spss相关分析案例多因素方差分析
- 格式:doc
- 大小:140.00 KB
- 文档页数:8

使用SPSS软件进行多因素方差分析使用SPSS软件进行多因素方差分析一、引言多因素方差分析是一种重要的统计方法,用于分析多个自变量对因变量的影响。
它可以帮助研究人员确定不同因素对研究对象的差异产生的影响,以及这些因素之间是否存在交互作用。
SPSS软件是一款功能强大且易于使用的统计分析工具,可以帮助用户在进行多因素方差分析时快速、准确地得出结果。
本文将介绍使用SPSS软件进行多因素方差分析的步骤,并通过一个案例来具体说明。
二、SPSS软件介绍SPSS(Statistical Package for the Social Sciences)是一款专业的统计分析软件,被广泛应用于社会科学、医学、商业等领域。
它提供了丰富的统计方法和分析工具,并具备数据清洗、可视化、报告生成等功能。
在多因素方差分析中,SPSS 可以帮助用户进行方差分析表的生成、方差分析的可视化、方差齐性检验和事后比较等操作,大大简化了分析过程。
三、多因素方差分析的步骤1. 数据准备:将需要分析的数据录入SPSS软件,并确定自变量和因变量的测量水平。
一般自变量为定类变量,而因变量可以是定量或定类变量。
2. 方差分析表的生成:选择“分析”菜单中的“一元方差分析”选项,然后将因变量添加到依赖变量框中,将自变量添加到因子框中。
接下来,点击“选项”按钮设置参数,如设定显著性水平和置信区间。
点击“确定”后,SPSS会生成方差分析表。
3. 方差分析的可视化:在方差分析表中,用户可以查看各个因素的主效应和交互作用,以及统计指标如F值、p值等。
此外,SPSS还提供了绘制效应图、交互作用图等功能,帮助用户更直观地理解分析结果。
4. 方差齐性检验:方差齐性检验用于验证因变量的变异是否在各组间具有相同的方差。
SPSS软件可以通过选择“分析”菜单中的“Compare Means”选项,进而进行多个组间方差齐性检验。
5. 事后比较:当发现方差分析存在显著差异时,需要进一步进行事后比较以确定差异所在。
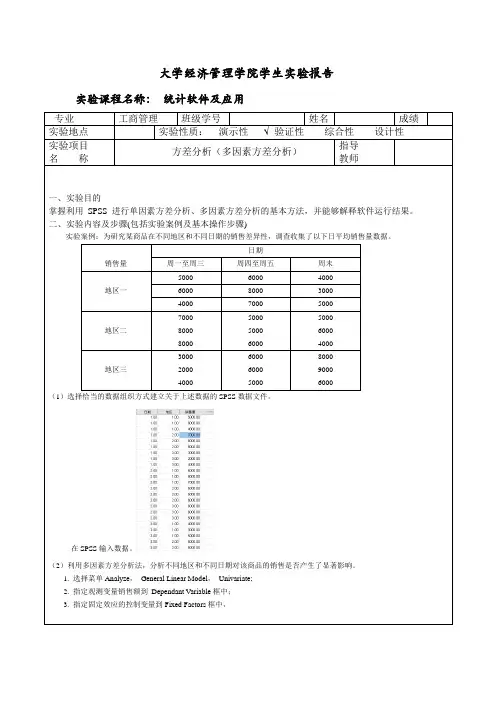
大学经济管理学院学生实验报告实验课程名称:统计软件及应用专业工商管理班级学号姓名成绩实验地点实验性质:演示性 验证性综合性设计性实验项目名称方差分析(多因素方差分析)指导教师一、实验目的掌握利用SPSS 进行单因素方差分析、多因素方差分析的基本方法,并能够解释软件运行结果。
二、实验内容及步骤(包括实验案例及基本操作步骤)实验案例:为研究某商品在不同地区和不同日期的销售差异性,调查收集了以下日平均销售量数据。
销售量日期周一至周三周四至周五周末地区一5000 6000 4000 6000 8000 3000 4000 7000 5000地区二700080008000500050006000500060004000地区三300020004000600060005000800090006000(1)选择恰当的数据组织方式建立关于上述数据的SPSS数据文件。
在SPSS输入数据。
(2)利用多因素方差分析法,分析不同地区和不同日期对该商品的销售是否产生了显著影响。
1. 选择菜单Analyze,General Linear Model,Univariate;2. 指定观测变量销售额到Dependant Variable框中;3. 指定固定效应的控制变量到Fixed Factors框中,4. OK,得到分析结果。
(3)地区和日期是否对该商品的销售产生了交互影响?若没有显著的交互影响,则试建立非饱和模型进行分析,并与饱和模型进行对比。
三、实验结论(包括SPSS输出结果及分析解释)SPSS输出的多因素方差分析的饱和模型分析:表的第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是方差;第五列是F检验统计量的观测值;第六列是检验统计量的概率P-值。
F日期,,F地区,F日期*地区概率P-值分别为0.254,0.313,0.000。
如果显著性水平α为0.05,由于F日期、,F地区大于显著性水平α,所以不应拒绝原假设,不同地区和不同日期对该商品没有显著性影响。

SPSS多因素方差分析体育统计与SPSS读书笔记(八)—多因素方差分析(1)具有两个或两个以上因素的方差分析称为多因素方差分析。
多因素是我们在试验中会经常遇到的,比如我们前面说的单因素方差分析的时候,如果做试验的不是一个年级,而是多个年纪,那就成了双因素了:不同教学方法的班级,不同年级。
