统计学原理公式及应用
- 格式:doc
- 大小:125.00 KB
- 文档页数:12

数理统计定理及公式数理统计是应用数学的一个分支,研究收集、整理、分析和解释数据的方法和技术。
在数理统计中,有一些重要的定理和公式,用于描述和计算概率、分布、样本统计量和假设检验。
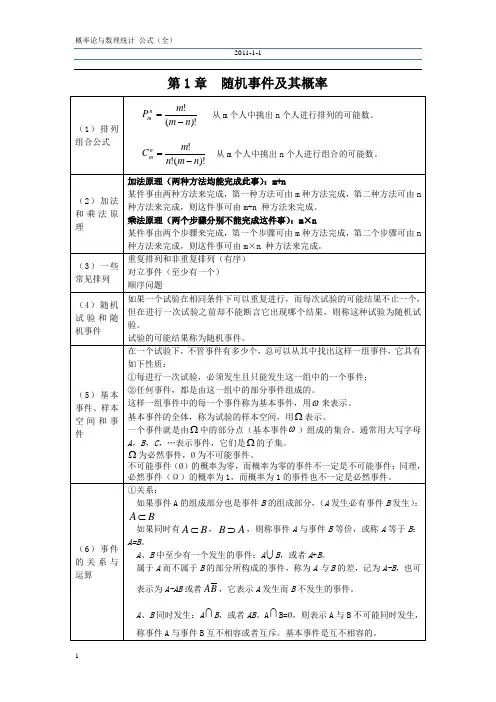
1. 大数定理(Law of Large Numbers):在重复多次独立实验的情况下,随着实验次数的增多,样本均值会趋近于总体均值。
大数定理是数理统计的基础之一,它是对样本均值的收敛性质的描述。
数学表达式为:其中,X1、X2、..、Xn是来自总体的独立同分布的随机变量,μ是总体的均值,n是样本大小。
2. 中心极限定理(Central Limit Theorem):在若干相互独立的随机变量的和的情况下,随着随机变量数量的增大,和的分布趋向于服从正态分布。
中心极限定理是数理统计中非常重要的一个定理,它不仅在理论上解释了为什么正态分布在自然界中具有如此重要的地位,而且提供了许多统计学中方法的理论基础。
数学表达式为:其中,X1、X2、..、Xn是独立同分布的随机变量,μ是总体的均值,σ是总体的标准差,n是样本大小。
3. 伯努利分布(Bernoulli Distribution):又称为两点分布,是最简单的概率分布之一、伯努利分布描述了只有两个可能结果的离散随机试验,如抛硬币的结果。
数学表达式为:其中,p表示事件出现的概率,1-p表示事件不出现的概率,X为随机变量。
4. 正态分布(Normal Distribution):也称为高斯分布,是统计学中最常见的连续型概率分布之一、正态分布具有钟形曲线,均值和标准差决定了曲线的位置和形状。
它在自然界中广泛存在,并且许多现实世界中的随机变量都可以近似地服从正态分布。
数学表达式为:其中,μ是均值,σ是标准差,x是随机变量。
5. t分布(Student's t-distribution):t分布是用于小样本情况下对总体均值进行假设检验的重要工具。
它形状类似于正态分布,但是更扁平,并且具有更重的尾部,以补偿小样本情况下对总体均值的估计不准确性。

一.加权算术平均数和加权调和平均数的计算加权算术平均数: ∑∑=fxf x 或 ∑∑=ffxx加权调和平均数: ∑∑∑∑==fxf x m m x频数也称次数。
在一组依大小顺序排列的测量值中,当按一定的组距将其分组时出现在各组内的测量值的数目,即落在各类别(分组)中的数据个数。
再如在3.14159265358979324中,…9‟出现的频数是3,出现的频率是3/18=16.7% 一般我们称落在不同小组中的数据个数为该组的频数,频数与总数的比为频率。
频数也称“次数”,对总数据按某种标准进行分组,统计出各个组内含个体的个数。
而频率则每个小组的频数与数据总数的比值。
在变量分配数列中,频数(频率)表明对应组标志值的作用程度。
频数(频率)数值越大表明该组标志值对于总体水平所起的作用也越大,反之,频数(频率)数值越小,表明该组标志值对于总体水平所起的作用越小。
掷硬币实验:在10次掷硬币中,有4次正面朝上,我们说这10次试验中…正面朝上‟的频数是4例题:我们经常掷硬币,在掷了一百次后,硬币有40次正面朝上,那么,硬币反面朝上的频数为____.解答,掷了硬币100次,40次朝上,则有100-40=60(次)反面朝上,所以硬币反面朝上的频数为60.一.加权算术平均数和加权调和平均数的计算加权算术平均数: ∑∑=fxf x 或 ∑∑=ffxxx 代表算术平均数;∑是总和符合;f 为标志值出现的次数。
加权算术平均数是具有不同比重的数据(或平均数)的算术平均数。
比重也称为权重,数据的权重反映了该变量在总体中的相对重要性,每种变量的权重的确定与一定的理论经验或变量在总体中的比重有关。
依据各个数据的重要性系数(即权重)进行相乘后再相加求和,就是加权和。
加权和与所有权重之和的比等于加权算术平均数。
加权平均数 = 各组(变量值 × 次数)之和 / 各组次数之和 = ∑xf / ∑f加权调和平均数: ∑∑∑∑==fxf xm m x加权算术平均数以各组单位数f 为权数,加权调和平均数以各组标志总量m 为权数但计算内容和结果都是相同的。

《统计学原理》常用公式汇总及计算题目分析第一部分常用公式第三章统计整理a)组距=上限-下限b)组中值=(上限+下限)÷2c)缺下限开口组组中值=上限-1/2邻组组距d)缺上限开口组组中值=下限+1/2邻组组距第四章综合指标i.相对指标1。
结构相对指标=各组(或部分)总量/总体总量2。
比例相对指标=总体中某一部分数值/总体中另一部分数值3。
比较相对指标=甲单位某指标值/乙单位同类指标值4。
强度相对指标=某种现象总量指标/另一个有联系而性质不同的现象总量指标5.计划完成程度相对指标=实际数/计划数=实际完成程度(%)/计划规定的完成程度(%)ii.平均指标1.简单算术平均数:2。
加权算术平均数或iii。
变异指标1.全距=最大标志值-最小标志值2.标准差: 简单σ= ;加权σ=3。
标准差系数:第五章抽样估计1。
平均误差:重复抽样:不重复抽样:2。
抽样极限误差3。
重复抽样条件下:平均数抽样时必要的样本数目成数抽样时必要的样本数目4.不重复抽样条件下:平均数抽样时必要的样本数目第七章相关分析1.相关系数2。
配合回归方程y=a+bx3.估计标准误:第八章指数分数一、综合指数的计算与分析(1)数量指标指数此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。
