应用多元统计分析课后习题答案高惠璇(第二章部分习题解答
- 格式:pptx
- 大小:824.35 KB
- 文档页数:25
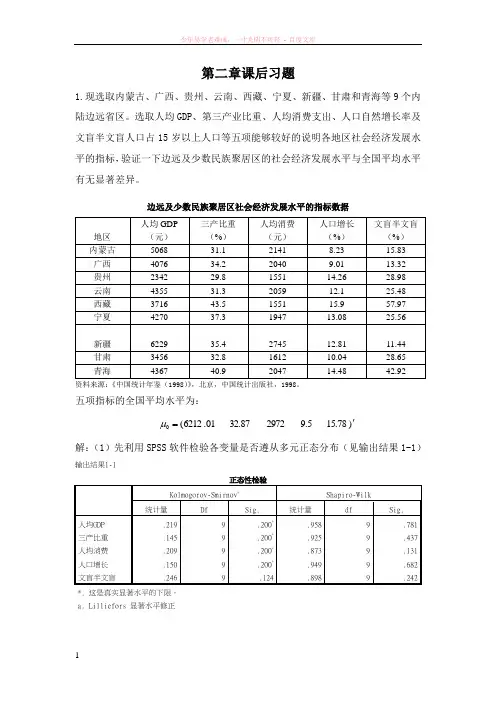
第二章课后习题1.现选取内蒙古、广西、贵州、云南、西藏、宁夏、新疆、甘肃和青海等9个内陆边远省区。
选取人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口等五项能够较好的说明各地区社会经济发展水平的指标,验证一下边远及少数民族聚居区的社会经济发展水平与全国平均水平有无显著差异。
边远及少数民族聚居区社会经济发展水平的指标数据地区人均GDP(元)三产比重(%)人均消费(元)人口增长(%)文盲半文盲(%)内蒙古506831.121418.2315.83广西407634.220409.0113.32贵州234229.8155114.2628.98云南435531.3205912.125.48西藏371643.5155115.957.97宁夏427037.3194713.0825.56新疆622935.4 274512.8111.44甘肃345632.8161210.0428.65青海436740.9204714.4842.92资料来源:《中国统计年鉴(1998)》,北京,中国统计出版社,1998。
五项指标的全国平均水平为:)15.789.5297232.8701.6212(0'=μ解:(1)先利用SPSS软件检验各变量是否遵从多元正态分布(见输出结果1-1)输出结果1-1正态性检验Kolmogorov-Smirnov a Shapiro-Wilk统计量Df Sig. 统计量df Sig.人均GDP .219 9 .200*.958 9 .781 三产比重.145 9 .200*.925 9 .437 人均消费.209 9 .200*.873 9 .131 人口增长.150 9 .200*.949 9 .682 文盲半文盲.246 9 .124 .898 9 .242 *. 这是真实显著水平的下限。
a. Lilliefors 显著水平修正上表给出了对每一个变量进行正态性检验的结果,因为该例中样本数n=9,所以此处选用Shapiro-Wilk 统计量。





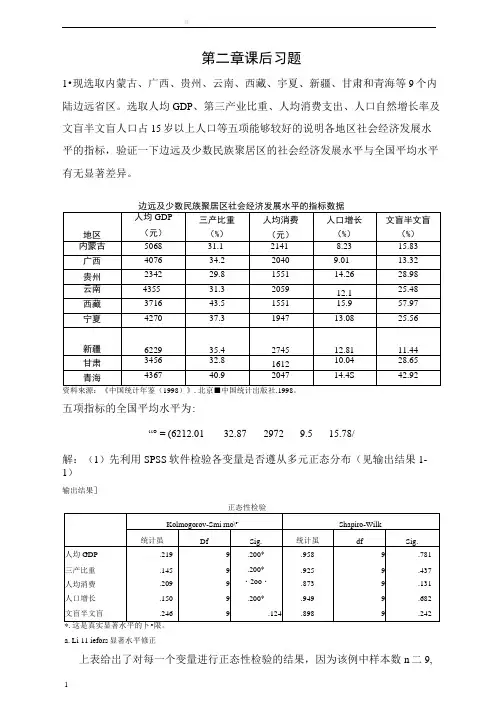
年第二章课后习题1•现选取内蒙古、广西、贵州、云南、西藏、宇夏、新疆、甘肃和青海等9个内陆边远省区。
选取人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口等五项能够较好的说明各地区社会经济发展水平的指标,验证一下边远及少数民族聚居区的社会经济发展水平与全国平均水平有无显著差异。
五项指标的全国平均水平为:“° = (6212.01 32.87 2972 9.5 15.78/解:(1)先利用SPSS软件检验各变量是否遵从多元正态分布(见输出结果1-1)输出结果]a. Li 11 iefors显著水平修正上表给岀了对每一个变量进行正态性检验的结果,因为该例中样本数n二9,所以此处选用Shapiro-Wilk统计量。
则Sig.值分别为0. 781、0. 437、0. 131、0.682、0.242均大于显著性水平,由此可以知道,人均GDP、三产比重、人均消费、人口增长、文盲半文盲这五个变量组成的向量均服从正态分布,即我们认为这五个指标可以较好对各地区社会经济发展水平做出近似的度量。
(2)提出原假设及备选假设Hi :(3)做出统讣判断,最后对统讣判断作出具体的解释SPSS的GLM模块可以完成多元正态分布有关均值与方差的检验。
依次点选Analyze —>General Linear Mode^ IMultivariate ..................... 进入Multivariate 对话框,将人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口等这五项指标选入Dependent列表框,将分类指标选入Fixed Factor (s)框,点击OK运行,则可以得到如下结果(见输出结果1-2)。
输出结果1-2a.设计:截距+分类b.精确统计虽少年易学老难成,上面第一张表是样本数据分别来自边远及少数民族聚居区社会经济发展水平、全国的个数。



2.1.试叙述多元联合分布和边际分布之间的关系。
解:多元联合分布讨论多个随机变量联合到一起的概率分布状况,12(,,)p X X X X '=L 的联合分布密度函数是一个p 维的函数,而边际分布讨论是12(,,)p X X X X '=L 的子向量的概率分布,其概率密度函数的维数小于p 。
