第五章:异方差性(作业)
- 格式:doc
- 大小:541.50 KB
- 文档页数:13

选择题:1. G-Q 检验的局限性在于() A. 该方法适用于大样本B. 该方法无法判断异方差由哪一个变量引起C. 该方法只能检验单调递增或单调递减形式的异方差D. 以上三种说法都正确。
2. 模型遗漏重要变量的可能后果包括() A. 产生异方差性 B. 产生多重共线性 C. 产生序列自相关性D. 误差项与解释变量相关E. 误差项非正态3. 模型包含无关变量的可能后果包括() A. 产生异方差性 B. 产生多重共线性 C. 产生序列自相关性D. 误差项与解释变量相关E. 误差项非正态4. 那些检验方法可以判断异方差性由哪一个变量引起?()A. G-Q 检验B. White 检验C. ARCH 检验D. Glejser 检验E. 以上四种方法皆可5. ****对于模型0112233i i i i i Y X X X u ββββ=++++ ,在使用white 方法检验异方差性时,若要得到可靠的检验结果,则所需要的样本数至少为()A. 30B. 34C. 11D. 406. ***为了弥补White 检验对自由度损失过重的情况,人们提出了如下形式的辅助回归:22123ˆˆi i i ie Y Y αααν=+++ 则下列说法正确的是:( )A. 原假设是:0123:0H ααα=== ;B. 原假设是:023:0H αα== ;C. 检验统计量为F 统计量;D. 检验统计量为2nR ( );E. ˆiY 为多元线性回归的拟合值7. 关于ARCH 方法检验异方差性,说法正确的是() A. 可以应用在截面数据和时间序列数据中;B. ARCH 检验的辅助回归是自回归条件异方差过程;C. 样本数的数目;D. 检验统计量是2()n p R - ,其中2R 为原模型的可决系数。
8. 若Glejser 检验结果显示对于i i i e X ν= ,F 检验的p 值为0.005,而对于1i i ie X βν=+ ,F 检验的p 值为0.15, 则考虑在进行加权最小二乘估计时,选用的权重i w 为()A. i iw X =; B. 1i iw X =; C. i i w X =; D. 2i i w X =. 9. 仅在异方差存在时,会对以下哪些产生影响?()A. OLS 的无偏性;B. OLS 的一致性;C. OLS 的有效性;D. 显著性检验;E. 区间预测 10. 对模型进行对数变换是常用的模型修订的方法,有关对数变换描述错误的是() A. 可以用来修正异方差性 B. 可以用来修正多重共线性 C. 可以用来修正序列自相关性D. 对变量取对数时要注意取对数后变量符合经济意义。

第五章 异方差二、简答题1.异方差的存在对下面各项有何影响? (1)OLS 估计量及其方差; (2)置信区间;(3)显著性t 检验和F 检验的使用。
2.产生异方差的经济背景是什么?检验异方差的方法思路是什么?3.从直观上解释,当存在异方差时,加权最小二乘法(WLS )优于OLS 法。
4.下列异方差检查方法的逻辑关系是什么? (1)图示法 (2)Park 检验 (3)White 检验5.在一元线性回归函数中,假设误差方差有如下结构:()i i i x E 22σε=如何变换模型以达到同方差的目的?我们将如何估计变换后的模型?请列出估计步骤。
三、计算题1.考虑如下两个回归方程(根据1946—1975年美国数据)(括号中给出的是标准差):t t t D GNP C 4398.0624.019.26-+=e s :(2.73)(0.0060) (0.0736)R ²=0.999t t t GNP D GNP GNP C ⎥⎦⎤⎢⎣⎡-+=⎥⎦⎤⎢⎣⎡4315.06246.0192.25 e s : (2.22) (0.0068)(0.0597)R ²=0.875式中,C 为总私人消费支出;GNP 为国民生产总值;D 为国防支出;t 为时间。
研究的目的是确定国防支出对经济中其他支出的影响。
(1)将第一个方程变换为第二个方程的原因是什么?(2)如果变换的目的是为了消除或者减弱异方差,那么我们对误差项要做哪些假设? (3)如果存在异方差,是否已成功地消除异方差?请说明原因。
(4)变换后的回归方程是否一定要通过原点?为什么? (5)能否将两个回归方程中的R ²加以比较?为什么?2.1964年,对9966名经济学家的调查数据如下:资料来源:“The Structure of Economists’ Employment and Salaries”, Committee on the National Science Foundation Report on the Economics Profession, American Economics Review, vol.55, No.4, December 1965.(1)建立适当的模型解释平均工资与年龄间的关系。



计量经济学课件第五章异方差性第五章异方差性1 / 80计量经济学课件第五章 异方差性 2 / 80引子:更为接近真实的结论是什么?根据四川省2000年21个地市州医疗机构数及人口数资料,分析医疗机构及人口数量的关系,建立卫生医疗机构数及人口数的回归模型。
对模型估计的结果如下:ˆ Yi -563.0548 5.3735 X i(291.5778) (0.644284) t (-1.931062) (8.340265) R2 0.785456 R 2 0.774146 F 69.56003式中 Y 表示卫生医疗机构数(个), X 表示人口数量(万人)。
