常见水文模型参数率定概要
- 格式:ppt
- 大小:609.50 KB
- 文档页数:31
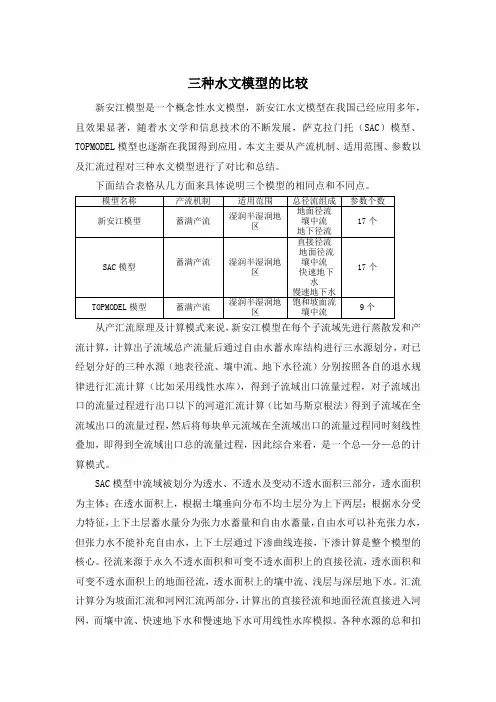
三种水文模型的比较新安江模型是一个概念性水文模型,新安江水文模型在我国已经应用多年,且效果显著,随着水文学和信息技术的不断发展,萨克拉门托(SAC)模型、TOPMODEL模型也逐渐在我国得到应用。
本文主要从产流机制、适用范围、参数以及汇流过程对三种水文模型进行了对比和总结。
下面结合表格从几方面来具体说明三个模型的相同点和不同点。
从产汇流原理及计算模式来说,新安江模型在每个子流域先进行蒸散发和产流计算,计算出子流域总产流量后通过自由水蓄水库结构进行三水源划分,对已经划分好的三种水源(地表径流、壤中流、地下水径流)分别按照各自的退水规律进行汇流计算(比如采用线性水库),得到子流域出口流量过程,对子流域出口的流量过程进行出口以下的河道汇流计算(比如马斯京根法)得到子流域在全流域出口的流量过程,然后将每块单元流域在全流域出口的流量过程同时刻线性叠加,即得到全流域出口总的流量过程,因此综合来看,是一个总—分—总的计算模式。
SAC模型中流域被划分为透水、不透水及变动不透水面积三部分,透水面积为主体;在透水面积上,根据土壤垂向分布不均土层分为上下两层;根据水分受力特征,上下土层蓄水量分为张力水蓄量和自由水蓄量,自由水可以补充张力水,但张力水不能补充自由水,上下土层通过下渗曲线连接,下渗计算是整个模型的核心。
径流来源于永久不透水面积和可变不透水面积上的直接径流,透水面积和可变不透水面积上的地面径流,透水面积上的壤中流、浅层与深层地下水。
汇流计算分为坡面汇流和河网汇流两部分,计算出的直接径流和地面径流直接进入河网,而壤中流、快速地下水和慢速地下水可用线性水库模拟。
各种水源的总和扣除时段内的水面蒸发4E ,即得河网总入流。
河网汇流一般采用无因次单位线。
总的来看是一个分—总的过程。
新安江模型在每个子流域先进行蒸散发和产流计算,计算出子流域总产流量后通过自由水蓄水库结构进行三水源划分,对已经划分好的三种水源(地表径流、壤中流、地下水径流)分别按照各自的退水规律进行汇流计算(比如采用线性水库),得到子流域出口流量过程,对子流域出口的流量过程进行出口以下的河道汇流计算(比如马斯京根法)得到子流域在全流域出口的流量过程,然后将每块单元流域在全流域出口的流量过程同时刻线性叠加,即得到全流域出口总的流量过程,因此综合来看,是一个总—分—总的计算模式。


水文模型率定研究水文模型是一种数学模型,用于描述水文过程,包括降雨、蒸发、径流等。
水文模型的建立和率定是水文学研究的重要内容之一。
本文将介绍水文模型的基本概念和建立方法,并以一个实例来说明水文模型的率定过程。
一、水文模型的基本概念水文模型是一种描述水文过程的数学模型,它可以用来预测水文变量的变化,如降雨、蒸发、径流等。
水文模型通常包括两个部分:输入和输出。
输入是指模型所需的数据,如降雨量、蒸发量、土地利用类型等;输出是指模型预测的结果,如径流量、地下水位等。
水文模型可以分为两类:分布式模型和集中式模型。
分布式模型是指将流域划分为若干个小区域,每个小区域都有自己的输入和输出。
集中式模型是指将整个流域看作一个整体,只有一个输入和一个输出。
分布式模型通常比集中式模型更准确,但也更复杂。
水文模型的建立需要考虑多种因素,如流域的地形、土地利用类型、降雨量、蒸发量等。
建立水文模型的过程通常包括以下几个步骤:1. 收集数据:收集流域的地形、土地利用类型、降雨量、蒸发量等数据。
