基于Tingxml的XML数据解析方法研究
- 格式:pdf
- 大小:159.29 KB
- 文档页数:2

tinyxml用法TinyXML是一个用于解析和生成XML文件的C++库。
它提供了一组简单且易于使用的API,可将XML文档解析为树状结构,让用户可以通过遍历这棵树来获取和修改XML文件中的内容。
本文将详细介绍TinyXML的使用方法,包括如何解析XML文件、访问节点、修改节点内容以及生成XML 文件等。
一、解析XML文件1.引入头文件和命名空间要使用TinyXML,首先需要引入头文件tinyxml.h:#include <tinyxml.h>然后在代码中使用命名空间:using namespace std;using namespace tinyxml2;2.打开并解析XML文件创建一个XML文档对象以及一个错误代码对象,然后调用LoadFile(方法打开并解析XML文件:XMLDocument doc;doc.LoadFile("example.xml");3.获取根节点使用RootElement(方法获取根节点:XMLElement* root = doc.RootElement(;4.遍历子节点可以使用FirstChildElement(方法获取第一个子节点,然后使用NextSiblingElement(方法依次获取下一个兄弟节点,直到遍历完所有子节点:for (XMLElement* child = root->FirstChildElement(; child != NULL; child = child->NextSiblingElement()//对子节点进行操作5.获取节点属性和内容使用Attribute(方法获取节点的属性值,使用GetText(方法获取节点的文本内容:const char* attributeValue = node->Attribute("属性名");const char* textContent = node->GetText(;二、访问和修改节点1.创建新节点可以使用NewElement(方法创建一个新节点,然后将其添加到指定节点的子节点列表中:XMLElement* newNode = doc.NewElement("节点名称");parentNode->InsertEndChild(newNode);2.修改节点属性和内容使用SetAttribute(方法设置节点的属性值,使用SetText(方法设置节点的文本内容:node->SetAttribute("属性名", "属性值");node->SetText("文本内容");3.删除节点使用DeleteChildren(方法删除节点的所有子节点:node->DeleteChildren(;4.复制节点可以使用CloneNode(方法复制一个节点:XMLElement* newNode = node->CloneNode(true);三、生成XML文件1.创建一个XML文档对象XMLDocument doc;2.创建根节点使用NewElement(方法创建一个根节点并将其添加到文档中:XMLElement* root = doc.NewElement("根节点名称");doc.InsertEndChild(root);3.创建子节点使用NewElement(方法创建一个子节点并将其添加到根节点的子节点列表中:XMLElement* child = doc.NewElement("子节点名称");root->InsertEndChild(child);4.创建属性使用SetAttribute(方法设置节点的属性值:child->SetAttribute("属性名", "属性值");5.创建文本内容使用SetText(方法设置节点的文本内容:child->SetText("文本内容");6.保存XML文件使用SaveFile(方法将XML文档保存为文件:doc.SaveFile("example.xml");以上就是TinyXML库的基本用法。
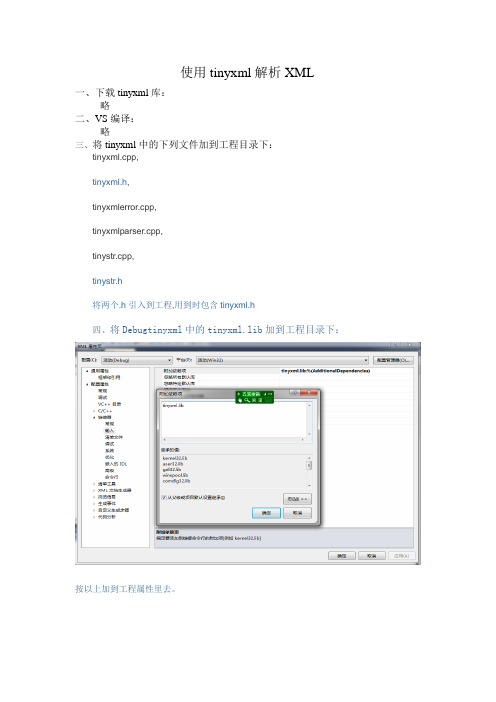
使用tinyxml解析XML一、下载tinyxml库:略二、VS编译:略三、将tinyxml中的下列文件加到工程目录下:tinyxml.cpp,tinyxml.h,tinyxmlerror.cpp,tinyxmlparser.cpp,tinystr.cpp,tinystr.h将两个.h引入到工程,用到时包含tinyxml.h四、将Debugtinyxml中的tinyxml.lib加到工程目录下:按以上加到工程属性里去。
*注*:std.xml是工程目录下的文件:<Class name="计算机软件班"><Students><student name="张三" studentNo="13031001" sex="男" age="22"> <phone>88208888</phone><address>西安市太白南路二号</address></student><student name="李四" studentNo="13031002" sex="男" age="20"> <phone>88206666</phone><address>西安市光华路</address></student><student name="王五" studentNo="13031003" sex="男" age="23"> <phone>8820777</phone><address>西安市光华2路</address></student></Students></Class>测试代码:TiXmlDocument* myDocument = new TiXmlDocument();//创洹?