如果再加上性别上的因素,那就成了三因素了。
如果我们把实验前和试验后的数据用一个时间的变量来表示,那又多了一个时间的因素。
如果每个年级都是不同的老师来上,那又多了一个老师的因素,等等等等,所以我们在设计试验的时候都要进行充分考虑,并确定自己只研究哪些因素。
下面用例子的形式来说说多因素方差分析的运用。
还是用前面说单因素的例子,前面的例子说了只在五年级抽三个班进行不同教学方法的试验,现在我们还要在初二和高二各抽三个班进行不同教学方法的试验。
形成年级和不同教学法班级双因素。
分析:1.根据实验方案我们划出双因素分析的表格,可以看出每个单元格都是有重复数据(也就是不只一个数据),年级不同教学方法的班级定性班定量班定性定量班五年级页脚内容1(班级每个人)(班级每个人)(班级每个人)初中二年级(班级每个人)(班级每个人)(班级每个人)高中二年级(班级每个人)(班级每个人)(班级每个人)2.因为有重复数据,所以存在在数据交互效应的可能。
我们来看看交效应的含义:如果在A因素的不同水平上,B因素对因变量的影响不同,则说明A、B两因素间存在交互作用。
交互作用是多因素实验分析的一个非常重要的内容。
如因素间存在交互作用而又被忽视,则常会掩盖因素的主效应的显著性,另一方面,如果对因变量Y,因素A与B之间存在交互作用,则已说明这两个因素都Y对有影响,而不管其主效应是否具有显著性。
在统计模型中考虑交互作用,是系统论思想在统计方法中的反映。
在大多数场合,交互作用的信息比主效应的信息更为有用。
根据上面的判断。
根据上面的说法,我也无法判断是否有交互作用,不像身高和体重那么直接。
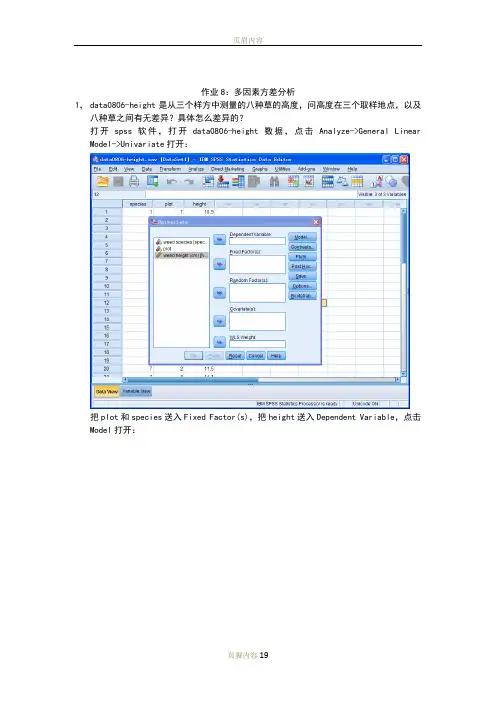
作业8:多因素方差分析1,data0806-height是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及八种草之间有无差异?具体怎么差异的?打开spss软件,打开data0806-height数据,点击Analyze->General Linear Model->Univariate打开:把plot和species送入Fixed Factor(s),把height送入Dependent Variable,点击Model打开:选择Full factorial,Type III Sum of squares,Include intercept in model(即全部默认选项),点击Continue回到Univariate主对话框,对其他选项卡不做任何选择,结果输出:因无法计算MM M rror,即无法分开MM intercept 和MM error,无法检测interaction 的影响,无法进行方差分析,重新Analyze->General Linear Model->Univariate打开:选择好Dependent Variable和Fixed Factor(s),点击Model打开:点击Custom,把主效应变量species和plot送入Model框,点击Continue回到Univariate 主对话框,点击Plots:把date送入Horizontal Axis,把depth送入Separate Lines,点击Add,点击Continue 回到Univariate对话框,点击Options:把OVERALL,species, plot送入Display Means for框,选择Compare main effects,Bonferroni,点击Continue回到Univariate对话框,输出结果:可以看到:SS species=33.165,df species=7,MS species=4.738;SS plot=33.165,df plot=7,MS plot=4.738;SS error=21.472,df error=14,MS error=1.534;Fspecies=3.089,p=0.034<0.05;Fplot=12.130,p=0.005<0.01;所以故认为在5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。

