模式识别实验报告iris
- 格式:doc
- 大小:298.36 KB
- 文档页数:12
实验报告试验课程名称: 模式识别姓名: 王宇班级: 0813 学号: 081325注: 1、每个试验中各项成绩根据5分制评定, 试验成绩为各项总和2、平均成绩取各项试验平均成绩3、折合成绩根据教学纲领要求百分比进行折合6月试验一、 图像贝叶斯分类一、 试验目将模式识别方法与图像处理技术相结合, 掌握利用最小错分概率贝叶斯分类器进行图像分类基础方法, 经过试验加深对基础概念了解。
二、 试验仪器设备及软件 HP D538、 MATLAB 三、 试验原理 概念:阈值化分割算法是计算机视觉中常见算法, 对灰度图象阈值分割就是先确定一个处于图像灰度取值范围内灰度阈值, 然后将图像中每个像素灰度值与这个阈值相比较。
并依据比较结果将对应像素划分为两类, 灰度值大于阈值像素划分为一类, 小于阈值划分为另一类, 等于阈值可任意划分到两类中任何一类。
最常见模型可描述以下: 假设图像由含有单峰灰度分布目标和背景组成, 处于目标和背景内部相邻像素间灰度值是高度相关, 但处于目标和背景交界处两边像素灰度值有较大差异, 此时, 图像灰度直方图基础上可看作是由分别对应于目标和背景两个单峰直方图混合组成。
而且这两个分布应大小靠近, 且均值足够远, 方差足够小, 这种情况下直方图展现较显著双峰。
类似地, 假如图像中包含多个单峰灰度目标, 则直方图可能展现较显著多峰。
上述图像模型只是理想情况, 有时图像中目标和背景灰度值有部分交错。
这时如用全局阈值进行分割肯定会产生一定误差。
分割误差包含将目标分为背景和将背景分为目标两大类。
实际应用中应尽可能减小错误分割概率, 常见一个方法为选择最优阈值。
这里所谓最优阈值, 就是指能使误分割概率最小分割阈值。
图像直方图能够看成是对灰度值概率分布密度函数一个近似。
如一幅图像中只包含目标和背景两类灰度区域, 那么直方图所代表灰度值概率密度函数能够表示为目标和背景两类灰度值概率密度函数加权和。
假如概率密度函数形式已知, 就有可能计算出使目标和背景两类误分割概率最小最优阈值。


实验一、二维随机数的产生1、实验目的(1) 学习采用Matlab 程序产生正态分布的二维随机数 (2) 掌握估计类均值向量和协方差矩阵的方法(3) 掌握类间离散度矩阵、类内离散度矩阵的计算方法(4) 熟悉matlab 中运用mvnrnd 函数产生二维随机数等matlab 语言2、实验原理多元正态分布概率密度函数:11()()2/21/21()(2)||T X X d p X eμμπ---∑-=∑其中:μ是d 维均值向量:Td E X μμμμ=={}[,,...,]12Σ是d ×d 维协方差矩阵:TE X X μμ∑=--[()()](1)估计类均值向量和协方差矩阵的估计 各类均值向量1ii X im X N ω∈=∑ 各类协方差矩阵1()()iTi iiX iX X N ωμμ∈∑=--∑(2)类间离散度矩阵、类内离散度矩阵的计算类内离散度矩阵:()()iTi iiX S X m X m ω∈=--∑, i=1,2总的类内离散度矩阵:12W S S S =+类间离散度矩阵:1212()()Tb S m m m m =--3、实验内容及要求产生两类均值向量、协方差矩阵如下的样本数据,每类样本各50个。
1[2,2]μ=--,11001⎡⎤∑=⎢⎥⎣⎦,2[2,2]μ=,21004⎡⎤∑=⎢⎥⎣⎦ (1)画出样本的分布图;(2) 编写程序,估计类均值向量和协方差矩阵;(3) 编写程序,计算类间离散度矩阵、类内离散度矩阵; (4)每类样本数增加到500个,重复(1)-(3)4、实验结果(1)、样本的分布图(2)、类均值向量、类协方差矩阵根据matlab 程序得出的类均值向量为:N=50 : m1=[-1.7160 -2.0374] m2=[2.1485 1.7678] N=500: m1=[-2.0379 -2.0352] m2=[2.0428 2.1270] 根据matlab 程序得出的类协方差矩阵为:N=50: ]0628.11354.01354.06428.1[1=∑ ∑--2]5687.40624.00624.08800.0[N=500:∑--1]0344.10162.00162.09187.0[∑2]9038.30211.00211.09939.0[(3)、类间离散度矩阵、类内离散度矩阵根据matlab 程序得出的类间离散度矩阵为:N=50: ]4828.147068.147068.149343.14[=bS N=500: ]3233.179843.169843.166519.16[b =S根据matlab 程序得出的类内离散度矩阵为:N=50:]0703.533088.73088.71052.78[1=S ]7397.2253966.13966.18975.42[2--=S ]8100.2789123.59123.50026.121[=W SN=500: ]5964.5167490.87490.86203.458[1--=S ]8.19438420.78420.70178.496[2=S ]4.24609071.09071.06381.954[--=W S5、结论由mvnrnd 函数产生的结果是一个N*D 的一个矩阵,在本实验中D 是2,N 是50和500.根据实验数据可以看出,当样本容量变多的时候,两个变量的总体误差变小,观测变量各个取值之间的差异程度减小。

武汉理工大学模式识别实验报告姓名:班级:学号:姓名:班级:学号:实验一总体概率密度分布的非参数方法一、实验目的1.了解使用非参数方法估计样本概率密度函数的原理。
2.了解Parzen窗法的原理及其参数h1,N对估计结果的影响。
3.掌握Parzen窗法的算法并用Matlab实现。
4.使用Matlab分析Parzen窗法的参数h1,N对估计结果的影响。
二、实验数据一维正态分布样本,使用函数randn生成。
三、实验结果选取的h1=0.25,1,4,N=1,16,256,4096,65536,得到15个估计结果,如下图所示。
由下面三组仿真结果可知,估计结果依赖于N和h1。
当N=1时,是一个以样本为中心的小丘。
当N=16和h1=0.25时,仍可以看到单个样本所起的作用;但当h1=1及h1=4时就受到平滑,单个样本的作用模糊了。
随着N的增加,估计量越来越好。
这说明,要想得到较精确的估计,就需要大量的样本。
但是当N取的很大,h1相对较小时,在某些区间内hN趋于零,导致估计的结果噪声大。
分析实验数据发现在h1=4,N=256时,估计结果最接近真实分布。