建¨了?一?个?对?象ómyDocument->LoadFile("std.xml");//读á取?本?目?录?下?文?件tTiXmlElement* rootElement = myDocument->RootElement(); //ClassTiXmlElement* studentsElement = rootElement->FirstChildElement(); //所ù有瓺的?StudentsTiXmlElement* studentElement = studentsElement->FirstChildElement(); //第台?一?个?Studentwhile ( studentElement ){TiXmlAttribute* attributeOfStudent = studentElement->FirstAttribute(); //获?得?student的?属?性?while ( attributeOfStudent ){std::cout<< attributeOfStudent->Name() << " : "<< attributeOfStudent->Value() << std::endl;attributeOfStudent = attributeOfStudent->Next();}TiXmlElement* phoneElement= studentElement->FirstChildElement();//获?得?student 的?phone元a素?std::cout << "phone" << " : " << phoneElement->GetText() << std::endl;TiXmlElement* addressElement = phoneElement->NextSiblingElement();//下?一?个?addressstd::cout << "address" << " : " << phoneElement->GetText() << std::endl;studentElement = studentElement->NextSiblingElement();//下?一?个?student }。


这次使用了TinyXML后,觉得这个东西真是不错,于是将使用方法坐下总结来和大家分享。
该解析库在开源网站()上有下载,在本Blog也提供下载(下载TinyXML)TinyXML是一个开源的解析XML的解析库,能够用于C++,能够在Windows或Linux 中编译。
这个解析库的模型通过解析XML文件,然后在内存中生成DOM模型,从而让我们很方便的遍历这课XML树。
注:DOM模型即文档对象模型,是将整个文档分成多个元素(如书、章、节、段等),并利用树型结构表示这些元素之间的顺序关系以及嵌套包含关系(理解html语言的读者会很容易理解这种树状模型)。
如下是一个XML片段:<Persons><Person ID="1"><name>周星星</name><age>20</age></Person><Person ID="2"><name>白晶晶</name><age>18</age></Person></Persons>在TinyXML中,根据XML的各种元素来定义了一些类:TiXmlBase:整个TinyXML模型的基类。
TiXmlAttribute:对应于XML中的元素的属性。
TiXmlNode:对应于DOM结构中的节点。
TiXmlComment:对应于XML中的注释。
TiXmlDeclaration:对应于XML中的申明部分,即<?versiong="1.0" ?>。
TiXmlDocument:对应于XML的整个文档。
TiXmlElement:对应于XML的元素。
TiXmlText:对应于XML的文字部分。
TiXmlUnknown:对应于XML的未知部分。
TiXmlHandler:定义了针对XML的一些操作。

C++使⽤TinyXML解析XML⽬录1.介绍2.TinyXML配置3.TinyXML读取和保存⽂件3.1 读取xml⽂件3.2 读取xml参数3.3 保存xml参数到⽂本3.4 保存xml参数到临时变量4.TinyXML增删改查4.1 增4.2 删4.3 改4.4 查5.⼀个完整例⼦1.介绍在TinyXML中,根据XML的各种元素来定义了⼀些类:TiXmlBase:整个TinyXML模型的基类。
TiXmlAttribute:对应于XML中的元素的属性。
TiXmlNode:对应于DOM结构中的节点。
TiXmlComment:对应于XML中的注释TiXmlDeclaration:对应于XML中的申明部分,即<?versiong="1.0" ?>。
TiXmlDocument:对应于XML的整个⽂档。
TiXmlElement:对应于XML的元素。
TiXmlText:对应于XML的⽂字部分TiXmlUnknown:对应于XML的未知部分。
TiXmlHandler:定义了针对XML的⼀些操作。
