诊断性试验Meta分析报告
- 格式:doc
- 大小:1.57 MB
- 文档页数:33

Meta分析论文数据国内学者将Meta分析也称为荟萃分析、汇总分析或元分析。
狭义的Meta 分析是指对资料进行定量合成的统计处理方法,实质上就是将相同研究目标的多个研究结果汇总并分析评价其合并效应量的一系列过程,即通过综合多个研究结果而提供一个量化的平均效果或联系来回答问题。
Meta分析是由英国教育心理学家Glass于1976年首次正式命名[],最初应用于教育学、心理学等社会科学领域。
20世纪70年代末,随着医学研究者开始吸收社会和行为科学的某些内容,Meta分析被引入医学领域,医学文献中出现了Meta分析这样的文献类型。
80年代后期Meta分析在解决医学问题上取得了很大进展,有研究发现截止1988年已经有超过110篇医学方面的Meta分析正式发表。
1989年,美国国立医学图书馆的医学主题词表出现了与Meta分析相对应的主题词——Meta-Anal-ysis as Topic,并且在1993年有了“Meta-Analysis”这一出版类型,该词表对其做了如下的阐释:Meta分析这类文献是用定量的方法合并多个独立研究结果、综合这些文献的摘要和结论,目的是评价治疗效果、计划进行新的研究等等;Meta分析常常是临床试验的全面评述,应该与传统的文献综述相区别[a]。
从这个意义上讲,Meta分析应该属于一种系统综述类文献,是用Meta分析的定量方法对资料进行统计学处理所获得的系统综述。
Meta分析具有传统综述的优点,又提供了定量的总结与统计估计,其主要贡献是为某一问题的了解提供了系统、全面、客观的评价。
鉴于Meta分析在循证临床决策中的重要性,目前临床医务工作者开始注重使用并尝试着撰写Meta分析。
但是有研究表明我国Meta分析的方法学质量和报告质量有待提高。
临床上在Meta分析的撰写方面还存在很多的问题,如:文献的查全率不高,没有列出被排除的试验,病人的特征范围、诊断标准和治疗范围不明确,对资料的可合并性的检验较差,对潜在偏倚的控制和检测不足,统计分析不规范,缺少对原始研究的质量评价,未改变方法进行敏感度分析,缺少对发表偏倚的检测,缺少对结果应用价值的评估等。

诊断性试验Meta分析报告一、引言诊断性试验在医学领域中具有至关重要的作用,它们帮助医生确定患者是否患有某种疾病,以及评估疾病的严重程度和预后。
然而,单个诊断性试验往往受到样本量、研究人群、研究方法等因素的限制,其结果可能存在偏差。
Meta 分析作为一种系统评价方法,能够综合多个诊断性试验的结果,提供更全面、更准确的诊断信息。
二、目的本 Meta 分析的目的是综合评估某种诊断性试验在特定疾病中的诊断价值,为临床医生的诊断决策提供依据。
三、资料与方法(一)检索策略我们在多个数据库(如 PubMed、Embase、Cochrane Library 等)中进行了系统的检索,检索时间范围为_____至_____。
检索词包括疾病名称、诊断性试验名称以及相关的关键词。
(二)纳入与排除标准纳入标准:①研究对象为疑似患有特定疾病的患者;②使用了所关注的诊断性试验;③报告了诊断准确性的相关指标,如敏感度、特异度、阳性预测值、阴性预测值等。
排除标准:①重复发表的研究;②研究质量差,如样本量过小、方法学存在明显缺陷等;③无法获取全文或关键数据的研究。
(三)数据提取由两名研究者独立提取纳入研究的基本信息(如作者、发表年份、研究地点等)、研究对象的特征(如年龄、性别、疾病严重程度等)、诊断性试验的方法和参数、诊断准确性的指标等。
如有分歧,通过讨论或咨询第三方解决。
(四)质量评估采用 QUADAS-2(Quality Assessment of Diagnostic Accuracy Studies 2)工具对纳入研究的质量进行评估,评估内容包括病例的选择、待评价试验、金标准、病例流程和进展情况等方面。
(五)数据分析使用 Review Manager 53 软件进行数据分析。
对于诊断准确性的指标,计算合并的敏感度、特异度、阳性似然比、阴性似然比和诊断比值比,并绘制森林图和受试者工作特征(ROC)曲线。
采用随机效应模型或固定效应模型进行合并分析,根据异质性检验的结果(I²值)选择合适的模型。

完结篇:如何解读meta分析结果Meta简明教程(8)Meta简明教程目录1. 认识一下meta方法! | Meta简明教程(1)2. 一文初步学会Meta文献检索| Meta简明教程(2)3. 如何搞定“文献筛选” | Meta简明教程(3)4.Meta分析文献质量评价 | Meta简明教程(4)5.Meta分析数据提取| Meta简明教程(5)6.一文学会revman软件| Meta简明教程(6)7.手把手教你用Stata进行Meta分析 | Meta简明教程(7)Meta简明教程(8)本期是meta简明教程的最后一章,将对meta分析的结果进行解读。
meta分析结果的正确解读,有利于得到准确的结论。