附录:1.Parzen窗法函数文件parzen.m function parzen=parzen(N,h1,x) %ParzenhN = h1/sqrt(N);num_x = numel(x);parzen = zeros(1, num_x);for u = 1:num_xfor i=1:Nparzen(u) = parzen(u)+exp(((x(u)-x(i))/hN).^2/-2);endparzen(u)=parzen(u)/sqrt(2*pi)/h1/sqrt(N);end2.例程文件parzen_sample.mx = randn(1,10000);%Normally distributed pseudorandom numberspx = normpdf(x,0,1);%Normal probability density function - normpdf(X,mu,sigma)h1 = [0.25, 1, 4];N = [1, 16, 256, 1024, 4096];num_h1 = numel(h1);%Number of array elementsnum_N = numel(N);figure('Name', '总体概率密度分布的非参数方法');%遍历h1for i_h1 = 1:length(h1)h1_offset = (i_h1-1)*(num_N+1)+1;%绘图位置的偏移量subplot(num_h1, num_N+1, h1_offset);plot(x, px, '.');ylabel(sprintf('%s%4.2f', 'h1=', h1(i_h1)));title('正态分布样本的概率密度函数')%遍历Nfor i_N = 1 : length(N)pNx=parzen(N(i_N), h1(i_h1), x);subplot(num_h1, num_N+1, h1_offset+i_N);plot(x, pNx, '.');title(sprintf('%s%d', 'N=', N(i_N)));endend姓名:班级:学号:实验二感知器准则算法实验一、实验目的1.了解利用线性判别函数进行分类的原理。

《模式识别》实验报告---最小错误率贝叶斯决策分类一、实验原理对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T d p π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ 式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ二、实验步骤(1)从Iris.txt 文件中读取估计参数用的样本,每一类样本抽出前40个,分别求其均值,公式如下11,2,3ii iii N ωωω∈==∑x μxclear% 原始数据导入iris = load('C:\MATLAB7\work\模式识别\iris.txt'); N=40;%每组取N=40个样本%求第一类样本均值 for i = 1:N for j = 1:4w1(i,j) = iris(i,j+1); end endsumx1 = sum(w1,1); for i=1:4meanx1(1,i)=sumx1(1,i)/N; end%求第二类样本均值 for i = 1:N for j = 1:4 w2(i,j) = iris(i+50,j+1);end endsumx2 = sum(w2,1); for i=1:4meanx2(1,i)=sumx2(1,i)/N; end%求第三类样本均值 for i = 1:N for j = 1:4w3(i,j) = iris(i+100,j+1); end endsumx3 = sum(w3,1); for i=1:4meanx3(1,i)=sumx3(1,i)/N; end(2)求每一类样本的协方差矩阵、逆矩阵1i -∑以及协方差矩阵的行列式i ∑, 协方差矩阵计算公式如下11()(),1,2,3,41i ii N i jklj j lk k l i x x j k N ωωσμμ==--=-∑其中lj x 代表i ω类的第l 个样本,第j 个特征值;ij ωμ代表i ω类的i N 个样品第j 个特征的平均值lk x 代表i ω类的第l 个样品,第k 个特征值;iw k μ代表i ω类的i N 个样品第k 个特征的平均值。

模式识别实验报告学生姓名:班学号:指导老师:机械与电子信息学院2014年 6月基于K-means算法的改进算法方法一:层次K均值聚类算法在聚类之前,传统的K均值算法需要指定聚类的样本数,由于样本初始分布不一致,有的聚类样本可能含有很多数据,但数据分布相对集中,而有的样本集却含有较少数据,但数据分布相对分散。
因此,即使是根据样本数目选择聚类个数,依然可能导致聚类结果中同一类样本差异过大或者不同类样本差异过小的问题,无法得到满意的聚类结果。
结合空间中的层次结构而提出的一种改进的层次K均值聚类算法。
该方法通过初步聚类,判断是否达到理想结果,从而决定是否继续进行更细层次的聚类,如此迭代执行,生成一棵层次型K均值聚类树,在该树形结构上可以自动地选择聚类的个数。
标准数据集上的实验结果表明,与传统的K均值聚类方法相比,提出的改进的层次聚类方法的确能够取得较优秀的聚类效果。
设X = {x1,x2,…,xi,…,xn }为n个Rd 空间的数据。
改进的层次结构的K均值聚类方法(Hierarchical K means)通过动态地判断样本集X当前聚类是否合适,从而决定是否进行下一更细层次上的聚类,这样得到的最终聚类个数一定可以保证聚类测度函数保持一个较小的值。
具体的基于层次结构的K均值算法:步骤1 选择包含n个数据对象的样本集X = {x1,x2,…,xi,…,xn},设定初始聚类个数k1,初始化聚类目标函数J (0) =0.01,聚类迭代次数t初始化为1,首先随机选择k1个聚类中心。
步骤2 衡量每个样本xi (i = 1,2,…,n)与每个类中心cj ( j = 1,2,…,k)之间的距离,并将xi归为与其最相似的类中心所属的类,并计算当前聚类后的类测度函数值J (1) 。
步骤3 进行更细层次的聚类,具体步骤如下:步骤3.1 根据式(5)选择类半径最大的类及其类心ci :ri = max ||xj - ci||,j = 1,2,…,ni且xj属于Xj(5)步骤3.2 根据距离公式(1)选择该类中距离类ci最远的样本点xi1,然后选择该类中距离xi1最远的样本点xi2。
