比重是衡量公司财务管理能力和有效利用费用的重要指标。
二、盈利能力指标
1.总资产报酬率:总资产报酬率是指公司在一定会计期间内,所有资产获得报酬的百分比,是量化衡量公司财务状况最佳指标之一
2.营业利润率:营业利润率反映公司的经营能力,由于公司的生产成本和产品价格的变化,其变化幅度比营业利润更大,它可反映公司的经营状况。
3.净资产收益率:净资产收益率是指公司每一元股东权益带来的资产收益,是衡量公司资源使用效率最重要的指标之一
4.毛利率:毛利率是指营业收入中营业成本占比。
15个行业财务指标参考值在以下部分中,将列举出15个常见的行业财务指标的参考值。
这些指标可以帮助评估公司或企业的财务状况、盈利能力和偿债能力。
需要注意的是,这些参考值的适用性会根据不同行业的特点和经济环境的变化而有所不同。
1. 企业利润率(Profit Margin):通常以百分比形式表示,计算公司净利润与总营业收入之间的比率。
通常,高于20%的利润率被认为是良好的表现,但也可能因行业而异。
2. 资产负债率(Debt-to-Asset Ratio):将公司的总债务与总资产之间的比率。
通常认为,低于50%的资产负债率是健康的。
3. 毛利率(Gross Margin):计算公司销售商品或提供服务的收入与相关成本之间的比率。
一般来说,高于30%的毛利率被认为是良好的。
4. 当期比率(Current Ratio):用于评估企业的流动性,即企业可用于偿还短期债务的流动资产与当前债务之间的比率。
一般而言,高于2的当期比率被认为是健康的。
5. 速动比率(Quick Ratio):类似于当期比率,但排除了存货对流动资产的影响。
一般来说,高于1的速动比率被认为是有利的。
6. 应收账款周转率(Accounts Receivable Turnover):衡量公司销售和收款的效率。
该指标计算公司在一定时间内收回欠款的次数。
高于6的周转率被视为一项良好的指标。
7. 存货周转率(Inventory Turnover):衡量公司有效管理存货的能力。
此指标显示公司在一定时间范围内销售存货的次数。
高于4的周转率被视为良好。
8. 总资本回报率(Return on Total Capital):计算公司净利润与总资本(股东资本和借款资金)之间的比率。
一般来说,高于10%的回报率被视为可接受的。
9. 预收账款比率(Prepaid Expense Ratio):衡量公司预付账款和费用的比率。
此指标用于评估公司的流动资金管理能力。
10. 营业利润率(Operating Profit Margin):计算公司销售商品或提供服务的收入扣除经营费用后的利润与总营业收入之间的比率。
上市公司财务指标汇总上市公司的财务指标是评估公司财务状况的重要工具,可以帮助投资者和分析师判断公司的盈利能力、偿债能力、运营能力以及价值水平。
下面是一些常见的上市公司财务指标汇总:1.盈利能力指标:-每股收益(EPS):公司每股盈利的金额。
-毛利率:公司销售商品或提供服务所获得的毛利润与销售收入的比率。
-净利率:公司净利润与销售收入的比率。
-总资产净利率:公司净利润与总资产的比率。
-ROE(净资产收益率):公司净利润与股东权益的比率。
2.偿债能力指标:-负债比率:公司负债总额与总资产的比率。
-流动比率:公司流动资产与流动负债的比率。
-速动比率:公司流动资产减去存货后,再与流动负债的比率。
-利息保障倍数:公司税前利润与利息费用的比率,用于评估公司偿付利息的能力。
3.运营能力指标:-库存周转率:公司销售成本与平均库存的比率。
-应收账款周转率:公司销售收入与平均应收账款的比率。
-资产周转率:公司销售收入与平均总资产的比率。
-现金流量比率:公司现金流量与净利润的比率,用于评估公司的现金生成能力。
4.价值水平指标:-市盈率(PE):公司股价与每股盈利的比率,用于评估公司的投资回报率。
-市净率(PB):公司股价与每股净资产的比率,用于评估公司的价值水平。
-净资产收益率(ROA):公司净利润与净资产的比率。
除了以上列举的指标外,还有一些与行业特点相关的财务指标,如营业收入增长率、净利润增长率、资产负债率增长率等。
需要注意的是,财务指标只是评估公司财务状况的一部分工具,投资者和分析师在进行投资决策时还应综合考虑公司的经营模式、行业前景、市场竞争等因素。
此外,财务指标的解读也需要结合公司历史数据和行业平均水平进行比较,以更准确地评估公司的运营状况。
总结起来,上市公司的财务指标汇总包括盈利能力指标、偿债能力指标、运营能力指标和价值水平指标。
这些指标能够提供关于公司盈利能力、偿债能力、运营能力和价值水平的重要信息,帮助投资者和分析师评估公司的财务状况和投资价值。
上市公司三个重要财务指标的
1.利润率指标:
利润率是指公司实现营业收入后,所获得的利润占营业收入的比例。
利润率可以分为净利润率、毛利润率和营业利润率等多个类型。
其中,净利润率是最常用的评估指标之一、计算净利润率的公式是:净利润率=净利润/营业收入*100%。
利润率指标可以反映公司经营效益和盈利能力,较高的利润率通常意味着更好的财务状况。
2.偿债能力指标:
偿债能力是指公司清偿债务的能力,也是投资者和债权人关注的重要指标之一、常用的偿债能力指标包括流动比率、速动比率和负债率等。