计量经济学课件第五章 异方差性3 / 80模型显示的结果和问题 ●人口数量对应参数的标准误差较小;● t 统计量远大于临界值,可决系数和修正的可决系数结果较好,F 检验结果明显显著;表明该模型的估计效果不错,可以认为人口数量每增加1万人,平均说来医疗机构将增加5.3735人。
然而,这里得出的结论可能是不可靠的,平均说来每增加1万人口可能并不需要增加这样多的医疗机构,所得结论并不符合真实情况。
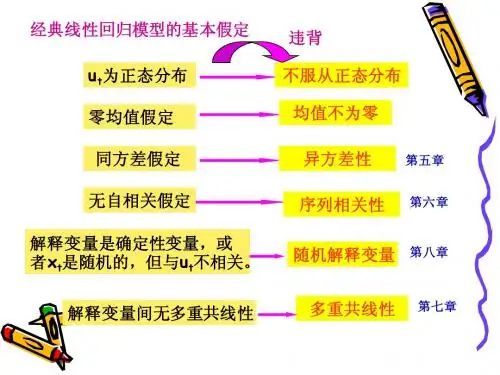
有什么充分的理由说明这一回归结果不可靠呢?更为接近真实的结论又是什么呢?计量经济学课件第五章 异方差性4 / 80第五章 异 方 差 性 本章讨论四个问题:●异方差的实质和产生的原因●异方差产生的后果●异方差的检测方法●异方差的补救计量经济学课件第五章 异方差性5 / 80第一节 异方差性的概念 本节基本内容:●异方差性的实质●异方差产生的原因计量经济学课件第五章 异方差性6 / 80一、异方差性的实质 同方差的含义同方差性:对所有的 i (i1,2,..., n)有: Var(ui ) = 2 (5.1) 因为方差是度量被解释变量 Y 的观测值围绕回归线 E(Yi ) 1 2 X 2i 3 X 3i ... k X ki (5.2) 的分散程度,因此同方差性指的是所有观测值的分散程度相同。

第五章课后答案5.1(1)因为22()i i f X X =,所以取221iiW X =,用2i W 乘给定模型两端,得 312322221i i ii i i i Y X u X X X X βββ=+++ 上述模型的随机误差项的方差为一固定常数,即22221()()i i i iu Var Var u X X σ==(2)根据加权最小二乘法,可得修正异方差后的参数估计式为***12233ˆˆˆY X X βββ=-- ()()()()()()()***2****22232322322*2*2**2223223ˆi i i i i i i i i i i i i i i i i iW y x W x W y x W x x W x W x W x x β-=-∑∑∑∑∑∑∑()()()()()()()***2****23222222332*2*2**2223223ˆii ii i i iii i i ii i i i i iW y x W x W y x W x x Wx W x W x x β-=-∑∑∑∑∑∑∑其中22232***23222,,iii i i i iiiW XW X W Y X X Y WWW ===∑∑∑∑∑∑******222333i i i i i x X X x X X y Y Y=-=-=- 5.2(1)2222211111 ln()ln()ln(1)1 u ln()1Y X Y X Yu u X X X u ββββββββββ--==+≈=-∴=+[ln()]0()[ln()1][ln()]11E u E E u E u μ=∴=+=+=又(2)[ln()]ln ln 0 1 ()11i i iiP P i i i i P P i i E P E μμμμμμμ===⇒====∑∏∏∑∏∏不能推导出所以E 1μ()=时,不一定有E 0μ(ln )= (3) 对方程进行差分得:1)i i βμμ--i i-12i i-1lnY -lnY =(lnX -X )+(ln ln 则有:1)]0i i μμ--=E[(ln ln5.3(1)该模型样本回归估计式的书写形式为:Y = 11.44213599 + 0.6267829962*X (3.629253) (0.019872)t= 3.152752 31.5409720.944911R =20.943961R = S.E.=9.158900 DW=1.597946 F=994.8326(2)首先,用Goldfeld-Quandt 法进行检验。


第五章-异方差性-答案第五章 异方差性一、判断题1. 在异方差的情况下,通常预测失效。
( T )2. 当模型存在异方差时,普通最小二乘法是有偏的。
( F )3. 存在异方差时,可以用广义差分法进行补救。
(F )4. 存在异方差时,普通最小二乘法会低估参数估计量的方差。
(F )5. 如果回归模型遗漏一个重要变量,则OLS 残差必定表现出明显的趋势。
( T )二、单项选择题1.Goldfeld-Quandt 方法用于检验( A )A.异方差性B.自相关性C.随机解释变量D.多重共线性2.在异方差性情况下,常用的估计方法是( D )A.一阶差分法B.广义差分法C.工具变量法D.加权最小二乘法3.White 检验方法主要用于检验( A )A.异方差性B.自相关性C.随机解释变量D.多重共线性4.下列哪种方法不是检验异方差的方法( D )A.戈德菲尔特——匡特检验B.怀特检验C.戈里瑟检验D.方差膨胀因子检验5.加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即( B )A.重视大误差的作用,轻视小误差的作用B.重视小误差的作用,轻视大误差的作用C.重视小误差和大误差的作用D.轻视小误差和大误差的作用6.如果戈里瑟检验表明,普通最小二乘估计结果的残差与有显著的形式的相关关系(满足线性模型的全部经典假设),则用加权最小二乘法估计模型参数时,权数应为( B )A. B. C. D. 7.设回归模型为,其中()2i2i x u Var σ=,则b 的最有效估计量为( D )i e i x i i i v x e +=28715.0i v i x 21i x i x 1ix 1i i i u bx y +=A. B. C. D. ∑=i i x y n 1b ˆ 8.容易产生异方差的数据是( C )A. 时间序列数据B.平均数据C.横截面数据D.年度数据9.假设回归模型为i i i u X Y ++=βα,其中()2i 2i X u Var σ=,则使用加权最小二乘法估计模型时,应将模型变换为( C )。
