确定型时间序列预测方法
- 格式:ppt
- 大小:1.11 MB
- 文档页数:20




时间序列模型一、分类①按所研究的对象的多少分,有一元时间序列和多元时间序列。
②按时间的连续性可将时间序列分为离散时间序列和连续时间序列两种。
③按序列的统计特性分,有平稳时间序列和非平稳时间序列。
狭义时间序列:如果一个时间序列的概率分布与时间t无关。
广义时间序列:如果序列的一、二阶矩存在,而且对任意时刻t满足均值为常数和协方差为时间间隔T勺函数。
(下文主要研究的是广义时间序列)。
④按时间序列的分布规律来分,有高斯型时间序列和非高斯型时间序列。
二、确定性时间序列分析方法概述时间序列预测技术就是通过对预测目标自身时间序列的处理,来研究其变化趋势的。
一个时间序列往往是以下几类变化形式的叠加或耦合。
①长期趋势变动:它是指时间序列朝着一定的方向持续上升或下降,或停留在某一水平上的倾向,它反映了客观事物的主要变化趋势。
通常用T t表示。
②季节变动:通常用S t表示。
③循环变动:通常是指周期为一年以上,由非季节因素引起的涨落起伏波形相似的波动。
通常用C t表示。
④不规则变动。
通常它分为突然变动和随机变动。
通常用R t表示。
也称随机干扰项。
常见的时间序列模型:⑴加法模型:y t = S t + T t + C t + R t;⑵乘法模型:y t =S T t C t -R t ;⑶混合模型:y t =S T t + R t ;y t = S t +2T t G R t ;R t这三个模型中y t表示观测目标的观测记录, E R t = 0, E R t2 ==o2如果在预测时间范围以内,无突然变动且随机变动的方差 /较小,并且有理由认为过去和现在的演变趋势将继续发展到未来时,可用一些经验方法进行预测。
三、移动平均法当时间序列的数值由于受周期变动和不规则变动的影响,起伏较大,不易显示出发展趋势时,可用移动平均法,消除这些因素的影响,分析、预测序列的长期趋势。
移动平均法有简单移动平均法,加权移动平均法,趋势移动平均法等。

自回归模型一、 预测方法综述预测方法大体上分为定性预测法、时间序列预测法和因果模型预测法。
定性预测法是在数据资料掌握不多的情况下,依靠人的经验和分析能力,用系统的、逻辑的思维方法,把有关资料加以综合、进行预测的方法。
定性预测法包括特尔斐法、主观概率预测法、判断预测法等方法。
时间序列预测法是依据预测对象过去的统计数据,找到其随时间变化的规律,建立时序模型,以判断未来数值的预测方法。
其基本思想是:过去的变化规律会持续到未来,即未来是过去的延伸。
时间序列预测法包括时间序列平滑法、趋势外推法、季节变动预测法等确定型时间序列的预测方法和马尔可夫法、随机型时间序列的预测方法。
因果模型预测法是把所要预测的对象同其他有关因素联系起来进行分析,制定出揭示因果关系的模型,然后根据模型进行预测。
因果模型预测法包括回归分析预测法、经济计量模型法、投入产出预测法等。
由于时间序列预测法和因果模型预测法都是以统计资料为依据,应用统计方法进行预测的,所以有时两者统称为统计预测。
到目前为止,已有近二百种预测方法。
1987年,Ledes和Farbor首次将神经网络引入到预测领域中,无论是从思想上、还是技术上都是一种拓宽和突破。
常用的分析和预测方法有下面几种:(1) 投资分析方法。
这是市场分析家常用的方法。
(2) 时间序列分析法。
这种方法主要是通过建立综合指数之间的时间序列相关辩识模型,如自回归移动平均模型(ARMA)、齐次非平稳模型(ARIMA)等来预测未来变化。
(3) 神经网络预测法。
神经网络是一种最新的时间序列分析方法。
(4) 其他预测方法。
如专家评估法和市场调查法等定性方法、季节变动法、马尔柯夫法和判别分析法等定量预测方法。
传统的预测方法大都采用线性模型来近似地表达预测对象的发展规律。
如最常用的AR模型预测,就是在时间序列平稳的假设基础之上,对其建立线性模型,然后采用模型外推的方法预测其未来值。
然而这些方法只适用于平稳时间序列的预测。

Stata是一个广泛使用的统计和数据分析软件,它提供了多种时间序列预测方法。
以下是一些常用的方法:
1.ARIMA模型:这是最常用的一类时间序列预测模型。
ARIMA模型
(AutoRegressive Integrated Moving Average)由自回归项(AR)、差分项(I)和移动平均项(MA)组成。
通过估计这些参数,可以对未来值进行预测。
2.指数平滑:指数平滑是一种简单的时间序列预测方法,它根据过去的数据
对未来值进行预测。
Stata提供了多种指数平滑方法,如简单指数平滑、Holt-Winters方法等。
3.VAR和VECM模型:这些模型用于分析多个时间序列之间的相互关系。
VAR(Vector AutoRegressive)模型和VECM(Vector Error Correction Model)模型可以用于研究多个时间序列之间的长期均衡关系和短期调整机制。
4.神经网络:神经网络是一种强大的预测工具,可以用于处理非线性时间序
列数据。
Stata提供了多种神经网络方法,如多层感知器、径向基函数等。
5.其他方法:除了上述方法外,Stata还提供了其他一些时间序列预测方法,
如季节性自回归积分滑动平均模型(SARIMA)、季节性自回归积分滑动平均向量误差修正模型(SARIMA-VECM)等。
在Stata中实现这些方法需要使用相应的命令或程序包。
例如,可以使用arima 命令来拟合ARIMA模型,使用smooth命令来执行指数平滑,使用var命令来拟合VAR和VECM模型等。