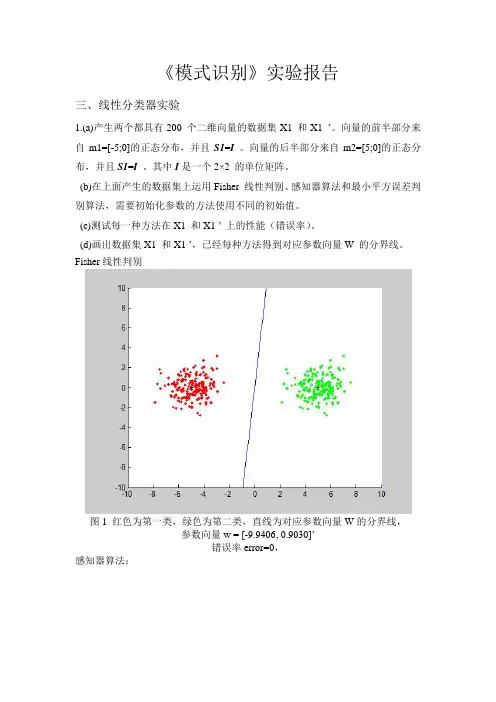
《模式识别》实验报告三、线性分类器实验1.(a)产生两个都具有200 个二维向量的数据集X1 和X1 ’。
向量的前半部分来自m1=[-5;0]的正态分布,并且S1=I 。
向量的后半部分来自m2=[5;0]的正态分布,并且S1=I。
其中I是一个2×2 的单位矩阵。
(b)在上面产生的数据集上运用Fisher 线性判别、感知器算法和最小平方误差判别算法,需要初始化参数的方法使用不同的初始值。
(c)测试每一种方法在X1 和X1 ’ 上的性能(错误率)。
(d)画出数据集X1 和X1 ’,已经每种方法得到对应参数向量W 的分界线。
Fisher线性判别图1 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数向量w = [-9.9406, 0.9030]’错误率error=0,感知器算法:图2 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1;0.1];迭代次数iter=2参数向量w = [-4.8925, 0.0920]’错误率error=0图3 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];迭代次数iter=2参数向量w = [-3.9925, 0.9920]’错误率error=0图4 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[10; 10];迭代次数iter=122参数向量w = [-5.6569, 7.8096]’错误率error=0图5 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 50];迭代次数iter=600参数向量w = [-27.0945, 37.4194]’错误率error=0图6 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 100];迭代次数iter=1190参数向量w = [-54.0048, 74.5875]’错误率error=0最小平方误差判别算法:图7 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1; 0.1];参数向量w = [-0.1908, -0.0001]’错误率error=0图8 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.5; 0.5];参数向量w = [-0.1924, 0.1492]’错误率error=0图9 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 0.5];参数向量w = [-0.1914, 0.0564]’错误率error=0图10 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];参数向量w = [-0.1943, 0.3359]’错误率error= 0.00502.重复1.中的实验内容,数据集为X2 和X2 ’。

河海大学物联网工程学院《模式识别》课程实验报告学号 _______________专业 ____计算机科学与技术_____ 授课班号 _________________________ 学生姓名 ___________________指导教师 ___________________完成时间 _______________实验报告格式如下(必要任务必须写上,可选的课后实验任务是加分项,不是必要任务,可不写):实验一、Fisher分类器实验1.实验原理如果在二维空间中一条直线能将两类样本分开,或者错分类很少,则同一类别样本数据在该直线的单位法向量上的投影的绝大多数都应该超过某一值。
而另一类数据的投影都应该小于(或绝大多数都小于)该值,则这条直线就有可能将两类分开。
准则:向量W的方向选择应能使两类样本投影的均值之差尽可能大些,而使类內样本的离散程度尽可能小。
2.实验任务(1)两类各有多少组训练数据?(易)(2)试着用MATLAB画出分类线,用红色点划线表示(中)(3)画出在投影轴线上的投影点(较难)3.实验结果(1)第一类数据有200组训练数据,第二类数据有100组训练数据。
(2)如图所示,先得出投影线的斜率,后求其投影线的垂直线的斜率,即分类线的斜率,再求分类线的过的中垂点,加上即可得出。
画出红线代码:m = (-40:0.1:80);kw = w(2)/w(1);b = classify(w1, w2, w, 0);disp(b);n = (-1/kw).* m + b;plot(m,n,'r-', 'LineWidth', 3);(3)画出投影上的投影点如图,点用X表示。
代码:u = w/sqrt(sum(w.^2));p1 = w1*u*u';plot(p1(:,1),p1(:,2),'r+')p2 = w2*u*u';plot(p2(:,1),p2(:,2),'b+')实验二、感知器实验1.实验原理(1)训练数据必须是线性可分的(2)最小化能量,惩罚函数法-错分样本的分类函数值之和(小于零)作为惩罚值(3)方法:梯度下降法,对权值向量的修正值-错分样本的特征向量2.实验任务(1)训练样本不线性可分时,分类结果如何?(2)程序33-35行完成什么功能?用MATLAB输出x1、x2、x的值,进行观察(中)(3)修改程序,输出梯度下降法迭代的次数(易);3.实验结果(1)在创建样本时,故意将两组数据靠近,实现训练样本非线性。

一、实验原理实验数据:IRIS 数据。
分为三种类型,每种类型中包括50个思维的向量。
实验模型:假设IRIS 数据是正态分布的。
实验准备:在每种类型中,选择部分向量作为训练样本,估计未知的均值和方差的参数。
实验方法:最小错误判别准则;最小风险判别准则。
实验原理:1.贝叶斯公式已知共有M 类别M i i ,2,1,=ω,统计分布为正态分布,已知先验概率)(i P ω及类条件概率密度函数)|(i X P ω,对于待测样品,贝叶斯公式可以计算出该样品分属各类别的概率,叫做后验概率;看X 属于哪个类的可能性最大,就把X 归于可能性最大的那个类,后验概率即为识别对象归属的依据。
贝叶斯公式为M i P X P P X P X P Mj jji i i ,2,1,)()|()()|()|(1==∑=ωωωωω该公式体现了先验概率、类条件概率、后验概率三者的关系。
