大数据治理基础-Training
- 格式:pdf
- 大小:3.82 MB
- 文档页数:30

数据治理面试题一、数据治理的定义和重要性1.1 数据治理的概念数据治理是指通过规范的方法和流程来管理组织内外的数据资源,以保证数据的质量、可用性、合规性和安全性,为组织的决策和业务活动提供可靠的数据支持。
1.2 数据治理的重要性数据治理对于企业的发展至关重要。
合理的数据治理可以帮助企业实现以下几个方面的价值:- 数据质量管理:数据治理可以确保数据的准确性、一致性和完整性,降低数据错误和冲突带来的风险。
- 决策支持:通过数据治理,企业可以为决策者提供准确、及时、全面的数据,以支持决策的制定和执行。
- 合规管理:数据治理可以确保组织在数据处理和存储过程中遵守法规、合规标准和内部规定,降低合规风险。
- 数据安全保护:通过数据治理,企业可以制定和执行有效的数据安全策略和措施,保护数据免受潜在的安全威胁。
二、数据治理的关键要素2.1 数据所有权和责任数据治理需要明确数据的所有权和责任,确定数据的管理与维护责任人,以确保数据的合法、合规和可信。
2.2 数据分类与分类标准数据治理需要对数据进行分类,以便针对不同类型的数据采取相应的管理和保护措施。
数据分类标准可以根据业务需求、安全性要求等因素来制定。
2.3 数据质量管理数据质量管理是数据治理的核心内容之一。
通过建立数据质量管理的流程和规范,可以对数据进行质量评估、纠错和监控,确保高质量的数据可用于决策和业务活动。
2.4 数据安全保护数据安全是数据治理的一个重要方面。
数据治理需要确保数据在存储、传输和处理过程中的安全,可以采取加密、访问控制、备份恢复等安全措施来保护数据的安全性。
2.5 数据生命周期管理数据生命周期管理是指对数据从创建到销毁的全过程进行管理。
通过数据生命周期管理,可以确保数据按照规定的周期进行备份、迁移、归档和销毁,最大程度地降低数据管理的成本和风险。
三、数据治理的实施步骤3.1 确定数据治理目标和策略在实施数据治理之前,需要明确数据治理的目标和策略,以便制定相应的计划和措施。
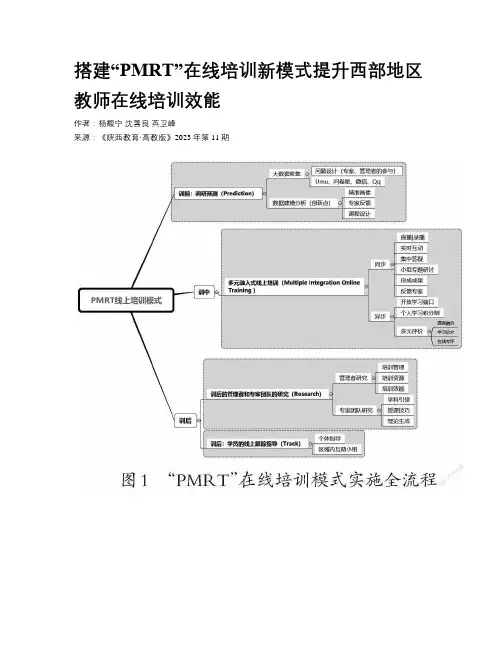
搭建“PMRT”在线培训新模式提升西部地区教师在线培训效能作者:杨馥宁沈善良英卫峰来源:《陕西教育·高教版》2023年第11期[摘要]教师培训是教师发展的重要途径。
为推进教师培训模式的改革创新,充分利用互联网、大数据等信息技术,创新培训模式和管理机制,提升培训质量,探索标准化、制度化、体系化的教师在线培训管理机制,西北大学教师发展中心立足西部地区教师培训工作现状,对标新时代教师发展需求,灵活安排,有效开展教师线上培训,在实践中搭建了“PMRT”在线培训新模式,聚焦“三位一体”教师培训学习共同体效能的提升,有力支持参训教师立足教育教学岗位。
[关键词]国培工作“PMRT”在线培训新模式“三位一体”学共体在教育信息化建设日新月异的今天,线上教师培训已经成为传统教师培训工作的有力补充,尤其在西部地区,在线培训可以借助网络平台,有效调配多地区的优质师资资源,为本地教师培训工作增效赋能。
2019年,教育部发布了《中国教育现代化2035》,该文件明确指出要优先发展教育,大力推进教育理念、体系、制度、内容、方法和治理现代化。
在信息技术平台上进行线上培训是面对后疫情时代的应时之举,更是实现教育制度现代化的有力举措。
“PMRT”在线培训模式是基于网络平台基础之上,贴合培训对象的实际需求和培训对象的长期发展目标,将施训者、受训者、管理者三方融入一个共同的学习体中的全新在线培训方式,它包括训前调研预测(Prediction)、训中多元融入式线上培训(Multiple integration online training )、训后的管理者和专家团队的研究(Research)和学员跟踪指导(Track)三大板块四个部分的创新培训模式。
“PMRT”在线培训模式的搭建提升了教师在线教学能力的提升,也提升了学校线上培训工作的效能,有力推动了教师在线培训方式的改革。
“PMRT”在线培训模式提出的背景线下集中面授是目前使用最为普遍的一种培训方式,具有不可替代的现场优势,施训者、管理者、受训者三方通过走进一个共同空间建构起一个学习共同体,在共同体中彼此影响、相互学习,促进三方尤其是受训者的快速成长。


