BP神经网络MATLAB实例(简单而经典)_2
- 格式:pdf
- 大小:208.99 KB
- 文档页数:9

MATLAB程序代码--BP神经网络的设计实例例1 采用动量梯度下降算法训练 BP 网络。
训练样本定义如下:输入矢量为p =[-1 -2 3 1-1 1 5 -3]目标矢量为t = [-1 -1 1 1]解:本例的 MATLAB 程序如下:close allclearecho onclc% NEWFF——生成一个新的前向神经网络% TRAIN——对 BP 神经网络进行训练% SIM——对 BP 神经网络进行仿真pause% 敲任意键开始clc% 定义训练样本% P 为输入矢量P=[-1, -2,3,1;-1,1,5, -3];% T 为目标矢量T=[-1, -1, 1, 1];pause;clc% 创建一个新的前向神经网络net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingd m')% 当前输入层权值和阈值inputWeights=net.IW{1,1}inputbias=net.b{1}% 当前网络层权值和阈值layerWeights=net.LW{2,1} layerbias=net.b{2}pauseclc% 设置训练参数net.trainParam.show = 50; net.trainParam.lr = 0.05; net.trainParam.mc = 0.9;net.trainParam.epochs = 1000;net.trainParam.goal = 1e-3; pauseclc% 调用 TRAINGDM 算法训练 BP 网络[net,tr]=train(net,P,T);pauseclc% 对 BP 网络进行仿真A = sim(net,P)% 计算仿真误差E = T - AMSE=mse(E)pauseclcecho off例2 采用xx正则化算法提高 BP 网络的推广能力。
![利用MATLAB实现BP神经网络的设计[2页]](https://uimg.taocdn.com/ef8bb6383968011ca30091c0.webp)

BP神经网络的设计MATLAB编程例1 采用动量梯度下降算法训练 BP 网络。
训练样本定义如下:输入矢量为p =[-1 -2 3 1-1 1 5 -3]目标矢量为 t = [-1 -1 1 1]解:本例的 MATLAB 程序如下:close allclearecho onclc% NEWFF——生成一个新的前向神经网络% TRAIN——对 BP 神经网络进行训练% SIM——对 BP 神经网络进行仿真pause% 敲任意键开始clc% 定义训练样本% P 为输入矢量P=[-1, -2, 3, 1; -1, 1, 5, -3];% T 为目标矢量T=[-1, -1, 1, 1];pause;clc% 创建一个新的前向神经网络net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingdm')% 当前输入层权值和阈值inputWeights=net.IW{1,1}inputbias=net.b{1}% 当前网络层权值和阈值layerWeights=net.LW{2,1}layerbias=net.b{2}pauseclc% 设置训练参数net.trainParam.show = 50;net.trainParam.lr = 0.05;net.trainParam.mc = 0.9;net.trainParam.epochs = 1000;net.trainParam.goal = 1e-3;pauseclc% 调用 TRAINGDM 算法训练 BP 网络[net,tr]=train(net,P,T);pauseclc% 对 BP 网络进行仿真A = sim(net,P)% 计算仿真误差E = T - AMSE=mse(E)pauseclcecho off例2 采用贝叶斯正则化算法提高 BP 网络的推广能力。

BP神经网络预测的matlab代码附录5:BP神经网络预测的matlab代码: P=[ 00.13860.21970.27730.32190.35840.38920.41590.43940.46050.47960.49700.52780.55450.59910.60890.61820.62710.63560.64380.65160.65920.66640.67350.72220.72750.73270.73780.74270.74750.75220.75680.76130.76570.7700]T=[0.4455 0.323 0.4116 0.3255 0.4486 0.2999 0.4926 0.2249 0.48930.2357 0.4866 0.22490.4819 0.2217 0.4997 0.2269 0.5027 0.217 0.5155 0.1918 0.5058 0.2395 0.4541 0.2408 0.4054 0.2701 0.3942 0.3316 0.2197 0.2963 0.5576 0.1061 0.4956 0.267 0.5126 0.2238 0.5314 0.2083 0.5191 0.208 0.5133 0.18480.5089 0.242 0.4812 0.2129 0.4927 0.287 0.4832 0.2742 0.5969 0.24030.5056 0.2173 0.5364 0.1994 0.5278 0.2015 0.5164 0.2239 0.4489 0.2404 0.4869 0.2963 0.4898 0.1987 0.5075 0.2917 0.4943 0.2902 ]threshold=[0 1]net=newff(threshold,[11,2],{'tansig','logsig'},'trainlm');net.trainParam.epochs=6000net.trainParam.goal=0.01LP.lr=0.1;net=train(net,P',T')P_test=[ 0.77420.77840.78240.78640.79020.7941 ] out=sim(net,P_test')友情提示:以上面0.7742为例0.7742=ln(47+1)/5因为网络输入有一个元素,对应的是测试时间,所以P只有一列,Pi=log(t+1)/10,这样做的目的是使得这些数据的范围处在[0 1]区间之内,但是事实上对于logsin命令而言输入参数是正负区间的任意值,而将输出值限定于0到1之间。

