(优选)第时间序列分析和预测
- 格式:ppt
- 大小:1.22 MB
- 文档页数:61

2012年第3期 青海师范大学学报(自然科学版)Journal of Qinghai Normal University(Natural Science) 2012No.3收稿日期:2012-04-10作者简介:赵晓葵(1968-),女(汉族),青海西宁人,副教授,硕士.研究方向:计量经济学.沪深A股综合指数的时间序列分析建模与预测赵晓葵(青海师范大学经济管理学院,青海西宁 810008)摘 要:通过基于Box-Jenkins方法的时间序列分析技术,对中国沪、深A股综合指数的2000~2009年月收盘数据序列进行建模分析,验证了沪、深A股综合指数月收盘数据的时间序列特性,研究并选择了这两个序列的最佳ARMA模型,本文也通过模型对2010年的综合指数进行了预测.模型实证分析的结果表明:在股市综合指数时间序列分析建模与预测方面,Box-Jenkins方法及其模型是一种精度较高且切实有效的方法模型.关键词:Box-Jenkins方法;股票综合指数;时间序列分析;ARMA模型中图分类号:O212,C8 文献标识码:A 文章编号:1001-7542(2012)03-0026-041 研究意义股票价格指数波动变化从较长时间序列看,由于宏观经济变化、公司业绩、行业周期性的作用,呈现一定的规律,这对预测股票价格指数提供了依据,从短期看,由于受到不确定因素影响,股票价格指数表现出一定的波动,这对预测造成了困难.目前,灰色理论、生长曲线、指数平滑法等在预测股票价格指数方面有一些应用,这些方法对股票价格指数长期趋势的把握较准,但对短期波动把握的概率度不高.作为上世纪70年代后理论开始成熟和完善的统计数学分支之——时间序列分析,不仅考察预测变量的过去值与当前值,同时对模型同过去值拟合产生的误差也作为重要因素进入模型,作为一种精确度相当高的短期预测方法,近年来在其它经济预测过程中得以广泛的应用,取得了相当好的结果,但在预测股票价格及指数方面应用较少.本文利用中国股票市场沪、深A股综合指数的月度收盘数据,通过基于Box-Jenkins方法的时间序列分析技术,验证了它们数据序列的时间序列特性,研究并选择了这些序列的最佳ARMA模型,本文也通过模型对两个股票指数2010年的月度价格进行了预测,模型实证分析的结果表明:在沪、深A股综合指数分析建模与预测方面,Box-Jenkins方法及其ARMA模型是一种精度较高且切实有效的方法模型.这些实证分析的结果可为股票投资提供一定科学参考,同时也是时间序列分析统计在实际应用中的一次有益尝试.2 关于Box-Jenkins方法和时间序列分析上世纪70年代,美国学者Box和英国统计学者Jenkins提出了一整套关于时间序列分析、预测和控制的方法,被称为Box-Jenkins方法,在各方面的应用十分广泛,有时也称为传统的时间序列建模方法.该方法把时间序列建模表述为三个阶段:第一,模式识别:确定时间序列应属的模型类型,其基本原理是根据数据的相关特性进行鉴别.第二,估计模型的参数,并结合定阶准则和残差检验对模型的适用性进行诊断检验.第三,应用模型进行预测.这种方法不仅考察预测变量的过去值与当前值,同时对模型同过去值拟合产生的误差也作为重要因素进入模型,有利于提高模型的精确度,是一种精确度相当高的短期预测方法.Box-Jenkins方法在应用中的常见模型形式为:自回归移动平均模型(Autoregressive Moving AverageModel,简记ARMA):若时间序列yt为它的当前与前期的误差和随机项,以及它的前期值的线性函数:yt=φ1yt-1+…+φpyt-p+μt-θ1μt-1-…-θqμt-q则称该时间序列yt为自回归移动平均模型,记为ARMA(p,q).参数φ1,…,φp为待估自回归参数,θ1,…,θq为待估移动平均参数,残差μt为白噪声序列.显然,AR(p)模型和MA(q)模型都是ARMA(p,q)模型的特例.Box-Jenkins模型要求时间序列为平稳序列,而实际应用中时间序列往往表现为长期趋势,季节第3期赵晓葵:沪深A股综合指数的时间序列分析建模与预测变动、循环变动的非平稳数列,这时可通过差分法反复差分以消除其趋势,于是上述ARMA(p,q)又经常以自回归移动求积平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA)的形式加以标记.其模型符号为ARIMA(p,d,q),p代表自回归阶数,d,表示对非平稳数列进行差分处理的次数,q代表移动平均的阶数,至于Box-Jenkins模型建模的具体工作步骤,在以下实证分析过程中在计量经济学软件Eviews5.0支持下加以应用和阐述.3 沪、深A股综合指数的时间序列分析建模与预测3.1 数据来源为保证研究的科学性和实际意义,根据Box-Jenkins时间序列分析方法对分析数据的基本要求,本文选择中国股票市场沪、深A股综合指数的2000年1月—2009年12月度收盘数据来作建模分析,为方便讨论,沪、深A股综合指数序列分别记作ser01、ser02,其时间序列的折线图分别如图1所示,并用建立的模型预测2010年1月~6月的收盘指数并与实际数据实现检验预测精度的比较(列入表2).