15分钟课程设计一、课程目标知识目标:1. 学生能理解并掌握本节课的核心概念,如×××(具体知识点),并能够准确运用相关术语进行表达。
2. 学生能掌握×××(学科方法或技能),例如,通过分析实例,运用×××方法解决问题。
技能目标:1. 学生能够运用×××(具体技能)解决实际问题,如运用×××软件进行数据处理、分析等。
2. 学生能够通过小组合作,有效沟通,共同完成课堂任务,提高团队协作能力。
情感态度价值观目标:1. 学生能够积极主动地参与课堂讨论,敢于表达自己的观点,培养自信心和批判性思维。
2. 学生能够认识到×××(学科领域)在现实生活中的重要性,激发学习兴趣,培养探究精神。
3. 学生能够尊重他人的意见,学会倾听,培养良好的沟通能力和人际交往能力。
课程性质:本节课以实践性、探究性为主,结合理论讲解,注重培养学生的动手操作能力和实际问题解决能力。
学生特点:考虑到学生所在年级的特点,课程设计将注重启发式教学,激发学生的学习兴趣,培养其自主学习能力。
教学要求:教学过程中,教师需关注学生的个体差异,因材施教,确保每个学生都能在课堂上获得成就感。
同时,注重培养学生的团队协作能力和情感态度价值观。
通过分解课程目标为具体的学习成果,以便于后续的教学设计和评估。
二、教学内容本节课依据课程目标,选择以下教学内容:1. 知识点讲解:介绍×××(具体知识点),结合课本第×章第×节内容,通过实例解析,让学生理解并掌握相关概念。
-×××(具体概念1)-×××(具体概念2)2. 技能训练:教授×××(具体技能),指导学生运用×××软件或工具进行操作实践,提高解决实际问题的能力。

The Science Education Article CollectsNo.5,2021 Sum No.5212021年第5期总第521期摘要目前学生对“大数据处理技术”课程普遍存在畏难情绪,因此探索并实践一种基于超星+EduCoder+QQ的“互联网+”多元混合教学模式显得十分必要。
这种多元混合教学模式是在超星平台上开展理论课教学,在EduCoder平台上开展实训课教学,全程通过QQ进行答疑、交流,并建立多元化考核评价机制、多元化激励督促机制,做到作业分层分级,加强交流互动和学习反馈,以提高学生的学习积极性和学习质量。
关键词混合式教学;大数据课程;教学改革;网络教学平台;多元化考核评价机制Exploration and Practice on the Multi-blended Teaching Model Based on"Internet+":Taking"Big Data Process-ing Technology"as an Example//GAO Qunxia Abstract Students are generally afraid of difficulties in the"Big Data Processing Technology"course.Therefore,this paper ex-plores and practices an"Internet+"multi-blended teaching model based on Chaoxing+EduCoder+QQ.Theoretical courses are carried out on the Chaoxing platform,and practical training courses are carried out on the EduCoder platform.The whole process is carried out through QQ question-answering and com-munication.Diversified assessment and evaluation mechanisms, multiple incentives and supervision mechanisms,and hierarchi-cal assignments are implemented,in order to strengthen commu-nication and interaction and learning feedback,and improve learning enthusiasm and teaching quality.Key words blended teaching;big data course;teaching reform; online teaching platform;multiple assessment and evaluation mechanism近年来,越来越多的高校开设了大数据专业。

