SQL分组排序取最新一条记录
- 格式:pdf
- 大小:134.19 KB
- 文档页数:1
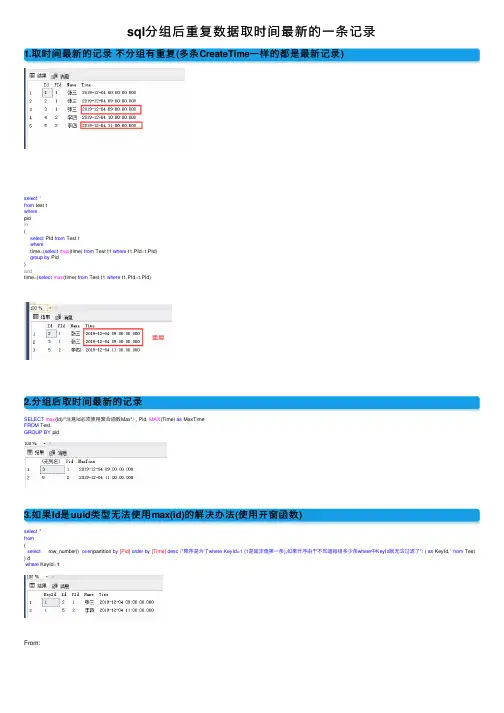
sql分组后重复数据取时间最新的⼀条记录1.取时间最新的记录不分组有重复(多条CreateTime⼀样的都是最新记录)select*from test twherepidin(select PId from Test twheretime=(select max(time) from Test t1 where t1.PId=t.PId)group by Pid)andtime=(select max(time) from Test t1 where t1.PId=t.PId)2.分组后取时间最新的记录SELECT max(Id)/*注意Id必须使⽤聚合函数Max*/ , Pid, MAX(Time) as MaxTimeFROM TestGROUP BY pid3.如果Id是uuid类型⽆法使⽤max(id)的解决办法(使⽤开窗函数)select *from(select row_number() over(partition by[Pid]order by[Time]desc /*降序是为了where KeyId=1 (1是固定值第⼀条),如果升序由于不知道每组多少条where中KeyId就⽆法过滤了*/ ) as KeyId,*from Test ) dwhere KeyId=1From:DROP TABLE IF EXISTS ##tmpTable; --存在表则删除select CONVERT(varchar(100), @time, 23) --取datetime的年⽉⽇ 2019-12-17 select CONVERT(varchar(100), GETDATE(), 24) --取datetime的时间 10:57:47。

mysql分组取最新的⼀条记录(整条记录)⽅法:mysql取分组后最新的⼀条记录,下⾯两种⽅法.⼀种是先筛选出最⼤和最新的时间,在连表查询.⼀种是先排序,然后在次分组查询(默认第⼀条),就是最新的⼀条数据了#select*from t_assistant_article as a, (select max(base_id) as base_id, max(create_time) as create_time from t_assistant_article as b group by base_id ) as b where a.base_id=b.base_id and a.create_time = b.create_time #select base_id,max(create_time), max(article_id) as article_id from t_assistant_article as b group by base_idselect*from (select*from t_assistant_article order by create_time desc) as a group by base_id order by create_time desc来源:/swweb/article/details/11059037mysql "group by"与"order by"的研究--分类中最新的内容 /article/23969.htm在使⽤mysql排序的时候会想到按照降序分组来获得⼀组数据,⽽使⽤order by往往得到的不是理想中的结果,那么怎么才能使⽤group by 和order by得到理想中的数据结果呢?例如有⼀个帖⼦的回复表,posts( id , tid , subject , message , dateline ) ,id为⾃动增长字段, tid为该回复的主题帖⼦的id(外键关联), subject 为回复标题, message 为回复内容, dateline 为回复时间,⽤UNIX 时间戳表⽰,现在要求选出前⼗个来⾃不同主题的最新回复SELECT * FROM posts GROUP BY tid LIMIT 10这样⼀个sql语句选出来的并⾮你想要的最新的回复,⽽是最早的回复,实际上是某篇主题的第⼀条回复记录!也就是说 GROUP BY 语句没有排序,那么怎么才能让 GROUP 按照 dateline 倒序排列呢?加上 order by ⼦句?