模式识别实验报告(一二)
- 格式:doc
- 大小:909.00 KB
- 文档页数:16

《模式识别》实验报告---最小错误率贝叶斯决策分类一、实验原理对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T d p π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ 式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ二、实验步骤(1)从Iris.txt 文件中读取估计参数用的样本,每一类样本抽出前40个,分别求其均值,公式如下11,2,3ii iii N ωωω∈==∑x μxclear% 原始数据导入iris = load('C:\MATLAB7\work\模式识别\iris.txt'); N=40;%每组取N=40个样本%求第一类样本均值 for i = 1:N for j = 1:4w1(i,j) = iris(i,j+1); end endsumx1 = sum(w1,1); for i=1:4meanx1(1,i)=sumx1(1,i)/N; end%求第二类样本均值 for i = 1:N for j = 1:4 w2(i,j) = iris(i+50,j+1);end endsumx2 = sum(w2,1); for i=1:4meanx2(1,i)=sumx2(1,i)/N; end%求第三类样本均值 for i = 1:N for j = 1:4w3(i,j) = iris(i+100,j+1); end endsumx3 = sum(w3,1); for i=1:4meanx3(1,i)=sumx3(1,i)/N; end(2)求每一类样本的协方差矩阵、逆矩阵1i -∑以及协方差矩阵的行列式i ∑, 协方差矩阵计算公式如下11()(),1,2,3,41i ii N i jklj j lk k l i x x j k N ωωσμμ==--=-∑其中lj x 代表i ω类的第l 个样本,第j 个特征值;ij ωμ代表i ω类的i N 个样品第j 个特征的平均值lk x 代表i ω类的第l 个样品,第k 个特征值;iw k μ代表i ω类的i N 个样品第k 个特征的平均值。


实习报告一、实习背景及目的随着科技的飞速发展,模式识别技术在众多领域发挥着越来越重要的作用。
模式识别是指对数据进行分类、识别和解释的过程,其应用范围广泛,包括图像处理、语音识别、机器学习等。
为了更好地了解模式识别技术的原理及其在实际应用中的重要性,我参加了本次模式识别实习。
本次实习的主要目的是:1. 学习模式识别的基本原理和方法;2. 掌握模式识别技术在实际应用中的技巧;3. 提高自己的动手实践能力和团队协作能力。
二、实习内容及过程实习期间,我们团队共完成了四个模式识别项目,分别为:手写数字识别、图像分类、语音识别和机器学习。
下面我将分别介绍这四个项目的具体内容和过程。
1. 手写数字识别:手写数字识别是模式识别领域的一个经典项目。
我们使用了MNIST数据集,这是一个包含大量手写数字图片的数据集。
首先,我们对数据集进行预处理,包括归一化、数据清洗等。
然后,我们采用卷积神经网络(CNN)作为模型进行训练,并使用交叉验证法对模型进行评估。
最终,我们得到了一个识别准确率较高的模型。
2. 图像分类:图像分类是模式识别领域的另一个重要应用。
我们选择了CIFAR-10数据集,这是一个包含大量彩色图像的数据集。
与手写数字识别项目类似,我们先对数据集进行预处理,然后采用CNN进行训练。
在模型训练过程中,我们尝试了不同的优化算法和网络结构,以提高模型的性能。
最终,我们得到了一个识别准确率较高的模型。
3. 语音识别:语音识别是模式识别领域的又一项挑战。
我们使用了TIMIT数据集,这是一个包含大量语音样本的数据集。
首先,我们对语音样本进行预处理,包括特征提取、去噪等。
然后,我们采用循环神经网络(RNN)作为模型进行训练。
在模型训练过程中,我们尝试了不同的优化算法和网络结构。
最后,我们通过对模型进行评估,得到了一个较为可靠的语音识别系统。
4. 机器学习:机器学习是模式识别领域的基础。
我们使用了UCI数据集,这是一个包含多个数据集的数据集。

