编译原理教程课后习题答案——第二章
- 格式:doc
- 大小:375.00 KB
- 文档页数:7

第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。
第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指。
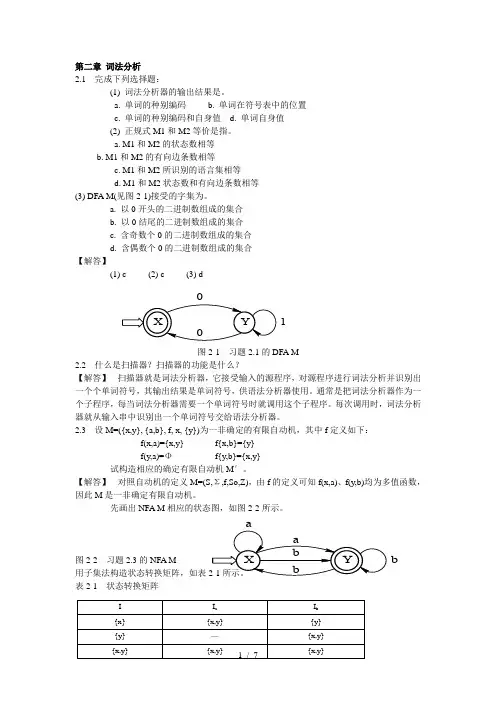
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。



第1章引论第1题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1) 编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2) 源程序:源语言编写的程序称为源程序。
(3) 目标程序:目标语言书写的程序称为目标程序。
(4) 编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5) 后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6) 遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。

第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}==============================================2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D===============================================3.已知文法G[S]:S→dAB A→aA|a B→ε|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法?[答案]正规式是daa*b*;相应的正规文法为(由自动机化简来):G[S]:S→dA A→a|aB B→aB|a|b|bC C→bC|b也可为(观察得来):G[S]:S→dA A→a|aA|aB B→bB|ε===================================================================== ==========4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}===================================================================== =========5.给出语言{a n b n c m|n>=1,m>=0}的上下文无关文法。

第二章高级语言的语法描述6、令文法G 6为:N →D|ND D → 0|1|2|3|4|5|6|7|8|9(1)G 6 的语言L (G 6)是什么?(2)给出句子01270127、、34和568的最左推导和最右推导。
解答:思路:由N N →→ D|ND 可得出如下推导N =>=>ND ND ND=>=>=>NDD NDD NDD=>…=>=>…=>=>…=>D D n(n >=1=1))可以看出,N 最终可以推导出1个或多个(也可以是无穷)D ,而D D →→ 0|1|2|3|4|5|6|7|8|9可知,每个D 为0~9中的任一个数字,所以,中的任一个数字,所以,N N N 最终推导出的就是由最终推导出的就是由0~9这10个数字组成的字符串。
(1)G 6 的语言L (G 6)是由0~9这10个数字组成的字符串个数字组成的字符串,,或{0{0,,1,1,……,9}+。
(2)(2)句子句子01270127、、34和568的最左推导分别为的最左推导分别为: : N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>NDDD NDDD NDDD=>=>=>DDDD DDDD DDDD=>=>=>0DDD 0DDD 0DDD=>=>=>01DD 01DD 01DD=>=>=>012D 012D 012D=>=>=>0127 0127 N =>=>ND ND ND=>=>=>DD DD DD=>=>=>3D 3D 3D=>=>=>34 34N =>=>ND ND ND=>=>=>NDD NDD NDD=>=>=>DDD DDD DDD=>=>=>5DD 5DD 5DD=>=>=>56D 56D 56D=>=>=>568 568 句子01270127、、34和568的最右推导分别为的最右推导分别为: :N =>=>ND ND ND=>=>=>N7N7N7=>=>=>ND7ND7ND7=>=>=>N27N27N27=>=>=>ND27ND27ND27=>=>=>N127N127N127=>=>=>D127D127D127=>=>=>0127 0127 N =>=>ND ND ND=>=>=>N4N4N4=>=>=>D4D4D4=>=>=>34 34N =>=>ND ND ND=>=>=>N8N8N8=>=>=>ND8ND8ND8=>=>=>N68N68N68=>=>=>D68D68D68=>=>=>568 5687、写一个文法,使其语言是奇数集,且每个基数不以0开头。