根据下图来说明常⽤的类对应的⽂本格式:<?xml version="1.0" ?> //TiXmlDeclaration,声明<MyApp> //TiXmlElement,元素<!-- Settings for MyApp -->//TiXmlComment,注释<Messages>//TiXmlElement,元素<Welcome>Welcome to MyApp</Welcome>//<Welcome>是元素TiXmlElement ,“Welcome to MyApp”是TiXmlText,⽂本<Farewell>Thank you for using MyApp</Farewell>//同上</Messages><Windows>//TiXmlElement,元素<Window name="MainFrame" x="5" y="15" w="400" h="250" />// Window是元素TiXmlElement ,name、x、y、h是TiXmlAttribute</Windows><Connection ip="192.168.0.1" timeout="123.456000" /></MyApp>TinyXML是个解析库,主要由DOM模型类(TiXmlBase、TiXmlNode、TiXmlAttribute、TiXmlComment、TiXmlDeclaration、TiXmlElement、TiXmlText、TiXmlUnknown)和操作类(TiXmlHandler)构成。

TinyXml使用指南一、 TinyXml的特点TinyXml是一个基于DOM模型的、非验证的轻量级C++解释器。
1. SAX和DOM目前XML的解析主要有两大模型:SAX和DOM。
其中SAX是基于事件的,其基本工作流程是分析XML文档,当发现了一个新的元素时,产生一个对应事件,并调用相应的用户处理函数。
这种方式占用内存少,速度快,但用户程序相应得会比较复杂。
而DOM(文档对象模型),则是在分析时,一次性的将整个XML文档进行分析,并在内存中形成对应的树结构,同时,向用户提供一系列的接口来访问和编辑该树结构。
这种方式占用内存大,速度往往慢于SAX,但可以给用户提供一个面向对象的访问接口,对用户更为友好。
2. 验证和非验证对于一个特定的XML文档而言,其正确性分为两个层次。
首先是其格式应该符合XML的基本格式要求,比如第一行要有声明,标签的嵌套层次必须前后一致等等,符合这些要求的文件,就是一个合格的XML文件,称作well-formatted。
但除此之外,一个XML文档因其内容的不同还必须在语义上符合相应的标准,这些标准由相应的DTD 文件或者Schema文件来定义,符合了这些定义要求的XML文件,称作valid。
因此,解析器也分为两种,一种是验证的,即会跟据XML文件中的声明,用相应的DTD文件对XML文件进行校验,检查它是否满足DTD文件的要求。
另一种是忽略DTD文件,只要基本格式正确,就可以进行解析。
就我所知,验证的解析器通常都是比较重量级的。
TinyXml不支持验证,但是体积很小,用在解析格式较为简单的XML文件,比如配置文件时,特别的合适。
二、 TinyXml的构建和使用1. 获取TinyXml首页在/tinyxml/index.html,从这里可以找到最新版本的源代码,目前的版本是2.3.4。
2.构建TinyXml在构建时可以选择是否支持STL,选择的话,则可以使用std::string,所以通常应该打开这个选项。
Linux下TinyXml库使⽤⽅法及实例解析 TinyXml库下载,我保存在⾃⼰的⽹盘中,可⾃⾏下载:链接:提取码:e50y⾸先介绍⼀下TinyXml类XmlBase:整个TinyXML模型的基类;XmlAttribute:对应于XML中的元素的属性;XmlComment:对应于XML中的注释,评论类;XmlDeclaration:对应于XML中的申明部分,即<?versiong="1.0" ?>;XmlElement:对应于XML的元素;XmlDocument:对应于XML的整个⽂档;XmlText:对应于XML的⽂字部分;XmlUnknown:对应于XML的未知部分;XmlHandler:定义了针对XML的⼀些操作;类之间的关系如下:需要注意的是:元素⼀定的节点,节点不⼀定是元素(TiXmlElement类)⼀.加载XML⽂件//加载XML⽂件TiXmlDocument doc;if(!doc.LoadFile("test.xml")){qDebug()<<"加载XML⽂件失败";const char *errorStr = doc.ErrorDesc();qDebug()<<errorStr; //打印失败原因;}⼆.获取XML 的根节点//加载XML⽂件TiXmlDocument doc;if(!doc.LoadFile("test.xml")){qDebug()<<"加载XML⽂件失败";const char *errorStr = doc.ErrorDesc();qDebug()<<errorStr; //打印失败原因;}else{//获取根节点元素TiXmlElement *root = doc.FirstChildElement();}三.