对应分析数学模型解析
- 格式:doc
- 大小:96.00 KB
- 文档页数:4



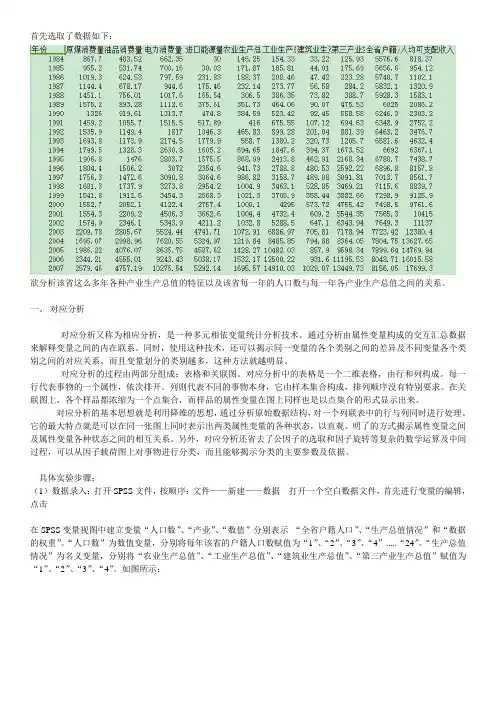
首先选取了数据如下:欲分析该省这么多年各种产业生产总值的特征以及该省每一年的人口数与每一年各产业生产总值之间的关系。
一、对应分析对应分析又称为相应分析,是一种多元相依变量统计分析技术。
通过分析由属性变量构成的交互汇总数据来解释变量之间的内在联系。
同时,使用这种技术,还可以揭示同一变量的各个类别之间的差异及不同变量各个类别之间的对应关系。
而且变量划分的类别越多,这种方法就越明显。
对应分析的过程由两部分组成:表格和关联图。
对应分析中的表格是一个二维表格,由行和列构成。
每一行代表事物的一个属性,依次排开。
列则代表不同的事物本身,它由样本集合构成,排列顺序没有特别要求。
在关联图上,各个样品都浓缩为一个点集合,而样品的属性变量在图上同样也是以点集合的形式显示出来。
对应分析的基本思想就是利用降维的思想,通过分析原始数据结构,对一个列联表中的行与列同时进行处理。
它的最大特点就是可以在同一张图上同时表示出两类属性变量的各种状态,以直观、明了的方式揭示属性变量之间及属性变量各种状态之间的相互关系。
另外,对应分析还省去了公因子的选取和因子旋转等复杂的数学运算及中间过程,可以从因子载荷图上对事物进行分类,而且能够揭示分类的主要参数及依据。
具体实验步骤:(1)数据录入:打开SPSS文件,按顺序:文件——新建——数据打开一个空白数据文件,首先进行变量的编辑,点击在SPSS变量视图中建立变量“人口数”、“产业”、“数值”分别表示“全省户籍人口”、“生产总值情况”和“数据的权重”。
“人口数”为数值变量,分别将每年该省的户籍人口数赋值为“1”、“2”、“3”、“4”.....“24”。
“生产总值情况”为名义变量,分别将“农业生产总值”、“工业生产总值”、“建筑业生产总值”、“第三产业生产总值”赋值为“1”、“2”、“3”、“4”。
如图所示:在SPSS活动数据文件的数据视图中,把相关数据输入到各个变量中。
(2)打开数据文件,进入SPSS Statistics 数据编辑器窗口,在菜单栏中选择“数据——加权个案”命令,将变量“数值”选入加权个案,单击“确定”按钮。


对应分析数学模型解析1.对应分析模型的提出在因子分析时常常会出现以下三个问题:第一,因子分析分为R型和Q型,寻找变量的公因子就采用R型,寻找样品的公因子就采用Q型;R型是从变量的相关系数矩阵出发,Q型是从样品的相似矩阵出发。
在因子分析中把R型和Q型互相割裂单独进行,有些问题只做R型分析,有些只做Q型分析,即使有些问题同时做了这两种分析,在解释时也无法将它们有机地联系起来。
然而变量和样品是分不开的,这也就说明R型分析和Q 型分析是不可分割的。
第二,在实际生活中,我们往往取得样本数目要远远大于变量的数目,这就给Q型因子分析带来了计算上的困难。
比如说,有150个样品,每个样品分析10个变量,如果做R型因子分析时只需计算1010⨯阶的变量向关系数矩阵的特征值和特征向量,而Q型因子分析则要计算150150⨯阶的样品相似矩阵的特征值和特征向量,这个计算量相当可观。
第三,在因子分析中我们为了能将量纲不同的变量进行比较,往往要对变量进行标准化处理,然而这种标准化只能对变量进行,对样品则无从谈标准化,所以标准化对变量和样品是非对等的,这也就给R型和Q型因子分析之间的联系带来障碍。
针对以上问题,我们综合了Q型和R型因子分析的优点,并将他们统一起来使得由R型的分析结果很容易得到Q型的分析结果,这就克服了Q型分析计算量大的问题,更重要的是可以把变量和样品的载荷反映在相同的公因轴上,这样把变量和样品连接起来便于解释和推断。
2. 基本思想:是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
首先编制两变量的交叉列联表,将交叉列联表中的每个数据单元看成两变量在相应类别上的对应点;然后,对应分析将变量及变量之间的联系同时反映在一张二维或三维的散点图;最后,通过观察对应分布图就能直接地把握变量之间的类别联系;3. 它最大特点:是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。

对应分析方法与对应图解读方法——七种分析角度对应分析是一种多元统计分析技术,主要分析定性数据Category Data方法,也是强有力的数据图示化技术,当然也是强有力的市场研究分析技术。