第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2.文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D……D3.已知文法G[S]:Sf dAB Af aA|a B|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法? [答案]正规式是daa*b* ;相应的正规文法为(由自动机化简来):G[S]:S —dA A —a|aB B —aB|a|b|bC C —bC|b也可为(观察得来):G[S]:S —dA A —a|aA|aB B —bB| &4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}5.给出语言{a n b n c1 n>=1,m>=0}的上下文无关文法。
[分析]本题难度不大,主要是考上下文无关文法的基本概念。
上下文无关文法的基本定义是:A-> B ,A € Vn ,B€( VnU Vt) *,注意关键问题是保证a n b n的成立,即“ a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解决。
[答案]构造上下文无关文法如下:S->AB|AA->aAb|abB->Bc|c[扩展]凡是诸如此类的题都应按此思路进行,本题可做为一个基本代表。
基本思路是这样的:要求符合a n b n c m,因为a与b要求个数相等,所以把它们应看作一个整体单元进行,而c m做为另一个单位,初步产生式就应写为S->AB,其中A推出a n b n,B推出c m。

第二章3.何谓“标志符”,何谓“名字”,两者的区别是什么答:标志符是一个没有意义的字符序列,而名字却有明确的意义和属性。
4.令+、*和↑代表加、乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值。
(1)优先顺序(从高到低)为+、*和↑,同级优先采用左结合。
(2)优先顺序为↑、+、*,同级优先采用右结合。
答:(1)1+1*2↑2*1↑2=2*2↑2*1↑2=4↑2*1↑2=4↑2↑2=16↑2=256(2)1+1*2↑2*1↑2=1+1*2↑2*1=1+1*4*1=2*4*1=2*4=86.令文法G6为N-〉D|NDD-〉0|1|2|3|4|5|6|7|8|9(1)G6的语言L(G6)是什么(2)给出句子0127、34、568的最左推导和最右推导。
答:(1)由0到9的数字所组成的长度至少为1的字符串。
即:L(G6)={d n|n≧1,d∈{0,1,…,9}}(2)0127的最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 0127的最右推导:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127(其他略)7.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
答:G(S):S->+N|-NN->ABC|CC->1|3|5|7|9A->C|2|4|6|8B->BB|0|A|ε[注]:可以有其他答案。
[常见的错误]:N->2N+1原因在于没有理解形式语言的表示法,而使用了数学表达式。
8.令文法为E->T|E+T|E-TT->F|T*F|T/FF->(E)|i(1)给出i+i*i、i*(i+i)的最左推导和最右推导。
(2)给出i+i+i、i+i*i和i-i-i的语法树,并给出短语,简单短语和句柄。

第2章习题2-1 设有字母表A1 ={a,b,c,…,z},A2 ={0,1,…,9},试回答下列问题:(1) 字母表A1上长度为2的符号串有多少个?(2) 集合A1A2含有多少个元素?(3) 列出集合A1(A1∪A2)*中的全部长度不大于3的符号串。
2-2 试分别构造产生下列语言的文法:(1){a n b n|n≥0};(2){a n b m c p|n,m,p≥0};(3){a n#b n|n≥0}∪{c n#d n|n≥0};(4){w#w r# | w∈{0,1}*,w r是w的逆序排列 };(5)任何不是以0打头的所有奇整数所组成的集合;(6)所有由偶数个0和偶数个1所组成的符号串的集合。
