SPSS数据分析—描述性统计分析
- 格式:docx
- 大小:493.64 KB
- 文档页数:9
描述性统计分析是针对数据本身而言,用统计学指标描述其特征的分析方法,这种描述看似简单,实际上却是很多高级分析的基础工作,很多高级分析方法对于数据都有一定的假设和适用条件,这些都可以通过描述性统计分析加以判断,我们也会发现,很多分析方法的结果中,或多或少都会穿插一些描述性分析的结果。
描述性统计主要关注数据的三大内容:
1.集中趋势
2.离散趋势
3.数据分布情况
描述集中趋势的指标有均值、众数、中位数,其中均值包括截尾均值、几何均值、调和均值等。
描述离散趋势的指标有频数、相对数、方差、标准差、标准误、全距、四分位间距、四分位数、百分位数、变异系数等。
注意:连续型变量和离散型变量的指标有所不同。
由于很多统计分析都有一个正态分布的假设,因此我们经常也会关注数据的分布特征,常用峰度系数和偏度系数来描述数据偏离正态分布的程度,也可以使用Bootstrap方法计算出结果与经典统计学方法计算出的结果进行对比,如果差异明显,则说明原数据呈偏态分布或存在极值
SPSS用于描述性统计分析的过程大部分都在分析—描述统计菜单中,另有一个在比较均值—均值菜单,虽然这几个过程用途不同,但是基本上都可以输出常用的指标结果。
一、分析—描述统计—频率
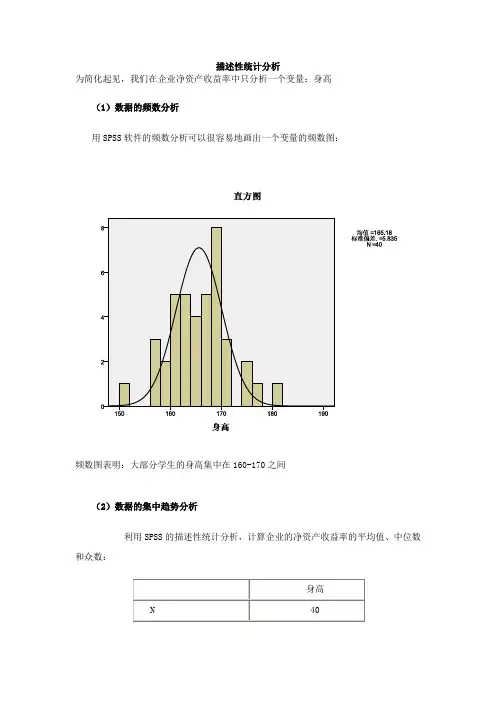
此过程可以输出连续型变量集中趋势和离散趋势的主要指标,还可以输出判断分布的直方图、峰度值
和偏度值,此外,该过程最主要的作用是输出频数表,结果举例如下:
二、分析—描述统计—描述
看起来似乎这个过程才是正统的描述统计分析过程,实际上该过程输出的内容并不多,也没有统计图可以调用,唯一特别的是该过程可以对数据进行标准化变换,并保存为新变量。
三、分析—描述统计—探索
探索性分析是对原有数据进行描述性统计的基础上,更进一步的描述数据,和前两种过程相比,它能提供更详细的结果。
四、分析—描述统计—比率
该过程主要用于对两个连续变量间的比率进行描述分析
输出的结果比较简单,只是指标的汇总表格,在此略去
五、分析—描述统计—交叉表
分类变量的描述性统计比较简单,主要就是看频数分布和构成比,基本用交叉表一个过程就可以完成,该过程虽然放在描述统计中,但是由于功能丰富,也经常被用来做列联表的推断分析。
六、分析—比较均值—均值
该过程在比较均值菜单中,但是大部分输出结果都是描述性统计指标。