spss平均数、标准差与变异系数
- 格式:ppt
- 大小:154.50 KB
- 文档页数:25

变异系数平均值标准差变异系数、平均值和标准差是统计学中常用的三个描述性统计量,它们可以帮助我们更好地理解数据的分布和变异程度。
在本文中,我们将分别介绍这三个统计量的概念、计算方法以及它们在实际应用中的意义。
首先,让我们来了解一下变异系数。
变异系数是用来衡量数据变异程度的一个指标,它的计算公式是标准差除以平均值,通常以百分比的形式表示。
变异系数的数值越大,表示数据的变异程度越高;反之,数值越小,表示数据的变异程度越低。
在实际应用中,变异系数可以帮助我们比较不同数据集的变异程度,从而更好地进行数据分析和决策。
接下来,让我们来介绍平均值。
平均值是一组数据的总和除以数据的个数,它是描述数据集中心位置的一个重要指标。
平均值可以帮助我们了解数据的集中趋势,通常用来代表整个数据集的中心位置。
在实际应用中,平均值经常被用来进行数据的比较和分析,是统计学中最基本的描述性统计量之一。
最后,让我们来讨论标准差。
标准差是衡量数据离散程度的一个指标,它表示一组数据的离散程度或者波动程度。
标准差的计算方法是先计算每个数据与平均值的差值,然后求这些差值的平方和的平均值,最后再取平方根。
标准差的数值越大,表示数据的离散程度越高;反之,数值越小,表示数据的离散程度越低。
在实际应用中,标准差经常被用来衡量数据的风险和波动性,是金融领域和科学研究中常用的一个重要指标。
在实际应用中,变异系数、平均值和标准差经常是一起使用的。
它们可以帮助我们更全面地了解数据的特征和分布,从而更好地进行数据分析和决策。
通过对这三个统计量的合理运用,我们可以更准确地把握数据的特点,为实际工作和研究提供有力的支持。
综上所述,变异系数、平均值和标准差是统计学中常用的三个描述性统计量,它们分别衡量了数据的变异程度、中心位置和离散程度。
在实际应用中,它们可以帮助我们更好地理解数据的特征和分布,为数据分析和决策提供重要的参考依据。
希望本文对读者对这三个统计量有更深入的理解和运用有所帮助。

spss均值和标准差SPSS均值和标准差。
SPSS(Statistical Product and Service Solutions)是一个用于统计分析的软件包,它可以帮助研究人员进行数据的处理、分析和展示。
在SPSS中,均值和标准差是两个常用的统计量,它们可以帮助我们了解数据的集中趋势和离散程度。
本文将介绍如何使用SPSS计算均值和标准差,并解释它们在统计分析中的重要性。
首先,我们需要准备一份包含数据的数据集。
在SPSS中,可以通过导入外部文件或手动输入数据来创建数据集。
假设我们有一个包含学生数学成绩的数据集,我们想要计算这些成绩的均值和标准差。
我们可以在SPSS中打开这个数据集,并选择“分析”菜单中的“描述统计”选项。
在“描述统计”对话框中,我们需要将所需分析的变量移动到右侧的“变量”框中。
在这个例子中,我们将学生数学成绩的变量移动到“变量”框中。
然后,我们需要勾选“均值”和“标准差”选项,并点击“确定”按钮。
SPSS将会生成一个包含所选变量的均值和标准差的统计表。
通过这个统计表,我们可以看到学生数学成绩的均值和标准差。
均值代表了数据的集中趋势,它可以帮助我们了解这组数据的平均水平。
标准差则代表了数据的离散程度,它可以帮助我们了解这组数据的分散情况。
通过均值和标准差,我们可以对这组数据有一个直观的认识。
除了计算单个变量的均值和标准差外,SPSS还可以帮助我们进行多个变量的均值和标准差比较。
比如,我们可以使用SPSS的“交叉表”功能来计算不同性别学生的数学成绩均值和标准差,从而比较两组学生的成绩情况。
