参数估计的基本理论
- 格式:doc
- 大小:474.00 KB
- 文档页数:9


统计推断与参数估计的基本理论与方法统计推断是统计学中的一门重要的研究领域,它主要关注如何通过样本数据对总体特征进行推断。
参数估计则是统计推断的一个重要组成部分,它通过样本数据来估计总体参数。
本文将介绍统计推断和参数估计的基本理论和方法。
一、统计推断的基本理论统计推断的基本理论包括抽样理论、似然函数和假设检验等。
1. 抽样理论抽样理论是统计推断的基础,它研究的是如何从总体中抽取样本以便对总体进行推断。
通过合理的抽样方法,可以保证样本对总体的代表性。
2. 似然函数似然函数是参数估计的基本工具,它是样本观测值关于参数的函数。
通过最大似然估计可以得到参数的最优估计值。
3. 假设检验假设检验是统计推断的重要方法,用于检验某个关于总体参数的假设。
它包括构造检验统计量和确定拒绝域两个步骤,从而进行参数推断。
二、参数估计的基本方法参数估计是统计推断中的核心内容,它通过样本数据来估计总体参数。
参数估计的基本方法包括点估计和区间估计。
1. 点估计点估计是一种直接估计总体参数的方法,它通过样本数据来估计总体参数的具体值。
最常用的点估计方法是最大似然估计和矩估计。
2. 区间估计区间估计是一种间接估计总体参数的方法,它给出了参数的估计区间。
通过给出一个置信区间,可以对总体参数进行估计,并给出估计的精度。
三、常用的统计推断方法在实际应用中,统计学家们发展了许多常用的统计推断方法,包括假设检验、方差分析、回归分析等。
1. 假设检验假设检验是统计推断中最常用的方法之一,它用于检验某个关于总体参数的假设。
例如,检验某种药物对疾病的治疗效果是否显著。
2. 方差分析方差分析是一种用于比较多个总体均值的方法,它通过分析不同组之间的方差来判断各组均值是否有显著差异。
例如,在新产品开发中,可以通过方差分析评估不同市场的销售情况。
3. 回归分析回归分析是一种用于建立变量之间关系的方法,它可以推断自变量对因变量的影响程度。
通过回归分析可以得到回归方程,从而进行预测和解释。

各种参数的极大似然估计1.引言在统计学中,参数估计是一项关键任务。
其中,极大似然估计是一种常用且有效的方法。
通过极大化似然函数,我们可以估计出最有可能的参数值,从而进行推断、预测和优化等相关分析。
本文将介绍各种参数的极大似然估计方法及其应用。
2.独立同分布假设下的参数估计2.1参数估计的基本理论在独立同分布假设下,我们假设观测数据相互独立且具有相同的概率分布。
对于一个已知的概率分布,我们可以通过极大似然估计来估计其中的参数。
2.2二项分布参数的极大似然估计对于二项分布,其参数为概率$p$。
假设我们有$n$个独立的二项分布样本,其中成功的次数为$k$。
通过极大似然估计,我们可以得到参数$p$的估计值$\h at{p}$为:$$\h at{p}=\f ra c{k}{n}$$2.3正态分布参数的极大似然估计对于正态分布,其参数为均值$\mu$和标准差$\si gm a$。
假设我们有$n$个独立的正态分布样本,记为$x_1,x_2,...,x_n$。
通过极大似然估计,我们可以得到参数$\mu$和$\si gm a$的估计值$\h at{\m u}$和$\ha t{\s ig ma}$分别为:$$\h at{\mu}=\f rac{1}{n}\su m_{i=1}^nx_i$$$$\h at{\si gm a}=\s q rt{\fr ac{1}{n}\s um_{i=1}^n(x_i-\h at{\mu})^2}$$3.非独立同分布假设下的参数估计3.1参数估计的基本理论在非独立同分布假设下,我们允许观测数据的概率分布不完全相同。
