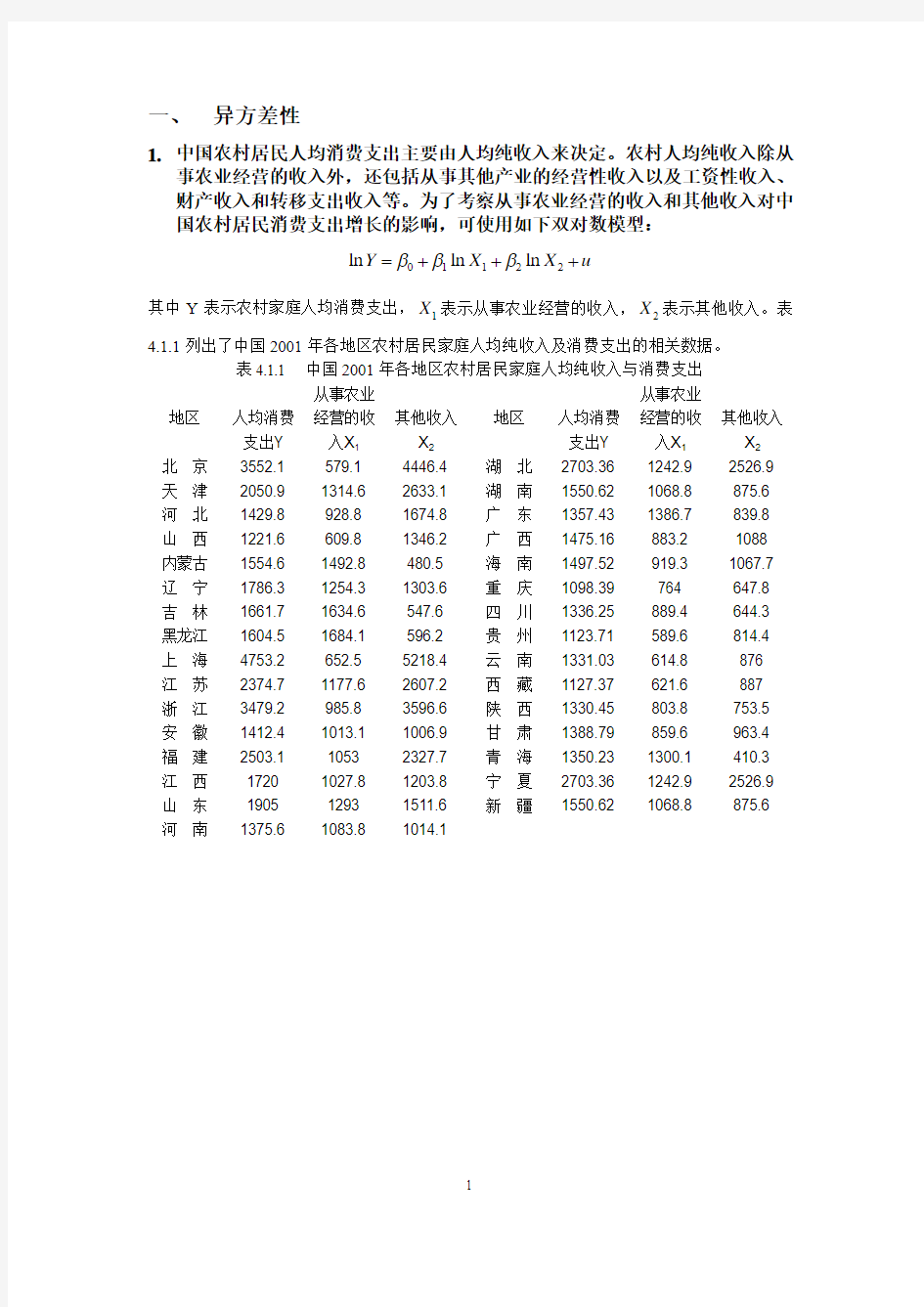

一、 异方差性
1. 中国农村居民人均消费支出主要由人均纯收入来决定。农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支出收入等。为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,可使用如下双对数模型:
01122ln ln ln Y X X u βββ=+++
其中Y 表示农村家庭人均消费支出,1X 表示从事农业经营的收入,2X 表示其他收入。表4.1.1列出了中国2001年各地区农村居民家庭人均纯收入及消费支出的相关数据。
表4.1.1 中国2001年各地区农村居民家庭人均纯收入与消费支出
地区 人均消费支出Y 从事农业
经营的收入X 1 其他收入X 2 地区
人均消费支出Y 从事农业经营的收入X 1 其他收入X 2 北 京 3552.1 579.1 4446.4 湖 北 2703.36 1242.9 2526.9 天 津 2050.9 1314.6 2633.1 湖 南 1550.62 1068.8 875.6 河 北 1429.8 928.8 1674.8 广 东 1357.43 1386.7 839.8 山 西 1221.6 609.8 1346.2 广 西 1475.16 883.2 1088 内蒙古 1554.6 1492.8 480.5 海 南 1497.52 919.3 1067.7 辽 宁 1786.3 1254.3 1303.6 重 庆 1098.39 764 647.8 吉 林 1661.7 1634.6 547.6 四 川 1336.25 889.4 644.3 黑龙江 1604.5 1684.1 596.2 贵 州 1123.71 589.6 814.4 上 海 4753.2 652.5 5218.4 云 南 1331.03 614.8 876 江 苏 2374.7 1177.6 2607.2 西 藏 1127.37 621.6 887 浙 江 3479.2 985.8 3596.6 陕 西 1330.45 803.8 753.5 安 徽 1412.4 1013.1 1006.9 甘 肃 1388.79 859.6 963.4 福 建 2503.1 1053 2327.7 青 海 1350.23 1300.1 410.3 江 西 1720 1027.8 1203.8 宁 夏 2703.36 1242.9 2526.9 山 东 1905 1293 1511.6 新 疆 1550.62
1068.8
875.6
河 南
1375.6
1083.8
1014.1
用OLS 法进行估计,结果如下:
对应的表达式为:
12ln 1.6030.325ln 0.507ln Y X X =++
(1.86) (3.14) (10.43)
20.7965,0.78,0.8117R R RSS ===
不同地区农村人均消费支出的差别主要来源于非农经营收入及其他收入的差别,因此,如果存在异方差性,则可能是2X 引起的。 对异方差性的检验:
做OLS 回归得到的残差平方项与ln 2X 的散点图:
从散点图可以看出,两者存在异方差性。下面进行统计检验。
采用White异方差检验:
EViews提供了包含交叉项和没有交叉项两个选择。本例选择没有包含交叉项。
得到如下结果:
所以辅助回归结果为:
2221122? 3.9820.579ln 0.042(ln )0.563ln 0.04(ln )e
X X X X =-+-+ (1.38) (-0.63) (0.63) (-2.77) (2.9)
其他收入2X 与2X 的平方项的参数的t 检验是显著的,且White 统计量为13.36,在5%的显著性水平下,拒绝同方差性这一原假设,方程确实存在异方差性。
用加权最小二乘法对异方差性进行修正,重新进行回归估计,过程如下:
在EViews 工作窗口输入如下命令,定义加权数:
估计过程如下:
得到加权后消除异方差性的估计结果:
回归表达式为:
12
?ln 1.2280.376ln 0.51ln Y X X =++ (4.13) (6.61) (28.69)
20.993,0.992,0.047R R RSS ===
从上面的结果看出,运用加权最小二乘法估计的结果不论拟合度,残差,还是
各参数的t 统计量的值都有了显著的改善。
2. 表4.1.2列出了2000年中国部分省市城镇居民每个家庭平均全年可支配收入(X )与消费性支出(Y )的统计数据。
表4.1.2 单位:元 地区 可支配收入X 消费性支出Y 地区 可支配收入X 消费性支出Y 北 京 10349.69 8493.49 浙 江 9279.16 7020.22 天 津 8140.5 6121.04 山 东 6489.97 5022 河 北 5661.16 4348.47 河 南 4766.26 3830.71 山 西 4724.11 3941.87 湖 北 5524.54 4644.5 内蒙古 5129.05 3927.75 湖 南 6218.73 5218.79 辽 宁 5357.79 4356.06 广 东 9761.57 8016.91 吉 林 4810 4020.87 陕 西 5124.24 4276.67 黑龙江 4912.88 3824.44 甘 肃 4916.25 4126.47 上 海 11718.01 8868.19 青 海 5169.96 4185.73 江 苏 6800.23 5323.18 新 疆 5644.86 4422.93