所有数据都是通过大智慧股票行情软件下载后输入EViews5.0软件下实现建模分析.图1 沪、深A股综合指数的2000年1月—2009年12月度收盘数据时间序列折线图3.2 时间序列平稳性检验和处理从对图1的观测无法直接判定以上股票综合指数序列是否为平稳序列,首先通过计算绘制它们的自相关函数(ACF)图和偏自相关函数(PACF)图(见图2前2个子图),ACF图证实了序列都具有显著的自相关性,这也符合Box-Jenkins方法建模对随机序列的基本要求,但由于这两个序列的ACF值没有很快落入置信区间,由此初步判定它们可能都是非平稳序列.图2 沪、深A股综合指数时间序列及差分序列ACF、PACF图 为进一步检验确定以上判断,再利用Eviews5.0的单位根检验功能来验证序列的平稳性,主要计算结果见表1,从表1可知序列ser01、ser02没有都通过了扩充ADF单位根检验,它们可被认为是非平稳的,为使其平稳,通过一阶差分得到序列Dser01和Dser02,ACF、PACF图(见图2第三、四子图)及ADF单位根检验结果(见表1)证实了差分后序列的平稳性.表1中的ADF检验值(ADF test statistic),它等价于滞后1期72青海师范大学学报(自然科学版)2012年的t检验值,当小于各显著性水平下的临界值,可认为序列平稳,否则为非平稳.表1 沪、深A股综合指数时间序列及差分序列及模型残差Augmented Dickey-Fuller检验结果表ser01 ser01 Dser01 Dser01Residue of rainfall1byARIMA(1,1,1)of ser01Residue of rainfall1byARIMA(1,1,1)of ser02ADF test statistic-1.7546-1.4116-5.3904-3.5285-4.848-6.5461%Test critical alues-3.4870-3.4891-3.4870-3.4891-4.116-4.7665%Test critical alues-2.8862-2.8871-2.8862-2.8871-3.432-3.77810%Test critical alues-2.5800-2.5805-2.5800-2.5805-2.898-3.1563.3 模型的识别、参数估计、优选与检验Box-Jenkins方法首先可根据时间序列模型自相关函数和偏自相关函数图的识别规则,建立相应的AR-MA模型.若偏相关函数(PAC)截尾,而自相关函数(AC)拖尾,可断定序列适合AR模型;若PAC拖尾,AC截尾,则为MA模型;若PAC和AC均是拖尾的,则序列适合ARMA模型.结合图2可认为序列Dser01、Dser02都适合ARMA模型.进行参数估计,估计暂定可能模型参数并检验其统计意义,拟合优度统计量中最重要的有两个AIC(Akaike information criterion)和SIC(Schwarz information criterion),AIC和SIC值最小的模型即是最佳的预测模型.在上述过程中,穿插进行模型残差白噪声检验(利用AC、PAC图和ADF单位根检验).经过综合比较,ARMA(1,1)为Dser01的最佳拟合预测模型,即对ser01而言,最佳拟合预测模型为ARIMA(1,1,1),ARMA(3,1)为Dser01的最佳拟合预测模型,即对ser02而言,最佳拟合预测模型为ARI-MA(3,1,1).从这两个模型的拟合回归图看到模型效果较好(见图3).模型的适用性检验按白噪音独立性检验准则,其基本思想是:若由估计模型拟合的残差纯粹由干扰产生,则该模型是适用的,可用于外推预测;否则,估计模型不合适.表1最后两列显示残差通过扩充ADF单位根检验.所以残差通过白噪声检验.而且,模型的检验效果比较好,由此诊断该模型是可行的,可用于预测.图3 沪、深A股综合指数时间序列的最佳ARIMA模型拟合回归图3.4 沪、深A股综合指数的2010年1月—2010年6月度收盘数据预测与讨论利用建立的最佳拟合预测模型,使用Eviews5.0的Forecast功能对沪、深A股综合指数的2010年1月—2010年6月度收盘数据分别计算出预测值,为便于比较,同时将实际值同时列入表2:82第3期赵晓葵:沪深A股综合指数的时间序列分析建模与预测表2 沪、深A股综合指数的2010年1月—2010年6月度收盘数据预测值与实际值对照表2010年1月2010年2月2010年3月2010年4月2010年5月2010年6月预测值实际值预测值实际值预测值实际值预测值实际值预测值实际值预测值实际值ser01(沪综指)3009.28 2989.29 3046.49 3051.94 309769 3109.10 3088.52 2870.61 3013.34 2592.15 2918.55 2398.37ser02(深综指)12118.7 12137.2 12376.4 12436.66 12487.9 12494.35 12399.5 11162.54 12394.0 10204.17 12355.2 9386.94从表2可以看出三月内预测值和实际值的差异很小,预测相当准确,随着预测的延长,三月以上预测误差较大,这也是ARMA模型的一个缺陷.