模式识别实验报告(二)学院:专业:学号:姓名:XXXX教师:目录1实验目的 (1)2实验内容 (1)3实验平台 (1)4实验过程与结果分析 (1)4.1基于BP神经网络的分类器设计 .. 1 4.2基于SVM的分类器设计 (4)4.3基于决策树的分类器设计 (7)4.4三种分类器对比 (8)5.总结 (8)1)1实验目的通过实际编程操作,实现对课堂上所学习的BP神经网络、SVM支持向量机和决策树这三种方法的应用,加深理解,同时锻炼自己的动手实践能力。
2)2实验内容本次实验提供的样本数据有149个,每个数据提取5个特征,即身高、体重、是否喜欢数学、是否喜欢文学及是否喜欢运动,分别将样本数据用于对BP神经网络分类器、SVM支持向量机和决策树训练,用测试数据测试分类器的效果,采用交叉验证的方式实现对于性能指标的评判。
具体要求如下:BP神经网络--自行编写代码完成后向传播算法,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算可以基于平台的软件包);SVM支持向量机--采用平台提供的软件包进行分类器的设计以及测试,尝试不同的核函数设计分类器,采用交叉验证的方式实现对于性能指标的评判;决策树--采用平台提供的软件包进行分类器的设计以及测试,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算基于平台的软件包)。
3)3实验平台专业研究方向为图像处理,用的较多的编程语言为C++,因此此次程序编写用的平台是VisualStudio及opencv,其中的BP神经网络为自己独立编写, SVM 支持向量机和决策树通过调用Opencv3.0库中相应的库函数并进行相应的配置进行实现。
将Excel中的119个数据作为样本数据,其余30个作为分类器性能的测试数据。
4)4实验过程与结果分析4.1基于BP神经网络的分类器设计BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。

《模式识别》实验报告-贝叶斯分类一、实验目的通过使用贝叶斯分类算法,实现对数据集中的样本进行分类的准确率评估,熟悉并掌握贝叶斯分类算法的实现过程,以及对结果的解释。
二、实验原理1.先验概率先验概率指在不考虑其他变量的情况下,某个事件的概率分布。
在贝叶斯分类中,需要先知道每个类别的先验概率,例如:A类占总样本的40%,B类占总样本的60%。
2.条件概率后验概率指在已知先验概率和条件概率下,某个事件发生的概率分布。
在贝叶斯分类中,需要计算每个样本在各特征值下的后验概率,即属于某个类别的概率。
4.贝叶斯公式贝叶斯公式就是计算后验概率的公式,它是由条件概率和先验概率推导而来的。
5.贝叶斯分类器贝叶斯分类器是一种基于贝叶斯定理实现的分类器,可以用于在多个类别的情况下分类,是一种常用的分类方法。
具体实现过程为:首先,使用训练数据计算各个类别的先验概率和各特征值下的条件概率。
然后,将测试数据的各特征值代入条件概率公式中,计算出各个类别的后验概率。
最后,取后验概率最大的类别作为测试数据的分类结果。
三、实验步骤1.数据集准备本次实验使用的是Iris数据集,数据包含150个Iris鸢尾花的样本,分为三个类别:Setosa、Versicolour和Virginica,每个样本有四个特征值:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
2.数据集划分将数据集按7:3的比例分为训练集和测试集,其中训练集共105个样本,测试集共45个样本。
计算三个类别的先验概率,即Setosa、Versicolour和Virginica类别在训练集中出现的频率。
对于每个特征值,根据训练集中每个类别所占的样本数量,计算每个类别在该特征值下出现的频率,作为条件概率。
5.测试数据分类将测试集中的每个样本的四个特征值代入条件概率公式中,计算出各个类别的后验概率,最后将后验概率最大的类别作为该测试样本的分类结果。
6.分类结果评估将测试集分类结果与实际类别进行比较,计算分类准确率和混淆矩阵。
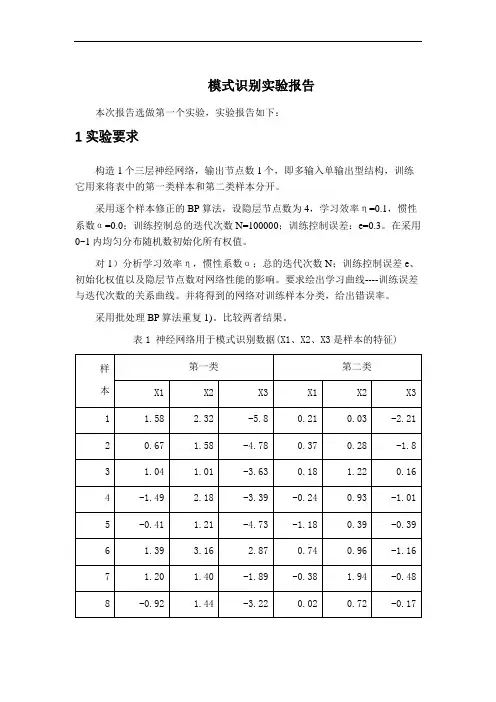
模式识别实验报告本次报告选做第一个实验,实验报告如下:1 实验要求构造1个三层神经网络,输出节点数1个,即多输入单输出型结构,训练它用来将表中的第一类样本和第二类样本分开。
采用逐个样本修正的BP算法,设隐层节点数为4,学习效率η=0.1,惯性系数α=0.0;训练控制总的迭代次数N=100000;训练控制误差:e=0.3。
在采用0~1内均匀分布随机数初始化所有权值。
对1)分析学习效率η,惯性系数α;总的迭代次数N;训练控制误差e、初始化权值以及隐层节点数对网络性能的影响。
要求绘出学习曲线----训练误差与迭代次数的关系曲线。