matlab bp预测例子一、引言人工神经网络(Artificial Neural Network,ANN)是一种模拟人脑神经元网络的数学模型,具有自我学习和适应能力。
而BP神经网络(Back Propagation Neural Network)是其中的一种常见类型,它通过反向传播算法来调整网络的权重和阈值,从而实现对样本数据的拟合和预测。
本文将以MATLAB为例,介绍如何使用BP神经网络进行预测。
二、数据准备我们需要准备用于训练和测试的数据。
假设我们要预测某城市的房价,我们可以收集到以下数据:房屋面积、房间数量、楼层高度、建筑年份和房价。
我们将这些数据存储在一个Excel文件中,然后使用MATLAB的数据导入工具将其读入到工作空间中。
三、数据预处理在进行BP神经网络训练之前,我们需要对数据进行预处理。
首先,我们要将数据划分为训练集和测试集,一般可以按照70%的比例划分。
然后,我们需要对数据进行归一化处理,将所有特征值缩放到0-1之间,以避免某个特征对网络的影响过大。
MATLAB提供了相关函数可以进行数据归一化处理。
四、网络建模在进行网络建模之前,我们需要确定网络的结构和参数。
一般来说,输入层的节点数应该等于特征的个数,输出层的节点数应该等于预测的目标个数。
隐藏层的节点数可以根据经验选择,一般不宜过多,以免过拟合。
然后,我们需要选择合适的激活函数和学习率。
在MATLAB中,可以使用“patternnet”函数来创建BP神经网络对象,并设置相应的参数。
五、网络训练在进行网络训练之前,我们需要将数据转换为MATLAB所需的格式。
然后,可以使用“train”函数对网络进行训练。
训练过程中,MATLAB会根据样本数据和预测结果计算误差,并根据误差进行反向传播调整权重和阈值。
训练的次数可以根据需要进行调整,一般情况下,训练次数越多,网络的拟合能力越强,但也容易造成过拟合。
六、网络预测在网络训练完成后,我们可以使用训练好的网络对新的样本进行预测。

PSO优化的BP神经⽹络(Matlab版)前⾔:最近接触到⼀些神经⽹络的东西,看到很多⼈使⽤PSO(粒⼦群优化算法)优化BP神经⽹络中的权值和偏置,经过⼀段时间的研究,写了⼀些代码,能够跑通,嫌弃速度慢的可以改⼀下训练次数或者适应度函数。
在我的理解⾥,PSO优化BP的初始权值w和偏置b,有点像数据迁徙,等于⽤粒⼦去尝试作为⽹络的参数,然后训练⽹络的阈值,所以总是会看到PSO优化了权值和阈值的说法,(⼀开始我是没有想通为什么能够优化阈值的),下⾯是我的代码实现过程,关于BP和PSO的原理就不⼀⼀赘述了,⽹上有很多⼤佬解释的很详细了……⾸先是利⽤BP作为适应度函数function [error] = BP_fit(gbest,input_num,hidden_num,output_num,net,inputn,outputn)%BP_fit 此函数为PSO的适应度函数% gbest:最优粒⼦% input_num:输⼊节点数⽬;% output_num:输出层节点数⽬;% hidden_num:隐含层节点数⽬;% net:⽹络;% inputn:⽹络训练输⼊数据;% outputn:⽹络训练输出数据;% error : ⽹络输出误差,即PSO适应度函数值w1 = gbest(1:input_num * hidden_num);B1 = gbest(input_num * hidden_num + 1:input_num * hidden_num + hidden_num);w2 = gbest(input_num * hidden_num + hidden_num + 1:input_num * hidden_num...+ hidden_num + hidden_num * output_num);B2 = gbest(input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:...input_num * hidden_num + hidden_num + hidden_num * output_num + output_num);net.iw{1,1} = reshape(w1,hidden_num,input_num);net.lw{2,1} = reshape(w2,output_num,hidden_num);net.b{1} = reshape(B1,hidden_num,1);net.b{2} = B2';%建⽴BP⽹络net.trainParam.epochs = 200;net.trainParam.lr = 0.05;net.trainParam.goal = 0.000001;net.trainParam.show = 100;net.trainParam.showWindow = 0;net = train(net,inputn,outputn);ty = sim(net,inputn);error = sum(sum(abs((ty - outputn))));end 然后是PSO部分:%%基于多域PSO_RBF的6R机械臂逆运动学求解的研究clear;close;clc;%定义BP参数:% input_num:输⼊层节点数;% output_num:输出层节点数;% hidden_num:隐含层节点数;% inputn:⽹络输⼊;% outputn:⽹络输出;%定义PSO参数:% max_iters:算法最⼤迭代次数% w:粒⼦更新权值% c1,c2:为粒⼦群更新学习率% m:粒⼦长度,为BP中初始W、b的长度总和% n:粒⼦群规模% gbest:到达最优位置的粒⼦format longinput_num = 3;output_num = 3;hidden_num = 25;max_iters =10;m = 500; %种群规模n = input_num * hidden_num + hidden_num + hidden_num * output_num + output_num; %个体长度w = 0.1;c1 = 2;c2 = 2;%加载⽹络输⼊(空间任意点)和输出(对应关节⾓的值)load('pfile_i2.mat')load('pfile_o2.mat')% inputs_1 = angle_2';inputs_1 = inputs_2';outputs_1 = outputs_2';train_x = inputs_1(:,1:490);% train_y = outputs_1(4:5,1:490);train_y = outputs_1(1:3,1:490);test_x = inputs_1(:,491:500);test_y = outputs_1(1:3,491:500);% test_y = outputs_1(4:5,491:500);[inputn,inputps] = mapminmax(train_x);[outputn,outputps] = mapminmax(train_y);net = newff(inputn,outputn,25);%设置粒⼦的最⼩位置与最⼤位置% w1阈值设定for i = 1:input_num * hidden_numMinX(i) = -0.01*ones(1);MaxX(i) = 3.8*ones(1);end% B1阈值设定for i = input_num * hidden_num + 1:input_num * hidden_num + hidden_numMinX(i) = 1*ones(1);MaxX(i) = 8*ones(1);end% w2阈值设定for i = input_num * hidden_num + hidden_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_numMinX(i) = -0.01*ones(1);MaxX(i) = 3.8*ones(1);end% B2阈值设定for i = input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_num + output_num MinX(i) = 1*ones(1);MaxX(i) = 8*ones(1);end%%初始化位置参数%产⽣初始粒⼦位置pop = rands(m,n);%初始化速度和适应度函数值V = 0.15 * rands(m,n);BsJ = 0;%对初始粒⼦进⾏限制处理,将粒⼦筛选到⾃定义范围内for i = 1:mfor j = 1:input_num * hidden_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num + 1:input_num * hidden_num + hidden_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num + hidden_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_num + output_num if pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendend%评估初始粒⼦for s = 1:mindivi = pop(s,:);fitness = BP_fit(indivi,input_num,hidden_num,output_num,net,inputn,outputn);BsJ = fitness; %调⽤适应度函数,更新每个粒⼦当前位置Error(s,:) = BsJ; %储存每个粒⼦的位置,即BP的最终误差end[OderEr,IndexEr] = sort(Error);%将Error数组按升序排列Errorleast = OderEr(1); %记录全局最⼩值for i = 1:m %记录到达当前全局最优位置的粒⼦if Error(i) == Errorleastgbest = pop(i,:);break;endendibest = pop; %当前粒⼦群中最优的个体,因为是初始粒⼦,所以最优个体还是个体本⾝for kg = 1:max_iters %迭代次数for s = 1:m%个体有52%的可能性变异for j = 1:n %粒⼦长度for i = 1:m %种群规模,变异是针对某个粒⼦的某⼀个值的变异if rand(1)<0.04pop(i,j) = rands(1);endendend%r1,r2为粒⼦群算法参数r1 = rand(1);r2 = rand(1);%个体位置和速度更新V(s,:) = w * V(s,:) + c1 * r1 * (ibest(s,:)-pop(s,:)) + c2 * r2 * (gbest(1,:)-pop(s,:));pop(s,:) = pop(s,:) + 0.3 * V(s,:);%对更新的位置进⾏判断,超过设定的范围就处理下。

GA-BP神经网络应用实例之MATLAB程序% gap.xls中存储训练样本的原始输入数据 37组% gat.xls中存储训练样本的原始输出数据 37组% p_test.xls中存储测试样本的原始输入数据 12组% t_test.xls中存储测试样本的原始输出数据 12组% 其中gabpEval.m适应度值计算函数,gadecod.m解码函数%--------------------------------------------------------------------------nntwarn off;% nntwarn函数可以临时关闭神经网络工具箱的警告功能,当代码使用到神经% 网络工具箱的函数时会产生大量的警告而这个函数可以跳过这些警告但% 是,为了保证代码可以在新版本的工具箱下运行,我们不鼓励这么做pc=xlsread('gap.xls');tc=xlsread('gat.xls');p_test=xlsread('p_test.xls');t_test=xlsread('t_test.xls');p=pc';t=tc';p_test=p_test';t_test=t_test';% 归一化处理for i=1:2P(i,:)=(p(i,:)-min(p(i,:)))/(max(p(i,:))-min(p(i,:))); endfor i=1:4T(i,:)=(t(i,:)-min(t(i,:)))/(max(t(i,:))-min(t(i,:))); endfor i=1:2P_test(i,:)=(p_test(i,:)-min(p_test(i,:)))/(max(p_test(i,:))-min(p_test(i,:)));end%--------------------------------------------------------------------------% 创建BP神经网络,隐含层节点数为12net=newff(minmax(P),[12,4],{'tansig','purelin'},'trainlm'); %-------------------------------------------------------------------------- % 