在meta分析结果解读时,要考虑到研究的异质性、采用的模型、选用的效应量、研究样本量、研究偏倚性等,本期将给大家介绍几类数据meta分析的森林图,漏斗图和SROC曲线。
一、二分类数据、生存-时间数据的meta分析结果森林图1.纳入研究个体,一般以作者和发表年份标注2.Meta分析的分组3.合并效应值,RR值、OR值、RD值、HR值,(Meta分析数据提取| Meta简明教程(5))已做介绍,需要根据纳入研究的设计方法,选择合适的效应指标分析4.Meta分析模型,可分为固定效应模型和随机效应模型,根据纳入文献的异质性进行选择5.各研究效应量及合并效应量的95%可信区间6.纳入分析的数据和权重7.异质性检验,p<0.05或I2>50%,认为各研究存在异质性,选用随机效应模型;P>0.05且I2<50%,不能认为各研究存在异质性,选用固定效应模型。
8.合并效应量OR值及可信区间,可信区间包含1,说明不认为两组率存在差异;可信区间不包含1,说明两组率存在差异9.各研究及合并效应量、可信区间,横线或菱形与竖线交叉,说明研究无统计学意义;研究中间方块面积越大,说明在分析中占权重越大二、连续型数据的meta分析结果森林图1.纳入研究个体,一般以作者和发表年份标注2.Meta分析的分组3.合并效应值,WMD、SMD值(Meta分析数据提取| Meta简明教程(5))已做介绍。


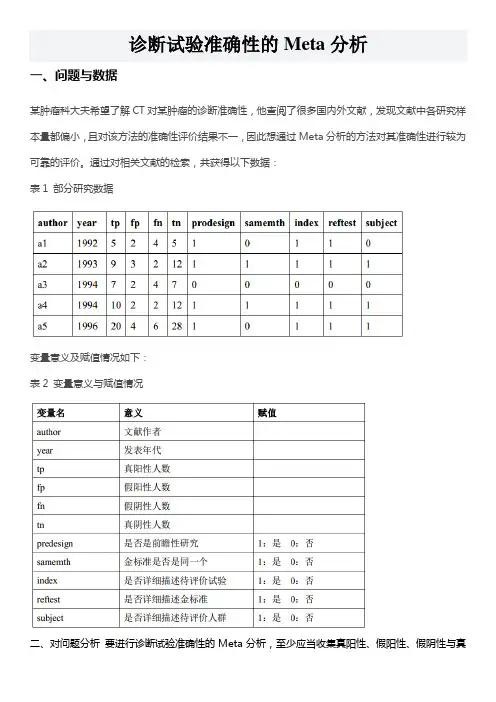
诊断试验准确性的Meta分析一、问题与数据某肿瘤科大夫希望了解CT对某肿瘤的诊断准确性,他查阅了很多国内外文献,发现文献中各研究样本量都偏小,且对该方法的准确性评价结果不一,因此想通过Meta分析的方法对其准确性进行较为可靠的评价。
通过对相关文献的检索,共获得以下数据:表1 部分研究数据变量意义及赋值情况如下:表2 变量意义与赋值情况二、对问题分析要进行诊断试验准确性的Meta分析,至少应当收集真阳性、假阳性、假阴性与真阴性的人数。
然而,Meta分析并不是简单的进行数据的加权合并,因为各研究结果不同的原因通常不仅仅是因为样本量小造成的结果不稳定,还可能是因为研究的设计、执行等多方面的因素存在差异所导致,因此Meta分析的一个重要的任务便是对可能的因素进行探讨,找出文献结果不一的原因,这也是证据评价的过程。
表1中,是否是前瞻性研究(predesign)、金标准是否是同一个(samemth)、是否详细描述待评价试验(index)、是否详细描述金标准(reftest)和是否详细描述待评价人群(subject)是本研究中研究者认为可能的影响因素。
三、Stata分析1. 安装分析包一般认为,诊断试验准确性的数据异质性比较明显,因此推荐使用随机效应模型进行分析。
Stata中有专门针对诊断试验准确性Meta分析的分析包midas和metandi,均是采用两水平的随机效应模型进行分析。
由于后者不支持meta回归功能,因此本文仅介绍midas包的使用。
在command窗口,依次输入以下命令,安装必需的分析包:ssc install midasssc install mylabels2. 数据录入在Stata窗口点击数据编辑按钮,弹出数据编辑窗口。
在变量名位置双击,弹出新建变量窗口。
如果变量是字符型,则变量类型(Variable type)选择str,是数值型则选择double(小数)或int (整数)。
设定好变量名后,从excel中将数据复制到新建变量窗口中即可,部分数据如下图。
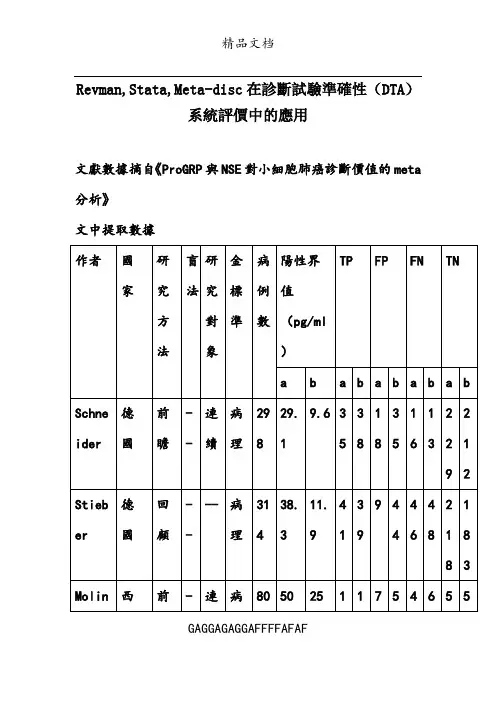
Revman,Stata,Meta-disc在診斷試驗準確性(DTA)系統評價中的應用文獻數據摘自《ProGRP與NSE對小細胞肺癌診斷價值的meta 分析》文中提取數據GAGGAGAGGAFFFFAFAFGAGGAGAGGAFFFFAFAFSun中國------病理105016.3251968915658Yang 中國------病理1444616.346491617237265注:表中 10 個原始研究均使用酶聯免疫吸附測定法檢測陽性界值; TP= 真陽性數; FP= 假陽性數; FN= 假陰性數; TN= 真陰性數a:ProGRP,b: NSERevman5.2新建診斷試驗準確性(DTA)系統評價模板GAGGAGAGGAFFFFAFAFGAGGAGAGGAFFFFAFAF添加所有納入研究GAGGAGAGGAFFFFAFAFGAGGAGAGGAFFFFAFAFGAGGAGAGGAFFFFAFAF此處對每篇文獻QUADAS2質量特征進行描述,以便探討異質性來源及作表圖數據分析里面添加所要研究的待評價診斷試驗GAGGAGAGGAFFFFAFAFGAGGAGAGGAFFFFAFAF可計算相關指標(似然比及診斷比值比和單獨在干預系統評價里面作森林圖)添加分析里面制作SEN和SPE森林圖及SROC曲線,可對數據進行重新制定GAGGAGAGGAFFFFAFAFGAGGAGAGGAFFFFAFAFStudyLamy 2000Molina 2009Nissan 