尽管如此,如果在建立模型过程中不断补充近期数据,调整和优选新模型并实现动态预测,则完全可以克服这一缺陷,与其它的预测方法相比,其预测的准确度还是比较高的.4 结束语Box-Jenkins建模思想,由于不需要对时间序列的发展模式作先验的假设,方法本身又可反复识别修改,直到获得满意的模型,因此适合种股票综合指数时间序列.本文实证分析时,最佳拟合预测模型都至少在由低阶至高阶的三种模型中选出,笔者不仅对最终的最佳模型,而且对其它候选模型都穿插进行了白噪音独立性检验,残差的ACF、PACF检验和扩充ADF单位根检验都证实了候选模型的残差具备白噪声序列性质,由此,说明利用ARMA模型对沪、深A股综合指数序列施行拟合预测具备较好适宜性.参考文献:[1] 何书元.应用时间序列分析[M].北京:北京大学出版社,2004.[2] G.P.E.Box,G.M.Jenkis.TimeSeriesAnalysis:ForecastingandControl[M].SanFrancisco:SanFranciscoPress,1978.[3] 蔺玉佩,杨一文.基于模糊时间序列模型的股票市场预测[J].统计与决策,2010,25(8).[4] 刘文虎.基于Malmquist指数的中国股市羊群效应测度研究[J].证券市场导报,2009,24(8).[5] 易丹辉.数据分析与Eviews的应用[M].北京:中国统计出版社,1994.[6] 李子奈.计量经济学[M].北京:高等教育出版社,2000.The modeling and forecasting on composite index time series ofShanghai and Shenzhen A-shareZHAO Xiao-kui(School of Economics and Management,Qinghai Normal University,Xining 810008,China)Abstract:Via time series analysis technique based on Box-Jenkins method,this article builds a modeland analysis China’s Shanghai and Shenzhen a-share index 2000~2009-month closing high of the data se-ries,then researches and selects the best of these two sequences ARMA model,this article also uses thismodel to predict the 2010index.Empirical analysis of the model results show that:On the stock marketcomposite index time series modeling and forecasting,Box-Jenkins method and its model is a high precisionand effective model of method.Key words:Box-Jenkins method;stock composite index;time series analysis;ARMA model92。

电力负荷预测中的时间序列分析方法电力负荷预测是电力系统运行和管理中的关键环节。
准确预测电力负荷可以为发电企业提供比较精确的发电计划,为向用户提供可靠的电力服务提供保障。
为了提高电力负荷预测的准确性,现今研究中主要采用时间序列分析方法来进行电力负荷的预测。
本文将介绍时间序列分析方法在电力负荷预测中的应用。
时间序列分析方法简介时间序列分析将时间序列的历史数据视为连续的观察值序列,并通过对时间序列进行模型拟合,预测未来的值。
时间序列分析中,预测值的种类包括点预测和区间预测。
点预测是指根据时间序列模型,预测未来某一点的数值。
例如,可以通过假定未来一段时间的负载保持某种趋势或周期性变化等方式,预测未来某个时间点的负载。
区间预测是指同时预测未来某一时间段内数值的上下限。
时间序列分析包括模型拟合和模型选择两个部分。
模型拟合是指根据历史数据,对某种时间序列模型的参数进行估计,从而利用该模型对未来数值进行预测。
模型选择则是在一组拟合时间序列模型中,通过选用某种标准,从中选择最优模型或拟合的较好的模型。
时间序列分析方法在电力负荷预测中的应用常用的时间序列分析方法有 ARIMA、季节性 ARIMA 和 GARCH 等模型。
(1) ARIMA 模型ARIMA(Autoregressive Integrated Moving Average)模型将自回归过程、滑动平均过程和差分法等方法结合起来。
ARIMA 模型适用于时间序列数据有自相关性和平稳性的情况。
ARIMA 模型分为三个部分,分别是自回归过程(AR)、差分过程(I)和滑动平均过程(MA)。
其中,自回归过程是指当前时刻的数值与前若干时刻的数值有关;滑动平均过程是指当前数值与前若干时刻的残差有关;差分过程是指将时间序列数据在$t$时刻与$t-1$时刻进行一次差分,得到的新数列为差分序列。