作业8:多因素方差分析1,data0806-height是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及八种草之间有无差异?具体怎么差异的?打开spss软件,打开data0806-height数据,点击Analyze->General Linear Model->Univariate 打开:把plot和species送入Fixed Factor(s),把height送入Dependent Variable,点击Model 打开:选择Full factorial,Type III Sum of squares,Include intercept in model(即全部默认选项),点击Continue回到Univariate主对话框,对其他选项卡不做任何选择,结果输出:因无法计算rror,即无法分开intercept和error,无法检测interaction的影响,无法进行方差分析,重新Analyze->General Linear Model->Univariate打开:选择好Dependent Variable和Fixed Factor(s),点击Model打开:点击Custom,把主效应变量species和plot送入Model框,点击Continue回到Univariate主对话框,点击Plots:Univariate对话框,点击Options:把OVERALL,species, plot送入Display Means for框,选择Compare main effects,Bonferroni,点击Continue回到Univariate对话框,输出结果:可以看到:SS species=33.165,df species=7,MS species=4.738;SS plot=33.165,df plot=7,MS plot=4.738;SS error=21.472,df error=14,MS error=1.534;Fspecies=3.089,p=0.034<0.05;Fplot=12.130,p=0.005<0.01;所以故认为在5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。


![多因素方差分析_数据分析方法及应用──基于SPSS和EXCEL环境_[共7页]](https://uimg.taocdn.com/9427d29de45c3b3566ec8b1a.webp)
118 果进行比较;图3-37 “单因素ANOVA:两两比较”对话框R-E-G-W F,即借助F检验进行多重比较检验;R-E-G-W Q,即在正态分布的范围内进行多重配对比较检验;S-N-K,用Student Range分布进行各个组间的均值配对比较;Tukey,即真实显著差异检验,用Student Range分布进行各个组间配对比较,用所有配对比较误差率作为实验误差率。
Tukey s-b,用Student Range分布进行各个组间配对比较,其精确度是前二者的均值。
②如果已知方差非齐性,则可借助图3-37底部的4种多重检验方法。
Tamhane’s T2检验,借助T检验进行配对比较检验;Dunnett’s T3检验,正态分布下的配对检验;Games-Howell检验,对应方差非齐性的检验;Dunnett’s C检验,正态分布下的配对比较检验。
(3)右上角的【选项】按钮单击右上角的【选项】按钮,启动如图3-34所示的“选项”对话框,以便进行具体设置。
在如图3-34所示的“单因素方差分析-选项”对话框中,可以把【方差同质性检验】复选框选中,以便在方差分析结束后能输出“方差齐性检验”的表格,掌握数据序列的不同分组的方差是否齐性。
在如图3-34所示的“单因素方差分析-选项”对话框中,也可以把【均值图】复选框选中,以便在方差分析结束后能输出各个分组的均值折线图。
3.3.3 多因素方差分析1.多因素方差分析的概念(1)多因素方差分析的定义多因素方差分析是研究在多个因素同时发生影响的过程中,因变量(即结果变量)在多因素的各级水平下的均值是否存在显著性差异。
在此过程中,既要考虑单个因素对方差的影响,还要考虑若干个因素交叉发生作用的影响力。
与单因素方差分析的目标相同,多因素方差分析也借助F值(组间均方值与组内均方值之比)判断多因素方差分析的均值差异是否显著,从而发现因素变量对因变量的影响能力。
119 (2)多因素方差分析的关键流程对于多因素方差分析,要求因变量满足正态分布且为高测度数据,各分组在因变量上的取值满足方差齐性,而且允许多个因素变量同时参与检验过程。

SPSS重复测量地多因素方差分析报告
一、实验结果的总体分析
1、总体数据及描述性统计
首先我们来分析实验的总体数据,主要包括对被试者的一般信息及参