下面使用遗传算法对网络进行优化R=size(P,1);% BP神经网络输入层节点数S2=size(T,1);% BP神经网络输出层节点数S1=12;% 隐含层节点数S=R*S1+S1*S2+S1+S2;% 遗传算法编码长度aa=ones(S,1)*[-1,1];popu=100;% 种群规模initPop=initializega(popu,aa,'gabpEval');% 初始化种群gen=500;% 遗传代数% 下面调用gaot工具箱,其中目标函数定义为gabpEval[x,endPop,bPop,trace]=ga(aa,'gabpEval',[],initPop,[1e-6 11],'maxGenTerm',...gen,'normGeomSelect',[0.09],['arithXover'],[2],'nonUnifMutation',[2 gen 3]);%--------------------------------------------------------------------------% 绘收敛曲线图figure;plot(trace(:,1),1./trace(:,3),'r-'); hold on;plot(trace(:,1),1./trace(:,2),'b-'); xlabel('遗传代数');ylabel('平方和误差');figure;plot(trace(:,1),trace(:,3),'r-'); hold on;plot(trace(:,1),trace(:,2),'b-'); xlabel('遗传代数');ylabel('适应度');legend('平均适应度值','最优适应度值'); %-------------------------------------------------------------------------- % 下面将初步得到的权值矩阵赋给尚未开始训练的BP网络[W1,B1,W2,B2,P,T,A1,A2,SE,val]=gadecod(x); net.IW{1,1}=W1;net.LW{2,1}=W2;net.b{1}=B1;net.b{2}=B2;% 设置训练参数net.trainParam.epochs=3000;net.trainParam.goal=1e-6;% 训练网络net=train(net,P,T);w1=net.IW{1,1};w2=net.LW{2,1};b1=net.b{1};b2=net.b{2};% 测试网络性能temp=sim(net,P_test);yuce1=[temp(1,:);temp(2,:),;temp(3,:);temp(4,:)];for i=1:4yuce(i,:)=yuce1(i,:)*(max(t_test(i,:))-min(t_test(i,:)))+min(t_test(i,:));end%--------------------------------------------------------------------------% 测试输出结果之一figure;plot(1:12,yuce(1,:),'bo-');ylabel('切口外径 mm');hold on;plot(1:12,t_test(1,:),'r*-'); legend('测试结果','测试样本');figure;plot(1:12,yuce(1,:)-t_test(1,:),'b-');ylabel('误差 mm');title('测试结果与测试样本误差');figure;plot(1:12,((yuce(1,:)-t_test(1,:))/t_test(1,:))*100,'b*'); ylabel('百分比');title('测试结果与测试样本误差');% 测试输出结果之二figure;plot(1:12,yuce(2,:),'bo-'); ylabel('切口内径 mm');hold on;plot(1:12,t_test(2,:),'r*-'); legend('测试结果','测试样本'); figure;plot(1:12,yuce(2,:)-t_test(2,:),'b-');ylabel('误差 mm');title('测试结果与测试样本误差');figure;plot(1:12,((yuce(2,:)-t_test(2,:))/t_test(2,:))*100,'b*'); ylabel('百分比');title('测试结果与测试样本误差');% 测试输出结果之三figure;plot(1:12,yuce(3,:),'bo-'); ylabel('最大滚切力 N');hold on;plot(1:12,t_test(3,:),'r*-'); legend('测试结果','测试样本'); figure;plot(1:12,yuce(3,:)-t_test(3,:),'b-');ylabel('误差 N');title('测试结果与测试样本误差');figure;plot(1:12,((yuce(3,:)-t_test(3,:))/t_test(3,:))*100,'b*');ylabel('百分比');title('测试结果与测试样本误差');% 测试输出结果之四figure;plot(1:12,yuce(4,:),'bo-'); ylabel('切断时间 s');hold on;plot(1:12,t_test(4,:),'r*-');legend('测试结果','测试样本');figure;plot(1:12,yuce(4,:)-t_test(4,:),'b-');ylabel('误差 s');title('测试结果与测试样本误差');figure;plot(1:12,((yuce(4,:)-t_test(4,:))/t_test(4,:))*100,'b*'); ylabel('百分比');title('测试结果与测试样本误差');%--------------------------------------------------------------------------。
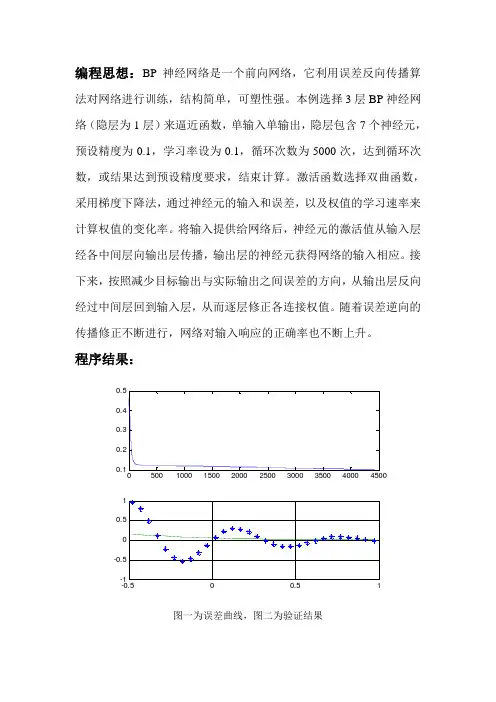
编程思想:BP神经网络是一个前向网络,它利用误差反向传播算法对网络进行训练,结构简单,可塑性强。
本例选择3层BP神经网络(隐层为1层)来逼近函数,单输入单输出,隐层包含7个神经元,预设精度为0.1,学习率设为0.1,循环次数为5000次,达到循环次数,或结果达到预设精度要求,结束计算。
