第十章 卡方检验..
- 格式:doc
- 大小:353.00 KB
- 文档页数:12

现代心理与教育统计学(张厚粲)课后习题答案第一章绪论(略)第二章统计图表(略)第三章集中量数4、平均数约为36.14;中位数约为36.635、总平均数为91.726、平均联想速度为5.27、平均增加率约为11%;10年后的毕业人数约有3180人8、次数分布表的平均数约为177.6;中位数约为177.5;原始数据的平均数约为176.7第四章差异量数5、标准差约为1.37;平均数约为1.196、标准差为26.3;四分位差为16.037、5cm组的差异比10cm组的离散程度大8、各班成绩的总标准差是6.039、次数分布表的标准差约为11.82;第一四分位为42.89;第三四分位为58.41;四分位差为7.76第五章相关关系5、应该用肯德尔W系数。
6、r=0.8;r R=0.79;这份资料只有10对数据,积差相关的适用条件是有30对以上数据,因此这份资料适用等级相关更合适。
7、这两列变量的等级相关系数为0.97。
8、上表中成绩与性别有很强的相关,相关系数为0.83。
9、r b=0.069小于0.2.成绩A与成绩B的相关很小,成绩A与成绩B的变化几乎没有关系。
10、测验成绩与教师评定之间有一致性,相关系数为0.87。
11、9名被试的等级评定具有中等强度的相关,相关系数为0.48。
12、肯德尔一致性叙述为0.31。
第六章概率分布4、抽得男生的概率是0.355、出现相同点数的概率是0.1676、抽一黑球与一白球的概率是0.24;两次皆是白球与黑球的概率分别是0.36和0.167、抽一张K的概率是4/54=0.074;抽一张梅花的概率是13/54=0.241;抽一张红桃的概率是13/54=0.241;抽一张黑桃的概率是13/54=0.241;抽不是J、Q、K的黑桃的概率是10/54=0.1858、两个正面,两个反面的概率p=6/16=0.375;四个正面的概率p=1/16=0.0625;三个反面的概率p=4/16=0.25;四个正面或三个反面的概率p=0.3125;连续掷两次无一正面的概率p=0.18759、二项分布的平均数是5,标准差是210、(1)Z≥1.5,P=0.5-0.43=0.07(2)Z≤1.5,P=0.5-0.43=0.07(3)-1.5≤Z≤1.5,p=0.43+0.43=0.86(4)p=0.78,Z=0.77,Y=0.30(5)p=0.23,Z=0.61,Y=0.33(6)1.85≤Z≤2.10,p=0.482—0.467=0.01511、(1)P=0.35,Z=1.04(2)P=0.05,Z=0.13(3)P=0.15,Z=-0.39(4)P=0.077,Z=-0.19(5)P=0.406,Z=-1.3212、(1)P=0.36,Z=-1.08(2)P=0.12,Z=0.31(3)P=0.125,Z=-0.32(4)P=0.082,Z=-0.21(5)P=0.229,Z=0.6113、各等级人数为23,136,341,341,136,2314、T分数为:73.3、68.5、64.8、60.8、57、53.3、48.5、46.4、38.2、29.515、三次6点向上的概率为0.054,三次以上6点向上的概率为0.06316、回答对33道题才能说是真会不是猜测17、答对5至10到题的概率是0.002,无法确定答对题数的平均数18、说对了5个才能说看清了而不是猜对的19、答对5题的概率是0.015;至少答对8题的概率为0.1220、至少10人被录取的概率为0.1821、(1)t0.05=2.060,t0.01=2.784(2)t0.05=2.021,t0.01=2.704(3)t0.05=2.048,t0.01=2.76322、(1)χ20.05=43.8,χ20.0,1=50.9