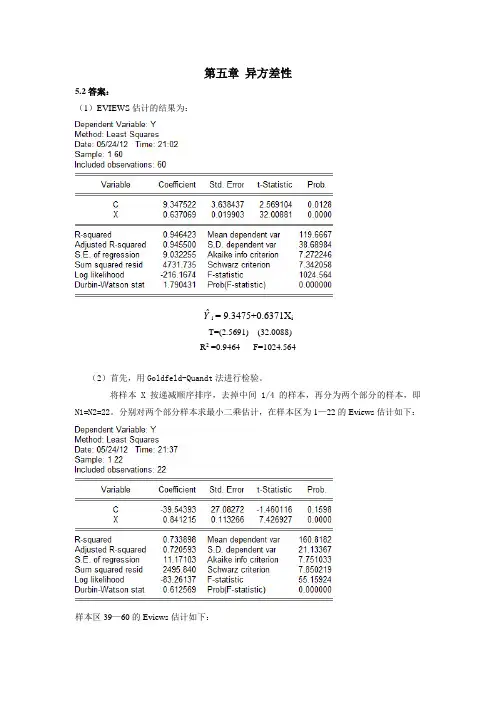
第五章异方差性5.2答案:(1)EVIEWS估计的结果为:Yˆi= 9.3475+0.6371X iT=(2.5691) (32.0088)R2 =0.9464 F=1024.564(2)首先,用Goldfeld-Quandt法进行检验。
将样本X按递减顺序排序,去掉中间1/4的样本,再分为两个部分的样本,即N1=N2=22。
分别对两个部分样本求最小二乘估计,在样本区为1—22的Eviews估计如下:样本区39—60的Eviews估计如下:得到两个部分各自的残差平方和,即∑e 12 =2495.840∑e 22 =603.0148求F 统计量为: F=∑∑e e 2221=2495.840/603.0148=4.1390给定α=0.05,查F 分布表,得临界值为F 0.05=(20,20)=2.12.比较临界值与F 统计量值,有F =4.1390>F 0.05=(20,20)=2.12,说明该模型的随机误差项存在异方差。
其次,用White 法进行检验结果如下:给定α=0.05,在自由度为2下查卡方分布表,得χ2=5.9915。
比较临界值与卡方统计量值,即nR2=10.8640>χ2=5.9915,同样说明模型中的随机误差项存在异方差。
(2)用权数W1=1/X,作加权最小二乘估计,得如下结果用White法进行检验得如下结果:F-statistic 3.138491 Probability 0.050925Obs*R-squared 5.951910 Probability 0.050999。
比较临界值与卡方统计量值,即nR2=5.9519<χ2=5.9915,说明加权后的模型中的随机误差项不存在异方差。
其估计的结果为:Yˆi= 10.3705+0.6309X iT=(3.9436) (34.0467)R2 =0.21144 F=1159.176 DW=0.95855.3答案:(1)EVIEWS估计结果:Yˆi= 179.1916+0.7195X iT=(0.808709) (15.74411)R2 =0.895260 F=247.8769 DW=1.461684 (2)利用White方法检验异方差,则White检验结果见下表:由上述结果可知,该模型存在异方差。
南阳师范学院课时教学计划式中Y表示卫生医疗机构数(个),X表示人口数量(万人)。
●人口数量对应参数的标准误差较小;一、异方差性产生的原因 例1:考察居民家庭收入与储蓄的关系时,用i x 表示第i 个家庭的收入量,用i y 表示第i 个家庭的储蓄量,假设这种关系是线性关系,因而储蓄函数模型可以表示为:i i i u x a y ++=β在这一问题中,收入低的家庭,他们除了必要的支出之外剩余较少,解:先在同方差假定下,应用OLS 对模型进行估计:i i x y8940.01347.1ˆ+-= 96786.02=R 利用此模型可算出yˆ和e 的值,最终得出e 与x 的等级相关系数:异方差性相关理论的解释一、异方差不影响估计量的线性和无偏性,但导致有效性不能满足 (1)线性无偏 证明:()()()()YX U βββββ'='=+'=+-1-1-1X X X (满足线性)那么E()=(无偏性)''X X X X X XU2.有效性 证明:()()()()()()()()()()()()()()()()()()122222222222222222222222222222222222222==i ii i j ii ji i i i i i jjx u x x u x x xx xx f x x x f x x x f x xx xx x βββββσββσσσσβ=++⎛⎫- ⎪+ ⎪ ⎪-⎝⎭-=---==--∑∑∑∑∑∑∑∑i 以一元回归为例假设y 直接做普通最小二乘回归,可得的估计量为:在没有自相关和U 与X 线性无关的假定下:易知的方差为:VAR 当存在异方差时:VAR ()()()()()()()()()2222222222222222=11,jii ji i jx xx f x xx x x f x xx β---->-∑∑∑∑∑由于难以保证所以,异方差的存在就容易使得的方差被高估或低估。
第五章 异方差性一、判断题1. 在异方差的情况下,通常预测失效。
( T )2. 当模型存在异方差时,普通最小二乘法是有偏的。
( F )3. 存在异方差时,可以用广义差分法进行补救。
(F )4. 存在异方差时,普通最小二乘法会低估参数估计量的方差。
(F )5. 如果回归模型遗漏一个重要变量,则OLS 残差必定表现出明显的趋势。
