多元统计学SPSS实验报告一
- 格式:docx
- 大小:748.01 KB
- 文档页数:5

实验一SPSS软件的基本操作与均值向量和协方差阵的检验【实验目的】通过本次实验,了解SPSS的基本特征、结构、运行模式、主要窗口等,了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法,对SPSS有一个浅层次的综合认识。
同时能够掌握对均值向量和协方差阵进行检验。
【实验性质】必修,基础层次【实验仪器及软件】计算机及SPSS软件【实验内容】1.操作SPSS的基本方法(打开、保存、编辑数据文件)2.问卷编码3.录入数据并练习数据相关操作4.对均值向量和协方差阵进行检验,并给出分析结论。
【实验学时】4学时【实验方法与步骤】1.开机2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS3.认识SPSS数据编辑窗、结果输出窗、帮助窗口、图表编辑窗、语句编辑窗4.对一份给出的问卷进行编码和变量定义5.按要求录入数据6.练习基本的数据修改编辑方法7.检验多元总体的均值向量和协方差阵8.保存数据文件9.关闭SPSS,关机。
【实验注意事项】1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。
2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员同意,禁止使用移动存储器。
4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换,应报指导教师或实验室管理人员同意。
5.上机时间,禁止使用计算机从事与课程无关的工作。
【上机作业】1.定义变量:试录入以下数据文件,并按要求进行变量定义。
表1学号姓名性别生日身高(cm)体重(kg)英语(总分100分)数学(总分100分)生活费($代表人民币)200201 刘一迪男1982.01.12 156.42 47.54 75 79 345.00 200202 许兆辉男1982.06.05 155.73 37.83 78 76 435.00 200203 王鸿屿男1982.05.17 144.6 38.66 65 88 643.50 200204 江飞男1982.08.31 161.5 41.68 79 82 235.50 200205 袁翼鹏男1982.09.17 161.3 43.36 82 77 867.00 200206 段燕女1982.12.21 158 47.35 81 74200207 安剑萍女1982.10.18 161.5 47.44 77 69 1233.00 200208 赵冬莉女1982.07.06 162.76 47.87 67 73 767.80 200209 叶敏女1982.06.01 164.3 33.85 64 77 553.90 200210 毛云华女1982.09.12 144 33.84 70 80 343.00200211 孙世伟男1981.10.13 157.9 49.23 84 85 453.80200212 杨维清男1981.12.6 176.1 54.54 85 80 843.00男1981.11.21 168.55 50.67 79 79 657.40 200213 欧阳已祥200214 贺以礼男1981.09.28 164.5 44.56 75 80 1863.90200215 张放男1981.12.08 153 58.87 76 69 462.20200216 陆晓蓝女1981.10.07 164.7 44.14 80 83 476.80200217 吴挽君女1981.09.09 160.5 53.34 79 82200218 李利女1981.09.14 147 36.46 75 97 452.80200219 韩琴女1981.10.15 153.2 30.17 90 75 244.70200220 黄捷蕾女1981.12.02 157.9 40.45 71 80 253.00要求:1)变量名同表格名,以“()”内的内容作为变量标签。

多元统计学SPSS实验报告一华东理工大学2016–2017学年第二学期《多元统计学》实验报告实验名称实验1数据整理与描述统计分析专业姓名学号组名/组号实验时间实验地点指导教师实验目的/要求1、掌握数据整理的基本方法:观察量排序(Sort Cases)、变量排序(Rank Cases)、计算新的变量(Compute Variables)、拆分数据文件(Split Files) 、分类汇总(Aggregate)等。
2、熟练应用SPSS输出描述统计量和绘制统计图。
实验内容1、对“employee data.sav ”进行数据整理,并分别给出三种工作类别(jobcat)的薪水(salary)的描述统计量(均值、方差等)。