看下⾯:SELECT * FROM posts GROUP BY tid ORDER BY dateline DESC LIMIT 10这条语句选出来的结果和上⾯的完全⼀样,不过把结果倒序排列了,⽽选择出来的每⼀条记录仍然是上⾯的记录,原因是 group by 会⽐ order by 先执⾏,这样也就没有办法将group by 之前,也就是在分组之前进⾏排序了,有⽹友会写出下⾯的sql 语句:SELECT * FROM posts GROUP BY tid DESC ORDER BY dateline DESC LIMIT 10也就是说在 GROUP BY 的字段 tid 后⾯加上递减顺序,这样不就可以取得分组时的最后回复了吗?这个语句执⾏结果会和上⾯的⼀模⼀样,这⾥加上 DESC 和ASC对执⾏结果没有任何影响!其实这是⼀个错误的语句,原因是GROUP BY 之前并没有排序功能,mysql ⼿册上⾯说,GROUP BY 时是按照某种顺序排序的,某种顺序到底是什么顺序?其实根本没有顺序,因为按照tid分组,其实也就是说,把tid相等的归纳到⼀个组,这样想的话,GROUP BY tid DESC 可以认为是在按照 tid 分组的时候,按照tid进⾏倒序排列,这不扯吗,既然是按照tid分组,当然是tid相等的归到⼀组,⽽这时候按照tid倒叙还是升序有个P⽤!于是有⽹友发明下⾯的语句:SELECT * FROM posts GROUP BY tid , dateline DESC ORDER BY dateline DESC LIMIT 10⼼想这样我就可以在分组前按照 dateline 倒序排列了,其实这个语句并没有起到按照tid分组的作⽤,原因还是上⾯的,在group by 字段后加 desc 还是 asc 是错误的写法,⽽这种写法⽹友本意是想按照 tid 分组,并且在分组的时候按照 dateline排倒序!⽽实际这句相当于下⾯的写法:(去掉 GROUP BY 字段后⾯的 DESC)SELECT * FROM posts GROUP BY tid , dateline ORDER BY dateline DESC LIMIT 10也就是说,按照 tid 和 dateline 联合分组,只有在记录tid和dateline 同时相等的时候才归纳到⼀组,这显然不可能,因为 dateline 时间线基本上是唯⼀的!有⼈写出下⾯的语句:SELECT *,max(dateline) as max_line FROM posts GROUP BY tid ORDER BY dateline DESC LIMIT 10这条语句的没错是选出了最⼤发布时间,但是你可以对⽐⼀下 dateline 和 max_dateline 并不相等!(可能有相当的情况,就是分组的⽬标记录只有⼀条的时候!)为什么呢?原因很简单,这条语句相当于是在group by 以后选出本组的最⼤的发布时间!对分组没有起到任何影响!因为SELECT⼦句是最后执⾏的!后来更有⽹友发明了下⾯的写法!SELECT *,max(dateline) as max_line FROM posts GROUP BY tid HAVING dateline=max(dateline) ORDER BY dateline DESC LIMIT 10这条语句的预期结果和想象中的并不相同!因为你会发现,分组的结果中⼤量的记录没有了!为什么?因为 HAVING 是在分组的时候执⾏的,也就说:在分组的时候加上⼀个这样的条件:选择出来的 dateline 要和本组最⼤的dateline 相等,执⾏的结果和下⾯的语句相同:SELECT *,max(dateline) as max_line FROM posts GROUP BY tid HAVING count(*)=1 ORDER BY dateline DESC LIMIT 10看了这条sql语句是不是明⽩了呢?dateline=max(dateline) 只有在分组中的记录只有⼀条的时候才成⽴,原因很明⽩吧!只有⼀条他才会和本组的最⼤发布时间相等阿,(默认dateline为不重复的值)原因还是因为 group by 并没有排序功能,所有的这些排序功能只是错觉,所以你最终选出的 dateline 和max(dateline) 永远不可能相等,除⾮本组的记录只有⼀条!GROUP BY在分组的时候,可能是⼀个⼀个来找的,发现有相等的tid,去掉,保留第⼀个发现的那⼀条记录,所以找出来的记录永远只是按照默认索引顺序排列的!那么说了这么多,到底有没有办法让 group by 执⾏前分组阿?有的,⼦查询阿!最简单的:SELECT * FROM (SELECT * FROM posts ORDER BY dateline DESC) GROUP BY tid ORDER BY dateline DESC LIMIT 10也有⽹友利⽤⾃连接实现的,这样的效率应该⽐上⾯的⼦查询效率⾼,不过,为了简单明了,就只⽤这样⼀种了,GROUP BY没有排序功能,可能是mysql弱智的地⽅,也许是我还没有发现,。