(—)此差额说明由于数量指标的变动对价值量指标影响的绝对额。
(2)质量指标指数此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度.(—)此差额说明由于质量指标的变动对价值量指标影响的绝对额.加权算术平均数指数=加权调和平均数指数=(3)复杂现象总体总量指标变动的因素分析相对数变动分析:= ×绝对值变动分析:—= (—)×(—)第九章动态数列分析一、平均发展水平的计算方法:(1)由总量指标动态数列计算序时平均数①由时期数列计算②由时点数列计算在间断时点数列的条件下计算:a.若间断的间隔相等,则采用“首末折半法”计算。

高考统计公式知识点总结统计学是一门研究数据收集、分析和解释的学科,其应用广泛而深入。
在高中阶段,学生们接触到的统计学知识主要集中在一些基本的统计公式上。
这些公式在高考中经常出现,对于顺利完成数学考试至关重要。
下面是对高考统计公式知识点的一些总结,希望对广大考生有所帮助。
1.概率概率是统计学中的一个重要概念,表示某个事件发生的可能性。
常用的概率公式包括:- 事件的概率公式:P(A) = n(A) / n(S),其中P(A)表示事件A发生的概率,n(A)表示事件A包含的基本事件数,n(S)表示样本空间中的基本事件数。
- 对立事件的概率公式:P(A') = 1 - P(A),其中A'表示事件A的对立事件。
2.排列组合排列组合是统计学中另一个重要概念,用于计算有关事物的不同排列或组合方式的个数。
常用的排列组合公式包括:- 排列公式:A(n, m) = n! / (n-m)!,表示从n个元素中取出m个元素进行排列的方式总数。
- 组合公式:C(n, m) = n! / (m!(n-m)!),表示从n个元素中取出m个元素进行组合的方式总数。
3.均值和标准差均值和标准差是描述一组数据分布特征的指标。
常用的计算公式包括:- 均值公式:μ = (x1 + x2 + ... + xn)/ n,其中μ表示均值,x表示数据的观测值,n表示数据的总数。
- 标准差公式:σ = √( (x1 - μ)² + ... + (xn - μ)² )/ n,其中σ表示标准差。
4.正态分布正态分布是一种常见的概率分布,其形状呈钟形曲线,对于统计学的许多问题具有重要的应用。
正态分布的概率可以通过标准正态分布表来查找,也可以利用相关的计算公式计算。
在高考中,统计学是数学考试的一个重要组成部分。
掌握以上提到的统计公式,对于正确理解和解答与统计学有关的问题至关重要。
考生可以通过多做一些相关的题目,熟悉这些公式的应用,提升自己的解题能力,在考试中取得好成绩。


数。
)如:产量指数、销售量指数、生产指数、人数指数、运输量指数。
说明复杂现象总体的质量指标变动程度的相对数。
(说明总体内涵数量变动情况的相对数。
)例:价格指数、成本指数、工资水平指数、股票价格指数。
:平均数指数总体:即统计总体,是指客观存在的、在同一性质基础上结合起来的许多个别事物的整体。
总体单位:即构成统计总体的个别单位。
标志:即指表明总体单位特征的名称。
可分为品质标志和数量标志。
品质标志:说明总体单位质的特征,用属性表示(如:性别、民族、籍贯、工种) 数量标志:说明总体单位量的特征,用数值表示。
(如:年龄、工资额)数量标志的具体表现,统计上称为标志值(或变量值)指标(亦称统计指标):说明总体的综合数量特征。
包括指标名称和指标数值。
数量指标如:人口数、工业增加值、货运量等。
用绝对数表示。
质量指标如:人口的性别比例、单位产品成本、劳动生产率等。
用相对数或平均数表示。
:标志是说明总体单位特征的;指标是说明总体特征的。
标志中的品质标志不能用数量表示;而所有的指标都能用数量表示。
标志(指数量标志)不一定经过汇总,可直接取得;而指标(指数量指标)一定要经过汇总才能取得。
∑∑=pqpqK q1∑∑=111qpqpKpqkk kV qqσ=pkk kV ppσ=标志一般不具备时间、地点等条件;但完整的统计指标一定要讲明时间、地点、范围。
变异:标志在各总体单位具体表现的差异 —— 一般意义上的变异。
严格地说,变异仅指品质标志的不同具体表现。
如:性别为男或女。
变量:指可变的数量标志。
变量的具体数值表现即变量值。
按取值是否连续分—— 只能取整数的变量。
(如:人数,企业数,机器台数)—— 在整数之间可插入小数的变量。
(如:身高、体重、总产值、资金、利润等)例如:搜集国有及国有控股企业生产情况的资料时,每一个国有及国有控股企业是调查单位,也是填报单位;当搜集国有及国有控股企业中高精尖设备的使用情况的资料时,国有及国有控股企业中每一台高精尖设备是调查单位,而填报单位是每一个国有及国有控股企业。

统计学原理常用公式1.样本均值公式:样本均值是用来估计总体均值的一种方法,公式为:\bar{x} = \frac{{\sum_{i=1}^n x_i}}{n}\]其中,\(\bar{x}\) 是样本均值,\(x_i\) 是第 \(i\) 个观察值,\(n\) 是样本容量。
2.样本方差公式:样本方差是用来估计总体方差的一种方法,公式为:s^2 = \frac{{\sum_{i=1}^n (x_i - \bar{x})^2}}{n-1}\]其中,\(s^2\) 是样本方差,\(x_i\) 是第 \(i\) 个观察值,\(\bar{x}\) 是样本均值,\(n\) 是样本容量。
计算样本方差时使用的是无偏估计公式。
3.标准差公式:标准差是样本方差的平方根,公式为:s = \sqrt{s^2}\]其中,\(s\)是样本标准差。