ARIMA 模型为线性模型,尽管其应用范围广泛,但存在以下限制:首先,必须假定所研究的时间序列具有稳定性,这在实际应用中不易满足;其次,每次建立模型都需要大量的数据,对数据要求较高,而对于只有数年数据的相关变量,衡量负荷准确性是不精确的。

时间序列预测是机器学习领域中的一个重要应用。
通过对历史数据进行分析和建模,可以预测未来一段时间内的趋势和变化。
在实际生活和工作中,时间序列预测可以帮助我们做出更准确的决策,提前做好准备。
本文将介绍如何利用机器学习进行时间序列预测,并讨论其中的一些常见方法和技巧。
数据准备首先,进行时间序列预测的第一步是数据准备。
我们需要收集并整理历史数据,确保数据的完整性和准确性。
通常情况下,时间序列数据是按照一定的时间间隔采集的,比如每天、每周或每月。
在准备数据时,需要注意处理缺失值和异常值,以及进行数据平滑和变换等操作,以确保数据的质量和可用性。
特征工程在进行时间序列预测之前,还需要进行特征工程的工作。
特征工程是指通过对原始数据进行处理和转换,提取出与预测目标相关的特征。
在时间序列预测中,常见的特征包括时间、趋势、季节性和周期性等。
通过合理选择和构建特征,可以提高模型的性能和预测能力。
模型选择选择合适的模型是进行时间序列预测的关键步骤。
在机器学习中,常用的时间序列预测模型包括自回归模型(AR)、移动平均模型(MA)、自回归移动平均模型(ARMA)和自回归积分移动平均模型(ARIMA)等。
此外,还可以利用深度学习模型如循环神经网络(RNN)和长短期记忆网络(LSTM)来进行时间序列预测。
模型训练和评估在选择模型之后,需要对模型进行训练和评估。
通常情况下,可以将历史数据划分为训练集和测试集,用训练集来训练模型,然后用测试集来评估模型的性能。
常用的评估指标包括均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE)等。
通过选择合适的评估指标,可以更好地评估模型的预测能力。
模型调参在训练和评估模型的过程中,还需要进行模型的调参工作。
模型的调参是指通过调整模型的参数和超参数,提高模型的性能和泛化能力。
在时间序列预测中,常见的调参方法包括网格搜索、随机搜索和贝叶斯优化等。
通过合理选择调参方法和参数范围,可以找到最优的模型参数。

统计学时间序列分析时间序列是经济学、金融学和其他社会科学领域中的一个重要分析对象。
通过对时间序列数据的分析,我们可以揭示数据之间的关系、趋势和周期性,从而为决策提供有力的支持和预测。
统计学时间序列分析是一种应用数学方法的工具,用于对时间序列数据进行建模和预测。
一、时间序列的基本概念时间序列是按时间顺序排列的一系列观测值的集合。
在时间序列分析中,我们关注数据之间的内在关系,而忽略其他因素的影响。
时间序列数据通常具有以下特征:1. 趋势性:时间序列数据的长期变化趋势。
2. 季节性:时间序列数据在一年内固定时间段内的重复模式。
3. 循环性:时间序列数据中存在的多重周期性波动。
4. 随机性:时间序列数据中的不规则、无法预测的波动。
二、时间序列分析的方法在进行时间序列分析时,我们可以采用以下方法来揭示数据的内在规律:1. 描述性统计分析:通过计算数据的均值、方差、相关系数等指标,对数据的整体特征进行描述。
2. 图表分析:通过绘制折线图、柱状图等图表,展示时间序列数据的变化趋势和周期性。
3. 分解模型:将时间序列数据分解为趋势项、季节性项和残差项,以揭示数据的内在结构。
4. 平滑法:通过移动平均法、指数平滑法等方法,消除时间序列数据的随机波动,从而揭示趋势和季节性成分。
5. 自回归移动平均模型(ARIMA):ARIMA模型是一种常用的时间序列分析方法,可以对数据进行预测和建模。
它综合考虑了自回归、移动平均和差分的影响因素。
三、时间序列分析的应用领域时间序列分析广泛应用于经济学、金融学、市场调研等领域,具体应用包括:1. 经济预测:通过对经济数据进行时间序列分析,可以预测未来的经济发展趋势,为政府决策提供参考。
2. 股票市场分析:时间序列分析可以帮助分析师预测股票市场的走势,制定投资策略。
3. 需求预测:通过对销售数据进行时间序列分析,可以预测产品的需求量,为企业的生产和供应链管理提供指导。
4. 天气预测:通过对气象数据进行时间序列分析,可以预测未来的天气状况,为农业、旅游等行业提供参考。

时间序列分析法范文1.数据收集:收集时间序列数据,确保数据准确性和完整性。
2.数据可视化:绘制时间序列数据的图表,以便观察其趋势和周期性。
3.时间序列分解:将时间序列数据分解为趋势、周期和随机成分。
趋势部分表示数据的长期变化趋势,周期部分表示数据的循环变化趋势,随机部分表示数据的不规律波动。
4.数据平稳性检验:判断时间序列数据是否具有平稳性,即均值和方差是否稳定。
5.模型拟合:根据数据的特征选择适当的时间序列模型,如AR模型(自回归模型)、MA模型(移动平均模型)或ARMA模型(自回归移动平均模型)。
6.模型检验:利用统计方法对拟合好的模型进行检验,如检查残差序列是否为白噪声序列。
