词法分析程序的设计
- 格式:ppt
- 大小:118.50 KB
- 文档页数:14


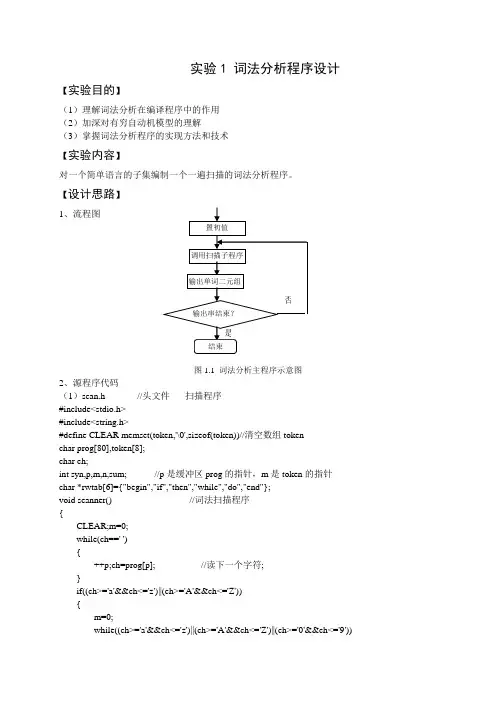
实验1 词法分析程序设计【实验目的】(1)理解词法分析在编译程序中的作用(2)加深对有穷自动机模型的理解(3)掌握词法分析程序的实现方法和技术【实验内容】对一个简单语言的子集编制一个一遍扫描的词法分析程序。
【设计思路】图1.1 词法分析主程序示意图2、源程序代码(1)scan.h //头文件-----扫描程序#include<stdio.h>#include<string.h>#define CLEAR memset(token,'\0',sizeof(token))//清空数组tokenchar prog[80],token[8];char ch;int syn,p,m,n,sum; //p是缓冲区prog的指针,m是token的指针char *rwtab[6]={"begin","if","then","while","do","end"};void scanner() //词法扫描程序{CLEAR;m=0;while(ch==' '){++p;ch=prog[p]; //读下一个字符;}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){m=0;while((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch>='0'&&ch<='9')){token[m++]=ch;++p;ch=prog[p];//读下一个字符;}token[m++]='\0';syn=10;for(n=0;n<6;++n)if(strcmp(token,rwtab[n])==0){syn=n+1;break;}}elseif(ch>='0'&&ch<='9'){sum=0;while(ch>='0'&&ch<='9'){sum=sum*10+ch-'0';//将ch转换为数字++p;ch=prog[p];}syn=11;}elseswitch(ch)//其他字符情况{case'<':m=0;token[m++]=ch;++p;ch=prog[p];if(ch=='>'){syn=21;++m;token[m]=ch;}else if(ch=='='){syn=22;++m;token[m]=ch;}{syn=20;}break;case'>':token[0]=ch;++p;ch=prog[p];if(ch=='='){syn=24;token[0]=ch;}else{syn=23;}break;case':':token[0]=ch;++p;ch=prog[p];if(ch=='='){syn=18;++m;token[m]=ch;++p;ch=prog[p];}else{syn=17;}break;case'+':syn=13;token[0]=ch;ch=prog[++p];break;case'-':syn=14;token[0]=ch;ch=prog[++p];break;case'*':syn=15;token[0]=ch;ch=prog[++p];case'/':syn=16;token[0]=ch;ch=prog[++p];break;case'=':syn=25;token[0]=ch;ch=prog[++p];break;case';':syn=26;token[0]=ch;ch=prog[++p];break;case'(':syn=27;token[0]=ch;ch=prog[++p];break;case')':syn=28;token[0]=ch;ch=prog[++p];break;case'#':syn=0; token[0]=ch;ch=prog[++p];break;default:syn=-1;}}(2)word.cpp // 词法分析主程序#include"scan.h"void main(void){p=0;printf("\n please input string:\n");do{ch=getchar();prog[p++]=ch;}while(ch!='#');p=0;ch=prog[0];if(ch>='0'&&ch<='9')printf("error!\n");else{do{scanner();//调用扫描子程序switch(syn){case 11:printf("(%d,%d)\n",11,sum);break;case -1:printf("error!\n");break;default:printf("(%d,'%s')\n",syn,token);}} while(syn!=0);}}【思考题】在编程过程中遇到了哪些问题,你是如何解决的。