4.离差平方和公式:离差平方和是指每个观察值与均值之差的平方的总和,公式为:\sum_{i=1}^n (x_i - \bar{x})^2\]5.切比雪夫不等式:切比雪夫不等式给出了随机变量与其均值之间的关系,公式为:P(,X-\mu,\geq k\sigma) \leq \frac{1}{k^2}\]其中,\(X\) 是随机变量,\(\mu\) 是均值,\(\sigma\) 是标准差,\(k\) 是大于零的常数。
6.二项分布的期望值和方差公式:二项分布用于描述在\(n\)次独立重复试验中成功的次数的概率分布。
其期望值和方差分别为:E(X) = np\]Var(X) = np(1-p)\]其中,\(X\)是二项分布随机变量,\(n\)是试验次数,\(p\)是单次试验成功的概率。
7.正态分布的概率密度函数和累积分布函数公式:正态分布描述了大部分自然现象中的连续性随机变量的分布。
f(x) = \frac{1}{{\sqrt{2\pi}\sigma}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]F(x) = \frac{1}{2}\left[1 + \text{erf}\left(\frac{x -\mu}{\sqrt{2}\sigma}\right)\right]\]其中,\(x\) 是正态分布的随机变量,\(\mu\) 是均值,\(\sigma\) 是标准差,\(\text{erf}\) 是误差函数。

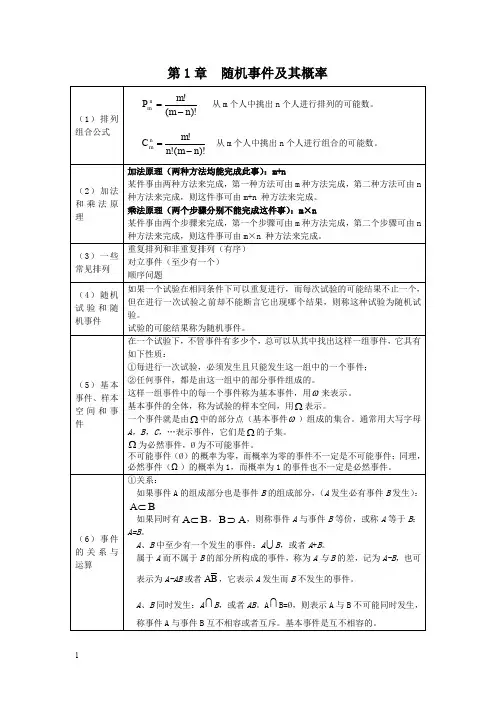
位值平均数计算公式1众数:是一组数据中出现次数最多的变量值L m o:代表众数组下限;丄1二fm 。
一 fm °—1 :代表众数组频数一众数组前一组频数dm 0 :代表组距; 2 ~ f m 0 一 f m 0 1 :代表众数组频数一众数组后一组频数2、中位数:是一组数据按顺序排序后,处于中间位置上的变量值。
n 十1中位数位置分组向上累计公式:2Sme-1Sme-1 :代表中位数所在组之前各组的累计频数;fm e 代表中位数组频数;d m e代表组距3、四分位数:也称四分位点,它是通过三个点将全部数据等分为四部分,其中每部分包含25%处在25唏口 75%分位点上的数值就是四分位数。
实例数据总量:7, 15, 36, 39, 40, 41 一共6项Q1 的位置=(6+1) /4=1.75 Q2 的位置=(6+1) /2=3.5 Q3 的位置=3( 6+1) /4=5.25Q1 = 7+ ( 15-7 ) X( 1.75-1 ) =13, Q2 = 36+ ( 39-36 )X( 3.5-3 ) =37.5 , Q3 = 40+ ( 41-40 ) X( 5.25-5 ) =40.25组距式分组下限公式:M 。
A 1 A + A 1 2dm om em em eLm e 代表中位数组下限;其公式为:Q1 = Q 2(中位数)3(n 1) 4数值平均数计算公式1、简单算术平均数:是将总体单位的某一数量标志值之和除以总体单位。
3、加权算术平均数的频率:其公式为:x = X i 」X 2;次「"X\f4、调和平均数:由于只掌握每组某个标志的数值总和(M )而缺少总体单位数(f )的资 料,不冃匕直接采用加权算术平均数法计算干均数,贝U 应采用加权调和平 均数。
H = P其公式为:「mL ---X5、简单几何平均数: 就是n 个变量值(Xn )连乘积的n 次方根:标志变异绝对指标及成数计算公式、标志变异绝对指标:1、异众比率(又称离异比率或变差比,它是指非众数组的频数占总频数的比率)公式即,Vr2、极差(也称全距,它是一组数据的最大值与最小值这差其公式为:乂 X 「X 2nX n2、加权算术平均数:受各组组中值及各组变量值出现的频数(即权数 f )大小的影响,其公式为:x 1 f 〔 x 2 f 2f l f 2X i f i f inX x 2 x 36、加权几何平均数: 如果变量值较多,其出现的次数不同,则应米用加权几何平均数,其公式为: TxJ X 2f 2X n其公式为:n公式即:R 二X max 一X min3、平均差(总体各单位标志值对算数平均数的绝对离差的算术平均数,平均差是反映各 标志值对平均数的平均距离,平均差越大,说明总体各标志值越分散,平均差越 小,说明各标志值越集中),方差简便算法的公式即为:二2= x 2 一(x )2、是非标志的平均数、方差、标准差:是非标志:将总体分成具有某种性质和不具有某种性质的两部分,我们所关心的标志表现称为“是”,另一标志标现称为“非”。

标准差:未分组:n x x 2)(-∑=σ分组:ff x x ∑-∑=2)(σ 标准差离散系数:%100⨯=x v σσ 几何平均数:n n n x x x x G∏== 21(简单) f f f f n f f x x x x G n ∑∑∏== 2121(加权) 众数:)(2110下限公式d L M ⨯∆+∆∆+= )(2120上限公式d U M ⨯∆+∆∆-= L :众数组的下限;U :众数组的上限;1∆:众数组次数与前一组次数之差;2∆:众数组次数与后一组次数之差;d :组距 中位数:)(21下限公式i f S f L M mm e ⨯-∑+=- (上限公式)i f S f U M m m e ⨯-∑-=+12 L :中位数所在组的下限;U :中位数所在组的上限;m f :中位数所在组的次数;1S -m :中位数所在组的下限以前各组的累计次数;1+m S :中位数所在组的上限以后各组的累计次数;f ∑:总次数定基发展速度=某一固定时期水平报告期水平;环比发展速度=前一期水平报告期水平;增长速度=基期水平增长量=基期水平基期水平报告期水平-=1-基期水平报告期水平=发展速度-1;定基增长速度=1-=定基发展速度某一固定时期水平累计增长速度;环比增长速度=1-=环比发展速度前一期水平逐期增长量; 增长1%的绝对值=100前期水平;平均增长速度=平均发展速度-1 个体指数⎪⎩⎪⎨⎧==0101q q K p p K q p 数量:质量:综合指数⎪⎩⎪⎨⎧∑∑=∑∑=00011011p q p q K q p q p K q p 数量:质量:加权算术平均数指数⎪⎩⎪⎨⎧∑∑=∑∑=00001010k p q p q K q p q p k K q q p p 数量:质量: 加权调和平均数指数⎪⎩⎪⎨⎧∑∑=∑∑=q q p p k q p q p K k q p q p K 10101111数量:质量:总量指标⎪⎩⎪⎨⎧∑∑⨯∑∑=∑∑∑-∑+∑-∑=∑-∑101100010011101100010011)()(q p q p p q p q q p q p q p q p p q p q q p q p 相对数:绝对数: 平均指标⎪⎩⎪⎨⎧⨯=-+-=-01010101)()(x x x x x x x x x x x x n n n n 相对数:绝对数: 可变K (可变构成指数)=00011101f f x f f x x x ∑∑∑∑=固定K (固定构成指数)=1101111f f x f f x x x n ∑∑∑∑=结构K (结构影响指数)=0001100f f x f f x x x n ∑∑∑∑=。
数理统计中的重要公式整理正文:数理统计是一门研究统计学原理和方法的学科,其重要性不可忽视。
在数理统计中,有一些重要的公式被广泛应用于各类统计问题的求解和分析。
本文将对数理统计中的重要公式进行整理,以帮助读者更好地掌握和应用这些公式。
1. 概率论与数理统计基本公式1.1 概率论基本公式:(1) 加法法则:P(A ∪ B) = P(A) + P(B) − P(A ∩ B)(2) 乘法法则:P(A ∩ B) = P(A)P(B|A) = P(B)P(A|B)(3) 全概率公式:P(A) = ∑ P(A ∩ Bᵢ) = ∑ P(Bᵢ)P(A|Bᵢ)(4) 贝叶斯公式:P(A|B) = P(B|A)P(A) / P(B)1.2 数理统计基本公式:(1) 期望值公式:E(X) = ∑ XᵢP(Xᵢ)(2) 方差公式:Var(X) = E[(X - E(X))²] = E(X²) - [E(X)]²(3) 协方差公式:Cov(X, Y) = E[(X - E(X))(Y - E(Y))] = E(XY) -E(X)E(Y)(4) 相关系数公式:ρ(X, Y) = Cov(X, Y) / σ(X)σ(Y)2. 统计推断中的重要公式2.1 参数估计公式:(1) 矩估计:θ̂= ḡ(m₁, m₂, ..., mₖ)(2) 最大似然估计:θ̂= argmax[∏ f(x; θ)](3) 最小二乘估计:θ̂= argmin[∑ (yᵢ - g(xᵢ; θ))²]2.2 假设检验公式:(1) z检验:z = (x - μ) / (σ/√n)(2) t检验:t = (x - μ) / (s/√n)(3) 卡方检验:χ² = ∑ (Oᵢ - Eᵢ)² / Eᵢ3. 抽样理论中的重要公式3.1 随机变量公式:(1) 期望值公式:E(X) = μ(2) 方差公式:Var(X) = σ²/n(3) 中心极限定理:Z = (X - μ) / (σ/√n) 服从标准正态分布3.2 总体参数估计公式:(1) 基本抽样分布(z分布):z = (X - μ) / (σ/√n)(2) t分布:t = (X - μ) / (s/√n)(3) X²分布:χ² = ∑ (Xᵢ - Eᵢ)² / Eᵢ4. 方差分析中的重要公式4.1 单因素方差分析公式:(1) 总平方和公式:SST = ∑ (xᵢj - x)²(2) 因素平方和公式:SFA = n ∑ (xₖ - x)²(3) 误差平方和公式:SSE = ∑ (xᵢj - xₖ)²4.2 F检验公式:F = (SFA / (k - 1)) / (SSE / (n - k))5. 相关分析中的重要公式5.1 简单线性回归公式:(1) 回归模型:Y = β₀ + β₁X + ε(2) 最小二乘估计公式:β̂₁ = ∑((Xᵢ - X)(Yᵢ - Ȳ)) / ∑((Xᵢ - X)²)β̂₀ = Ȳ - β̂₁X(3) 相关系数公式:r = Cov(X, Y) / (σ(X)σ(Y))6. 抽样调查中的重要公式6.1 简单随机抽样公式:(1) 抽样率:p = n / N(2) 估计总量公式:T = N * (X / n)(3) 估计方差公式:Var(T) = N² * ((1 - p/n) / n) * σ²7. 时间序列分析中的重要公式7.1 平稳时间序列公式:(1) 自协方差公式:γ(h) = Cov(Xₖ, Xₖ₋ₖ) = γ(-h)(2) 自相关系数公式:ρ(h) = Cov(Xₖ, Xₖ₋ₖ) / (σ(Xₖ)σ(Xₖ₋ₖ))通过对这些数理统计中的重要公式的整理,我们可以更加方便地在实际问题中应用这些公式,进行数据分析、参数估计、假设检验等统计推断工作。
统计学原理公式统计学是一门研究数据收集、分析、解释和呈现的学科,它在各个领域都有着广泛的应用。
在统计学中,公式是非常重要的工具,它们可以帮助我们理解数据的规律,进行数据分析和推断。
本文将介绍一些统计学原理中常用的公式,帮助读者更好地理解统计学的基本概念和原理。
1. 样本均值公式。
样本均值是统计学中最基本的概念之一,它表示了一组数据的平均水平。