激活函数选择双曲函数,采用梯度下降法,通过神经元的输入和误差,以及权值的学习速率来计算权值的变化率。
将输入提供给网络后,神经元的激活值从输入层经各中间层向输出层传播,输出层的神经元获得网络的输入相应。
接下来,按照减少目标输出与实际输出之间误差的方向,从输出层反向经过中间层回到输入层,从而逐层修正各连接权值。
随着误差逆向的传播修正不断进行,网络对输入响应的正确率也不断上升。
程序结果:050010001500200025003000350040004500-0.500.51图一为误差曲线,图二为验证结果由图可见:当输入样本samplelist=-0.5:0.05:0.45时,网络经过5000次的循环计算,误差几乎为0.验证数据的输入样本为:-0.48:0.05:1。
可以发现在输入小于0时,期望的输出值和通过神经网络得到的输出值偏差较大,但当输入大于0时,偏差逐渐减小,输入大于0.5时,偏差基本为0。
分析原因,可能是因为隐层数目较少,隐层神经元数目选择不当造成。
Matlab程序如下(附详细注释):clear all%********预设各个参数大小和存储空间********inputnums=1;%输入层节点为1outputnums=1;%输出层节点为1hidenums=7;%隐层节点为7maxcount=5000;%最大迭代次数samplenum=19;%一个计数器,无意义precision=0.1;%预设精度alpha=0.01;%学习率设定值error=zeros(1,maxcount+1);%error数组初始化,目的是预分配内存空间errorp=zeros(1,samplenum);%同上v=rand(inputnums,hidenums);%1*7;v初始化为一个1*7的随机归一矩阵;v表输入层到隐层的权值deltv=zeros(inputnums,hidenums);%1*7;内存空间预分配dv=zeros(inputnums,hidenums);%1*7;w=rand(hidenums,outputnums);%7*1;隐层到输出层的权值deltw=zeros(hidenums,outputnums);%7*1dw=zeros(hidenums,outputnums);%7*1samplelist=-0.5:0.05:0.45;%输入数据expectlist=exp(-1.9.*(samplelist+0.5)).*sin(10.*samplelist); %期望输出[samplelist,minp,maxp]=premnmx(samplelist);%输入数据预处理%************BP神经网络循环调整权值*************count=1;while(count<=maxcount)%结束条件1迭代5000次c=1;while(c<=samplenum)for k=1:outputnumsd(k)=expectlist(c);%获得期望输出的向量endfor i=1:inputnumsx(i)=samplelist(c);%获得输入的向量数据end%******前向计算**********;for j=1:hidenumsnet=0.0;for i=1:inputnumsnet=net+x(i)*v(i,j);%输入层到隐层的加权和∑X(i)V(i)endy(j)=1/(1+exp(-net));%输出层处理f(x)=1/(1+exp(-x)),单极性sigmiod函数 endfor k=1:outputnumsnet=0.0;for j=1:hidenumsnet=net+y(j)*w(j,k);endo(k)=1/(1+exp(-net));%计算获得的输出值end%********反向计算,修改权值*******errortmp=0.0;for k=1:outputnumserrortmp=errortmp+(d(k)-o(k))^2;%第一组训练后的误差计算errorp(c)=0.5*errortmp;%误差E=∑(d(k)-o(k))^2 * 1/2%end%****backward()********;for k=1:outputnumsyitao(k)=(d(k)-o(k))*o(k)*(1-o(k));%输出层误差偏导endfor j=1:hidenumstem=0.0;for k=1:outputnumstem=tem+yitao(k)*w(j,k);%为了求隐层偏导,而计算的求和endyitay(j)=tem*y(j)*(1-y(j));%隐层偏导end%******调整各层权值********for j=1:hidenumsfor k=1:outputnumsdeltw(j,k)=alpha*yitao(k)*y(j);%权值w的调整量deltw(已乘学习率) w(j,k)=w(j,k)+deltw(j,k);%权值调整endendfor i=1:inputnumsfor j=1:hidenumsdeltv(i,j)=alpha*yitay(j)*x(i);%同上deltwv(i,j)=v(i,j)+deltv(i,j);endendc=c+1;end %第二个while结束;表示一次BP训练结束double tmp;for i=1:samplenumtmp=tmp+errorp(i)*errorp(i);%误差求和endtmp=tmp/c;error(count)=sqrt(tmp);%误差求均方根,即精度if(error(count)<precision)%误差是否达到精度要求break;endcount=count+1;%训练次数加1end%第一个while结束%*****用其他的数据验证********error(maxcount+1)=error(maxcount);z=1:count-1;p=-0.48:0.05:1;%验证输入数据t=exp(-1.9.*(p+0.5)).*sin(10.*p)[pn,minpn,maxpn]=premnmx(p);simt=zeros(1,30);%while(a<=19)for i=1:30x=p(i);%获得输入的向量数据for j=1:hidenumsnet=0.0;net=net+x*v(1,j);%输入层到隐层的加权和y(j)=1/(1+exp(-net)); %输出层处理f(x)=1/(1+exp(-x)),单极性sigmiod函数 endnet=0.0;for k=1:hidenumsnet=net+y(k)*w(k,1);endo=1/(1+exp(-net));simt(i)=o;endsubplot(2,1,1);plot(z,error(z),'-');subplot(2,1,2);plot(p,t,'*',p,simt,'-'); grid on。