2. 建立模型:根据收集到的数据,建立数学模型,描述流域的水文过程。
3. 参数估计:根据实测数据,估计模型中的参数。
4. 模型率定:将模型预测的结果与实测数据进行比较,调整模型参数,使模型预测结果更加准确。
5. 模型验证:使用另外一组数据来验证模型的准确性。
二、水文模型的建立方法水文模型的建立方法有很多种,常用的方法包括统计模型、物理模型和组合模型。
1. 统计模型:统计模型是根据历史数据建立的模型,它通常基于统计学原理,如回归分析、时间序列分析等。
统计模型的优点是简单易用,但缺点是对数据的要求较高,需要有足够的历史数据支持。
2. 物理模型:物理模型是基于物理原理建立的模型,它通常包括流体力学、热力学等方面的知识。
物理模型的优点是准确性高,但缺点是建模过程较为复杂,需要大量的实验数据支持。
3. 组合模型:组合模型是将统计模型和物理模型结合起来建立的模型,它既考虑了历史数据的影响,又考虑了物理原理的影响。



四种⽔⽂模型的⽐较四种⽔⽂模型的⽐较摘要:⽔⽂模型是⽤数学的语⾔对现实⽔⽂过程进⾏模拟和预报,在进⾏⽔⽂规律的探讨和解决⽔⽂及⽣产实际问题中起着重要作⽤。
本⽂分别介绍了新安江模型、萨克拉门托(SAC)模型、SWAT模型以及TOPMODEL模型,并对这四种⽔⽂模型的蒸发计算、产流机制、汇流计算、适⽤流域、参数以及模型特点等不同⽅⾯进⾏了⽐较分析。
并结合对着4种模型之间的⽐较,作出了总结分析和展望。
关键词:新安江模型;SAC模型;SWA T模型;TOPMODEL模型;模型⽐较引⾔流域⽔⽂模型在进⾏⽔⽂规律研究和解决⽣产实际问题中起着重要的作⽤。
新安江模型是⼀个概念性⽔⽂模型,1973年由赵⼈俊教授领导的研究组在编制新安江预报⽅案时,汇集了当时在产汇流理论⽅⾯的成果,并结合⼤流域洪⽔预报的特点,设计出的我国第⼀个完整的流域⽔⽂模型,⾄今仍在我国湿润和半湿润地区的洪⽔预报中得到⼴泛应⽤;萨克拉门托⽔⽂模型,简称SAC模型,是R.C.伯纳什(Burnash)和R.L.费雷尔(Ferral)以及R.A.麦圭⼉(Mcguire)于20世纪60年代末⾄70年代初研制的,是⼀个连续模拟模型,模型研制完成时间相对较晚,其功能较为完善,兼有蓄满产流和超渗产流,⼴泛应⽤于美国⽔⽂预报中;SWAT模型是美国农业部农业研究中⼼研制开发的⽤于模拟预测⼟地利⽤及⼟地管理⽅式对流域⽔量、⽔质过程影响的分布式流域⽔⽂模型;TOPMODEL为基于地形的半分布式流域⽔⽂模型,于1979年由Beven和Kirkby提出,其主要特征是将数字⾼程模型(DEM)的⼴泛适⽤性与⽔⽂模型及地理信息系统(GIS)相结合,基于DEM数据推求地形指数,并以此来反映下垫⾯的空间变化对流域⽔⽂循环过程的影响,描述⽔流趋势。
本⽂对这四中⽔⽂模型从蒸发计算、产汇流计算、适⽤流域以及参数等⽅⾯进⾏分析⽐较,并得出结论。
1模型简介1.1新安江模型新安江模型是赵⼈俊等在对新安江⽔库做⼊库流量预报⼯作中,归纳成的⼀个完整的降⾬径流模型。

新安江模型参数率定方法新安江模型参数率定1. 参数的物理意义新安江(三水源) 模型的参数一般具有明确的物理意义,可以分为如下四类:1) 蒸散发参数: K、WUM、WLM、CK 为蒸散发能力折算系数,是指流域蒸散发能力与实测水面蒸发值之比。
此参数控制着总水量平衡,因此,对水量计算是十分重要的。
WUM 为上层蓄水容量,它包括植物截留量。
在植被与土壤比较发育的流域,约为20mm;在植被与土壤颇差的流域,约为5,6mm。
WLM 为下层蓄水容量。
可取60,90mm。
C 为深层蒸散发系数。
它决定于深根植物占流域面积的比数,同时也与WUM+WLM值有关,此值越大,深层蒸散发越困难。