样本均值的计算公式如下:\[ \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i \]其中,\( \bar{x} \) 表示样本均值,\( n \) 表示样本容量,\( x_i \) 表示第 \( i \) 个观测值。
通过样本均值公式,我们可以快速计算出一组数据的平均值,从而对数据的集中趋势有一个直观的认识。
2. 样本方差公式。
样本方差是衡量一组数据离散程度的指标,它表示了数据点与样本均值之间的差异程度。
样本方差的计算公式如下:\[ s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i \bar{x})^2 \]其中,\( s^2 \) 表示样本方差,\( n \) 表示样本容量,\( x_i \) 表示第 \( i \) 个观测值,\( \bar{x} \) 表示样本均值。
样本方差公式可以帮助我们衡量数据的离散程度,从而对数据的分布情况有一个直观的了解。
3. 样本标准差公式。
样本标准差是样本方差的平方根,它也是衡量数据离散程度的重要指标。
样本标准差的计算公式如下:\[ s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i \bar{x})^2} \]其中,\( s \) 表示样本标准差,其他符号的含义与样本方差公式相同。
样本标准差公式可以帮助我们更直观地理解数据的离散程度,它是许多统计推断和假设检验的基础。
4. 正态分布概率密度函数。
正态分布是统计学中最重要的概率分布之一,它具有许多重要的性质和应用。
一.加权算术平均数与加权调与平均数得计算加权算术平均数:或加权调与平均数:频数也称次数。
在一组依大小顺序排列得测量值中,当按一定得组距将其分组时出现在各组内得测量值得数目,即落在各类别(分组)中得数据个数。
再如在3.149324中,‘9’出现得频数就是3,出现得频率就是3/18=16。
7%一般我们称落在不同小组中得数据个数为该组得频数,频数与总数得比为频率、频数也称“次数”,对总数据按某种标准进行分组,统计出各个组内含个体得个数、而频率则每个小组得频数与数据总数得比值。
在变量分配数列中,频数(频率)表明对应组标志值得作用程度。
频数(频率)数值越大表明该组标志值对于总体水平所起得作用也越大,反之,频数(频率)数值越小,表明该组标志值对于总体水平所起得作用越小。
掷硬币实验:在10次掷硬币中,有4次正面朝上,我们说这10次试验中‘正面朝上’得频数就是4例题:我们经常掷硬币,在掷了一百次后,硬币有40次正面朝上,那么,硬币反面朝上得频数为____、解答,掷了硬币100次,40次朝上,则有100-40=60(次)反面朝上,所以硬币反面朝上得频数为60。
一。
加权算术平均数与加权调与平均数得计算加权算术平均数:或代表算术平均数;∑就是总与符合;f为标志值出现得次数。
加权算术平均数就是具有不同比重得数据(或平均数)得算术平均数。
比重也称为权重,数据得权重反映了该变量在总体中得相对重要性,每种变量得权重得确定与一定得理论经验或变量在总体中得比重有关。
依据各个数据得重要性系数(即权重)进行相乘后再相加求与,就就是加权与、加权与与所有权重之与得比等于加权算术平均数。
加权平均数=各组(变量值 ×次数)之与 / 各组次数之与=∑xf /∑f加权调与平均数:加权算术平均数以各组单位数f为权数,加权调与平均数以各组标志总量m为权数但计算内容与结果都就是相同得。
二.标准差与标准差系数得计算方法标准差:σ=公式标准差也被称为标准偏差,或者实验标准差,公式如图、简单来说,标准差就是一组数据平均值分散程度得一种度量。
统计学原理重要公式1.样本均值公式:样本均值是样本数据的总和除以样本的大小。
它的公式是:$$ \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i $$其中,n是样本的大小,xi是第i个观测值。
2.总体均值公式:总体均值是从总体中取得的全部样本数据的总和除以总体的大小。
它的公式是:$$ \mu = \frac{1}{N} \sum_{i=1}^{N} x_i $$其中,N是总体的大小,xi是第i个观测值。
3.样本方差公式:样本方差是样本数据与样本均值差的平方和的平均值。
它的公式是:$$ s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2 $$其中,n是样本的大小,xi是第i个观测值,$ \bar{x} $是样本均值。
4.总体方差公式:总体方差是总体数据与总体均值差的平方和的平均值。
它的公式是:$$ \sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 $$其中,N是总体的大小,xi是第i个观测值,$ \mu $是总体均值。
5.样本标准差公式:样本标准差是样本方差的平方根。
它的公式是:$$ s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2} $$其中,n是样本的大小,xi是第i个观测值,$ \bar{x} $是样本均值。
6.总体标准差公式:总体标准差是总体方差的平方根。
它的公式是:$$ \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2} $$其中,N是总体的大小,xi是第i个观测值,$ \mu $是总体均值。
7.样本比例公式:样本比例是样本中具有一些特征的观测值的比例。