其中,类条件概率密度函数)|(i X P ω为正态密度函数,用大量样本对其中未知参数进行估计,多维正态密度函数为)]()(21exp[)2(1)(12/12/μμπ---=-X S X SX P T n 式中,),,(21n x x x X =为n 维向量; ),,(21n μμμμ =为n 维均值向量; ]))([(TX X E S μμ--=为n 维协方差矩阵; 1-S是S 的逆矩阵;S 是S 的行列式。
大多数情况下,类条件密度可以采用多维变量的正态密度函数来模拟。
)]}()(21exp[)2(1ln{)|()(1)(2/12/i i X X S X X S X P i T in i ωωπω---=- i i T S n X X S X X i i ln 212ln 2)()(21)(1)(-----=-πωω )(i X ω为i ω类的均值向量。
2.最小错误判别准则① 两类问题有两种形式,似然比形式:⎩⎨⎧∈⇒⎩⎨⎧<>=211221)()()|()|()(ωωωωωωX P P X P X P X l 其中,)(X l 为似然比,)()(12ωωP P 为似然比阈值。

《模式识别》大作业人脸识别方法二---- 基于PCA 和FLD 的人脸识别的几何分类器(修改稿)一、 理论知识1、fisher 概念引出在应用统计方法解决模式识别问题时,为了解决“维数灾难”的问题,压缩特征空间的维数非常必要。
fisher 方法实际上涉及到维数压缩的问题。
fisher 分类器是一种几何分类器, 包括线性分类器和非线性分类器。
线性分类器有:感知器算法、增量校正算法、LMSE 分类算法、Fisher 分类。
若把多维特征空间的点投影到一条直线上,就能把特征空间压缩成一维。
那么关键就是找到这条直线的方向,找得好,分得好,找不好,就混在一起。
因此fisher 方法目标就是找到这个最好的直线方向以及如何实现向最好方向投影的变换。
这个投影变换恰是我们所寻求的解向量*W ,这是fisher 算法的基本问题。
样品训练集以及待测样品的特征数目为n 。
为了找到最佳投影方向,需要计算出各类均值、样品类内离散度矩阵i S 和总类间离散度矩阵w S 、样品类间离散度矩阵b S ,根据Fisher 准则,找到最佳投影准则,将训练集内所有样品进行投影,投影到一维Y 空间,由于Y 空间是一维的,则需要求出Y 空间的划分边界点,找到边界点后,就可以对待测样品进行进行一维Y 空间的投影,判断它的投影点与分界点的关系,将其归类。
Fisher 法的核心为二字:投影。
二、 实现方法1、 一维实现方法(1) 计算给类样品均值向量i m ,i m 是各个类的均值,i N 是i ω类的样品个数。
11,2,...,ii X im X i nN ω∈==∑(2) 计算样品类内离散度矩阵iS 和总类间离散度矩阵wS1()()1,2,...,i Ti i i X w ii S X m X m i nS Sω∈==--==∑∑(3) 计算样品类间离散度矩阵b S1212()()Tb S m m m m =--(4) 求向量*W我们希望投影后,在一维Y 空间各类样品尽可能地分开,也就是说我们希望两类样品均值之差(12m m -)越大越好,同时希望各类样品内部尽量密集,即希望类内离散度越小越好,因此,我们可以定义Fisher 准则函数:()Tb F Tw W S W J W W S W=使得()F J W 取得最大值的*W 为 *112()w WS m m -=-(5) 将训练集内所有样品进行投影*()Ty W X =(6) 计算在投影空间上的分割阈值0y在一维Y 空间,各类样品均值i m为 11,2,...,ii y imy i n N ω∈==∑样品类内离散度矩阵2i s和总类间离散度矩阵w s 22()ii iy sy mω∈=-∑21w ii ss==∑【注】【阈值0y 的选取可以由不同的方案: 较常见的一种是1122012N m N m y N N +=+另一种是121201ln(()/())22m m P P y N N ωω+=++- 】(7) 对于给定的X ,计算出它在*W 上的投影y (8) 根据决策规则分类0102y y X y y X ωω>⇒∈⎧⎨<⇒∈⎩2、程序中算法的应用Fisher 线性判别方法(FLD )是在Fisher 鉴别准则函数取极值的情况下,求得一个最佳判别方向,然后从高位特征向量投影到该最佳鉴别方向,构成一个一维的判别特征空间将Fisher 线性判别推广到C-1个判决函数下,即从N 维空间向C-1维空间作相应的投影。

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。
iris数据集的贝叶斯分类IRIS 数据集的Bayes 分类实验⼀、实验原理 1) 概述模式识别中的分类问题是根据对象特征的观察值将对象分到某个类别中去。
统计决策理论是处理模式分类问题的基本理论之⼀,它对模式分析和分类器的设计有着实际的指导意义。
贝叶斯(Bayes )决策理论⽅法是统计模式识别的⼀个基本⽅法,⽤这个⽅法进⾏分类时需要具备以下条件:各类别总体的分布情况是已知的。
要决策分类的类别数是⼀定的。
其基本思想是:以Bayes 公式为基础,利⽤测量到的对象特征配合必要的先验信息,求出各种可能决策情况(分类情况)的后验概率,选取后验概率最⼤的,或者决策风险最⼩的决策⽅式(分类⽅式)作为决策(分类)的结果。
也就是说选取最有可能使得对象具有现在所测得特性的那种假设,作为判别的结果。
常⽤的Bayes 判别决策准则有最⼤后验概率准则(MAP ),极⼤似然⽐准则(ML ),最⼩风险Bayes 准则,Neyman-Pearson 准则(N-P )等。
2) 分类器的设计对于⼀个⼀般的c 类分类问题,其分类空间:{}c w w w ,,,21 =Ω表特性的向量为:()T d x x x x ,,,21 =其判别函数有以下⼏种等价形式:a) ()()i j i w w i j c j w w x w P x w P ∈→≠=∈→>,且,,,2,11, b) ()()()()i j j i w w i j c j w P w x p w P w x p ∈→≠=>,且,,,2,1ic) ()()()()()i i j ji w w i j c j w P w P w x p w x p x l ∈→≠=>=,且,,,2,1d)()()()()ij j i i w w i j c j w P w x np w P w x p ∈→≠=+>+,且,,,2,1ln ln ln3) IRIS 数据分类实验的设计IRIS 数据集:⼀共具有三组数据,每⼀组都是⼀个单独的类别,每组有50个数据,每个数据都是⼀个四维向量。