( T ) 二、单项选择题1.Goldfeld-Quandt 方法用于检验( A )A.异方差性B.自相关性C.随机解释变量D.多重共线性 2.在异方差性情况下,常用的估计方法是( D )A.一阶差分法B.广义差分法C.工具变量法D.加权最小二乘法 3.White 检验方法主要用于检验( A )A.异方差性B.自相关性C.随机解释变量D.多重共线性 4.下列哪种方法不是检验异方差的方法( D )A.戈德菲尔特——匡特检验B.怀特检验C.戈里瑟检验D.方差膨胀因子检验 5.加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即( B )A.重视大误差的作用,轻视小误差的作用B.重视小误差的作用,轻视大误差的作用C.重视小误差和大误差的作用D.轻视小误差和大误差的作用 6.如果戈里瑟检验表明,普通最小二乘估计结果的残差与有显著的形式的相关关系(满足线性模型的全部经典假设),则用加权最小二乘法估计模型参数时,权数应为( B ) A. B.C. D.7.设回归模型为,其中()2i2i x u Var σ=,则b 的最有效估计量为( D )A. B.C. D. ∑=ii x y n 1b ˆ8.容易产生异方差的数据是( C )A. 时间序列数据B.平均数据C.横截面数据D.年度数据9.假设回归模型为i i i u X Y ++=βα,其中()2i 2i X u Var σ=,则使用加权最小二乘法估计模i e i x i i i v x e +=28715.0i v i x 21i x i x 1ix 1i i i u bx y +=∑∑=2ˆxxy b 22)(ˆ∑∑∑∑∑--=x x n y x xy n b xyb=ˆ型时,应将模型变换为( C )。
第五章:异方差性(作业)标准化文件发布号:(9312-EUATWW-MWUB-WUNN-INNUL-DQQTY-为了研究中国出口商品总额EXPORT 对国内生产总值GDP 的影响,搜集了1990~2015年相关的指标数据,如表所示。
(1) 根据以上数据,建立适当线性回归模型。
(2) 试分别用White 检验法与ARCH 检验法检验模型是否存在异方差 (3) 如果存在异方差,用适当方法加以修正。
解:(1)100,000200,000300,000400,000500,000600,000700,000XYDependent Variable: Y Method: Least SquaresDate: 04/18/20 Time: 15:38 Sample: 1991 2015Included observations: 25VariableCoefficient Std. Error t-Statistic Prob.C X R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid +10 Schwarz criterionLog likelihood Hannan-Quinn criter. F-statisticDurbin-Watson stat Prob(F-statistic)模型回归的结果:^673.0863 4.0611iX i Y =-+()(0.043820.1368)t =-20.9463,25R n ==(2)white: 该模型存在异方差Heteroskedasticity Test: WhiteF-statistic Prob. F(2,22) Obs*R-squared Prob. Chi-Square(2) Scaled explained SS Prob. Chi-Square(2)Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 04/18/20 Time: 17:45 Sample: 1991 2015 Included observations: 25Variable Coefficient Std. Error t-StatisticProb. C +09 +09 X^2 X R-squared Mean dependent var +09 Adjusted R-squared . dependent var +09. of regression +09 Akaike info criterion Sum squared resid +20 Schwarz criterion Log likelihood Hannan-Quinn criter. F-statistic Durbin-Watson stat Prob(F-statistic)ARCH 检验:该模型存在异方差Heteroskedasticity Test: ARCHF-statisticProb. F(1,22)Obs*R-squaredProb. Chi-Square(1)Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 04/18/20 Time: 19:55Sample (adjusted): 1992 2015Included observations: 24 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C+08+08RESID^2(-1)R-squared Mean dependent var+09 Adjusted R-squared . dependent var+09 . of regression+09 Akaike info criterionSum squared resid+20 Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)(3)修正:加权最小二乘法修正Dependent Variable: YMethod: Least SquaresDate: 04/18/20 Time: 