流动比率指标是用来衡量公司的流动性状况,计算公式是:流动比率=流动资产/流动负债。
速动比率是流动比率的一种更严格的计算方式,计算公式是:速动比率=(流动资产-存货)/流动负债。
负债率指标是用来衡量公司资产负债结构,计算公式是:负债率=总负债/总资产*100%。
较高的流动比率、速动比率和较低的负债率通常意味着公司具有较好的偿债能力。
3.市盈率指标:
市盈率是衡量公司股票价格相对于每股盈利的指标。
计算市盈率的公式是:市盈率=市值/净利润。
市盈率可以反映公司的投资价值和投资回报率。
较低的市盈率通常是价值投资者的关注点,因为较低的市盈率可能意味着公司的股价被低估,而较高的市盈率可能是成长投资者的关注点,因为较高的市盈率可能意味着公司具有较高的增长潜力。
除了这三个重要的财务指标之外,还有其他一些指标如资本回报率、股息收益率、净资产收益率等也是评估上市公司财务状况的重要指标。
不
同的指标可以提供不同的信息,综合考虑多个指标可以更全面地评估上市公司的财务状况和经营水平。
上市公司财务指标(精华)(一)引言:上市公司的财务指标是评估和衡量其财务健康状况的重要参考依据。
本文将介绍上市公司财务指标的精华内容,帮助读者更好地理解和运用这些指标。
一、盈利能力指标1.1 营业收入:反映公司销售业务的总收入。
1.2 净利润:表示扣除营业成本和费用后的利润额。
1.3 毛利率:计算方法为(营业收入-营业成本)/营业收入,反映出产品或服务的盈利能力。
1.4 净利率:计算方法为净利润/营业收入,衡量公司在销售过程中的净利润水平。
1.5 利润增长率:用于评估公司盈利能力的增长情况。
二、偿债能力指标2.1 资产负债率:计算方法为总负债/总资产,衡量公司利用借来的资金进行投资的能力和风险承受能力。
2.2 流动比率:计算方法为流动资产/流动负债,衡量公司短期债务偿付能力。
2.3 速动比率:计算方法为(流动资产-存货)/流动负债,排除了存货,以更准确地衡量公司的偿债能力。
2.4 利息保障倍数:计算方法为(利润总额+利息费用)/利息费用,衡量公司偿付利息的能力。
2.5 现金比率:计算方法为现金/流动负债,衡量公司应对突发流动性需求的能力。
三、运营能力指标3.1 应收账款周转率:计算方法为营业收入/平均应收账款,衡量公司收回应收账款的速度。
3.2 存货周转率:计算方法为营业成本/平均存货,反映公司存货的周转速度。
3.3 总资产周转率:计算方法为营业收入/平均总资产,反映公司资产的利用效率。
3.4 存货占比:计算方法为存货/总资产,衡量存货在资产中的比重。
3.5 应付账款周转率:计算方法为营业成本/平均应付账款,衡量公司支付应付账款的速度。
四、投资价值指标4.1 市盈率:计算方法为市价/每股收益,衡量投资者购买一股公司股票所需付出的价格。
4.2 市净率:计算方法为市值/净资产,衡量投资者购买一股公司股票时所付出的溢价。
4.3 股息率:计算方法为每股股息/股票市价,衡量公司派发给股东的股息相对于股票市价的比率。
题目:下表是15个上市公司2001年的一些主要财务指标,使用系统聚类法和K-均值法分别对这些公司进行聚类,并对结果进行比较分析。
解:令净资产收益率为X1,每股净利润X2,总资产周转率为X3,资产负债率为X4,流动负债比率为X5,每股净资产为X6,净利润增长率为X7,总资产增长率为X8,用spss对公司聚类分析的步骤如下:
a)系统聚类法:
1. 在SPSS窗口中选择Analyze宀Classify宀Hierachical Cluster,调出系统聚类分析主界面,并将变量X8-X1移入Variables框中。
在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。
在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。
图5.1糸统分析迭王界面
2•点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。
我们选择Agglomeration schedule 与Cluster Membership 中的Range of solution 2-4,如图5.2 所示,点击Continue按钮,返回主界面。
(其中,Agglomeration schedule表示在结果中给出聚类过
程表,显示系统聚类的详细步骤;Proximity matrix表示输出各个体之间的距离矩阵;Cluster Membership表示在结果中输出一个表,表中显示每个个体被分配到的类别,Range of solution 2-4即将所有个体分为2至4类。
)
3.点击Plots按钮,设置结果输出窗口中给出的聚类分析统计图。
选中Dendrogram复选框
和Icicle栏中的None单选按钮,如图5.3,即只给出聚类树形图,而不给出冰柱图。
单击Continue按钮,返回主界面。
蠹Hinrarchicdl ClLrst»r Analyte 应d
Singh1
CanCTi
图5.2 Statistics子对话框图5.3 Plots子对话框
4•点击Method 按钮,设置系统聚类的方法选项。