这可以帮助我们发现不同群体之间的差异,为进一步的分析提供参考。
在统计分析中,均值和标准差是最基本的统计量,它们可以为我们提供大量有用的信息。
比如,我们可以通过均值和标准差来判断数据是否符合正态分布,从而决定使用何种统计方法进行分析。
另外,均值和标准差也可以帮助我们进行数据的比较和分类,从而深入挖掘数据背后的规律。

SPSS相关统计学指标SPSS(Statistical Package for the Social Sciences)是一款统计学软件,广泛用于社会科学领域的数据分析和统计建模。
在SPSS中,有很多常用的统计学指标可以用来描述和解释数据。
本文将介绍一些常见的SPSS相关统计学指标。
1. 平均数(Mean):平均数是一组数据的数值总和除以数据个数的结果。
通过计算平均数,可以了解数据的中心趋势。
2. 中位数(Median):中位数将一组数据按照大小排序,然后取中间位置的数值作为中位数。
对于偏态数据集,中位数通常更适合表示数据的中心位置。
3. 众数(Mode):众数是一组数据中出现次数最多的数值。
众数可以用来表示数据的最常见取值。
4. 标准差(Standard Deviation):标准差是一组数据的离散程度的度量指标。
标准差越大,表示数据的离散程度越大。
5. 方差(Variance):方差是一组数据的离散程度的度量指标,计算方法为每个数据值与平均数之差的平方的平均数。
6. 百分位数(Percentiles):百分位数将一组数据从小到大排序后,按百分比划分数据的位置。
例如,第50百分位数即为中位数。
7. 四分位数(Quartiles):四分位数将一组数据从小到大排序后,将数据划分为四个等份。
第一四分位数将数据划分为25%、第二四分位数为50%(即中位数)、第三四分位数为75%。
8. 偏态(Skewness):偏态用来衡量数据分布的对称性。
正偏态表示数据右偏,负偏态表示数据左偏。
9. 峰度(Kurtosis):峰度用来衡量数据分布的峰态或尖锐程度。
正峰度表示数据分布比较尖锐,负峰度表示数据分布比较平坦。
10. 相关系数(Correlation coefficient):相关系数衡量两个变量之间的线性关系强度和方向。
相关系数的取值范围为-1到1,绝对值越接近1表示关系越强。
11. 回归系数(Regression coefficient):对于回归分析,回归系数表示自变量对因变量的影响程度。

spss求平均值和标准差SPSS求平均值和标准差。
在统计学中,平均值和标准差是两个非常重要的概念。
平均值是一组数据的中心点,用来衡量数据的集中趋势;而标准差则是用来衡量数据的离散程度。
在SPSS软件中,我们可以很方便地求取数据的平均值和标准差,本文将介绍如何在SPSS中进行这两项统计分析。
首先,打开SPSS软件并导入你的数据文件。
在数据文件中,你可以看到各个变量的数值以及对应的样本。
在这个例子中,我们将以一个假设的数据集为例进行说明。
接下来,点击菜单栏中的“分析”选项,然后选择“描述统计”中的“统计”命令。
在弹出的对话框中,你可以选择要计算的统计量,包括平均值和标准差。
将这两个选项勾选上,然后点击“确定”按钮。
SPSS软件会自动为你计算所选变量的平均值和标准差,并将结果显示在输出窗口中。
在输出窗口中,你可以看到每个变量的平均值和标准差的数值,以及其他一些统计信息。
除了通过菜单栏进行操作,你还可以使用SPSS的语法来计算平均值和标准差。
在语法编辑窗口中,你可以输入类似以下的命令来进行计算:```SPSS。
DESCRIPTIVES VARIABLES=var1 var2 var3。
/STATISTICS=MEAN STDDEV.```。