与实验的各个变量的描述统计及分布情况。
基本信息:本次实验共有30名参与者,其平均年龄为31岁。
其中男
性占比为53.3,女性占比为46.7%。
变量的描述性统计:检测变量的标准差为0.614,最小值为1.4,最
大值为3.0,平均值为2.2,中位数为2.2,偏度为0.00,峰度为0.61变量的分布情况:根据变量分布图可以看出,变量的分布情况接近正
态分布。
2、数据检验
完成数据收集后需要对数据进行检验,以确保数据的准确性和可靠性。
检验的方法包括残差检验、异方差分析以及 Shapiro-Wilk 检验等。
经过
检验后,发现所有数据满足检验条件,可以用于进一步的分析。
二、多因素重复测量方差分析
本次实验使用多因素重复测量方差分析,用来检验被试者对不同环境
条件下的反应差异。
由于本次实验中因素为环境条件A、B、C,为三因素
实验,所以本次实验的实验设计为3X3实验设计。
1、方差分析表
计算完毕后,计算结果如下所示:。
SPSS多因素方差分析一、问题对小白鼠喂以三种不同的营养素,目的是了解不同营养素增重的效果。
采用随机区组设计方法,以窝别作为划分区组的特征,以消除遗传因素对体重增长的影响。
现将同品系同体重的24只小白鼠分为8个区组,每个区组3只小白鼠。
三周后体重增量结果(克)列于下表,问小白鼠经三种不同营养素喂养后所增体重有无差别?SPSS软件版本:18.0中文版。
二、统计操作:1、建立数据文件变量视图:建立3个变量,如下图数据视图:如下图:区组号用1-8表示,营养素号用1-3表示。
数据文件见“小白鼠喂3种不同的营养素增重数量.sav”,可以直接使用。
2、统计分析菜单选择:分析-> 一般线性模型-> 单变量点击进入“单变量”对话框将“体重”选入“因变量”框,“区组”、“营养素”选入固定因子框点击右边“模型”按钮,进入“单变量:模型对话框”点击“设定”单选按钮,在“构建项”下拉菜单中选择“主效应”把左边的因子与协变量框中区组和营养素均选入右边的模型框中其余选项取默认值就行,点击“继续”按钮,回到“单变量”界面点击“两两比较”按钮,进入下面对话框将左边框中“区组”、“营养素”均选入右边框中再选择两两比较的方法,LSD、S-N-K,Duncan为常用的三种方法,点击“继续”按钮回到“单变量”主界面。
点击“选项”按钮勾选“统计描述”及“方差齐性检验”,设置显著性水平,点击“继续”按钮,回到“单变量”主界面点击下方“确定”按钮,开始分析。
3、结果解读这是一个所分析因素的取值情况列表。
变量的描述性分析这是一个典型的方差分析表,有2个因素“营养素”和“区组”,首先是所用方差分析模型的检验,F值为11.517,P小于0.05,因此所用的模型有统计学意义,即认为至少有一个因素对体重增长有显著影响,可以用它来判断模型中系数有无统计学意义;第二行是截距,它在我们的分析中没有实际意义,忽略即可;第三行是变量是区组,P<0.001,可见有统计学意义(即认为区组对体重增长有显著影响),不过通常我们关心的也不是他;第四行是我们真正要分析的营养素,非常遗憾,它的P值为0.084,没有统计学意义(即认为营养素对体重增长没有显著影响)。
作业8:多因素方差分析1,data0806-height是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及八种草之间有无差异?具体怎么差异的?打开spss软件,打开data0806-height数据,点击Analyze->General Linear Model->Univariate打开:把plot和species送入Fixed Factor(s),把height送入Dependent Variable,点击Model打开:选择Full factorial,Type III Sum of squares,Include intercept in model(即全部默认选项),点击Continue回到Univariate主对话框,对其他选项卡不做任何选择,结果输出:因无法计算MM M rror,即无法分开MM intercept 和MM error,无法检测interaction的影响,无法进行方差分析,重新Analyze->General Linear Model->Univariate打开:选择好Dependent Variable和Fixed Factor(s),点击Model打开:点击Custom,把主效应变量species和plot送入Model框,点击Continue回到Univariate主对话框,点击Plots:把date送入Horizontal