此时,我们需要更加灵活的方法来估计参数。
3.2伯努利分布参数的极大似然估计伯努利分布是一种二点分布,其参数$p$表示某事件发生的概率。
假设我们有$n$组独立的伯努利分布样本,其中事件发生的次数为$k$。
通过极大似然估计,我们可以得到参数$p$的估计值$\h at{p}$为:$$\h at{p}=\f ra c{k}{n}$$3.3泊松分布参数的极大似然估计泊松分布是一种描述罕见事件发生次数的概率分布,其参数$\la mb da$表示单位时间(或单位面积)内平均发生的次数。

参数区间估计的基本原理
参数区间估计是一种统计学方法,用于根据样本数据推断总体参数的取值范围。
它基于概率论和抽样分布理论,通过计算样本统计量(如样本均值、样本比例等)并结合置信水平,确定总体参数可能落在的一个区间范围内。
参数区间估计的基本原理可以概括如下:
1. 抽样分布:从总体中抽取一个样本,样本统计量的分布称为抽样分布。
例如,当从正态总体中抽取样本时,样本均值的分布也是正态分布。
2. 置信水平:置信水平表示我们对估计结果的置信程度,通常用百分数表示。
常见的置信水平包括 90%、95%和 99%等。
3. 计算区间:根据样本统计量和置信水平,可以计算出一个置信区间。
置信区间是一个包含总体参数的区间范围,它表示在给定的置信水平下,总体参数有多大的概率会落在这个区间内。
4. 推断结论:根据计算得到的置信区间,可以推断出总体参数的取值范围。
如果置信区间包含了零或其他特定的值,可以得出关于总体参数是否显著不同于零或其他特定值的结论。
参数区间估计的基本原理是基于样本数据和抽样分布,通过计算置信区间来推断总体参数的可能取值范围。
这种方法在统计学中被广泛应用,用于推断总体参数的值、检验假设、进行统计推断等。

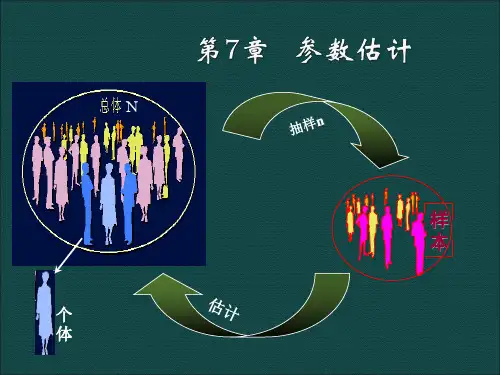





第3章 参数估计的基本理论信号检测:通过准则来判断信号有无;参数估计:由观测量来估计出信号的参数;解决1)用什么方法求取参数,2)如何评价估计质量或者效果严格来讲,这一章研究的是参数的统计估计方法,它是数理统计的一个分支。
推荐两本参考书高等教育出版社《数理统计导论》,《Nonlinear Parameter Estimation 》。
我们首先从一个估计问题入手,来了解参数估计的基本概念。
3.1 估计的基本概念3.1.1 估计问题对于观察值x 是信号s 和噪声n 叠加的情况:()x s n θ=+其中θ是信号s 的参数,或θ就是信号本身。
若能找到一个函数()f x ,利用()12,,N f x x x 可以得到参数θ的估计值 θ,相对估计值 θ,θ称为参数的真值。
则称()12,,N f x x x 为参数θ的一个估计量。
记作 ()12,,Nf x x x θ= 。
在上面的方程中,去掉n 实际上是一个多元方程求解问题。
这时,如果把n 看作是一种干扰或摄动,那么就可以用解确定性方程的方法来得出()f x 。
但是我们要研究的是参数的统计估计方法,所以上面的描述并不适合我们的讨论。
下面给出估计的统计问题描述。
(点估计)设随机变量x 具有某一已知函数形式的概率密度函数,但是该函数依赖于未知参数θ,Ω∈θ ,Ω称为参数空间。
因此可以把x 的概率密度函数表示为一个函数族);(θx p 。
N x x x ,,,21 表示随机样本,其分布取自函数族);(θx p 的某一成员,问题是求统计量 ()12,,Nf x x x θ= ,作为参数θ的一个估计量。