在这个命令中,DESCRIPTIVES表示进行描述统计分析,VARIABLES后面列出了要计算的变量,/STATISTICS=MEAN STDDEV表示要计算平均值和标准差。
无论是通过菜单栏操作还是通过语法,SPSS都能够很方便地帮助你计算数据的平均值和标准差。
这些统计量可以帮助你更好地理解数据的特征,为进一步的分析和研究提供重要参考。
在进行数据分析时,平均值和标准差是最基本的统计量之一。
它们可以帮助我们了解数据的分布情况,判断数据的稳定性和可靠性。
同时,它们也是其他统计分析的基础,比如t检验、方差分析等。
因此,掌握如何在SPSS中求取平均值和标准差是非常重要的。
除了平均值和标准差之外,SPSS还提供了其他丰富的统计分析功能,比如频数分析、相关分析、回归分析等。

SPSS实现经典统计学分析与变异系数偏度峰度等常用统计学指标计算SPSS是一个广泛使用的统计软件,可以进行各种经典统计学分析和计算常用统计学指标。
1.经典统计学分析经典统计学分析是指通过描述性统计和推断统计方法对数据进行分析。
SPSS提供了各种分析方法,包括描述性统计、相关性分析、T检验、方差分析、回归分析等。
-描述性统计:描述性统计是对数据进行总体和样本的基本描述。
可以计算平均值、中位数、众数、标准差、方差、最大值、最小值等。
在SPSS中,可以通过选择Analyze菜单下的Descriptive Statistics来进行描述性统计分析。
-相关性分析:相关性分析用于检测两个或多个变量之间是否存在关联关系。
可以通过计算皮尔逊相关系数来衡量变量之间的线性关系。
在SPSS中,可以通过选择Analyze菜单下的Correlate来进行相关性分析。
-T检验:-方差分析:方差分析用于比较三个或多个样本均值是否存在显著差异。
可以进行单因素方差分析和多因素方差分析。
在SPSS中,可以通过选择Analyze菜单下的General Linear Model来进行方差分析。
-回归分析:回归分析用于建立一种变量和其他若干个变量之间的函数关系。
可以进行一元线性回归、多元线性回归和逻辑回归等。
在SPSS中,可以通过选择Analyze菜单下的Regression来进行回归分析。
变异系数、偏度和峰度是常用的描述性统计学指标。
-变异系数:变异系数是用来衡量样本观测值的变异程度大小的指标。
它是标准差与均值之比,通常以百分比表示。
在SPSS中,可以通过计算标准差和平均值来得到变异系数。
-偏度:偏度是用来衡量一个数据分布是否对称的指标。
正偏表示分布右尾较长,负偏表示分布左尾较长,零偏表示分布基本对称。
在SPSS中,可以通过计算偏度来得到偏度指标。
-峰度:峰度是用来衡量一个数据分布的离散程度的指标。
正峰表示分布具有较高的峰,负峰表示分布具有较低的峰,零峰表示分布具有与正态分布相同的峰度。
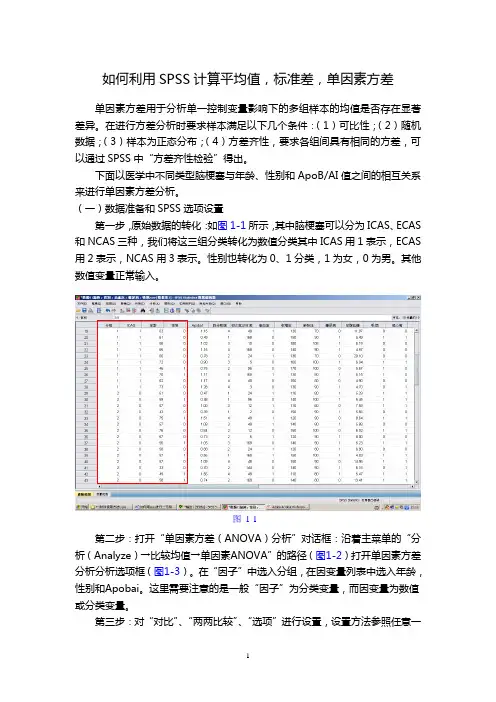
如何利用SPSS计算平均值,标准差,单因素方差单因素方差用于分析单一控制变量影响下的多组样本的均值是否存在显著差异。
在进行方差分析时要求样本满足以下几个条件:(1)可比性;(2)随机数据;(3)样本为正态分布;(4)方差齐性,要求各组间具有相同的方差,可以通过SPSS中“方差齐性检验”得出。
下面以医学中不同类型脑梗塞与年龄、性别和ApoB/AI值之间的相互关系来进行单因素方差分析。
(一)数据准备和SPSS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS 和NCAS三种,我们将这三组分类转化为数值分类其中ICAS用1表示,ECAS 用2表示,NCAS用3表示。
性别也转化为0、1分类,1为女,0为男。
其他数值变量正常输入。