(1)试用OLS法建立居民人均消费支出与可支配收入的线性模型(2)检验模型是否存在异方差性
(3)如果存在异方差性,试采用适当的方法估计模型对数。
采用OLS法建立线性模型,结果如下:
进行异方差性的检验,本例采用White检验,过程如下:
得到如下部分输出结果:
从伴随概率值可以看出,在5%的显著性水平下,原模型存在异方差性。采用加权最小二乘法进行估计,过程如下:
得到如下结果:
此时的回归表达式为:
y x
=+
415.660.729
(3.55) (32.5)
拟合度和残差都有所改善。
二、序列相关性
1.经济理论指出,商品几口主要由进口国的经济发展水平,以及商品进口价格
指数与国内价格指数对比因素决定。由于无法取得中国商品进口价格指数,我们主要研究中国商品进口M与国内生产总值GDP的关系,数据见表4.2.1
表4.2.1 1978—2001年中国商品进口与国内生产总值 年份 国内生产总值/亿元 商品进口/亿美元 年份 国内生产总值/亿元 商品进口/亿美元 1978 3624.1 108.9 1990 18547.9 533.5 1979 4038.2 156.7 1991 21617.8 637.9 1980 4517.8 200.2 1992 26638.1 805.9 1981 4862.4 220.2 1993 34634.4 1039.6 1982 5294.7 192.9 1994 46759.4 1156.1 1983 5934.5 213.9 1995 58478.1 1320.8 1984 7171 274.1 1996 67884.6 1388.3 1985 8964.4 422.5 1997 74462.6 1423.7 1986 10202.2 429.1 1998 78345.2 1402.4 1987 11962.5 432.1 1999 82067.46 1657 1988 14928.3 552.7 2000 89442.2 2250.9 1989
16909.2 591.4 2001 95933.3 2436.1
用OLS 法建立中国商品进口方程,回归结果如下:
对应的表达式为:
?194.840.02t t
M GDP =+ (5.65) (18.12)
20.945,0.942,110.33,0.375R R ESS DW ====
进行序列相关性检验,作残差项t e
与时间t 以及t e 与1t e 的关系图,如下:
得到如下关系图:
从上图可以看出,随即干扰项呈现正序列相关性。
DW 检验结果表明,在5%的显著性水平下,n=24,k=2,查表得
1.27. 1.45l u d d ==,由于0.375l DW d = ,故存在正自相关。
下面进行拉格朗日乘数检验。含1阶滞后残差项的辅助回归过程如下:
输入滞后阶数:
得到如下结果:
辅助回归表达式为:
121.670.0010.926t t e
GDP e -=-+ (0.99) (-1.85) (5.55)
LM=13.246,从伴随概率值可以看出,在显著性为5%的水平下,模型存在1阶
序列相关性。
作2阶滞后残差项的辅助回归结果如下:
辅助回归表达式为:
1217.90.0010.99960.128t t t e
GDP e e --=-+- (0.746) (-1.256) (4.172) (-0.438)
LM 值的伴随概率说明模型仍然存在序列相关性,但是2t e
- 的参数不显著,说明不存在2阶序列相关性。
运用广义差分法进行自相关的处理,采用科克伦—奥科特迭代法。
1阶广义差分的估计过程为:
回归结果如下:
表明模型已经不存在序列相关性。
2. 中国1980—2000年投资总额X 与工业总产值Y 的统计资料如表4.2.2所示。
表4.2.2 单位:亿元
年份 全社会固定资产投资X 工业增加值Y 年份
全社会固定资产投资X 工业增加值Y 1980 910.9000 1996.500 1991 5594.500 8087.100 1981 961.0000 2048.400 1992 8080.100 10284.50 1982 1230.400 2162.300 1993 13072.30 14143.80 1983 1430.100 2375.600 1994 17042.10 19359.60 1984 1832.900 2789.000 1995 20019.30 24718.30 1985 2543.200 3448.700 1996 22913.50 29082.60 1986 3120.600 3967.000 1997 24941.10 32412.10 1987 3791.700 4585.800 1998 28406.20 33387.90 1988 4753.800 5777.200 1999 29854.71 35087.21 1989 4410.400 6484.000 2000 32917.73