数据治理体系培训内容
数据治理体系的培训内容多种多样,以下是可能包括的内容:
1. 数据治理的概念和意义:包括数据的定义、数据治理的目的、原则和好处。
2. 数据治理的组成部分:包括数据管理、数据安全、数据质量、数据价值、数据合规等。
3. 数据治理的步骤和方法:包括数据识别、分类、归档、标准化、清洗、整合、分析、监控等。
4. 数据治理的工具和技术:包括数据质量工具、数据分析工具、数据清洗工具、元数据管理工具、数据视图工具等。
5. 数据治理的流程和规范:包括数据治理的组织结构、职责分工、流程描述、信息共享、监控管理等。
6. 数据治理的实践案例:包括企业数据治理的成功案例、失败案例及其教训,行业标准和最佳实践。
7. 数据治理的未来趋势:包括人工智能、区块链、大数据、智能化等新兴技术对数据治理的影响,以及数据治理的未来发展方向。
总的来说,数据治理体系培训的目的是让企业员工深入了解数据治理的基础知识和流程,掌握相关技能和方法,并能够在实践中不断完善和提高数据治理体系的质量和效率。

2023REPORTING 大数据时代的数据治理ppt课件•数据治理概述•大数据时代下的数据挑战•数据治理的关键技术•数据治理的实施步骤•数据治理的实践案例•数据治理的未来展望目录20232023REPORTINGPART01数据治理概述数据治理的定义与重要性定义数据治理是一种组织范围内的数据管理策略,旨在确保数据质量、安全性和有效利用,以满足组织战略和业务目标。
重要性随着大数据时代的到来,数据已成为企业核心竞争力的重要组成部分。
数据治理能够确保数据的准确性、一致性和可靠性,提高数据价值,降低数据风险,从而为企业创造更多商业机会。
以数据管理为主,关注数据存储、备份和恢复等基础设施层面的问题。
初级阶段数据管理逐渐演变为数据治理,关注数据的全生命周期管理,包括数据质量、安全、隐私等方面。
发展阶段数据治理成为企业战略层面的重要议题,与业务战略紧密结合,实现数据驱动的企业决策和优化。
成熟阶段确保数据质量保障数据安全促进数据利用遵守法规要求通过建立数据质量标准和检测机制,确保数据的准确性、完整性、一致性和及时性。
通过合理的数据共享和交换机制,推动数据在组织内部的充分利用,提高数据价值。
制定和执行数据安全策略,防止数据泄露、篡改和损坏,确保数据的机密性、完整性和可用性。
确保数据处理活动符合相关法律法规和行业标准的要求,降低合规风险。
2023REPORTINGPART02大数据时代下的数据挑战随着互联网、物联网等技术的普及,数据产生速度呈指数级增长,给数据存储和处理带来巨大压力。
数据产生速度加快数据存储成本上升数据管理难度增加大规模数据的存储需要庞大的存储空间,导致存储成本不断攀升。
海量数据的管理和维护变得异常复杂,需要高效的数据管理技术和工具。
030201数据量的爆炸式增长03数据语义丰富数据的含义和背景信息千差万别,需要深入挖掘和理解数据的内在含义。
01结构化数据与非结构化数据并存除了传统的结构化数据外,非结构化数据如文本、图片、视频等日益增多,给数据处理和分析带来挑战。

大数据治理职业技能等级标准 2.0一、背景介绍随着大数据时代的到来,大数据治理成为了企业和组织管理的重要课题。
而在大数据治理领域中,专业人员的技能水平和职业能力标准至关重要。
为了规范大数据治理领域的人才培养和职业发展,我们需要建立一套专业的职业技能等级标准。
二、大数据治理职业技能等级标准的重要性1. 规范行业发展:职业技能等级标准可以规范大数据治理行业的发展,促进行业的规范化和专业化。
2. 人才评价标准:职业技能等级标准可以作为评价人才能力和水平的依据,帮助企业和组织更好地招聘和培养人才。
3. 提升职业发展:职业技能等级标准可以指导个人职业发展规划,提升个人的职业竞争力和发展空间。
三、大数据治理职业技能等级标准 2.0的框架和内容大数据治理职业技能等级标准2.0分为初级、中级和高级三个等级,分别对应于不同的职业技能水平和能力要求。
1. 初级技能等级(1)数据基础知识:掌握基本的数据概念和数据分析方法。
(2)数据收集和清洗:能够运用数据收集和清洗工具进行基本的数据处理和整理。