图1-1第二步:打开“单因素方差(ANOVA)分析”对话框:沿着主菜单的“分析(Analyze)→比较均值→单因素ANOVA”的路径(图1-2)打开单因素方差分析分析选项框(图1-3)。
在“因子”中选入分组,在因变量列表中选入年龄,性别和Apobai。
这里需要注意的是一般“因子”为分类变量,而因变量为数值或分类变量。
第三步:对“对比”、“两两比较”、“选项”进行设置,设置方法参照任意一本SPSS统计书籍中关于单因素方差分析的部分。
图1-2图1-3点击确定后输出数据,这里重点讲输出数据中各项所代表的意思。
我们经常会在其他文献中看到有关平均值(mean),标准差(SD)和标准误差(SE),即mean±SD或SE的情况。
如图1-4所示“描述图”中,在该图中我们很容易找到以上几项。
如图1-4所示“方差齐性检验”中,我们可以找到各组的显著性(即P值),也有软件表示为Sig.。
当该值大于0.05时说明各组间方差是齐性的,既满足前提的第四点。
可以进行后续分析。
一般我们需要的是多重比较的表格,如图1-5所示,该表中给出了年龄、性别和ApoB/AI值中各组间的显著性水平(P值),如年龄组中1、2组间显著性为0.972,差异不显著。

心理统计常用公式总结1 、组数 K (总体分布为正态)( N 为数据个数, K 取近似整数)2 、算术平均数3 、中数4 、众数5 、加权平均数,其中 W i 为权数,其中为各小组的平均数, n i 为各小组人数6 、几何平均数,其中 n 为数据个数, X i 为数据的值7 、调和平均数8 、方差与标准差,其中9 、变异系数,其中 S 为标准差, M 为平均数10 、标准分数,其中 X 为原始数据,为平均数, S 为标准差11 、全距 R =最大数-最小数12 、平均差13 、四分差,其中 L b 为该四分点所在组的精确下限, F b 为该四分点所在组以下的累加次数,和为该四分点所在组的次数, i 为组距, N 为数据个数14 、积差相关基本公式:,其中, , N 为成对数据的数目, S x 、 S y 分别为 X 和 Y 的标准差变形:差法公式:用估计平均数计算:用相关表计算:15 、斯皮尔曼等级相关,其中 D 为各对偶等级之差直接用等级序数计算:,其中 R X 、 R Y 分别为二变量各等级数有相同等级时:16 、肯德尔等级相关有相同等级:17 、点二列相关,其中是两个二分变量对偶的连续变量的平均数,p 、 q 是二分变量各自所占的比率, p+q=1 , S t 是连续变量的标准差18 、二列相关,其中 S T 与是连续变量的标准差与平均数, y 为 P 的正态曲线的高度19 、多系列相关,其中 P i 为每系列的次数比率, y 1 为每一名义变量下限的正态曲线高度, y h 为每一名义变量上线的正态曲线高度,为每一名义变量对偶的连续变量的平均数, S t 为连续变量的标准差20 、总体为正态,σ 2 已知:21 、总体为正态,σ 2 未知:22 、23 、24 、。

spss计算均值和标准差SPSS计算均值和标准差。
在统计学中,均值和标准差是描述数据集中集中趋势和离散程度的两个重要指标。
在SPSS软件中,计算均值和标准差非常简单,本文将介绍如何在SPSS中进行这两项统计指标的计算。
首先,打开SPSS软件并导入你的数据集。
在数据编辑界面中,选择“转到”菜单下的“变量视图”,然后点击空白行以添加新的变量。
在“名称”栏中输入你要计算的变量名称,比如“均值”,然后在“类型”栏中选择“数值”,在“宽度”和“小数位数”中输入适当的数值。
接下来,切换到“数据视图”,找到你要计算均值和标准差的变量所在的列。
