stata上机实验第五讲——面板数据的处理..教学内容
- 格式:ppt
- 大小:83.00 KB
- 文档页数:40

面板数据的常见处理面板数据(Panel Data)是一种涉及多个个体(cross-section units)和多个时间点(time periods)的数据结构。
它在经济学、社会科学和其他领域中被广泛应用。
处理面板数据需要采取一系列的方法和技巧,以确保数据的准确性和可靠性。
下面将介绍面板数据的常见处理方法和步骤。
一、面板数据的类型面板数据可以分为两种类型:平衡面板数据和非平衡面板数据。
1. 平衡面板数据:每个个体在每个时间点都有观测值,数据完整且连续。
2. 非平衡面板数据:个体在某些时间点上可能没有观测值,数据不完整或不连续。
二、面板数据的处理步骤1. 数据清洗和准备面板数据的处理首先需要进行数据清洗和准备工作,包括以下步骤:- 去除缺失值:对于非平衡面板数据,需要检查并去除缺失值,确保数据的完整性和连续性。
- 数据排序:根据个体和时间变量对数据进行排序,以便后续处理和分析。
- 数据转换:根据需要,对数据进行转换,如对数转换、差分等,以满足模型的要求。
2. 面板数据的描述性统计分析描述性统计分析是对面板数据的基本特征进行总结和分析,包括以下内容:- 平均值和标准差:计算每个变量在不同时间点上的平均值和标准差,了解变量的分布情况。
- 相关性分析:计算不同变量之间的相关系数,了解变量之间的关系。
- 可视化分析:绘制折线图、散点图等可视化图形,展示变量的变化趋势和关系。
3. 面板数据的面板单位根检验面板单位根检验是判断面板数据是否存在单位根(unit root)的一种方法,常用的检验方法有以下几种:- Levin-Lin-Chu (LLC)检验:用于检验面板数据是否存在单位根。
- Fisher ADF检验:用于检验面板数据是否存在单位根。
- Im-Pesaran-Shin (IPS)检验:用于检验面板数据是否存在单位根。
4. 面板数据的固定效应模型固定效应模型是用于分析面板数据的一种方法,它考虑了个体固定效应对数据的影响。
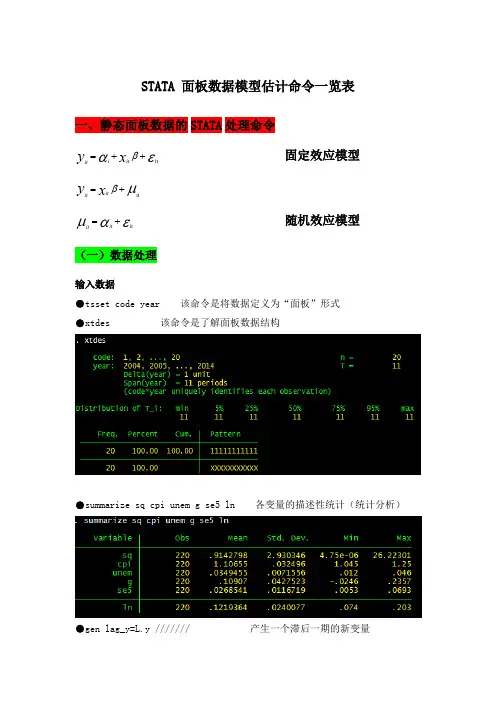
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
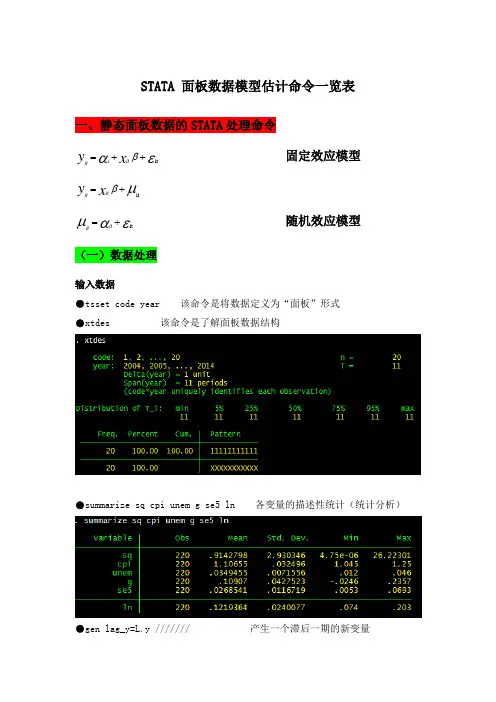
STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。

第十三章面板数据的处理第十三章面板数据的处理一、面板数据的定义、意义和种类面板数据是调查经历一段时间的同样的横截面数据,具有空间和时间的两种特性。
它还有其他一些名称,诸如混合数据,纵列数据,平行数据等,这些名字都包含了横截面单元在一段时期的活动。
面板数据的优点在于:1.提供了更有价值的数据,变量之间增加了多变性和减少了共线性,并且提高了自由度和有效性。
2.能够更好地检测和度量单纯使用横截面数据或时间序列数据无法观测到的影响。
3.能够对更复杂的行为模型进行研究。
形如01122it it it it Y X X u βββ=+++其中,i 表示第i 个横截面单元,t 表示第t 年。
一般,我们用i 来表示横截面标识符,用t 表示时间标识符。
假设N 个横截面单元的观测次数相同,我们称之为平衡面板,反之,称为非平衡面板。
一般假设X 是非随机的,误差项遵从经典假设。
二、面板数据回归模型的类型与估计方法(一)面板数据回归模型的类型对于面板数据模型 i t i i t i Y X u αβ=++,可能的情形主要有如下几种。
1.所有系数都不随时间和个体而变化在横截面上无个体影响、无结构变化,即i j αα=,i j ββ=。
则普通最小二乘估计给出了和的一致有效估计。
相当于将多个时期的截面数据放在一起作为样本数据。
it it it Y X u αβ=++。
2.变截距模型在横截面上个体影响不同,个体影响表现为在模型中被忽略的反映个体差异的影响,又分为固定效应和随机效应两种。
it i it it Y X u αβ=++3.变系数模型除了存在个体影响之外,在横截面上还存在变化的经济结构,因而结构参数在不同横截面单位是不同的。