SQL分组排序后取每组最新⼀条数据的另⼀种思路在hibernate框架和mysql、oracle两种数据库兼容的项⽬中实现查询每个id最新更新的⼀条数据。
之前⼯作中⼀直⽤的mybatis+oracle数据库这种,⼀般写这类分组排序取每组最新⼀条数据的sql都是使⽤row_number() over()函数来实现例如:select t1.* from ( select t.*, ROW_NUMBER() over(partition t.id order by t.update_time desc) as rn from table_name t) t1 where t1.rn = 1;但是新公司项⽬是兼容mysql和oracle两种数据库切换的,那么row_number() over()在使⽤mysql的情况下会出现错误,所以我在⽹上查找了⼀下mysql实现分组排序取最新数据的例⼦有两种写法,如下:第⼀种select t1.*from table_name t1, (select t.id, max(t.update_time) as uTime from table_name t group by t.id) t2where 1=1and t1.id = t2.idand t1.update_time = t2.uTime;第⼆种(这⾥limit是为了固定⼦查询中的排序,如果没有这个limit,外层使⽤虚拟表t1进⾏group by的时候就不会根据之前update_time排好的倒序进⾏分组了。
limit具体的数字可以根据要查询数据的总数来决定。
)select t1.* from ( select * from table_name t order by t.update_time desc limit 1000) t1 group by t1.id;这⾥⼜遇到了⼀个问题,虽然第⼀种⽅式使⽤mysql和oracle都可以查询,但是hibernate是不⽀持from (⼦查询) ... 这种结构的sql的,因为hibernate的核⼼是⾯向对象⽽⾮⾯向数据库,⽹上搜到是这种解决⽅案解决hibernate不⽀持from (⼦查询) ... 参考地址:为了⼀个⼦查询再新建⼀个实体类...虽然觉得这样有点⿇烦但是我还是搜索了⼀下整个项⽬看有没有类似的做法,结果⼀个都没有找到!这时候我请教了⼀下部门的⽼⼈想看看他们做这类查询是如何处理的,⼤佬给出的⽅案是换⼀种sql写法如下:select * from table_name t1 where t1.update_time= (select max(t.update_time) from table_name t where t.id= t1.id);⾄此问题解决...。
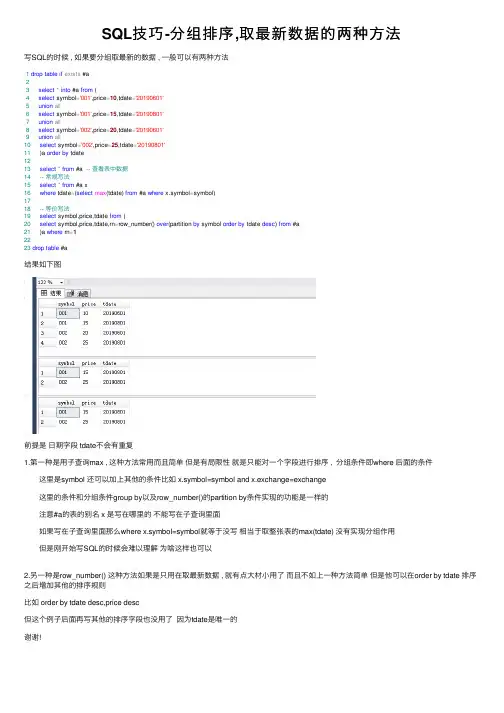
SQL技巧-分组排序,取最新数据的两种⽅法写SQL的时候 , 如果要分组取最新的数据 , ⼀般可以有两种⽅法1drop table if exists #a23select*into #a from (4select symbol='001',price=10,tdate='20190601'5union all6select symbol='001',price=15,tdate='20190801'7union all8select symbol='002',price=20,tdate='20190601'9union all10select symbol='002',price=25,tdate='20190801'11 )a order by tdate1213select*from #a -- 查看表中数据14-- 常规写法15select*from #a x16where tdate=(select max(tdate) from #a where x.symbol=symbol)1718-- 等价写法19select symbol,price,tdate from (20select symbol,price,tdate,rn=row_number() over(partition by symbol order by tdate desc) from #a21 )a where rn=12223drop table #a结果如下图前提是⽇期字段 tdate不会有重复1.