《Python机器学习编程与实战》第7章 餐饮企业综合分析
- 格式:pptx
- 大小:628.82 KB
- 文档页数:56

python——餐饮数据分析· 话不多说,直接上代码。
⼀、import pandas as pdimport numpy as npimport matplotlib.pyplot as pltinfo = pd.read_csv('meal_order_info.csv', encoding='utf-8')info_before = pd.read_csv('info_new.csv', encoding='utf-8')#将两个数据拼起来info_all = pd.concat([info_before, info])print('查看各表的维数:\n', info.shape, info_before.shape, info_all.shape)info.head()split():就是将⼀个字符串分隔成多个字符串组成的列表enumerate(info['use_start_time'])基本应⽤就是⽤来遍历⼀个集合对象,它在遍历的同时还可以得到当前元素的索引位置#条件选取order_status==1的数据info = info_all[info_all['order_status'].isin(['1'])]# data = info_all[info_all['order_status']==1]info = info.reset_index(drop=True)# 统计每⽇⽤餐⼈数与营业额#将时间后⾯的师傅们去掉for i, k in enumerate(info['use_start_time']):y = k.split()y = pd.to_datetime(y[0])info.loc[i, 'use_start_time'] = y#提取三列数据# info[['use_start_time', 'number_consumers','accounts_payable']]groupbyday = info[['use_start_time', 'number_consumers','accounts_payable']].groupby(by='use_start_time')#以时间分组sale_day = groupbyday.sum()#定义列名称sale_day.columns = ['⼈数', '销量']sale_day散点图:fig1 = plt.figure()#定义⼀个数组作为横坐标x = np.arange(1,244,1)#图⼤⼩设置plt.figure(figsize=(12, 6))y = sale_day['⼈数']plt.plot(x,y,'.r')plt.xlabel('x')plt.ylabel('y')plt.savefig('散点图.png',dpi=300) plt.show()进阶散点图#x,y变量变化nbins = 200H, xedges, yedges = np.histogram2d(x,y,bins=nbins) # H needs to be rotated and flippedH = np.rot90(H)H = np.flipud(H)# 将zeros maskHmasked = np.ma.masked_where(H==0,H)fig2 = plt.figure()#图⼤⼩设置plt.figure(figsize=(12, 6))plt.pcolormesh(xedges,yedges,Hmasked)plt.xlabel('x')plt.ylabel('y')cbar = plt.colorbar()cbar.ax.set_ylabel('Counts')plt.savefig('2D.png',dpi=300)plt.show()折线图:# 每⽇⽤餐⼈数折线图# 解决中⽂显⽰问题plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(12, 6))plt.title('每⽇⽤餐⼈数折线图')plt.xlabel('⽇期')plt.ylabel('⽤餐⼈数')plt.plot(sale_day['⼈数'])plt.show()plt.close# 画出每⽇销售额的折线图# 新建画板plt.figure(figsize=(12, 6))plt.title('每⽇销售额的折线图')plt.xlabel('⽇期')plt.ylabel('销售额')plt.plot(sale_day['销量'])plt.show()plt.close折线图进阶——双坐标轴plt.figure(figsize=(12, 