并将得到的网络对训练样本分类,给出错误率。
采用批处理BP算法重复1)。
比较两者结果。
表1 神经网络用于模式识别数据(X1、X2、X3是样本的特征)2 BP 网络的构建三层前馈神经网络示意图,见图1.图1三层前馈神经网络①网络初始化,用一组随机数对网络赋初始权值,设置学习步长η、允许误差ε、网络结构(即网络层数L 和每层节点数n l );②为网络提供一组学习样本; ③对每个学习样本p 循环a .逐层正向计算网络各节点的输入和输出;b .计算第p 个样本的输出的误差Ep 和网络的总误差E ;c .当E 小于允许误差ε或者达到指定的迭代次数时,学习过程结束,否则,进行误差反向传播。
d .反向逐层计算网络各节点误差)(l jp δ如果l f 取为S 型函数,即xl e x f -+=11)(,则 对于输出层))(1()()()()(l jp jdp l jp l jp l jp O y O O --=δ 对于隐含层∑+-=)1()()()()()1(l kj l jp l jp l jp l jp w O O δδe .修正网络连接权值)1()()()1(-+=+l ip l jp ij ij O k W k W ηδ式中,k 为学习次数,η为学习因子。
η取值越大,每次权值的改变越剧烈,可能导致学习过程振荡,因此,为了使学习因子的取值足够大,又不至产生振荡,通常在权值修正公式中加入一个附加动量法。

《模式识别》大作业人脸识别方法二---- 基于PCA 和FLD 的人脸识别的几何分类器(修改稿)一、 理论知识1、fisher 概念引出在应用统计方法解决模式识别问题时,为了解决“维数灾难”的问题,压缩特征空间的维数非常必要。
fisher 方法实际上涉及到维数压缩的问题。
fisher 分类器是一种几何分类器, 包括线性分类器和非线性分类器。
线性分类器有:感知器算法、增量校正算法、LMSE 分类算法、Fisher 分类。
若把多维特征空间的点投影到一条直线上,就能把特征空间压缩成一维。
那么关键就是找到这条直线的方向,找得好,分得好,找不好,就混在一起。
因此fisher 方法目标就是找到这个最好的直线方向以及如何实现向最好方向投影的变换。
这个投影变换恰是我们所寻求的解向量*W ,这是fisher 算法的基本问题。
样品训练集以及待测样品的特征数目为n 。
为了找到最佳投影方向,需要计算出各类均值、样品类内离散度矩阵i S 和总类间离散度矩阵w S 、样品类间离散度矩阵b S ,根据Fisher 准则,找到最佳投影准则,将训练集内所有样品进行投影,投影到一维Y 空间,由于Y 空间是一维的,则需要求出Y 空间的划分边界点,找到边界点后,就可以对待测样品进行进行一维Y 空间的投影,判断它的投影点与分界点的关系,将其归类。
Fisher 法的核心为二字:投影。
二、 实现方法1、 一维实现方法(1) 计算给类样品均值向量i m ,i m 是各个类的均值,i N 是i ω类的样品个数。
11,2,...,ii X im X i nN ω∈==∑(2) 计算样品类内离散度矩阵iS 和总类间离散度矩阵wS1()()1,2,...,i Ti i i X w ii S X m X m i nS Sω∈==--==∑∑(3) 计算样品类间离散度矩阵b S1212()()Tb S m m m m =--(4) 求向量*W我们希望投影后,在一维Y 空间各类样品尽可能地分开,也就是说我们希望两类样品均值之差(12m m -)越大越好,同时希望各类样品内部尽量密集,即希望类内离散度越小越好,因此,我们可以定义Fisher 准则函数:()Tb F Tw W S W J W W S W=使得()F J W 取得最大值的*W 为 *112()w WS m m -=-(5) 将训练集内所有样品进行投影*()Ty W X =(6) 计算在投影空间上的分割阈值0y在一维Y 空间,各类样品均值i m为 11,2,...,ii y imy i n N ω∈==∑样品类内离散度矩阵2i s和总类间离散度矩阵w s 22()ii iy sy mω∈=-∑21w ii ss==∑【注】【阈值0y 的选取可以由不同的方案: 较常见的一种是1122012N m N m y N N +=+另一种是121201ln(()/())22m m P P y N N ωω+=++- 】(7) 对于给定的X ,计算出它在*W 上的投影y (8) 根据决策规则分类0102y y X y y X ωω>⇒∈⎧⎨<⇒∈⎩2、程序中算法的应用Fisher 线性判别方法(FLD )是在Fisher 鉴别准则函数取极值的情况下,求得一个最佳判别方向,然后从高位特征向量投影到该最佳鉴别方向,构成一个一维的判别特征空间将Fisher 线性判别推广到C-1个判决函数下,即从N 维空间向C-1维空间作相应的投影。