模式识别课程实验报告学院专业班级姓名学号指导教师提交日期1 Data PreprocessingThe provide dataset includes a training set with 3605 positive samples and 10055 negative samples, and a test set with 2043 positive samples and 4832 negative samples. A 2330-dimensional Haar-like feature was extracted for each sample. For high dimensional data, we keep the computation manageable by sampling , feature selection, and dimension reduction.1.1 SamplingIn order to make the samples evenly distributed, we calculate the ratio of negative samples and positive samples int test set. And then randomly select the same ratio of negative samples in training set. After that We use different ratios of negative and positive samples to train the classifier for better training speed.1.2 Feature SelectionUnivariate feature selection can test each feature, measure the relationship between the feature and the response variable so as to remove unimportant feature variables. In the experiment, we use the method sklearn.feature_selection.SelectKBest to implement feature selection. We use chi2 which is chi-squared stats of non-negative features for classification tasks to rank features, and finally we choose 100 features ranked in the top 100.2 Logistic regressionIn the experiment, we choose the logistic regression model, which is widely used in real-world scenarios. The main consideration in our work is based on the binary classification logic regression model.2.1 IntroductionA logistic regression is a discriminant-based approach that assumes that instances of a class are linearly separable. It can obtain the final prediction model by directly estimating the parameters of the discriminant. The logistic regression model does not model class conditional density, but rather models the class condition ratio.2.2 processThe next step is how to obtain the best evaluation parameters, making the training of the LR model can get the best classification effect. This process can also be seen as a search process, that is, in an LR model of the solution space, how to find a design with our LR model most match the solution. In order to achieve the best available LR model, we need to design a search strategy.The intuitive idea is to evaluate the predictive model by judging the degree of matching between the results of the model and the true value. In the field of machine learning, the use of loss function or cost function to calculate the forecast. For the classification, logistic regression uses the Sigmoid curve to greatly reduce the weight of the points that are far from the classification plane through the nonlinear mapping, which relatively increases the weight of the data points which is most relevant to the classification.2.3 Sigmoid functionWe should find a function which can separate two in the two classes binary classification problem. The ideal function is called step function. In this we use the sigmoid function.