在该列下方的空白单元格中输入以下公式来计算均值,MEAN(variable1, variable2, ...),其中“variable1, variable2, ...”代表你要计算的变量名称。
按下回车键,SPSS将会自动计算并显示出该变量的均值。
同样地,要计算标准差,只需要在该列下方的空白单元格中输入以下公式,SD(variable1, variable2, ...),其中“variable1, variable2, ...”代表你要计算的变量名称。
按下回车键,SPSS将会自动计算并显示出该变量的标准差。
通过上述步骤,你就可以在SPSS中轻松地计算出你感兴趣的变量的均值和标准差了。
这两个统计指标可以帮助你更好地理解你的数据集,揭示数据的分布规律和离散程度,为后续的分析和决策提供重要参考。
需要注意的是,SPSS还提供了更多的统计分析功能,比如频数统计、相关分析、回归分析等,可以帮助你深入挖掘数据背后的信息。
因此,熟练掌握SPSS软件的使用,对于进行科学研究和数据分析是非常有帮助的。
总之,本文介绍了在SPSS中如何计算均值和标准差,希望能对你有所帮助。
在实际应用中,要根据具体情况选择合适的统计方法,并结合其他分析手段进行综合分析,以便更好地理解数据和做出科学决策。
SPSS作为一款强大的统计分析工具,可以帮助你更好地处理和分析数据,为科研工作提供有力支持。



SPSS操作练习(t检验)要求:1、用SPSS进行统计分析;2、分析说明使用某一统计处理方法的依据;3、将统计结果正确地在论文中进行表达并进行结果分析。
1.计算下列两个玉米品种10个果穗长度(cm)的平均值、标准差和变异系数,并解释两个玉米品种的果穗长度有无差异。
【变异系数C·V=(标准偏差SD/平均值MN)×100%】玉米24号:19,21,20,20,18,19,22,21,21,19金皇后:16,21,24,15,26,18,20,19,22,19解:(1)选择分析方法:被比较的玉米24号、金皇后玉米是两个品种的玉米,试验中彼此独立、无配对关系。
先用SPSS对数据是否服从正态分布进行Kolmogorov-Smirnov 检验,得到,玉米24号的p=0.869>0.05,金皇后玉米的p=0.99>0.05,说明两个样本均服从正态分布(来自正态总体),因此选择独立样本t检验进行数据分析。
经Levene方差齐性检验得P=0.028<0.05,表明方差不齐,因此选择t检验的结果,使用方差不齐时的计算结果。
(2)结果:为比较玉米24号、金皇后两个品种果穗长度的差异,分别随机选定10株进行测定,结果见表1。
表1 玉米24号与金皇后玉米果穗长度的差异(X±SD)品种样品数/株果穗长度/cm 变异系数/% P值(双侧)玉米24号10 20±1.25 6.241.00金皇后10 20±3.40 17.00(3)分析与结论:从表1可以看出,果穗的长度,玉米24号为20±1.25cm,金皇后为20±3.40cm;玉米24号C·V是6.00%,金皇后的C·V为17.00%,金皇后的变异程度大于玉米24号。
两个品种的玉米果穗长度平均值一样,金皇后玉米的标准差、变异系数较大,表明金皇后玉米果穗长度的变异程度大。
双尾t检验分析的结果表明,比较两个品种的果穗长度差异性(P=1.00>0.05),所以,两个品种玉米的果穗长度差异无显著性。
标准差通常是相对于样本数据的平均值而定的,通常用M±SD来表示,表示样本某个数据观察值相距平均值有多远。
M:平均数(Mean)。
SD:标准差(Standard Deviation)。
MSE:均方误差(Mean Squared Error, MSE),均方误差是各数据偏离真实值的距离平方和的平均数,也即误差平方和的平均数,计算公式形式上接近方差,它的开方叫均方根误差。