2-3 试描述由下列文法所产生的语言的特点:(1)S→10S0S→aA A→bA A→a(2)S→SS S→1A0A→1A0A→ε(3)S→1A S→B0A→1A A→CB→B0B→C C→1C0C→ε(4)S→aSS S→a2-4 试证明文法S→AB|DC A→aA|a B→bBc|bc C→cC|c D→aDb|ab为二义性文法。
2-5 对于下列的文法S→AB|c A→bA|a B→aSb|c试给出句子bbaacb的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
2-6 化简下列各个文法(1) S→aABS|bCACd A→bAB|cSA|cCC B→bAB|cSB C→cS|c(2) S→aAB|E A→dDA|e B→bE|fC→c AB|dSD|a D→eA E→fA|g(3) S→ac|bA A→c BC B→SA C→bC|d2-7 消除下列文法中的ε-产生式(1) S→aAS|b A→cS|ε(2) S→aAA A→bAc|dAe|ε2-8 消除下列文法中的无用产生式和单产生式(1) S→aB|BC A→aA|c|aDb B→DB|C C→b D→B(2) S→SA|SB|A A→B|(S)|( ) B→[S]|[ ](3) E→E+T|T T→T*F|F F→P↑F|P P→(E)|i第2章习题答案2-1 答:(1) 26*26=676(2) 26*10=260(3) {a,b,c,...,z, a0,a1,...,a9, aa,...,az,...,zz, a00,a01,...,zzz},共有26+26*36+26*36*36=34658个2-2 解:(1) 对应文法为G(S)=({S},{a,b},{ S→ε| aSb },S)(2) 对应文法为G(S)=({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε },S)(3)对应文法为G(S)=({S,X,Y},{a,b,c,d,#}, {S→X,S→Y,X→aXb|#, Y→cYd|# },S)(4) G(S)=({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5) G(S)=({S,A,B,I,J},{0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|ε, I→J|2|4|6|8, J→1|3|5|7|9},S)(6)对应文法为S→0A|1B|ε,A→0S|1C,B→0C|1S,C→1A|0B2-3 解:(1) 本文法构成的语言集为:L(G)={(10)n ab m a0n|n,m≥0}。

第二章习题解答2.1①该文法定义的是0到9这10个数字{0,1,2,3,4,5,6,7,8,9};②同①;③该文法定义的是{b n a2∣n≥0};2.2①因为语言的句子要求由3的整数倍的a组成,所以在构造产生式时,要保证每次产生的a 的个数是3。
得到文法G[S]:S→aaa|Saaa②因为符号串中a、b的个数没有直接关系,所以,将句子分成两部分:a n和b2m–1,分别进行构造,然后再合并。
可由产生式A→a|aA得到a n。
而由产生式B→b|bbB得到b2m–1。
由于n≥1,m≥1,所以得到文法G[S]:S→ABA→a|aAB→b|bbB③因为句子中,a和b的个数一样多,且a全部在句子的前半部分,b全部在句子的后半部分,所以在构造产生式时,可让a和b对称出现。
得文法G[S]:S→aSb|ab④因为句子中a、b、c的个数没有直接关系,所以分别构造生成a n、b m、c k的产生式,然后再合成。
可由产生式A→aA|得到a n。
而由产生式B→bB|得到b m。
再由产生式C→cC|得到c k。
所以得到文法G[S]:S→ABCA→aA|B→bB|C→cC|⑤文法为G[S]:S→(+|–)(ABC|2|4|6|8)|0C→0|2|4|6|8B→BA|B0|A→1|2|3|…|9⑥能被5整除的整数的末位数必定是0或5。
所以只要保证生成的整数末位数字是0或5即可。
据此,构造描述能被5整除的整数集合的文法如下:G[S]:S→(+|-)A(0|5)A→0|1|2|3|4|5|6|7|8|9|AA如果还要求整数除0外,均不以0开头,则文法为G[S]:S→(+|-)(A(0|5)|0|5)A→AB|CB→0|C|BBC→1|2|3|4|5|6|7|8|9⑦由于文法的句子∈{a, b}+,因此文法的句子可分解为两种情形:以a打头的符号串;以b打头的符号串。
于是只要在构造产生式时保证每次产生相同个数的a和b即可。
可以构造文法如下。
第2章习题2-1 设有字母表A1 ={a,b,c,…,z},A2 ={0,1,…,9},试回答下列问题:(1) 字母表A1上长度为2的符号串有多少个?(2) 集合A1A2含有多少个元素?(3) 列出集合A1(A1∪A2)*中的全部长度不大于3的符号串。