6))Y1=sale_day['⼈数']Y2=sale_day['销量']#标题plt.title("title")#create figure#fig, ax =plt.subplots(1)# Plot y1 vs x in blue on the left vertical axis.plt.xlabel("时间")plt.ylabel("y1", color="g")plt.tick_params(axis="y", labelcolor="g")plt.plot(Y1, "g-", linewidth=2)fig.autofmt_xdate(rotation=50)# Plot y2 vs x in red on the right vertical axis.plt.twinx()plt.ylabel("y2", color="r")plt.tick_params(axis="y", labelcolor="r")plt.plot(Y2, "r-", linewidth=2)#To save your graph#plt.savefig('saltandtemp_V1.png' ,dpi=300)plt.show()⼆、info_august = pd.read_csv('meal_order_info.csv', encoding='utf-8') users_august = pd.read_csv('users.csv', encoding='gbk')# 提取订单状态为1的数据info_august_new = info_august[info_august['order_status'].isin(['1'])] info_august_new = info_august_new.reset_index(drop=True)print('提取的订单数据维数:', info_august_new.shape)info_august_new.head()info_august_new.to_csv('info_august_new.csv', index=False, encoding='utf-8')# 匹配⽤户的最后⼀次⽤餐时间for i in range(1, len(info_august_new)):num = users_august[users_august['USER_ID'] ==info_august_new.iloc[i-1, 1]].index.tolist()users_august.iloc[num[0], 14] = info_august_new.iloc[i-1, 9]users_august.iloc[num[0], 14] = info_august_new.iloc[i-1, 9]user = users_augustuser['LAST_VISITS'] = user['LAST_VISITS'].fillna(999)user = user.drop(user[user['LAST_VISITS'] == 999].index.tolist())user = user.iloc[:, [0, 2, 12, 14]]user.head()# 读取数据users = pd.read_csv('user_loss.csv', encoding='gbk')info = pd.read_csv('info_new.csv', encoding='utf-8')print('历史客户信息表的维数:', users.shape)print('历史订单表的维数:', info.shape)# 将时间转为时间格式users['CREATED'] = pd.to_datetime(users['CREATED'])info['use_start_time'] = pd.to_datetime(info['use_start_time'])info['lock_time'] = pd.to_datetime(info['lock_time'])# 匹配⽤户的最后⼀次⽤餐时间for i in range(len(users)):info1 = info.iloc[info[info['name'] == users.iloc[i, 2]].index.tolist(), :]if sum(info['name']==users.iloc[i, 2]) != 0:users.iloc[i, 14] = max(info1['use_start_time'])# 特征选取# 提取有效订单info = info.loc[info['order_status'] == 1, ['emp_id', 'number_consumers', 'expenditure']] info = info.rename(columns={'emp_id': 'USER_ID'}) # 修改列名info.head()info_user.to_csv('info_user.csv', index=False, encoding='utf-8')import pandas as pdfrom sklearn.preprocessing import StandardScalerimport numpy as npuser_value1.columns = ['USER_ID', 'F'] # 修改列名print('F特征的最⼤值:', max(user_value1['F']))print('F特征的最⼩值:', min(user_value1['F']))# 构建M特征user_value2 = info[['emp_id', 'expenditure']].groupby(by='emp_id').sum() user_value2 = pd.DataFrame(user_value2).reset_index()user_value2.columns = ["USER_ID", "M"]user_value = pd.merge(user_value1, user_value2, on='USER_ID') print('M特征的最⼤值:', max(user_value['M']))print('M特征的最⼩值:', min(user_value['M']))# 构建R特征user_value = pd.merge(user_value, user, on='USER_ID') # 合并两个表# 转换时间格式for i, k in enumerate(user_value['LAST_VISITS']):y = k.split()y = pd.to_datetime(y[0])user_value.loc[i, 'LAST_VISITS'] = ylast_time = pd.to_datetime(user_value['LAST_VISITS'])deadline = pd.to_datetime("2016-8-31") # 观测窗⼝结束时间user_value['R'] = deadline - last_timeprint('R特征的最⼤值:', max(user_value['R']))print('R特征的最⼩值:', min(user_value['R']))# 代码 7-5# 特征提取user_value = user_value.iloc[:, [0, 3, 6, 1, 2]]user_value.to_csv("user_value.csv", encoding="utf-8_sig", index=False)USER_ID = user_value['USER_ID']ACCOUNT = user_value['ACCOUNT']user_value = user_value.iloc[:, [2, 3, 4]]user_value.iloc[:, 0] = [i.days for i in user_value.iloc[:, 0]]# 标准差标准化standard = StandardScaler().fit_transform(user_value)np.savez('standard.npz', standard)print(standard)三、聚类standard = np.load('standard.npz')['arr_0']k = 3 # 聚类中⼼数# 构建模型kmeans_model = KMeans(n_clusters=k, n_jobs=3, random_state=123)fit_kmeans = kmeans_model.fit(standard) # 模型训练print('聚类中⼼:\n', kmeans_model.cluster_centers_)print('样本的类别标签:\n', kmeans_bels_)# 统计不同类别样本的数⽬r1 = pd.Series(kmeans_bels_).value_counts()print('最终每个类别的数⽬为:\n', r1)# 代码 7-7# %matplotlib inlineimport matplotlib.pyplot as plt# 中⽂和负号的正常显⽰plt.rcParams['font.sans-serif'] = 