2、对第1章的习题4进行描述统计分析。
实验总结教师批阅:实验成绩:教师签名: 日期:实验报告正文:实验 1.1数据整理(一)对“employee data.sav ”进行数据整理1.观察量排序 ( based on current salary)2.变量值排序(based on current salary : rsalary)3.计算新的变量(incremental salary=current salary - beginning salary)4.拆分数据文件(based on gender)结论:There are 215 female employees and 259 male employees.5.分类汇总 (break variable: gender ; function: mean )结论:The average current salary of female is 26031.92.The average current salary of male is 41441.78.(二)分别给出三种工作类别的薪水的描述统计量实验2.2描述统计分析1)样本均值矩阵结论:总共分析六组变量,每组含有十个样本。

【精品】多元统计分析--判别分析SPSS实验报告一、实验目的1.掌握判别分析的基本原理和应用方法;2.掌握SPSS软件进行判别分析的具体操作;3.通过一个实例,学习如何运用判别分析对指标进行判别。
二、实验内容三、实验原理1.判别分析基本原理:判别分析(Discriminant Analysis),是一种统计学中的分类技术,它是对变量进行归类的技术。
判别分析是用来确定一个对象或自变量集合属于哪一个预设类型或者组别的过程。
判别分析能够生成一个函数,将数据点映射到特定的类型上。
判别分析的应用领域非常广泛,主要应用于以下领域:(1)股票市场(预测股价的涨跌与时间、公司发展情况等因素的关系);(2)医学(区分疾病、患者状态等);(3)市场调查(确定客户类型、产品或服务喜好);(4)产业分析(区分有助于产品销售的市场决策因素);(5)经济学(预测月度或季度的经济指标)。
3.判别分析的主要应用步骤:(1)建立模型:首先选择和收集数据,将收集的数据分为训练集和测试集;(2)训练模型:使用训练数据建立模型;(3)评估模型:通过模型诊断来评估建立的模型的好坏;(4)应用模型:对新的数据建立模型并进行预测。
四、实验过程1. 上机操作:1)打开SPSS软件,加载数据文件;2)选择分类变量和连续变量;3)选择训练数据集;4)建立模型;5)预测实验数据集。
2. 操作步骤:SPSS分析的步骤如下:1)将数据输入SPSS软件,确保数据格式正确;2)选择Analyse- Classify- Discriminant;3)有两种不同的分类变量,单分类或多分类,如果你要解释一个特定的分类变量,选择单分类。
如果你不确定哪个分类变量最适合,请尝试不同的选项;4)选择两个或更个你认为与指定分类变量相关的连续变量;5)选择要用于判别分析的数据集;6)确定分类变量分类比率。
这可以在设置选项中完成;7)点击OK,开始进行分析;8)评估结果,包括汇总、判别函数、方差-方差贡献、判别矩阵;五、实验结果选取鸢尾花数据,经过训练,得到如下表所示的结果。

一、实验背景随着社会经济的发展和科学技术的进步,数据量日益庞大,如何从大量数据中提取有价值的信息,成为统计学研究的热点问题。
多元统计分析作为统计学的一个重要分支,通过对多个变量之间的关系进行分析,为决策者提供有力的数据支持。
本实验旨在通过实际操作,让学生熟练掌握多元统计分析方法,提高数据分析能力。
二、实验目的1. 掌握多元统计分析的基本概念和方法;2. 学会运用多元统计分析方法解决实际问题;3. 提高数据分析能力,为后续课程打下坚实基础。
三、实验内容本次实验以某城市居民消费数据为例,运用多元统计分析方法对其进行分析。
四、实验步骤1. 数据导入首先,将实验数据导入统计软件(如SPSS、R等)。
本实验采用SPSS软件,数据集包含以下变量:(1)收入(y):居民年收入;(2)教育程度(x1):居民最高学历;(3)年龄(x2):居民年龄;(4)家庭人口(x3):家庭人口数量;(5)住房面积(x4):家庭住房面积。
2. 描述性统计分析对数据集进行描述性统计分析,包括各变量的均值、标准差、最大值、最小值等。
3. 相关性分析运用皮尔逊相关系数、斯皮尔曼等级相关系数等方法,分析变量之间的相关关系。
4. 主成分分析运用主成分分析方法,提取主要成分,降低数据维度。
5. 聚类分析运用K-means聚类分析方法,将居民划分为不同的消费群体。
6. 随机森林回归分析运用随机森林回归分析方法,预测居民收入。