39570.30
1990
4517.000
6858.000
(1) 当设定模型为01ln ln t t t Y X u ββ=++时,是否存在序列相关性 (2) 若按一阶自相关假设,使用广义最小二乘法估计原模型。
(3) 采用差分形式*1t t t X X X -=-,*1t t t Y Y Y -=-作为新数据,估计模型
**01t t t Y X v αα=++,该模型是否存在序列相关?
(1) 对方程进行回归分析,结果如下:
由上面的结果可以看出,DW=0.45,小于显著性水平为5%下,样本容量为21的DW 分布的下限临界值 1.22l d =。因此,可判定模型存在一阶序列相关。
(2) 运用广义最小二乘法估计模型,过程如下:
得到如下输出结果:
则回归模型表达式为:
ln 1.1260.904ln 0.65(1)t t Y X AR =++
运用拉格朗日乘数检验模型是否还存在一阶序列相关性,过程如下:
检验一阶滞后项
检验部分结果如下:
从伴随概率值可以看出,此时已经不存在一阶序列相关性了。
(3)采用差分形式估计模型,过程如下:
回归结果如下:
此时的DW值为1.62,大于5%的显著性水平下容量为20的DW检验的临界值
d ,因此差分形式的模型不存在一阶序列相关性。
上限 1.41
u
3. 某上市公司的子公司的年销售额Y 与其总公司年销售额X 的观测数据见表
4.2.3
表4.2.3
序号 X Y 序号 X Y 1 127.3 20.96 11 148.3 24.54 2 130 21.4 12 146.4 24.3 3 132.7 21.96 13 150.2 25 4 129.4 21.52 14 153.1 25.64 5 135 22.39 15 157.3 26.36 6 137.1 22.76 16 160.7 26.98 7 141.2 23.48 17 164.2 27.52 8 142.8 23.66 18 165.6 27.78 9 145.5 24.1 19 168.7 28.24 10
145.3
24.01
20
171.7
28.78
(1) 用最小二乘法估计Y 关于X 的回归方程; (2) 用DW 检验分析随机干扰项的一阶自相关性; (3) 直接用差分法估计回归模型的参数。
首先运用OLS 法估计Y 关于X 的回归方程,结果如下:
回归方程表达式为:
? 1.45480.1763t t
Y X =-+ (-6.79) (122.01)
在5%的显著性水平下,容量为n=20的DW 分布的临界值为
1.201, 1.411L U d d ==,由于0.735L DW d =<,所以该模型存在一阶正自相关。
直接运用差分法对原模型进行估计,过程如下:
回归结果如下:
在5%的显著性水平下,容量为19的DW 检验的临界值的下限与上限分别为
1.18, 1.40L U d d ==, 1.75U DW d =>,所以模型已经不存在一阶序列相关性。 估计的回归模型表达式为:
()0.04050.1588()t t D Y D X =+
(1.8) (21.9)
系统动力学模型介绍 1.系统动力学的思想、方法 系统动力学对实际系统的构模和模拟是从系统的结构和功能两方面同时进行的。系统的结构是指系统所包含的各单元以及各单元之间的相互作用与相互关系。而系统的功能是指系统中各单元本身及各单元之间相互作用的秩序、结构和功能,分别表征了系统的组织和系统的行为,它们是相对独立的,又可以在—定条件下互相转化。所以在系统模拟时既要考虑到系统结构方面的要素又要考虑到系统功能方面的因素,才能比较准确地反映出实际系统的基本规律。系统动力学方法从构造系统最基本的微观结构入手构造系统模型。其中不仅要从功能方面考察模型的行为特性与实际系统中测量到的系统变量的各数据、图表的吻合程度,而且还要从结构方面考察模型中各单元相互联系和相互作用关系与实际系统结构的一致程度。模拟过程中所需的系统功能方面的信息,可以通过收集,分析系统的历史数据资料来获得,是属定量方面的信息,而所需的系统结构方面的信息则依赖于模型构造者对实际系统运动机制的认识和理解程度,其中也包含着大量的实际工作经验,是属定性方面的信息。因此,系统动力学对系统的结构和功能同时模拟的方法,实质上就是充分利用了实际系统定性和定量两方面的信息,并将它们有机地融合在一起,合理有效地构造出能较好地反映实际系统的模型。 2.建模原理与步骤
(1)建模原理 用系统动力学方法进行建模最根本的指导思想就是系统动力学的系统观和方法论。系统动力学认为系统具有整体性、相关性、等级性和相似性。系统内部的反馈结构和机制决定了系统的行为特性,任何复杂的大系统都可以由多个系统最基本的信息反馈回路按某种方式联结而成。系统动力学模型的系统目标就是针对实际应用情况,从变化和发展的角度去解决系统问题。系统动力学构模和模拟的一个最主要的特点,就是实现结构和功能的双模拟,因此系统分解与系统综合原则的正确贯彻必须贯穿于系统构模、模拟与测试的整个过程中。与其它模型一样,系统动力学模型也只是实际系统某些本质特征的简化和代表,而不是原原本本地翻译或复制。因此,在构造系统动力学模型的过程中,必须注意把握大局,抓主要矛盾,合理地定义系统变量和确定系统边界。系统动力学模型的一致性和有效性的检验,有一整套定性、定量的方法,如结构和参数的灵敏度分析,极端条件下的模拟试验和统计方法检验等等,但评价一个模型优劣程度的最终标准是客观实践,而实践的检验是长期的,不是一二次就可以完成的。因此,一个即使是精心构造出来的模型也必须在以后的应用中不断修改、不断完善,以适应实际系统新的变化和新的目标。 (2)建模步骤 系统动力学构模过程是一个认识问题和解决问题的过程,根据人们对客观事物认识的规律,这是一个波浪式前进、螺旋式上升的过程,因此它必须是一个由粗到细,由表及里,多次循环,不断深化的过程。系统动力学将整个构模过程归纳为系统分析、结构分析、模型建立、模型试验和模型使用五大步骤这五大步骤有一定的先后次序,但按照构模过程中的具体情况,它们又都是交叉、反复进行的。 第一步系统分析的主要任务是明确系统问题,广泛收集解决系统问题的有关数据、资料和信息,然后大致划定系统的边界。 第二步结构分析的注意力集中在系统的结构分解、确定系统变量和信息反馈机制。 第三步模型建立是系统结构的量化过程(建立模型方程进行量化)。 第四步模型试验是借助于计算机对模型进行模拟试验和调试,经过对模型各种性能指标的评估不断修改、完善模型。 第五步模型使用是在已经建立起来的模型上对系统问题进行定量的分析研究和做各种政策实验。 3.建模工具 系统动力学软件VENSIM PLE软件 4.建模方法 因果关系图法 在因果关系图中,各变量彼此之间的因果关系是用因果链来连接的。因果链是一个带箭头的实线(直线或弧线),箭头方向表示因果关系的作用方向,箭头旁标有“+”或“-”号,分别表示两种极性的因果链。