Cluster Method 下拉列表用于指定 聚类的
方法,这里选择 Between-group inkage (组间平均数连接距离); Measure 栏 用于选择对距
离和相似性的测度方法,选择 Squared Euclidean distanee (欧氏距离);单击 Continue 按钮, 返
回主界面。
S HlfrjrchkilClwrtff Arulysit : bffthod
图5.4 Method 子对话框 图5.5 Save 子对话框
5•点击Save 按钮,指定保存在数据文件中的用于表明聚类结果的新变量。
None 表示不保
存任何新变量;Single solution 表示生成一个分类变量,在其后的矩形框中输入要分成的类
数;Range of solutions 表示生成多个分类变量。
这里我们选择
Range of solutions ,并在后面
的两个矩形框中分别输入 2和4,即生成三个新的分类变量,分别表明将样品分为 2类、3
类和4类时的聚类结果,如图5.5。
点击Continue ,返回主界面。
6•点击0K 按钮,运行系统聚类过程。
聚类结果分析:
下面的群集成员表给出了把公司分为 2类,3类,4类时各个样本所属类别的情况,另外, 从右边的树形图也可以直观地看到,
若将15个公司分为2类,则13独自为一类,其余的为
一类;若分为3类,则公司8分离出来,自成一类。
以此类推。
表 5.1各样品所属类别表
Cluster Membership
Case 4 Clusters
3 Clusters
2 Clusters
1 1 1 1
2 1 1 1
3 1 1 1
4 1 1 1
5 2 1 1
6 1 1 1 7
1
1
1
Ortm* Ctficql
〔3」
rli 6
二 qpngegp
to ()^1 r«ngc-
* * * * * * * * * * * * * * * * * * * H i E R A R C H I C A L c L U S T E R
*******************
Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25
Label Num + ---------- + -------- +-------- + -------- + -------- +
61
9T
2T
12T
4T
10T
1T
7T
14T
3T
15-4
11T
5__ 1
8
13
图5.6聚类树形图
b ) K 均值法:
1.在SPSS 窗口中选择 Analyze f Classify f K-Means Cluster ,调出K 均值聚类分析主界 面,
并将变量 X1-X8移入 Variables 框中。
在 Method 框中选择Iterate classify ,即使用 K-means 算法不
断计算新的类中心,并替换旧的类中心(若选择 Classify only ,则根据初始类中心进
行聚类,在聚类过程中不改变类中心) 。
在Number of Cluster 后面的矩形框中输入想要把样
品聚成的类数,这里我们输入
3,即将15个公司分为3类。
(Centers 按钮,则用于设置
迭代的初始类中心。
如果不手工设置,则系统会自动设置初始类中心,
这里我们不作设置。
)
E 5 - K 均值聚类分析王界面
2. 点击Iterate 按钮,对迭代参数进行设置。
Maximum Iterations 参数框用于设定 K-means
算法迭代的最大次数,输入 10,Convergence Criterion 参数框用于设定算法的收敛判据,输
入0,只要在迭代的过程中先满足了其中的参数,则迭代过程就停止。
单击
Continue ,返回
主界面。
3.
点击Save 按钮,设置保存在数据文件中的表明聚类结果的新变量。
我们将两个复 选框都
选中,其中Cluster membership 选项用于建立一个代表聚类结果的变量,默
认变量名为
qcl_1 ; Distanee from cluster center 选项建立一个新变量,代表各观测量与其所属类中心的欧
氏距
图 5,8 Iterate 对话框
:Iterate
翳5.9 Save 子对话框
图5.10 OptioiK 子对话框
离。
单击Continue按钮返回。
4. 点击Optio ns 按钮,指定要计算的统计量。
选中In itial cluster cen ters 和Cluster in formation for each case复选框。
这样,在输出窗口中将给出聚类的初始类中心和每个公司的分类信息,包括分配到哪一类和该公司距所属类中心的距离。
单击Continue返回。
5. 点击OK按钮,运行K均值聚类分析程序。
K均值聚类结果分析:
以下三表给出了各公司所属的类及其与所属类中心的距离,聚类形成的类的中心的各变量值
以及各类的公司数。
由以上表格可得公司13与公司8各自成一类,其余的公司为一类。
通过比较可知,两种聚类方法得到的聚类结果完全一致。
表K-1聚类成员
表K-2每个聚类中的案例数
Number of Cases in each
表K-3最终聚类中心。