袁卫《统计学》(第3版)【课后习题】详解 第1章~第3章【圣才出品】
- 格式:pdf
- 大小:2.13 MB
- 文档页数:52



第二部分课后习题第1章数据与统计学1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学,其目的是探索数据内在的数量规律性。
统计学是由收集、整理、显示和分析统计数据的方法组成的,这些方法来源于对统计数据的研究,目的也在于对统计数据的研究。
离开了统计数据,统计方法乃至统计学就失去了其存在的意义。
2.试举出日常生活或工作中统计数据及其规律性的例子。
答:(1)对人类性别比例的调查,新生婴儿男女性别比为105:100,如果没有人为的干扰,其规律是婴幼儿时男性略多于女性,中青年时男女人数大致相同,老年时女性又略多于男性。
(2)施肥量与粮食产量之间的数量关系的调查研究,其规律性为某种粮食作物的产量会随某种施肥量的增加而增加。
当开始增加施肥量时,产量增加较快。
以后增加同样的施肥量,粮食产量的增加量逐渐减少。
当施肥量增加到一定数值量,产量不再增加。
这时如果再增加肥料,产量反而会减少。
(3)商品广告费用与销售额的关系的调查,其规律性为,随着广告费用的增加,商品的知名度和销售额会相应增加。
3.联系实际简要说明统计数据的来源。
答:统计数据的来源大致分为两种,其中来源于直接组织的调查、观察和科学试验的数据,称为第一手数据或直接的数据;来源于已有的数据,称为第二手数据或间接的数据。
4.直接获取统计数据的渠道主要有哪些?答:(1)对于社会经济管理和决策而言,主要是通过统计调查的方式获取数据,如客户满意度调查、电视收视率调查、家庭收支情况调查、居民闲暇时间利用调查等。
(2)在自然科学和工程的研究领域,通常是通过科学实验的方法获得研究的统计数据。
5.简要说明抽样误差和非抽样误差。
答:(1)抽样误差是利用样本推断总体时产生的误差;抽样误差对任何一个随机样本来讲都是不可避免的。
但它又是可以计量的,并且是可以控制的。
在坚持随机原则的条件下,一般来讲,样本量越大,抽样误差就越小。
(2)非抽样误差是由于调查过程中各有关环节工作失误造成的。

统计学第三版答案第一章1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.简要说明统计数据的来源答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
3.简要说明抽样误差和非抽样误差答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
4.答:(1)有两个总体:A品牌所有产品、B品牌所有产品(2)变量:口味(如可用10分制表示)(3)匹配样本:从两品牌产品中各抽取1000瓶,由1000名消费者分别打分,形成匹配样本。
(4)从匹配样本的观察值中推断两品牌口味的相对好坏。
第二章、统计数据的描述思考题1描述次数分配表的编制过程答:分二个步骤:(1)按照统计研究的目的,将数据按分组标志进行分组。
按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。
按数量标志进行分组,可分为单项式分组与组距式分组单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。
统计分组应遵循“不重不漏”原则(2)将数据分配到各个组,统计各组的次数,编制次数分配表。
2.解释洛伦兹曲线及其用途答:洛伦兹曲线是20世纪初美国经济学家、统计学家洛伦兹根据意大利经济学家帕累托提出的收入分配公式绘制成的描述收入和财富分配性质的曲线。
洛伦兹曲线可以观察、分析国家和地区收入分配的平均程度。

第一章1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.简要说明统计数据的来源答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
3.简要说明抽样误差和非抽样误差答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
4.答:(1)有两个总体:A品牌所有产品、B品牌所有产品(2)变量:口味(如可用10分制表示)(3)匹配样本:从两品牌产品中各抽取1000瓶,由1000名消费者分别打分,形成匹配样本。
(4)从匹配样本的观察值中推断两品牌口味的相对好坏。
第二章、统计数据的描述思考题1描述次数分配表的编制过程答:分二个步骤:(1)按照统计研究的目的,将数据按分组标志进行分组。
按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。
按数量标志进行分组,可分为单项式分组与组距式分组单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。
统计分组应遵循“不重不漏”原则(2)将数据分配到各个组,统计各组的次数,编制次数分配表。
2.解释洛伦兹曲线及其用途答:洛伦兹曲线是20世纪初美国经济学家、统计学家洛伦兹根据意大利经济学家帕累托提出的收入分配公式绘制成的描述收入和财富分配性质的曲线。
洛伦兹曲线可以观察、分析国家和地区收入分配的平均程度。
3. 一组数据的分布特征可以从哪几个方面进行测度?答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。