20:46Sample: 1991 2015Included observations: 25Weighting series: W2Weight type: Inverse variance (average scaling)Variable Coefficient Std. Error t-Statistic Prob.CXWeighted StatisticsR-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid+09 Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic) Weighted mean dep.Unweighted StatisticsR-squaredMean dependent var Adjusted R-squared . dependent var . of regressionSum squared resid+10修正后进行white 检验:Heteroskedasticity Test: WhiteF-statistic Prob. F(2,22) Obs*R-squared Prob. Chi-Square(2) Scaled explained SS Prob. Chi-Square(2)Test Equation: Dependent Variable: WGT_RESID^2 Method: Least Squares Date: 04/18/20 Time: 20:41 Sample: 1991 2015 Included observations: 25 Collinear test regressors dropped from specificationVariable Coefficient Std. Error t-StatisticProb. C X*WGT^2 WGT^2R-squared Mean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid +16 Schwarz criterion Log likelihood Hannan-Quinn criter. F-statistic Durbin-Watson stat Prob(F-statistic)修正后的模型为^10781.17 3.931606iX i Y =+(4.925821)(20.47667)t =20.9480,25R n ==表的数据是2011年各地区建筑业总产值(X )和建筑业企业利润总额(Y )。
第五章 异方差性 思考题5.1 简述什么是异方差 ? 为什么异方差的出现总是与模型中某个解释变量的变化有关 ?5.2 试归纳检验异方差方法的基本思想 , 并指出这些方法的异同。
5.3 什么是加权最小二乘法 , 它的基本思想是什么 ?5.4 产生异方差的原因是什么 ? 试举例说明经济现象中的异方差性。
5.5 如果模型中存在异方差性 , 对模型有什么影响 ? 这时候模型还能进行应用分析吗 ?5.6 对数变化的作用是什么 ? 进行对数变化应注意什么 ? 对数变换后模型的经济意义有什么变化 ? 5.7 怎样确定加权最小二乘法中的权数 ? 练习题5.1 设消费函数为 12233i i i i Y X X u βββ=+++其中,i Y 为消费支出;2i X 为个人可支配收入;3i X 为个人的流动资产;i u 为随机误差项 ,并且 E(i u )=0,Var(i u )= 222i X σ( 其中2σ为常数) 。
试回答以下问题 : 1) 选用适当的变换修正异方差 , 要求写出变换过程 ; 2) 写出修正异方差后的参数估计量的表达式。
5.2 根据本章第四节的对数变换 , 我们知道对变量取对数通常能降低异方差性 , 但需对这种模型的随机误差项的性质给予足够的关注。
例如 ,设模型为21Y X u ββ=,对该模型中 的变量取对数后得12ln ln ln ln Y X u ββ=++1) 如果ln u 要有零期望值 ,u 的分布应该是什么 ? 2) 如果 E(u )=1, 会不会 E(ln u )=0? 为什么 ? 3) 如果 E(ln u ) 不为零 , 怎样才能使它等于零 ?5.3 表 5.8 给出消费 Y 与收入 X 的数据 , 试根据所给数据资料完成以下问题 :1) 估计回归模型12Y X u ββ=++中的未知参数1β和2β, 并写出样本回归模型的书写格式;2) 试用 GOMeld-Quandt 法和 White 法检验模型的异方差性 3 3) 选用合适的方法修正异方差。
为了研究中国出口商品总额EXPORT 对国内生产总值GDP 的影响,搜集了1990~2015年相关的指标数据,如表所示。
资料来源:《国家统计局网站》(1) 根据以上数据,建立适当线性回归模型。
(2) 试分别用White 检验法与ARCH 检验法检验模型是否存在异方差 (3) 如果存在异方差,用适当方法加以修正。