BP神经网络的设计MATLAB编程例1 采用动量梯度下降算法训练 BP 网络。
训练样本定义如下:输入矢量为p =[-1 -2 3 1-1 1 5 -3]目标矢量为 t = [-1 -1 1 1]解:本例的 MATLAB 程序如下:close allclearecho onclc% NEWFF——生成一个新的前向神经网络% TRAIN——对 BP 神经网络进行训练% SIM——对 BP 神经网络进行仿真pause% 敲任意键开始clc% 定义训练样本% P 为输入矢量P=[-1, -2, 3, 1; -1, 1, 5, -3];% T 为目标矢量T=[-1, -1, 1, 1];pause;clc% 创建一个新的前向神经网络net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingdm')% 当前输入层权值和阈值inputWeights=net.IW{1,1}inputbias=net.b{1}% 当前网络层权值和阈值layerWeights=net.LW{2,1}layerbias=net.b{2}pauseclc% 设置训练参数net.trainParam.show = 50;net.trainParam.lr = 0.05;net.trainParam.mc = 0.9;net.trainParam.epochs = 1000;net.trainParam.goal = 1e-3;pauseclc% 调用 TRAINGDM 算法训练 BP 网络[net,tr]=train(net,P,T);pauseclc% 对 BP 网络进行仿真A = sim(net,P)% 计算仿真误差E = T - AMSE=mse(E)pauseclcecho off例2 采用贝叶斯正则化算法提高 BP 网络的推广能力。

MATLAB 程序代码--BP 神经网络的设计实例例 1 采用动量梯度下降算法训练BP 网络。
训练样本定义如下:输入矢量为p =[-1 -2 3 1-1 1 5 -3]目标矢量为t = [-1 -1 1 1]解:本例的MA TLAB 程序如下:close allclearecho on clc% NEWFF ——生成一个新的前向神经网络% TRAIN ——对BP 神经网络进行训练% SIM ——对BP 神经网络进行仿真pause% 敲任意键开始clc% 定义训练样本% P 为输入矢量P=[-1, -2, 3, 1; -1, 1, 5,-3];% T 为目标矢量T=[-1, -1, 1, 1];pause; clc% 创建一个新的前向神经网络net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingdm')% 当前输入层权值和阈值inputWeights=net.IW{1,1} inputbias=net.b{1}% 当前网络层权值和阈值layerWeights=net.LW{2,1} layerbias=net.b{2} pause clc% 设置训练参数net.trainParam.show = 50; net.trainParam.lr = 0.05; net.trainParam.mc = 0.9;n et.tra in Param.epochs = 1000;n et.tra in Param.goal = 1e-3;pauseclc% 调用TRAINGDM 算法训练BP网络[n et,tr]=trai n(n et,P,T);pauseclc% 对BP网络进行仿真A = sim( net,P)% 计算仿真误差E = T - AMSE=mse(E) pause clc echo off例2采用贝叶斯正则化算法提高BP网络的推广能力。

(整理)BP神经网络matlab实现和matlab工具箱使用实例.BP神经网络matlab实现和matlab工具箱使用实例经过最近一段时间的神经网络学习,终于能初步使用matlab实现BP网络仿真试验。
这里特别感谢研友sistor2004的帖子《自己编的BP算法(工具:matlab)》和研友wangleisxcc的帖子《用C++,Matlab,Fortran实现的BP算法》前者帮助我对BP算法有了更明确的认识,后者让我对matlab下BP函数的使用有了初步了解。
因为他们发的帖子都没有加注释,对我等新手阅读时有一定困难,所以我把sistor2004发的程序稍加修改后加注了详细解释,方便新手阅读。
%严格按照BP网络计算公式来设计的一个matlab程序,对BP网络进行了优化设计%yyy,即在o(k)计算公式时,当网络进入平坦区时(<0.0001)学习率加大,出来后学习率又还原%v(i,j)=v(i,j)+deltv(i,j)+a*dv(i,j); 动量项clear allclcinputNums=3; %输入层节点outputNums=3; %输出层节点hideNums=10; %隐层节点数maxcount=20000; %最大迭代次数samplenum=3; %一个计数器,无意义precision=0.001; %预设精度yyy=1.3; %yyy是帮助网络加速走出平坦区alpha=0.01; %学习率设定值a=0.5; %BP优化算法的一个设定值,对上组训练的调整值按比例修改字串9error=zeros(1,maxcount+1); %error数组初始化;目的是预分配内存空间errorp=zeros(1,samplenum); %同上v=rand(inputNums,hideNums); %3*10;v初始化为一个3*10的随机归一矩阵; v表输入层到隐层的权值deltv=zeros(inputNums,hideNums); %3*10;内存空间预分配dv=zeros(inputNums,hideNums); %3*10;w=rand(hideNums,outputNums); %10*3;同Vdeltw=zeros(hideNums,outputNums);%10*3dw=zeros(hideNums,outputNums); %10*3samplelist=[0.1323,0.323,-0.132;0.321,0.2434,0.456;-0.6546,-0.3242,0.3255]; %3*3;指定输入值3*3(实为3个向量)expectlist=[0.5435,0.422,-0.642;0.1,0.562,0.5675;-0.6464,-0.756,0.11]; %3*3;期望输出值3*3(实为3个向量),有导师的监督学习count=1;while (count<=maxcount) %结束条件1迭代20000次c=1;while (c<=samplenum)for k=1:outputNumsd(k)=expectlist(c,k); %获得期望输出的向量,d(1:3)表示一个期望向量内的值endfor i=1:inputNumsx(i)=samplelist(c,i); %获得输入的向量(数据),x(1:3)表一个训练向量字串4end%Forward();for j=1:hideNumsnet=0.0;for i=1:inputNumsnet=net+x(i)*v(i,j);%输入层到隐层的加权和∑X(i)V(i)endy(j)=1/(1+exp(-net)); %输出层处理f(x)=1/(1+exp(-x))单极性sigmiod函数endfor k=1:outputNumsnet=0.0;for j=1:hideNumsnet=net+y(j)*w(j,k);endif count>=2&&error(count)-error(count+1)<=0.0001o(k)=1/(1+exp(-net)/yyy); %平坦区加大学习率else o(k)=1/(1+exp(-net)); %同上endend%BpError(c)反馈/修改;errortmp=0.0;for k=1:outputNumserrortmp=errortmp+(d(k)-o(k))^2; %第一组训练后的误差计算enderrorp(c)=0.5*errortmp; %误差E=∑(d(k)-o(k))^2 * 1/2%end%Backward();for k=1:outputNumsyitao(k)=(d(k)-o(k))*o(k)*(1-o(k)); %输入层误差偏导字串5endfor j=1:hideNumstem=0.0;for k=1:outputNumstem=tem+yitao(k)*w(j,k); %为了求隐层偏导,而计算的∑endyitay(j)=tem*y(j)*(1-y(j)); %隐层偏导end%调整各层权值for j=1:hideNumsfor k=1:outputNumsdeltw(j,k)=alpha*yitao(k)*y(j); %权值w的调整量deltw(已乘学习率)w(j,k)=w(j,k)+deltw(j,k)+a*dw(j,k);%权值调整,这里的dw=dletw(t-1),实际是对BP算法的一个dw(j,k)=deltw(j,k); %改进措施--增加动量项目的是提高训练速度endendfor i=1:inputNumsfor j=1:hideNumsdeltv(i,j)=alpha*yitay(j)*x(i); %同上deltwv(i,j)=v(i,j)+deltv(i,j)+a*dv(i,j);dv(i,j)=deltv(i,j);endendc=c+1;end%第二个while结束;表示一次BP训练结束double tmp;tmp=0.0; 字串8for i=1:samplenumtmp=tmp+errorp(i)*errorp(i);%误差求和endtmp=tmp/c;error(count)=sqrt(tmp);%误差求均方根,即精度if (error(count)<precision)%另一个结束条件< p="">break;endcount=count+1;%训练次数加1end%第一个while结束error(maxcount+1)=error(maxcount);p=1:count;pp=p/50;plot(pp,error(p),"-"); %显示误差然后下面是研友wangleisxcc的程序基础上,我把初始化网络,训练网络,和网络使用三个稍微集成后的一个新函数bpnet %简单的BP神经网络集成,使用时直接调用bpnet就行%输入的是p-作为训练值的输入% t-也是网络的期望输出结果% ynum-设定隐层点数一般取3~20;% maxnum-如果训练一直达不到期望误差之内,那么BP迭代的次数一般设为5000% ex-期望误差,也就是训练一小于这个误差后结束迭代一般设为0.01% lr-学习率一般设为0.01% pp-使用p-t虚拟蓝好的BP网络来分类计算的向量,也就是嵌入二值水印的大组系数进行训练然后得到二值序列% ww-输出结果% 注明:ynum,maxnum,ex,lr均是一个值;而p,t,pp,ww均可以为向量字串1% 比如p是m*n的n维行向量,t那么为m*k的k维行向量,pp为o*i的i维行向量,ww为o* k的k维行向量%p,t作为网络训练输入,pp作为训练好的网络输入计算,最后的ww作为pp经过训练好的BP训练后的输出function ww=bpnet(p,t,ynum,maxnum,ex,lr,pp)plot(p,t,"+");title("训练向量");xlabel("P");ylabel("t");[w1,b1,w2,b2]=initff(p,ynum,"tansig",t,"purelin"); %初始化含一个隐层的BP网络zhen=25; %每迭代多少次更新显示biglr=1.1; %学习慢时学习率(用于跳出平坦区)litlr=0.7; %学习快时学习率(梯度下降过快时)a=0.7 %动量项a大小(△W(t)=lr*X*ん+a*△W(t-1))tp=[zhen maxnum ex lr biglr litlr a 1.04]; %trainbpx[w1,b1,w2,b2,ep,tr]=trainbpx(w1,b1,"tansig",w2,b2,"purelin", p,t,tp);ww=simuff(pp,w1,b1,"tansig",w2,b2,"purelin"); %ww就是调用结果下面是bpnet使用简例:%bpnet举例,因为BP网络的权值初始化都是随即生成,所以每次运行的状态可能不一样。
1. 数据预处理在训练神经网络前一般需要对数据进行预处理,一种重要的预处理手段是归一化处理。
下面简要介绍归一化处理的原理与方法。
(1) 什么是归一化?数据归一化,就是将数据映射到[0,1]或[-1,1]区间或更小的区间,比如(0.1,0.9) 。
(2) 为什么要归一化处理?<1>输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。
<2>数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