'SimHei'plt.rcParams['axes.unicode_minus'] = False# 绘制雷达图N = len(kmeans_model.cluster_centers_[0])# 设置雷达图的⾓度,⽤于平分切开⼀个圆⾯angles = np.linspace(0, 2 * np.pi, N, endpoint=False)# 为了使雷达图⼀圈封闭起来angles = np.concatenate((angles, [angles[0]]))# 绘图fig = plt.figure(figsize=(7, 7))ax = fig.add_subplot(111, polar=True)sam = ['r','g','b']lstype = ['-','--','-.']lab = []for i in range(len(kmeans_model.cluster_centers_)):values = kmeans_model.cluster_centers_[i]feature = ['R','F','M']values = np.concatenate((values, [values[0]]))# 绘制折线图ax.plot(angles, values, sam[i], linestyle=lstype[i], linewidth=2, markersize=10)ax.fill(angles, values, alpha=0.5) # 填充颜⾊#ax.set_thetagrids(angles * 180 / np.pi, feature, fontsize=15) # 添加每个特征的标签 plt.title('客户群特征分布图') # 添加标题ax.grid(True)lab.append('客户群' + str(i+1))plt.legend(lab)#plt.savefig('征分布图.png')plt.show()plt.close。

第9章餐饮企业综合分析教案课程名称:R语言商务数据分析实战课程类别:必修适用专业:大数据技术类相关专业总学时:80学时(其中理论45学时,实验35学时)总学分:5.0学分本章学时:20学时一、材料清单(1)《R语言商务数据分析实战》教材。
(2)配套PPT。
(3)引导性提问。
(4)探究性问题。
(5)拓展性问题。
二、教学目标与基本要求1.教学目标主要介绍利用多种模型综合分析餐饮企业,先介绍餐饮企业的现状,对数据进行简单的统计分析。
而后利用ARIMA模型、智能推荐、K-Means模型和决策树模型,对某餐饮企业的菜品和客户进行不同方面的分析,并针对性地提出相关建议,以提高某餐饮企业的经营收益。
2.基本要求(1)熟悉餐饮企业数据分析的步骤与流程。
(2)了解简单的统计分析的应用。
(3)使用ARIMA预测销售额。
(4)使用协同过滤算法对菜品进行智能推荐。
(5)使用Apriori算法对菜品进行关联分析。
(6)使用K-Means算法进行客户分群。
(7)使用决策树算法进行客户流失预测。
三、问题1.引导性提问引导性提问需要教师根据教材内容和学生实际水平,提出问题,启发引导学生去解决问题,提问,从而达到理解、掌握知识,发展各种能力和提高思想觉悟的目的。
(1)目前一般餐饮企业会面临哪些问题?(2)餐饮企业产生的数据有哪些,能做什么分析?2.探究性问题探究性问题需要教师深入钻研教材的基础上精心设计,提问的角度或者在引导性提问的基础上,从重点、难点问题切入,进行插入式提问。
或者是对引导式提问中尚未涉及但在课文中又是重要的问题加以设问。
(1)客户价值分析构建的模型是否还能优化?(2)客户流失预测模型是否还能优化?3.拓展性问题拓展性问题需要教师深刻理解教材的意义,学生的学习动态后,根据学生学习层次,提出切实可行的关乎实际的可操作问题。
亦可以提供拓展资料供学生研习探讨,完成拓展性问题。
(1)客户流失预测的方法,除了决策树之外,还有哪些方法?四、主要知识点、重点与难点1.主要知识点(1)了解餐饮企业的数据情况。

Python机器学习编程教案教案概述:本教案旨在通过Python编程语言和机器学习算法,帮助学生掌握餐饮企业综合分析的基本方法和技巧。
学生将通过编程习题的方式,学习如何使用Python处理数据、构建模型和进行预测。
教学目标:1. 理解Python编程语言的基本概念和语法。
2. 掌握使用Python进行数据处理和分析的基本方法。
3. 学习机器学习算法的基本原理和应用。
4. 能够使用Python编程语言和机器学习算法进行餐饮企业综合分析。