五、实验结果与分析1. 描述性统计分析根据描述性统计分析结果,可知居民年收入、教育程度、年龄、家庭人口、住房面积的平均值、标准差、最大值、最小值等。
2. 相关性分析通过相关性分析,发现收入与教育程度、年龄、家庭人口、住房面积之间存在显著的正相关关系。
3. 主成分分析根据主成分分析结果,提取出两个主成分,累计方差贡献率为84.95%,可以解释大部分的变量信息。
4. 聚类分析通过K-means聚类分析,将居民划分为3个消费群体。

多元统计分析实验报告学院名称理学院专业班级应用统计学14-2学生姓名张艳雪学号201411081051工资、受教育年限、初始工资和工作经验资料如下表所示: 设职工总体的以上变量服从多元正态分布,根据样本资料利用 SPSS 软件求出均注 1:最大似然估计公式为: μˆ = X = ∑ ∑ (X i - X )(X i - X )' ; ˆ第一章 多元正态分布1.1 从某企业全部职工中随机抽取一容量为 6 的样本,该样本中个职工的目前值向量和协方差矩阵的最大似然估计。
1 n n i =1 X i , Σ = 1 nn i =1一.SPSS 操作步骤:第一步:利用 spss 建立数据集第二步:分析--描述统计--描述 计算样本均值向量 第三步:分析--相关--双变量计算样本协方差阵与样本相关系数二.输出结果:⎪ μ= 37125 ⎪ 152.50⎪ ⎛ 352068000 12500 -110677500 102000 ⎫= -110677500 - 86250 2192793750 691125 ⎪16695.1⎪⎭ ∑ X i,∑ (X i - X )(X i - X )'ˆ三.实验结果分析:样本均值为样本的协方差∑⎪⎪如此就可以按照极大似然估计方程:1 nΣ =n i =1得出均值向量与协方差向量的最大似然估计结果。
μ=X=1nn i=1ˆ第三章聚类分析3.1下表是15个上市公司2001年的一些主要财务指标,使用系统聚类法和K-均值法利用SPSS软件分别对这些公司进行聚类,并对结果进行比较分析。
公司编号净资产收益率每股净利润总资产周转率资产负债率流动负债比率每股净资产净利润增长率总资产增长率111.090.210.0596.9870.53 1.86-44.0481.99211.960.590.7451.7890.73 4.957.0216.11300.030.03181.99100-2.98103.3321.18411.580.130.1746.0792.18 1.14 6.55-56.325-6.19-0.090.0343.382.24 1.52-1713.5-3.366100.470.4868.486 4.7-11.560.85710.490.110.3582.9899.87 1.02100.2330.32811.12-1.690.12132.14100-0.66-4454.39-62.759 3.410.040.267.8698.51 1.25-11.25-11.4310 1.160.010.5443.7100 1.03-87.18-7.411130.220.160.487.3694.880.53729.41-9.97128.190.220.3830.31100 2.73-12.31-2.771395.79-5.20.5252.3499.34-5.42-9816.52-46.821416.550.350.9372.3184.05 2.14115.95123.4115-24.18-1.160.7956.2697.8 4.81-533.89-27.74一、实验原理:1.系统聚类的基本思想是:首先,每个样品(或变量)先聚成一类,然后,选择距离公式计算类与类之间的距离,把距离相近的样品(或变量)先聚成类,距离相远的后聚成类,该过程一直进行下去,每个样品(或变量)总能聚到合适的类中,最后,所有的样品(或变量)聚成一类。


【精品】SPSS统计实验报告多元线性回归分析
本文旨在通过多元线性回归分析,深入研究X、Y、Z三个变量之间的关系,以探究这三个变量对结果的影响。
本实验中样本数量为100人,本文采用SPSS22.0计算软件进行多元线性回归分析,统计计算结果如下:
(一)检验变量X、Y、Z三个变量是否有关:
Sig.=.633。
结果显示,该值大于0.05,表明X、Y、Z三者之间没有显著统计关系;
(二)确定拟合模型:
以X、Y、Z三个变量回归拟合,得出模型为:y=1.746+0.660X+0.783Y+0.430Z。
(三)检验回归模型的有效性:
1. 回归系数的统计量检验
模型的R方为.668,该值表明,X、Y、Z三个自变量可以解释本回归模型的67.0%的变化量;
2.F检验
结果显示,f分数为20.670,Sig.=.000,结果显示,f分数小于阈值0.05,因此可以接受回归模型;