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。

模式识别实验报告(2)姓名:某某某班号:075113学号:2011100xxxx指导老师:马丽基于kNN算法的遥感图像分类一、目标:1. 掌握KNN算法原理2. 用MATLAB实现kNN算法,并进行结果分析二、算法分析:所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用她最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
kNN方法在类别决策时,只与极少量的相邻样本有关。
由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
三、实验内容:1.利用所有带标记的数据作为train数据,调用KNN分类函数KNN_Cla()对整个图像进行分类,得到整个图像的分类结果图。
2.随机在所有带标记的数据中选择train和test数据(50%train数据,50%test 数据)然后进行kNN分类。
随机选择10次,计算总体分类精度OA,然后求平均结果,作为最终对算法的评价。
K值依次选择1,3,5,7,9,11,分别用这6种K的取值进行kNN算法,得到每种K值下的总体分类精度OA,然后进行比较。
分类结果:四、数据介绍:zy3sample1:资源三号卫星遥感图,Img为读入遥感图生成的400*400*4矩阵。
xy3roi:ROI数据,GT为读入ROI生成的400*400矩阵。
INP_200:INP高光谱数据145*145*200。
92A V3GT_cls:ROI数据45*145。
五、实验程序:function [result,OA]=knn_classifier(X_train,Y_train,X_test,Y_test,options)%% 实现KNN分类% 输入参数% X_train : N*D% Y_train : 1*N% X_test : N*D% 输出参数% result :N*1% OA :精确度for k=1:len%一次处理1个点len=length(X_test);d=Euclidian_distance(X_train,X_test(k,:);%计算所有待分类点到所有训练点的距离[D,n]=sort(d);ind=n(1:option.K);%找到所有距离中最小的K个距离for k=1:len%一次处理1个点C(k)=length(find(Y_train(ind)==k);endindc=find(max(C));result(k)=indc(1);end;error=length(find(result'~=Y_test));%求出差错率OA=1-error/len;六、实验结果:zy3sample数据KNN分类结果(K=1):不同k值下的OA变化曲线图:七、心得体会:这次的程序主要是弄懂KNN 算法的思想就可以画出流程图其实最主要的就是搞清楚中间迭代部分的写法。

模式识别技术实验报告本实验旨在探讨模式识别技术在计算机视觉领域的应用与效果。
模式识别技术是一种人工智能技术,通过对数据进行分析、学习和推理,识别其中的模式并进行分类、识别或预测。
在本实验中,我们将利用机器学习算法和图像处理技术,对图像数据进行模式识别实验,以验证该技术的准确度和可靠性。
实验一:图像分类首先,我们将使用卷积神经网络(CNN)模型对手写数字数据集进行分类实验。
该数据集包含大量手写数字图片,我们将训练CNN模型来识别并分类这些数字。
通过调整模型的参数和训练次数,我们可以得到不同准确度的模型,并通过混淆矩阵等评估指标来评估模型的性能和效果。
实验二:人脸识别其次,我们将利用人脸数据集进行人脸识别实验。
通过特征提取和比对算法,我们可以识别不同人脸之间的相似性和差异性。
在实验过程中,我们将测试不同算法在人脸识别任务上的表现,比较它们的准确度和速度,探讨模式识别技术在人脸识别领域的应用潜力。
实验三:异常检测最后,我们将进行异常检测实验,使用模式识别技术来识别图像数据中的异常点或异常模式。
通过训练异常检测模型,我们可以发现数据中的异常情况,从而做出相应的处理和调整。
本实验将验证模式识别技术在异常检测领域的有效性和实用性。