<3>由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。
例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
<4>S形激活函数在(0,1)区间以外区域很平缓,区分度太小。
例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。
(3) 归一化算法一种简单而快速的归一化算法是线性转换算法。
线性转换算法常见有两种形式:<1>y = ( x - min )/( max - min )其中min为x的最小值,max为x的最大值,输入向量为x,归一化后的输出向量为y 。
上式将数据归一化到[ 0 , 1 ]区间,当激活函数采用S形函数时(值域为(0,1))时这条式子适用。
<2>y = 2 * ( x - min ) / ( max - min ) - 1这条公式将数据归一化到[ -1 , 1 ] 区间。
当激活函数采用双极S形函数(值域为(-1,1))时这条式子适用。
(4) Matlab数据归一化处理函数Matlab中归一化处理数据可以采用premnmx ,postmnmx ,tramnmx 这3个函数。
<1> premnmx语法:[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t)参数:pn:p矩阵按行归一化后的矩阵minp,maxp:p矩阵每一行的最小值,最大值tn:t矩阵按行归一化后的矩阵mint,maxt:t矩阵每一行的最小值,最大值作用:将矩阵p,t归一化到[-1,1] ,主要用于归一化处理训练数据集。
计算智能实验报告实验名称:BP神经网络算法实验班级名称: 2010级软工三班专业:软件工程姓名:李XX学号: XXXXXX2010090一、实验目的1)编程实现BP神经网络算法;2)探究BP算法中学习因子算法收敛趋势、收敛速度之间的关系;3)修改训练后BP神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果,理解神经网络分布存储等特点。
二、实验要求按照下面的要求操作,然后分析不同操作后网络输出结果。
1)可修改学习因子2)可任意指定隐单元层数3)可任意指定输入层、隐含层、输出层的单元数4)可指定最大允许误差ε5)可输入学习样本(增加样本)6)可存储训练后的网络各神经元之间的连接权值矩阵;7)修改训练后的BP神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果。
三、实验原理1 明确BP神经网络算法的基本思想如下:在BPNN中,后向传播是一种学习算法,体现为BPNN的训练过程,该过程是需要教师指导的;前馈型网络是一种结构,体现为BPNN的网络构架反向传播算法通过迭代处理的方式,不断地调整连接神经元的网络权重,使得最终输出结果和预期结果的误差最小BPNN是一种典型的神经网络,广泛应用于各种分类系统,它也包括了训练和使用两个阶段。
由于训练阶段是BPNN能够投入使用的基础和前提,而使用阶段本身是一个非常简单的过程,也就是给出输入,BPNN会根据已经训练好的参数进行运算,得到输出结果2 明确BP神经网络算法步骤和流程如下:1初始化网络权值2由给定的输入输出模式对计算隐层、输出层各单元输出3计算新的连接权及阀值,4选取下一个输入模式对返回第2步反复训练直到网络设输出误差达到要求结束训练。
四、实验内容和分析1.实验时建立三层BP神经网络,输入节点2个,隐含层节点2个,输出节代码:P=[0.0 0.0 1.0 1.0;0.0 1.0 0.0 1.0];%输入量矩阵T=[0.0 1.0 1.0 0.0];%输出量矩阵net=newff(minmax(P),T,[2 1],{'tansig','purelin'},'traingd');%创建名为net的BP神经网络inputWeights=net.IW{1,1};%输入层与隐含层的连接权重inputbias=net.b{2};%输入层与隐含层的阈值net.trainParam.epochs=5000;%网络参数:最大训练次数为5000次net.trainParam.goal=0.01;%网络参数:训练精度为0.001 net.trainparam.lr=0.5;%网络参数:学习设置率为0.5net.trainParam.mc=0.6; %动量[net,tr]=train(net,P,T); %训练A=sim(net,P); %仿真E=T-A; %误差MSE=mse(E); %均方误差训练次数5000,全局误差0.0083642.输入测试样本为可见网络性能良好,输出结果基本满足识别要求。
MATLAB程序代码--bp神经网络应用举例1BP神经网络的设计实例例1采用动量梯度下降算法训练BP网络。
训练样本定义如下:输入矢量为p=[-1-231-115-3]目标矢量为t=[-1-111]解:本例的MATLAB程序如下:close allclearecho onclc%NEWFF——生成一个新的前向神经网络%TRAIN——对BP神经网络进行训练%SIM——对BP神经网络进行仿真pause%敲任意键开始clc%定义训练样本%P为输入矢量P=[-1,-2,3,1;-1,1,5,-3];%T为目标矢量T=[-1,-1,1,1];pause;clc%创建一个新的前向神经网络net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingdm')%当前输入层权值和阈值inputWeights=net.IW{1,1}inputbias=net.b{1}%当前网络层权值和阈值layerWeights=net.LW{2,1}layerbias=net.b{2}pauseclc%设置训练参数net.trainParam.show=50;%两次显示之间的训练次数,缺省值为25 net.trainParam.lr=0.05;%学习速率net.trainParam.mc=0.9;%动量常数设置,缺省就是0.9net.trainParam.epochs=1000;%训练次数,缺省值为100net.trainParam.goal=1e-3;%网络性能目标,缺省值为0clc%调用TRAINGDM算法训练BP网络[net,tr]=train(net,P,T);pauseclc%对BP网络进行仿真A=sim(net,P)%计算仿真误差E=T-AMSE=mse(E)pauseclcecho off例2采用贝叶斯正则化算法提高BP网络的推广能力。