解:(1)100,000200,000300,000400,000500,000600,000700,000XYDependent Variable: Y Method: Least Squares Date: 04/18/20 Time: 15:38Sample: 1991 2015Included observations: 25VariableCoefficientStd. Error t-Statistic Prob.C XR-squared Mean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid +10 Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson stat Prob(F-statistic)模型回归的结果:^673.0863 4.0611iX i Y =-+()(0.043820.1368)t =-20.9463,25R n ==(2)white: 该模型存在异方差Heteroskedasticity Test: WhiteF-statistic Prob. F(2,22) Obs*R-squared Prob. Chi-Square(2) Scaled explained SSProb. Chi-Square(2)Test Equation:Dependent Variable: RESID^2 Method: Least Squares Date: 04/18/20 Time: 17:45 Sample: 1991 2015Included observations: 25VariableCoefficientStd. Error t-Statistic Prob.C +09+09X^2XR-squared Mean dependent var+09 Adjusted R-squared. dependent var+09. of regression+09Akaike info criterionSum squared resid+20Schwarz criterionLog likelihoodHannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)ARCH检验:该模型存在异方差Heteroskedasticity Test: ARCHF-statistic Prob. F(1,22)Obs*R-squared Prob. Chi-Square(1)Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 04/18/20 Time: 19:55Sample (adjusted): 1992 2015Included observations: 24 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C+08+08RESID^2(-1)R-squared Mean dependent var+09 Adjusted R-squared. dependent var+09. of regression+09Akaike info criterionSum squared resid+20Schwarz criterionLog likelihoodHannan-Quinn criter.F-statistic Durbin-Watson stat Prob(F-statistic)(3)修正:加权最小二乘法修正Dependent Variable: YMethod: Least SquaresDate: 04/18/20 Time: 20:46Sample: 1991 2015Included observations: 25Weighting series: W2Weight type: Inverse variance (average scaling)Variable Coefficient Std. Error t-Statistic Prob.CXWeighted StatisticsR-squared Mean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared resid+09Schwarz criterionLog likelihoodHannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)Weighted mean dep.Unweighted StatisticsR-squared Mean dependent varAdjusted R-squared. dependent var. of regression Sum squared resid+10修正后进行white检验:Heteroskedasticity Test: WhiteF-statistic Prob. F(2,22)Obs*R-squared Prob. Chi-Square(2)Scaled explained SSProb. Chi-Square(2)Test Equation:Dependent Variable: WGT_RESID^2 Method: Least Squares Date: 04/18/20 Time: 20:41 Sample: 1991 2015Included observations: 25Collinear test regressors dropped from specificationVariableCoefficientStd. Error t-Statistic Prob.C X*WGT^2 WGT^2R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid +16 Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson stat Prob(F-statistic)修正后的模型为^10781.17 3.931606iX i Y =+(4.925821)(20.47667)t =20.9480,25R n ==表的数据是2011年各地区建筑业总产值(X )和建筑业企业利润总额(Y )。
