(完整版)SQLServer存储过程的基本概念以及语法汇总
- 格式:doc
- 大小:23.51 KB
- 文档页数:10

sql server select 语句中调用存储过程-概述说明以及解释1.引言1.1 概述存储过程是一种预先定义好的SQL代码集合,它可以被重复使用来完成特定的任务。
在SQL Server中,存储过程可以帮助我们提高数据库的性能和安全性,并且可以简化复杂的业务逻辑。
在开发应用程序时,我们常常需要执行一系列的SQL语句来完成某个特定的任务。
如果这些任务需要在多个地方使用或者需要经常更新,那么每次都编写相同的SQL语句会非常繁琐和低效。
而存储过程的出现正是为了解决这个问题。
通过将一组SQL语句封装到一个存储过程中,我们可以将复杂的逻辑封装在数据库中,从而减少了应用程序的复杂性。
此外,存储过程还具有以下优点:1. 重用性:存储过程可以在多个地方使用,可以在应用程序中简单地调用它们而无需重复编写相同的SQL语句。
2. 性能优化:存储过程可以提高数据库的性能。
因为它们是预编译的,数据库会将存储过程的执行计划缓存起来,以便下次再次执行时可以直接使用之前的执行计划,而无需再次解析SQL语句。
3. 安全性:存储过程可以帮助我们实现数据访问的安全性。
通过存储过程,我们可以控制用户对数据库的访问权限,并且可以避免SQL注入等安全风险。
本文将重点介绍在SQL Server中如何调用存储过程的语法和方法。
通过学习这些内容,读者将能够更好地理解存储过程的概念和作用,并能够灵活运用它们来提高应用程序的性能和安全性。
接下来的章节将详细介绍相关的内容。
1.2文章结构1.2 文章结构本文将围绕SQL Server中调用存储过程的话题展开讨论。
首先,我们将介绍存储过程的概念和作用,以使读者对其有一个全面的认识。
接着,我们将详细说明在SQL Server中如何调用存储过程的语法和方法,帮助读者掌握这一重要的技能。
在正文部分,我们将以简明易懂的方式解释存储过程的概念和作用。
我们将探讨存储过程在数据库管理中的优势和用途,引导读者了解存储过程如何简化复杂的数据库操作,并提高数据库的性能和安全性。

SQL Server存储过程实例详解一、背景介绍存储过程是S QL Se rv e r中一种非常重要的数据库对象,它是一组预编译的SQ L语句集合,可以被存储在数据库中并被反复调用。
本文将详细介绍SQ LS er ve r存储过程的概念、用途以及如何创建和调用存储过程。
二、概念解析1.什么是存储过程?存储过程是一组S QL语句的集合,经过编译并存储在数据库中,以便被反复执行和调用。
它可以接受参数,并且可以返回结果集。
2.存储过程的优势有哪些?-提高数据库性能:存储过程可以预编译,加快SQ L语句的执行速度。
-提高数据安全性:将敏感的数据库操作封装在存储过程中,只对外暴露存储过程的接口,提高数据的安全性。
-提高开发效率:存储过程可以被反复调用,在多个应用程序中共享和复用。
3.存储过程的语法结构存储过程的语法结构如下所示:C R EA TE PR OC ED UR Epr o ce du re_n am e[@pa ra me te r1da tat y pe[=de fa ul t_val u e][O UT|O UT PU T]][@pa ra me te r2da tat y pe[=de fa ul t_val u e][O UT|O UT PU T]]...A SB E GI N--存储过程的执行逻辑E N D三、创建存储过程在SQ LS er ve r中,创建存储过程需要使用`CR EA TE P RO CED U RE`语句,下面是一个创建存储过程的示例:C R EA TE PR OC ED UR EGe t Em pl oy ee Co un tA SB E GI NS E LE CT CO UN T(*)ASE m pl oy ee Co un tF R OM Em pl oy ee sE N D四、调用存储过程调用存储过程可以使用`EX EC UT E`语句或者直接使用存储过程名称,下面是两种调用存储过程的示例:1.使用`E XE CU TE`语句调用存储过程:E X EC UT EG et Em pl oye e Co un t2.直接使用存储过程名称调用存储过程:G e tE mp lo ye eC ou nt五、存储过程参数存储过程可以接受输入参数和输出参数,下面是一个接受输入参数的存储过程示例:C R EA TE PR OC ED UR EGe t Em pl oy ee By Na me@n am eN VA RC HA R(50)A SB E GI NS E LE CT*F R OM Em pl oy ee sW H ER EE mp lo ye eN ame=@n am eE N D调用带有输入参数的存储过程时,需要传入参数的值,示例代码如下:E X EC UT EG et Em pl oye e By Na me@n am e='Jo h nS mi th'六、控制流程和逻辑处理存储过程可以包含控制流程和逻辑处理,例如条件判断、循环和异常处理,下面是一个带有I F条件判断的存储过程示例:C R EA TE PR OC ED UR EGe t Em pl oy ee By Sa lar y@s al ar yF LO ATA SB E GI NI F@s al ar y>5000B E GI NS E LE CT*F R OM Em pl oy ee sW H ER ES al ar y>@s ala r yE N DE L SEB E GI NS E LE CT*F R OM Em pl oy ee sW H ER ES al ar y<=@sal a ryE N DE N D七、常见问题和注意事项1.存储过程应该经过充分的测试和性能优化,以确保其高效运行。

sqlserver语法大全包含条件SQL Server 是一种关系型数据库管理系统(RDBMS),用于存储、管理和检索数据。
以下是 SQL Server 中常用的语法和条件的详细介绍,包括创建表、插入数据、查询数据、更新数据和删除数据等。
一、创建表语法在 SQL Server 中,使用 CREATE TABLE 语句来创建表,语法如下:CREATE TABLE 表名 (列名1 数据类型,列名2 数据类型,...列名n 数据类型);其中,表名是要创建的表的名称,列名是表中每个列的名称,数据类型是列中存储的数据类型。
例子如下:CREATE TABLE Students (ID INT,Name VARCHAR(50),Age INT);以上语句创建了一个名为 Students 的表,包含三个列:ID,Name 和 Age。
二、插入数据语法在 SQL Server 中,使用 INSERT INTO 语句来插入数据,语法如下:INSERT INTO 表名 (列1, 列2, ..., 列n) VALUES (值1, 值2, ..., 值n);其中,表名是要插入数据的表的名称,列1 到列n 是要插入数据的列,值1 到值n 是要插入的数据。
例子如下:INSERT INTO Students (ID, Name, Age) VALUES (1, 'John', 20);以上语句将 ID 为 1,Name 为 'John',Age 为 20 的数据插入到 Students 表中。
三、查询数据语法在 SQL Server 中,使用 SELECT 语句来查询数据,语法如下:SELECT 列1, 列2, ..., 列n FROM 表名 WHERE 条件;其中,列1 到列n 是要查询的列,表名是要查询的表的名称,条件是要满足的条件。
例子如下:SELECT Name, Age FROM Students WHERE Age > 18;以上语句查询了 Students 表中年龄大于 18 的学生的姓名和年龄。

SQL Server存储过程是一种预先编译的SQL语句集,存储在数据库中,可以通过存储过程的名称和参数来调用。
存储过程的编写可以大大提高数据库的性能和安全性,同时也可以简化复杂的数据库操作。
下面将从存储过程的基本语法、参数传递、错误处理、性能优化等方面来介绍SQL Server存储过程的编写。