结论通过以上实验,我们对模式识别技术在计算机视觉领域的应用进行了初步探索和验证。
模式识别技术在图像分类、人脸识别和异常检测等任务中展现出了良好的性能和准确度,具有广泛的应用前景和发展空间。
未来,我们将进一步深入研究和实践,探索模式识别技术在更多领域的应用,推动人工智能技术的发展和创新。
【字数:414】。
姓名:学号:院系:电子与信息工程学院课程名称:模式识别实验名称:神经网络用于模式识别同组人:实验成绩:总成绩:教师评语教师签字:年月日1实验目的1.掌握人工神经网络的基本结构与原理,理解神经网络在模式识别中的应用;2.学会使用多输入多输出结构,构造三层神经网络并对给定的样本进行分类;3.分析学习效率η,惯性系数α,总的迭代次数N,训练控制误差ε,初始化权值以及隐层节点数对网络性能的影响;4.采用批处理BP重复算法进行分类,结果与三层神经网络进行对比。
2原理2.1人工神经网络人工神经网络(Artificial Neural Network,即ANN),是20世纪80年代以来人工智能领域兴起的研究热点。
它从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。
在工程与学术界也常直接简称为神经网络或类神经网络。
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。
每个节点代表一种特定的输出函数,称为激励函数(activation function)。
每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。
网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。
而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
最近十多年来,人工神经网络的研究工作不断深入,已经取得了很大的进展,其在模式识别、智能机器人、自动控制、预测估计、生物、医学、经济等领域已成功地解决了许多现代计算机难以解决的实际问题,表现出了良好的智能特性。
2.1.1人工神经元图 1 生物神经元神经元是大脑处理信息的基本单元,以细胞体为主体,由许多向周围延伸的不规则树枝状纤维构成的神经细胞,其形状很像一棵枯树的枝干。
它主要由细胞体、树突、轴突和突触(Synapse,又称神经键)组成。
胞体:是神经细胞的本体(可看成系统);树突:长度较短,接受自其他神经元的信号(输入); 轴突:它用以输出信号;突触:它是一个神经元与另一个神经元相联系的部位,是一个神经元轴突的端部将信号(兴奋)传递给下一个神经元的树突或胞体;对树突的突触多为兴奋性的,使下一个神经元兴奋;而对胞体的突触多为抑制性,其作用是阻止下一个神经元兴奋。
一、实验背景随着计算机科学和信息技术的飞速发展,模式识别技术在各个领域得到了广泛应用。
模式识别是指通过对数据的分析、处理和分类,从大量数据中提取有用信息,从而实现对未知模式的识别。
本实验旨在通过实践操作,加深对模式识别基本概念、算法和方法的理解,并掌握其应用。
二、实验目的1. 理解模式识别的基本概念、算法和方法;2. 掌握常用的模式识别算法,如K-均值聚类、决策树、支持向量机等;3. 熟悉模式识别在实际问题中的应用,提高解决实际问题的能力。
三、实验内容本次实验共分为三个部分:K-均值聚类算法、决策树和神经网络。
1. K-均值聚类算法(1)实验目的通过实验加深对K-均值聚类算法的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组二维数据,包括100个样本,每个样本包含两个特征值;② 初始化聚类中心:随机选择K个样本作为初始聚类中心;③ 计算每个样本到聚类中心的距离,并将其分配到最近的聚类中心;④ 更新聚类中心:计算每个聚类中所有样本的均值,作为新的聚类中心;⑤ 重复步骤③和④,直到聚类中心不再变化。
(3)实验结果通过实验,可以得到K个聚类中心,每个样本被分配到最近的聚类中心。
通过可视化聚类结果,可以直观地看到数据被分成了K个类别。
2. 决策树(1)实验目的通过实验加深对决策树的理解,掌握其基本原理和实现方法。
(2)实验步骤① 准备实验数据:选取一组具有分类标签的二维数据,包括100个样本,每个样本包含两个特征值;② 选择最优分割特征:根据信息增益或基尼指数等指标,选择最优分割特征;③ 划分数据集:根据最优分割特征,将数据集划分为两个子集;④ 递归地执行步骤②和③,直到满足停止条件(如达到最大深度、叶节点中样本数小于阈值等);⑤ 构建决策树:根据递归分割的结果,构建决策树。