7.模型预测:基于拟合好的模型,对未来的时间序列数据做出预测。
时间序列分析中最常用的模型之一是ARIMA模型(自回归整合移动平均模型)。
ARIMA模型基于时间序列数据的自相关性和移动平均性来做出预测。
ARIMA模型的三个参数分别代表自回归部分的阶数(AR)、差分次数(I)和移动平均部分的阶数(MA),通过对这三个参数的选择和拟合,可以得到最优的模型。
时间序列分析还可以应用于季节性数据的预测。
季节性数据具有明显的周期性,例如每年销售额的变化或每月的气温变化。
对季节性数据进行分析时,需要使用季节性ARIMA模型(SARIMA),该模型结合了ARIMA模型和季节性变化的效应。
在金融领域,时间序列分析可用于股票市场的预测和波动性分析。
例如,可以利用时间序列分析来研究股票市场的趋势,预测未来的股价,并进行风险管理。
时间序列分析的优点包括可以从历史数据中提取有用的信息,预测未来的趋势,并进行风险管理。
它还可以帮助研究人员了解时间序列数据的动态特征和影响因素。
然而,时间序列分析也存在一些局限性,例如对数据平稳性的要求较高,数据的缺失或异常值可能会影响预测结果的准确性。
总之,时间序列分析是一种有效的统计方法,可帮助我们理解和预测随时间变化的数据。

初计量经济学之时间序列分析1. 引言时间序列分析是计量经济学中的一个重要领域,研究的是时间序列数据的性质、模式和预测方法。
时间序列数据是按照时间顺序排列的一系列观测值,包括经济指标、股票价格、气象数据等。
时间序列分析可以帮助我们理解和预测经济现象的发展趋势,为政府和企业决策提供科学依据。
本文将介绍时间序列分析的基本概念、方法和应用。
首先,我们将介绍时间序列分析的基本步骤和基本假设。
然后,我们将介绍时间序列模型的常用类型,包括自回归模型(AR)、滑动平均模型(MA)和自回归滑动平均模型(ARMA)。
最后,我们将介绍时间序列的应用领域,包括经济预测、金融风险管理和气象预测。
2. 时间序列分析的基本步骤时间序列分析的基本步骤包括数据的收集和准备、数据的探索性分析、模型的选择和估计、模型的诊断和预测。
下面将对每个步骤进行详细介绍。
2.1 数据的收集和准备数据的收集和准备是时间序列分析的第一步。
我们需要收集时间序列数据,并进行数据清洗和预处理。
数据清洗包括删除缺失值、处理异常值和去除趋势。
数据预处理包括对数据进行平滑处理、差分和变换。
2.2 数据的探索性分析数据的探索性分析是时间序列分析的第二步。
我们需要对时间序列数据进行可视化和统计分析,以了解数据的基本性质和模式。
可视化方法包括绘制时间序列图、自相关图和偏自相关图。
统计分析方法包括计算统计指标、分析趋势、季节性和周期性。
2.3 模型的选择和估计模型的选择和估计是时间序列分析的第三步。
我们需要选择合适的时间序列模型,并进行参数估计。
常用的时间序列模型包括自回归模型(AR)、滑动平均模型(MA)、自回归滑动平均模型(ARMA)和季节性模型。
2.4 模型的诊断和预测模型的诊断和预测是时间序列分析的最后一步。
我们需要对模型进行诊断,检验模型的拟合程度和残差的平稳性、独立性和正态性。
然后,我们可以使用模型进行未来值的预测。
3. 时间序列模型时间序列模型是描述和预测时间序列数据的数学模型。

时间序列分析与ARIMA模型时间序列分析是一种研究时间上连续测量所构成的数据的方法。
它可以用来分析数据中的趋势、周期性和随机性,并预测未来的走势。
ARIMA(自回归滑动平均模型)是时间序列分析中常用的模型之一。
本文将介绍时间序列分析的基本概念以及ARIMA模型的原理和应用。
一、时间序列分析的基本概念时间序列是按照时间顺序排列的一组连续观测数据。
在时间序列分析中,我们常常关注序列中的趋势(trend)、季节性(seasonality)和周期性(cycle)等特征。
趋势是指长期上升或下降的走势;季节性是指数据在相同周期内波动的规律性;周期性是指超过一年的时间内出现的规律性波动。
二、ARIMA模型的原理ARIMA模型是由自回归(AR)和滑动平均(MA)模型组成的。
AR模型用过去的观测值来预测未来的值,滑动平均模型则用过去的噪声来预测未来的值。
ARIMA模型是将这两种模型结合起来,对时间序列进行建模和预测。
ARIMA模型包括三个主要部分:自回归阶数(p)、差分阶数(d)和滑动平均阶数(q)。
p表示模型中的自回归项数目,d表示需要进行的差分次数,q表示模型中的滑动平均项数目。
通过对时间序列的观测值进行差分,ARIMA模型可以将非平稳的序列转化为平稳的序列。
然后,可以通过对平稳序列的自回归和滑动平均建模,预测未来的值。
三、ARIMA模型的应用ARIMA模型在实际应用中被广泛使用。
它可以用于经济学、金融学、气象学等领域中的时间序列预测和分析。
以股票市场为例,投资者可以利用ARIMA模型对历史股价进行分析,预测未来股价的走势。
在气象学中,ARIMA模型可以用于预测未来的天气情况。
除了ARIMA模型,时间序列分析还包括其他模型,如季节性分解、移动平均、指数平滑等。
这些模型都有各自的优点和应用领域。
在实际应用中,根据不同的数据特点和研究目的,选择合适的模型进行分析和预测是十分重要的。
总结时间序列分析和ARIMA模型是研究时间数据的重要方法。