Axis,把depth送入Separate Lines,点击Add,点击Continue 回到Univariate对话框,点击Options:把OVERALL,species, plot送入Display Means for框,选择Compare main effects,Bonferroni,点击Continue回到Univariate对话框,输出结果:可以看到:SS species=33.165,df species=7,MS species=4.738;SS plot=33.165,df plot=7,MS plot=4.738;SS error=21.472,df error=14,MS error=1.534;Fspecies=3.,p=0.034<0.05;Fplot=12.130,p=0.005<0.01;所以故认为在5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。
SPSS操作多因素方差分析实验题目:多因素方差分析实验类型:基本操作实验目的:掌握方差分析的基本原理及方法实验内容:某种果汁在不同地区的销售数据,调查人员统计了易拉罐包装和玻璃包装的饮料在三个地区的销售金额,利用多因素方差分析,分析销售地区和包装方式对销售金额的影响。
(1)试计算因变量在各个因素下的描述性统计量及在各个因素水平下的误差方差的Levene检验。
(2)对数据进行多因素方差分析,分析不同包装的和地区下的效果是否相同,及交互作用的效应是否显著。
实验步骤:步骤一:打开数据集,选择“分析”—“一般线性模型”—“单变量”,将操作框打开;步骤二:将“销售额”选为“因变量”,“包装形式”和“购物地区”选为“固定因子”,然后选择“选项”,将“描述统计”和“方差齐性检验”勾选。
得到描述性统计量和Levene检验,和主体间效应的结果。
实验结果:(1)试计算因变量在各个因素下的描述性统计量及在各个因素水平下的误差方差的Levene检验。
描述性统计量因变量:销售额包装形式购物地区均值标准偏差Ndime nsion1 易拉罐dimensio n2地区A 413.0657 90.86574 35地区B 440.9647 98.23860 120地区C 407.7747 69.33334 30总计430.3043 93.47877 185 玻璃瓶dimensio n2地区A 343.9763 100.47207 35地区B 361.7205 90.46076 102地区C 405.7269 80.57058 29总计365.6671 92.64058 166 总计dimensio n2地区A 378.5210 101.25839 70地区B 404.5552 102.48440 222地区C 406.7681 74.42114 59总计399.7352 98.40821 351描述性统计量的分析结果:在只考虑包装形式的情况下:易拉罐:均值=430.3043 ,标准偏差=93.47877玻璃瓶:均值=365.6671,标准偏差=92.64058在只考虑地区差异的情况下:地区A:均值=378.5210,标准偏差=101.25839地区B:均值=404.5552,标准偏差=102.4844地区C:均值=406.7681,标准偏差=74.42114由结果可知,在只考虑包装形式的情况下,采用易拉罐的形式进行销售额会有明显较高的销售额,且两种形式之间的偏差值相差不大,即采用易拉罐的形式进行销售会更有利于销售;在只考虑地区差异的情况下,三个地区之间在地区B 和地区C进行销售的销售额很接近,但是地区C的标准偏差明显比另外两个地区要小,所以建议应该在地区C加大销售力度。
SPSS 生物统计分析示例3 (多因素方差分析)例一:番薯种植的两因素方差分析通过SPSS 统计分析推断种植密度(因素一)、品种(因素二)对亩产量(鲜重)的影响数据文件“sweetpotato-wet.sav ”品种5532304徐薯18 胜利百号 红东 利丰3号 二黄C-17C-3039(脱毒胜百)1)方差分析:Analyze→ General linear model→Univariate…结果输出:方差分析表Tests of Between-Subjects Effects Dependent Variable: 每亩鲜产a R Squared = .747 (Adjusted R Squared = .502)无交互效应,密度因素不显著,品种因素极显著2)多重比较(Post Hoc)结果LSD法:Multiple Comparisons Dependent Variable: 每亩鲜产Based on observed means.