检验结果显示,当其他X、Y、Z三个自变量的条件不变的情况下,X、Y、Z三个自变量对Y的影响是有显著性的。
综上所述,本文使用SPSS22.0计算软件进行多元线性回归分析,探究X、Y、Z三个变量之间的关系。
结果显示,X、Y、Z三者之间没有显著统计关系;拟合模型为:
y=1.746+0.660X+0.783Y+0.430Z;最后,证实X、Y、Z三个自变量对Y的影响是有显著性的。

《统计实习》SPSS实验报告实验报告二实验项目:描述性统计分析实验目的:1、掌握数据集中趋势和离中趋势的分析方法;2、熟练掌握各个分析过程的基本步骤以及彼此之间的联系和区别。
实验内容及步骤一、数据输入案例:对6名男生和6名女生的肺活量的统计,数据如下:1.打开SPSS软件,进行数据输入:通过打开数据的方式对XLS的数据进行输入其变量视图为:二、探索分析进行探索分析得出如下输出结果:浏览由上表可以看出,6例均为有效值,没有记录缺失值得情况。
由上表可以看出,男女之间肺活量的差异,男生明显优于女生,范围更广,偏度大。
男男 Stem-and-Leaf PlotFrequency Stem & Leaf2.00 1 . 342.00 1 . 892.00 2 . 02Stem width: 1000Each leaf: 1 case(s)女女 Stem-and-Leaf PlotFrequency Stem & Leaf2.00 1 . 233.00 1 . 568 1.00 2 . 0Stem width: 1000Each leaf: 1 case(s)三、频率分析进行频率分析得出如下输出结果:由上图可知,分析变量名:肺活量。
可见样本量N为6例,缺失值0例, 1500以下的33%,1500-2000男生33%女生50%,2000以上女生16.7%,男生33%。
四、描述分析进行描述分析得出如下输出结果:由上图可知,分析变量名:工资,可见样本量N为6例,极小值为男1342女1213,极大值为男2200女2077,说明12人中肺活量最少的为女生是1213,最多的为男生有2200,均值为1810.50/1621.33,.标准差为327.735/325.408,离散程度不算大。
五、交叉分析实验报告三实验项目:均值比较实验目的:.学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验。
实验内容及步骤(一)描述统计案例:某医疗机构为研究某种减肥药的疗效,对15位肥胖者进行为期半年的观察测试,测试指标为使用该药之前和之后的体重。

统计学spss实验报告《统计学SPSS实验报告》在统计学领域,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,它能够帮助研究人员对数据进行分析和处理。
本实验报告将介绍使用SPSS进行统计分析的过程和结果。
实验目的:本实验旨在使用SPSS软件对一组数据进行统计分析,包括描述统计、相关分析和回归分析,以验证数据的相关性和预测能力。
实验步骤:1. 数据导入:首先将实验所需的数据导入SPSS软件中,确保数据格式正确。
2. 描述统计:对数据进行描述统计分析,包括均值、标准差、最大值、最小值等。
3. 相关分析:通过SPSS进行相关分析,探究变量之间的相关性。
4. 回归分析:进行回归分析,验证变量之间的预测能力。
实验结果:1. 描述统计结果显示,样本的平均值为X,标准差为X,最大值为X,最小值为X。
2. 相关分析结果表明,变量A与变量B之间存在显著的正相关关系(r=0.7,p<0.05)。
3. 回归分析结果显示,变量A对变量B的预测能力较高(R²=0.5,p<0.05)。
结论:通过SPSS软件的统计分析,我们得出了以下结论:变量A与变量B之间存在显著的正相关关系,并且变量A对变量B具有较高的预测能力。
这些结果为我们提供了对数据的深入理解和有效的预测能力。
总结:SPSS软件作为一种强大的统计分析工具,能够帮助研究人员对数据进行全面的统计分析。
通过本实验,我们深入了解了SPSS软件的使用方法和统计分析过程,为今后的研究工作提供了重要的参考和指导。
通过本次实验报告,我们对SPSS软件的统计分析能力有了更深入的了解,也为我们今后的科研工作提供了重要的参考和指导。
希望本实验报告能够对读者有所启发和帮助。

多元统计分析实验报告(精选多篇)第一篇:多元统计分析实验报告多元统计分析得实验报告院系:数学系班级:13级 B 班姓名:陈翔学号:20131611233 实验目得:比较三大行业得优劣性实验过程有如下得内容:(1)正态性检验;(2)主体间因子,多变量检验a;(3)主体间效应得检验;(4)对比结果(K 矩阵);(5)多变量检验结果;(6)单变量检验结果;(7)协方差矩阵等同性得Box 检验a,误差方差等同性得Levene 检验 a;(8)估计;(9)成对比较,多变量检验;(10)单变量检验。