一、存储过程的基本语法1.1 创建存储过程在SQL Server中,可以使用CREATE PROCEDURE语句来创建存储过程,例如:```sqlCREATE PROCEDURE proc_nameASBEGIN-- 存储过程的逻辑代码END```1.2 存储过程的参数存储过程可以接受输入参数和输出参数,例如:```sqlCREATE PROCEDURE proc_nameparam1 INT,param2 VARCHAR(50) OUTPUTASBEGIN-- 存储过程的逻辑代码END```1.3 调用存储过程使用EXECUTE语句可以调用存储过程,例如:```sqlEXECUTE proc_name param1, param2 OUTPUT```二、参数传递2.1 输入参数输入参数用于向存储过程传递数值、字符等数据,可以在存储过程内部进行计算和逻辑操作。
2.2 输出参数输出参数用于从存储过程内部传递数据到外部,通常用于返回存储过程的计算结果或状态信息。
2.3 默认参数在创建存储过程时可以指定默认参数值,当调用存储过程时如果未传入参数,则使用默认值。
三、错误处理3.1 TRY...CATCH语句使用TRY...CATCH语句可以捕获存储过程中的异常并进行处理,例如:```sqlBEGIN TRY-- 存储过程的逻辑代码END TRYBEGIN CATCH-- 异常处理代码END CATCH```3.2 R本人SEERROR函数可以使用R本人SEERROR函数来抛出自定义的异常信息,例如: ```sqlR本人SEERROR('Custom error message', 16, 1)```四、性能优化4.1 索引优化在存储过程中执行的SQL语句涉及到大量数据查询时,可以使用索引来提升查询性能。

sqlserver储存过程简单写法全文共四篇示例,供读者参考第一篇示例:SQL Server是一种流行的关系型数据库管理系统,储存过程是一个可以包含一系列SQL语句的代码块,可以被多次调用来完成特定的任务。
储存过程可以提高数据库性能、安全性和可维护性,因为它们可以减少应用程序与数据库之间的数据传输量,并且可以把逻辑代码集中在数据库中。
在SQL Server中,储存过程通常是使用T-SQL编写的。
下面我们将介绍SQL Server中储存过程的简单写法,让您能够轻松地创建和使用储存过程。
1. 创建储存过程要创建一个储存过程,您需要使用CREATE PROCEDURE语句,后面跟着储存过程的名称和参数(如果有的话),然后是储存过程的主体代码。
以下是一个简单的示例,创建一个接受一个参数并返回查询结果的储存过程:```sqlCREATE PROCEDURE GetEmployeeByID@EmployeeID INTASBEGINSELECT * FROM Employees WHERE EmployeeID =@EmployeeIDEND```在这个例子中,我们创建了一个名为GetEmployeeByID的储存过程,它接受一个参数@EmployeeID,然后查询Employees表中的数据并返回给用户。
以下是执行上面创建的GetEmployeeByID储存过程的示例:```sqlEXEC GetEmployeeByID @EmployeeID = 1```总结:通过本文的介绍,您应该已经了解了SQL Server中储存过程的简单写法。
创建、执行、修改和删除储存过程是数据库管理的基本技能之一,希望这些简单示例能够帮助您更好地理解和使用储存过程。
如果您想深入学习更多关于SQL Server储存过程的知识,可以查阅相关资料或者参加专业的培训课程。
祝您在数据库管理领域取得更大的成就!第二篇示例:SQL Server是一款强大的关系型数据库管理系统,它支持存储过程(Stored Procedure)这一重要的数据库功能。

SQLServer存储过程Return、output参数及使⽤技巧SQL Server⽬前正⽇益成为WindowNT操作系统上⾯最为重要的⼀种数据库管理系统,随着 SQL Server2000的推出,微软的这种数据库服务系统真正地实现了在WindowsNT/2000系列操作系统⼀统天下的局⾯,在微软的操作系统上,没有任何⼀种数据库系统能与之抗衡,包括数据库领域中的领头⽺甲⾻⽂公司的看家数据库Oracle在内。
不可否认,SQL Server最⼤的缺陷就是只能运⾏在微软⾃⼰的操作系统上,这⼀点是SQL Server的致命点。
但在另⼀⽅⾯却也成了最好的促进剂,促使SQL Server在⾃⼰仅有的“⼟地”上⾯将⾃⼰的功能发挥到了极⾄最⼤限度的利⽤了NT系列操作系统的各种潜能!作为SQL Server数据库系统中很重要的⼀个概念就是存储过程,合理的使⽤存储过程,可以有效的提⾼程序的性能;并且将商业逻辑封装在数据库系统中的存储过程中,可以⼤⼤提⾼整个软件系统的可维护性,当你的商业逻辑发⽣改变的时候,不再需要修改并编译客户端应⽤程序以及重新分发他们到为数众多的⽤户⼿中,你只需要修改位于服务器端的实现相应商业逻辑的存储过程即可。
合理的编写⾃⼰需要的存储过程,可以最⼤限度的利⽤SQL Server的各种资源。
下⾯我们来看看各种编写SQL Server 存储过程和使⽤存储过程的技巧经验。
Input 此参数只⽤于将信息从应⽤程序传输到存储过程。
InputOutput 此参数可将信息从应⽤程序传输到存储过程,并将信息从存储过程传输回应⽤程序。
Output 此参数只⽤于将信息从存储过程传输回应⽤程序。
ReturnValue 此参数表⽰存储过程的返回值。
SQL Server 的存储过程参数列表中不显⽰该参数。
它只与存储过程的 RETURN 语句中的值相关联。
存储过程为主键⽣成新值后,通常使⽤存储过程中的 RETURN 语句返回该值,因此⽤来访问该值的参数类型是 ReturnValue 参数。
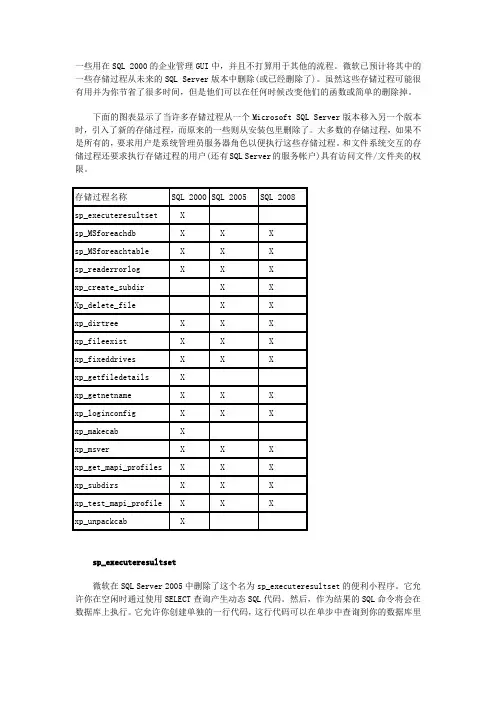
一些用在SQL 2000的企业管理GUI中,并且不打算用于其他的流程。
微软已预计将其中的一些存储过程从未来的SQL Server版本中删除(或已经删除了)。
虽然这些存储过程可能很有用并为你节省了很多时间,但是他们可以在任何时候改变他们的函数或简单的删除掉。
下面的图表显示了当许多存储过程从一个Microsoft SQL Server版本移入另一个版本时,引入了新的存储过程,而原来的一些则从安装包里删除了。
大多数的存储过程,如果不是所有的,要求用户是系统管理员服务器角色以便执行这些存储过程。
和文件系统交互的存储过程还要求执行存储过程的用户(还有SQL Server的服务帐户)具有访问文件/文件夹的权限。
sp_executeresultset微软在SQL Server 2005中删除了这个名为sp_executeresultset的便利小程序。
它允许你在空闲时通过使用SELECT查询产生动态SQL代码。
然后,作为结果的SQL命令将会在数据库上执行。
它允许你创建单独的一行代码,这行代码可以在单步中查询到你的数据库里的每一个表的记录数目(就像例子中所显示的)。
这是一个未公开的存储过程,而且无法知道它为什么被删除了。
但是,唉,这个便利的有用存储过程已经没有了。
exec sp_execresultset 'SELECT ''SELECT '''''' + name + '''''',count(*) FROM '' + namefrom sysobjectswhere xtype = ''U'''sp_MSforeachdb / sp_MSforeachtablesp_MSforeachdb / sp_MSforeachtable两个存储过程,sp_MSforeachdb和sp_MSforeachtable封装了一个指针。

SQLserver存储过程语法及实例存储过程如同一门程序设计语言,同样包含了数据类型、流程控制、输入和输出和它自己的函数库。