2009Schneider 2003Shibayama 2001Stieber 1999Sun 2005Takada 1996Yamaguchi 1995Yang 2005TP3541134297411773802546FP18979611222669FN164641840292847917TN229218548119234972034696072Sensitivity (95% CI)0.69 [0.54, 0.81]0.47 [0.36, 0.58]0.77 [0.70, 0.83]0.78 [0.62, 0.90]0.65 [0.55, 0.74]0.80 [0.73, 0.86]0.72 [0.62, 0.81]0.63 [0.54, 0.71]0.74 [0.56, 0.87]0.73 [0.60, 0.83]Specificity (95% CI)0.93 [0.89, 0.96]0.96 [0.93, 0.98]0.87 [0.85, 0.90]0.95 [0.90, 0.98]0.96 [0.92, 0.98]0.98 [0.93, 1.00]0.90 [0.86, 0.94]0.99 [0.97, 1.00]0.91 [0.81, 0.97]0.89 [0.80, 0.95]Sensitivity (95% CI)00.20.40.60.81Specificity (95% CI)00.20.40.60.81設置參數GAGGAGAGGAFFFFAFAF若用戶對上圖窗口中的統計分析顯示的結果不滿意,可點擊右上角的屬性按鈕); 或依次展开树形目录分支"Data and Analyses→Analyses→ProGRP",选中"ProGRP"并单击右键,选择"Properties … ",弹出属性设置对话框。




Stata软件在诊断性研究的meta分析中的命令在诊断性研究的meta分析中可以计算合并阳性似然比、合并阴性似然比、诊断OR值、ROC值、SROC曲线、HSROC-bivariate meta-analysis等。
Stata进行诊断研究meta分析时的起始命令:*Variable codes: tp=true positives; fp=false positives; tn=true negatives;fn=false negatives*add .5 to all zero cellsgen zero=0replace zero=1 if tp==0|fp==0|fn==0|tn==0replace tp=tp+.5 if zero==1replace fp=fp+.5 if zero==1replace fn=fn+.5 if zero==1replace tn=tn+.5 if zero==1gen tpr= tp/(tp+fn)gen fpr=fp/(fp+tn)gen logittpr=ln(tp/fn)gen logitfpr=ln(fp/tn)gr7 tpr fpr, s(O) noaxis ysize(6) xsize(6) xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1) ylab(0(.1)1) t1(1-Specificity) l1(Sensitivity) b2(1-Specificity) b1(ROC Plot of Sensitivity vs Specificity)gr7 logittpr logitfprspearman logittpr logitfpr1.1 合并阳性似然比命令:metan tp fn fp tn, rr random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary LR+, Random Effects)2.2 合并阴性似然比命令:metan fn tp tn fp, rr random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary LR-, Random Effects)2.3 合并诊断OR值命令:metan tp fn fp tn, or random nowt sortby(author) xlab(.01,1,100) label(namevar=author, yearvar=pubyear) t1(Summary Diagnostic Odds Ratio, Random Effects)2.4 ROC值命令:gr7 tpr fpr, s(O) noaxis ysize(6) xsize(6) xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1) ylab(0(.1)1) t1(1-Specificity) l1(Sensitivity) b2(1-Specificity) b1(ROC Plot of Sensitivity vs