这里主要介绍大家了解对应分析的基本方法,如何帮助探索数据,分析列联表和卡方的独立性检验,如何解释对应图,当然大家也可以看到如何用SPSS操作对应分析和对数据格式的要求!对应分析是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
适用于两个或多个定类变量。
主要应用领域:•概念发展(Concept Development)•新产品开发 (New Product Development)•市场细分 (Market Segmentation)•竞争分析 (Competitive Analysis)•广告研究 (Advertisement Research)主要回答以下问题:•谁是我的用户?•还有谁是我的用户?•谁是我竞争对手的用户?•相对于我的竞争对手的产品,我的产品的定位如何?•与竞争对手有何差异?•我还应该开发哪些新产品?•对于我的新产品,我应该将目标指向哪些消费者?数据的格式要求•对应分析数据的典型格式是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
•两个变量间——简单对应分析。
•多个变量间——多元对应分析。
案例分析:自杀数据分析上面的交互分析表,主要收集了48961人的自杀方式以及自杀者的性别和年龄数据!POISON(毒药)GAS(煤气)HANG(上吊)DROWN(溺水)GUN(开枪)JUMP(跳楼)(我们就不翻译成中文了,读者可以把六个方式想象成品牌或别的什么)当然,我们拿到的最初原始数据可能是SPSS数据格式记录表,其中,性别取值1-male 2-female,年龄取值1-5,分别表示不同年龄段。




因子分析及对应分析因子分析(Factor Analysis)是一种常用的多变量分析方法,用于确定一组观测变量之间的共同因子。
通过因子分析,我们可以找到描述数据变异的较少的变量,从而简化分析和解释数据。
对应分析(Correspondence Analysis)则是一种用于分析分类数据的多元统计方法,能够捕捉各个分类变量之间的关联关系。
因子分析可以用于降维分析,即从原有的一组变量中提取出少数几个“主要成分”来代表原有的变量。
在因子分析中,我们需要先建立起一个数学模型,假设原始的变量与一组不可观测的因子之间存在一种线性关系。
这些因子是一些无法直接测量的潜在变量,但是它们可以通过观测到的一组变量来间接地描述。
通过因子分析,我们可以求得这些潜在因子的权重系数,以及每个观测变量与这些因子之间的相关系数。
然后,我们可以根据这些相关系数来解释原始变量与潜在因子之间的关联关系。
对应分析作为一种非参数的方法,对变数之间的关联关系进行了很好的可视化,并提供了一种直观的方法来分析分类变量之间的关系。
在对应分析中,我们将分类变量转换为数值变量,并绘制一个二维平面,使得各个分类变量之间的距离反映它们之间的相关程度。
通过对应分析,我们可以发现分类变量之间的关联关系,甚至可以发现隐藏在数据背后的一些结构。
对应分析和因子分析的应用领域非常广泛。
在社会科学研究中,因子分析经常用于测量社会心理和个人意识等难以直接观察的潜在因子。
例如,在教育研究中,我们可以通过因子分析来寻找能够解释学生学习成绩差异的潜在因素,以此来改进教育方法和策略。
在市场研究中,因子分析可以用于挖掘消费者之间的共同偏好,从而更好地进行市场定位和产品设计。
对应分析在数据可视化和数据挖掘领域也有广泛的应用。
在信息检索中,对应分析可以用于分析两个文本集合之间的关联关系,从而提高文档的效果。
在社交网络分析中,对应分析可以用于研究用户之间的社交关系和行为模式,通过对用户数据的可视化,可以更好地理解和预测用户的行为。
数学建模模型常用的四大模型及对应算法原理总结四大模型对应算法原理及案例使用教程:一、优化模型线性规划线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,在线性回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
案例实操非线性规划如果目标函数或者约束条件中至少有一个是非线性函数时的最优化问题叫非线性规划问题,是求解目标函数或约束条件中有一个或几个非线性函数的最优化问题的方法。