教学内容:第一章:Python编程基础1.1 Python简介1.2 Python安装和环境配置1.3 Python语法基础1.4 Python数据类型1.5 Python控制结构第二章:Python数据处理2.1 NumPy库介绍2.2 NumPy数组操作2.3 Pandas库介绍2.4 Pandas数据处理2.5 数据可视化第三章:机器学习基本概念3.1 机器学习简介3.2 监督学习3.3 无监督学习3.4 评估指标3.5 模型选择与优化第四章:Python机器学习库4.1 scikit-learn库介绍4.2 分类算法4.3 回归算法4.4 聚类算法4.5 模型评估与选择第五章:餐饮企业综合分析实例5.1 数据收集与预处理5.2 特征选择与提取5.3 构建分类模型5.4 模型评估与优化5.5 结果分析与决策支持教学方法:1. 讲解与示范:教师通过PPT和代码示例进行讲解,让学生理解和掌握Python 编程语言和机器学习算法的基本概念和方法。
2. 编程习题:学生通过完成编程习题,巩固所学知识和提高编程能力。
3. 案例分析:学生通过分析餐饮企业综合分析实例,学会将机器学习算法应用于实际问题。
教学评估:1. 课堂参与度:观察学生在课堂上的积极参与程度和提问回答情况,评估学生对教学内容的理解和掌握程度。
2. 编程习题完成情况:评估学生在编程习题中的表现,检查学生对Python编程语言和机器学习算法的掌握情况。


Python数据分析与机器学习实战在过去的几年中,Python一直是数据分析和机器学习领域中最受欢迎的编程语言之一。
其简洁的语法和强大的库使得Python成为了许多数据科学家和机器学习工程师的首选工具。
本文将介绍Python在数据分析和机器学习方面的应用,并展示一些实战案例。
一、数据分析数据分析是指通过收集、清洗、转换和建模数据,从数据中提取有用的信息和洞察,以支持决策和解决问题。
Python提供了一些重要的库,如NumPy、Pandas和Matplotlib,用于数据处理、分析和可视化。
1. NumPyNumPy是Python中最基础的科学计算库之一,提供了高性能的多维数组对象和对数组操作的各种函数。
它为数据分析提供了强大的基础,能够快速高效地进行数值计算和数据处理。
2. PandasPandas是一个数据分析和处理库,提供了数据结构和操作工具,如Series和DataFrame,用于处理结构化数据。
它可以轻松地读取、写入和处理各种格式的数据,如CSV、Excel和SQL数据库。
3. MatplotlibMatplotlib是一个用于创建静态、动态和交互式可视化图表的库。
它可以创建各种类型的图表,如折线图、散点图、柱状图等,以帮助我们更好地理解和解释数据。
Matplotlib还可以与Pandas库无缝集成,使得数据可视化变得非常方便。
二、机器学习机器学习是一门研究如何使计算机具有学习能力的领域。
Python提供了许多强大的机器学习库,如Scikit-learn和TensorFlow,用于实现各种机器学习算法和模型。
1. Scikit-learnScikit-learn是一个简单而高效的机器学习库,提供了丰富的机器学习算法和工具,如分类、回归、聚类和降维等。
它还提供了模型选择、评估和预处理等功能,使得机器学习任务变得更加简单和高效。
2. TensorFlowTensorFlow是一个开源的机器学习框架,由Google开发。

Python数据分析实战之机器学习实战教程机器学习是人工智能的一个分支,它的主要目标是让计算机从数据中学习规律并进行预测、分类和聚类等任务。
Python是广受欢迎的编程语言,由于其易学易用、插件丰富的特点,成为了数据科学领域的首选工具。
本篇文章将为大家介绍Python数据分析实战之机器学习实战教程,让大家了解Python在机器学习领域的应用。
一、Python在机器学习领域的重要性Python作为一种高级编程语言,其语法简洁易懂,代码可读性好并且易于维护,因此在数据科学领域里得到了广泛应用。
Python通过numpy、scipy等数学计算库,Pandas数据分析库和matplotlib等数据可视化库等工具包,可以进行数据处理及可视化;通过scikit-learn等机器学习库、TensorFlow等深度学习框架,Python可以进行机器学习和神经网络等领域的高级研究。
二、机器学习的基本技术和模型机器学习主要分为监督学习、无监督学习和强化学习三类。
其中,监督学习有分类和回归两种类型,无监督学习主要包括聚类、降维等。
在机器学习的算法中,最常用的监督学习的模型是决策树、朴素贝叶斯、支持向量机、神经网络等;无监督学习的模型常用的有k-means聚类、主成分分析等。