Specificity)2.5 SROC曲线命令:gen sum= logittpr+ logitfprgen diff= logittpr- logitfprregress diff sumpredict yhatgr7 diff yhat sum, ylab(3,4,5,6,7,8) xlab(-4,-3,-2,-1,0,1,2) c(.l) s(oi)gen tse=1/(1+(1/(exp(_cons/1-_b)*(fpr/spec)^1+_b/1-_b)))(constant and b are derived from the above regression model)*plot SROC curve (generic)gr7 se tse fpr, ysize(6) xsize(6) noaxis xline(0(.1)1) yline(0(.1)1) tlab(0(.1)1) xlab(0(.1)1)ylab(0(.1)1) s(Oi) c(.s) l1(Sensitivity) b2(1-Specificity) ti(Summary ROC Curve) key1(" ")key2(" ")2.6 HSROC-bivariate meta-analysis命令:metandi tp fp fn tn, plot (基于SROC命令)2.7 发表偏倚命令:gen or=(tp*tn)/(fp*fn)gen lnor=ln(or)gen selnor=(1/tp)+(1/fp)+(1/fn)+(1/tn)*Begg and Egger test for publication bias with Begg's funnel plot: metabias lnor selnor, graph(begg)*Begg and Egger tests for subgroups (eg. Covariate=1)metabias lnor selnor if covariate==1, graph(begg)。
诊断性meta分析手把教你做临床Meta 分析——诊断试验性 Meta-Disc分析导读:诊断性meta分析,手把教你做临床 Meta 分析——诊断试验性 Meta-Disc 分析,诊断性meta分析stata,诊断性试验meta,推荐访问:诊断性meta分析stata诊断性试验meta手把教你做临床 Meta 分析——诊断试验性Meta-Disc 分析临床治疗的基础首先是需要准确的诊断,准确诊断性 Meta 分析是 Meta 分析的一个重要部分,本次想向大家推荐的是一款专用于诊断性试验的免费 Meta 分析软件,临床医学、临床检验、临床病理、临床科研人员、临床康复科及临床影像科等工作人员可用它写上一篇高大上的诊断准确性试验的 Meta 分析文章。
安装软件Meta-DiSc 是一个免费的下载软件,登录http://www.hrc.es/investigacion/metadisc_en.htm,下载安装软件,目前最新版本是 1.4 版。
运行软件在试行此软件之前,必须明确和熟悉准确诊断性 Meta 分析里结果计算的经典四格表(可能不会在您所纳入的文献中出现,需要研究人自己总结并准确的填写在四格表内,不易混淆而且方便分析)。
TP:True positive 表示真阳性的结果,用数字表示;FP:False positive 表示假阳性的结果,用数字表示;FN:False negative 表示假阴性的结果,用数字表示;TN:True negative 表示真阴性的结果,用数字表示。
1打开软件,可以看到如下界面Author:第一作者名 + 文章年限,如 Rachow 2013;StudyID:纳入文献的排序编号,亦可以按照自己理想的排名排序;2数据的输入有三种方法可以输入,我们掌握其中两种就足够运用,一种是当纳入的文献较多的时候,可以按照软件中表格的形式对应写在 Excel 表上,点击复制 Ctrl+c,并点击黏贴 Ctrl+v,便可以 copy 至软件中的表格内;另一种当纳入的文献数量较少时,则可以直接用手动输入到 Meta-disc 数据表内,如下图。
Revman,Stata,Meta-disc在诊断试验准确性(DTA)系统评价中的应用文献数据摘自《ProGRP与NSE对小细胞肺癌诊断价值的meta分析》文中提取数据注:表中 10 个原始研究均使用酶联免疫吸附测定法检测阳性界值; TP= 真阳性数; FP= 假阳性数; FN= 假阴性数; TN= 真阴性数a:ProGRP,b: NSERevman5.2新建诊断试验准确性(DTA)系统评价模板添加所有纳入研究此处对每篇文献QUADAS2质量特征进行描述,以便探讨异质性来源及作表图数据分析里面添加所要研究的待评价诊断试验可计算相关指标(似然比及诊断比值比和单独在干预系统评价里面作森林图)添加分析里面制作SEN和SPE森林图及SROC曲线,可对数据进行重新制定StudyLamy 2000 Molina 2009 Nissan 2009 