一般经验,在江南湿润地区C值约为0.15,0.20左右,而在华北半湿润地区则在0.09,0.12左右。
2) 产流量参数: WM、B、IMPWM 为流域蓄水容量,是流域干湿程度的指标。
一般分为上层WUM、下层WLM和深层WDM,约为120,180mm。
B 为蓄水容量曲线的指数。
它反映流域上蓄水容量分布的不均匀性。
一般经验,流域越大,各种地质地形配置越多样,B值也越大。
在山丘区域,很小面积(几平方公里)的B值为0.1左右,中等面积(300平方公里以内)的B值为0.2,0.3左右,较大面积(数千平方公里)的B值为0.3,0.4左右。
IMP 为不透水面积占全流域面积之比,一般较小,取为0.01,0.05。
3) 水源划分参数: SM、EX、KSS、KGSM 为流域平均自由水蓄水容量,本参数受降雨资料时段均化的影响,当以日为计算时段长时,一般流域的SM值约为10,50mm,当所选取的计算时段长较小时,SM要增大,这个参数对地面径流的多少起着决定性作用,因此十分重要。
EX 为自由水蓄水容量曲线指数,它表示自由水容量分布不均匀性。
通常EX取值在1,1.5之间。
KSS 为自由水蓄水库对壤中流的出流系数,KG为自由水蓄水库对地下径流出流系数,这两个出流系数是并联的,其和代表着自由水出流的快慢。

SWMM模型作为一个城市雨洪管理模型已经被越来越广泛地使用,但是建立一个精度良好的模型并不容易,往往需要花费相当精力来进行参数率定工作。
参数率定或者说调参的前提条件是模型已经基本搭建好,降雨与管网这些基础数据具有一定的精度以及在此基础上的各种概化处理相对合理,否则的话调参就没有多少意义。
SWMM模型的参数很多且又是一个分布式的,所以调参是一件很复杂的事情,需要有一定经验才能完成好,盲目地调整不仅浪费时间,有时还浪费表情,因为不是每次调整都会出现预期的结果。
深入了解SWMM模型各个参数的含义和敏感性对率定工作还是相当有好处的,至少能够明确调整的方向。
一般来讲,对于径流系数或者产流量来讲,不透水率、流域的面积以及特征宽度还有坡度是影响最大的几个参数,其余参数的影响几乎可以忽略不计。
对于洪峰流量,一般来说影响最大的几个参数依次是流域面积,特征宽度,不透水率,透水区洼蓄量,不透水区曼宁系数,坡度。
当然,不同区域不同情形下,这个参数的排序会略有差别,但也不会有较大的出入。
至于每个参数的具体影响,这里就不详述了,如果知道模型计算原理的话是很容易推导出来的。
需要说明的是有人也许会说降雨量是对结果影响最大的一个参数,这话也没有错,但这里没有将降雨当作一个参数来分析。
有时会碰到这样一个问题,当我们把结果调得很接近现实或者说实测数据时,却发现有些参数已经被调得很离谱了,早就不满足其物理意义了或者说离实际差好远了,出现这种情况怎么办?我的观点是如果这样一套参数能把大部分场次暴雨洪水都模拟得很好,那么是可以接受的,毕竟我们关注的主要还是结果,不管白猫黑猫,抓到老鼠的就是好猫。
但是,如果这样一套参数只是能将某一两场洪水模拟好或者说只有一两场实测数据用来调参,然后调整成了这样,那最好还是不要采用了。
当然,这个问题还是要具体情形具体分析了,上述只是我个人的一些看法。
记得几年前,在一个学术会议上,一个外国佬说他们连降雨量都调。


城市水文模型的参数识别和预测研究随着城市化进程的加速,城市经济和人口的迅猛增长,城市水资源问题已成为城市可持续发展面临的重大难题。
为了保障城市正常用水,同时避免城市洪涝灾害的发生,水文模型的参数识别和预测研究变得越来越重要。
水文模型是指通过对水文流域的物理、化学、生态等要素进行数学描述和建模,对水动力、水文循环等过程进行模拟和预测的模型。