(3)实验结果通过实验,可以得到一棵决策树,可以用于对新样本进行分类。
3. 神经网络(1)实验目的通过实验加深对神经网络的理解,掌握其基本原理和实现方法。
模式识别实验报告实验一、线性分类器的设计与实现1. 实验目的:掌握模式识别的基本概念,理解线性分类器的算法原理。
2. 实验要求:(1)学习和掌握线性分类器的算法原理;(2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类;(3)对实现的线性分类器性能进行简单的评估(例如算法适用条件,算法效率及复杂度等)。
注:三种线性分类器为,单样本感知器算法、批处理感知器算法、最小均方差算法批处理感知器算法算法原理:感知器准则函数为J p a=(−a t y)y∈Y,这里的Y(a)是被a错分的样本集,如果没有样本被分错,Y就是空的,这时我们定义J p a为0.因为当a t y≤0时,J p a是非负的,只有当a是解向量时才为0,也即a在判决边界上。
从几何上可知,J p a是与错分样本到判决边界距离之和成正比的。
由于J p梯度上的第j个分量为∂J p/ða j,也即∇J p=(−y)y∈Y。
梯度下降的迭代公式为a k+1=a k+η(k)yy∈Y k,这里Y k为被a k错分的样本集。
算法伪代码如下:begin initialize a,η(∙),准则θ,k=0do k=k+1a=a+η(k)yy∈Y k|<θuntil | ηk yy∈Y kreturn aend因此寻找解向量的批处理感知器算法可以简单地叙述为:下一个权向量等于被前一个权向量错分的样本的和乘以一个系数。
每次修正权值向量时都需要计算成批的样本。
算法源代码:unction [solution iter] = BatchPerceptron(Y,tau)%% solution = BatchPerceptron(Y,tau) 固定增量批处理感知器算法实现%% 输入:规范化样本矩阵Y,裕量tau% 输出:解向量solution,迭代次数iter[y_k d] = size(Y);a = zeros(1,d);k_max = 10000; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% k=0;y_temp=zeros(d,1);while k<k_maxc=0;for i=1:1:y_kif Y(i,:)*a'<=tauy_temp=y_temp+Y(i,:)';c=c+1;endendif c==0break;enda=a+y_temp';k=k+1;end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %k = k_max;solution = a;iter = k-1;运行结果及分析:数据1的分类结果如下由以上运行结果可以知道,迭代17次之后,算法得到收敛,解出的权向量序列将样本很好的划分。
信息与通信工程学院模式识别实验报告班级:姓名:学号:日期:2011年12月实验一、Bayes 分类器设计一、实验目的:1.对模式识别有一个初步的理解2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识3.理解二类分类器的设计原理二、实验条件:matlab 软件三、实验原理:最小风险贝叶斯决策可按下列步骤进行: 1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==cj iii i i P X P P X P X P 1)()()()()(ωωωωω j=1,…,x2)利用计算出的后验概率及决策表,按下面的公式计算出采取ia ,i=1,…,a 的条件风险∑==cj j jii X P a X a R 1)(),()(ωωλ,i=1,2,…,a3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策ka ,即()()1,min k i i aR a x R a x ==则ka 就是最小风险贝叶斯决策。
四、实验内容假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。
现有一系列待观察的细胞,其观察值为x :已知先验概率是的曲线如下图:)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果进行分类。