()z e z -+=11σWhen we increase the value of x, the sigmoid will approach 1, and when we decrease the value of x, the sigmoid will gradually approaches 0. The sigmoid looks like a step function On a large enough scale.2.4 gradient descenti n i i T i x x y L ∑=+--=∂∂-=1t t1t ))(()(θσαθθθαθθThe parameter α called learning rate, in simple terms is how far each step. this parameter is very critical. parameter σis sigmoid function that we introduce in 2.3.3 Train classifierWe use the gradient descent algorithm to train the classifier. Gradient descent is a method of finding the local optimal solution of a function using the first order gradient information. In optimized gradient rise algorithm, each step along the gradient negative direction. The implementation code is as follows:# calculate the sigmoid functiondef sigmoid(inX):return 1.0 / (1 + exp(-inX))#train a logistic regressiondef trainLogisticRegression(train_x, train_y, opts):numSamples, numFeatures = shape(train_x)alpha = opts['alpha'];maxIter = opts['maxIter']weights = ones((numFeatures, 1))# optimize through gradient descent algorilthmfor k in range(maxIter):if opts['optimizeType'] == 'gradDescent': # gradient descent algorilthm output = sigmoid(train_x * weights)error = train_y - outputweights = weights + alpha * train_x.transpose() * error return weightsIn the above program, we repeat the following steps until the convergence:(1) Calculate the gradient of the entire data set(2) Use alpha x gradient to update the regression coefficientsWhere alpha is the step size, maxIter is the number of iterations.4 evaluate classifier4.1 optimizationTo find out when the classifier performs best, I do many experiments. The three main experiments are listed below.First.I use two matrix types of data to train a logistic regression model using some optional optimize algorithm, then use some optimization operation include alpha and maximum number of iterations. These operations are mainly implemented by this function trainLogisticRegression that requires three parameters train_x, train_y, opts, of which two parameters are the matrix type of training data set, the last parameter is some optimization operations, including the number of steps and the number of iterations. And the correct rate as follows:When we fixed the alpha, change the number of iterations, we can get the results as shown below:Red: alpha = 0.001Yellow: alpha = 0.003Blue: alpha = 0.006Black: alpha = 0.01Green: alpha = 0.03Magenta: alpha = 0.3This line chart shows that if the iterations too small, the classifier will perform bad. As the number of iterations