* The mean difference is significant at the .05 level.2304553C-17C-3023040.0580.394徐薯180.276黄色阴影为差异极显著(P<0.01**),绿色阴影为差异显著(P<0.05*),其余无显著差异Duncan法:每亩鲜产品种NSubset1 2 3 4 5红东 6 982.982509C-30 6 1183.224658 1183.224658C-17 6 1246.833306 1246.83330639(脱毒胜百) 6 1378.033689 1378.033689 1378.033689553 6 1469.473579 1469.473579胜利百号 6 1717.694931 1717.694931二黄 6 1764.122633 1764.1226332304 6 1819.723120 1819.723120 1819.723120 徐薯18 6 1999.091807 1999.091807 利丰3号 6 2229.200327 Sig. .090 .218 .065 .225 .070 Means for groups in homogeneous subsets are displayed.Based on Type III Sum of SquaresThe error term is Mean Square(Error) = 128993.994.a Uses Harmonic Mean Sample Size = 6.000.b Alpha = .05.每亩鲜产Duncan品种NSubset1 2 3 4红东 6 982.982509C-30 6 1183.224658 1183.224658C-17 6 1246.833306 1246.83330639(脱毒胜百) 6 1378.033689 1378.033689 1378.033689553 6 1469.473579 1469.473579 1469.473579胜利百号 6 1717.694931 1717.694931 1717.694931 二黄 6 1764.122633 1764.122633 1764.122633 2304 6 1819.723120 1819.723120 1819.723120 徐薯18 6 1999.091807 1999.091807 利丰3号 6 2229.200327 Sig. .042 .010 .011 .033 Means for groups in homogeneous subsets are displayed.Based on Type III Sum of SquaresThe error term is Mean Square(Error) = 128993.994.a Uses Harmonic Mean Sample Size = 6.000.b Alpha = .01.汇总表:品种每亩产率Alpha=0.01 Alpha=0.05红东982.982509 a AC-30 1183.224658 ab ABC-17 1246.833306 ab AB39(脱毒胜百) 1378.033689 abc ABC553 1469.473579 abc BC胜利百号1717.694931 bcd CD二黄1764.122633 bcd CD2304 1819.723120 bcd CDE徐薯18 1999.091807 cd DE利丰3号2229.200327 d E注:不同字母代表用邓肯新复极差法多重比较中差异显著利丰3号徐薯18 2304 二黄胜利百号553 39(脱毒胜百) C-17 C-30二黄2304徐薯18黄色阴影为差异极显著(P<0.01**),绿色阴影为差异显著(P<0.05*),其余无显著差异。