实验结果:综上所述,我们对三个行业得运营能力进行了具体得比较分析,所得数据表明,从总体来瞧,信息技术业要稍好于电力、煤气及水得生产与供应业以及房地产业。
1。
正态性检验Kolmogorov-SmirnovaShapir o—Wilk 统计量 df Sig.统计量df Sig、净资产收益率。
113 35、200*。
978 35。
677 总资产报酬率。
121 35、200*。
964 35、298 资产负债率。
086 35。
200*.962 35、265 总资产周转率.180 35、006。
864 35。
000流动资产周转率、164 35、018.88535、002 已获利息倍数、28135.000。
55135、000 销售增长率.103 35、200*。
949 35、104 资本积累率。
251 35。
000、655 35。
000 *。
这就是真实显著水平得下限。
a。
Lilliefors显著水平修正此表给出了对每一个变量进行正态性检验得结果,因为该例中样本中n=35<2000,所以此处选用 Shapiro—W ilk 统计量。
由 Sig。
值可以瞧到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面得分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成得向量遵从正态分布(尽管事实上并非如此)。
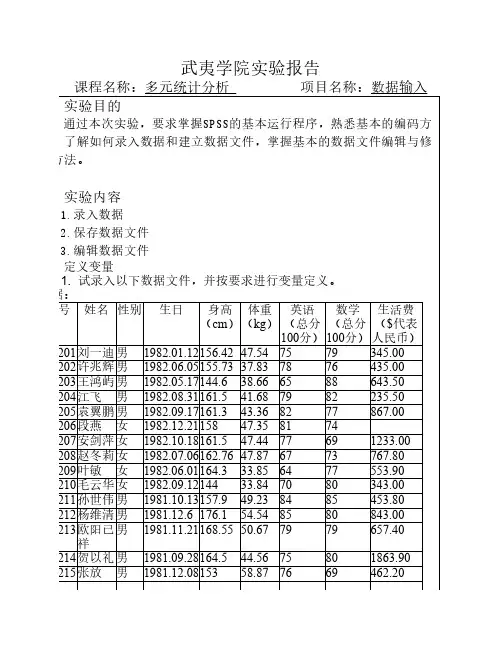
武夷学院实验报告00216陆晓蓝女1981.10.07164.744.148083476.80 200217吴挽君女1981.09.09160.553.347982200218李利女1981.09.1414736.467597452.80 200219韩琴女1981.10.15153.230.179075244.70 200220黄捷蕾女1981.12.02157.940.457180253.00要求:1)对性别(Sex)设值标签“男=0;女=1”。
2)正确设定变量类型。
其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。
3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
.试录入以下数据文件,保存为“数据1.sav”。
工资1男253020002女242519003女252820004男112515005男383530006男232918507男3103432008女283019509女1327160010女41538420011男3835300012男2532200013女1225155014女2930210015女31434350016女1326160017男41036400018女3934315019男2628180020男2228180021女2328185022男21030190023男32050340024男31645330025男42548480026男41034450027女2529200028女31538320029女1125150030男363531003、实验步骤1.开机2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS3.认识SPSS数据编辑窗4.按要求录入数据5.联系基本的数据修改编辑方法6.保存数据文件7.关闭SPSS,关机。
4、实验结果1.将数据输入EXCEL中,由SPASS将数据导入得到如图:对性别(Sex)设值标签“男=0;女=1”。
《多元统计分析分析》实验报告2012 年月日学院经贸学院姓名学号实验实验成绩名称一、实验目的(一)利用SPSS对主成分回归进行计算机实现.(二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释.二、实验内容以教材例题7.2为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用三、实验步骤(以文字列出软件操作过程并附上操作截图)1、数据文件的输入或建立:(文件名以学号或姓名命名)将表7.2数据输入spss:点击“文件”下“新建”——“数据”见图1:图1点击左下角“变量视图”首先定义变量名称及类型:见图2:图2:然后点击“数据视图”进行数据输入(图3):图3完成数据输入2、具体操作分析过程:(1)首先做因变量Y与自变量X1-X3的普通线性回归:在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4):图4将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5):然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“D.W”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。