统计学第一章1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.简要说明统计数据的来源答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
3.简要说明抽样误差和非抽样误差答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
4.答:(1)有两个总体:A品牌所有产品、B品牌所有产品(2)变量:口味(如可用10分制表示)(3)匹配样本:从两品牌产品中各抽取1000瓶,由1000名消费者分别打分,形成匹配样本。
(4)从匹配样本的观察值中推断两品牌口味的相对好坏。
第二章、统计数据的描述思考题1描述次数分配表的编制过程答:分二个步骤:(1)按照统计研究的目的,将数据按分组标志进行分组。
按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。
按数量标志进行分组,可分为单项式分组与组距式分组单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。
统计分组应遵循“不重不漏”原则(2)将数据分配到各个组,统计各组的次数,编制次数分配表。
2.解释洛伦兹曲线及其用途答:洛伦兹曲线是20世纪初美国经济学家、统计学家洛伦兹根据意大利经济学家帕累托提出的收入分配公式绘制成的描述收入和财富分配性质的曲线。
洛伦兹曲线可以观察、分析国家和地区收入分配的平均程度。
3. 一组数据的分布特征可以从哪几个方面进行测度?答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。

第三部分章节题库第1章数据与统计学一、单项选择题1.被马克思誉为“政治经济学之父,在某种程度上也是统计学的创始人”的是()。
A.布莱斯·帕斯卡B.威廉·配第C.费马D.约翰·格朗特【答案】B【解析】布莱斯·帕斯卡和费马是古典概率论的奠基人;约翰·格朗特是人口统计的创始人。
2.统计学的两大分类是()。
A.统计资料的收集和分析B.理论统计和运用统计C.统计预测和决策D.描述统计和推断统计【答案】D3.下列不属于描述统计问题的是()。
A.根据样本信息对总体进行的推断B.了解数据分布的特征C.分析感兴趣的总体特征D.利用图、表或其他数据汇总工具分析数据【答案】A【解析】描述统计研究的是数据收集、处理、汇总、图表描述、概括与分析等统计方法;推断统计是研究如何利用样本数据来推断总体特征的统计方法。
4.下列叙述中,采用推断统计方法的是()。
A.用饼图描述某企业职工的学历构成B.反映大学生统计学成绩的条形图C.一个城市在1月份的平均汽油价格D.从一个果园中采摘36个橘子,利用这36个橘子的平均重量估计果园中橘子的平均重量【答案】D【解析】推断统计是根据样本信息对总体进行估计、假设检验、预测或其他推断的统计方法。
由题可知,根据36个橘子的平均重量估计果园中橘子的平均重量属于推断统计方法。
5.如果一个样本因人故意操纵而出现偏差,这种误差属于()。
A.抽样误差B.非抽样误差C.设计误差D.实验误差【答案】B【解析】非抽样误差是由于调查过程中各有关环节工作失误造成的。
它包括调查方案中有关规定或解释不明确所导致的填报错误、抄录错误、汇总错误,不完整的抽样框导致的误差,人为干扰造成的误差,调查中由于被调查者不回答产生的误差等。
6.下列说法错误的是()。
A.抽样误差只存在于概率抽样中B.非抽样误差只存在于非概率抽样中C.无论是概率抽样还是非概率抽样都存在非抽样误差D.在全面调查中也存在非抽样误差【答案】B【解析】抽样误差是由于抽样的随机性引起的样本结果与总体真值之间的误差;非抽样误差是相对抽样误差而言的,是指除抽样误差之外的,由于其他原因引起的样本观察结果与总体真值之间的差异。
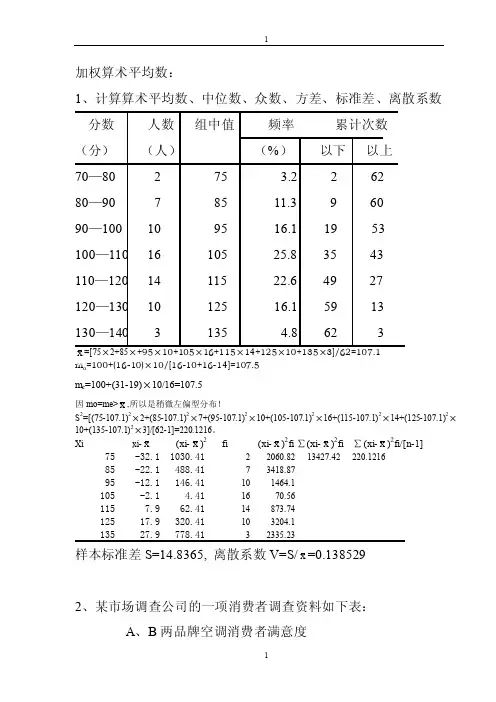