以上就是用统计的语言给出的参数估计问题的描述。
数。
统计量的两个特征:1,随机变量的函数,因此也是随机变量;2,不依赖于未知参数,因此当我们得到随机变量的一组抽样,就可以计算得到统计量的值。
例3-1:考虑由(1,2,,)i ix s n i N =+= ,给定的观测样本。
第3章 参数估计的基本理论信号检测:通过准则来判断信号有无;参数估计:由观测量来估计出信号的参数;解决1)用什么方法求取参数,2)如何评价估计质量或者效果严格来讲,这一章研究的是参数的统计估计方法,它是数理统计的一个分支。
推荐两本参考书高等教育出版社《数理统计导论》,《Nonlinear Parameter Estimation 》。
我们首先从一个估计问题入手,来了解参数估计的基本概念。
3.1 估计的基本概念3.1.1 估计问题对于观察值x 是信号s 和噪声n 叠加的情况:()x s n θ=+其中θ是信号s 的参数,或θ就是信号本身。
若能找到一个函数()f x ,利用()12,,N f x x x 可以得到参数θ的估计值 θ,相对估计值 θ,θ称为参数的真值。
则称()12,,N f x x x 为参数θ的一个估计量。
记作 ()12,,Nf x x x θ= 。
在上面的方程中,去掉n 实际上是一个多元方程求解问题。
这时,如果把n 看作是一种干扰或摄动,那么就可以用解确定性方程的方法来得出()f x 。
但是我们要研究的是参数的统计估计方法,所以上面的描述并不适合我们的讨论。
下面给出估计的统计问题描述。
(点估计)设随机变量x 具有某一已知函数形式的概率密度函数,但是该函数依赖于未知参数θ,Ω∈θ ,Ω称为参数空间。
因此可以把x 的概率密度函数表示为一个函数族);(θx p 。
N x x x ,,,21 表示随机样本,其分布取自函数族);(θx p 的某一成员,问题是求统计量 ()12,,Nf x x x θ= ,作为参数θ的一个估计量。
以上就是用统计的语言给出的参数估计问题的描述。
数。
统计量的两个特征:1,随机变量的函数,因此也是随机变量;2,不依赖于未知参数,因此当我们得到随机变量的一组抽样,就可以计算得到统计量的值。
例3-1:考虑由(1,2,,)i ix s n i N =+= ,给定的观测样本。
其中s 是未知参数,i n 为噪声,取自分布),0(2n n σ。
容易得到x 服从分布),(2n s n σ,s 的一个估计值是:12121ˆ(,,)()N N sf x x x x x x N==++ 如果2n σ未知,则它的一个估计量为:∑∑===-=N k k x N k x k nx N x N 11221,)(1ˆμμσ有时估计结果会以这样的形式给出:s 以95%的置信度位于区间()ˆˆˆˆ,n n st s t σσ-+中。
我们称其为区间估计。
区间估计量也可以直接计算得到,而不必先计算点估计量。
当我们以某种函数形式给出估计量以后,是不是任务就结束了呢?还有一个任务是:建立一些准则或者性能指标来评价估计的质量。
3.1.2 估计的偏差和无偏性若 θ是参数θ的估计值,则定义估计的偏差为: ()b E θθθ=- (3-1)即估计值的均值与真值的差。
若估计偏差0b θ=,即 ()E θθ=,则估计是无偏估计。
这里隐含假定ˆ()E θ是存在的。
无偏性定义:定义: θ是θ的一个无偏估计,若θ在所有可能的样本范围内的平均值等于θ的真值,即E θθ⎡⎤=⎣⎦(3-2)称为无偏估计,否则 E θθ⎡⎤≠⎣⎦为有偏估计。
在有偏估计中,如果随着样本数N 的不断增大,偏差 b θ趋向于0,即:l i m 0N b θ→∞= 则该估计称为渐进无偏估计让我们分析例3-1的无偏性,注意数学期望是一个线性算子。