三、Python机器学习库简介Python有众多的机器学习库,让数据科学家可以非常方便地使用机器学习算法进行各种应用。
以下是一些常见的Python机器学习库:1. Scikit-learn:是一个简单的机器学习库,它包含用于分类、回归和聚类等任务的算法,还有用于模型选择、数据预处理和特征选择等方面的工具。
2. TensorFlow:是谷歌开发的深度学习库,可以用于自然语言处理、语音识别、计算机视觉、机器翻译等方面的应用。
3. Keras:是一个高层次的深度学习库,可以让使用者轻松地进行深度学习的建模,Keras可以在TensorFlow、Microsoft Cognitive Toolkit和Theano等深度学习框架之上运行。



Python机器学习编程教案(Python scikit-learn教案)教案章节:一、Python机器学习简介1.1 Python在机器学习中的应用1.2 安装Python和必要的库1.3 第一个机器学习算法:线性回归二、数据预处理2.1 数据清洗2.2 特征选择2.3 特征缩放2.4 数据转换三、监督学习算法3.1 线性回归3.2 逻辑回归3.3 决策树3.4 随机森林3.5 支持向量机(SVM)四、无监督学习算法4.1 K-近邻(KNN)4.2 聚类算法(如K-均值)4.3 主成分分析(PCA)4.4 关联规则学习五、模型评估与优化5.1 交叉验证5.2 评估指标(如准确率、召回率、F1分数)5.3 网格搜索与随机搜索5.4 超参数调优六、Python scikit-learn库详解6.1 scikit-learn概述6.2 安装和配置scikit-learn6.3 使用scikit-learn进行数据预处理6.4 使用scikit-learn进行特征选择和特征提取七、监督学习实战7.1 使用scikit-learn实现线性回归7.2 使用scikit-learn实现逻辑回归7.3 使用scikit-learn实现决策树7.4 使用scikit-learn实现随机森林7.5 使用scikit-learn实现支持向量机(SVM)八、无监督学习实战8.1 使用scikit-learn实现K-近邻(KNN)8.2 使用scikit-learn实现K-均值聚类8.3 使用scikit-learn实现主成分分析(PCA)8.4 使用scikit-learn实现关联规则学习九、模型评估与优化策略9.1 使用scikit-learn进行交叉验证9.2 使用scikit-learn评估模型性能9.3 使用网格搜索优化模型参数9.4 使用随机搜索优化模型参数十、综合案例分析10.1 案例选择与数据准备10.2 数据预处理和特征工程10.3 监督学习算法应用10.4 无监督学习算法应用10.5 模型评估与优化总结十一、高级监督学习算法11.1 梯度提升机(GBM)11.2 随机梯度下降(SGD)11.3 套索回归(Lasso)和弹性网(Elastic Net)11.4 神经网络简介十二、深度学习与Python12.1 深度学习概述12.2 使用TensorFlow和Keras进行深度学习12.3 构建和训练简单的神经网络模型12.4 应用:手写数字识别(MNIST数据集)十三、自然语言处理与机器学习13.1 自然语言处理基础13.2 使用scikit-learn进行文本预处理13.3 机器学习算法在NLP中的应用13.4 词嵌入和词袋模型十四、集成学习方法14.1 集成学习的基本概念14.2 随机森林和梯度提升机的集成14.3 堆叠(Stacking)和Boosting14.4 XGBoost和LightGBM简介十五、真实世界中的机器学习项目15.1 项目流程与管理15.2 数据收集和准备15.3 模型选择与训练15.4 模型评估与部署15.5 案例研究:推荐系统重点和难点解析1. 理解并应用监督学习算法,如线性回归、逻辑回归、决策树、随机森林和支持向量机。

Python机器学习编程教案第一章:Python基础回顾1.1 Python简介1.2 Python安装与使用1.3 Python基本语法1.4 数据类型1.5 控制流程1.6 函数1.7 模块与包第二章:数据预处理2.1 数据清洗2.2 数据转换2.3 特征选择2.4 特征缩放2.5 数据集划分第三章:监督学习3.1 线性回归3.2 逻辑回归3.3 支持向量机3.4 决策树3.5 随机森林第四章:无监督学习4.1 聚类算法4.2 关联规则挖掘4.3 降维技术4.4 孤立森林4.5 深度学习简介第五章:模型评估与优化5.1 交叉验证5.2 评分指标5.3 超参数调优5.4 模型融合5.5 模型可视化第六章:餐饮企业数据采集与处理6.1 数据来源与采集6.2 