常⽤⽅法TiXmlDocument doc;doc.LoadFile("test.xml");TiXmlElement *root = doc.FirstChildElement(); //获取根节点元素QString ElementName = root->Value(); //获取元素名bool Children = root->NoChildren(); //判断该元素是否有⼦元素返回true 有,false 没有TiXmlElement *child = root->FirstChildElement(); //获取root元素下的第⼀个⼦元素child = root->FirstChildElement("major"); //获取root元素的⼦元素指定元素名字(major)TiXmlElement *brother = child->NextSiblingElement(); //获取child元素的下⼀个兄弟元素brother = child->NextSiblingElement("specVersion"); //获取child元素的兄弟元素指定元素名字(specVersion)QString text = brother->GetText(); //获取brother元素的值TiXmlAttribute *Attribute = brother->FirstAttribute(); //获取brother元素的第⼀个属性QString AttributeName = Attribute->Name(); //获取Attribute属性的名字QString AttributeValue = Attribute->Value(); //获取Attribute属性的值AttributeValue = brother->Attribute("AttributeName"); //获取brother的属性名为(AttributeName)的值TiXmlDocument *myDocument = new TiXmlDocument(); //创建⼀个XML⽂件TiXmlDeclaration *pDeclaration=new TiXmlDeclaration("1.0","UTF-8",""); //创建xml⽂件头(<?xml version="1.0" encoding="UTF-8" ?>)myDocument->LinkEndChild(pDeclaration); //加⼊将xml⽂件头加⼊⽂档中TiXmlElement *BUSINESS=new TiXmlElement("BUSINESS"); //创建⼀个元素节点myDocument->LinkEndChild(BUSINESS); //加⼊BUSINESS元素节点到⽂档中TiXmlElement *COUNTRY = new TiXmlElement("COUNTRY"); //创建两个节点TiXmlElement *PLANET = new TiXmlElement("PLANET");BUSINESS->LinkEndChild(PLANET); //将新建的节点加到BUSINESS下⼀级BUSINESS->LinkEndChild(COUNTRY);TiXmlText *PLANETtxt = new TiXmlText("one"); //添加节点内的⽂本TiXmlText *COUNTRYtxt = new TiXmlText("china");COUNTRY->LinkEndChild(COUNTRYtxt);PLANET->LinkEndChild(PLANETtxt);myDocument->SaveFile("test.xml"); //保存xml下⾯介绍⼀个实例解析使⽤TinyXML库进⾏解析时,只需要将其中的6个⽂件拷贝到项⽬中就可以直接使⽤了,这六个⽂件是:tinyxml.h、tinystr.h、tinystr.cpp、tinyxml.cpp、tinyxmlerror.cpp、tinyxmlparser.cpp;XML⽂件如下---test.xml1 <School name="软件学院">2 <Class name = "C++">3 <Student name="tinyxml" number="123">4 <email>tinyxml@</email>5 <address>中国</address>6 </Student>7 <Student name="jsoncpp" number="456">8 <email>jsoncpp@</email>9 <address>美国</address>10 </Student>1112 </Class>1314 </School>~解析实例代码为:readxml.cpp1 #include<iostream>2 #include"tinyxml.h"3 #include<string>45using namespace std;67int main()8 {9const char * xmlFile = "test.xml";10 TiXmlDocument doc;11if(doc.LoadFile(xmlFile)){12 doc.Print();13 }else{14 cout << "can not parse xml school" << endl;1516 }17 TiXmlElement* rootElement = doc.RootElement();18 TiXmlElement* classElement = rootElement->FirstChildElement();19 TiXmlElement* studentElement = classElement->FirstChildElement();2021for(; studentElement != NULL; studentElement = studentElement->NextSiblingElement()){22 TiXmlAttribute* attribute0fStudent = studentElement->FirstAttribute();23for(; attribute0fStudent != NULL; attribute0fStudent = attribute0fStudent->Next()){24 cout << attribute0fStudent->Name() << " : " << attribute0fStudent->Value() << endl ;25 }26 TiXmlElement* studentContactElement = studentElement->FirstChildElement();27for(; studentContactElement != NULL; studentContactElement = studentContactElement->Ne xtSiblingElement()){28string contactType = studentContactElement->Value();29string contactValue = studentContactElement->GetText();30 cout << contactType << " : " << contactValue << endl;31 }32 }33return0;34 }35~如下为我⼯程下的⽂件csc105@csc105:~/workspace/configure-the-lower-computer/zmqcore/test_t/template/tinyxml$ lsreadxml test.xml tinystr.h tinyxmlerror.cpp tinyxmlparser.cppreadxml.cpp tinystr.cpp tinyxml.cpp tinyxml.h运⾏执⾏⽂件,解析结果为:csc105@csc105:~/workspace/configure-the-lower-computer/zmqcore/test_t/template/tinyxml$ ./readxml <School name="软件学院"><Class name="C++"><Student name="tinyxml" number="123"><email>tinyxml@</email><address>中国</address></Student><Student name="jsoncpp" number="456"><email>jsoncpp@</email><address>美国</address></Student></Class></School>name : tinyxmlnumber : 123email : tinyxml@address : 中国name : jsoncppnumber : 456email : jsoncpp@address : 美国到此,完成了XML 实例的解析最后感谢原博主:https:///qq_26374395/article/details/80171906。
C++使⽤TinyXML解析XML⽂件1.介绍 读取和设置xml配置⽂件是最常⽤的操作,TinyXML是⼀个开源的解析XML的C++解析库,能够在Windows或Linux中编译。
这个解析库的模型通过解析XML⽂件,然后在内存中⽣成DOM模型,从⽽让我们很⽅便的遍历这棵XML树。
下载TinyXML的⽹址: 使⽤TinyXML只需要将其中的6个⽂件拷贝到项⽬中就可以直接使⽤了,这六个⽂件是:tinyxml.h、tinystr.h、tinystr.cpp、tinyxml.cpp、tinyxmlerror.cpp、tinyxmlparser.cpp。
2.读取XML⽂件如读取⽂件a.xml:<ToDo><Item priority="1"><bold>Book store!</bold></Item><Item priority="2">book1</Item><Item priority="2">book2</Item></ToDo>读取代码如下:1 #include "tinyxml.h"2 #include <iostream>3 #include <string>45using namespace std;67enum SuccessEnum {FAILURE, SUCCESS};89 SuccessEnum loadXML()10 {11 TiXmlDocument doc;12if(!doc.LoadFile("a.xml"))13 {14 cerr << doc.ErrorDesc() << endl;15return FAILURE;16 }1718 TiXmlElement* root = doc.FirstChildElement();19if(root == NULL)20 {21 cerr << "Failed to load file: No root element." << endl;22 doc.Clear();23return FAILURE;24 }2526for(TiXmlElement* elem = root->FirstChildElement(); elem != NULL; elem = elem->NextSiblingElement())27 {28string elemName = elem->Value();29const char* attr;30 attr = elem->Attribute("priority");31if(strcmp(attr,"1")==0)32 {33 TiXmlElement* e1 = elem->FirstChildElement("bold");34 TiXmlNode* e2=e1->FirstChild();35 cout<<"priority=1\t"<<e2->ToText()->Value()<<endl;3637 }38else if(strcmp(attr,"2")==0)39 {40 TiXmlNode* e1 = elem->FirstChild();41 cout<<"priority=2\t"<<e1->ToText()->Value()<<endl;42 }43 }44 doc.Clear();45return SUCCESS;46 }4748int main(int argc, char* argv[])49 {50if(loadXML() == FAILURE)51return1;52return0;53 }View Code3.