Schneider 2003 Shibayama 2001 Stieber 1999Sun 2005 Takada 1996 Yamaguchi 1995 Yang 2005TP3541134297411773802546FP18979611222669FN164641840292847917TN229218548119234972034696072Sensitivity (95% CI)0.69 [0.54, 0.81]0.47 [0.36, 0.58]0.77 [0.70, 0.83]0.78 [0.62, 0.90]0.65 [0.55, 0.74]0.80 [0.73, 0.86]0.72 [0.62, 0.81]0.63 [0.54, 0.71]0.74 [0.56, 0.87]0.73 [0.60, 0.83]Specificity (95% CI)0.93 [0.89, 0.96]0.96 [0.93, 0.98]0.87 [0.85, 0.90]0.95 [0.90, 0.98]0.96 [0.92, 0.98]0.98 [0.93, 1.00]0.90 [0.86, 0.94]0.99 [0.97, 1.00]0.91 [0.81, 0.97]0.89 [0.80, 0.95]Sensitivity (95% CI)00.20.40.60.81Specificity (95% CI)00.20.40.60.81设置参数若用户对上图窗口中的统计分析显示的结果不满意,可点击右上角的属性按钮); 或依次展开树形目录分支"Data and Analyses→Analyses→ProGRP",选中"ProGRP"并单击右键,选择"Properties … ",弹出属性设置对话框。
在图对话框中,可对统计指标(General)、SROC图、森林图和异质性来源的参数进行设置,并点击"Apply"使其生效,见下图。
亚组分析(假如,原文没做)ProGRP(高质量)StudyLamy 2000Molina 2009 Nissan 2009 Schneider 2003 Shibayama 2001TP35411342974FP18979611FN164641840TN229218548119234Sensitivity (95% CI)0.69 [0.54, 0.81]0.47 [0.36, 0.58]0.77 [0.70, 0.83]0.78 [0.62, 0.90]0.65 [0.55, 0.74]Specificity (95% CI)0.93 [0.89, 0.96]0.96 [0.93, 0.98]0.87 [0.85, 0.90]0.95 [0.90, 0.98]0.96 [0.92, 0.98]Sensitivity (95% CI)00.20.40.60.81Specificity (95% CI)00.20.40.60.81ProGRP(低质量)StudyStieber 1999Sun 2005Takada 1996 Yamaguchi 1995 Yang 2005TP11773802546FP222669FN292847917TN972034696072Sensitivity (95% CI)0.80 [0.73, 0.86]0.72 [0.62, 0.81]0.63 [0.54, 0.71]0.74 [0.56, 0.87]0.73 [0.60, 0.83]Specificity (95% CI)0.98 [0.93, 1.00]0.90 [0.86, 0.94]0.99 [0.97, 1.00]0.91 [0.81, 0.97]0.89 [0.80, 0.95]Sensitivity (95% CI)00.20.40.60.81Specificity (95% CI)00.20.40.60.81QUADAS-2偏倚表(图)制作Patient Selection14463 Index Test424451 Reference Standard24446 Flow and Timing2530%25%50%75%100%0%25%50%75%100%Risk of Bias Applicability Concerns High Unclear LowP a t i e n t S e l e c t i o nLamy 2000?Molina 2009Nissan 2009+Schneider 2003?Shibayama 2001+Stieber 1999–Sun 2005+Takada 1996?Yamaguchi 1995+Yang 2005?I n d e x T e s t–?+–+––?++R e f e r e n c e S t a n d a r d??+–+?–?++F l o w a n d T i m i n g??+??––?++Risk of Bias P a t i e n t S e l e c t i o n––?–––?–?I n d e x T e s t??–?–?+?––R e f e r e n c e S t a n d a r d–?–?–???–?Applicability Concerns–High ?Unclear +Low异质性来源在DTA系统评价里面不能直接进行似然比、诊断比值比的森林图以及各指标漏斗图制作,但可以改变四个表数据模式或直接计算相关指标,添加入干预性系统评价模板中进行制作及查看异质性、发表偏倚(漏斗图)。