2.2设二维随机向量12()X X '服从二元正态分布,写出其联合分布。
解:设12()X X '的均值向量为()12μμ'=μ,协方差矩阵为21122212σσσσ⎛⎫ ⎪⎝⎭,则其联合分布密度函数为1/21222112112222122121()exp ()()2f σσσσσσσσ--⎧⎫⎛⎫⎛⎫⎪⎪'=---⎨⎬ ⎪⎪⎝⎭⎝⎭⎪⎪⎩⎭x x μx μ。
2.3已知随机向量12()X X '的联合密度函数为121212222[()()()()2()()](,)()()d c x a b a x c x a x c f x x b a d c --+-----=--其中1ax b ≤≤,2c x d ≤≤。
求(1)随机变量1X 和2X 的边缘密度函数、均值和方差; (2)随机变量1X 和2X 的协方差和相关系数;(3)判断1X 和2X 是否相互独立。
(1)解:随机变量1X 和2X 的边缘密度函数、均值和方差;112121222[()()()()2()()]()()()dx cd c x a b a x c x a x c f x dx b a d c --+-----=--⎰12212222222()()2[()()2()()]()()()()dd c c d c x a x b a x c x a x c dx b a d c b a d c -------=+----⎰ 121222202()()2[()2()]()()()()dd c c d c x a x b a t x a t dt b a d c b a d c ------=+----⎰ 2212122222()()[()2()]1()()()()d cdc d c x a x b a t x a t b a d c b a d c b a------=+=----- 所以 由于1X 服从均匀分布,则均值为2b a+,方差为()212b a -。

第四章4-1 设⎪⎩⎪⎨⎧++=+-=+=,2,2,332211εεεb a y b a y a y ).,0(~323321I N σεεεε⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=(1)试求参数b a ,的最小二乘估计;(2)试导出检验b a H =:0的似然比统计量,并指出当假设成立时,这个统计量是分布是什么?解:(1)由题意可知.,,,211201321321⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=⎥⎦⎤⎢⎣⎡=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡-=εεεεβ b a y y y Y C 则⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡-⎪⎪⎪⎪⎭⎫ ⎝⎛⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡-⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡-==--321'1''1'211201************)(ˆy y y Y C C C β.ˆˆ)2(51)2(6132321⎥⎦⎤⎢⎣⎡=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡+-++ba y y y y y(2)由题意知,检验b a H =:0的似然比统计量为2322ˆ⎪⎪⎭⎫ ⎝⎛=σσλ 其中,])ˆ2ˆ()ˆˆ2()ˆ[(31ˆ2322212b a y b a y a y --++-+-=σ。
当0H 成立时,设0a b a ==,则⎪⎩⎪⎨⎧+=+=+=,3,,303202101εεεa y a y a y ,311⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=C 可得,ˆ)3y (111311311311)(ˆ0321321'1''1'ay y y y y Y C C C =++=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡⎪⎪⎪⎪⎭⎫ ⎝⎛⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡==--β ],)ˆ3()ˆ()ˆ[(31ˆ20320220120a y a y ay -+-+-=σ因此,当假设0H 成立时,与似然比统计量λ等价的F 统计量及其分布为).1,1(~ˆˆˆ2202F F σσσ-=4-3 设Y 与321,,x x x 有相关关系,其8组观测数据见表4.5.表 4.5 观测数据序号 1x2x3xY1 38 47.5 23 66.02 41 21.3 17 43.0 3 34 36.5 21 36.0 4 35 18.0 14 23.0 5 31 29.5 11 27.06 34 14.2 9 14.07 29 21.0 4 12.0 83210.087.6(1)设εββββ++++=3322110x x x Y ,试求回归方程及决定系数2R 和均方误差2s 。