$$ p = \frac{x}{n} $$其中,n是样本的大小,x是具有特征的观测值的数量。
第二章数据描述1、组距=上限—下限2、简单平均数:x=Σx/n3、加权平均数:x=Σxf/Σf4、全距: R=x max-x min5、方差和标准差:方差是将各个变量值和其均值离差平方的平均数。
其计算公式:未分组的计算公式:σ2=Σ(x-x)2/n分组的计算公式:σ2=Σ(x-x)2f/Σf样本标准差则是方差的平方根:未分组的计算公式:s=[Σ(x-x)2/(n-1)]1/2分组的计算公式:s=[Σ(x-x)2f/(Σf-1)] 1/2σ=[Σ(x-x)/n] 1/26、离散系数:总体数据的离散系数:Vσ=σ/x样本数据的离散系数:V s=s/x10、标准分数:标准分数也称标准化值或Z分数,它是变量值与其平均数的离差除以标准差后的值,用以测定某一个数据在该组数据的相对位置。
其计算公式为:Z i=(x i-x)/s标准分数的最大的用途是可以把两组数组中的两个不同均值、不同标准差的数据进行对比,以判断它们在各组中的位置。
第三章参数估计1、统计量的标准误差:(样本误差)(1)在重复抽样时;样本标准误差:σx=σ/n或σx=s/n样本的比例误差可表示为:σp=[π(1-π)/n]1/2或σp=[p(1-p)/n] 1/2(2)不重复抽样时:σ2x=σ2/n×(N-n/N-1)σ2p=p(1-p)/n×(N-n/N-1)2、估计总体均值时样本量的确定,在重复抽样的条件下:n= Z2σ2/E23、估计总体比例时样本量的确定,在重复抽样的条件下:n=Z2×p(1-p)/E24、(1)在大样本情况下,样本均值的抽样分布服从正态分布,因此采用正态分布的检验统计量,当总体方差已知时,总体均值检验统计量为:Z=(x-μ)/( σ/n)(2)当总体方差未知时,可以用样本方差来代替,此时总体均值检验的统计量为:Z=(x-μ)/( s/n)5、小样本的检验:在小样本(n<30)情况下,检验时,首先假定总体均值服从正态分布。
《统计学原理》公式大全一、统计整理1.组距=上限 - 下限 2.组中值(1)闭口组2下限上限组中值+= (2)开口组组中值①2相邻组组距上限值缺下限的开口组的组中-= ②2相邻组组距下限值缺上限的开口组的组中+= 二、综合指标1.计划完成相对数 =计划任务数实际完成数2.计划执行进度 =计划期计划任务累计数数一时间的实际完成累计自计划执行之日起至某3.结构相对数 =总体总量总体中某部分数值4.总体中另一部分数值总体中某部分数值比例相对数=5.值另一总体的同类指标数某总体的某指标数值比较相对数=6.的总量指标数值另一性质不同但有联系某一总量指标数值强度相对数=7.基期指标数值报告期指标数值动态相对数=8.总体单位总量总体标志总量算术平均数=9.简单算术平均数 x —=nxn x x x n ∑=+++ 21 10.加权算术平均数 x —=∑∑=∑+++f xf f f x f x f x n n 2211 11.简单调和平均数 ∑=-xN x H 112.加权调和平均数 ∑∑=-mxmx H 113.极差(R )= 最大标志值 — 最小标志值14.简单平均差 D A ⋅=nx x∑-—15.加权平均差 D A ⋅=∑-fx x —16.简单标准差 nx x ∑-=)(—2σ17.加权标准差 ∑∑-=ffx x )(—2σ三、抽样推断1.重复抽样条件下的抽样平均数的抽样平均误差 nx σμ2=2.重复抽样条件下的抽样成数的抽样平均误差 nP P p )1(-=μ 3.不重复抽样条件下的抽样平均数的抽样平均误差 )1(2N nn x -=σμ4.抽样成数的抽样平均误差 )1()1(Nnn P P p --=μ 5.抽样平均数的抽样极限误差 =∆xμ-⋅x t 6.抽样成数的抽样极限误差=∆pμp t ⋅7.概率度 t =μxx ∆ t = μpp ∆8.总体均值的区间估计 x __±∆x9.总体比例的区间估计 p ±∆P四、统计指数1.个体价格指数 p pk p 01=2.个体产量指数 q q k q 01=3.个体成本指数 z z k z 01=4.数量指标综合指数 ∑∑=p q p q k q 00015.质量指标综合指数 ∑∑=p q p q k p 01116.加权算术平均数指数 ∑∑⋅=p q p q k k q q 0007.加权调和平均数指数 ∑⋅∑=p q k p q k pp 111118.可变构成指数 ∑∑∑∑⋅⋅==)()(00011101_________f x f f x x x k 可变9.固定构成指数 ∑∑∑∑⋅⋅=)()(110111___f f x f x k 固定10.结构影响指数 ∑∑∑∑⋅⋅=)()(00110___f x f f x k 结构11.指数体系相对数形式 k k k p q qp ⨯= 即∑∑⨯∑∑=∑∑p q p q p q p q p q p q 011100010011 绝对数形式:)()(011100010011∑∑-+∑∑-∑∑=-p q p q p q p q p q p q五、动态数列1.根据时期数列计算平均发展水平 n a na a a a n ∑=+++=21—2.根据间隔相等的连续时点数列计算平均发展水平n a na a a a n ∑=+++=21—3.根据间隔不等的连续时点数列计算平均发展水平∑∑=ffa a —4.根据间隔相等的间断时点数列计算平均发展水平1221222132113221—-++++=-++++++=--n n a a a a a a a a a a a a nn nn5.