increases, the accuracy will increase. And we can konw iterations of 800 seems to be better. The value of alpha influences the result slightly. If the iterations is larger then 800, the accuracy of the classifier will stabilize and the effect of the step on it can be ignored.Second.When we fixed the iterations, change the alpha, we can get the results as shown below:This line chart shows when the number of iterations is larger 800, the accuracy is relatively stable, with the increase of the alpha, the smaller the change. And when the number of iterations is small, for example, the number of times is 100, the accuracy is rather strange, the accuracy will increase with the increase of alpha. We can know that when the number of iterations is small, even if the alpha is very small, its accuracy is not high. The number of iterations and the alpha is important for the accuracy of the logical regression model training.Third.The result of the above experiment is to load all the data to train the classifier, but there are 3605 pos training data but 10055 neg training data. So I am curious about whether can I use less neg training data to train the classifier for better training speed.I use the test_differentNeg.py to does this experiment:Red: iterations = 100 Yellow: iterations = 300 Blue: iterations = 800 Black: iterations = 1000The line chart shows that the smaller the negative sample, the lower the accuracy. However, as the number of negative samples increases, the accuracy of the classifier.I found that when the number of negative samples is larger 6000, the accuracy was reduced and then began to increase.4.2 cross-validationWe divided the data set into 10 copies on average,9 copies as a training set and 1 copies as a test set.we can get the results as shown below:Red: alpha = 0.001Yellow: alpha = 0.003Blue: alpha = 0.006Black: alpha = 0.01Green: alpha = 0.03Magenta: alpha = 0.3This figure shows that if the iterations too small, the classifier will perform bad. Asthe number of iterations increases, the accuracy will increase. And we can konw iterations of 1000 seems to be better. The value of alpha influences the result slightly.If the iterations is larger then 1000, the accuracy of the classifier will achieve 84% and stable. And the effect of the step on it can be ignored.5 ConclusionIn this experiment, We notice that no matter before or after algorithm optimization,the test accuracy does not achieve our expectation. At first the accuracy of LR can reach 80%. After optimization, the accuracy of LR can reach 88%. I think there are several possible reasons below:(1) The training set is too small for only about 700 samples for active training sets, while the negative training set has only 800 samples;(2) We did not use a more appropriate method to filter the samples;(3) The method of selecting features is not good enough because it is too simple;(4) Dimension reduction does not be implemented, so that The high dimension of features increases the computation complexity and affects the accuracy;(5) The test sets may come from different kinds of video or images which are taken from different areas.