i j αα≠,i j ββ≠。
it i it i it Y X u αβ=++。
看到面板数据之后,如何确定属于哪一种类型呢?用F 检验假设1:斜率在不同的横截面样本点上和时间上都相同,但截距不相同,即情形2。





Chp8 Panel Data一直想把看Panel模型时的感悟整理成笔记,但终因懒惰而未能成行。
今天终于下决心开了个头,可遗憾的是,这个开头却是从本章的结尾写起,因为这一部分最容易写。
不过,凡事有了好的开头基本上也算成功一半了,所以后面的整理工作还要有劳各位的督促。
文中的不足还望不吝指出。
8.1简介8.2一般模型8.2.1固定效应模型(Fixed Effect Model)8.2.2随机效应模型(Random Effect Model)8.3自相关性8.4动态Panel Data8.5门槛Panel Data8.6非稳定Panel Data及协整8.7Panel V AR8.8Stata8.0实现在介绍了Panel Data的基本理论后,下面我们介绍如何使用STATA8.0软件包来实现模型的估计。
前面我们已经提到,Panel Data具有如下数据存储格式:company year invest mvalue11951755.94833.011952891.24924.9119531304.46241.7119541486.75593.621951588.22289.521952645.52159.421953641.02031.321954459.32115.531951135.21819.431952157.32079.731953179.52371.631954189.62759.9其中,变量company和year分别为截面变量和时间变量。
显然,通过这两个变量我们可以非常清楚地确定panel data的数据存储格式。
因此,在使用STATA8.0估计模型之前,我们必须告诉它截面变量和时间变量分别是什么,所用的命令为tsset1,命令格式如下:tsset panelvar timevar这里需要指出的是,由于Panel Data本身兼具截面数据和时间序列二者的特性,所以对时间序列进行操作的运算同样可以应用到Panel Data身上。
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。

stata面板数据标准化Stata面板数据标准化。
在进行面板数据分析时,数据的标准化是非常重要的。
标准化可以帮助我们消除不同变量之间的量纲差异,使得数据更具有可比性,从而更好地进行分析和解释。
本文将介绍如何使用Stata对面板数据进行标准化处理。
1. 数据准备。
在进行标准化之前,首先需要准备好面板数据。
面板数据是指在时间和个体(或者空间)两个维度上进行观测的数据,通常包括了多个时间点和多个个体的观测数值。
在Stata中,可以使用panel data命令来导入和管理面板数据。
2. 变量标准化。
在Stata中,可以使用egen命令来创建标准化变量。
假设我们有一个名为income的变量,我们可以使用以下命令来对其进行标准化处理:```stata。
egen income_std = std(income)。
```。
这条命令将创建一个名为income_std的新变量,该变量是income变量的标准化值。
标准化后的变量具有均值为0,标准差为1的特性,从而消除了原始数据的量纲差异。
3. 面板数据标准化。
对于面板数据,我们通常需要对每个个体(或者空间单位)在不同时间点上的变量进行标准化处理。
在Stata中,可以使用by命令来实现对每个个体的标准化处理。
假设我们有一个名为gdp的变量,我们可以使用以下命令来对其进行面板数据标准化处理:```stata。
by id: egen gdp_std = std(gdp)。
```。
这条命令将创建一个名为gdp_std的新变量,该变量是gdp变量在每个个体上的标准化值。
使用by命令可以确保我们对每个个体的数据进行独立的标准化处理,从而保证了数据的准确性和可比性。
4. 数据检验。
在进行标准化处理之后,我们需要对数据进行检验,确保标准化后的数据符合我们的分析要求。