关于计量经济学经典线性回归模型基本假定的思考 在计量经济学建模实践中,研究者都力所能及的令所创建的模型满足经典线性回归模型的所有基本假定,因为只有这样,该模型的参数估计才具有一系列的优良统计性质,与之相关的各种假设检验才精确可靠,模型总体l来讲也才具有最佳的应用价值,否则,模型将或多或少存在着不足之处,使得其应用性能大打折扣。为什么计量经济学模型需要这些基本假定呢?这些假定又具有什么样的意义呢?对于这些最基本的问题,笔者将结合计量经济学的教学实践经验以及对该学科的理解,来对计量经济学经典线性回归模型的基本假定作出通俗的解释。 1.计量经济学模型需要完美性 辨证唯物主义告诉我们,不管是什么偶然的现象,其背后都有必然的规律性在起着支配作用,世界是偶然性与必然性的辩证统一。科学研究的目的,即是在诸多的偶然性现象中发现其不变的必然性,从而推动人类物质文明和精神文明的进步。 计量经济学的研究也不例外,其目的是为了在复杂多变的经济现象中发现其不变的本质,从而获得对特定经济系统的规律性认识,为经济发展与社会进步服务。计量经济学通过创建数学模型来揭示经济现象的数量规律,从而弥补了以逻辑推理和文字描述为主、缺乏定量分析的经济理论的不足。以研究商品需求为例,传统的经济学理论“需求定律”只能告诉我们商品需求与价格之间具有反向变动的关系,但无法告诉我们当价格变化一定量时,需求会随之变化多少量,而计量经济学的建模分析则能够把两者之间的定量关系估计出来,这种能力是其他经济学理论所不能替代的。 既然计量经济学建模分析的目的是通过创建适当的数学模型来揭示经济变量之间的数量规律性,那么计量经济学就必须首先要回答这样一个问题一一“我们到底需要一个什么样的计量经济学模型?”这个问题的答案是显而易见的,那就是,我们需要一个“尽可能完全揭示经济变量之间的数量规律性” (以下称“第一大完美性特征”)并且“便于进行研究” (以下称“第二大完美性特征”)的计量经济学模型。这里的“便于进行研究”是指便于进行参数估计和假设检验,并且便于进行数学推导。很显然,具备这两大特征的计量经济学模型才是最完美的模型。尽管这种“完美模型”的第一大特征在现实中可能不会完全存在,但在理论上我们必须事先创建出一个完美的标准,以此来作为参照系,从而才能对现实模型作出优劣的比较、判断和修正,使之更好地揭示经济变量之间的规律性。 根据计量经济学的基本理论,我们不难发现,经典线性回归模型就是具备“尽可能完全揭示经济变量之间的数量规律性和“便于进行研究”这两大特征的完美模型。接下来,笔者将从“模型完美性”角度出发,对经典线性回归模型的基本假定(不含正态性假定)在两大完美特征方面对其作出通俗的解释。 2.与第一大完美性特征有关的基本假定 2.1假定:“线性回归模型是指对参数而言为线性的回归模型。” …根据该假定,因变量和解释变量以线性或非线性形式进入回归模型都是允许的,但参数必须要求在本质上是线性的。参数线性这一假定并不符合实际,因为从现实来讲,经济变量之间的关系在参数上往往不是线性的。既然如此,那为什么还要假定参数线性呢?原因在于,参数线性的模型可以很
放宽基本假定的计量经济模型 ( 异方差、自相关和多重共公线性模型 ) 一、单选题 1.容易产生异方差的数据是( C ) A 、时间序列数据 B 、虚变量数据 C 、横截面数据 D 、年度数据 2.下列哪种方法不能用来检验异方差( D ) A 、G—Q检验 B 、H.White 检验 C 、Glejser 检验 D 、D W -检验 3.如果回归模型中的随机误差项存在异方差,则模型参数的普通最小二乘估计量是( B ) A 、无偏、有效估计 B 、无偏、非有效估计量 C 、有偏、有效估计量 D 、有偏、非有效估计量 4.设回归模型为i i i Y X βμ=+,其中22(),i i Var X μσ=则β的有效估计量为( D ) A 、2XY X β=∑∑ B 、22 ()n XY X Y n X X β-=-∑∑∑∑∑ C 、Y X β= D 、1Y n X β=∑ 5. 当模型中出现异方差现象时,估计参数的适当方法是(A ) A 、加权最小二乘估计法 B 、工具变量法 C 、广义差分法 D 、使用非样本先验信息 7.设回归模型为01i i i Y X ββμ=++,其中22(),i i Var X μσ=则用加权最小二乘估计法估计模型时,应将模型变换为( C ) A 、01Y X ββμ= B 、01Y ββμ=+C 、01///Y X X X ββμ=++ D 、22201////i Y X X X X X ββμ=++ 8.下列哪种形式的序列相关可用..DW 统计量来检验, (t ε为具有零均值、常数方差,且不存在序列相关的随机变量)( A )
A 、1t t t μρμε-=+ B 、1122t t t t μρμρμε--=+++ C 、t t μρε= D 、21t t t μρερε-=++ 9.给定显著水平,若..DW 统计量的下和尚临界值分别为 L d 和U d 来检验,则 当..L U d DW d <<时,可以认为随机误差项( D ) A 、存在一阶正自相关 B 、存在一阶负自相关 C 、不存在序列相关 D 、存在序列相关与否不能断定 10.采用一阶差分模型克服一阶线性自相关问题是用于下列哪种情况( B ) A 、0ρ≈ B 、1ρ≈ C 、10ρ-<< D 、01ρ<< 11.根据一个30n =的样本估计01??i i i Y X ββμ=++后计算得.. 1.2DW =,已知在5%的显著水平下, 1.35L d =, 1.49U d =,则认为原模型( C ) A 、不存在一序列自相关 B 、不能断定是否存在一阶自相关 C 、存在正的一阶自相关 D 、存在负一阶自相关 12.对于模型01t t t Y X e ββ=++,以ρ表示t e 与1t e -之间的线性相关系数(1,2,,)t n =,则下面明显错误的是(B ) A 、0.8,..0.4DW ρ== B 、0.8,..0.4DW ρ=-=- C 、1,..0DW ρ== D 、0,..2DW ρ== 14.应用D W -检验须满足的条件不包括(D ) A 、模型包含截距项 B 、模型解释变量不能包含被解释变量的滞后项 C 、样本容量足够大 D 、解释变量为随机变量 16.在线性回归模型中,若解释变量1X 和2X 的观测值成比例,即12X kX =,其中为非零常数,则表明模型中存在( B ) A 、异方差 B 、多重共线性 C 、序列相关 D 、设定误差 二、多选题
商业案例分析的常见框架与工具 1.Strategy 1.1市场进入类 ?公司宏观环境:PEST(政治、经济、社会、技术) ?公司微观环境:SWOT分析、波特五力模型 ?市场情况分析:市场趋势、市场规模、市场份额、市场壁垒等 ?利益相关方分析:公司、供应商、经销商、顾客、竞争对手、大众 ?3C战略三角 ?市场细分(定位目标客户群;Niche Market) - 地理细分:国家、地区、城市、农村、气候、地形 - 人口细分:年龄、性别、职业、收入、教育、家庭人口、家庭类型、家庭生命周期、国籍、民族、宗教、社会阶层 - 心理细分:社会阶层、生活方式、个性 - 行为细分:时机、追求利益、使用者地位、产品使用率、忠诚程度、购买准备阶段、态度 ?风险预测与防范 1.2行业分析类 ?市场:市场规模、市场细分、产品需求/趋势分析、客户需求;BCG Matrix ?竞争:竞争对手的经济情况、产品差异化、市场整合度、产业集中度 ?顾客/供应商关系:谈判能力、替代者、评估垂直整合 ?进入/离开的障碍:对新加入者的反应、经济规模、预测学习曲线、研究政府调控 ?资金:主要资金来源、产业风险因素、成本变化趋势 1.3新产品引入类 ?营销调研数据分析 ?收入预测:时间推导、可比公司推导 ?产品生命周期 ?产品战略:4P, 4C, STP, 安索夫矩阵 ?市场营销战略:以消费者为核心的整合营销,关注各触点,并有所创新 ?物流条件:存储、运输 2.Operation 2.1市场容量扩张类:竞争对手、消费者、自身(广义3C理论) 2.2利润改善类:利润减少的两种可能 ?成本上升:固定成本/可变成本 - 固定成本过高:更新设备?削减产能?降低管理者/一般员工工资? - 可变成本过高:降低原材料价格?更换供应商?降低工资?裁员? - 成本结构是否合理? - 产能利用是否合理(闲置率)? ?销售额下降:4P(价格过高?产品品质?分销渠道?促销效果?) 2.3产品营销类(接近于“新产品引入类”) 2.4产品定价类 ?以成本为基础的定价:成本加成定价、以目标利润(盈亏平衡)定价 ?以价值为基础定价