第⼀种是⽤⼦查询max , 这种⽅法常⽤⽽且简单但是有局限性就是只能对⼀个字段进⾏排序 , 分组条件即where 后⾯的条件 这⾥是symbol 还可以加上其他的条件⽐如 x.symbol=symbol and x.exchange=exchange 这⾥的条件和分组条件group by以及row_number()的partition by条件实现的功能是⼀样的 注意#a的表的别名 x 是写在哪⾥的不能写在⼦查询⾥⾯ 如果写在⼦查询⾥⾯那么where x.symbol=symbol就等于没写相当于取整张表的max(tdate) 没有实现分组作⽤ 但是刚开始写SQL的时候会难以理解为啥这样也可以2.另⼀种是row_number() 这种⽅法如果是只⽤在取最新数据 , 就有点⼤材⼩⽤了⽽且不如上⼀种⽅法简单但是他可以在order by tdate 排序之后增加其他的排序规则⽐如 order by tdate desc,price desc但这个例⼦后⾯再写其他的排序字段也没⽤了因为tdate是唯⼀的谢谢!。

sqlsever根据某个字段分组后获取到最新数据
SELECT *
FROM ( SELECT * ,
ROW_NUMBER() OVER ( PARTITION BY title ORDER BY creat_time DESC ) AS count
FROM drug_activity
) a
WHERE a.count = 1
ORDER BY a.creat_time DESC
关键字解释:
1. row_number() over():sqlsever中实现分组排序的关键字
2. partition by title order by creat_time desc:先通过title分组再通过creat_time排序(查出来的数据条数没有变化,只是显⽰顺序发⽣了
变化)
3. 查询出来的结果集中会多⼀个count字段,这个字段就是将分组后的数据按照我们的排序规则排列后显⽰的序号,因为我们⽤的倒序排
序,所以分组后的每组数据的第⼀条就是我们要的最新数据,然后只需要取count字段等于1的数据,就是我们需要的结果集了
4. a.count=1 ORDER BY a.creat_time desc:获取每⼀组中的第⼀条并且通过 creat_time字段排序。

取分组后的最大一条记录全文共四篇示例,供读者参考第一篇示例:在数据处理的过程中,经常会涉及到将数据按照某种规则进行分组,然后对每个组进行相应的计算或操作。
有时候我们可能会面临着需要在每个分组中找到最大值或者最小值的需求。
本文将会探讨在数据分组后如何取得每个分组的最大一条记录。
在数据分析中,取得每个分组的最大一条记录是一项比较常见的操作。
这可以帮助我们从海量的数据中快速筛选出每个分组中的重要信息,进而进行进一步的分析和决策。
我们需要先了解什么是数据分组。
数据分组是根据某些条件对数据进行分类归纳的过程。
在Python中,我们可以使用pandas库来对数据进行分组操作。
下面是一个简单的示例:```pythonimport pandas as pddata = {'group': ['A', 'A', 'A', 'B', 'B', 'B'],'value': [10, 20, 30, 15, 25, 35]}df = pd.DataFrame(data)grouped = df.groupby('group')for name, group in grouped:print(name)print(group)```运行以上代码后,我们可以看到输出结果中每个分组的数据都被打印出来了。
接下来我们可以通过以下代码来取得每个分组的最大一条记录:```pythonmax_values = grouped.apply(lambda x:x.loc[x['value'].idxmax()])print(max_values)```运行以上代码后,我们可以得到每个分组的最大一条记录。
这里用了一个lambda函数来在每个分组中找到最大值所在的行,并且使用idxmax()函数来返回最大值所在的索引。