2-2 试分别构造产生下列语言的文法:(1){a n b n|n≥0};(2){a n b m c p|n,m,p≥0};(3){a n#b n|n≥0}∪{c n#d n|n≥0};(4){w#w r# | w∈{0,1}*,w r是w的逆序排列 };(5)任何不是以0打头的所有奇整数所组成的集合;(6)所有由偶数个0和偶数个1所组成的符号串的集合。
2-3 试描述由下列文法所产生的语言的特点:(1)S→10S0S→aA A→bA A→a(2)S→SS S→1A0A→1A0A→ε(3)S→1A S→B0A→1A A→CB→B0B→C C→1C0C→ε(4)S→aSS S→a2-4 试证明文法S→AB|DC A→aA|a B→bBc|bc C→cC|c D→aDb|ab为二义性文法。
2-5 对于下列的文法S→AB|c A→bA|a B→aSb|c试给出句子bbaacb的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
2-6 化简下列各个文法(1) S→aABS|bCACd A→bAB|cSA|cCC B→bAB|cSB C→cS|c(2) S→aAB|E A→dDA|e B→bE|fC→c AB|dSD|a D→eA E→fA|g(3) S→ac|bA A→c BC B→SA C→bC|d2-7 消除下列文法中的ε-产生式(1) S→aAS|b A→cS|ε(2) S→aAA A→bAc|dAe|ε2-8 消除下列文法中的无用产生式和单产生式(1) S→aB|BC A→aA|c|aDb B→DB|C C→b D→B(2) S→SA|SB|A A→B|(S)|( ) B→[S]|[ ](3) E→E+T|T T→T*F|F F→P↑F|P P→(E)|i第2章习题答案2-1 答:(1) 26*26=676(2) 26*10=260(3) {a,b,c,...,z, a0,a1,...,a9, aa,...,az,...,zz, a00,a01,...,zzz},共有26+26*36+26*36*36=34658个2-2 解:(1) 对应文法为G(S)=({S},{a,b},{ S→ε| aSb },S)(2) 对应文法为G(S)=({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε },S)(3)对应文法为G(S)=({S,X,Y},{a,b,c,d,#}, {S→X,S→Y,X→aXb|#, Y→cYd|# },S)(4) G(S)=({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5) G(S)=({S,A,B,I,J},{0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|ε, I→J|2|4|6|8, J→1|3|5|7|9},S)(6)对应文法为S→0A|1B|ε,A→0S|1C,B→0C|1S,C→1A|0B2-3 解:(1) 本文法构成的语言集为:L(G)={(10)n ab m a0n|n,m≥0}。
第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是 。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指 。
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为 。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。
2-1 设有字母表A1 ={a,b,c,…,z},A2 ={0,1,…,9},试回答下列问题:(1) 字母表A1上长度为2的符号串有多少个?(2) 集合A1A2含有多少个元素?(3) 列出集合A1(A1∪A2)*中的全部长度不大于3的符号串。
2-2 试分别构造产生下列语言的文法:(1){a n b n|n≥0};(2){a n b m c p|n,m,p≥0};(3){a n#b n|n≥0}∪{c n#d n|n≥0};(4){w#w r# | w∈{0,1}*,w r是w的逆序排列 };(5)任何不是以0打头的所有奇整数所组成的集合;(6)所有由偶数个0和偶数个1所组成的符号串的集合。
2-3 试描述由下列文法所产生的语言的特点:(1)S→10S0S→aA A→bA A→a(2)S→SS S→1A0A→1A0A→ε(3)S→1A S→B0A→1A A→CB→B0B→C C→1C0C→ε(4)S→aSS S→a2-4 试证明文法S→AB|DC A→aA|a B→bBc|bc C→cC|c D→aDb|ab为二义性文法。
2-5 对于下列的文法S→AB|c A→bA|a B→aSb|c试给出句子bbaacb的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