作业8:多因素方差分析1,data0806-height是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及八种草之间有无差异?具体怎么差异的?打开spss软件,打开data0806-height数据,点击Analyze->General Linear Model->Univariate打开:把plot和species送入Fixed Factor(s),把height送入Dependent Variable,点击Model打开:选择Full factorial,Type III Sum of squares,Include intercept in model(即全部默认选项),点击Continue回到Univariate主对话框,对其他选项卡不做任何选择,结果输出:因无法计算MM M rror,即无法分开MM intercept 和MM error,无法检测interaction 的影响,无法进行方差分析,重新Analyze->General Linear Model->Univariate打开:选择好Dependent Variable和Fixed Factor(s),点击Model打开:点击Custom,把主效应变量species和plot送入Model框,点击Continue回到Univariate 主对话框,点击Plots:把date送入Horizontal Axis,把depth送入Separate Lines,点击Add,点击Continue 回到Univariate对话框,点击Options:把OVERALL,species, plot送入Display Means for框,选择Compare main effects,Bonferroni,点击Continue回到Univariate对话框,输出结果:可以看到:SS species=33.165,df species=7,MS species=4.738;SS plot=33.165,df plot=7,MS plot=4.738;SS error=21.472,df error=14,MS error=1.534;Fspecies=3.089,p=0.034<0.05;Fplot=12.130,p=0.005<0.01;所以故认为在5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。
本次实验采用2005年东部、中部和西部各地区省份城镇居民月平均消费类型划分的数据(课本139页),将东部、中部和西部看作三个不同总体,31个数据分别来自于这三个总体。
本人对这三个不同地区的城镇居民月平均消费水平进行比较,并选取人均粮食支出、副食支出、烟酒及饮料支出、其他副食支出、衣着支出、日用杂品支出、水电燃料支出和其他非商品支出八个指标来衡量城镇居民月平均消费情况。
在进行比较分析之前,首先对个数据是否服从多元正态分布进行检验,输出结果为:
表一
如表一,因为该例中样本数n=31<2000,所以此处选用Shapiro-Wilk统计量。
由正态性检验结果的sig.值可以看到,人均粮食支出、烟酒及饮料支出、其他副食支出、水电燃料支出和其他非商品支出均明显不遵从正态分布(Sig.值小于,拒绝服从正态分布的原假设),因此,在下面分析中,只对人均副食支出、衣着支出和日用杂品支出三项指标进行比较,并认为这三个变量组成的向量都遵从正态
分布,并对城镇居民月平均消费状况做出近似的度量。
另外,正态性的检验还可以通过Q-Q图来实现,此时应判别数据点是否与已知直线拟合得好。
如果数据点均落在直线附近,说明拟合得好,服从正态分布,反之,不服从。
具体情况这里不再赘述。
下面进行多因素方差分析:
一、多变量检验
表二
由地区一栏的(即第二栏)所列几个统计量的Sig.值可以看到,无论从那个统计量来看,三个地区的城镇居民月平均消费水平都是有显著差别的(Sig.值小于,拒绝地区取值不同,对Y,即城镇居民月平均消费水平的取值没有显著影响的原假设)。
二、主体间效应检验
表三
如表三,可以看到三个指标地区一栏的(即第三栏)Sig.值分别为、、,说明三个地区在人均衣着支出指标上没有明显的差别(Sig.值大于,不拒绝地区取值不同,对指标的取值没有显著影响的原假设),反之,而在人均副食支出和日用杂品支出指标上有显著差别。
三、多重比较
表四
Contrast Results (K Matrix)
地区 Simple Contrast a
Dependent Variable 人均副食支出(元/人)
人均日用杂品支出(元
/人)
人均衣着支出(元/人)
Level 1 vs. Level 3 Contrast Estimate
Hypothesized Value
0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig.