数据来源:国家统计局网站根据样本资料建立回归模型,分析建筑业企业利润总额与建筑业总产值的关系,并判断模型是否存在异方差,如果有异方差,选用最简单的方法加以修正。
解:散点图:0100200300400500600700X Y建立线性回归模型:Dependent Variable: Y Method: Least Squares Date: 04/18/20 Time: 21:16 Sample: 1 31Included observations: 31VariableCoefficientStd. Error t-Statistic Prob.C XR-squared Mean dependent var Adjusted R-squared. dependent var. of regressionAkaike info criterionSum squared resid Schwarz criterionLog likelihoodHannan-Quinn criter.F-statistic Durbin-Watson statProb(F-statistic)white检验:Heteroskedasticity Test: WhiteF-statistic Prob. F(2,28)Obs*R-squared Prob. Chi-Square(2)Scaled explained SS Prob. Chi-Square(2)Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 04/18/20 Time: 21:19Sample: 1 31Included observations: 31Variable Coefficient Std. Error t-Statistic Prob.CX^2XR-squared Mean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared resid Schwarz criterionLog likelihoodHannan-Quinn criter.F-statistic Durbin-Watson stat Prob(F-statistic)模型存在异方差模型修正:加权最小二乘法Dependent Variable: YMethod: Least SquaresDate: 04/18/20 Time: 21:24Sample: 1 31Included observations: 31Weighting series: W2Weight type: Inverse variance (average scaling)Variable Coefficient Std. Error t-Statistic Prob.CXWeighted StatisticsR-squared Mean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared resid Schwarz criterionLog likelihoodHannan-Quinn criter.F-statistic Durbin-Watson stat Prob(F-statistic)Weighted mean dep.Unweighted StatisticsR-squared Mean dependent var Adjusted R-squared. dependent var. of regression Sum squared resid Durbin-Watson stat加权后进行white检验:Heteroskedasticity Test: WhiteF-statistic Prob. F(2,28)Obs*R-squared Prob. Chi-Square(2) Scaled explained SS Prob. Chi-Square(2)Test Equation:Dependent Variable: WGT_RESID^2Method: Least SquaresDate: 04/18/20 Time: 21:25Sample: 1 31Included observations: 31Collinear test regressors dropped from specificationVariableCoefficientStd. Error t-Statistic Prob.C X*WGT^2 WGT^2R-squared Mean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid Schwarz criterion Log likelihood Hannan-Quinn criter.F-statistic Durbin-Watson stat Prob(F-statistic)修正成功,修正后的模型为:^0.0207340.034505iX i Y =+(0.015338)(14.11049)t =20.8729,31R n ==表是2015年中国各地区人均可支配收入(X )与居民每百户汽车拥有量(Y )的数据。