--------------------基本语法--------------------一.创建存储过程create procedure sp_name()begin.........end二.调用存储过程1.基本语法:call sp_name()注意:存储过程名称后面必须加括号,哪怕该存储过程没有参数传递三.删除存储过程1.基本语法:drop procedure sp_name//2.注意事项(1)不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程四.其他常用命令1.show procedure status显示数据库中所有存储的存储过程基本信息,包括所属数据库,存储过程名称,创建时间等2.show create procedure sp_name显示某一个mysql存储过程的详细信息--------------------数据类型及运算符--------------------一、基本数据类型:略二、变量:自定义变量:DECLARE a INT ; SET a=100; 可用以下语句代替:DECLARE a INT DEFAULT 100;变量分为用户变量和系统变量,系统变量又分为会话和全局级变量用户变量:用户变量名一般以@开头,滥用用户变量会导致程序难以理解及管理1、在mysql客户端使用用户变量mysql> SELECT 'Hello World' into @x;mysql> SELECT @x;mysql> SET @y='Goodbye Cruel World';mysql> select @y;mysql> SET @z=1+2+3;mysql> select @z;2、在存储过程中使用用户变量mysql> CREATE PROCEDURE GreetWorld( ) SELECT CONCAT(@greeting,' World');mysql> SET @greeting='Hello';mysql> CALL GreetWorld( );3、在存储过程间传递全局范围的用户变量mysql> CREATE PROCEDURE p1( ) SET @last_procedure='p1';mysql> CREATE PROCEDURE p2( ) SELECT CONCAT('Last procedure was ',@last_procedure);mysql> CALL p1( );mysql> CALL p2( );三、运算符:1.算术运算符+ 加 SET var1=2+2; 4- 减 SET var2=3-2; 1* 乘 SET var3=3*2; 6/ 除 SET var4=10/3; 3.3333DIV 整除 SET var5=10 DIV 3; 3% 取模 SET var6=10%3 ; 12.比较运算符> 大于 1>2 False< 小于 2<1 False<= 小于等于 2<=2 True>= 大于等于 3>=2 TrueBETWEEN 在两值之间 5 BETWEEN 1 AND 10 TrueNOT BETWEEN 不在两值之间 5 NOT BETWEEN 1 AND 10 False IN 在集合中 5 IN (1,2,3,4) FalseNOT IN 不在集合中 5 NOT IN (1,2,3,4) True= 等于 2=3 False<>, != 不等于 2<>3 False<=> 严格比较两个NULL值是否相等NULL<=>NULL TrueLIKE 简单模式匹配 "Guy Harrison" LIKE "Guy%" TrueREGEXP 正则式匹配"Guy Harrison" REGEXP "[Gg]reg" FalseIS NULL 为空 0 IS NULL FalseIS NOT NULL 不为空 0 IS NOT NULL True3.逻辑运算符4.位运算符| 或& 与<< 左移位>> 右移位~ 非(单目运算,按位取反)注释:mysql存储过程可使用两种风格的注释双横杠:--该风格一般用于单行注释c风格:/* 注释内容 */ 一般用于多行注释--------------------流程控制--------------------一、顺序结构二、分支结构ifcase三、循环结构for循环while循环loop循环repeat until循环注:区块定义,常用begin......end;也可以给区块起别名,如:lable:begin...........end lable;可以用leave lable;跳出区块,执行区块以后的代码begin和end如同C语言中的{ 和 }。

SqlServer存储过程详解SqlServer存储过程详解1.创建存储过程的基本语法模板:if (exists (select*from sys.objects where name ='pro_name'))drop proc pro_namegocreate proc pro_name@param_name param_type [=default_value]asbeginsql语句endps:[]表⽰⾮必写内容。
sys.objects存储的是本数据库中的信息,不仅仅存储表名,还有存储过程名、视图名、触发器等等。
例如:1if (exists (select*from sys.objects where name ='USP_GetAllUser'))2drop proc USP_GetAllUser3go4create proc USP_GetAllUser5@UserId int=16as7set nocount on;8begin9select*from UserInfo where Id=@UserId10endps:SQL Server 实⽤⼯具将 GO 解释为应将当前的 Transact-SQL 批处理语句发送给 SQL Server 的信号。
当前批处理语句是⾃上⼀ GO 命令后输⼊的所有语句,若是第⼀条 GO 命令,则是从特殊会话或脚本的开始处到这条 GO 命令之间的所有语句。
2.调⽤⽅法:exec P_GetAllUser 2;ps:⼀般在执⾏存储过程是,最好加上架构名称,例如 P_GetAllUser 这样可以可以减少不必要的系统开销,提⾼性能。
因为如果在存储过程名称前⾯没有加上架构名称,SQL SERVER ⾸先会从当前数据库sys schema(系统架构)开始查找,如果没有找到,则会去其它schema查找,最后在dbo架构(系统管理员架构)⾥⾯查找。

存储过程也称为存储查询,是存储在数据库中预先定义的SQL语句。
它可以将常用的或很复杂的工作预先用SQL语句写好,并用一个值得的名称存储起来。
使用时,只需要调用该存储过程就可以自动完成命令。
现在的程序员在代码中都不直接使用SQL字符串,而是利用创建和使用存储过程来代替。
这样做的好处如下。
1.存储过程只在创建时进行编译,以后执行存储过程时都不需要重新编译;而SQL语句每执行一次都要编译一次,所以使用存储过程可以提供数据库执行速度。
2.当对数据库进行复杂操作时,可以将这些复杂操作利用存储过程封装起来与数据库提供的事务处理结合在一起使用。
3.存储过程的安全性高,可以设定只有魔鬼用户才具有对其指定存储过程的使用权。
4.存储过程可以将所有SQL语句代码集中存放于服务器,避免将.net代码和冗长的SQL语句混在一起,从而使.NET代码更容易维护。
5.在存储过程中可以使用输出参数,允许返回记录集或其他值。
6.存储过程可以重复使用,大大减少了数据库开发人员的工作量。
存储过程几乎总是比相应的SQL语句执行速度快,可以使用CreateProcedure语句来创建一个存储过程,基本语法如下:Create Proc[edure][拥有者]存储过程名][;程序编号][(canshu #1,…参数#1024)[with{recompile|encryption|recomole,encryption}][for replication]As 程序行其中,存储过程名不能超过128个自己。
每个存储过程中最多设定1024个参数,参数的使用方法如下:@参数名数据类型【varying】【=内定值】【outPut】在每个参数名的前面要有一个“@”符号,每一个存储过程的参数均为程序内部使用,参数的类型除了Image外,其他SQL Server所支持的数据库都可以使用。
【=内定值】相当于在建立数据库时设定的一个自动的默认值,这里是为这个参数设定默认值。