.001
.036
.517
95% Confidence Interval for Difference
Lower Bound
.173
Upper Bound
Level 2 vs. Level 3 Contrast Estimate
Hypothesized Value
0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig.
.668
.343
.638
95% Confidence Interval for Difference
Lower Bound
Upper Bound
表四
Contrast Results (K Matrix)
地区 Simple Contrast a
Dependent Variable 人均副食支出(元/人)
人均日用杂品支出(元
/人)
人均衣着支出(元/人)
Level 1 vs. Level 3 Contrast Estimate
Hypothesized Value
0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig.
.001
.036
.517
95% Confidence Interval for Difference
Lower Bound
.173
Upper Bound
Level 2 vs. Level 3 Contrast Estimate
Hypothesized Value
0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig.
.668
.343
.638
95% Confidence Interval for Difference
Lower Bound
Upper Bound
a. Reference category = 3
如表四,在显著水平下,东部和西部的人均副食支出(Sig.值为)和日用杂品支出(Sig.值为)指标有明显差别(小于,拒绝原假设),而在人均衣着支出(Sig.值为)指标上没有明显的差别。
并且东部的人均副食支出、衣着支出和日
用杂品支出三项指标均高于西部地区,说明东部的城镇居民月平均消费水平较西部来说,高出很多,符合实际的情况。
另外,中部和西部的人均副食支出、衣着支出和日用杂品支出(Sig.值分别为、、,均大于显著水平)三个指标均无明显差别,但中部的人均副食支出和日用杂品支出指标低于西部地区,人均衣着支出指标高于西部,说明中、西部的城镇居民月平均消费水平差不多,但消费结构有差异,符合实际的情况。
表五
表五是上面多重比较可信性的度量,由Sig.的值可以看到(均小于),比较检验是可信的。
四、协方差阵相等检验
表六
Box's Test of Equality of
Covariance Matrices a
Box's M
F
df112
df2
Sig..085
Tests the null hypothesis that
the observed covariance
matrices of the dependent
variables are equal across
groups.
a. Design: + 地区
如表六,是协方差阵相等检验,检验统计量是Box’s M,由Sig.值>可以看到,可以认为三个地区(总体)的协方差阵是相等的。
表七
表七给出了各地区同一指标误差的方差检验,在水平下,人均副食支出、衣着支出和日用杂品支出(Sig.值分别为、、,均大于)三个指标的误差平方在三个地区间均没有显著差别,这说明,除了地区因素外,其他因素对人均副食支出、衣着支出和日用杂品支出三个指标的影响很小。
综上所述,对三个地区的城镇居民月平均消费水平进行了具体的比较分析,所得结果表明,东部地区较中、西部地区的城镇居民月平均消费水平差别较大,远高于中、西部两个地区。
而中部和西部之间的城镇居民月平均消费水平差别不太明显,主要是消费结构有所不同,这说明西部地区在国家施行西部大开发政策之后发展很快,人民生活水平显著提高,赶上中部地区,体现政策的有效性。