R2:复平方相关系数(Squared Multiple Correlations)。
σ:标准差是离均差平方和平均后的方根。
CV:变异系数S2:方差N:样本个数数理统计基本字母及其含意Spss软件中相关字母及其含意判断相关性,先看p值,看有没有相关性;再看r值,看相关性是强还是弱。
sig是差异性显著的检验值,该值一般与0.05或0.01比较,若小于0.05或者0.01 则表示差异显著。
所谓双侧的意思是有可能在大于,有可能小于的,而单侧的意思是只有一边或者大于,或者小于的。
1.在SPSS软件统计结果中,不管是回归分析还是其它分析,都会看到“SIG”,SIG=significance,意为“显著性”,后面的值就是统计出的P值,如果P值0.01<P<0.05,则为差异显著,如果P<0.01,则差异极显著。
2.F值是方差检验量,是整个模型的整体检验,看你拟合的方程有没有意义。
自由度指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的自变量的个数,称为该统计量的自由度。
F值是方差检验量,是整个模型的整体检验,看你拟合的方程有没有意义。
3.在SPSS软件统计结果中,不管是回归分析还是其它分析,都会看到“SIG”,SIG=significance,意为“显著性”,后面的值就是统计出的P值,如果P值0.01<P<0.05,则为差异显著,如果P<0.01,则差异极显著。
4.t值是对每一个自变量(logistic回归)的逐个检验,看它的beta值β即回归系数有没有意义。
spss作图均数和标准差SPSS作图均数和标准差。
在SPSS中,作图是数据分析的重要环节之一。
通过作图,我们可以直观地展现数据的分布情况、趋势变化等信息。
而在作图时,均数和标准差是两个重要的统计指标,它们可以帮助我们更好地理解数据的特征。
本文将介绍如何在SPSS中绘制均数和标准差的图表,并解释如何解读这些图表。
首先,我们需要打开SPSS软件,并导入我们需要分析的数据。
在数据文件中,我们可以选择“分析”菜单下的“描述统计”选项,然后在弹出的对话框中选择我们需要分析的变量。
在选择完变量后,点击“统计”按钮,勾选“均数”和“标准差”,然后点击“确定”按钮进行计算。
接下来,我们可以通过“图表”菜单下的“直方图”选项来绘制均数和标准差的图表。
在弹出的对话框中,我们选择需要分析的变量,并将其拖动到“横轴”框中。
然后点击“选项”按钮,在弹出的对话框中选择“统计”选项卡,勾选“均数”和“标准差”,然后点击“确定”按钮进行绘图。
绘制完成后,我们可以对图表进行解读。
对于均数图表,我们可以通过柱状图或折线图来展现不同组别的均数值,从而比较它们的差异。
而对于标准差图表,我们可以通过误差线图或箱线图来展现不同组别的数据离散程度,从而比较它们的稳定性。
通过均数和标准差的图表,我们可以得出一些结论。
例如,如果不同组别的均数值有明显差异,那么我们可以认为这些组别之间存在显著差异。
而如果不同组别的标准差值较大,那么我们可以认为这些组别的数据较为分散。
这些结论可以帮助我们更好地理解数据的特征,从而为后续的分析和决策提供参考。
总之,在SPSS中绘制均数和标准差的图表是数据分析的重要步骤之一。
通过这些图表,我们可以更直观地了解数据的特征,从而为后续的分析和决策提供支持。
希望本文的介绍能够帮助读者更好地掌握SPSS作图的技巧,提高数据分析的效率和准确性。
spss计算均值和标准差SPSS计算均值和标准差。
在统计学中,均值和标准差是描述数据集中集中趋势和离散程度的重要统计量。
在SPSS软件中,我们可以通过简单的操作来计算数据的均值和标准差。
本文将介绍如何在SPSS中进行这些计算,并对计算结果进行解释和分析。