五、实验步骤:1.用matlab 完成分类器的设计,说明文字程序相应语句,子程序有调用过程。
2.根据例子画出后验概率的分布曲线以及分类的结果示意图。
3.最小风险贝叶斯决策,决策表如下:结果,并比较两个结果。
六、实验代码1.最小错误率贝叶斯决策 x=[] pw1=; pw2=; e1=-2; a1=; e2=2;a2=2;m=numel(x); %得到待测细胞个数pw1_x=zeros(1,m); %存放对w1的后验概率矩阵 pw2_x=zeros(1,m); %存放对w2的后验概率矩阵results=zeros(1,m); %存放比较结果矩阵for i = 1:m%计算在w1下的后验概率pw1_x(i)=(pw1*normpdf(x(i),e1,a1))/(pw1*normpdf(x(i),e1,a1)+pw2*normp df(x(i),e2,a2)) ;%计算在w2下的后验概率pw2_x(i)=(pw2*normpdf(x(i),e2,a2))/(pw1*normpdf(x(i),e1,a1)+pw2*normp df(x(i),e2,a2)) ;endfor i = 1:mif pw1_x(i)>pw2_x(i) %比较两类后验概率result(i)=0; %正常细胞elseresult(i)=1; %异常细胞endenda=[-5::5]; %取样本点以画图n=numel(a);pw1_plot=zeros(1,n);pw2_plot=zeros(1,n);for j=1:npw1_plot(j)=(pw1*normpdf(a(j),e1,a1))/(pw1*normpdf(a(j),e1,a1)+pw2*no rmpdf(a(j),e2,a2));%计算每个样本点对w1的后验概率以画图pw2_plot(j)=(pw2*normpdf(a(j),e2,a2))/(pw1*normpdf(a(j),e1,a1)+pw2*no rmpdf(a(j),e2,a2));endfigure(1);hold onplot(a,pw1_plot,'co',a,pw2_plot,'r-.');for k=1:mif result(k)==0plot(x(k),,'cp'); %正常细胞用五角星表示elseplot(x(k),,'r*'); %异常细胞用*表示end;end;legend('正常细胞后验概率曲线','异常细胞后验概率曲线','正常细胞','异常细胞');xlabel('样本细胞的观察值');ylabel('后验概率');title('后验概率分布曲线');grid onreturn%实验内容仿真:x = [, ,,, , ,, , , ,,,,,,, ,,,,,,, ]disp(x);pw1=;pw2=;[result]=bayes(x,pw1,pw2);2.最小风险贝叶斯决策x=[]pw1=; pw2=;m=numel(x); %得到待测细胞个数R1_x=zeros(1,m); %存放把样本X判为正常细胞所造成的整体损失R2_x=zeros(1,m); %存放把样本X判为异常细胞所造成的整体损失result=zeros(1,m); %存放比较结果e1=-2;a1=;e2=2;a2=2;%类条件概率分布px_w1:(-2,) px_w2(2,4)r11=0;r12=2;r21=4;r22=0;%风险决策表for i=1:m%计算两类风险值R1_x(i)=r11*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*norm pdf(x(i),e2,a2))+r21*pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1) +pw2*normpdf(x(i),e2,a2));R2_x(i)=r12*pw1*normpdf(x(i),e1,a1)/(pw1*normpdf(x(i),e1,a1)+pw2*norm pdf(x(i),e2,a2))+r22*pw2*normpdf(x(i),e2,a2)/(pw1*normpdf(x(i),e1,a1) +pw2*normpdf(x(i),e2,a2));endfor i=1:mif R2_x(i)>R1_x(i) %第二类比第一类风险大result(i)=0; %判为正常细胞(损失较小),用0表示elseresult(i)=1; %判为异常细胞,用1表示endenda=[-5::5] ; %取样本点以画图n=numel(a);R1_plot=zeros(1,n);R2_plot=zeros(1,n);for