()E s ()E x =()()11N E x E x N =++⎡⎤⎣⎦()()11N s E n s E n N =+++⎡⎤⎣⎦ ()()11N s E n E n N=+++⎡⎤⎣⎦ 如果噪声i n 是零均值的,即()()10N E n E n ++= ,或对所有i 有()0i E n =,则s是s 的一个无偏估计。
从数理统计这门课,我们知道样本方差∑∑===-=N k k x N k x k nx N x N 11221,)(1ˆμμσ对于方差2n σ是有偏的,因为无偏估计量是22,1111ˆ(),1N Nn ubiask x xkk k x xN Nσμμ===-=-∑∑。
但是样本方差是渐进无偏的。
直觉上,一个好的估计量应当具有无偏性,但是实际上完全的无偏性通常是达不到的,只能希望小的偏差。
而且估计的偏差也不是特别地的重要,因为估计误差不仅仅是偏差。
估计的偏差和估计误差不是一回事,偏差只代表估计量的系统误差。
1,x x μ都是s 的无偏估计量,系统误差都为零。
接下来,要研究估计误差的另一个性质——估计的方差,它反映了估计量的随机误差大小。
3.1.3 估计的方差和Cramer-Rao (克拉美-劳)不等式估计的方差: (){}22ˆE E θσθθ⎡⎤=-⎣⎦方差:估计值 θ相对于均值 ()E θ的分散程度。
即2ˆθσ越大就越发散,反之2ˆθσ越小就越集中。
任何无偏估计方差的下界叫做C-R 下界用它来衡量估值方差的最小值。
下面给出的定理是克拉美-劳定理的精简版。
定理:若 θ是参数θ的一个无偏估计,()|p X θ是观测值X (Nx x x ,,,21 )的联合条件概率密度,若()|p X θθ∂∂存在,则该估计的方差存在一个下界,即 ()()2ˆ22211ln |ln |p X E p X E θσθθθθ≥=-⎧⎫⎧⎫∂∂⎡⎤⎪⎪⎨⎬⎨⎬⎢⎥∂⎩⎭∂⎣⎦⎪⎪⎩⎭(3-3)这个不等式就被称为克拉美-劳不等式,此下界被称为是估计方差的 C-R 下界。
式中等式在下述条件下是成立的:()() ()ln |p X k θθθθθ∂=-∂ (3-4) 其中()k θ是与参数θ有关与观测值X 无关的正函数。
这里把参数θ当作随机变量。
如果其真值0θ是客观存在的未知常数,怎么去理解?我们将参数空间Ω,分成若干个子空间(或子集),认为0θ将以不同的概率落入不同的子空间当中。
()|p X θ如果实在理解不了,可以看做是();p X θ。
证明 :由于 θ是参数θ的一个无偏估计,有: E θθ⎡⎤=⎣⎦即 0E θθ⎡⎤-=⎣⎦ 而 E θθ⎡⎤-⎣⎦可以写成为: ()()E p X d x θθθθθ∞-∞⎡⎤-=-⎣⎦⎰,dx 表示12n dx dx dx 所以: ()()0p X dx θθθ∞-∞-=⎰对参数求偏导:[()()]()()0p X p X dx dx θθθθθθθθ∞∞-∞-∞∂-∂-==∂∂⎰⎰()()()0p X p X dx dx θθθθθ∞∞-∞-∞∂-+-=∂⎰⎰由于有关系式:()1p X dx θ∞-∞=⎰()ln ()()p X p X p X θθθθθ∂∂=∂∂ 则可以得:ln ()()()1p X p X dx θθθθθ∞-∞∂-=∂⎰根据:()p X θ=有: )]1dx θθ∞-∞-=⎰ 根据Schwarz 不等式得:22ln ()[]()()()1p X p X dx p X dx θθθθθθ∞∞-∞-∞∂-≥∂⎰⎰ 即: 221()()ln ()[]()p X