词法分析程序的设计与实现方法1:采用C作为实现语言,手工编制一.文法及状态转换图1.语言说明:C语言有以下记号及单词:(1)标识符:以字母开头的、后跟字母或数字组成的符号串。
(2)关键字:标识符集合的子集,该语言定义的关键字有32个,即auto,break,case,char,const,continue,default,do,double,else,enum, extern,float,for,goto,if,int,long,register,return,short,signed,static, sizeof,struct,switch,typedef ,union,unsigned ,void, volatile和while。
(3)无符号数:即常数。
(4)关系运算符:<,<=,==,>,>=,!=。
(5)逻辑运算符:&&、||、!。
(6)赋值号:=。
(7)标点符号:+、++、-、--、*、:、;、(、)、?、/、%、#、&、|、“”、,、.、{}、[]、_、^等(8)注释标记:以“/*”开始,以“*/”结束。
(9)单词符号间的分隔符:空格。
2.记号的正规文法:仅给出各种单词符号的文法产生式(1)标识符的文法id->letter ridrid->ε|letter rid|digit rid(2)无符号整数的文法digits->digit remainderremainder->ε|digit remainder(3)无符号数的文法num->digit num1num1->digit num1|. num2|E num4|εnum2->digit num3num3->digit num3|E num4|εnum4->+digits|-digits|digit num5digits->digit num5num5->digit num5|ε(4)关系运算符的文法relop-> <|<=|==|>|>=|!=(5)赋值号的文法assign_op->=(6)标点符号的文法special_symbol->+|-|*|%|#|^|(|)|{|}|[|]|:|;|”|?|/|,|.& (7)逻辑运算符的文法logic->&&| || | !(8)注释头符号的文法note->/starstar->*3.状态转换图其中,状态0是初始状态,若此时读入的符号是字母,则转换到状态1,进入标识符识别过程;如果读入的是数字,则转换到状态2,进入无符号数识别过程;……;若读入的符号是/,转换到状态11,再读入下一个符号,如果读入的符号是*,则转换到状态12,进入注释处理状态;如果在状态0读入的符号不是语言所定义的单词符号的开始字符,则转换到状态13,进入错误处理状态。

实验三词法分析与语法分析程序设计一.实验目的基本掌握计算机语言的词法分析程序和语法分析程序的设计方法。
二.实验要求、内容及步骤实验要求:1.根据以下的正规式,画出状态图;标识符:<字母>(<字母>|<数字字符>)*关键字:if then else while do十进制整数:0 | (1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)* 运算符和分隔符:+ - * / > < = ( ) 。
2.根据状态图,设计词法分析函数int scan( ),从键盘读入数据,分析出一个单词。
3.对于只含有+、*运算的算术表达式的如下文法,编写相应的语法分析程序,要求用LL(1)分析表实现,并以id+id*id为例进行测试:E —> TE′E′—> +TE′|εT —> FT′T′—> *FT′|εF —>(E)| id实验步骤:1.根据状态图,设计词法分析算法;2.采用C++语言,实现该算法;3.调试程序:输入一组单词,检查输出结果;4.编制给定文法的非递归的预测分析程序,并加以测试。
三.实验设备计算机、Windows 操作系统、Visual C++ 程序集成环境。
四.实验原理1. 词法分析器读入输入串,将其转换成将被语法分析器分析的词法单元序列。
产生下述小语言的单词序列。
这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表:单词符号种别编码助记符内码值DIMIFDO STOP END标识符常数(整)=+***,()1234567891011121314$DIM$IF$DO$STOP$END$ID$INT$ASSIGN$PLUS$STAR$POWER$COMMA$LPAR$RPAR------内部字符串标准二进形式------对于这个小语言,有几点重要的限制:首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。
所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。
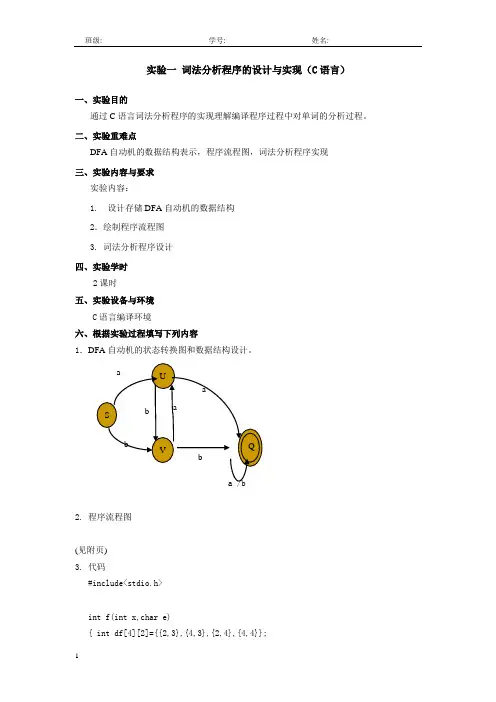
实验一 词法分析程序的设计与实现(C 语言)一、实验目的通过C 语言词法分析程序的实现理解编译程序过程中对单词的分析过程。
二、实验重难点DFA 自动机的数据结构表示,程序流程图,词法分析程序实现三、实验内容与要求实验内容:1. 设计存储DFA 自动机的数据结构2.绘制程序流程图3. 词法分析程序设计四、实验学时2课时五、实验设备与环境C 语言编译环境六、根据实验过程填写下列内容1.DFA 自动机的状态转换图和数据结构设计。
a /b2. 程序流程图(见附页)3. 代码#include<stdio.h>int f(int x,char e){ int df[4][2]={{2,3},{4,3},{2,4},{4,4}};U a a a S b Q bV bint i;if(e=='a')i=df[x][1];if(e=='b')i=df[x][2];return(i);}void main(){ int S=1,U=2,V=3,Q=4;int k=S;char c;printf("请输入字符,按#结束:\n");c=getchar();while(c!='#'){k=f(k,c);c=getchar();}if(k==Q) printf("你输入的字符串能被DFA所识别\n");else printf("你输入的字符串能被DFA所识别\n");}4.测试数据及结果分析(结果见附页)分析:从实验的结果可以看出上面程序代码基本上可以实现所给DFA的要求,但是有关实验的可读性和功能方面还有待进一步改进。
程序流程图教师评语:是否完成实验程序的预备设计? 是: 不是: 程序能否正常运行? 是: 不是: 有无测试数据及结果分析 是: 不是: 是否在本次规定时间完成所有项目? 是: 不是: 实验成绩等级: 教师签名:N0:时间:开始初始化输入句子判断是否退出标志判断是否被接受?接受不接受输出错误位置NY NY结束。