第四章经典单方程计量经济学模型:放宽基本假定的模型 一、内容提要 本章主要介绍计量经济模型的二级检检验问题,即计量经济检验。主要讨论对回归模型的若干基本经典假定是否成立进行检验、当检验发现不成立时继续采用OLS估计模型所带来的不良后果以及如何修正等问题。具体包括异方差性问题、序列相关性问题、多重共线性问题以及随机解释变量这四大类问题。 异方差是模型随机扰动项的方差不同时产生的一类现象。在异方差存在的情况下,OLS 估计尽管是无偏、一致的,但通常的假设检验却不再可靠,这时仍采用通常的t检验和F 检验,则有可能导致出现错误的结论。同样地,由于随机项异方差的存在而导致的参数估计值的标准差的偏误,也会使采用模型的预测变得无效。对模型的异方差性有若干种检测方法,如图示法、Park与Gleiser检验法、Goldfeld-Quandt检验法以及White检验法等。而当检测出模型确实存在异方差性时,通过采用加权最小二乘法进行修正的估计。 序列相关性也是模型随机扰动项出现序列相关时产生的一类现象。与异方差的情形相类似,在序列相关存在的情况下,OLS估计量仍具无偏性与一致性,但通常的假设检验不再可靠,预测也变得无效。序列相关性的检测方法也有若干种,如图示法、回归检验法、Durbin-Watson检验法以及Lagrange 乘子检验法等。存在序列相关性时,修正的估计方法有广义最小二乘法(GLS)以及广义差分法。 多重共线性是多元回归模型可能存在的一类现象,分为完全共线与近似共线两类。模型的多个解释变量间出现完全共线性时,模型的参数无法估计。更多的情况则是近似共线性,这时,由于并不违背所有的基本假定,模型参数的估计仍是无偏、一致且有效的,但估计的参数的标准差往往较大,从而使得t-统计值减小,参数的显著性下降,导致某些本应存在于模型中的变量被排除,甚至出现参数正负号方面的一些混乱。显然,近似多重共线性使得模型偏回归系数的特征不再明显,从而很难对单个系数的经济含义进行解释。多重共线性的检验包括检验多重共线性是否存在以及估计多重共线性的范围两层递进的检验。而解决多重共线性的办法通常有逐步回归法、差分法以及使用额外信息、增大样本容量等方法。 当模型中的解释变量是随机解释变量时,需要区分三种类型:随机解释变量与随机扰动项独立,随机解释变量与随机扰动项同期无关、但异期相关,随机解释变量与随机扰动项
1 第四章经典单方程计量经济学模型:放宽基本假定的模型 一、内容提要 本章主要介绍计量经济模型的二级检检验问题,即计量经济检验。主要讨论对回归模型的若干基本经典假定是否成立进行检验、当检验发现不成立时继续采用OLS估计模型所带来的不良后果以及如何修正等问题。具体包括异方差性问题、序列相关性问题、多重共线性问题以及随机解释变量这四大类问题。 异方差是模型随机扰动项的方差不同时产生的一类现象。在异方差存在的情况下,OLS 估计尽管是无偏、一致的,但通常的假设检验却不再可靠,这时仍采用通常的t检验和F检验,则有可能导致出现错误的结论。同样地,由于随机项异方差的存在而导致的参数估计值的标准差的偏误,也会使采用模型的预测变得无效。对模型的异方差性有若干种检测方法,如图示法、Park与Gleiser检验法、Goldfeld-Quandt检验法以及White检验法等。而当检测出模型确实存在异方差性时,通过采用加权最小二乘法进行修正的估计。 序列相关性也是模型随机扰动项出现序列相关时产生的一类现象。与异方差的情形相类似,在序列相关存在的情况下,OLS估计量仍具无偏性与一致性,但通常的假设检验不再可靠,预测也变得无效。序列相关性的检测方法也有若干种,如图示法、回归检验法、Durbin-Watson检验法以及Lagrange 乘子检验法等。存在序列相关性时,修正的估计方法有广义最小二乘法(GLS)以及广义差分法。 多重共线性是多元回归模型可能存在的一类现象,分为完全共线与近似共线两类。模型的多个解释变量间出现完全共线性时,模型的参数无法估计。更多的情况则是近似共线性,这时,由于并不违背所有的基本假定,模型参数的估计仍是无偏、一致且有效的,但估计的参数的标准差往往较大,从而使得t-统计值减小,参数的显著性下降,导致某些本应存在于模型中的变量被排除,甚至出现参数正负号方面的一些混乱。显然,近似多重共线性使得模型偏回归系数的特征不再明显,从而很难对单个系数的经济含义进行解释。多重共线性的检验包括检验多重共线性是否存在以及估计多重共线性的范围两层递进的检验。而解决多重共线性的办法通常有逐步回归法、差分法以及使用额外信息、增大样本容量等方法。 当模型中的解释变量是随机解释变量时,需要区分三种类型:随机解释变量与随机扰动项独立,随机解释变量与随机扰动项同期无关、但异期相关,随机解释变量与随机扰动项
BOX-JENKINS 预测法 1 适用于平稳时序的三种基本模型 (1)()AR p 模型(Auto regression Model )——自回归模型 p 阶自回归模型: 式中,为时间序列第时刻的观察值,即为因变量或称被解释变量;, 为时序的滞后序列,这里作为自变量或称为解释变量;是随机误 差项;,,,为待估的自回归参数。 (2)()MA q 模型(Moving Average Model )——移动平均模型 q 阶移动平均模型: 式中,μ为时间序列的平均数,但当{}t y 序列在0上下变动时,显然μ=0,可删除此项;t e ,1t e -,2t e -,…,t q e -为模型在第t 期,第1t -期,…,第t q -期 的误差;1θ,2θ,…,q θ为待估的移动平均参数。 (3)(,)ARMA p q 模型——自回归移动平均模型(Auto regression Moving Average Model ) 模型的形式为: 显然,(,)ARMA p q 模型为自回归模型和移动平均模型的混合模型。当q =0,时,退化为纯自回归模型()AR p ;当p =0时,退化为移动平均模型()MA q 。 2 改进的ARMA 模型 (1)(,,)ARIMA p d q 模型 这里的d 是对原时序进行逐期差分的阶数,差分的目的是为了让某些非平稳(具有一定趋势的)序列变换为平稳的,通常来说d 的取值一般为0,1,2。 对于具有趋势性非平稳时序,不能直接建立ARMA 模型,只能对经过平稳化处理,而后对新的平稳时序建立(,)ARMA p q 模型。这里的平文化处理可以是差分处理,也可以是对数变换,也可以是两者相结合,先对数变换再进行差分处理。 (2)(,,)(,,)s ARIMA p d q P D Q 模型 对于具有季节性的非平稳时序(如冰箱的销售量,羽绒服的销售量),也同样需要进行季节差分,从而得到平稳时序。这里的D 即为进行季节差分的阶数; ,P Q 分别是季节性自回归阶数和季节性移动平均阶数;S 为季节周期的长度, 如时序为月度数据,则S =12,时序为季度数据,则S =4。 在SPSS19.0中的操作如下