S2_Sql 端口1433第1章1、创建一个数据文件和一个日志文件.create database StuDB--数据裤名称on primary--primary指定是主数据裤文件(name='StuDB_data',--name为数据文件的逻辑称filename='f:\冯建\StuDB_data.mdf',--数据文件的物理名称size=3mb,--数据文件的初始大小maxsize=100mb,--数据文件增长的最大值filegrowth=10%--数据文件的增长率)log on--日志文件,各参数含义同上(name='stuDB_log',filename='f:\冯建\StuDB_log.ldf',size=2mb,filegrowth=1mb)2、删除数据裤..drop database 数据裤名Sql Server 将数据裤的清单存放在master系统数据裤的sysdatabases表中,只需要查看该表中是否存于该数据库中就可以了。
use master--设置当前的数据库为master,以便访问sysdatabases表goif exists(select*from sysdatabases where name='stuDB')drop database stuDBcreate database stuDBon()log on()Exists(查询语句)检测某个查询是否存在。
如果查询语句返回的记录结果不为空,则表示存在;否则表示不存在。
3、创建学员信息表和删除学员信息表--创建学员信息表/*语法carate table 表名(字段 1数据类型列的特征字段2 数据类型列的特征....)*/use stuDBgoif exists(select*from sysobjects where type='u'and name=StuInfo) drop table StuInfo –-删除表的语句create table StuInfo(stuname varchar(20)not null,--学员姓名,非空stuNo char(6)not null,--学号,非空StuID numeric(18,0), --身份证号码,numeric(18,0)代表位数字,小数位数为位stuSeat smallint identity(1,1),--座位号,自动编号(标识列),identity(起始值,递增量)stuAddress text--允许为,住址)4、使用sql语句创建和删除约束添加约束语法:Alter table 表名Add constraint 约束名约束类型具体的约束说明删除约束语法:alter table stuInfodrop constraint 约束名--添加主键约束将stuNO作为主键alter table stuInfoadd constraint PK_stuNo primary key(stuNo)--添加唯一约束(身份证号唯一,建立唯一约束)alter table stuInfoadd constraint UQ_StuID unique(stuID)--添加默认约束(地址默认为“地址不详”)alter table stuInfoadd constraint DF_stuAddress default('地址不详')for stuAddress--添加检查约束(年龄)alter table stuInfoadd constraint CK_stuAge check(Stuage between 15 and 40)--添加外键约束(主表stuInfo和从表StuMarks建立关系,关系字段为stuNO)alter table stuMarksadd constraint FK_stuNO foreign key(stuNO) references stuInfo(stuNO)5.使用SQL语句创建登录1、创建windows登录账户语法:exec sp_grantlogin‘windows域名\域账户’2、创建sql登录账户语法:exec sp_addlogin‘账户名’,’密码’3、创建数据库用户:需调用系统存储过程sp_grantdbaccessexec sp_grantdbaccess ‘登录账户’,’数据库用户’4、给数据库用户授权:常用的权限包括insert,delete,update,select,create table等等语法:grant权限[on 表名] to 数据库用户6、视图和索引---创建索引的语法if exists(select*from sysindexes where name='index_name')create [unique] [clustered] [nonclustered]index index_name on table_name(指定的字段)[withfillfactor=X]--指定按索引查询select*from table_name with(index_name)where [......]--创建视图的语法create view view_nameas<select语句>7、触发器1、语法: if exists(select * from sysobjects where name='trigger_name')drop trigger trigger_namegocreate trigger trigger_nameon table_name[with encryption]for [delete,insert,update]asT-SQL语句Go2、instead of 触发器---以下删除使用instead of触发器实现,原因:after触发器不能删除有主外键关系表的数据create trigger cardInfoDeleteon cardInfoinstead of deleteasset nocount onbegindeclare @cardid char(19)select @cardid=cardid from deletedbegin trandeclare @error intdelete from transinfo where cardid=@cardidset @error=@@errordelete from cardInfo where cardid=@cardidset @error=@@error+@errorif(@error<>0)beginraiserror('删除时出错,',16,1)rollbackendelseendset nocount off3、8、时间查询datediff(时间类型,前面比较小的时间,后面比较大的时间)<=datepart(dw,getdate())。
sql存储过程语句SQL存储过程是一种在数据库中存储的程序,它可以接收参数并执行一系列的SQL语句。
存储过程可以提高数据库的性能和安全性,减少网络流量,同时也可以简化应用程序的开发。
本文将介绍SQL存储过程的基本概念、语法和应用,以及如何使用SQL存储过程来提高数据库的性能和安全性。
一、SQL存储过程的基本概念SQL存储过程是一种预编译的程序,它可以存储在数据库中,并在需要的时候被调用。
存储过程可以接收参数,并执行一系列的SQL 语句,最终返回结果集或输出参数。
SQL存储过程与函数类似,但它可以执行更复杂的操作,比如控制流程、事务处理、异常处理等。
存储过程还可以提高数据库的性能和安全性,因为它可以预编译和缓存SQL语句,减少网络流量,并且只有授权用户才能调用。
二、SQL存储过程的语法SQL存储过程的语法与SQL语句类似,但它需要使用特定的语法结构和关键字。
下面是一个简单的SQL存储过程的示例:CREATE PROCEDURE sp_get_customer_info@customer_id INTASBEGINSELECT * FROM customers WHERE customer_id = @customer_idEND这个存储过程接收一个整型参数customer_id,然后根据这个参数查询customers表中的数据,并返回结果集。
下面是SQL存储过程的语法结构:CREATE PROCEDURE procedure_name@parameter_name data_type [= default_value] [OUT]ASBEGIN-- SQL statementsEND其中,CREATE PROCEDURE是创建存储过程的关键字,procedure_name是存储过程的名称,@parameter_name是存储过程的参数名称,data_type是参数的数据类型,default_value是参数的默认值(可选),[OUT]表示该参数是输出参数(可选),AS是存储过程的开始标记,BEGIN和END之间是存储过程的SQL语句。