选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9)其他选项按软件默认。
最后点击“确定”,运行线性回归,输出相关结果(见表1-3)图5 图6图7图8图9回归分析输出结果:的协差阵也就是相关阵进行分解做因子分析或主成分分析),如果不需要对变量做标准化处理就选“协方差矩阵”;“输出”中的两项都选,要求输出没有旋转的因子解(主成分分析必选项)和碎石图(用图形决定提取的主成分或因子的个数);“抽取“下,默认的是基于特征值(大于1表示提取的因子或主成分至少代表1个单位标准差的变量信息,因为标准化后的变量方差为1,因子或者主成分作为提取的综合变量应该至少代表1个变量的信息),也可以自选提取的因子个数(即第二项),本例中做主成分回归,选择提取全部可能的3个主成分,所以自选个数填3。
---------------------------------------------------------------最新资料推荐------------------------------------------------------多元统计分析实验报告实验一实验名称时间 2014-12-31 地点 S3-204对应分析一、实验目的及要求对应分析是你也降维的思想以达到减化数据结构的目的,凤的研究广泛用于定义属性变量构成的列联表利用对应分析方法分析问卷中教育程度与网上购物支付方式之间的相互关系。
二、实验环境 SPSS 19.0window 7 系统三、实验内容及实验步骤(实践内容、设计思想与实现步骤)实验题目:通过分析问卷数据,绘制如下的教育程度与网上购物支付方式的交叉表,运用对应分析方法研究教育程度与网上购物所选择的支付方式之间的相关性,及揭示不同人群网上购物的特征等问题。
设计思想:实现步骤:2 原假设:1 : 2 > [( ? 1)( ? 1)]1.在变量视窗中录入 3 个变量,用 edu 表示【教育程度】,用 fangshi 表示【在网上购物时采用什么样的支付方式】,用 pinshu 表示【频数】;如图所示:1/ 162.先对数据进行预处理。
执行【数据】→【加权个案】命令,弹出【加权个案】对话框。
选中【加权个案】按钮,把【频数】放入【频率变量】框中,点击【确定】按钮完成。
3.打开主窗口,选择菜单栏中的【分析】→【降维】→【对应分析】命令,弹出【对应分析】对话框。
4.将【教育程度】导入【行】,将【在网上购物时采用什么样的支付方式】导入【列】。
5. 单击【定义范围(D)】,打开【对应分析:定义行范围】对话框;定义行变量分类全距最小值为 1,最大值为 4,单击【更新】;点击【继续】,返回【对应分析】对话框;同方法打开【对应分析:定义列范围】对话框;定义列变量全距最小值为 1,最大值为 5,单击【更新】;6. 单击【统计量】打开【对应分析:统计量】对话框;选择【行轮廓表】,【列轮廓表】;单击【继续】,返回【对应分析】对话框,7.选择【绘制】→【对应分析:图】对话框,选择【散点图】中的【行点】、【列点】选择【线图】中的【已转换的行类别】、【已转换的列类别】,单击【继续】,返回【对应分析】对话框。
华东理工大学2008—2009 学年第一学期《应用统计学》实验报告1班级学号姓名开课学院任课教师成绩实验报告:一、安装步骤及要点:安装时要留有一定的磁盘空间,开始安装时双击安装程序,选择软件安装的位置,下一步,选择要安装的软件,以及是否安装推荐的软件,最后输入软件注册码,提示重启电脑完成配置,重启,完成安装,可以使用。
二、1.观察量排序(Sort Cases)在数据(Data)菜单选择排序个案(sort case),按照近期收入(current salary)分类排序。
结果如下图:2.变量排序(Rake Cases)在转换(Transform)菜单选择个案等级排序(rake cases), 按照起始收入(salary begin)对员工号码(id)进行排序。
结果如下图:3.拆分数据文件(Split Files)在数据(Data)菜单选择拆分文件(split file),选择“按组织输出”(compare by group)选项卡。
将教育水平(educational level)和性别(gender)放入分组方式(groups based on)选项框内。
结果如下图:4. 分类汇总(Aggregate)在数据(Data ) 菜单选择汇总(aggregate ),选择变量为性别(gender ),即将gender 放入分组变量(break variables )框中,将salary 和prevexp 放入变量摘要,根据gender 对salary 求和以及对prevexp.求平均。