数据预处理方法6.3 数据清洗与转换6.4 特征工程6.5 数据集划分第七章:餐饮企业数据分析案例7.1 案例一:销售数据分析7.2 案例二:顾客满意度调查分析7.3 案例三:库存管理优化7.4 案例四:菜品推荐系统7.5 案例五:营业时间优化第八章:Python编程习题8.1 基本语法练习8.2 数据类型与运算符练习8.3 控制流程练习8.4 函数与模块练习8.5 综合编程练习第九章:监督学习编程习题9.1 线性回归编程习题9.2 逻辑回归编程习题9.3 支持向量机编程习题9.4 决策树编程习题9.5 随机森林编程习题第十章:综合项目实战10.1 项目背景与需求分析10.2 数据采集与预处理10.3 模型选择与训练10.4 模型评估与优化重点和难点解析重点一:Python基础回顾Python基本语法、数据类型、控制流程、函数、模块与包是Python编程的核心内容,需要重点掌握。
重点二:数据预处理数据清洗、转换、特征选择、特征缩放和数据集划分是机器学习项目中的关键步骤,对模型的性能有重要影响。
重点三:监督学习线性回归、逻辑回归、支持向量机、决策树和随机森林是常见的监督学习算法,了解它们的工作原理和应用场景至关重要。
Python机器学习编程教案第一章:Python基础与环境搭建1.1 Python简介Python的历史与发展Python的应用领域Python的特点与优势1.2 Python环境搭建Python安装与配置虚拟环境创建与使用Python解释器与交互式编程1.3 Python编程基础Python数据类型与变量控制结构:条件语句与循环语句函数与模块导入第二章:数据处理与可视化2.1 NumPy库介绍NumPy库的基本功能NumPy数组创建与操作NumPy矩阵运算与线性代数2.2 Pandas库介绍Pandas数据结构:Series与DataFrame 数据读取与写入:CSV、Excel等文件格式数据清洗与预处理2.3 Matplotlib与Seaborn库介绍数据可视化基本概念Matplotlib绘图入门Seaborn库高级绘图技巧第三章:机器学习基本概念3.1 机器学习概述机器学习的定义与发展历程机器学习的主要任务与类型机器学习的基本流程3.2 监督学习线性回归与线性分类决策树与随机森林支持向量机与核函数3.3 无监督学习聚类分析:K-means、层次聚类等关联规则挖掘:Apriori、FP-growth等降维技术:PCA、t-SNE等第四章:Python机器学习库Scikit-learn 4.1 Scikit-learn库介绍Scikit-learn库的基本功能与结构机器学习算法分类与选择模型评估与交叉验证4.2 常用分类算法逻辑回归支持向量机(SVM)神经网络与K近邻算法4.3 常用回归算法线性回归岭回归与Lasso回归决策树与随机森林第五章:餐饮企业综合分析案例5.1 数据准备与预处理数据来源与收集数据清洗与预处理数据探索性分析5.2 特征工程特征选择与降维特征转换与标准化特征编码与处理5.3 模型训练与评估建立分类与回归模型模型训练与调优模型评估与结果解释Python机器学习编程教案第六章:文本挖掘与自然语言处理6.1 文本挖掘基础文本数据预处理词频统计与TF-IDF文本分类与情感分析6.2 自然语言处理库NLTK与spaCy NLTK库的基本功能spaCy库的安装与使用词性标注与命名实体识别6.3 机器学习在自然语言处理中的应用基于机器学习的文本分类基于机器学习的情感分析机器翻译与模型第七章:时间序列分析与预测7.1 时间序列基本概念时间序列的类型与特点时间序列分析的主要方法指数平滑与ARIMA模型7.2 Python时间序列分析库statsmodels statsmodels库的基本功能时间序列数据的拟合与预测模型评估与优化7.3 机器学习在时间序列预测中的应用基于回归与分类算法的预测模型基于深度学习的时间序列预测实际案例分析:股票价格预测第八章:推荐系统与广告投放8.1 推荐系统基本概念推荐系统的类型与流程协同过滤与基于内容的推荐混合推荐与深度学习推荐8.2 Python推荐系统库Surprise Surprise库的基本功能推荐模型与算法实现模型评估与参数调优8.3 广告投放与率预测广告投放策略与目标率预测模型实际案例分析:在线广告投放优化第九章:深度学习与神经网络9.1 深度学习基本概念深度学习的发展历程与现状神经网络的基本结构与原理激活函数与反向传播算法9.2 TensorFlow与PyT orch库介绍TensorFlow的基本使用方法PyTorch库的特点与优势构建与训练神经网络模型9.3 常见深度学习模型与应用卷积神经网络(CNN)循环神经网络(RNN)对抗网络(GAN)第十章:项目实战与案例分析10.1 实战项目一:房价预测数据准备与预处理特征工程与模型选择模型训练与评估10.2 实战项目二:情感分析数据收集与预处理特征提取与模型训练结果分析与优化10.3 实战项目三:电商推荐系统数据集准备与处理模型构建与训练推荐结果评估与优化重点解析:1. Python基础与环境搭建:理解Python的数据类型、控制结构、函数与模块导入,以及如何搭建Python开发环境。