(2)χ20.05=7.43,χ20.0,1=10.923、(1)F0.05=2.31,F0.01=3.03(2)F0.05=6.18,F0.01=12.5324、Z值为3,大于Z的概率是0.0013525、大于该平均数以上的概率为0.0826、χ2以上的概率为0.1;χ2以下的概率为0.927、χ2是20.16,小于该χ2值以下概率是0.8628、χ2值是12.32,大于这个χ2值的概率是0.2129、χ2值是15.92,大于这个χ2值的概率是0.0730、两方差之比比小于F0.05第七章参数估计5、该科测验的真实分数在78.55—83.45之间,估计正确的概率为95%,错误概率为5%。

卡方检验医学统计学卡方检验是医学统计学中最常用的检验方法之一,它可用于测量两组数据之间的关联性。
在研究中,我们常常需要探究二者之间是否存在某种关联,卡方检验就是我们解决这个问题的利器。
卡方检验的原理卡方检验的原理是基于期望频数和实际频数的差异来检验两个变量之间的关系。
期望频数指的是在假设两个变量独立的情况下,我们可以根据样本量和其他条件,计算出不同组之间的理论值。
而实际频数则是实验中观察到的实际结果。
卡方检验的步骤如下:1.建立零假设和备择假设。
零假设指的是假设两个变量之间不存在任何关系,备择假设则是反之。
2.确定显著性水平 alpha,通常取值为0.05。
3.构建卡方检验统计量。
计算方法为将所有观察值与期望值的差平方后,再除以期望值的总和。
4.根据自由度和显著性水平,查卡方分布表得到 P 值。
5.如果 P 值小于显著性水平,拒绝零假设;否则无法拒绝零假设。
卡方检验的应用卡方检验可以应用于多个领域,其中医学统计学是最为常见的一个。
卡方检验可以用来分析两个疾病之间的相关性或者测量一种治疗方法的效果。
举个例子,某药厂要研发一种新的药物来治疗心脏病。
为了验证该药的疗效,实验组和对照组各50 人。
在 6 个月的治疗后,实验组和对照组中分别有 10 人和 15 人痊愈了。
卡方检验的作用就在于此时可以用来检验两组之间的差异是否具有统计学意义。
除了医学统计学之外,卡方检验在社会学、心理学、市场营销、物理等领域也都有广泛应用。
卡方检验的限制虽然卡方检验被广泛应用于各种实验和研究中,但它也有着自己的限制。
其中比较明显的一点就是对样本量有一定的要求。
当样本量较小的时候,期望频数的计算就会出现一定的误差,进而导致检验结果不准确。
此外,在面对非常态分布数据时,卡方检验也会出现问题。
当数据呈现正态分布时,卡方检验的准确性最高。
然而,实际上,很多数据都呈现出非正态分布,这时需要使用一些修正方法来解决。
卡方检验是医学统计学中最常用的统计方法之一,它可以用来测量两个变量之间的关联性。






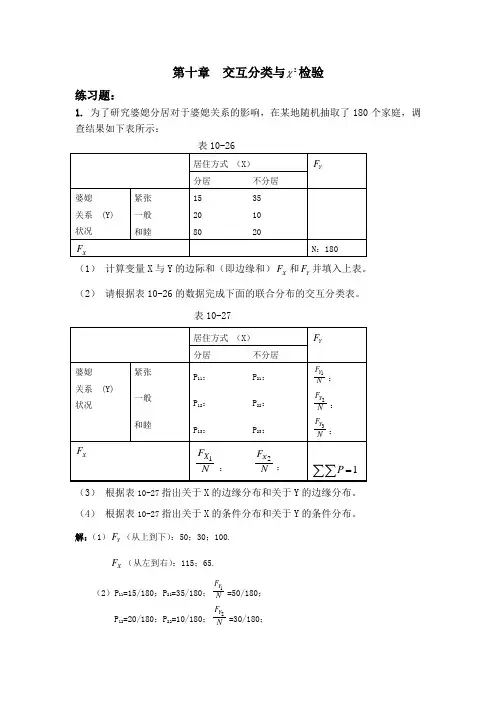
第十章 交互分类与2χ检验练习题:1. 为了研究婆媳分居对于婆媳关系的影响,在某地随机抽取了180个家庭,调查结果如下表所示:(1) 计算变量X 与Y 的边际和(即边缘和)X F 和Y F 并填入上表。
(2) 请根据表10-26的数据完成下面的联合分布的交互分类表。
表10-27(3) 根据表10-27指出关于X 的边缘分布和关于Y 的边缘分布。
(4) 根据表10-27指出关于X 的条件分布和关于Y 的条件分布。