2-6 化简下列各个文法(1) S→aABS|bCACd A→bAB|cSA|cCC B→bAB|cSB C→cS|c(2) S→aAB|E A→dDA|e B→bE|fC→c AB|dSD|a D→eA E→fA|g(3) S→ac|bA A→c BC B→SA C→bC|d2-7 消除下列文法中的ε-产生式(1) S→aAS|b A→cS|ε(2) S→aAA A→bAc|dAe|ε2-8 消除下列文法中的无用产生式和单产生式(1) S→aB|BC A→aA|c|aDb B→DB|C C→b D→B(2) S→SA|SB|A A→B|(S)|( ) B→[S]|[ ](3) E→E+T|T T→T*F|F F→P↑F|P P→(E)|i第2章习题答案2-1 答:(1) 26*26=676(2) 26*10=260(3) {a,b,c,...,z, a0,a1,...,a9, aa,...,az,...,zz, a00,a01,...,zzz},共有26+26*36+26*36*36=34658个2-2 解:(1) 对应文法为G(S)=({S},{a,b},{ S→ε| aSb },S)(2) 对应文法为G(S)=({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε },S)(3)对应文法为G(S)=({S,X,Y},{a,b,c,d,#}, {S→X,S→Y,X→aXb|#, Y→cYd|# },S)(4) G(S)=({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5) G(S)=({S,A,B,I,J},{0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|ε, I→J|2|4|6|8, J→1|3|5|7|9},S)(6)对应文法为S→0A|1B|ε,A→0S|1C,B→0C|1S,C→1A|0B2-3 解:(1) 本文法构成的语言集为:L(G)={(10)n ab m a0n|n,m≥0}。
第二章 词法分析
2.1 完成下列选择题:
(1) 词法分析器的输出结果是 。
a. 单词的种别编码
b. 单词在符号表中的位置
c. 单词的种别编码和自身值
d. 单词自身值
(2) 正规式M1和M2等价是指 。
a. M1和M2的状态数相等
b. M1和M2的有向边条数相等
c. M1和M2所识别的语言集相等
d. M1和M2状态数和有向边条数相等
(3) DFA M(见图2-1)接受的字集为 。
a. 以0开头的二进制数组成的集合
b. 以0结尾的二进制数组成的集合
c. 含奇数个0的二进制数组成的集合
d. 含偶数个0的二进制数组成的集合
【解答】
(1) c (2) c (3) d
图2-1 习题2.1的DFA M
2.2 什么是扫描器?扫描器的功能是什么?
【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:
f(x,a)={x,y} f {x,b}={y}
f(y,a)=Φ f{y,b}={x,y}
试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表
表2-1 状态转换矩阵
1b a
将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵
将图2-3所示的DFA M ′最小化。
首先,将M ′的状态分成终态组{1,2}与非终态组{0}。
其次,考察{1,2},由于{1,2}a={1,2}b={2}⊂{1,2},所以不再将其划分了,也即整个划分只有两组:{0}和{1,2}。
令状态1代表{1,2},即把原来到达2的弧都导向1,并删除状态2。
最后,得到如图2-4所示的化简了的DFA M ′。
′
DFA M ′
2.4 正规式(ab)*a 与正规式a(ba)*是否等价?请说明理由。
【解答】 正规式(ab)*a 对应的NFA
如图2-5所示,正规式a(ba)*对应的NFA 如图2-6
图2-5 正规式(ab)*a 对应的NFA
图2-6 正规式a(ba)*对应的DFA
这两个正规式最终都可得到最简DFA ,如图2-7所示。
因此,这两个正规式等价。
a, b a a, b
图2-7 最简NFA
2.5 设有L(G)={a2n+1b2ma2p+1| n ≥0,p ≥0,m ≥1}。
(1) 给出描述该语言的正规表达式;
(2)
构造识别该语言的确定有限自动机(可直接用状态图形式给出)。
【解答】 该语言对应的正规表达式为a(aa)*bb(bb)*a(aa)*,正规表达式对应的NFA 如图2-8所示。
图2-8 习题2-5的NFA 用子集法将图2-8确定化,如图2-9所示。
由图2-9重新命名后的状态转换矩阵可化简为(也可由最小化方法得到) {0,2} {1} {3,5} {4,6} {7}