(3)数据安全意识:具备基本的数据安全意识和数据保护知识。
2. 中级技能等级(1)数据分析能力:具备较强的数据分析和挖掘能力,能够运用统计方法和数据挖掘技术进行数据分析。
(2)数据治理技术:熟练掌握数据治理工具和技术,能够进行数据质量管理和数据标准化工作。
(3)沟通协调能力:具备良好的沟通和协调能力,能够与不同部门和人员有效地进行沟通和协作。
3. 高级技能等级(1)数据策略和规划:能够制定和实施企业的数据治理策略和规划,具备较强的数据治理规划能力。
(2)数据技术领导:具备领导团队进行大数据治理工作的能力,能够指导团队进行数据治理相关工作。
(3)创新能力和战略思维:具备创新能力和战略思维,能够为企业提供创新的数据治理解决方案。
四、大数据治理职业技能等级标准 2.0的意义和影响大数据治理职业技能等级标准 2.0的推出将对行业和个人产生积极的意义和影响。


大数据发展过程中存在的问题及对策1.数据隐私保护问题日益突出,需要加强数据安全管理。
The issue of data privacy protection is becoming increasingly prominent, and it is necessary to strengthen data security management.2.数据采集过程中可能存在数据质量问题,需要建立严格的数据质量控制体系。
There may be data quality issues in the data collection process, so it is necessary to establish a strict dataquality control system.3.数据治理体系不够健全,需要建立完善的数据治理机制。
The data governance system is not sound enough, and it is necessary to establish a complete data governance mechanism.4.数据分析人才短缺,需加强人才培养和引进。
There is a shortage of data analysis talent, and it is necessary to strengthen talent training and introduction.5.数据安全漏洞频发,需要加强数据安全管理和技术防护。
Data security vulnerabilities are frequent, and it is necessary to strengthen data security management andtechnical protection.6.数据孤岛现象严重,需要建立数据共享与交换机制。
The phenomenon of data silos is serious, and it is necessary to establish a mechanism for data sharing and exchange.7.大数据存储和计算成本较高,要优化大数据存储和计算技术。
第1篇大家好!今天,我们在这里举行数据治理培训,旨在提升我们全体员工的数据治理意识和能力。
数据是企业的宝贵财富,也是企业决策的重要依据。
在信息化时代,数据治理已经成为企业核心竞争力的重要组成部分。
以下是我对数据治理的一些思考和体会,希望能与大家共同探讨。
一、数据治理的重要性1. 数据是企业的核心资产在当今社会,数据已经成为企业的重要资产。
企业通过收集、存储、分析和利用数据,可以更好地了解市场动态、客户需求、竞争对手等信息,从而为企业决策提供有力支持。
2. 数据治理有助于提高企业竞争力良好的数据治理能够提高数据质量,降低数据风险,提升企业运营效率。
在激烈的市场竞争中,拥有高质量数据的企业更容易抓住机遇,实现快速发展。
3. 数据治理有助于提升企业风险管理能力数据治理可以帮助企业识别、评估和应对数据风险,确保企业数据安全、合规。
在数据泄露、数据篡改等事件频发的背景下,数据治理显得尤为重要。
二、数据治理的原则1. 法规遵从原则企业应遵守国家相关法律法规,确保数据治理工作合规合法。
2. 质量优先原则数据治理应以数据质量为核心,确保数据准确、完整、一致。
3. 安全可靠原则企业应建立完善的数据安全体系,保障数据安全。