解:(1)Y F (从上到下):50;30;100.X F (从左到右):115;65.(2)P 11=15/180;P 21=35/180;1Y F N =50/180;P 12=20/180;P 22=10/180;2Y F N =30/180;P 13=80/180;P 23=20/180;3Y F N =100/180;1X F N =115/180;2X F N =65/180.(3)关于X 的边缘分布:x 分居 不分居 P(x)115/18065/180关于Y 的边缘分布: y 紧张 一般 和睦 P(y)50/18030/180100/180(4)关于X 的条件分布有三个:y=“紧张” x 分居 不分居 P(x)15/5035/50y=“一般” x 分居 不分居 P(x)20/3010/30y=“和睦” x 分居 不分居 P(x) 80/10020/100关于y 的条件分布有两个: X=“分居”y紧张 一般 和睦 P(y)15/11520/11580/115X=“不分居”y紧张 一般 和睦 P(y)35/6510/6520/652. 一名社会学家关于“利他主义”的研究中,对被调查者的宗教信仰情况进行 了分析,得到的结果如下表所示:表10-28(1)根据表10-28的观察频次,计算每一个单元格的期望频次并填入表10-29。
表10-29 (2)根据表10-28和表10-29计算2χ,计算公式为2()2o e ef f f χ-=∑。


第十章χ2检验χ检验的原理第一节2χ检验的假设一、2(一)分类相互排斥,互不包容2χ检验中的分类必须相互排斥,这样每一个观测值就会被划分到一个类别或另一个类别之中。
此外,分类必须互不包容,这样,就不会出现某一观测值同时划分到更多的类别当中去的情况。
(二)观测值相互独立各个被试的观测值之间彼此独立,这是最基本的一个假定。
如一个被试对某一品牌的选择对另一个被试的选择没有影响。
当同一被试被划分到一个以上的类别中时,常常会违反这个假定。
当讨论列联表时,独立性假定是指变量之间的相互独立。
这种情况下,这种变量的独立性正在被检测。
而观测值的独立性则是预先的一个假定。
(三)期望次数的大小每一个单元格中的期望次数应该至少在5以上。
一些更加谨慎的统计学家提出了更严格χ检验时,每一个单元格的期望次数至少不应低于的标准,当自由度等于1时,在进行210,这样才能保证检验的准确性。
另外,在许多分类研究中会存在这样一种情况,如自由度很大,有几个类别的理论次数虽然很小,但在给以接受的标准范围内,只有一个类别的理论次数低于1。
此时,一个简单的处理原则是设法使每一个类别的理论次数都不要低于1,分类中不超过20%的类别的理论次数可以小于5。
在理论次数较小的特殊的四格表中,应运用一个精确的多项检验来避免使χ检验。
用近似的2χ检验的类别二、2(一)配合度检验配合度检验主要用来检验一个因素多项分类的实际观察数与某理论次数是否接近,这种2χ检验方法有时也称为无差假说检验。
当对连续数据的正态性进行检验时,这种检验又可称为正态吻合性检验。
(二)独立性检验独立性检验是用来检验两个或两个以上因素各种分类之间是否有关联或是否具有独立χ检验适用于探讨两个变量之间是否具有关联(非独立)或无关(独性的问题。
这种类型的2立),如果再加入另一个变量的影响,即探讨三个变量之间关系时,就必须使用多维列联表分析方法。
(三)同质性检验同质性检验的主要目的在于检定不同人群母总体在某一个变量的反应是否具有显著差异。
当用同质性检验检测双样本在单一变量的分布情形,如果两样本没有差异,就可以说两个母总体是同质的,反之,则说这两个母总体是异质的。
三、2χ检验的基本公式2χ是表示实测次数与理论次数(即期望次数)之间差异程度的指标,其基本数学定义是实测次数与期望次数之差的平方与期望次数的比率。
2χ检验就是检验实测次数与期望次数是否一致的统计方法。
基本公式如下:2)(∑-=ee f f f χ 其中 0f 表示实际观察次数,e f 表示某理论次数。
要求:≥e f 5四、小期望次数的连续性校正第一,单元格合并法。
若有一格或多个单元格的期望次数小于5时,在配合研究目的情况下,可适当调整变量的分类方式,将部分单元格予以合并。
第二,增加样本数。