按顺序重新命名为0、1、2、3、4后得到最简的DFA ,如图2-10所示。
图2-9
习题2.5的状态转换矩阵
图2-10 习题2.5的最简DFA
2.6 有语言L={w|w ∈(0,1)+,并且w 中至少有两个1,又在任何两个1之间有偶数个0},试构造接受该语言的确定有限状态自动机(DFA)。
【解答】 对于语言L ,w 中至少有两个1,且任意两个1之间必须有偶数个0;也即在第一个1之前和最后一个1之后,对0的个数没有要求。
据此我们求出L 的正规式为0*1(00(00)*1)*00(00)*10*,画出与正规式对应的NFA ,如图2-11所示。
习题2.6的NFA
a a 重新命名a
b a
用子集法将图2-11的NFA确定化,如图2-12所示。
图
2-12 习题2.6的状态转换矩阵
由图2-12可看出非终态2和4的下一状态相同,终态6和8的下一状态相同,即得到最简状态为
{0}、{1}、{2,4}、{3}、{5}、{6,8}、{7}
按顺序重新命名为0、1、2、3、4、5、6,则得到最简DFA,如图2-13所示。
2.7 已知正规式((a|b)*|aa)*b和正规式(a|b)*b。
(1) 试用有限自动机的等价性证明这两个正规式是等价的;
(2) 给出相应的正规文法。
2-14所示。
对应的NFA 用子集法将图2-14所示的NFA确定化为DFA,如图2-15所示。
图2-15 图2-14确定化后的状态转换矩阵
重新命名
重新命名
由于对非终态的状态1、2来说,它们输入a 、b 的下一状态是一样的,故状态1和状态2可以合并,将合并后的终态3命名为2,则得到表2-3(注意,终态和非终态即使输入a 、b 的下一状态相同也不能合并)。
由此得到最简DFA ,如图2-16所示。
正规式(a|b)*b 对应的NFA 如图2-17所示。
表2-3 合并后的状态转换矩阵
图2-16 习题2.7的最简DFA
图2-17 正规式(a|b)*b 对应的NFA
用子集法将图2-17所示的NFA 确定化为如图2-18所示的状态转换矩阵。
图2-18 图2-17确定化后的状态转换矩阵
比较图2-18与图2-15,重新命名后的转换矩阵是完全一样的,也即正规式(a|b)*b 可以同样得到化简后的DFA 如图2-16所示。
因此,两个自动机完全一样,即两个正规文法等价。
(2) 对图2-16,令A 对应状态1,B 对应状态2,则相应的正规文法G[A]为 G[A]:A →aA|bB|b
B →aA|bB|b
G[A]可进一步化简为G[S]:S →aS|bS|b(非终结符B 对应的产生式与A 对应的产生式相同,故两非终结符等价,即可合并为一个产生式)。
2.8 下列程序段以B 表示循环体,A 表示初始化,I 表示增量,T 表示测试:
I=1;
while (I<=n)
{
sun=sun+a[I];
I=I+1;}
b
a
a b 重新命名
请用正规表达式表示这个程序段可能的执行序列。
【解答】 用正规表达式表示程序段可能的执行序列为A(TBI)*。
2.9 将图2-19所示的非确定有限自动机(NFA)变换成等价的确定有限自动机
(DFA)。
图2-19 习题2.9的NFA
其中,X 为初态,Y 为终态。
【解答】 用子集法将NFA 确定化,如图2-20所示。
图2-2习题2.9的状态转换矩阵
图2-20所对应的DFA 如图2-21所示。
习题2.9的DFA
习题2.9的最简DFA
对图2-21的DFA 进行最小化。
首先将状态分为非终态集和终态集两部分:{0,1,2,5}和b 重新命名
{3,4,6,7}。
由终态集可知,对于状态3、6、7,无论输入字符是a还是b的下一状态均为终态集,而状态4在输入字符b的下一状态落入非终态集,故将其化为分
{0,1,2,5}, {4}, {3,6,7}
对于非终态集,在输入字符a、b后按其下一状态落入的状态集不同而最终划分为{0}, {1}, {2}, {5}, {4}, {3,6,7}
按顺序重新命名为0、1、2、3、4、5,得到最简DFA如图2-22所示。
2.10 有一台自动售货机,接收1分和2分硬币,出售3分钱一块的硬糖。
顾客每次向机器中投放≥3分的硬币,便可得到一块糖(注意:只给一块并且不找钱)。
(1) 写出售货机售糖的正规表达式;
(2) 构造识别上述正规式的最简DFA。
【解答】(1) 设a=1,b=2,则售货机售糖的正规表达式为a (b|a(a|b))|b(a|b)。
(2) 画出与正规表达式a(b|a(a|b))|b(a|b)对应的NFA,如图2-23所示。
图2-23 习题2.10的NFA
用子集法将图2-21的NFA确定化,如图2-24所示。
图2-24 习题
2.10的状态转换矩阵
由图2-24可看出,非终态2和非终态3面对输入符号a或b的下一状态相同,故合并为一个状态,即最简状态{0}、{1}、{2,3}、{4}。
按顺序重新命名为0、1、2、3,则得到最简DFA,如图2-25所示。
图2-25 习题2.10的最简DFA
重新命名。