sql语句获取今天、昨天、近7天、本周、上周、本⽉、上⽉、半年数据sql语句获取今天、昨天、近7天、本周、上周、本⽉、上⽉、半年数据01 话说有⼀⽂章表article,存储⽂章的添加⽂章的时间是add_time字段,该字段为int(5)类型的,现需要查询今天添加的⽂章总数并且按照时间从⼤到⼩排序,则查询语句如下:0203 1 select * from `article` where date_format(from_UNIXTIME(`add_time`),'%Y-%m-%d') = date_format(now(),'%Y-%m-%d');04 或者:0506 1 select * from `article` where to_days(date_format(from_UNIXTIME(`add_time`),'%Y-%m-%d')) = to_days(now());07 假设以上表的add_time字段的存储类型是DATETIME类型或者TIMESTAMP类型,则查询语句也可按如下写法:0809 查询今天的信息记录:1011 1 select * from `article` where to_days(`add_time`) = to_days(now());12 查询昨天的信息记录:1314 1 select * from `article` where to_days(now()) – to_days(`add_time`) <= 1;15 查询近7天的信息记录:1617 1 select * from `article` where date_sub(curdate(), INTERVAL 7 DAY) <= date(`add_time`);18 查询近30天的信息记录:1920 1 select * from `article` where date_sub(curdate(), INTERVAL 30 DAY) <= date(`add_time`);21 查询本⽉的信息记录:2223 1 select * from `article` where date_format(`add_time`, ‘%Y%m') = date_format(curdate() , ‘%Y%m');24 查询上⼀⽉的信息记录:2526 1 select * from `article` where period_diff(date_format(now() , ‘%Y%m') , date_format(`add_time`, ‘%Y%m')) =1;27 对上⾯的SQL语句中的⼏个函数做⼀下分析:2829 (1)to_days3031 就像它的名字⼀样,它是将具体的某⼀个⽇期或时间字符串转换到某⼀天所对应的unix时间戳,如:3233 01 mysql> select to_days('2010-11-22 14:39:51');34 02 +--------------------------------+35 03 | to_days('2010-11-22 14:39:51') |36 04 +--------------------------------+37 05 | 734463 |38 06 +--------------------------------+39 0740 08 mysql> select to_days('2010-11-23 14:39:51');41 09 +--------------------------------+42 10 | to_days('2010-11-23 14:39:51') |43 11 +--------------------------------+44 12 | 734464 |45 13 +--------------------------------+46 可以看出22⽇与23⽇的差别就是,转换之后的数增加了1,这个粒度的查询是⽐较粗糙的,有时可能不能满⾜我们的查询要求,那么就需要使⽤细粒度的查询⽅法str_to_date函数了,下⾯将分析这个函数的⽤法。

GROUP BY 条件查询最新时间记录2017/10/25 12625 最近项目一个查询需求是从一个表中同一个IP 多条记录的只获取一条IP 记录,而这条IP 记录要最新的。
很明显需求没什么难,分组当然想到的是group by,但是这里是有个时间条件筛选的。
虽然网上很多答案,但是我发现实际操作上是没有生效的,不知道是MYSQL 版本问题还是答主们只是理论而没有实际尝试过,这里分享一下我的处理方式。
1、首先看我准备了同一个IP 两条数据,时间不一样的。
2、然后我们尝试一下,直接group by 获得的是哪一条数据。
3、从上图可知,分组是实现了,但是并不是自己想要的最新时间的那条记录。
到此,如果你尝试从网上搜索具体的解决方法,你会发现大多数答主会告诉你,对group by 的表先进行时间排序作为子查询提供给group by 就能解决。
大多数答案如下图。
那么如果我们按照这答案调整SQL 再查询一次呢?到这里就傻眼了吧?说好的能解决问题呢?甚至答主连搜索结果截图都给出来了,可自己为什么就还是没有得到想要的结果呢?我猜可能是版本问题吧。