如果研究者无法改变变量的分类方式,又想获得有效样本,最佳的方法是直接增加样本数来提高期望次数。
第三,去除样本法。
如果样本无法增加,次数偏低的类别又不具有分析与研究价值时,可以将该类被试除去,但研究的结论不能推论到这些被除去的母总体中。
第四,使用校正公式。
在2×2的列联表检验中,若单元格的期望次数低于10但高于5,可使用耶茨校正(Yates ’ correction for continuity)公式来加以校正。
若期望次数低于5时,或样本总人数低于20时,则应使用费舍精确概率检验法(Fisher ’s exact probability test)。
当单元格内容牵涉到重复测量设计时(例如前后测设计),则可使用麦内玛检验(McNemar test)。
第二节 配合度检验配合度检验(goodness of fit test )主要用于检验单一变量的实际观察次数分布与某理论次数是否有差别。
由于它检验的内容仅涉及一个因素多项分类的计数资料,故可以说是一种单因素检验(One-way test)。
一、配合度检验的一般问题1.建立假设0H :e f f =0 a H :e f f =0在2χ检验中,理论(或期望)次数的确定就取决于这种比例的假设。
2χ的临界值是在0H 成立的条件下导出理论分布,并由2χ公式计算出来的。
若实际计算出的2χ值大于理论上的临界值()205.0df χ,即2χ>()205.0df χ则说在05.0=α的显著水平上拒绝0H 。
2.自由度的确定原则自由度确定的一般原则是:以相互独立的类别数k (或C )减去所受的限制数M ,即M k df -=在各种适合性检验中,如果理论次数只受到总和的限制,即受∑∑=e f f的限制,则自由度为1-=k df在正态分布的适合性检验,因其除了受∑∑=e f f的限制以外,还受理论分布的均数和标准差两个未知参数的限制,即受到三个条件的限制,其自由度为3-=k df3.理论次数的计算规则一是数据分布有其理论概率为依据,这时的理论次数()e f 等于总次数乘以某种属性出现的概率(p ),即Np f e =理论次数的计算,一般是根据某种理论,按一定的概率通过样本即实际观察次数计算。
某种理论有经验概率,也有理论概率,如二项分布、正态分布等理论概率。
二、配合度检验的应用 (一)检验无差假说这里讲的无差假说,是指各项分类的实计数之间没有差异,也就是假设,各项分类之间的几会相等,或概率相等,因此理论次数完全按概率相等的条件计算。
即:理论次数=总数×例10-1:随机抽取60名学生,询问他们在高中是否需要文理分科,赞成分科的39人,反对分科的21人,问他们对分科的意见是否有显著差异?解:1)建立假设(赞成与反对的人数相等)分类项数1f f H e =00:(赞成与反对的人数不相等)2)计算统计量302160=⨯=e f 30)3021(30)3039()(2222-+-=-=∑fff eeχ 4.530)9(922=-+=3)进行统计决策 查2χ表,当1=df 时,,,63.684.3201.0205.0==χχ因为4.52=χ,201.02205.0χχχ<<,所以,05.001.0<<p 。
达到显著性水平,拒绝原假设。
说明两种态度有显著差异。
例10-2:某项民意测验,答案有同意、不置可否、不同意三种。
调查了48人,结果同意的24人,不置可否的12人,不同意的12人。
问持这三种意见的人数是否有显著不同?解:此题为检验无差假说,已知分类的项数为三,故各项分类假设实计数相等。
所以1)建立假设ffH e=:ffH e≠1:2)计算统计量616)1612(16)1612(16)1624(2222=-+-+-=χ 3)进行统计决策 查2χ表,当213=-=df 时,99.5205.0=χ,因为205.026χχ〉=,所以05.0<p 。
达到显著性水平,拒绝原假设。
说明三种态度有显著差异。