首先,我们需要打开SPSS软件,并导入我们要分析的数据集。
在数据集导入后,我们可以通过如下步骤来计算数据的均值和标准差。
1. 计算均值:在SPSS软件中,我们可以通过如下步骤来计算数据的均值:点击“分析”菜单,选择“描述统计”子菜单,然后点击“描述”;在弹出的对话框中,选择需要计算均值的变量,并将其移动到右侧的“变量”框中;点击“统计”按钮,然后在弹出的对话框中勾选“均值”选项;点击“确定”按钮,SPSS将会输出所选变量的均值。
2. 计算标准差:类似地,我们可以通过如下步骤来计算数据的标准差:在上述步骤的基础上,点击“统计”按钮,在弹出的对话框中勾选“标准差”选项;点击“确定”按钮,SPSS将会输出所选变量的标准差。
在计算完均值和标准差后,我们可以对计算结果进行解释和分析。
均值可以帮助我们了解数据的集中趋势,而标准差则可以帮助我们了解数据的离散程度。
通过这些统计量,我们可以更好地理解数据的特征,并进行进一步的数据分析和建模工作。
需要注意的是,均值和标准差只是描述数据分布的两个方面,对于不同类型的数据,我们可能还需要使用其他统计量来进行描述和分析。
在实际应用中,我们应该根据具体情况选择合适的统计量,并结合领域知识进行综合分析。
总之,通过SPSS软件,我们可以方便地计算数据的均值和标准差,并通过这些统计量来描述和分析数据的特征。
在实际应用中,我们应该充分利用统计工具来辅助我们对数据进行深入的理解和分析,从而更好地支持决策和研究工作。
spss均值和标准差SPSS均值和标准差。
在统计学中,均值和标准差是两个非常重要的概念,它们可以帮助我们更好地理解数据的分布和变异程度。
在SPSS软件中,我们可以很方便地计算出数据的均值和标准差,从而进行进一步的分析和研究。
本文将介绍如何在SPSS中进行均值和标准差的计算,并对其进行简要的解释和应用。
首先,我们需要打开SPSS软件,并导入我们要进行分析的数据。
在数据导入后,我们可以通过如下步骤进行均值和标准差的计算:1. 点击“分析”菜单,选择“描述统计”子菜单中的“描述”选项;2. 在弹出的对话框中,将需要计算均值和标准差的变量移动到右侧的“变量”框中;3. 点击“统计”按钮,在弹出的对话框中勾选“均值”和“标准差”选项;4. 点击“确定”按钮,SPSS将会自动计算所选变量的均值和标准差,并在输出窗口中显示结果。
通过以上步骤,我们可以很容易地得到数据的均值和标准差。
均值代表了数据的平均水平,而标准差则代表了数据的离散程度。
接下来,我们将对均值和标准差进行简要的解释和应用。
均值是一组数据的平均水平,它可以帮助我们了解数据的集中趋势。
例如,我们可以计算一组学生的考试成绩的均值,从而了解这个班级整体的学习水平。
另外,均值也可以用来比较不同组别之间的差异,例如不同性别、年龄、教育水平的人群在某项指标上的平均水平是否存在显著差异。
标准差则代表了数据的离散程度,它可以帮助我们了解数据的变异程度。
标准差越大,代表数据的离散程度越大,反之亦然。
例如,在招聘面试中,我们可以计算应聘者的面试成绩的标准差,从而了解这个群体的面试表现的变异程度。
另外,标准差也可以用来衡量数据的稳定性,例如在质量控制中,我们可以通过标准差来评估产品质量的稳定程度。
在实际应用中,均值和标准差经常被用来进行数据分析和决策。
例如,在市场调研中,我们可以通过计算消费者对某一产品的满意度的均值和标准差,来评估产品的市场表现和改进空间。
另外,在医学研究中,我们也可以通过计算患者的生化指标的均值和标准差,来评估疾病的严重程度和治疗效果。
spss计算均值和标准差SPSS计算均值和标准差。
在统计学中,均值和标准差是描述数据集中集中趋势和离散程度的重要指标。