如下图:5.选择观测量(Select Cases)在数据(Data )菜单选择个案(select cases )选项。
选中后,会弹出对话框,有选择变量的依据,如选择满足salary>=40000条件的个案,并导出到salary1新数据集,如图:。
. . .数学与计算科学学院实验报告实验项目名称相应与典型相关分析所属课程名称多元统计分析实验实验类型验证型实验日期2016年6月13日星期一班级学号姓名成绩因素B 具有对等性。
通过变换。
得c '=ΣZ Z ,r '=ΣZZ 。
(3)对因素B 进行因子分析。
计算出c '=ΣZ Z 的特征向量 及其相应的特征向量计算出因素B 的因子)(4)对因素A 进行因子分析。
计算出r '=ΣZZ 的特征向量 及其相应的特征向量计算出因素A 的因子(5)选取因素B 的第一、第二公因子 选取因素A 的第一、第二公因子将B 因素的c 个水平,,A 因素的r 个水平同时反应到相同坐标轴的因子平面上上(6)根据因素A 和因素B 各个水平在平面图上的分布,描述两因素及各个水平之间的相关关系。
1.3 在进行相应分析时,应注意的问题要注意通过独立性检验判定是否有必要进行相应分析。
因此在进行相应分析前应做独立性检验。
独立性检验中,0H :因素A 和因素B 是独立的;1H :因素A 和因素B 不独立 由上面的假设所构造的统计量为2211ˆ[()]ˆ()rcij ij i j ijk E k E k χ==-=∑∑211()r c ij i j k z ===∑∑ 其中....(/)/ij ij i j i j z k k k k k k =-,拒绝区域为221[(1)(1)]r c αχχ->--()(1)()(1)i i P Pa X '++a X ()(2)()(2)i i q qb X '++b X(2))1=X 的条件下,使得()(2)()(2)i i q qb X '+b X(2))1=X 的条件下,使得(1)、(2)X 的第一对典型相关变量。
1,2,,)r()p⎦()p ⎥⎦pU⎥⎥⎦p V⎥⎥⎦*(1)*== A X V Bˆˆr() ++b bz【实验过程】(实验步骤、记录、数据、分析)一.问题1的求解步骤:1. 将数据输入在SPSS后,在窗口中选择数据→加权个案,调出加权个案主界面,并将变量人数移入加权个案中的频率变量框中。
多元统计分析实验报告表2-2 对应分析数据(老龄化数据)三、实验过程在spss16.0软件中,对表2-2数据做对应分析。
首先应对个案进行加权操作。
选择【Date】—【Weight Cases】,出现表3对话框。
选择frequency作为加权,如图3-1所示。
图3-1 加权个案对个案加权后,开始做对应分析。
选择【Analyze】—【Date Reduction】—【Corespondence Analysis】,会出现图3-2对话画框。
图3-2 对应分析对话框接下来对行变量和列变量进行设置。
将selfassess(自评健康状况)选入Row,作为行变量,并选择【Define Range】,填写范围后点击【Update】—【Continue】,如图3-3所示;按同样的步骤,将independence(生活自理能力)选入Column(列变量),并设置列变量,如图3-4所示;最终设置结果如图3-5所示。
图3-3 行变量设置图3-4 列变量设置图3-5 对应分析设置结果点击【OK】,便可得到对应分析结果。
四、实验过程表4-1为对应分析的版本信息。
图中显示为1.1版本。
表4-1 对应分析版本信息表4-2是列联表,列示了在各个水平下的人数。
表4-2 列联表表4-3为对应分析总述表。
表中显示了奇异值(Singular Value),第一个维度的奇异值为0.253,第二个维度的奇异值为0.125;惯量(Inertia)为特征根,就是奇异值的平方;Chi Square 值为212.593,是总样本数除以总的Inertia 觉原假设,认为两个随机变量不是相互独立的,本例中就是自评健康状况和生活自理能力不是相互独立的;贡献率(Accounted for)显示,第一个维度解释了总变异的80.4%,第二个维度解释了19.6%,两个维度解释了所有的变异;接下来依次为累计贡献率(Cumulative)、奇异值的方差(Standard Deviation)、奇异值的相关系数(Correlation)。
实验课程名称: __多元统计分析--判别分析___准则判别归类,则可写成:⎪⎩⎪⎨⎧=>∈<∈),(),( ,),(),(,),(),(,21212211G X D G X D G X D G X D G X G X D G X D G X 当待判当当题目:表11.5的数据包含三种鸢尾的X2=萼片宽度与X4=花瓣的宽度的观测值。