SQL Server 存储过程详解◆优点:执行速度更快。
存储过程只在创造时进行编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程执行速度更快。
存储过程用于处理复杂的操作时,程序的可读性更强、网络的负担更小。
使用存储过程封装事务性能更佳。
能有效的放注入,安全性更好。
可维护性高,在一些业务规则发生变化时,有时只需调整存储过程即可,而不用改动和重编辑程序。
更好的代码重用。
◆缺点:存储过程将给服务器带来额外的压力。
存储过程多多时维护比较困难。
移植性差,在升级到不同的数据库时比较困难。
调试麻烦,SQL语言的处理功能简单。
总之复杂的操作或需要事务操作的SQL建议使用存储过程,而参数多且操作简单SQL 语句不建议使用存储过程。
存储过程定义存储过程是一组Transact-SQL 语句,它们只需编译一次,以后即可多次执行。
因为Transact-SQL 语句不需要重新编译,所以执行存储过程可以提高性能。
触发器是一种特殊的存储过程,不由用户直接调用。
创建触发器时,将其定义为在对特定表或列进行特定类型的数据修改时激发。
存储过程的设计规则CREATE PROCEDURE 定义自身可以包括任意数量和类型的SQL 语句,但以下语句除外。
不能在存储过程的任何位置使用这些语句。
CREATE AGGREGATE、CREATE RULE、CREATE DEFAULT、CREATE SCHEMA、CREATE 或ALTER FUNCTION、CREATE 或ALTER TRIGGER、CREATE 或ALTER PROCEDURE、CREATE 或ALTER VIEW、SET PARSEONLY、SET SHOWPLAN_ALL、SET SHOWPLAN_TEXT、SET SHOWPLAN_XML、USE database_name其他数据库对象均可在存储过程中创建。
可以引用在同一存储过程中创建的对象,只要引用时已经创建了该对象即可。
第一章数据库基础1数据库系统:是由数据库及其管理软件组成的系统,常常把数据库有关的硬件和软件系统成为数据库系统2.数据库:数据库就是数据的仓库,由表、关系以及操作对象组成3.数据:是描述事物的符号记录(数字、文字、图形、图像、声音等)4.数据库的作用存储大量数据,方便检索和访问保持数据信息的一致、完整共享和安全通过组合分析,产生新的有用信息5.数据库经历的三个阶段及特点1)人工管理阶段: 数据不保存;使用应用程序管理数据;数据不共享;数据不具有独立性。
2)文件系统阶段:数据可以长期保存;由文件系统管理数据;共享性差,数据冗余大;数据独立性差。
3)数据库系统阶段:数据结构化;数据共享性高;数据独立性强;数据粒度小;独立的数据操作界面;统一管理和控制6.数据模型的分类层次模型网络模型关系模型7.E-R图三个主要部分1)1.实体集:在E-R图中用长方形来表示实体集,实体是实体集的成员。
2) 联系:在E-R图中用菱形来表示联系,联系与其涉及的实体集之间以直线连接,并在直线端部标上联系的种类, (1:1,1:N,M:N)。
3) 属性:在E-R图中用椭圆形来表示实体集和联系的属性,对于主键码的属性,在属性名下划一横线。
8.绘制E-R图所需的图形1) 长方形框----实体集(考虑问题的对象)2) 菱形框----联系(实体集间联系)3) 椭圆形框----实体集和联系的属性4) 直线----连接相关的联系和实体,并可标上联系的种类9.E-R图设计原则:真实性;避免冗余;简单性10.三大范式第一范式:在关系模型中的每一个具体关系R中,如果每个属性都是不可再分的,则称关系(R)属于第一范式(1NF)第二范式:如果关系模式R属于第一范式,且每一个非主属性都完全依赖于主码,则称关系R是属于第二范式的第三范式:如果关系模式R为2NF,并且R中的每个非主属性不传递依赖于R的主码,则称关系R是属于第三范式的第二章数据库的安装1.常见的数据库类型:Access、SQL server2000、2005、2008,Oracle数据库等2.数据库管理员的工作是:配置数据库服务器环境;管理数据库的逻辑对象结构;配置数据库的对象权限;制定数据库的性能优化策略;数据库的备份还原策略;数据库的异构协同结构3.SQL Server 2008 的版本Express 适用于无连接的客户端或独立应用程序Workgroup 适用于工作组或分支机构操作的数据库Standard 部门级应用程序的数据库服务器Enterprise 高度可伸缩和高度可用的企业级数据库Developer Enterprise 版,但是只授予开发和测试用许可Web 供托管公司提供低成本、高伸缩的托管服务,只收取低廉的每月许可费Mobile 用于智能手持式设备的精简数据库12.掌握SQL Server 2008数据库的安装与卸载第三章数据库的管理1.T-SQL语言分类DDL(数据定义语言)-create(创建)-alter (修改)-drop (删除)DQL(数据查询语言)-inter(插入)-update(更新)DML(数据操作语言)-select(查询)DCL(数据控制语言)-revoke(撤销)-deny(拒绝)-grant(同意、授权)2.数据库文件主数据文件(.mdf):一个数据库有且只有一个辅助数据文件(.ndf):根据需要自由选择,当数据库很大时,可以选择多个日志文件(.ldf):用于存储恢复数据库所需的事务日志信息3.掌握数据库的创建及修改(图形化及代码)修改数据库包括:扩展、收缩、分离附加、删除4.语法1)修改数据库名Alter database 原数据库名Modify name =新数据库名例子:【例】将数据库book的名字改为booksalter database bookmodify name=books2)修改文件属性Alter database 数据库名Modify file(name='逻辑名',size=修改后的大小,maxsize=修改后的大小,filegrowth=修改后的大小)Go例子:把初始大小由原来5mb增大为12mbalter database booksmodify file(name='book_data',size=12mb)go3)添加日志文件Alter database 数据库名Add log file(name= ‘逻辑名’,filename = ‘文件的存放路径’,size=日志文件的初始大小,maxsize=日志文件的最大大小,filegrowth=日志文件的增长方式)Go例子:【例】向shop数据库中添加一个日志文件alter database shopadd log file(name='shop_log2',filename ='c:\shop_log2.ldf',size=10mb, maxsize=20mb,filegrowth=10%)go4)删除空文件Alter database 数据库名Remove file 文件的逻辑名例子: 删除文件shop_data2 alterdatabase shop removefile shop_data24)添加辅助数据文件alter database 数据库名add file(name=‘逻辑名’,filename=‘文件存放的路径’,size=初始大小,maxsixe=最大大小,filegrowth=增长方式)Go例子:向数据库shop中添加一个辅助数据文件alter database shopadd file(name='shop_data3',filename='c:\shop_data3.ndf',size=5mb,maxsize=10mb,filegrowth=10%)go5)创建/删除数据库Create database 数据库名on primary( --数据文件name=‘逻辑名’,filename=‘文件的存放路径’,size=数据文件的初始大小,maxsize=数据文件的最大大小,filegrowth=文件的增长方式 )log on ( --日志文件name=‘逻辑名’,filename=‘文件的存放路径’,size=数据文件的初始大小,maxsize=数据文件的最大大小,filegrowth=文件的增长方式 )go例子:创建一个名为book的数据库,其初始值大小为5MB,最大大小为 50MB,允许数据库自动增长,增长方式是按10%比例增长;日志文件初始为2MB,最大可增长到5MB,按1MB增长。