Stata12一拟合双变量混合效应模型:midas命令1.计算所有诊断试验统计学指标(敏感度、特异度、似然比、诊断比值比等)及异质性检验统计量:Diagnostic Odds Ratio 39.071 [ 25.251, 60.456]Diagnostic Score 3.665 [ 3.229, 4.102]Negative Likelihood Ratio 0.316 [ 0.262, 0.381]Positive Likelihood Ratio 12.348 [ 8.245, 18.494]Specificity 0.943 [ 0.913, 0.963]Sensitivity 0.702 [ 0.641, 0.756]Parameter Estimate 95% CIInconsistency (I-square): LRT_I2 = 96.39, 95% CI = [93.72-99.06]Heterogeneity (Chi-square): LRT_Q = 55.419, df =2.00, LRT_p =0.000ROC Area, AUROC = 0.89 [0.86 - 0.92]Correlation (Mixed Model)= -0.491Between-study variance(varlogitSPE)= 0.406, 95% CI = [0.133-1.241]Between-study variance(varlogitSEN) =0.136, 95% CI = [0.041-0.452]Pretest Prob of Disease =0.279Reference-negative Subjects = 2417Reference-positive Subjects = 935Number of studies = 10Bivariate Binomial Mixed Model SUMMARY DATA AND PERFORMANCE ESTIMATES2. 绘制敏感度、 特异度森林图:SENSITIVITY (95% CI)0.70[0.64 - 0.76]0.69 [0.54 - 0.81]0.47 [0.36 - 0.58]0.77 [0.70 - 0.83]0.78 [0.62 - 0.90]0.65 [0.55 - 0.74]0.80 [0.73 - 0.86]0.72 [0.62 - 0.81]0.63 [0.54 - 0.71]0.74 [0.56 - 0.87]0.73 [0.60 - 0.83]STUDY(YEAR)COMBINEDQ = 39.00, df = 9.00, p = 0.00I2 = 76.92 [62.83 - 91.01]Schneider 2003Stieber 1999Molina 2009Nissan 2009Shibayama 2001Lamy 2000Takada 1996Yamaguchi 1995Sun 2005Yang 20050.40.9SENSITIVITYSPECIFICITY (95% CI)0.94[0.91 - 0.96]0.93 [0.89 - 0.96]0.96 [0.93 - 0.98]0.87 [0.85 - 0.90]0.95 [0.90 - 0.98]0.96 [0.92 - 0.98]0.98 [0.93 - 1.00]0.90 [0.86 - 0.94]0.99 [0.97 - 1.00]0.91 [0.81 - 0.97]0.89 [0.80 - 0.95]STUDY(YEAR)COMBINEDQ = 75.58, df = 9.00, p = 0.00I2 = 88.09 [82.01 - 94.17]Schneider 2003Stieber 1999Molina 2009Nissan 2009Shibayama 2001Lamy 2000Takada 1996Yamaguchi 1995Sun 2005Yang 20050.81.0SPECIFICITY3. 绘制 ROC 曲线图:0.00.51.0S e n s i t i v i t y0.00.51.0SpecificityObserved DataSummary Operating Point SENS = 0.70 [0.64 - 0.76]SPEC = 0.94 [0.91 - 0.96]SROC CurveAUC = 0.89 [0.86 - 0.92]95% Confidence Ellipse 95% Prediction EllipseSROC with Confidence and Predictive Ellipses4. 