我这里的版本是4、那么我们分析一下需求和解决方法吧,我们需要的是最新时间,强调的是一个“最”,那么聪明的你想到了什么了没有?对!就是聚合函数max(),我们可以分步来,先查分组每个IP 的最新时间再根据最新时间作为条件进行条件搜索就好。
查分组每个IP 的最新时间子查询:然后组合语句:以上就是我的答案,不过以上答案我是为了方便您们理解只用了一个IP 进行查询,那么我们再看看如果这样的方法在多个IP 中会不会失效。
表中的数据:其他答主不生效的方法试一下,以防冤枉别人了:很遗憾,还是不行!我的方法:最终多个IP 测试也是成功的。
网上搜索出来别人的答案,尽管别人截图都有了,但是还是有可能不适合自己的,关键是自己会思考改进。
同时,我这方法可能不是最简洁的SQL,我希望我这里能起到一个抛砖引玉的作用,有更好答案的您们,欢迎留言交流!!!tips:感谢大家的阅读,本文由我司收集整编。

oracle针对多数据只取最新一条的sql
业务场景:
在针对某个类型数据存在多条时,但只想取最新的一条。
在可以确定时哪种类型时我们使用简单sql就可以解决。
如: select * from ( select * from t_table a where a.tpye=? order by a.time desc ) where rownum=1;
但是在我们不确定时哪种类型时,需要全表扫描或者多数据扫描时,就需要用到oracle中特有的函数解决了。
如:select * from (select a.type,row_number() over(partition by a.type order by a.time desc) as rn from t_table a where xxxx) where rn=1;
其中partition by后面跟的字段表示根据此字段去区分跟分组,order by 进行排序,row_number() over 这个表示根据里面的条件去获取行数,
总结这个函数的意思:根据type字段分组根据time字段排序后,获取此type在表中存在多少数据(存在多少则表示rn有多少行)rn=1表示取第一行也就拿到了最新的数据。

oraclegroupby后取不为空的一条记录在Oracle中,使用GROUP BY子句可以将查询结果按照指定的列进行分组,并对每个组进行聚合操作。
然而,有时我们需要在分组后只选择其中不为空的一条记录。
下面是一种实现这个需求的方法。
假设我们有一个名为"employees"的表,包含以下列:employee_id、first_name、last_name和salary。
我们想要按照last_name对员工进行分组,并且只选择每个组中salary不为空的一条记录。
以下是实现该需求的步骤:1. 使用GROUP BY子句将员工按照last_name进行分组,并计算每个组中的记录数和最小salary。
```sqlSELECT last_name, COUNT(*) AS count, MIN(salary) ASmin_salaryFROM employeesGROUP BY last_name;```2. 使用HAVING子句筛选出count大于0(即至少有一条记录)且min_salary不为空的分组。
```sqlSELECT last_name, count, min_salaryFROMSELECT last_name, COUNT(*) AS count, MIN(salary) ASmin_salaryFROM employeesGROUP BY last_nameHAVING count > 0 AND min_salary IS NOT NULL```3.使用ROW_NUMBER(函数为每个分组的记录进行编号,并按照编号升序排序。
```sqlSELECT last_name, count, min_salaryFROMSELECT last_name, count, min_salary, ROW_NUMBER( OVER (PARTITION BY last_name ORDER BY min_salary) AS rnFROMSELECT last_name, COUNT(*) AS count, MIN(salary) ASmin_salaryFROM employeesGROUP BY last_nameHAVING count > 0 AND min_salary IS NOT NULLWHERE rn = 1;```在上述查询中,我们使用了嵌套查询来实现筛选出不为空的分组,并使用ROW_NUMBER(函数为每个分组的记录进行编号。