建立非线性规划模型首先要选定适当的目标变量和决策变量,并建立起目标变量与决策变量之间的函数关系,即目标函数。
然后将各种限制条件加以抽象,得出决策变量应满足的一些等式或不等式,即约束条件。
整数规划整数规划分为两类:一类为纯整数规划,记为PIP,它要求问题中的全部变量都取整数;另一类是混合整数规划,记之为MIP,它的某些变量只能取整数,而其他变量则为连续变量。
整数规划的特殊情况是0-1规划,其变量只取0或者1。
多目标规划求解多目标规划的方法大体上有以下几种:一种是化多为少的方法,即把多目标化为比较容易求解的单目标,如主要目标法、线性加权法、理想点法等;另一种叫分层序列法,即把目标按其重要性给出一个序列,每次都在前一目标最优解集内求下一个目标最优解,直到求出共同的最优解。
目标规划目标规划是一种用来进行含有单目标和多目标的决策分析的数学规划方法,是线性规划的特殊类型。
目标规划的一般模型如下:设xj是目标规划的决策变量,共有m个约束条件是刚性约束,可能是等式约束,也可能是不等式约束。
设有l个柔性目标约束条件,其目标规划约束的偏差为d+, d-。
设有q个优先级别,分别为P1, P2, …, Pq。
在同一个优先级Pk中,有不同的权重,分别记为[插图], [插图](j=1,2, …, l)。
将指标和变量放到一起进行分类、作图,便于做实际意义的解释,这就是对应分析
对应分析可以寻找出R型与Q型分析间的内在联系,由R型分析的结果可以方便地得到Q型分析的结果,克服了做Q型分析样品容量n很大时计算上的困难。
同时,对应分析把R型和Q型因子分析统一起来,把指标和样品同时反映到相同的坐标轴(因子轴)的一张图上,借以解释指标和样品间的如下对应关系:
1、在图形上邻近的指标点表示指标间的密切关系。
2、图形上邻近的样品点群具有相似性质,可以解释为同一过程所产生的结果,
或者说这些邻近的点群属于同一类型。
3、在某指标上的计量较高的样品,图示在代表该指标的点旁。
或者说,属于同
一类型的样品点群,可由与样品点群靠近的指标点所表征。
这有助于解释样品类型,并通过样品在空间的分布了解过程的空间关系
本数学模型方法较为复杂,一般可用在模型扩展。
对应分析方法与对应图解读方法——七种分析角度对应分析是一种多元统计分析技术,主要分析定性数据Category Data方法,也是强有力的数据图示化技术,当然也是强有力的市场研究分析技术。
这里主要介绍大家了解对应分析的基本方法,如何帮助探索数据,分析列联表和卡方的独立性检验,如何解释对应图,当然大家也可以看到如何用SPSS操作对应分析和对数据格式的要求!对应分析是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
适用于两个或多个定类变量。
主要应用领域:概念发展(Concept Development)新产品开发(New Product Development)市场细分(Market Segmentation)竞争分析(Competitive Analysis)广告研究(Advertisement Research)主要回答以下问题:谁是我的用户还有谁是我的用户谁是我竞争对手的用户相对于我的竞争对手的产品,我的产品的定位如何与竞争对手有何差异我还应该开发哪些新产品对于我的新产品,我应该将目标指向哪些消费者数据的格式要求对应分析数据的典型格式是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析。
多个变量间——多元对应分析。
案例分析:自杀数据分析上面的交互分析表,主要收集了48961人的自杀方式以及自杀者的性别和年龄数据!POISON(毒药)GAS(煤气)HANG(上吊)DROWN(溺水)GUN (开枪)JUMP(跳楼)(我们就不翻译成中文了,读者可以把六个方式想象成品牌或别的什么)当然,我们拿到的最初原始数据可能是SPSS数据格式记录表,其中,性别取值1-male 2-female,年龄取值1-5,分别表示不同年龄段。
对应分析数学模型解析
1.对应分析模型的提出
在因子分析时常常会出现以下三个问题:
第一,因子分析分为R型和Q型,寻找变量的公因子就采用R型,寻找样品的公因子就采用Q型;R型是从变量的相关系数矩阵出发,Q型是从样品的相似矩阵出发。
在因子分析中把R型和Q型互相割裂单独进行,有些问题只做R型分析,有些只做Q型分析,即使有些问题同时做了这两种分析,在解释时也无法将它们有机地联系起来。