在SPSS软件中,计算均值和标准差非常简单,本文将介绍如何在SPSS中进行这两项统计计算。
首先,打开SPSS软件并加载你的数据集。
在数据视图中,你将看到你的数据表格。
假设我们有一个包含了学生考试成绩的数据集,我们想要计算他们的数学成绩的均值和标准差。
首先,选择“分析”菜单,然后选择“描述统计”和“描述”。
在弹出的对话框中,将你想要计算的变量移动到右侧的框中。
在我们的例子中,我们将选择数学成绩这一变量。
然后点击“统计”按钮,在弹出的对话框中选择“均值”和“标准差”,然后点击“确定”。
SPSS将会生成一个新的输出窗口,其中包含了你所选择的变量的均值和标准差。
在输出窗口中,你将看到一个表格,其中包含了你所选择的变量的均值和标准差。
除了通过“描述统计”来计算均值和标准差之外,你还可以使用SPSS的计算变量功能来创建新的变量,其中包含了均值和标准差。
这样可以方便你在进一步的分析中使用这些统计指标。
要使用计算变量功能,选择“转换”菜单,然后选择“计算变量”。
在弹出的对话框中,输入你想要创建的新变量的名称,然后在“数值表达式”框中输入计算均值和标准差的表达式。
例如,你可以输入“MEAN(数学成绩)”来计算数学成绩的均值,输入“SD(数学成绩)”来计算数学成绩的标准差。
然后点击“OK”来创建新的变量。
无论是通过“描述统计”还是通过计算变量功能,SPSS都可以帮助你轻松地计算数据集中变量的均值和标准差。
这些统计指标对于理解数据的分布和特征非常重要,可以帮助你进行更深入的数据分析和建模。
总之,SPSS软件提供了多种方法来计算数据集中变量的均值和标准差。
通过本文介绍的方法,你可以轻松地在SPSS中进行这些统计计算,并且可以在进一步的数据分析中应用这些统计指标。
希望本文对你有所帮助,谢谢阅读!。
spss均值和标准差SPSS均值和标准差。
在统计学中,均值和标准差是描述数据分布和集中趋势的重要指标。
SPSS作为一款强大的统计分析软件,可以帮助研究者快速计算和分析数据的均值和标准差。
本文将介绍如何在SPSS中进行均值和标准差的计算,并对其结果进行解释和应用。
1. 数据导入。
在进行均值和标准差的计算之前,首先需要将数据导入SPSS软件中。
可以通过“文件”-“导入数据”命令,选择相应的数据文件进行导入。
在导入数据时,需要注意数据的格式和变量的命名,确保数据的准确性和完整性。
2. 计算均值。
在SPSS中,计算变量的均值非常简单。
选择“分析”-“描述统计”-“均值”命令,在弹出的对话框中选择需要计算均值的变量,然后点击“确定”按钮即可得到相应变量的均值。
此外,还可以通过计算新变量的方式,利用公式计算多个变量的均值。
均值的计算结果可以帮助研究者了解数据的集中趋势,即数据整体的平均水平。
通过对均值的比较,可以发现不同变量之间的差异,进而进行更深入的数据分析和解释。
3. 计算标准差。
标准差是衡量数据离散程度的重要指标,可以通过SPSS快速计算得出。
选择“分析”-“描述统计”-“频率”命令,在弹出的对话框中选择需要计算标准差的变量,然后点击“统计量”按钮,在弹出的对话框中勾选“标准差”选项,最后点击“确定”按钮即可得到相应变量的标准差。
标准差的计算结果可以帮助研究者了解数据的离散程度,即数据的分散情况。
通过对标准差的比较,可以发现数据的波动程度,进而进行数据的波动程度,进而进行更深入的数据分析和解释。
4. 结果解释和应用。
得到均值和标准差的计算结果之后,需要对其进行解释和应用。
首先,可以通过直方图、箱线图等可视化手段展示数据的分布情况,进一步分析数据的特点和规律。
其次,可以利用均值和标准差进行假设检验和方差分析,探究不同变量之间的关系和差异。
最后,可以将均值和标准差作为数据描述的重要依据,用于撰写研究报告和论文。