时间序列分析与预测模型时间序列分析是指对按时间顺序排列的观测数据进行分析的一种方法。
该方法可以帮助我们理解和解释数据的时间相关性,并且可以利用这种相关性进行预测。
时间序列分析在很多领域都有广泛的应用,如经济学、金融学、天气预测等。
1.数据收集:收集包含时间顺序的数据。
这些数据可以是连续的,如每天、每月或每年的数据,也可以是离散的,如每小时或每分钟的数据。
2.数据可视化:绘制时间序列图,将收集到的数据可视化。
通过观察时间序列图,我们可以发现数据的趋势、周期性和季节性。
3.数据平稳性检验:对时间序列数据进行平稳性检验。
平稳性是指数据的均值、方差和自协方差不随时间变化。
平稳性是许多时间序列模型的前提条件。
4.模型拟合:根据时间序列数据的特点选择合适的模型。
常见的时间序列模型包括自回归移动平均模型(ARMA)、自回归集成移动平均模型(ARIMA)和季节性自回归集成移动平均模型(SARIMA)等。
5.模型诊断:对拟合的模型进行诊断检验。
诊断检验可以判断模型是否良好地拟合了数据,并确定是否需要进行模型调整。
6.模型预测:利用已经拟合好的模型进行未来值的预测。
预测可以是单点预测,也可以是预测一段时间内的趋势。
时间序列分析的预测模型可以帮助我们预测未来的趋势,并且可以在实际决策中指导我们采取相应的行动。
例如,我们可以利用时间序列分析预测未来销售量,从而帮助我们制定合适的生产计划和库存策略。
在金融领域,时间序列分析可以帮助我们预测股价的涨跌,从而指导我们的投资决策。
总之,时间序列分析是一种重要的数据分析方法,它可以帮助我们理解和预测按时间顺序排列的数据。
在实际应用中,我们可以根据时间序列数据的特点选择合适的模型,并进行模型拟合和预测。
通过时间序列分析,我们可以获得有关未来趋势的信息,从而在实际决策中作出更准确的预测。

第七章时间序列剖析思虑与练习一、选择题1.已知 2000-2006 年某银行的年终存款余额,要计算各年均匀存款余额,该均匀数是 : ( b )a. 几何序时均匀数;b. “首末折半法”序时均匀数;c. 期间数列的均匀数; d. 时点数列的均匀数。
2.某地域粮食增加量 1990— 1995 年为 12 万吨, 1996— 2000 年也为 12 万吨。
那么, 1990— 2000 年期间,该地域粮食环比增加速度( d )a. 逐年上涨b. 逐年降落c. 保持不变d. 不可以做结论3. 某商业公司 2000—2001 年各季度销售资料以下:2000 年2001 年1 2 3 4 1 2 3 41. 零售额(百万)40 42 38 44 48 50 40 602. 季初库存额(百万)20 21 22 24 25 26 23 283. 流通花费额(百万) 3.8 3.2 2.8 3.2 3.0 3.1 3.14.04. 商品流转次数(次 / 季) 1.95 19.5 1.65 1.8 1.88 2.04 1.63 2.03上表资猜中,是总量期间数列的有(d)a. 1 、 2、 3b. 1、3、4c. 2、4d. 1、34. 利用上题资料计算零售额挪动均匀数(简单, 4 项挪动均匀), 2001 年第二季度挪动均匀数为( a )a. 47.5b. 46.5c. 49.5d. 48.4二、判断题1.连续 12 个月逐期增加量之和等于年距增加量。
2.计算固定财产投资额的年均匀发展速度应采纳几何均匀法。
3.用挪动均匀法剖析公司季度销售额时间序列的长久趋向时,一般应取4项进行挪动均匀。
4.计算均匀发展速度的水平法只合适时点指标时间序列。
5. 某公司连续四个季度销售收入增加率分别为9%、 12%、 20%和 18%,其125环比增加速度为 0.14%。
正确答案:(1)错;(2)错;( 3)对;( 4)错;( 5)错。
2、研究方法和理论分析非平稳时间序列可以用以下更一般的模型来描述:t t t Y u X +=其中,t u 表示t X 中随时间变化的均值,它往往可以用多项式、指数函数、正弦函数等描述,而t Y 是t X 中剔除趋势性或周期性t u 后余下的部分,往往可以认为是零均值的平稳过程,因而可以用ARMA 模型来描述。
一类具体做法是通过某些数学方法剔除掉t X 中所包含的趋势性或周期性(即t u ),余下的t Y 可按平稳过程进行分析与建模,最后再经反运算由t Y 的结果得出t X 的有关结果。
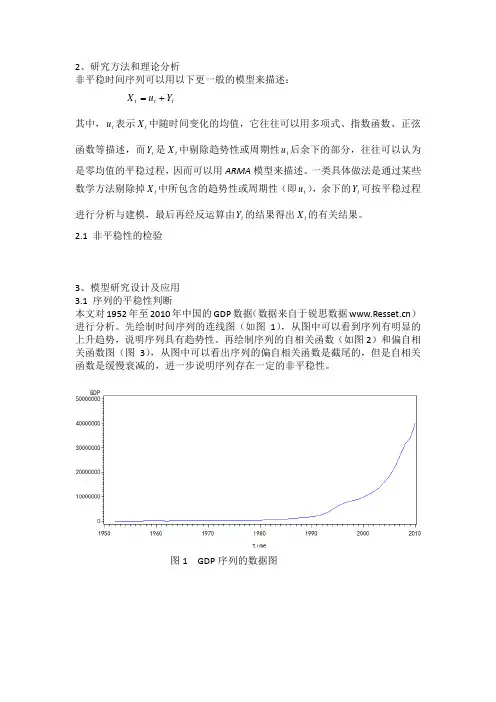
2.1 非平稳性的检验3、模型研究设计及应用3.1 序列的平稳性判断本文对1952年至2010年中国的GDP 数据(数据来自于锐思数据 )进行分析。
先绘制时间序列的连线图(如图1),从图中可以看到序列有明显的上升趋势,说明序列具有趋势性。
再绘制序列的自相关函数(如图2)和偏自相关函数图(图3),从图中可以看出序列的偏自相关函数是截尾的,但是自相关函数是缓慢衰减的,进一步说明序列存在一定的非平稳性。
图1 GDP 序列的数据图图2 GDP序列的自相关函数图图3 GDP序列的偏自相关函数图3.2 序列的平稳化由图1可以看到序列GDP含有指数趋势,可以通过取对数将指数趋势转化为线性趋,然后再进行差分以消除线性趋势。