一、 异方差性 1. 中国农村居民人均消费支出主要由人均纯收入来决定。农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支出收入等。为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,可使用如下双对数模型: 01122ln ln ln Y X X u βββ=+++ 其中Y 表示农村家庭人均消费支出,1X 表示从事农业经营的收入,2X 表示其他收入。表4.1.1列出了中国2001年各地区农村居民家庭人均纯收入及消费支出的相关数据。 表4.1.1 中国2001年各地区农村居民家庭人均纯收入与消费支出 地区 人均消费支出Y 从事农业 经营的收入X 1 其他收入X 2 地区 人均消费支出Y 从事农业经营的收入X 1 其他收入X 2 北 京 3552.1 579.1 4446.4 湖 北 2703.36 1242.9 2526.9 天 津 2050.9 1314.6 2633.1 湖 南 1550.62 1068.8 875.6 河 北 1429.8 928.8 1674.8 广 东 1357.43 1386.7 839.8 山 西 1221.6 609.8 1346.2 广 西 1475.16 883.2 1088 内蒙古 1554.6 1492.8 480.5 海 南 1497.52 919.3 1067.7 辽 宁 1786.3 1254.3 1303.6 重 庆 1098.39 764 647.8 吉 林 1661.7 1634.6 547.6 四 川 1336.25 889.4 644.3 黑龙江 1604.5 1684.1 596.2 贵 州 1123.71 589.6 814.4 上 海 4753.2 652.5 5218.4 云 南 1331.03 614.8 876 江 苏 2374.7 1177.6 2607.2 西 藏 1127.37 621.6 887 浙 江 3479.2 985.8 3596.6 陕 西 1330.45 803.8 753.5 安 徽 1412.4 1013.1 1006.9 甘 肃 1388.79 859.6 963.4 福 建 2503.1 1053 2327.7 青 海 1350.23 1300.1 410.3 江 西 1720 1027.8 1203.8 宁 夏 2703.36 1242.9 2526.9 山 东 1905 1293 1511.6 新 疆 1550.62 1068.8 875.6 河 南 1375.6 1083.8 1014.1
介绍的主要方法有六种,分别为: 1、对比分析法:将A公司和B公司进行对比、 2、外部因素评价模型(EFE)分析、 3、内部因素评价模型(IFE)分析、 4、swot分析方法、 5、三种竞争力分析方法、 6、五种力量模型分析。 对比分析法是最常用,简单的方法,将一个管理混乱、运营机制有问题的公司和一个管理有序、运营良好的公司进行对比,观察他们在组织结构上、资源配置上有什么不同,就可以看出明显的差别。在将这些差别和既定的管理理论相对照,便能发掘出这些差异背后所蕴含的管理学实质。企业管理中经常进行案例分析,将A和B公司进行对比,发现一些不同。各种现象的对比是千差万别的,最重要的是透过现象分析背后的管理学实质。所以说,只有表面现象的对比是远远不够的,更需要有理论分析。 外部因素评价模型(EFE)和内部因素评价模型(IFE)分析来源于战略管理中的环境分析。因为任何事物的发展都要受到周边环境的影响,这里的环境是广义的环境,不仅指外部环境,还指企业内部的环境。通常我们将企业的内部环境称作企业的禀赋,可以看作是企业资源的初始值。公司战略管理的基本控制模式由两大因素决定:外部不可控因素和内部可控因素。其中公司的外部不可控因素主要包括:政府、合作伙伴(如银行、投资商、供应商)、顾客(客户)、公众压力集团(如新闻媒体、消费者协会、宗教团体)、竞争者,除此之外,社会文化、政治、法律、经济、技术和自然等因素都将制约着公司的生存和发展。由此分析,外部不可控因素对公司来说是机会与威胁并存。公司如何趋利避险,在外部因素中发现机会、把握机会、利用机会,洞悉威胁、规避风险,对于公司来说是生死攸关的大事。在瞬息万变的动态市场中,公司是否有快速反应(应变)的能力,是否有迅速适应市场变化的能力,是否有创新变革的能力,决定着公司是否有可持续发展的潜力。公司的内部可控因素主要包括:技术、资金、人力资源和拥有的信息,除此之外,公司文化和公司精神又是公司战略制定和战略发展中不可或缺的重要部分。一个公司制定公司战略必须与公司文化背景相联。内部可控因素可以充分彰显出公司的优势与劣势或弱点。从而知己知彼,扬长避短,发挥自身的竞争优势,确定公司的战略发展方向和目标,使目标、资源和战略三者达到最佳匹配。公司通过对外部机会、风险以及内部优势、劣势的综合加权分析(借助外部因素评价矩阵[EFE]以及内部因素评价矩阵[IFE]),确立公司长期战略发展目标,制定公司发展战略。再将公司目标、资源与所制定的战略相比较,找出并建立外部与内部重要因素相匹配的有效的备选战略(借助SWOT矩阵、SPACE矩阵、BCG矩阵、IE矩阵及大战略矩阵),通过定量战略计划矩阵(QSPM)对若干备选战略的吸引力总分数的比较,确定公司最有效、最可能成功的战略。然后制定公司可量化的、具体的年度目标,围绕着已确立的目标,合理的进行各项资源的配置(如人、财、物方面的配置和调度),并有效地实施战略,最后是对已实施的战略进行控制、反馈与评价。这是最后一项工作,也是极重要的工作。往往一些战略的挫败很大部分是在实施战略的过程中,缺乏严格的控制机制和绩效考核标准所导致的。充分与及时的反馈是有效战略评价的基石,在快速而剧烈变化的环境中,公司的战略经受着巨大的挑战。通过战略评价决策矩阵,可以清晰地了解公司现行战略与实际的目标实现进程,
单选题(共10题,共20分) 1、BIM竣工模型形成后,土建和机电安装等各专业需要应用竣工模型指导施工,下列说法错误的是()。P244 A.根据甲方的整体项目节点时间要求制定机电专业的施工计划节点。 B.进行图纸深化设计。 C.完成机电施工建模。 D.完成机电施工设备材料的统计。 2、Revit施工图设计过程中各专业间模型的同步方式为()。P73 A.直接链接工作模型随时同步 B.完成模型设计后同步 C.完成外审后同步 D.建立专用条件模型按需同步 3、建模LOD100中说法不正确的是()。P125 A.只有管道类型、管径和主管标高 B.阀门不表示 C.仪表不表示 D.卫生器具有简单的体量 4、三维建模时,各专业协同绘图的方式不包括()。P111 A.可以使用链接方式完成各专业间协同工作 B.可以使用工作集方式完成各专业间协同工作 C.可以使用链接方式完成专业内部协同工作 D.可以使用拷贝方式完成专业内部协同工作 5、RFID指的是()。P356 A.射频识别技术 B.虚拟现实技术 C.虚拟原型技术 D.地理信息系统 6、与CAD相比,BIM模型的特性不包括()。《技术概论》P23 A.模型信息的完备性 B.模型信息的关联性 C.模型信息的一致性 D.计算机辅助设计 7、下列关于BIM参数化设计的描述中,()是不正确的。P66 A.BIM可以实现参数驱动模型变更 B.BIM便于后期基于参数统计工程量 C.BIM使变更更加方便快捷 D.使用BIM可以自由设计 8、施工企业应用BIM的内容不包括()。《BIM应用与项目管理》P80 A.施工建模 B.施工深化设计 C.施工工法模拟 D.运行维护 9、工作集协同绘图方式是将所有人的修改成果通过()的方式保存在中央服务器上。P112 A.网络共享文件夹 B.移动存储设备 C.云端存储 D.本地硬盘存储器 10、工作集协同绘图方式是将所有人的修改成果通过网络共享文件夹的方式保存在()上。P112
异方差性 1定义: 对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同。则认为出现了异方差性。 2影响: ① OLS 参数估计量非有效: 具有:线性性、无偏性 不具有:有效性 (大样本下) 具有:一致性 不具有:渐进有效性 ②变量的显著性检验失去意义 关于变量的显著性检验中,构造了t 统计量,他是建立在随机干扰项共同的方差 不变,而真确地估计了参数方差j B S ∧的基础之上的。如果出现了异方差性其估计值会偏大或偏小。t 检验失去意义。 ③ 模型的预测失效 预测值的置信区间中也包含有参数的方差的估计量j B S ∧。所以当模型出现异方差性是,任然 使用ols 估计量,将导致预测区间篇大或小,预测功能失效。 3判断: 假设4:2 )|(σμ=xi i Var 由于异方差性是相对于不同的解释变量观测值,随机误差项具有不同的方差。那么检验异方差性,也就是检验随机误差项的方差与解释变量观测值之间的相关性及其相关的“形式”。 随机误差项方差的表示! 一般的处理方法:首先采用OLS 估计,得到残差估计值。用它的平方近似随机误差项的方差。 残差估计值^~ )(OLS Y Y e i -= 近似随机误差项的方差 2 ~ )()(i e i E i Var ≈=μμ 图示检验法 帕克检验与戈里瑟检验 由于f(x)的形式未知,所以要进行各种形式的检验。 i ji i X f e ε+=)(~2i ji i X f e ε+=)(|~|