SQLSERVER存储过程基本语法⼀、定义变量--简单赋值declare@a intset@a=5print@a--使⽤select语句赋值declare@user1nvarchar(50)select@user1='张三'print@user1declare@user2nvarchar(50)select@user2= Name from ST_User where ID=1print@user2--使⽤update语句赋值declare@user3nvarchar(50)update ST_User set@user3= Name where ID=1print@user3⼆、表、临时表、表变量--创建临时表1create table #DU_User1([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL);--向临时表1插⼊⼀条记录insert into #DU_User1 (ID,Oid,[Login],Rtx,Name,[Password],State) values (100,2,'LS','0000','临时','321','特殊');--从ST_User查询数据,填充⾄新⽣成的临时表select*into #DU_User2 from ST_User where ID<8--查询并联合两临时表select*from #DU_User2 where ID<3union select*from #DU_User1--删除两临时表drop table #DU_User1drop table #DU_User2--创建临时表CREATE TABLE #t([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL,)--将查询结果集(多条数据)插⼊临时表insert into #t select*from ST_User--不能这样插⼊--select * into #t from dbo.ST_User--添加⼀列,为int型⾃增长⼦段alter table #t add[myid]int NOT NULL IDENTITY(1,1)--添加⼀列,默认填充全球唯⼀标识alter table #t add[myid1]uniqueidentifier NOT NULL default(newid())select*from #tdrop table #t--给查询结果集增加⾃增长列--⽆主键时:select IDENTITY(int,1,1)as ID, Name,[Login],[Password]into #t from ST_Userselect*from #t--有主键时:select (select SUM(1) from ST_User where ID<= a.ID) as myID,*from ST_User a order by myID--定义表变量declare@t table(id int not null,msg nvarchar(50) null)insert into@t values(1,'1')insert into@t values(2,'2')select*from@t三、循环--while循环计算1到100的和declare@a intdeclare@sum intset@a=1set@sum=0while@a<=100beginset@sum+=@aset@a+=1endprint@sum四、条件语句--if,else条件分⽀if(1+1=2)beginprint'对'endelsebeginprint'错'end--when then条件分⽀declare@today intdeclare@week nvarchar(3)set@today=3set@week=casewhen@today=1then'星期⼀'when@today=2then'星期⼆'when@today=3then'星期三'when@today=4then'星期四'when@today=5then'星期五'when@today=6then'星期六'when@today=7then'星期⽇'else'值错误'endprint@week五、游标declare@ID intdeclare@Oid intdeclare@Login varchar(50)--定义⼀个游标declare user_cur cursor for select ID,Oid,[Login]from ST_User --打开游标open user_curwhile@@fetch_status=0begin--读取游标fetch next from user_cur into@ID,@Oid,@Loginprint@ID--print @Loginendclose user_cur--摧毁游标deallocate user_cur六、触发器 触发器中的临时表: Inserted 存放进⾏insert和update 操作后的数据 Deleted 存放进⾏delete 和update操作前的数据--创建触发器Create trigger User_OnUpdateOn ST_Userfor UpdateAsdeclare@msg nvarchar(50)--@msg记录修改情况select@msg= N'姓名从“'+ + N'”修改为“'+ +'”'from Inserted,Deleted --插⼊⽇志表insert into[LOG](MSG)values(@msg)--删除触发器drop trigger User_OnUpdate七、存储过程--创建带output参数的存储过程CREATE PROCEDURE PR_Sum@a int,@b int,@sum int outputASBEGINset@sum=@a+@bEND--创建Return返回值存储过程CREATE PROCEDURE PR_Sum2@a int,@b intASBEGINReturn@a+@bEND--执⾏存储过程获取output型返回值declare@mysum intexecute PR_Sum 1,2,@mysum outputprint@mysum--执⾏存储过程获取Return型返回值declare@mysum2intexecute@mysum2= PR_Sum2 1,2print@mysum2⼋、⾃定义函数 函数的分类: 1)标量值函数 2)表值函数 a:内联表值函数 b:多语句表值函数 3)系统函数--新建标量值函数create function FUNC_Sum1(@a int,@b int)returns intasbeginreturn@a+@bend--新建内联表值函数create function FUNC_UserTab_1(@myId int)returns tableasreturn (select*from ST_User where ID<@myId)--新建多语句表值函数create function FUNC_UserTab_2(@myId int)returns@t table([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL)asbegininsert into@t select*from ST_User where ID<@myIdreturnend--调⽤表值函数select*from dbo.FUNC_UserTab_1(15)--调⽤标量值函数declare@s intset@s=dbo.FUNC_Sum1(100,50)print@s--删除标量值函数drop function FUNC_Sum1谈谈⾃定义函数与存储过程的区别:⼀、⾃定义函数: 1. 可以返回表变量 2. 限制颇多,包括 不能使⽤output参数; 不能⽤临时表; 函数内部的操作不能影响到外部环境; 不能通过select返回结果集; 不能update,delete,数据库表; 3. 必须return ⼀个标量值或表变量 ⾃定义函数⼀般⽤在复⽤度⾼,功能简单单⼀,争对性强的地⽅。