然而变量和样品是分不开的,这也就说明R型分析和Q 型分析是不可分割的。
第二,在实际生活中,我们往往取得样本数目要远远大于变量的数目,这就给Q型因子分析带来了计算上的困难。
比如说,有150个样品,每个样品分析10个变量,如果做R型因子分析时只需计算10
10⨯阶的变量向关系数矩阵的特征值和特征向量,而Q型因子分析则要计算150
150⨯阶的样品相似矩阵的特征值和特征向量,这个计算量相当可观。
第三,在因子分析中我们为了能将量纲不同的变量进行比较,往往要对变量进行标准化处理,然而这种标准化只能对变量进行,对样品则无从谈标准化,所以标准化对变量和样品是非对等的,这也就给R型和Q型因子分析之间的联系带来障碍。
针对以上问题,我们综合了Q型和R型因子分析的优点,并将他们统一起来使得由R型的分析结果很容易得到Q型的分析结果,这就克服了Q型分析计算量大的问题,更重要的是可以把变量和样品的载荷反映在相同的公因轴上,这样把变量和样品连接起来便于解释和推断。
2. 基本思想:是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
首先编制两变量的交叉列联表,将交叉列联表中的每个数据单元看成两变量在相应类别上的对应点;然后,对应分析将变量及变量之间的联系同时反映在一张二维或三维的散点图;最后,通过观察对应分布图就能直接地把握变量之间的类别联系;
3. 它最大特点:是能把众多的样品和众多的变量同时作到同一张图解
上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。
另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样品进行直观的分类,而且能够指示分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方便的多元统计方法。
4.对应分析的原理和方法
(1)对应分析的数据变换方法
设有n 个样品,每个样品有p 个变量,其资料阵为:
⎪⎪⎪⎪⎪⎭
⎫ ⎝⎛=np n2n12p 22211p 12x x x x x x x x x 11X 现在,我们既要对变量求它的主成分又要对样品求主成分,用p n ⨯阵X 表示数据阵,它的样品离差阵是()ij a A =,其中 p j i x x x x a j kj n k i ki ij ,1,))((1=--=
∑= 或者 '-='=n n n n n I I n
I D X D X A 1其中 而将样品看成是变量时,它的离差阵为 p p p p p l I p
I D X XD A 1,*-='= 因此,一般A 和A *的非零特征根不一样。
由于Z Z Z Z ''和有相同的非零特征根,现在我们将数据阵A 做一变换,成为Z ,使得的作用和能起到和A Z Z *A Z Z ''。
分别用分..
.,.x j x i x 和别表示X 的行和、列和与总和,那么
T
x x x x x x n i p
j ij p i ij
j p
j ij
i ====∑∑∑∑====11..1
.1
.
..../),(/x x p p x X P ij ij ij ===即令 那么就有,1,1011=<<∑∑==n i p
j ij ij p p 且
因而ij p 可解释为“概率”。
类似的,用j i p p ..,表示P 阵的行和列和,那么就可以得出一个列联表,通过分析就有:
⎪⎪⎭⎫ ⎝⎛=⎪⎪⎭⎫ ⎝⎛..
2.1..2.1,,,,,,i ip i i i i i ip i i i i x x x x x x p p p p p p 称作i 行的形象,其和为1。
类似的,有:
⎪⎪⎭
⎫ ⎝⎛=⎪⎪⎭⎫ ⎝⎛j nj j j j j j nj j j j
j x x x x x x p p p p p p .,,,,,,.2.1..2.1 称作j 列的形象,其和为1。
考虑点集 1(){(/,
,/)|1,,}i i ip i N R p p p p i n ==,行形象点集。
1(){(/,,/)|1,,}j j nj j N C p p p p j p ==,列形象点集。
由于/ij i p p 发生的机会是i p ,故第j 个列变量的期望是(记作j g ) 111/n n n
ij j i ij j i i i i p g p p p p ======∑∑∑。