dx p X p X dx θθθθθθ∞-∞∞-∞-≥∂∂⎰⎰由于 E θθ⎡⎤=⎣⎦则有: (){}2222ˆ()()()E E E p X dx θσθθθθθθθ∞-∞⎡⎤⎡⎤=-=-=-⎣⎦⎣⎦⎰ 而 22ln ()ln (){[]}[]()p X p X E p X dx θθθθθ∞-∞∂∂=∂∂⎰所以(3-3)的不等式成立同时,当且仅当()K θθθ=- 即:ln ()()()p X K θθθθθ∂=-∂ 其中()k θ是与参数θ有关而与观测值x 无关的系数时,(3-3)的等式成立。
定理给出了无偏估计最小方差的计算公式。
克拉美-劳下界与N 的关系。
定义随机变量()()1ln |ln |N i k p X p x z θθθθ=∂∂==∂∂∑()1i i p x dx θ∞-∞=⎰,()ln ()()i i i p x p x p x θθθθθ∂∂=∂∂, 所以有,()0i i p x dx θθ∞-∞∂=∂⎰,ln ()ln ()()()0i ii i p x p x E p x dx θθθθθ∞-∞∂∂==∂∂⎰。
从而z 为一组零均值且相互独立的随机变量的和,其方差()()()22221ln |ln |ln |N iz k p X p x p x E E N E θθθσθθθ=⎡⎤⎡⎤⎡⎤∂∂∂⎛⎫⎛⎫⎛⎫⎢⎥⎢⎥⎢⎥===⋅ ⎪ ⎪ ⎪∂∂∂⎢⎥⎢⎥⎢⎥⎝⎭⎝⎭⎝⎭⎣⎦⎣⎦⎣⎦∑因此,克拉美-劳下界与1/N 成正比。
3.1.4 估计的有效性上面介绍了估计量的偏差和方差。
下面介绍估计的另一个性质——有效性。
我们在科研工作当中,经常会用到“精度”或者“精确性”这样的词汇。
那么怎样来评价估计量的精度呢?显然,合理的评价方法应该是综合考虑偏差和方差,下面给出均方误差 D θ的定义:均方误差: ()2D E θθθ⎡⎤=-⎢⎥⎣⎦注意它与方差的区别。
估计的均方误差和方差、偏差存在如下关系:22ˆD b θθθσ=+ (3-5) 证明: ()2D E θθθ⎡⎤=-⎢⎥⎣⎦() ()2E E E θθθθ⎧⎫⎡⎤=-+-⎨⎬⎣⎦⎩⎭{}() (){}22()2()()()E E E E E E E θθθθθθθθ⎡⎤⎡⎤⎡⎤=-+--+-⎣⎦⎣⎦⎣⎦上式中的第一项就是方差2ˆθσ,第三项则是 2b θ(数学期望就是自身)。
注意 ()E θ本身是θ的函数,与θ一样都可以是随机变量;第一项和第三项也不一定是相互独立的。
() () () ()()()()()0E E E E E E θθθθθθθθ⎡⎤--=--=⎣⎦,则中间等于0 所以式(3-5)成立。
证毕。
方差2ˆθσ越小,每次估计值 θ相对于 ()E θ就越集中。
偏差b θ越小则数学期望 ()E θ就越接近真值θ。
原版的克拉美-劳定理中不要求ˆθ是无偏估计,并且θ为矢量,方差2ˆθσ的克拉美-劳下限是1PR P -T ,官方的名字叫MVB(Minimum Variance Bound),其中ˆ()P E θθ=∂∂,()()()()ln |ln |R E p x p x θθθθT ⎡⎤=∂∂∂⎣⎦如果用一种方法得到的估计值的方差小于用其它任何方法得到的方差,则称这种估计为有效估计。
若又是无偏估计,则称为均方误差最小估计。
若122ˆ2ˆθθσσ小于1,就说 1θ比 2θ更有效。
2ˆθσMVB 称为估计的效率。
例3-2:一观测过程由()()x n A v n =+定义,其中A 是一未知的常量参数,而()v n 是高斯白噪声,均值为零,方差为2σ。
若参数估计值11()Nn A x n N==∑,求其估计方差的C-R 下界。