第3章时间序列预测法§3.1 时间序列分析的基本问题3.1.1时间序列时间序列是指同一变量按发生时间的先后排列起来的一组观察值或记录值。
例如:1953~2001年的国民收入;1958~2001年全国汽车的产量;某物资公司1996~2001年逐月的机电产品月销售量;某省1962~2001年工业燃料消费量等等。
所用的时间单位可以根据情况取年、季、月等。
3.1.2时间序列预测经济预测中的预测目标及其影响因素的统计资料,大多是时间序列。
任何预测目标都有各自的时间演变过程,研究它如何由过去演变到现在的演变规律,并分析、研究它今后的变化规律,即可对它们进行预测,时间序列预测技术就是利用预测目标本身的时间序列,分析、研究预测目标未来的变化规律而进行预测的。
时间序列预测法,只要有预测目标的历史统计数据即可进行预测,统计资料易于收集,计算又比较简单,不仅可用来预测目标,还可用于预测回归预测法的影响因素。
因此,广泛地用于各方面的预测。
而当找不到预测目标的主要影响因素或者虽然知道其主要影响因素,但找不到有关的统计数据时,时间序列预测法的优越性更为显著。
时间序列预测技术,可分为确定型和随机型两大类。
本章只介绍确定型时间序列预测,第四章将介绍随机型时间序列预测。
3.1.3四类影响因素世间各种各样的事物,在各时间都可能受很多因素的影响,因此,所形成的时间序列,实际上是各个影响因素同时作用的综合结果。
我们想从给定的时间序列,分析出作用于所观察事物的每一个影响因素,是无法办到的。
因此,我们在分析各种时间序列时,通常把各种可能的影响因素,按其作用的效果分为四大类:1)趋势变动[记为T(t)]:指预测目标在长时间内的变动趋势——持续上升或持续下降。
2)季节变动[记为S(t)]:指每年受季节影响重复出现的周期性变动,一般是以十二个月或四个季度为一个周期。
3)循环变动[记为C(t)]:指以数年为周期(各周期的长短可能不一致)的一种周期性变动,例如经济景气指数,银行储蓄。

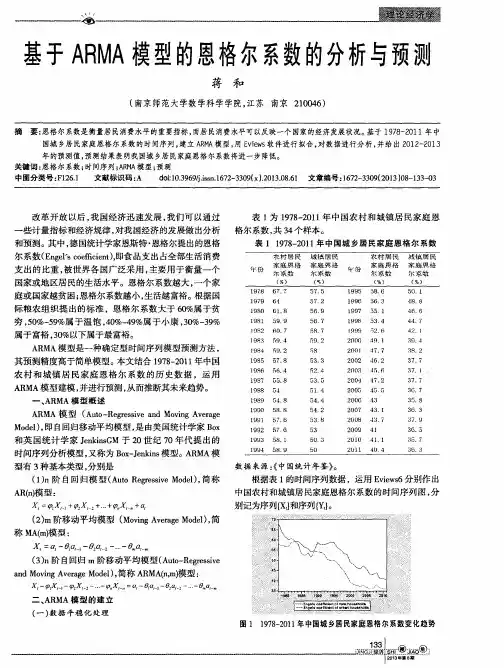
基于ARMA模型的恩格尔系数的分析与预测摘要:恩格尔系数是衡量居民消费水平的重要指标,而居民消费水平可以反映一个国家的经济发展状况。
基于1978-2011年中国城乡居民家庭恩格尔系数的时间序列,建立ARMA模型,用Eviews软件进行拟合,对数据进行分析,并给出2012-2013年的预测值,预测结果表明我国城乡居民家庭恩格尔系数将进一步降低。
关键词:恩格尔系数;时间序列;ARMA模型;预测改革开放以后,我国经济迅速发展,我们可以通过一些计量指标和经济规律,对我国经济的发展做出分析和预测。
其中,德国统计学家恩斯特·恩格尔提出的恩格尔系数(Engel’s coefficient),即食品支出占全部生活消费支出的比重,被世界各国广泛采用,主要用于衡量一个国家或地区居民的生活水平。
恩格尔系数越大,一个家庭或国家越贫困;恩格尔系数越小,生活越富裕。
根据国际粮农组织提出的标准,恩格尔系数大于60%属于贫穷,50%-59%属于温饱,40%-49%属于小康,30%-39%属于富裕,30%以下属于最富裕。
ARMA模型是一种确定型时间序列模型预测方法,其预测精度高于简单模型。
本文结合1978-2011年中国农村和城镇居民家庭恩格尔系数的历史数据,运用ARMA模型建模,并进行预测,从而推断其未来趋势。
一、ARMA模型概述ARMA模型(Auto-Regressive and Moving Average Model),即自回归移动平均模型,是由美国统计学家Box和英国统计学家JenkinsGM于20世纪70年代提出的时间序列分析模型,又称为Box-Jenkins模型。
ARMA模型有3种基本类型,分别是(1)n阶自回归模型(Auto Regressive Model),简称AR(n)模型:(2)m阶移动平均模型(Moving Average Model),简称MA(m)模型:(3)n阶自回归m阶移动平均模型(Auto-Regressive and Moving Average Model),简称ARMA(n,m)模型:二、ARMA模型的建立(一)数据平稳化处理表1为1978-2011年中国农村和城镇居民家庭恩格尔系数,共34个样本。