⽣成XML⽂件如⽣成⽂件b.xml如下所⽰:<root><Element1 attribute1="some value" /><Element2 attribute2="2" attribute3="3"><Element3 attribute4="4" />Some text.</Element2></root>⽣成上⾯b.xmlL⽂件代码如下:1 #include "tinyxml.h"2 #include <iostream>3 #include <string>4using namespace std;56enum SuccessEnum {FAILURE, SUCCESS};78 SuccessEnum saveXML()9 {10 TiXmlDocument doc;1112 TiXmlElement* root = new TiXmlElement("root");13 doc.LinkEndChild(root);1415 TiXmlElement* element1 = new TiXmlElement("Element1");16 root->LinkEndChild(element1);1718 element1->SetAttribute("attribute1", "some value");192021 TiXmlElement* element2 = new TiXmlElement("Element2"); ///元素22 root->LinkEndChild(element2);2324 element2->SetAttribute("attribute2", "2");25 element2->SetAttribute("attribute3", "3");262728 TiXmlElement* element3 = new TiXmlElement("Element3");29 element2->LinkEndChild(element3);3031 element3->SetAttribute("attribute4", "4");3233 TiXmlText* text = new TiXmlText("Some text."); ///⽂本34 element2->LinkEndChild(text);353637bool success = doc.SaveFile("b.xml");38 doc.Clear();3940if(success)41return SUCCESS;42else43return FAILURE;44 }4546int main(int argc, char* argv[])47 {48if(saveXML() == FAILURE)49return1;50return0;51 }View Code4.重要函数或类型的说明 (1)FirstChildElement(const char* value=0):获取第⼀个值为value的⼦节点,value默认值为空,则返回第⼀个⼦节点。
xml文件解析方法XML文件解析方法引言:XML(可扩展标记语言)是一种用于存储和传输数据的标记语言,它具有良好的可读性和灵活性,被广泛应用于数据交换和配置文件等领域。
在处理XML文件时,解析是必不可少的环节。
本文将介绍几种常用的XML文件解析方法,包括DOM、SAX和StAX。
一、DOM解析方法DOM(文档对象模型)是一种将整个XML文件以树形结构加载到内存中的解析方法。
DOM解析器将XML文件解析为一个树状结构,通过遍历节点来获取和操作XML文件中的数据。
DOM解析方法的优点是易于理解和使用,可以随机访问XML文件中的任意节点,但缺点是占用内存较大,不适用于大型XML文件的解析。
1. 创建DOM解析器对象:使用标准的Java API,可以通过DocumentBuilderFactory类来创建DOM解析器对象。
2. 加载XML文件:通过DOM解析器对象的parse()方法加载XML文件,将其转化为一个树形结构。
3. 遍历节点:使用DOM解析器对象提供的方法,如getElementsByTagName()、getChildNodes()等,可以遍历XML文件中的各个节点,获取节点的名称、属性和文本内容等信息。
4. 获取节点数据:通过节点对象提供的方法,如getNodeName()、getTextContent()等,可以获取节点的名称和文本内容。
二、SAX解析方法SAX(简单API for XML)是一种基于事件驱动的XML解析方法。
在SAX解析过程中,解析器顺序读取XML文件,当遇到节点开始、节点结束或节点文本等事件时,会触发相应的回调方法。
相比于DOM 解析方法,SAX解析方法具有内存占用小、解析速度快的优点,但缺点是无法随机访问XML文件中的节点。
1. 创建SAX解析器对象:使用标准的Java API,可以通过SAXParserFactory类来创建SAX解析器对象。