选择关于变量X 的不同的函数形式,对方程进行估计并进行显著性检验,如果存在某一种函数形式,使得方程显著成立,则说明原模型存在异方差性。 GQ 检验:适合样本容量大,异方差为单调增或单调减的函数形式。 Step1 将样本观测值按照有可能引起异方差的解释变量观测值排序 Step2 除去c=0.25n 观测值,讲剩下的观测值分为两组,每个子样样本容量为0.5(n-c ) Step3 对每个子样做OLS ,计算出两个残差平方和, 自由度为 0.5(n-c )-k-1 Step4 构建F 分布 F>F a (v1,v2) 拒绝同方差性假设,表明存在异方差。 White 检验:对任何形式的异方差均试用。 Step1 做OLS 回归,得到 Step2 辅助回归 辅助回归是检验2 ~i e 与解释变量可能组合的显著性。如果存在异方差性,则表明2 ~i e 与某种解释变量的组合存在显著的相关性,往往显示出比较大的可决系数,并且某一参数的t 检验值 比较大。 Step3 在同方差性假设下,辅助回归的可决系数R 2 ,与样本容量n 的乘积,渐进地服从自由度为辅助回归中解释变量个数的2 χ分布,即 2 2 ~χnR 。 )(2 2数辅助回归中解释变量个a nR χ> 拒绝同方差性假设,表明存在异方差。 4解决: 加权最小二乘法WLS (也称为广义最小二乘法GLS ):关键是寻找随机干扰项与解释变量间适当的函数形式。 加权最小二乘估计量,是无偏、有效的估计量。 广义最小二乘法估计量具有BLUE 特征。 思路:加权最小二乘法就是对原模型进行加权处理,使新模型不存在异方差性,然后采用普通最小二乘法进行回归。 对较大的残差平方和赋予较小的权,对较小的残差平方和赋予较大的权。 i i i i i i i i X X X X X X e εαααααα++++++=215224213221102~Var E e i i i ( ) ( ) ~ μ μ = ≈ 2 2
高中常见数学模型案例 中华人民共和国教育部2003年4月制定的普通高中《数学课程标准》中明确指出:“数学探究、数学建模、数学文化是贯穿于整个高中数学课程的重要内容”,“数学建模是数学学习的一种新的方式,它为学生提供了自主学习的空间,有助于学生体验数学在解决问题中的价值和作用,体验数学与日常生活和其他学科的联系,体验综合运用知识和方法解决实际问题的过程,增强应用意识;有助于激发学生学习数学的兴趣,发展学生的创新意识和实践能力。”教材中常见模型有如下几种: 一、函数模型 用函数的观点解决实际问题是中学数学中最重要的、最常用的方法。函数模型与方法在处理实际问题中的广泛运用,两个变量或几个变量,凡能找到它们之间的联系,并用数学形式表示出来,建立起一个函数关系(数学模型),然后运用函数的有关知识去解决实际问题,这些都属于函数模型的范畴。 1、正比例、反比例函数问题 例1:某商人购货,进价已按原价a 扣去25%,他希望对货物订一新价,以便按新价让利销售后仍可获得售价25%的纯利,则此商人经营者中货物的件数x 与按新价让利总额y 之间的函数关系是___________。 分析:欲求货物数x 与按新价让利总额y 之间的函数关系式,关键是要弄清原价、进价、新价之间的关系。 若设新价为b ,则售价为b (1-20%),因为原价为a ,所以进价为a (1-25%) 解:依题意,有25.0)2.01()25.01()2.01(?-=---b a b 化简得a b 45=,所以x a bx y ??==2.0452.0,即+∈=N x x a y ,4 2、一次函数问题 例2:某人开汽车以60km/h 的速度从A 地到150km 远处的B 地,在B 地停留1h 后,再以50km/h 的速度返回A 地,把汽车离开A 地的路x (km )表示为时间t (h )的函数,并画出函数的图像。 分析:根据路程=速度×时间,可得出路程x 和时间t 得函数关系式x (t );同样,可列出v(t)的关系式。要注意v(t)是一个矢量,从B 地返回时速度为负值,重点应注意如何画这两个函数的图像,要知道这两个函数所反映的变化关系是不一样的。 解:汽车离开A 地的距离x km 与时间t h 之间的关系式是:?? ???∈--∈∈=]5.6,5.3(),5.3(50150]5.3,5.2(,150]5.2,0[,60t t t t t x ,图略。 速度vkm/h 与时间t h 的函数关系式是:?? ???∈-∈∈=)5.6,5.3[,50)5.3,5.2[,0)5.2,0[,60t t t v ,图略。 3、二次函数问题 例3:有L 米长的钢材,要做成如图所示的窗架,上半部分为半圆,下半部分为六个全等小矩形组成的矩形,试问小矩形的长、宽比为多少时,窗所通过的光线最多,并具体标出窗框面积的最大值。
For personal use only in study and research; not for commercial use 第四章经典单方程计量经济学模型:放宽基本假定的模型 一、内容提要 本章主要介绍计量经济模型的二级检检验问题,即计量经济检验。主要讨论对回归模型的若干基本经典假定是否成立进行检验、当检验发现不成立时继续采用OLS估计模型所带来的不良后果以及如何修正等问题。具体包括异方差性问题、序列相关性问题、多重共线性问题以及随机解释变量这四大类问题。 异方差是模型随机扰动项的方差不同时产生的一类现象。在异方差存在的情况下,OLS 估计尽管是无偏、一致的,但通常的假设检验却不再可靠,这时仍采用通常的t检验和F检验,则有可能导致出现错误的结论。同样地,由于随机项异方差的存在而导致的参数估计值的标准差的偏误,也会使采用模型的预测变得无效。对模型的异方差性有若干种检测方法,如图示法、Park与Gleiser检验法、Goldfeld-Quandt检验法以及White检验法等。而当检测出模型确实存在异方差性时,通过采用加权最小二乘法进行修正的估计。 序列相关性也是模型随机扰动项出现序列相关时产生的一类现象。与异方差的情形相类似,在序列相关存在的情况下,OLS估计量仍具无偏性与一致性,但通常的假设检验不再可靠,预测也变得无效。序列相关性的检测方法也有若干种,如图示法、回归检验法、Durbin-Watson检验法以及Lagrange 乘子检验法等。存在序列相关性时,修正的估计方法有广义最小二乘法(GLS)以及广义差分法。 多重共线性是多元回归模型可能存在的一类现象,分为完全共线与近似共线两类。模型的多个解释变量间出现完全共线性时,模型的参数无法估计。更多的情况则是近似共线性,这时,由于并不违背所有的基本假定,模型参数的估计仍是无偏、一致且有效的,但估计的参数的标准差往往较大,从而使得t-统计值减小,参数的显著性下降,导致某些本应存在于模型中的变量被排除,甚至出现参数正负号方面的一些混乱。显然,近似多重共线性使得模型偏回归系数的特征不再明显,从而很难对单个系数的经济含义进行解释。多重共线性的检验包括检验多重共线性是否存在以及估计多重共线性的范围两层递进的检验。而解决多重共线性的办法通常有逐步回归法、差分法以及使用额外信息、增大样本容量等方法。 当模型中的解释变量是随机解释变量时,需要区分三种类型:随机解释变量与随机扰