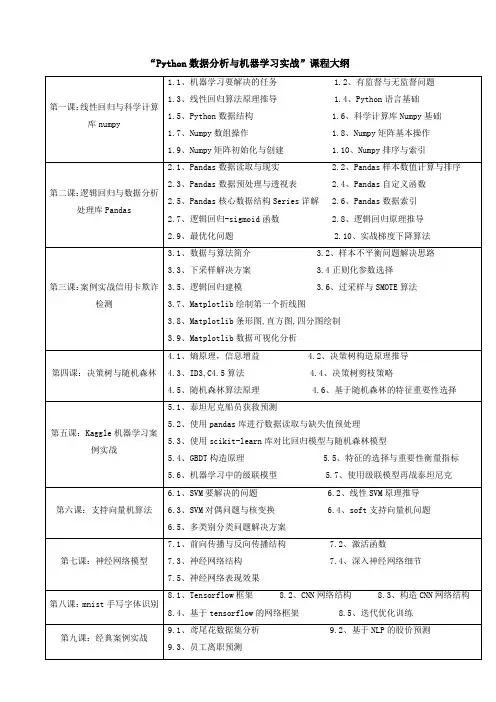
第7章餐饮企业综合分析教案课程名称:Python机器学习编程与实战课程类别:必修适用专业:大数据技术类相关专业总学时:64学时(其中理论36学时,实验28学时)总学分:4.0学分本章学时:12学时一、材料清单(1)《Python机器学习编程与实战》教材。
(2)配套PPT。
(3)数据。
(4)代码。
(5)引导性提问。
(6)探究性问题。
(7)拓展性问题。
二、教学目标与基本要求1.教学目标结合餐饮企业综合分析案例,介绍针对原始数据使用折线图进行统计分析,进行特征选择筛选掉原始数据中相关性不强的特征、通过特征构建构造RFM特征和客户流失特征,并重点介绍K-Means聚类算法在客户价值分析中的应用和决策树算法在客户流失预测中的应用。
针对聚类结果,通过雷达图对不同客户群进行价值分析。
针对分类预测模型,通过混淆矩阵等评价方法评价其预测效果。
2.基本要求(1)了解餐饮企业综合分析的背景知识,分析步骤和流程。
(2)掌握使用折线图分析趋势。
(3)掌握特征选择和特征构造的方法。
(4)掌握使用K-Means算法构建聚类模型的方法。
(5)掌握使用决策树算法构建分类模型的方法。
(6)掌握进行客户价值分析的方法。
(7)掌握评价分类模型效果的方法。
三、问题1.引导性提问引导性提问需要教师根据教材内容和学生实际水平,提出问题,启发引导学生去解决问题,提问,从而达到理解、掌握知识,发展各种能力和提高思想觉悟的目的。
(1)什么样的客户是餐饮企业的高价值客户?(2)餐饮企业能提供什么样的数据?(3)餐饮企业为什么要做客户价值分析与客户流失预测?2.探究性问题探究性问题需要教师深入钻研教材的基础上精心设计,提问的角度或者在引导性提问的基础上,从重点、难点问题切入,进行插入式提问。
或者是对引导式提问中尚未涉及但在课文中又是重要的问题加以设问。
(1)RFM模型对应的特征在本案例中是什么?(2)为什么K-Means可以用作客户分类?(3)应该依据哪些条件判断客户是否会流失?3.拓展性问题拓展性问题需要教师深刻理解教材的意义,学生的学习动态后,根据学生学习层次,提出切实可行的关乎实际的可操作问题。
《Python数据分析和机器学习实战》随着大数据时代的到来,数据分析和机器学习已成为了许多企业和组织中必不可少的一部分。
而Python作为一种具有广泛应用领域的高级编程语言,因其拥有简洁易学的语法、高效的计算性能和丰富的函数库而成为了数据分析和机器学习领域中的热门选择。
本文将从Python数据分析和机器学习的基础知识入手,介绍如何利用Python进行数据分析和机器学习实战。
一、Python数据分析基础1.1 Python的基本数据类型Python支持的基本数据类型包括整型、浮点型、布尔型、字符串型等。
其中,整型和浮点型用于存储数字类型的数据,布尔型用于存储真假值,字符串型则用于存储文本类型的数据。
Python中的数据类型具有动态性,也就是说,Python会根据变量所存储的数据类型来自动为其分配内存空间。
1.2 Python的数据结构Python支持多种常用的数据结构,如列表、元组、字典、集合等。
其中,列表和元组用于存储有序的数据集合,列表是可变的,而元组是不可变的;字典和集合则用于存储无序的数据集合,字典是由键值对组成的,而集合则是由元素组成的,可以去重。
1.3 Python的函数和模块Python中的函数和模块是用于实现代码复用和扩展功能的重要工具。
函数是一段有名字的可重复使用的代码块,可以接受参数并返回值。
而模块则是一组相关的函数和变量的集合,可以用于实现代码的组织和分离。
二、Python数据分析实战2.1 数据采集在进行数据分析之前,首先需要获取数据。
Python中有多种数据采集工具可以使用,如Requests库、Selenium库等。
Requests库可以用于发送HTTP 请求并获取响应,通常用于抓取静态网页数据;而Selenium库则可以用于模拟浏览器行为获取动态网页数据。
2.2 数据清洗在数据采集过程中,得到的数据不可避免地存在各种噪声、缺失值和异常值等问题,因此,数据清洗是提高数据质量的关键一步。