在城市水文模型中,参数识别和预测是建模过程中的关键环节,决定着模型的精度和可靠性。
城市水文模型参数识别的方法多种多样,常用的有经验公式法、统计分析法、试算法、模拟退火算法等。
其中,模拟退火算法是应用范围最广的一种参数识别方法,它通过模拟热力学中的退火过程,以一定的概率接受较差的解,最终找到全局最优解。
另外,城市水文模型中的参数预测也是一个关键环节,目的是根据历史数据和变化趋势,预测未来一段时间内的水文过程。
参数预测的方法包括基于物理模型的预测法、基于统计模型的预测法和基于人工智能的预测法等。
其中,基于统计模型的预测法常用的有ARIMA模型、BP神经网络模型等。
在城市水文模型参数识别和预测研究中,区域气候和地貌特征是不可忽视的因素。
北京市作为我国的首都,气候和地形条件非常复杂,城市水文模型的参数识别和预测研究也具有一定的特点。
例如,北京市的水质受到周边山区的土地利用和人类活动的影响比较大,城市水文模型的参数识别和预测研究需要更多注重山区、水源地对城市水资源的影响。
在城市水文模型参数识别和预测研究中,数据处理也是关键问题。
模型的精度和可靠性在很大程度上取决于数据的质量和数量。
在数据采集和处理过程中需要注意数据的真实性、完整性和准确性,同时还需要进行数据清洗和去噪处理,确保模型的精度和可靠性。
最后,城市水文模型参数识别和预测研究需要不断实践和探索,在研究过程中需要充分发挥自身的创新和改进能力,以推动城市水资源保障和可持续发展。
SWAT水文模型介绍1概述SWAT(Soil and Water Assessment Tool)模型是美国农业部(USDA)农业研究局(ARS)开发的基于流域尺度的一个长时段的分布式流域水文模型。
它主要基于SWRRB模型,并吸取了CREAMS、GLEAMS、EPIC和ROTO的主要特征。
SWAT具有很强的物理基础,能够利用GIS和RS提供的空间数据信息模拟地表水和地下水的水量和水质,用来协助水资源管理,即预测和评估流域内水、泥沙和农业化学品管理所产生的影响。
该模型主要用于长期预测,对单一洪水事件的演算能力不强,模型主要由8个部分组成:水文、气象、泥沙、土壤温度、作物生长、营养物、农业管理和杀虫剂。
SWAT模型拥有参数自动率定模块,其采用的是等在1992年提出的SCE-UA算法。
模型采用模块化编程,由各水文计算模块实现各水文过程模拟功能,其源代码公开,方便用户对模型的改进和维护。
2模型原理SWAT模型在进行模拟时,首先根据DEM把流域划分为一定数目的子流域,子流域划分的大小可以根据定义形成河流所需要的最小集水区面积来调整,还可以通过增减子流域出口数量进行进一步调整。
然后在每一个子流域内再划分为水文响应单元HRU。
HRU 是同一个子流域内有着相同土地利用类型和土壤类型的区域。
每一个水文响应单元内的水平衡是基于降水、地表径流、蒸散发、壤中流、渗透、地下水回流和河道运移损失来计算的。
地表径流估算一般采用SCS径流曲线法。
渗透模块采用存储演算方法,并结合裂隙流模型来预测通过每一个土壤层的流量,一旦水渗透到根区底层以下则成为地下水或产生回流。
在土壤剖面中壤中流的计算与渗透同时进行。
每一层土壤中的壤中流采用动力蓄水水库来模拟。
河道中流量演算采用变动存储系数法或马斯金根演算法。
模型中提供了三种估算潜在蒸散发量的计算方法—Hargreaves、Priestley-Taylor和Penman-Monteith。
每一个子流域内侵蚀和泥沙量的估算采用改进的USLE方程,河道内泥沙演算采用改进的Bagnold泥沙运移方程。