4. 效率优化原则数据治理应注重效率,简化流程,降低成本。
5. 协同共享原则企业内部应加强数据共享,促进各部门之间的协同合作。
三、数据治理的关键环节1. 数据标准制定数据标准是数据治理的基础,企业应根据业务需求制定统一的数据标准,确保数据的一致性和可比较性。
2. 数据质量管理数据质量管理是数据治理的核心环节,企业应建立数据质量管理体系,对数据质量进行监控、评估和改进。
3. 数据安全与合规企业应建立数据安全体系,确保数据在存储、传输、使用等环节的安全。
同时,要关注数据合规性,确保企业数据治理工作符合相关法律法规。
4. 数据生命周期管理数据生命周期管理是指对数据从创建、存储、使用到销毁的全过程进行管理,确保数据在整个生命周期内的合规性和有效性。
数据治理目录什么是数据治理什么是应对型数据治理什么是主动型数据治理应对型数据治理的缺点及其改进方案主动数据治理优势、应当避免的问题主动数据治理最适合哪些领域何时开始主动数据治理什么是数据治理数据治理是指从使用零散数据变为使用统一主数据、从具有很少或没有组织和流程治理到企业范围内的综合数据治理、从尝试处理主数据混乱状况到主数据井井有条的一个过程。
什么是应对型数据治理应对型数据治理是指通过客户关系管理(CRM) 等“前台”应用程序和诸如企业资源规划(ERP) 等“后台”应用程序授权主数据,例如客户、产品、供应商、员工等。
然后,数据移动工具将最新的或更新的主数据移动到多领域MDM 系统中。
它整理、匹配和合并数据,以创建或更新“黄金记录”,然后同步回原始系统、其它企业应用程序以及数据仓库或商业智能/分析系统。
什么是主动型数据治理我们如何朝着更主动的架构和数据治理模式前进?第一个要求是我们开始在多领域MDM 系统中直接授权数据,分离传统 CRM 和ERP 系统中的数据录入。
当录入系统和记录系统为同一个系统时,应用程序架构很简单。
CRM 和 ERP 系统变成主数据的消费者—它们不再创建它。
但是,为了实现此有价值的简化,需要灵活、用户友好的界面。
它有助于创建针对不同业务用户(从临时用户到专家)组的用户界面版本,同时仍然具有完整的数据管理控制台,数据管理员通过该控制台可处理需要人为判断的问题,并跟踪数据质量度量标准和解决异常。
多领域MDM 系统本身的角色发生变化,从在别处输入或更新的数据的被动接收者和整理者变为原始录入系统和记录系统。
新记录或修改后的记录通过内部数据治理规则后,MDM 系统通过实时或接近实时的中间件将经过认证的记录发布到CRM 和 ERP 系统以及所有数据仓库或分析系统。
如果不需要实时或接近实时的反馈,新记录和更改后的记录可排队等候,以便通过批量集成与企业的其它系统同步。
这一变化还消除了主要的复杂性原因。
实 验 技 术 与 管 理 第36卷 第7期 2019年7月Experimental Technology and Management Vol.36 No.7 Jul. 2019ISSN 1002-4956 CN11-2034/TDOI: 10.16791/ki.sjg.2019.07.038职业技术教育用大数据助力高职院校学生职业素质培养庞 成,丁志强(重庆工程职业技术学院,重庆 402260)摘 要:在分析高职院校学生职业素质的基础上,探讨利用大数据助力学生职业素质的培养,提出做好采集分析数据提前化解风险、院校数据共享打破孤岛效应、拓展数据功能避免短期行为等3方面工作,促进高职人才培养质量上新台阶,满足新时代对高素质新型职业人才的需要。
关键词:大数据;职业教育;素质教育;学校管理中图分类号:G710 文献标识码:A 文章编号:1002-4956(2019)07-0160-03Cultivation of students’ professional quality with aid ofbig data in higher vocational collegesPANG Cheng, DING Zhiqiang(Chongqing Engineering Vocational and Technical College, Chongqing 402260, China)Abstract: Based on the analysis of vocational quality of students in higher vocational