根据间隔不等的间断时点数列计算平均发展水平f f f f aa f a a f a a a n n n n 12111232121—222---+++++++++= 6.根据相对数动态数列或平均数动态数列计算平均发展水平ba c ———=7.增长量 = 报告期水平 一 基期水平 8.逐期增长量=报告期水平一前一期水平,用符号表示为:a a ,,a a ,a a ,a a n n 1231201----- 9.累计增长量 = 报告期水平一某一固定基期水平用符号表示为:a a ,,a a ,a a ,a a n 0030201---- 10.各期的逐期增长量之和等于最后一个时期的累计增长量,用公式表示为: a a a a a a a a a a n n n 01231201)()()()(-=-++-+-+--11.相邻两个时期的累计增长量之差等于相应时期的逐期增长量,用公式表示为: a a a a a a n n n n 1010)()(---=---12.年距增长量 = 本期发展水平 - 去年同期发展水平 13.1-==时间数列的项数累计增长量逐期增长量的个数逐期增长量之和平均增长量14.基期水平报告期水平发展速度=15.前一期水平报告期水平环比发展速度=用符号表示为:a a a a a a a a n n 1231201,,,,- 16.某一固定基期水平报告期水平定基发展速度=用符号表示为:a a a a a a a a no o 03201,,,,17.定基发展速度等于相应时期内的各环比发展速度的连乘积,用符号可表示为:a a a a a a a a n n 1231201-⨯⨯⨯⨯ =aa n 018.相邻两个定基发展速度之比等于相应时期的环比发展速度,用符号可表示为:a a a a a a n nn n 1010--=÷19.去年同期发展水平本期发展水平年距发展速度=20.11-=-=-==发展速度基期水平报告期水平基期水平基期水平报告期水平基期水平报告期增长量增长速度21.1-=-==环比发展速度前一期水平前一期水平报告期水平前一期水平逐期增长量环比增长速度 22.1-=-==定基发展速度某一固定基期水平某一固定基期水平报告期水平某一固定基期水平累计增长量定基增长速度23.()1-==年距发展速度月或季去年同期发展水平年距增长量年距增长速度24.平均发展速度的计算公式为:ninnx x x x x x ∏=⋅⋅⋅⋅= 321—由于环比发展速度的连乘积等于相应定基发展速度,因此平均发展速度的公式可写成:non a a x =—25.平均增长速度 = 平均发展速度 一1 26.100100100%1前一期水平前一期水平期增长量逐期增长量环比增长速度逐期增长量的绝对值增长=⨯=⨯=。
《统计学原理》常用公式汇总及计算题目分析
第一部分常用公式
第三章统计整理
a)组距=上限-下限
b)组中值=(上限+下限)÷2
c)缺下限开口组组中值=上限-1/2邻组组距
d)缺上限开口组组中值=下限+1/2邻组组距
第四章综合指标
i.相对指标
1.结构相对指标=各组(或部分)总量/总体总量
2.比例相对指标=总体中某一部分数值/总体中另一部分数值
3.比较相对指标=甲单位某指标值/乙单位同类指标值
4.强度相对指标=某种现象总量指标/另一个有联系而性质不同的现象
总量指标
5.计划完成程度相对指标=实际数/计划数
=实际完成程度(%)/计划规定的完成程度(%)
ii.平均指标
1.简单算术平均数:
2.加权算术平均数或
iii.变异指标
1.全距=最大标志值-最小标志值
2.标准差: 简单σ= ;加权σ=
3.标准差系数:
第五章抽样估计
1.平均误差:
重复抽样:
不重复抽样:
2.抽样极限误差
3.重复抽样条件下:
平均数抽样时必要的样本数目
成数抽样时必要的样本数目
4.不重复抽样条件下:
平均数抽样时必要的样本数目
第七章相关分析
1.相关系数
2.配合回归方程y=a+bx
3.估计标准误:
第八章指数分数
一、综合指数的计算与分析
(1)数量指标指数
此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。
(-)
此差额说明由于数量指标的变动对价值量指标影响的绝对额。
(2)质量指标指数
此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。
(-)
此差额说明由于质量指标的变动对价值量指标影响的绝对额。
加权算术平均数指数=
加权调和平均数指数=
(3)复杂现象总体总量指标变动的因素分析
相对数变动分析:
= ×
绝对值变动分析:
-= (-)×(-)第九章动态数列分析
一、平均发展水平的计算方法:
(1)由总量指标动态数列计算序时平均数
①由时期数列计算
②由时点数列计算
在间断时点数列的条件下计算:
a.若间断的间隔相等,则采用“首末折半法”计算。
公式为:
b.若间断的间隔不等,则应以间隔数为权数进行加权平均计算。
公式为:
(2)由相对指标或平均指标动态数列计算序时平均数
基本公式为:
式中:代表相对指标或平均指标动态数列的序时平均数;
代表分子数列的序时平均数;
代表分母数列的序时平均数;
逐期增长量之和累积增长量
二. 平均增长量=─────────=─────────
逐期增长量的个数逐期增长量的个数
(1)计算平均发展速度的公式为:
(2)平均增长速度的计算
平均增长速度=平均发展速度-1(100%)
第二部分计算题分析
要求写出公式和计算过程,结果保留两位小数。
计算参考作业及期末复习指导。
1、根据所给资料分组并计算出各组的频数和频率,编制次数分布表;根据整理表计算、算术平均数.