在Stata中,可以使用sum命令来查看标准化后变量的均值和标准差等统计量,以及使用histogram命令来绘制标准化后变量的分布直方图,从而对数据进行可视化检验。
stata⾯板数据计量知识及参考资料计量知识:1、横截⾯数据、时间序列、⾯板数据:横截⾯数据是在同⼀时间,不同统计单位相同统计指标组成的数据列。
横截⾯数据是按照统计单位排列的。
因此,横截⾯数据不要求统计对象及其范围相同,但要求统计的时间相同。
也就是说必须是同⼀时间截⾯上的数据。
,Pr i t emium ,1Pr i t emiun -H A Turnover Tutnover A H Size +/H A H SO SO +22/A H σσDummy时间序列数据:在不同时间点上收集到的数据,这类数据反映了某⼀事物、现象等随时间的变化状态或程度。
⾯板数据:是截⾯数据与时间序列数据综合起来的⼀种数据类型。
其有时间序列和截⾯两个维度,当这类数据按两个维度排列时,是排在⼀个平⾯上,与只有⼀个维度的数据排在⼀条线上有着明显的不同,整个表格像是⼀个⾯板,所以把panel data 译作“⾯板数据”。
举例:如:城市名:北京、上海、重庆、天津的GDP 分别为10、11、9、8(单位亿元)。
这就是截⾯数据,在⼀个时间点处切开,看各个城市的不同就是截⾯数据。
如:2000、2001、2002、2003、2004各年的北京市GDP 分别为8、9、10、11、12(单位亿元)。
这就是时间序列,选⼀个城市,看各个样本时间点的不同就是时间序列。
如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP 分别为:北京市分别为8、9、10、11、12;上海市分别为9、10、11、12、13;天津市分别为5、6、7、8、9;重庆市分别为7、8、9、10、11(单位亿元)。
这就是⾯板数据。
*变量合并2、截⾯数据,多重共线性和异⽅差都需要考虑,截⾯数据不需要检测DW 值!你做出来R ⽅⽐较⼩,可能原因是你的回归⽅程中没有纳⼊关键变量,建议你采⽤逐步回归⽅法,以提⾼R ⽅!对于截⾯数据来说,R ⽅⼀般在0.7左右都能接受!相关分析不是必要做的,在模型中加⼊什么变量进⾏回归,主要是依据前期的理论分析和研究⽬的!仅就计量回归⽽⾔,这些步骤只是告诉你,⾃变量与因变量的相关性会影响变量在模型中的显著性,⽽⾃变量间的相关则会带来多重共线性!3、线性相关,也叫⾃相关:可以⽤来看x和y的相关性,常⽤来考察各个x ⾃变量之间是否存在相关关系。
最全Stata⾯板数据学习⼿册来源:本⽂授权转载⾃数量经济学本⽂包括静态与动态⾯板数据处理⽅法,包含hausman检验,固定效应检验,随机效应检验,异⽅差检验、相关检验,⾯板logit与⾯板probit模型、⾯板泊松模型、⾯板负⼆项模型等众多⼲货内容,欢迎阅读。
本⽂⽬录⼀、静态⾯板数据●数据处理●模型的筛选和检验1、检验个体效应(混合效应还是固定效应)2、检验时间效应(混合效应还是随机效应)3、检验固定效应模型or随机效应模型(检验⽅法:Hausman检验)●模型的筛选和检验1、固定效应估计2、随机效应估计省略3、时间固定效应(以上分析主要针对的是个体效应)●异⽅差和⾃相关检验1、异⽅差检验(组间异⽅差)2、序列相关检验3、“异⽅差—序列相关”稳健型标准误4、截⾯相关检验5、“异⽅差—序列相关—截⾯相关”稳健型标准误⼆、动态⾯板数据三、⾯板logit与⾯板probit模型四、⾯板泊松模型五、⾯板负⼆项模型六、⾯板Tobit模型七、⾯板⼯具变量法⼋、⾯板随机前沿模型⼀.静态⾯板数据的STATA处理命令(⼀)数据处理输⼊数据use 'E:\stata\data\FDI.dta', cleartsset code year 该命令是将数据定义为“⾯板”形式xtdes 该命令是了解⾯板数据结构summarize lngdp lnfdi lnie lnex lnim lnci lngp各变量的描述性统计(统计分析)拓展命令:gen lag_y=L.y 产⽣⼀个滞后⼀期的新变量gen F_y=F.y 产⽣⼀个超前项的新变量gen D_y=D.y 产⽣⼀个⼀阶差分的新变量gen D2_y=D2.y 产⽣⼀个⼆阶差分的新变量(⼆)模型的筛选和检验1、检验个体效应(混合效应还是固定效应)(原假设:使⽤OLS混合模型)xtreg lngdp lnfdi lnie lnex lnim lnci lngp,fe对于固定效应模型⽽⾔,回归结果中最后⼀⾏汇报的F统计量便在于检验所有的个体效应整体上显著。