j=1:nR1_plot(j)=r11*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*n ormpdf(a(j),e2,a2))+r21*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1, a1)+pw2*normpdf(a(j),e2,a2))R2_plot(j)=r12*pw1*normpdf(a(j),e1,a1)/(pw1*normpdf(a(j),e1,a1)+pw2*n ormpdf(a(j),e2,a2))+r22*pw2*normpdf(a(j),e2,a2)/(pw1*normpdf(a(j),e1, a1)+pw2*normpdf(a(j),e2,a2))%计算各样本点的风险以画图endfigure(1);hold onplot(a,R1_plot,'co',a,R2_plot,'r-.');for k=1:mif result(k)==0plot(x(k),,'cp');%正常细胞用五角星表示elseplot(x(k),,'r*');%异常细胞用*表示end;end;legend('正常细胞','异常细胞','Location','Best');xlabel('细胞分类结果');ylabel('条件风险');title('风险判决曲线');grid onreturn%实验内容仿真:x = [, ,,, , ,, , , ,,,,,,, ,,,,,,, ]disp(x);pw1=;pw2=;[result]=bayes(x,pw1,pw2);七、实验结果1.最小错误率贝叶斯决策后验概率曲线与判决显示在上图中后验概率曲线:带红色虚线曲线是判决为异常细胞的后验概率曲线青色实线曲线是为判为正常细胞的后验概率曲线根据最小错误概率准则,判决结果显示在曲线下方:五角星代表判决为正常细胞,*号代表异常细胞各细胞分类结果(0为判成正常细胞,1为判成异常细胞):0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 0 0 1 0 12. 最小风险贝叶斯决策风险判决曲线如上图所示:带红色虚线曲线是异常细胞的条件风险曲线;青色圆圈曲线是正常细胞的条件风险曲线根据贝叶斯最小风险判决准则,判决结果显示在曲线下方:五角星代表判决为正常细胞,*号代表异常细胞各细胞分类结果(0为判成正常细胞,1为判成异常细胞):1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1 1 0 0 0 1 0 1八、实验分析由最小错误率的贝叶斯判决和基于最小风险的贝叶斯判决得出的图形中的分类结果可看出,样本、在前者中被分为“正常细胞”,在后者中被分为“异常细胞”,分类结果完全相反。
分析可知在最小风险的贝叶斯判决中,影响结果的因素多了一个“损失”。
在第一张图中,这两个样本点下两类决策的后验概率相差很小,当结合最小风险贝叶斯决策表进行计算时,“损失”起了主导作用,导致了相反的结果的出现。
同时,最小错误率贝叶斯决策就是在0-1损失函数条件下的最小风险贝叶斯决策,即前者是后者的特例。
九、实验心得通过本次实验,我对模式识别有了一个初步的理解,开始对模式识别的相关知识从书本上转移到了实践中,并跟据自己的设计对贝叶斯决策理论算法有一个深刻地认识,同时也理解二类分类器的设计原理。
同时,之前只学过浅显的Matlab 知识,用Matlab实现数值计算的能力又一次得到了训练,对以后的学习和实验都有极大的帮助。
实验二、基于Fisher 准则线性分类器设计一、实验目的:1.进一步了解分类器的设计概念2.能够根据自己的设计对线性分类器有更深刻地认识3.理解Fisher 准则方法确定最佳线性分界面方法的原理及Lagrande 乘子求解的原理二、实验条件:matlab 软件三、实验原理:线性判别函数的一般形式可表示成0)(w X W X g T+= 其中⎪⎪⎪⎭⎫⎝⎛=d x x X 1 ⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=d w w w W 21根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向W 的函数为:2221221~~)~~()(S S m m W J F +-= )(211*m m S W W -=-上面的公式是使用Fisher 准则求最佳法线向量的解,该式比较重要。