sql server基础语法摘要:1.SQL Server 简介2.SQL 语言分类3.SQL 基础语法3.1 数据定义语言(DDL)3.2 数据操纵语言(DML)3.3 数据查询语言(DQL)4.SQL 语句实例5.总结正文:SQL Server 是一个关系数据库管理系统,它使用结构化查询语言(SQL) 进行数据操作。
SQL 是一种强大的语言,可以对数据进行定义、操纵和查询。
在SQL Server 中,SQL 语言主要分为三类:数据定义语言(DDL)、数据操纵语言(DML) 和数据查询语言(DQL)。
1.SQL Server 简介SQL Server 是Microsoft 公司开发的一款关系数据库管理系统,它支持多种操作系统,并且提供了丰富的功能,如数据备份、恢复、安全性等。
SQL Server 广泛应用于企业级应用程序,例如电子商务、金融、医疗等领域。
2.SQL 语言分类SQL 语言主要分为三类:数据定义语言(DDL)、数据操纵语言(DML) 和数据查询语言(DQL)。
3.SQL 基础语法3.1 数据定义语言(DDL)DDL 用于定义数据库中的对象(如表、视图、索引等),主要包含以下关键字:- CREATE:创建对象- ALTER:修改对象- DROP:删除对象- DECLARE:声明变量3.2 数据操纵语言(DML)DML 用于对数据库中的数据进行操作,主要包含以下关键字:- SELECT:查询数据- INSERT:插入数据- UPDATE:更新数据- DELETE:删除数据3.3 数据查询语言(DQL)DQL 用于查询数据库中的数据,主要包含以下关键字:- SELECT:查询数据- FROM:指定数据来源- WHERE:设置查询条件- GROUP BY:分组汇总数据- HAVING:设置分组条件- ORDER BY:排序查询结果- DISTINCT:去除重复数据4.SQL 语句实例以下是一些SQL 语句实例:- 创建表:```CREATE TABLE students (id INT PRIMARY KEY,name NVARCHAR(50),age INT);```- 插入数据:```INSERT INTO students (id, name, age) VALUES (1, N"张三", 20); ```- 更新数据:```UPDATE students SET age = 21 WHERE id = 1;```- 删除数据:```DELETE FROM students WHERE id = 1;```- 查询数据:```SELECT * FROM students;```- 按年龄分组汇总:```SELECT age, COUNT(*) FROM students GROUP BY age;```5.总结SQL Server 基础语法包括数据定义语言(DDL)、数据操纵语言(DML) 和数据查询语言(DQL)。
SQL Server或语法一、概述S Q LS er ve r是一种关系型数据库管理系统,它提供了强大的数据存储和操作能力。
在使用S QL Se rv er进行数据库开发和管理的过程中,熟悉S Q LS er ve r的语法是非常重要的。
本文将介绍一些常用的SQ L Se rv er语法,帮助读者更好地理解和应用S QL Se rv e r。
二、基本语法1.创建数据库使用以下语句可以在S QL Se rv er中创建数据库:C R EA TE DA TA BA SE dat a ba se_n am e其中,`da ta ba se_n a me`是你想要创建的数据库的名称。
2.创建表使用以下语句可以在数据库中创建表:C R EA TE TA BL Et ab le_n am e(c o lu mn1d at a_ty pe,c o lu mn2d at a_ty pe,c o lu mn3d at a_ty pe,...)其中,`ta bl e_na me`是你想要创建的表的名称,`co lu mn1`、`c ol um n2`、`c ol um n3`等是表中的列名,`d at a_ty pe`是列的数据类型。
3.查询数据使用以下语句可以从表中查询数据:S E LE C T co lu mn1,col u mn2,...F R OM ta bl e_na meW H ER Ec on di ti on其中,`co lu mn1`、`c ol um n2`等是你想要查询的列,`t ab le_na me`是你想要查询的表,`c on di ti on`是查询条件。
4.插入数据使用以下语句可以向表中插入数据:I N SE RT IN TO ta bl e_n a me(c ol um n1,c olu m n2,...)V A LU ES(v al ue1,val u e2,...)其中,`ta bl e_na me`是你想要插入数据的表,`c ol um n1`、`c ol um n2`等是你要插入的列,`va lu e1`、`v al ue2`等是要插入的值。
SQL Server存储过程的基本概念以及语法【转】存储过程的概念SQL Server提供了一种方法,它可以将一些固定的操作集中起来由SQL Server 数据库服务器来完成,以实现某个任务,这种方法就是存储过程。
存储过程是SQL语句和可选控制流语句的预编译集合,存储在数据库中,可由应用程序通过一个调用执行,而且允许用户声明变量、有条件执行以及其他强大的编程功能。
在SQL Server中存储过程分为两类:即系统提供的存储过程和用户自定义的存储过程。
可以出于任何使用SQL语句的目的来使用存储过程,它具有以下优点:可以在单个存储过程中执行一系列SQL语句。
可以从自己的存储过程内引用其他存储过程,这可以简化一系列复杂语句。
存储过程在创建时即在服务器上进行编译,所以执行起来比单个SQL语句快,而且减少网络通信的负担。
安全性更高。
创建存储过程在SQL Server中,可以使用三种方法创建存储过程:①使用创建存储过程向导创建存储过程。
②利用SQL Server 企业管理器创建存储过程。
③使用Transact-SQL语句中的CREATE PROCEDURE命令创建存储过程。
下面介绍使用Transact-SQL语句中的CREATE PROCEDURE命令创建存储过程创建存储过程前,应该考虑下列几个事项:①不能将 CREATE PROCEDURE 语句与其它SQL语句组合到单个批处理中。
②存储过程可以嵌套使用,嵌套的最大深度不能超过32层。
③创建存储过程的权限默认属于数据库所有者,该所有者可将此权限授予其他用户。
④存储过程是数据库对象,其名称必须遵守标识符规则。
⑤只能在当前数据库中创建存储过程。
⑥一个存储过程的最大尺寸为128M。
使用CREATE PROCEDURE创建存储过程的语法形式如下:QUOTE:CREATE PROC[EDURE]procedure_name[;number][;number][{@parameter data_type}[VARYING][=default][OUTPUT]][,...n]WITH{RECOMPILE|ENCRYPTION|RECOMPILE,ENCRYPTION}][FOR REPLICATION]AS sql_statement [ ...n ]用CREATE PROCEDURE创建存储过程的语法参数的意义如下:procedure_name:用于指定要创建的存储过程的名称。
number:该参数是可选的整数,它用来对同名的存储过程分组,以便用一条 DROP PROCEDURE 语句即可将同组的过程一起除去。
@parameter:过程中的参数。
在 CREATE PROCEDURE 语句中可以声明一个或多个参数。
data_type:用于指定参数的数据类型。
VARYING:用于指定作为输出OUTPUT参数支持的结果集。
Default:用于指定参数的默认值。
OUTPUT:表明该参数是一个返回参数。
例如:下面创建一个简单的存储过程productinfo,用于检索产品信息。
USE Northwindif exists(select name from sysobjectswhere name='productinfo' and type = 'p'drop procedure productinfoGOcreate procedure productinfoasselect * from productsGO通过下述sql语句执行该存储过程:execute productinfo即可检索到产品信息。