第二章课后习题1.现选取内蒙古、广西、贵州、云南、西藏、宁夏、新疆、甘肃和青海等9个内陆边远省区。
选取人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口等五项能够较好的说明各地区社会经济发展水平的指标,验证一下边远及少数民族聚居区的社会经济发展水平与全国平均水平有无显著差异。
边远及少数民族聚居区社会经济发展水平的指标数据地区人均GDP(元)三产比重(%)人均消费(元)人口增长(%)文盲半文盲(%)内蒙古506831.121418.2315.83广西407634.220409.0113.32贵州234229.8155114.2628.98云南435531.3205912.125.48西藏371643.5155115.957.97宁夏427037.3194713.0825.56新疆622935.4 274512.8111.44甘肃345632.8161210.0428.65青海436740.9204714.4842.92资料来源:《中国统计年鉴(1998)》,北京,中国统计出版社,1998。
五项指标的全国平均水平为:)15.789.5297232.8701.6212(0'=μ解:(1)先利用SPSS软件检验各变量是否遵从多元正态分布(见输出结果1-1)输出结果1-1正态性检验Kolmogorov-Smirnov a Shapiro-Wilk统计量Df Sig. 统计量df Sig.人均GDP .219 9 .200*.958 9 .781 三产比重.145 9 .200*.925 9 .437 人均消费.209 9 .200*.873 9 .131 人口增长.150 9 .200*.949 9 .682 文盲半文盲.246 9 .124 .898 9 .242 *. 这是真实显著水平的下限。
a. Lilliefors 显著水平修正上表给出了对每一个变量进行正态性检验的结果,因为该例中样本数n=9,所以此处选用Shapiro-Wilk 统计量。
应⽤多元统计分析第⼆章习题解答2.1 试述多元联合分布和边缘分布之间的关系。
设,是p维随机向量,称由它的q(当的分布函数为F,时,的分布函数即边缘分布函数为F,=P()= F,当X有分布密度f(,)则也有分布密度,即边缘密度函数为:f(,)=(,)2.2 设随机向量服从⼆元正态分布,写出其联合分布密度函数和各⾃的边缘密度函数。
联合分布密度函数,0 , 其他==()所以指数部分变为令t== exp[] exp[] ,=0 ,其他同理,exp[] ,=0 ,其他2.3 已知随机向量的联合分布密度函数为,其中, 。
求:(1)随机变量各⾃的边缘密度函数、均值与⽅差。
解:==同理,==()()??+=-?==+∞∞-b aba dx ab x x f x x E 21111111 同理可得()22d c x E +=()()()()()()??-=-???? ?+-=-=∞+∞-ba b a dx a b b a x x d x f x E x x D 12122 1211112111 同理可得()()1222d c x D -=(2)随机变量的协⽅差和相关系数。
E( ==E(==E(= =E(=D( E( D( E(Cov E( E(=.===(3)判断是否独⽴。
不相互独⽴。
2.4设随机向量,服从正态分布,已知其协差阵为对⾓阵,证明的分量是相互独⽴的随机变量。
Σ=ΣΣΣΣ与不相关⼜,服从正态分布与相互独⽴。
(,,,,,) 2.5解:依据题意,X=E(X)=D(X)=注:利⽤ 11p n n ?'=1X X , S 1()n n n n''=-11X I X 其中 1001n ??=I 在SPSS 中求样本均值向量的操作步骤如下:1. 选择菜单项Analyze →Descriptive Statistics →Descriptives ,打开Descriptives 对话框。
将待估计的四个变量移⼊右边的Variables 列表框中,如图2.1。