3.2.1 对序列GDP取对数后,得到一个新的序列LDGP,绘制其数据图(图4),可以看出LGDP序列存在明显的线性趋势。
图4 对数GDP的数据图3.2.2 对序列LGDP做一阶差分处理,得到序列DLGDP,绘制其数据图(图5),从图中看到,序列DLGDP基本平稳。
图5 对数变换与差分运算后序列的数据图3.2.3 对序列DLGDP的白噪声检验如图6所示,可以看到序列的白噪声检验结果拒绝原假设,说明序列不是白噪声序列,故序列有继续研究的意义。
图6 DLGDP的白噪声检验3.3 序列DLGDP的ARMA模型定阶考察序列DLGDP的自相关、偏自相关函数。

《统计学》模拟试卷(一)一、填空题(每空1分,共10分)1、依据统计数据的收集方法不同,可将其分为____________数据和_____________数据。
2、收集的属于不同时间上的数据称为 数据。
3、设总体X 的方差为1,从总体中随机取容量为100的样本,得样本均值x =5,则总体均值的置信水平为99%的置信区间_________________。
(Z 0.005=2.58)4、某地区2005年1季度完成的GDP=50亿元,2005年3季度完成的GDP =55亿元,则GDP 年度化增长率为 。
5、在某城市随机抽取13个家庭,调查得到每个家庭的人均月收入数据如下:1080、750、1080、850、960、2000、1250、1080、760、1080、950、1080、660,则其众数为 ,中位数为 。
6、判定系数的取值范围是 。
7、设总体X ~) ,(2σμN ,x 为样本均值,S 为样本标准差。
当σ未知,且为小样本时, 则n s x μ-服从自由度为n-1的___________________分布。
8、若时间序列有20年的数据,采用5年移动平均,修匀后的时间序列中剩下的数据有 个。
二、单项选择题(在每小题的3个备选答案中选出正确答案,并将其代号填在题干后面的括号内。
每小题1分,共14分)1、.研究如何对现象的数量特征进行计量、观察、概括和表述的理论和方法属于 ( ) ①、应用统计学 ②、描述统计学 ③、推断统计学2、若各个标志值都扩大2倍,而频数都减少为原来的1/3,则平均数 ( ) ①、扩大2倍 ②、减少到1/3 ③、不变3、在处理快艇的6次试验数据中,得到下列最大速度值:27、38、30、37、35、31. 则最大艇速的均值 的无偏估计值为 ( ) ①、32.5 ②、33 ③、39.64、某地区粮食作物产量年平均发展速度:1998~2000年三年平均为1.03,2001~2002年两年平均为1.05,试确定1998~2002五年的年平均发展速度 ( )5、若两个变量的平均水平接近,平均差越大的变量,其 ( ) ①、平均值的代表性越好 ②、离散程度越大 ③、稳定性越高6、对正态总体均值进行区间估计时,其它条件不变,置信水平α-1越小,则置信上限与置信下限的差( ) ①、越大 ②、越小 ③、不变7、若某总体次数分布呈轻微左偏分布,则成立的有 ( )①、x > e M >o M ②、x <e M <o M ③、x >o M >e M8、方差分析中的原假设是关于所研究因素 ( )①、各水平总体方差是否相等 ②、各水平的理论均值是否相等③、同一水平内部数量差异是否相等9、某年某地区甲乙两类职工的月平均收入分别为1060元和3350元,标准差分别为230元和680元,则职工月平均收入的离散程度 ( )①、甲类较大 ②、乙类较大 ③、两类相同10、某企业2004年与2003年相比,各种产品产量增长了8%,总生产费用增长了 15%,则该企业2004年单位成本指数为 ( )①、187.5% ②、7% ③、106.48%11、季节指数刻画了时间序列在一个年度内各月或季的典型季节特征。
第一章财务管理总论(一)财务管理的概念 :财务管理是以公司理财为主体,以金融市场为背景,研究公司资本取得与使用的一种管理学科。
财务活动:资金筹集、投放、使用、收回及分配等一系列行为活动,也叫理财活动。
财务关系:企业与投资者、债权人、受资人、债务人、政府、内部各单位、职工之间 1、股东与经营管理者之间的关系:股东应在监督成本、激励成本和偏离股东目标的损失之间进行权衡,力求找出使三者之和最小的方法。
2、股东与债权人之间:①法律保护②限制性条款③收回借款或拒绝提供新借款。
(二)财务管理的方法:1、预测:定性预测、定量预测(时间序列预测、相关因素预测)2、决策:优选对比、数学微分、线性规划、概率决策、损益决策3、计划:固定法、弹性法、滚动法、零基法4、控制:保护性控制(前)、前馈性控制(中)、反馈性控制(后)5、分析:比较分析、趋势分析、比率分析、因素分析(三)财务管理的目标:是财务管理工作的导向和标准。
1、企业的总目标:生存、发展、获利2、企业财务管理目标:1)利润最大化 2)满意的利润水平 3)每股收益最大化 4)股东财富最大化 5)企业价值最大化 6)社会责任3、影响2的因素:1)投资回报率2 )风险3)投资项目4)资本结构5)股利政策(四)财务管理的环境:是指对企业财务活动产生影响的外部条件。
1、特征:1)动态性2)不确定性3)复杂性4)交叉性2、经济环境:指宏观经济的发展状况及其变化。