对每种鸢尾有n1=n2=n3=50个观测值。
部分数据:第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象记录,实验过程发现的问题等)散点图:图形→旧对话框→散点图,打开简单散点图子对话框;将想X2选入X轴变量,X4选入Y轴变量,将总体选入设置标记框中,点击确定。
判别分析:步骤:1、选择分析→分类→判别,打开判别分析子对话框。
2、选择变量“总体”,单击→,将其加入到分组变量栏中。
3、打开定义范围子对话框,最小值输入1,最大值输入3。
4、将变量“X2萼片宽度”、“X4花瓣的宽度”选入自变量栏中。
选择“一起输入自变量”的方法。
5、打开统计变量子对话框,选择均值、单变量ANOVA、Box’M、未标准化、组内协方差、分组协方差及总体协方差,单击继续。
6、打开分类子对话框,选择不考虑该个案时的分类,其余为默认值。
7、打开保存,选择所有的变量。
相关系数矩阵a总体萼片宽度X2 花瓣宽度X4合计萼片宽度X2 .190 -.122花瓣宽度X4 -.122 .581对数行列式总体秩对数行列式1 2 -6.4962 2 -6.1413 2 -5.189汇聚的组内 2 -5.583检验结果箱的M 52.832F 近似。
8.632df1 6df2 538562.769Sig. .000Wilks 的Lambda函数检验Wilks 的Lambda 卡方df Sig.1 到2 .038 477.868 4 .0002 .809 31.075 1 .000典型判别式函数系数函数1 2萼片宽度X2 -1.987 2.680花瓣宽度X4 5.477 .817(常量) -.494 -9.174非标准化系数组质心处的函数总体函数1 21 -5.958 .2152 1.265 -.6673 4.693 .452分类结果b,c总体预测组成员1 2 3 合计初始计数 1 50 0 0 502 0 49 1 503 04 46 50% 1 100.0 .0 .0 100.02 .0 98.0 2.0 100.03 .0 8.0 92.0 100.0 交叉验证a计数 1 50 0 0 502 0 48 2 503 04 46 50% 1 100.0 .0 .0 100.02 .0 96.0 4.0 100.03 .0 8.0 92.0 100.0。
华东理工大学2016–2017学年第二学期
《多元统计学》实验报告
实验名
称实验1数据整理与描述统计分析
实验报告正文:
实验 1.1数据整理
(一)对“employee data.sav ”进行数据整理
1.观察量排序 ( based on current salary)
2.变量值排序(based on current salary : rsalary)
3.计算新的变量(incremental salary=current salary - beginning salary)
4.拆分数据文件(based on gender)
结论:There are 215 female employees and 259 male employees.
5.分类汇总 (break variable: gender ; function: mean )
结论:The average current salary of female is 26031.92.
The average current salary of male is 41441.78.
(二)分别给出三种工作类别的薪水的描述统计量
实验2.2描述统计分析
1)样本均值矩阵
结论:总共分析六组变量,每组含有十个样本。
每股收益(X1)的均值为-0.0912;净资产收益率(X2)的均值为-0.0378;总资产报酬率(X3)的均值为-
0.0294;销售净利率(X4)的均值为-0.4284;主营业务增长率(X5)的均值为0.6334;净利润增长率
(X6)的均值为0.7797.
2)协方差阵
结论:矩阵共六行六列,显示了每股收益
(X1)、净资产收益率(X2)、总资产报酬
率(X3)、销售净利率(X4)、主营业务增
长率(X5)和净利润增长率(X6)的协方
差。
3)相关系数
结论:矩阵共六行六列,显示了每股收益(X1)、净资产收益率(X2)、总资产报酬率(X3)、销售净利率(X4)、主营业务增长率(X5)和净利润增长率(X6)之间的相关系数。
每格中三行分别显示了相关系数、显著性检验与样本个数。
4)矩阵散点图
结论:6*6的表格显示了每股收益(X1)、净资产收益率(X2)、总资产报酬率(X3)、销售净利率(X4)、主营业务增长率(X5)和净利润增长率(X6)之间的关系。
5)多维箱线图
结论:X1, X2中各出现一个异常值。