2. 实现事件处理器:自定义一个事件处理器,实现SAX解析器提供的DefaultHandler类,并重写相应的回调方法,如startElement()、endElement()和characters()等。
利用Tinyxml进行文本解析、分词、创建索引源代码/*---------------------------------------数据结构------------------------------------------------*************************************************************** *scws_t scws 操作句柄(指针),大多数API 的第一参数类型,通过 `scws_new()` 返回,不要尝试拷贝 `struct scws_st` 数据,拷贝结果不保证可以正确工作。
typedef struct scws_st {struct scws_st *p;xdict_t d; // 词典指针,可检测是否为 NULL 来判断是否加载成功rule_t r; // 规则集指针,可检测是否为 NULL 来判断是否加载成功unsigned char *mblen;unsigned int mode;unsigned char *txt;int len;int off;int wend;scws_res_t res0; // scws_res_t 解释见后面scws_res_t res1;word_t **wmap;struct scws_zchar *zmap;} scws_st, *scws_t;************************************************************** scws 分词结果集,单链表结构,通过 `scws_get_result()` 返回,每次分词返回的结果集次数是不定的,须循环调用直到返回`NULL`。
typedef struct scws_result *scws_res_t;struct scws_result {int off; // 该词在原文本中的偏移float idf; // 该词的 idf 值unsigned char len; // 该词的长度char attr[3]; // 词性scws_res_t next; // 下一个词};*************************************************************** --------------------------------------数据结构-----------------------------------------*//********************************** 此代码为××所写!***********************************/#include#include#include#include#include#include#include#define SCWS_PREFIX "/usr/local/scws"using namespace std;using namespace tinyxml2; //包含需要的头文件;int main(){/*--------------------------------第一步,解析xml文件--------------------------------------------*/int i=0; //i用作统计加载的文件中的个数char sIndexName[] = "test_index"; //xapian数据库名称;XMLDocument doc;if(doc.LoadFile("/cygdrive/c/cygwin/home/Administrator/te st/all_test.xml")) //all文件为源文件部分可用内容截取;cout <<"Load the file successfully!!" <<endl;else cout <<"Failed to load the file!" <XMLNode* docsNode=doc.FirstChild(); //我在所有的节点上层新建了一层节点,作为第一个节点,目的是方便遍历xml树;XMLNode* docNode=docsNode->FirstChild(); //while(docNode!=NULL) //循环遍历所有url、title、content节点并输出检验;{const char* url=docNode->FirstChild()->FirstChild()->Value();const char* title=docNode->FirstChild()->NextSibling()->FirstChild()->Valu e();const char* content=</endl;docNode->FirstChild()->NextSibling()->NextSibling()->First Child()->Value();cout <<<endl;cout <//异常处理;cout << "Exception: " << error.get_msg() << endl;}docNode=docNode->NextSibling(); //docNode向下挪一位,继续遍历下一个;i++; //统计一共加载了多少个;}cout <<"一共加载文档" <<<"篇"="" <<endl; return 0;}。