colleges, this paper probes into the cultivation of students’ professional quality by using big data, and puts forward the proposal from the three aspects such as collecting and analyzing data to defuse risks ahead of time, breaking the information island effect of data sharing in colleges, expanding the function of data and avoiding short-term behavior, so as to promote the quality of talent training in higher vocational colleges to a new level and meet the needs of the new era for new high-quality professional talent training. Key words: big data; vocational education; quality education; school management1 高职院校学生职业素质现状近年来,高职院校学生整体素质看好,但是在以下几方面仍不尽如人意:(1)职业认知视角不正,有学生对所学专业的职业前景有所担忧,因而对学习缺少动力;(2)职业情感联结不深,对所学专业情感淡漠,更多地关注能得到好职业和高收入,而失去了对当下学习内在意义和未来职业内在价值的把握与追求;(3)职业意志、品质不够好,不乏有学生在专业学习、准职业活动中表现出虎头蛇尾、心浮气躁;(4)职业道德约束不力,例如在生产实习的准职收稿日期: 2019-01-18基金项目: 2016重庆市教委人文社会科学研究项目(16SKGH252) 作者简介: 庞成(1975—),男,重庆,硕士,教授,高级工程师,主要研究方向为教育管理.业活动中存在抄袭作业、考试作弊、实训中损坏工具或零件隐瞒不报等;(5)职业安全意识不强,在实习实训中违反安全操作规程,在专业实践中不严谨。
DAMA中国数据治理专业人员认证CDGA(数据治理工程师)模拟测试题(一)注意事项:◆本卷共100道选择题,每题1分,满分100分;◆本卷包含单选题及多选题;1、一个组织在选择建立自身的数据管理组织时,需要开展哪些工作?(多选)A.了解现有组织和文化规范B.数据管理组织结构C.关键成功要素D.建立数据管理组织E.与其他数据机构沟通F.数据管理角色答案及解析:ABCDEF看16章目录即可,通过对本章整体章节的梳理和关联,组织如果选择建立与自身业务特征相适配的数据管理组织,主要需要开展了解现有组织和文化规范、数据管理组织结构、关键成功要素、建立数据管理组织、与其他数据机构沟通和数据管理角色定位与设置六项主要工作。
2、数据管理组织的模式主要有:(多选)A.分散运营模式B.集中运营模式C.网络运营模式D.矩阵运营模式E.混合运营模式F."联邦运营模式"答案及解析:ABCEF434页,16.3.1,数据管理组织的模式主要有:分散运营模式、集中运营模式、网络运营模式、混合运营模式、联邦运营模式。
3、确定组织最佳运营管理模式,主要需要了解:(多选)A.评估当前组织运营模式B.评估当前组织所处行业C.相关部门和区域的独立性D.企业领导的作风风格ACE438页16.3.6,"引入运营模式之前,需要了解它如何影响当前组织以及它可能会如何发展。
由于运营模式将帮助政策和流程的定义、批准和执行,因此确定最适合组织的运营模式是至关重要的。
评估当前组织运营模式、相关部门和区域的独立性和决策制定与实施方法三个问题的答案能够提供一个起点,以了解组织处于分散模式和集中模式之间的位置。
"4、识别关键利益相关方,应该主要考虑:(多选)A.谁控制关键资源B.谁可以之间或间接阻止数据管理计划C.谁可以影响其他关键因素D.利益相关方是否会支持即将发生的变化E.谁资金最多答案及解析:ABCD443页16.5.3,主要需要考虑一下几点:谁控制关键资源、谁可以之间或间接阻止数据管理计划、谁可以影响其他关键因素、利益相关方是否会支持即将发生的变化。