3、法律环境:指企业和外部发生筹资、投资、利润分配和营运资本管理等经济关系时所应遵守的法律、法规和规章。
4金融环境:金融市场第二章财务估价(一)货币的时间价值:指货币经历一定时间的投资和再投资所增加的价值,或同一货币量在不同时间里的价值差额。
(没有风险和通货膨胀条件下社会平均资金利润率) 绝对量-使用资金的机会成本相对量-相当于政府债券利率1、年金(A)是系列收付款项的特殊形式,它是指在一定时期内每隔相同时间(如一年)就发生相同数额的系列收付款项,也称等额系列款项。
第1篇一、摘要本报告旨在通过对优选平台的数据分析,深入了解平台运营状况、用户行为、市场竞争力等方面,为平台优化策略提供数据支持。
报告内容涵盖用户画像、交易分析、内容分析、市场竞争力分析等四个方面,旨在全面评估优选平台的现状,并提出相应的改进建议。
二、用户画像分析1. 用户年龄分布优选平台的用户年龄主要集中在18-35岁之间,占比达到65%。
这一年龄段用户对新鲜事物接受度高,消费能力强,是平台的核心用户群体。
2. 用户性别比例在性别比例上,优选平台女性用户占比略高于男性,达到53%。
女性用户在时尚、美妆、家居等领域消费需求较高,是平台重要的消费力量。
3. 用户地域分布优选平台的用户遍布全国,其中一线城市用户占比最高,达到30%。
二线城市用户占比25%,三线及以下城市用户占比45%。
这说明优选平台在一线城市拥有较高的品牌知名度和用户基础,同时也具备向三四线城市拓展的潜力。
4. 用户消费偏好通过对用户购买记录的分析,发现以下消费偏好:(1)时尚美妆:女性用户在时尚美妆类产品的消费占比最高,达到35%。
(2)家居用品:家居用品消费占比达到28%,用户对生活品质的追求日益提高。
(3)数码产品:数码产品消费占比达到20%,用户对科技产品的需求不断增长。
三、交易分析1. 交易额分析优选平台交易额呈逐年增长趋势,2021年交易额较2020年增长30%。
其中,11月和12月为交易高峰期,销售额占比达到40%。
2. 客单价分析优选平台客单价逐年上升,2021年客单价较2020年增长15%。
这得益于平台对商品品质的把控和用户消费能力的提升。
3. 订单量分析优选平台订单量呈稳步增长态势,2021年订单量较2020年增长25%。
其中,移动端订单量占比达到70%,表明移动端已成为用户购买的主要渠道。
4. 支付方式分析优选平台支付方式以支付宝和微信支付为主,占比达到90%。
此外,部分用户选择信用卡支付和余额支付。
四、内容分析1. 商品种类分析优选平台商品种类丰富,涵盖服装、美妆、家居、数码、食品等多个领域。
作者: 李宝仁
作者机构: 北京商学院
出版物刊名: 预测
页码: 21-21页
主题词: 指数平滑法;优选法;预测模型;平滑系数;试验次数;经济时间序列;数学模型;最佳点;
随机误差;加权系数
摘要: <正> 指数平滑法是分析经济时间序列的最常用方法,其数学模型为: 其中:S_t是第t+1期的预测值、α为平滑系数(或加权系数) 在应用指数平滑法进行预测时,如何确定平滑系数α是提高预测精度的关键。
在预测中,一方面我们希望提高α值,借以增加近期数据的权数;另一方面又希望减少α值以平滑随机误差,显然这两项要求是相互矛盾的。
所。
随着科技的不断发展,机器学习技术在各行各业中得到了广泛应用。
其中,时间序列预测作为机器学习的一个重要领域,对于金融、医疗、气象等各个领域都具有重要意义。
本文将从时间序列预测的基本概念开始,逐步介绍机器学习在时间序列预测中的应用。
1. 时间序列预测的基本概念时间序列是一系列按照时间顺序排列的数据点,例如股票价格、气温、销售额等。
时间序列预测即是通过已有的时间序列数据,来预测未来某一段时间内的数据走势。
时间序列预测的难点在于数据的非线性、不稳定性和噪声干扰等,因此传统的统计方法在处理时间序列预测时往往效果不佳。
2. 机器学习在时间序列预测中的应用机器学习技术的发展为时间序列预测提供了新的思路和方法。
其中,神经网络、支持向量机、随机森林等算法被广泛应用于时间序列预测中。
这些算法通过对大量的历史数据进行学习,从中总结出数据的规律和特征,然后利用这些规律和特征进行未来数据的预测。
3. 数据预处理在利用机器学习进行时间序列预测之前,需要进行数据的预处理工作。
这包括数据清洗、缺失值填充、特征工程等环节。
数据清洗是指去除异常值、噪声数据等;缺失值填充是指对于数据中的缺失值进行处理,可以通过插值、均值填充等方法;特征工程是指对原始数据进行特征提取和变换,以便于算法学习和预测。
4. 模型选择和训练在数据预处理完成后,需要选择合适的机器学习模型进行训练。
对于时间序列预测问题,常用的模型包括循环神经网络(RNN)、长短时记忆网络(LSTM)、卷积神经网络(CNN)等。
这些模型在处理时间序列数据时具有较强的表达能力和泛化能力,可以有效地捕捉数据的时间特征和非线性关系。
5. 模型评估和调参在模型训练完成后,需要进行模型的评估和调参工作。
常用的评估指标包括均方根误差(RMSE)、平均绝对误差(MAE)等,这些指标可以用来评估模型的预测精度和稳定性。
同时,还需要进行模型的调参工作,包括学习率的选择、模型的复杂度、训练轮数等参数的调整,以获得更好的预测效果。