绘制漏斗图, 识别发表偏倚:STATISTICAL TESTS FOR SMALL STUDY EFFECTS/PUBLICATIONBIAS> 206Intercept 3.78234 1.105751 3.42 0.009 1.232475 6.332> 146Bias -.7005376 17.62442 -0.04 0.969 -41.34253 39.94>> al]yb Coef. Std. Err. t P>|t| [95% Conf. Interv>11010010000.040.060.080.100.121/root(ESS)Study Regression LineLog Odds Ratio versus 1/sqrt(Effective Sample Size)(Deeks)5. 绘制似然比森林图:DLR POSITIVE (95% CI)12.35[8.24 - 18.49]9.42 [5.82 - 15.25]11.89 [6.03 - 23.41]6.08 [4.87 -7.59]16.33 [7.35 - 36.30]14.46 [7.99 - 26.16]39.67 [10.04 - 156.77]7.39 [4.88 - 11.19]49.87 [22.27 - 111.67]8.09 [3.67 - 17.81]6.57 [3.49 - 12.39]STUDY(YEAR)COMBINEDQ = 51.60, df = 9.00, p = 0.00I2 = 72.67 [72.67 - 92.45]Schneider 2003Stieber 1999Molina 2009Nissan 2009Shibayama 2001Lamy 2000Takada 1996Yamaguchi 1995Sun 2005Yang 20053.5156.8DLR POSITIVEDLR NEGATIVE (95% CI)0.32[0.26 - 0.38]0.34 [0.23 - 0.51]0.55 [0.45 - 0.67]0.27 [0.20 - 0.35]0.23 [0.12 - 0.42]0.37 [0.29 - 0.47]0.20 [0.15 - 0.28]0.31 [0.22 - 0.42]0.37 [0.30 - 0.47]0.29 [0.17 - 0.51]0.30 [0.20 - 0.46]STUDY(YEAR)COMBINEDQ = 42.30, df = 9.00, p = 0.00I2 = 78.72 [66.00 - 91.44]Schneider 2003Stieber 1999Molina 2009Nissan 2009Shibayama 2001Lamy 2000Takada 1996Yamaguchi 1995Sun 2005Yang 200501DLR NEGATIVE6.绘制诊断比值比森林图:7.绘制验前概率、验后概率图:验前概率=患病率,验后概率=验前概率*似然比0.0010.0020.0050.010.020.050.10.20.51251020501002005001000Likelihood Ratio 0.10.20.30.50.712357102030405060708090939597989999.399.599.799.899.9P o s t -t e s t P r o b a b i l i t y (%)0.10.20.30.50.712357102030405060708090939597989999.399.599.799.899.9Prior Prob (%) = 20LR_Positive = 12Post_Prob_Pos (%) = 76LR_Negative = 0.32Post_Prob_Neg (%) = 7Fagan's Nomogram二 拟合HSROC 模型:metandi 命令1.合并统计量命令. metandi tp fp fn tnRefining starting values:Iteration 0: log likelihood = -73.728348 (not concave)Iteration 1: log likelihood = -69.302533Iteration 2: log likelihood = -67.980313Iteration 3: log likelihood = -67.378598Performing gradient-based optimization:Iteration 0: log likelihood = -67.378598Iteration 1: log likelihood = -67.370761Iteration 2: log likelihood = -67.370744Iteration 3: log likelihood = -67.370744Meta-analysis of diagnostic accuracyLog likelihood = -67.370744 Number of studies = > 10>Coef. Std. Err. z P>|z| [95% Conf. Interv > al]>BivariateE(logitSe) .8564618 .1410043 .5800985 1.132 > 825E(logitSp) 2.808916 .230571 2.357005 3.260 > 826Var(logitSe) .1356511 .0833172 .0407018 .4520 > 984Var(logitSp) .4063271 .2312948 .1331508 1.23 > 996Corr(logits) -.4913658 .3666173 -.9024235 .3879 > 676>HSROCLambda 3.261869 .2776274 2.71773 3.806 > 009Theta -.5042014 .3386717 -1.167986 .159 > 583beta .5485361 .3866854 1.42 0.156 -.2093534 1.306 > 426s2alpha .2388279 .1917059 .0495257 1.151 > 701s2theta .1750668 .0938807 .0611986 .5008 > 023>Summary pt.Se .7019209 .029502 .6410901 .7563 > 599Sp .9431557 .0123616 .9134894 .9630 > 602DOR 39.07088 8.70083 25.25202 60.45 > 194LR+ 12.34813 2.544551 8.245105 18.49 > 296LR- .3160444 .0300356 .2623332 .3807 > 5261/LR- 3.164112 .3007045 2.626377 3.811 > 945>Covariance between estimates of E(logitSe) & E(logitSp) -.01172642.绘制SROC曲线S e n s i t i v it yMeta-disc14表2 Meta-Disc软件的主要功能主要功能说明Describing primary results and exploringheterogeneity描述原始结果和探索异质性●Tabular results ●将结果以表格形式列出●Forestplots(sensitivity,specificity,LRs,dOR) ●以森林图形式显示灵敏度、特异度、似然比和诊断比值比●ROC plane scatter-plots ●ROC平面散状图●Cochran-Q,Chi-Square, Inconsistency index ●判断研究间异质性●Filtering/subgrouping capacities ●亚组分析Exporing Threshold effect 探讨阈值效应●Spearman correlation coefficient ●Spearman相关系数●ROC plane plots ●ROC平面图SROC curve fitting.Area under the curve(AUC)and Q拟合SROC曲线、计算AUC和Q指数Meta-regression analysis 回归分析,探讨异质性来源●Univariate and multivariate Moses andLitteenberg model(weight and unweight) ●(加权或未加权)单变量及多变量MosesLitteenberg模型Statistical polling of indices 合并统计量●Fixed effect model ●固定效应模型●Random effect model ●随机效应模型数据录入Meta分析1.探索阈值效应2.合并效应量、探讨异质性Summary SpecificityStudy | Spe [95% Conf. Iterval.] TP/(TP+FN) TN/(TN+FP)-------------------------------------------------------------------------------------- Schneider | 0.927 0.887 - 0.956 35/51 229/247Stieber | 0.960 0.926 - 0.982 41/87 218/227Molina | 0.874 0.845 - 0.899 134/175 548/627Nissan | 0.952 0.898 - 0.982 29/37 119/1253.绘制森林图4.绘制SROC曲线5.meta回归分析。