执行存储过程直接执行存储过程可以使用EXECUTE命令来执行,其语法形式如下:[[EXEC[UTE]]{ [@return_status=]{procedure_name[;number]|@procedure_name_var} [[@parameter=]{value|@variable[OUTPUT]|[DEFAULT]}[,...n][ WITH RECOMPILE ]使用 EXECUTE 命令传递单个参数,它执行 showind 存储过程,以 titles 为参数值。
showind 存储过程需要参数 (@tabname,它是一个表的名称。
其程序清单如下:EXEC showind titles当然,在执行过程中变量可以显式命名:EXEC showind @tabname = titles如果这是 isql 脚本或批处理中第一个语句,则 EXEC 语句可以省略:showind titles或者showind @tabname = titles下面的例子使用了默认参数USE NorthwindGOCREATE PROCEDURE insert_Products_1( @SupplierID_2 int,@CategoryID_3 int,@ProductName_1 nvarchar(40='无'AS INSERT INTO Products(ProductName,SupplierID,CategoryIDVALUES(@ProductName_1,@SupplierID_2,@CategoryID_3GOexec insert_Products_1 1,1Select * from Products where SupplierID=1 and CategoryID=1 GO下面的例子使用了返回参数USE NorthwindGOCREATE PROCEDURE query_products( @SupplierID_1 int,@ProductName_2 nvarchar(40 outputASselect @ProductName_2 = ProductName from productswhere SupplierID = @SupplierID_1执行该存储过程来查询SupplierID为1的产品名:declare @product nvarchar(40exec query_products 1,@product outputselect '产品名'= @productgo查看存储过程存储过程被创建之后,它的名字就存储在系统表sysobjects中,它的源代码存放在系统表syscomments中。
可以使用使用企业管理器或系统存储过程来查看用户创建的存储过程。
使用企业管理器查看用户创建的存储过程在企业管理器中,打开指定的服务器和数据库项,选择要创建存储过程的数据库,单击存储过程文件夹,此时在右边的页框中显示该数据库的所有存储过程。
用右键单击要查看的存储过程,从弹出的快捷菜单中选择属性选项,此时便可以看到存储过程的源代码。
使用系统存储过程来查看用户创建的存储过程可供使用的系统存储过程及其语法形式如下:sp_help:用于显示存储过程的参数及其数据类型sp_help [[@objname=] name]参数name为要查看的存储过程的名称。
sp_helptext:用于显示存储过程的源代码sp_helptext [[@objname=] name]参数name为要查看的存储过程的名称。
sp_depends:用于显示和存储过程相关的数据库对象sp_depends [@objname=]’object’参数object为要查看依赖关系的存储过程的名称。
sp_stored_procedures:用于返回当前数据库中的存储过程列表修改存储过程存储过程可以根据用户的要求或者基表定义的改变而改变。
使用ALTER PROCEDURE语句可以更改先前通过执行 CREATE PROCEDURE 语句创建的过程,但不会更改权限,也不影响相关的存储过程或触发器。
其语法形式如下:ALTERPROC[EDURE]procedure_name[;number][{@parameterdata_type}[VARYING][=default][OUTPUT]][,...n] [WITH{RECOMPILE|ENCRYPTION|RECOMPILE,ENCRYPTION}][FOR REPLICATION]ASsql_statement [ ...n ]重命名和删除存储过程1. 重命名存储过程修改存储过程的名称可以使用系统存储过程sp_rename,其语法形式如下:sp_rename 原存储过程名称,新存储过程名称另外,通过企业管理器也可以修改存储过程的名称。
删除存储过程删除存储过程可以使用DROP命令,DROP命令可以将一个或者多个存储过程或者存储过程组从当前数据库中删除,其语法形式如下:drop procedure {procedure} [,…n]当然,利用企业管理器也可以很方便地删除存储过程。
存储过程的重新编译在我们使用了一次存储过程后,可能会因为某些原因,必须向表中新增加数据列或者为表新添加索引,从而改变了数据库的逻辑结构。
这时,需要对存储过程进行重新编译,SQL Server 提供三种重新编译存储过程的方法:1、在建立存储过程时设定重新编译语法格式:CREATE PROCEDURE procedure_name WITH RECOMPILE AS sql_statement2、在执行存储过程时设定重编译语法格式: EXECUTE procedure_name WITH RECOMPILE3、通过使用系统存储过程设定重编译语法格式为: EXEC sp_recompile OBJECT系统存储过程与扩展存储过程1.系统存储过程系统存储过程存储在master数据库中,并以sp_为前缀,主要用来从系统表中获取信息,为系统管理员管理SQL Server提供帮助,为用户查看数据库对象提供方便。
比如用来查看数据库对象信息的系统存储过程 sp_help、显示存储过程和其它对象的文本的存储过程 sp_helptext 等。
2.扩展存储过程:扩展存储过程以 xp_为前缀,它是关系数据库引擎的开放式数据服务层的一部分,其可以使用户在动态链接库(DLL 文件所包含的函数中实现逻辑,从而扩展了 Transact-SQL 的功能,并且可以象调用 Transact-SQL 过程那样从 Transact-SQL 语句调用这些函数。
例: 利用扩展存储过程 xp_cmdshell 为一个操作系统外壳执行指定命令串,并作为文本返回任何输出。
执行代码: use master exec xp_cmdshell 'dir *.exe' 执行结果返回系统目录下的文件内容文本信息。
最后给大家举一个例子: QUOTE: /** 1、在 Northwind 数据库中,创建一个带查询参数的存储过程,要求在输入一个定购金额总额@total 时,查询超出该值的所有产品的相关信息,包括产品名称和供应商名称、单位数量、单价、以及该产品的定购金额总额,并通过一个输出参数返回满足查询条件的产品数 **/ IF exists (select * from SysObjects where name='more_than_total' and type='p' drop procedure more_than_total go CREATE PROCEDURE More_Than_Total @total money = 0 AS Declare @amount smallint BEGIN select distinct P.productName, S.contactName, P.UnitPrice from Products P inner join [order Details] Oon p.productID=o.productID inner join suppliers s on p.supplierID=s.SupplierID where O.productID in (select productID from [order Details] group by productId having sum(quantity*unitprice>@total END GO。