群面/ 案例分析工具 1. 解决产业分析问题的模型【波特的五因素(Porter’s 5 Forces)】波特的五因素模型在战略分析模型工具中可能是最著名、运用最广泛的。其主要是运用在分析公司行业竞争能力和行业地位。这五个因素分别是:现在竞争者的竞 争潜在进入者的威胁供应商能力消费者能力替代品威胁行业中竞争越弱,行业 的整体利润就越高。同样的,在一个公司在整个行业中有很强的战略和市场地位,能够很好地 抵御以上五个因素的风险,该公司可以获得的利润就能够超过行业的平均水平。波特五因素 模型主要运用于:当你需要了解一个新的行业或者市场结构化/系统化你现有行业知识 定义一个行业,并明确你的研究对象在这个行业中的地位现在我们来看一下这个模型的具 体内容:使用波特模型有一个限制条件:此模型是静态分析,很少考虑行业内的一些变化,例 如行业内的政策等政治因素的变化等等。因此该模型一般只是辅助你开始对行业进行战略分析。可以适当结合其他的工具进行更为全面的分析。行业内竞争对手的策略和市场战新进入者 威胁潜在市场进入者和略,重点在于行业增长率,产品新进入者对市场可和品牌差异程度,退出行业竞争能造成的冲击的障碍供应商讨价还价的能力购买者讨价还价的能力 现有行业竞争者替代品生产的威胁消费者/购买者偏好的改变和讨供应商的讨价还价能 力以价还价的能力的改变主要因素及对企业会产生的压力。有购买数量大小,产品差异性, 主要考虑:更换供应商难信息掌握程度易程度,替代产品可能性和规模经济产品和科技是 否会替代现有产品或对现有产品造成竞争压力。取代的可能型多大。主要考虑替代成本。 2. 解决利润下降、企业经营发生变化的模型【根源分析模型】想了解某个企业的经营现象的变化是如何产生的,仅仅问几个问题是不够的,根源分析是一种组织性很强的且逻辑缜密的方法,通过“相互独立,完全穷尽”的方式进行分析使得你的分析结果更有说服力。根源分析可以十分广泛地应用于解决很多的问题,最典型的就是“利润下降”问题。我们来看一个以下的示例。利润下降了成本上升了?收入减少了?固定成本增多了?可变成本增多了?产品价格下降了?产品销量下降了?新投入设备了?原材料?竞争对手变强了?市场萎缩了?事实上,根源分析法可以解决的问题还远不止于此,例如:为什么我们的客户盈利率几乎是同行业平均水平的两部?为什么分销商不到我们这里进行采购?以后面这个例子为例而言针对“为什么分销商不到
计量经济学实验报告实验二:放宽基本假定模型 姓名: 班级: 序号: 学号:
1. 问题描述:2009年我国各地区城镇居民家庭人均全年消费性支出Y 与人均全年家庭工薪收入X1、人均全年经营净收入X2、及其他来源的收入X3之间的关系。 2. 理论模型:μββββ++++=3322110X X X Y 3. 数据
1.数据分析:33^ 22^ 11^ 0^ ^ X X X Y ββββ+++= 2. 参数假设: 321^ 4677.08458.06004.0800.1195X X X Y +++= (2.40) (11.72) (3.48) (4.04) 95.02=R 19.160=F 76.1..=W D Dependent Variable: Y Method: Least Squares Date: 12/08/11 Time: 22:15 Sample: 1 31 Included observations: 31 Variable Coefficient Std. Error t-Statistic Prob. X1 0.600363 0.051233 11.71839 0.0000 X2 0.845763 0.242822 3.483054 0.0017 X3 0.467674 0.115879 4.035888 0.0004 C 1195.800 497.9180 2.401601 0.0235 R-squared 0.946806 Mean dependent var 11628.97 Adjusted R-squared 0.940896 S.D. dependent var 2978.791 S.E. of regression 724.1850 Akaike info criterion 16.12789 Sum squared resid 14159986 Schwarz criterion 16.31292 Log likelihood -245.9822 F-statistic 160.1925 Durbin-Watson stat 1.763913 Prob(F-statistic) 0.000000
企业环境分析必备模型: 1. PEST:分析宏观环境,考虑policy,economy,society,teconology四个方面 2. Porter's diamond:分析特定国家地区环境,如新进入某国市场,考虑factor conditions, demand conditions, supporting and related industry, firm strategy and structure四个因素 3. Market segmentation: 通常按地域、人口统计学、经济状况、心理、行为划分,也可按维护客户成本等因素划分 4. 4P:分析市场组合,production,price,place,promotion 5. convergence:分析所在市场环境,横轴分为供应商推动和消费者拉动两维度,纵轴为新旧技术可并存和新技术取代旧技术两维度 6. Porter's five force: 分析所处竞争环境,new entrant, substitute, power of supplier, power of customer, rivalry五因素 7. life cycle: 分析产品或企业所处地位,introduction,growth,maturity,decline四阶段 8. BCG matrix波士顿矩阵:分析产品或子公司增长速度和市场份额,可结合财务信息计算和life cycle使用,分为problem child,star,cash cow,dog四种 9. SWOT:这个几乎适用于所有案例,但由于过于笼统,一般需要其他模型辅助 10. Value chain:分析企业竞争优势,首要活动分为inbound logistics,operations,outbound logistics,marketing,service,辅助活动包括infrastructure,HR,technology,procurement 11.stakeholder mapping:分析对不同利益相关方的态度,企业社会责任问题中重点使用,分为interest和power两个维度 企业发展战略选择: 12. 赢得竞争三大策略:cost-leadership,differentiation,focus。三策略根据产品价格和质量不同应用于不同市场。 13. Ansoff's matrix:针对新旧产品和市场采取不同战略,diversification(横纵向一体化,进军全新领域),market development(新细分市场,海外市场),products development(改进现有产品,为现有客户设计新产品),market penetration,consolidation,withdrawal 14. 企业扩张方式(大小面包题必备):自己逐步成长,并购,联营,战略联盟,连锁店 这些模型只列了简略的要点,毕竟都是很著名的模型,具体使用在网上很容易搜到,大家分析案例时可以灵活使用。由于是lz自己的总结,又不充分的大家再补充哈!! 认真攒rp~~~ case总共6页双面打印讲的是RTS作为一个成立8年的公司为中小客户节省通信成本主营业务有设备安装管理服务还有一个ongoing fees没看懂然后是客户饼图最大的一个客户逐渐份额变小另一个则成为了最大客户份额比以前的还要多然后就是4年利润表近两年利润