(6) The number of iterations is set too small or the alpha is set too small or too large. These questions above will be improved in future work.In this project, we use Logistic regression to solve the binary classification problem. Before the experiment, we studied and prepared the algorithm of the LR model and reviewed other machine learning models studied in the pattern recognition course. In this process, we use python with a powerful machine learning library to implement, continue to solve the various problems, and optimize the algorithm to make the classifier perform better. At the same time, we also collaborate and learn from each other. Although the project takes us a lot of time, We have consolidated the theoretical knowledge and have fun in practice.。
一.实验目的通过对Iris 数据进行测试分析,了解正态分布的监督参数估计方法,并利用最大似然估计对3类数据分别进行参数估计。
在得到估计参数的基础下,了解贝叶斯决策理论,并利用基于最小错误率的贝叶斯决策对3类数据两两进行分类。
二.实验原理Iris data set,也称鸢尾花卉数据集,是一类多重变量分析的数据集。
其数据集包含了150个样本,都属于鸢尾属下的三个亚属,分别是山鸢尾 (Iris setosa ),变色鸢尾(Iris versicolor )和维吉尼亚鸢尾(Iris virginica)。
四个特征被用作样本的定量分析,分别是花萼和花瓣的长度和宽度。
实验中所用的数据集已经分为三类,第一组为山鸢尾数据,第二组为变色鸢尾数据,第三组为维吉尼亚鸢尾数据. 1.参数估计不同亚属的鸢尾花数据的4个特征组成的4维特征向量1234(,,,)T x x x x x =服从于不同的4维正态分布。
以第一组为例,该类下的数据的特征向量1234(,,,)T x x x x x =服从于4维均值列向量1μ,44⨯维协方差矩阵1∑的4元正态分布.其概率密度函数为如下:1111122111()exp(()())2(2)T d p x x x μμπ-=--∑-∑参数估计既是对获得的该类下的山鸢尾数据样本,通过最大似然估计获得均值向量1μ,以及协方差矩阵1∑。
对于多元正态分布,其最大似然估计公式如下:111N k k x N μ∧==∑ 11111()()NT k k k x x N μμ∧∧∧=∑=--∑其中N 为样本个数,本实验中样本个数选为15,由此公式,完成参数估计。
得到山鸢尾类别的条件概率密度 11111122111()exp(()())2(2)T d p x x x ωμμπ-=--∑-∑同理可得变色鸢尾类别的条件概率密度2()p x ω,以及维吉尼亚鸢尾类别的条件概率密度3()p x ω2.基于最小错误率的贝叶斯决策的两两分类在以分为3类的数据中各取15个样本,进行参数估计,分别得到3类的类条件概率密度。
模式识别Iris数据分类一、实验简述Iris以鸢尾花的特征作为数据来源,数据集包含150个样本,分为3类,3类分别为setosa,versicolor,virginica,每类50个样本,每个样本包含4个属性,这些属性变量测量植物的花朵,像萼片和花瓣长度等.本实验通过贝叶斯判别原理对三类样本进行两两分类.假设样本的分布服从正态分布。
二、实验原理1、贝叶斯判别原理首先讨论两类情况.用ω1,ω2表示样本所属类别,假设先验概率P(ω1),P(ω2)已知。
这个假设是合理的,因为如果先验概率未知,可以从训练特征向量中估算出来.如果N是训练样本的总数,其中有N1,N2个样本分别属于ω1,ω2,则相应的先验概率为P(ω1)=N1/N, P(ω2)=N2/N。
另外,假设类条件概率密度函数P(x|ωi),i=1,2,…,n,是已知的参数,用来描述每一类特征向量的分布情况。
如果类条件概率密度函数是未知的,则可以从训练数据集中估算出来。
概率密度函数P(x|ωi)也指相对也x的ωi的似然函数.特征向量假定为k维空间中的任何值,密度函数P(x|ωi)就变成的概率,可以表示为P(x|ω。
i)P(ωi |x) = P(x |ωi )P (ωi )/P(x )贝叶斯的分类规则最大后验概率准则可以描述为:如果P (ω1|x)/P(ω2|x) > P(ω2) / P(ω1),则x 属于ω1类, 如果P (ω2|x )/P(ω1|x) 〉 P (ω1) / P(ω2),则x 属于ω2类。
2、多元正态分布多变量正态分布也称为多变量高斯分布.它是单维正态分布向多维的推广。
用特征向量X=[x 1, x 2,…, x n ]T 来表示多个变量.N 维特征向量的正态分布用下式表示:P(x ) =1(2π)N/2|Σ|1/2exp (−12(x −u)T Σ−1(x −u))其中Σ表示协方差矩阵,|Σ|表示协方差矩阵的行列式,u 为多元正态分布的均值。