例:某单位40名职工业务考核成绩分别为:
68 89 88 84 86 87 75 73 72 68
75 82 97 58 81 54 79 76 95 76
71 60 90 65 76 72 76 85 89 92
64 57 83 81 78 77 72 61 70 81
单位规定:60分以下为不及格,60─70分为及格,70─80分为中,80─90
分为良,90─100分为优。
要求:
1.将参加考试的职工按考核成绩分组并编制一张考核成绩次数分配表;
2.指出分组标志及类型及采用的分组方法;
3.根据整理表计算职工业务考核平均成绩;
4.分析本单位职工业务考核情况。
解:(1)
(2) 分组标志为"成绩",其类型为"数
量标志";分组方法为:变量分组中的开放组距式分组,组限表示方法是重叠组限;
(3)平均成绩:
(分)
2、根据资料计算算术平均数指标、计算变异指标比较平均指标的代表性。
例:某车间有甲、乙两个生产组,甲组平均每个工人的日产量为36件,
标准差为件;乙组工人日产量资料如下:
日产量(件)
工人数(人)
成 绩 职工人数 频率(%)
60分以下 60-70
70-80 80-90 90-100
3 6 15 12 4
15 30 10 合 计
40
100
15 25 35 45 15 38 34 13
要求:⑴计算乙组平均每个工人的日产量和标准差;
⑵比较甲、乙两生产小组哪个组的日产量更有代表性
解:(1)
(件)
(件)
(2)利用标准差系数进行判断:
因为>
故甲组工人的平均日产量更有代表性
3、采用简单重复抽样的方法计算平均数(成数)的抽样平均误差;根据要求进行平均数(成数)的区间估计。
例:采用简单随机重复抽样的方法,在2000件产品中抽查200件,其中合格品190件.
要求:(1)计算合格品率及其抽样平均误差
(2)以%的概率保证程度(t=2)对合格品率和合格品数量进行区间估计。
(3)如果极限误差为%,则其概率保证程度是多少解:(1)样本合格率
p =
n1/n = 190/200 =
95%
企业产品销售额(万销售利润(万
抽样平均误差:
= %
(2)抽样极限误差Δp= t·μp = 2×% = %
下限: △p=95%% = %
上限: △p=95%+% = %
则:总体合格品率区间:(% %)
总体合格品数量区间(%×2000=1838件%×2000=1962件)
(3)当极限误差为%时,则概率保证程度为% (t=Δ/μ)
4、计算相关系数;建立直线回归方程并指出回归系数的含义;利用建立的方程预测因变量的估计值。
例:
从某行业随机抽取6家企业进行调查,所得有关数据如上:
要求:
(1)拟合销售利润(y)对产品销售额(x)的回归直线,并说明回归系数的实际意义。
(2)当销售额为10 0万元时,销售利润为多少 解:(1)配合回归方程 y=a
+bx
=
=
回归方程为:y=-4.1343+0.3950x
回归系数b=,表示产品销售额每增加1万元,销售利润平均增加万元。
(2)当销售额为100万元时,即x=100,代入回归方程: y=-4.1343+0.3950×100=35.37(万元)
5、计算总指数、数量指数及质量指数并同时指出变动绝对值、计算平均数指数。
例:某商店两种商品的销售资料如下:
商品 单位 销售量 单价(元) 基期 计算期 基期 计算期 甲 乙 件
公斤 50 150
60 160
8 12
10
14
要求: (1)计算两种商品销售额指数及销售额变动的绝对额;
(2)计算两种商品销售量总指数及由于销售量变动影响销售额的绝对
额;
元) 元) 1 2 3
4 5 6
50 15 25 37 48 65 12 4 6 8 15 25
(3)计算两种商品销售价格总指数及由于价格变动影响销售额的绝对额。
解:(1)商品销售额指数=
销售额变动的绝对额:元(2)两种商品销售量总指数=
销售量变动影响销售额的绝对额
元
(3)商品销售价格总指数=
价格变动影响销售额的绝对额:元
6、根据资料计算各种发展速度(环比、定基)及平均增长量指标;根据资料利用平均发展速度指标公式计算期末水平。
例:有某地区粮食产量如下:
年份2000 2001 2002 2003 2004 2005
粮食产量(万吨200 220 251 291 305.5 283.6
要求:(1)计算2001年-2005年该地区粮食产量的环比发展速度、年平均增长量和年平均发展速度;
(2)如果从2005年以后该地区的粮食产量按8%的增长速度发展,2010年该地区的粮食产量将达到什么水平
解:(1)
时间2000 2001 2002 2003 2004 2005
粮食产量(万吨)
逐期增长量(万吨)
环比发展速度(%)200
-
-
220
20
110
251
31
291
40 14.55
104.98 92.83
年平均增长量==(万吨) (或年平均增长量)
年平均发展速度=
(2)=(万斤)。