第1章绪论5.简要说明抽样误差和非抽样误差。
答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
b5E2RGbCAP6.一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为 4.536 kg。
要求:p1EanqFDPw(1>描述总体;(2>描述研究变量;(3>描述样本;(4>描述推断。
答:(1>总体:最近的一个集装箱内的全部油漆;(2>研究变量:装满的油漆罐的质量;(3>样本:最近的一个集装箱内的50罐油漆;(4>推断:50罐油漆的质量应为4.536×50=226.8kg。
7.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝实验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝实验(即在品尝实验中,两个品牌不做外观标记>,请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:DXDiTa9E3d(1>描述总体;(2>描述研究变量;(3>描述样本;(4>描述推断。
答:(1>总体:市场上的“可口可乐”与“百事可乐”(2>研究变量:更好口味的品牌名称;(3>样本:1000名消费者品尝的两个品牌(4>推断:两个品牌中哪个口味更好。
第2章统计数据的描述思考题4. 一组数据的分布特征可以从哪几个方面进行测度?答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。

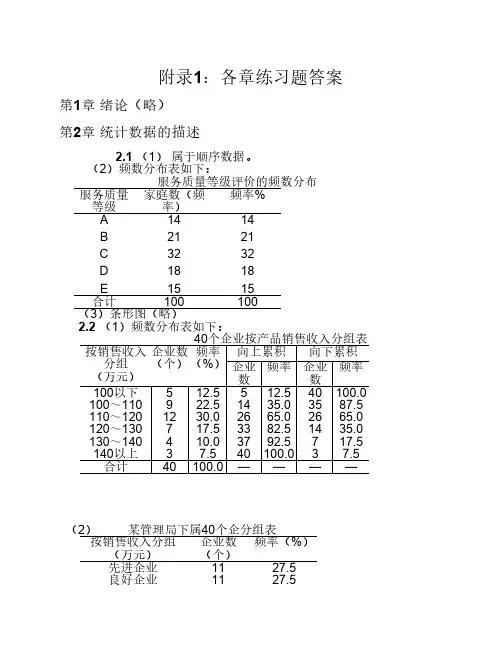
统计学(第三、四版)作者:袁卫庞皓曾五一贾俊平主编第2章统计数据的描述练习:2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
2.2某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元):1521241291161001039295127104105119114115871031181421351251171081051101071371201361171089788123115119138112146113126(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
2.3某百货公司连续40天的商品销售额如下(单位:万元):41252947383430384340463645373736454333443528463430374426384442363737493942323635根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
2.4为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下:700716728719685709691684705718706715712722691708690692707701708729694681695685706661735665668710693697674658698666696698706692691747699682698700710722694690736689696651673749708727688689683685702741698713676702701671718707683717733712683692693697664681721720677679695691713699725726704729703696717688(1)利用计算机对上面的数据进行排序;(2)以组距为10进行等距分组,整理成频数分布表,并绘制直方图;(3)绘制茎叶图,并与直方图作比较。
统计学课后习题答案(袁卫、庞皓、曾五一、贾俊平)第三版第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色.假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3)绘制一张条形图,反映评价等级的分布。
第9章统计指数思考题1.统计指数与数学上的指数函数有何不同?广义指数与狭义指数有何差异?答:与数学上的“指数函数”不同,统计学中的指数是一种对比性的分析指标,可以反映不同时间(时期、时点)或不同空间(国家、地区、部门、企业等)现象水平的数量对比关系,以及现象的实际水平与计划(规划或目标)水平的数量对比关系。
在经济分析的各个领域,指数工具都获得了广泛应用,因此,统计指数常常也被称为“经济指数”。
指数有广义和狭义之分。
广义地讲,任何两个数值对比形成的相对数都可以称为指数;狭义地讲,指数是用于测定多个项目在不同场合下综合变动的一种相对数。
从指数理论和方法上看,指数所研究的主要是狭义的指数。
2.与一般相对数比较,总指数所研究的现象总体有何特点?答:一般相对数是考察总体中个别现象或个别项目的数量对比关系的指数;总指数是考察整个总体现象的数量对比关系的指数。
它与一般相对数的区别不仅在于考察范围不同,还在于考察方法不同。
总指数不能简单地沿用一般相对数的计算分析方法,也不一定能够具备一般相对数的某些直观分析性质。
3.有人认为,不同商品的销售量是不同度量的现象,因为它们的计量单位可以不同;而不同商品的价格则是同度量的现象,因为它们的计量单位相同,都是货币单位。
这种看法是否正确?为什么?答:这种看法是不完全正确的。
在统计学中,一般把相乘以后使得不能直接相加的指标过渡到可以直接相加的指标的那个因素,叫做同度量因素。
同度量因素作为对比指标的媒介转化因素必须是一个水平相对固定的因素(即在同一综合指数的分子和分母中具有相同的水平),否则,它就不是同度量因素,而成为另一个对比指标了。
不同商品的销售量是不同度量的现象,不仅因为它们的计量单位可以不同,而且直接加总的结果也没有实际经济意义。
而不同商品的价格由于直接加总的结果没有实际意义,所以它也是不同度量的现象。
4.总指数有哪两种基本编制方式?它们各自有何特点?答:总指数的编制有综合指数的编制和平均指数的编制两种方式。
第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。