面板数据的常见处理引言概述:面板数据是经济学和社会科学研究中常用的一种数据类型,它包含了多个单位(如个人、家庭、企业等)在多个时间点上的观测值。
面板数据的处理对于研究者来说非常重要,因为它可以提供更准确的分析结果和更丰富的信息。
本文将介绍面板数据的常见处理方法,包括数据清洗、平衡性检验、面板单位的固定效应、时间效应和面板单位的随机效应。
一、数据清洗1.1 缺失值处理面板数据中常常存在缺失值,研究者需要采取适当的方法处理这些缺失值。
一种常见的方法是使用插补技术,如线性插值或多重插补来填补缺失值。
另一种方法是通过删除存在缺失值的观测值来处理缺失值。
1.2 异常值处理在面板数据中,有时会存在一些异常值,这些异常值可能会对分析结果造成影响。
研究者可以通过观察数据的分布情况,使用统计方法或专业知识来识别和处理异常值。
一种常见的方法是使用箱线图来检测异常值,并将其替换为合理的值。
1.3 数据平滑面板数据中的观测值通常包含噪声,为了提高数据的质量,研究者可以使用平滑技术来减少噪声的影响。
常见的平滑方法包括移动平均法和指数平滑法,这些方法可以帮助研究者更好地理解数据的趋势和变化。
二、平衡性检验2.1 时间平衡性检验在面板数据中,观测时间点可能不同,因此需要进行时间平衡性检验。
研究者可以通过计算每个面板单位的观测时间点数目来检验时间平衡性。
如果观测时间点数目不同,则需要采取相应的方法进行处理,如删除时间点较少的面板单位或使用面板单位的固定效应模型。
2.2 个体平衡性检验除了时间平衡性,面板数据还需要满足个体平衡性。
个体平衡性是指每个面板单位都需要有相同的观测时间点。
研究者可以通过计算每个面板单位的观测时间点数目来检验个体平衡性。
如果观测时间点数目不同,则需要采取相应的方法进行处理,如删除观测时间点较少的面板单位或使用面板单位的固定效应模型。
2.3 面板平衡性检验在面板数据中,观测时间点和面板单位都需要满足平衡性。
面板数据的常见处理面板数据(Panel Data)是一种包含了多个个体(cross-sectional units)和多个时间点(time periods)的数据结构。
在面板数据中,个体之间存在交叉关系,时间序列数据也同时存在。
面板数据的常见处理方法包括数据清洗、描述统计分析、面板数据模型估计等。
一、数据清洗1. 缺失值处理:面板数据中往往存在缺失值,可以采用删除、插补或者不处理等方法进行处理。
删除缺失值可能会导致样本减少,插补缺失值可能会引入估计误差,因此需要根据实际情况选择合适的方法。
2. 异常值处理:对于异常值,可以进行剔除或者修正。
剔除异常值可能会影响样本的代表性,修正异常值可能会引入估计误差,需要根据实际情况进行判断。
3. 数据标准化:对于不同单位的变量,可以进行标准化处理,使得它们具有可比性。
常见的标准化方法包括Z-score标准化和Min-Max标准化。
二、描述统计分析1. 平均值和标准差:计算面板数据中各个变量的平均值和标准差,用于描述变量的集中趋势和离散程度。
2. 相关系数:计算变量之间的相关系数,用于描述变量之间的线性关系。
3. 面板数据的趋势分析:通过绘制面板数据的时间序列图和趋势图,分析数据的时间变化趋势。
三、面板数据模型估计1. 固定效应模型:面板数据中可能存在个体固定效应,可以使用固定效应模型进行估计。
固定效应模型控制个体固定效应,使得估计结果更加准确。
2. 随机效应模型:面板数据中可能存在个体随机效应,可以使用随机效应模型进行估计。
随机效应模型考虑个体随机效应的影响,更加适合于面板数据的分析。
3. 差分法:差分法是一种常见的面板数据分析方法,通过计算变量的差分,消除个体固定效应和个体随机效应,从而得到更加准确的估计结果。
以上是面板数据的常见处理方法,通过数据清洗、描述统计分析和面板数据模型估计等步骤,可以对面板数据进行全面的分析和解释。
在实际应用中,根据具体问题的需求,选择合适的处理方法,进行准确的数据分析和判断。