(二)检验假设分布的概率假设某因素各项分类的次数分布为正态,检验实计数与理论上期望的结果之间是否有差异。
因为已假定所观察的资料是按正态分布的,故其理论次数的计算应按正态分布概率,分f f H e ≠01:163148,48,31=⨯===feN p别计算各项分类的理论次数。
具体方法是先按正态分布理论计算各项分类应有的概率再乘以总数,便得到各项分类的理论次数。
如果不是事先假定所观察的资料为正态分布而是其他分布,如二项分布、泊松分布等,其概率应按各所假定的分布计算。
事先假定的分布不是理论分布而是经验分布,亦可按此经验分布计算概率,在乘以总数便可得到理论次数,从而进一步检验假设分布与实计数的分布之间,亦即实计数与理论次数之间差异是否显著。
例10-3:某班有学生50人,体检结果按一定标准划分为甲乙丙三类,其中甲类16人,乙类24人,丙类10人,问该班学生的身体状况是否符合正态分布?解:该题中的理论次数应按假设的正态分布概率计算。
按正态分布,就可以认为σ3± 包括了全体,各等级所占的横坐标应该相同(σσ236=÷),故各类人数应占的比率为:甲级:σσ1~3之间,曲线下的面积应为1587.03413.050.0=- 乙级:σσ1~1-之间,曲线下的面积应为6826.023413.0=⨯ 丙级:σσ3~1--之间,曲线下的面积应为1587.03413.050.0=- 各等级的理论次数为:8501587.0≈⨯=甲e f1)建立假设H 0:学生的身体状况符合正态分布 H 1:学生的身体状况不符合正态分布 2)计算统计量44.11881034342488162222=-+-+-=)()()(χ3)进行统计决策 当213=-=df 时,6.10205.0=χ,χχ205.02>,所以达到显著性水平,拒绝原假设。
说明学生身体状况不符合正态分布。
例10-4:根据以往的经验,某校长认为高中生升学的男女比例为2 :1,今年的升学情况是男生85人,女生35人,问今年升学的男女比例是否符合该校长的经验?解:此题是假设男女生升学的人数分布与校长的经验分布相同,故理论次数应按经验分布的概率计算34506826.0=⨯=fe 乙8501587.0≈⨯=fe 丙理论次数为:8032)3585(=⨯+=fe 男40313585=⨯+=)(女fe1) 建立假设H 0:男女升学比例符合校长经验 H 1:男女升学比例不符合校长经验 2)计算统计量94.04040-358080-85222=+=)()(χ3)进行统计决策 当12-=df 时,84.3205.0=χ,因为χχ205.02<,故差异不显著。
接受原假设。
说明男女升学比例符合校长经验。
三、连续变量分布的吻合性检验(自学)对于连续性数据总体分布的检验,一种方法是将测量数据整理成次数分布表,画出次数分布曲线图,根据次数分布曲线,判断选择恰当的理论分布。
有时可选择某一直线或曲线的理论分布函数方程式计算理论次数,然后把实际分组次数(0f )和理论次数(e f )代入检验的基本公式,计算2χ 值查2χ表,确定其差异是否显著。
若差异显著,说明实际次数分布于所选择的理论次数分布不吻合,这时可另选择理论分布函数,再次比较,直至吻合,这个理论分布函数就是该实际测量的次数分布函数。
若差异不显著则说明所选的理论次数分布于实际次数分布吻合。
对连续随机变量分布的吻合性检验,关键的步骤是计算理论次数与确定自由度。
理论次数的计算是把实际次数分布的统计量代入所选的理论分布函数方程,计算各分组区间的理论频率,然后乘以总数得到各分组区间的理论次数。
确定自由度时是将分组的数目减去计算理论次数是所用统计量的数目。
下面以正态分布吻合性检验为例,说明理论次数的计算与自由度的确定。
例10-5:表10-1所列资料是552名中学生的身高次数分布,问这些学生的身高分布是否符合正态分布。