词法分析程序设计词法分析是编译器设计中的一个关键步骤,它负责将源代码文本转换成一系列的词法单元(tokens),这些词法单元是语法分析阶段的输入。
词法分析程序的设计通常包括以下几个主要部分:定义词法规则、构建词法分析器、生成词法单元以及错误处理。
1. 定义词法规则词法规则是词法分析器识别源代码中各种词法单元的基础。
这些规则通常包括关键字、标识符、常量(如数字和字符串)、运算符和分隔符等。
例如,对于C语言,词法规则可能包括识别`int`、`float`等关键字,以及识别变量名、数字和字符串字面量等。
2. 构建词法分析器构建词法分析器的过程通常涉及到选择一个合适的算法或工具。
常见的方法有手工编写词法分析器、使用词法分析生成器(如Lex或Flex)来自动生成词法分析器。
手工编写词法分析器手工编写词法分析器需要程序员根据词法规则,使用编程语言(如C、Java等)实现一个扫描器(scanner)。
扫描器的主要任务是逐字符地读取源代码,并根据词法规则识别出词法单元。
使用词法分析生成器使用词法分析生成器可以大大简化词法分析器的开发过程。
开发者只需定义词法规则,并使用生成器工具来生成扫描器代码。
例如,Flex是一个基于正则表达式的词法分析生成器,它可以从定义的规则中自动生成C或C++代码。
3. 生成词法单元词法单元是词法分析器输出的基本单位。
每个词法单元通常包含两个部分:类型和值。
类型指明词法单元的种类(如关键字、标识符等),而值则是词法单元的具体内容(如标识符的名称、数字的值等)。
在生成词法单元时,词法分析器需要根据识别出的词法规则,将源代码中的字符序列转换成相应的词法单元。
例如,当词法分析器读取到`123`时,它应该识别这是一个整数常量,并生成一个类型为`INTEGER`,值为`123`的词法单元。
4. 错误处理在词法分析过程中,可能会遇到不符合词法规则的字符序列,这时就需要进行错误处理。
错误处理通常包括以下几个方面:- 识别错误:当遇到无法识别的字符或字符序列时,词法分析器应该能够识别出这是一个错误。


实验一词法分析程序设计与实现一、实验目的通过设计调试词法分析程序,实现从源程序中分出各种单词的方法;加深对课堂教学的理解,深刻理解词法分析的整个过程,提高词法分析方法的实践能力。
二、实验要求(1)从源程序文件中读取有效字符和并将其转换成二元组机内表示形式输出。
(2)掌握词法分析的实现方法。
(3)实验要求独立完成,不允许有抄袭现象。
(4)实验完成后,要上交实验报告(包括源程序清单)。
(附:实验报告格式)三、实验内容1、主程序设计考虑:主程序的说明部分为各种表格和变量安排空间(关键字和特殊符号表)。
id 和ci 数组分别存放标识符和常数;还有一些为造表填表设置的变量。
主程序的工作部分建议设计成便于调试的循环结构。
每个循环处理一个单词;接收键盘上送来的一个单词;调用词法分析过程;输出每个单词的内部码。
2)词法分析过程考虑该过程取名为lexical,它根据输入单词的第一个有效字符(有时还需读第二个字符),判断单词类,产生类号。
对于标识符和常数,需分别与标识符表和常数表中已登记的元素相比较,如表中已有该元素,则记录其在表中的位置,如未出现过,将标识符按顺序填入数组id 中,将常数变为存入数组中ci 中,并记录其在表中的位置。
注:所有识别出的单词都用二元组表示。
第一个表示单词的种类。
关键字的t=1;标识符的t=2;常数t=3;运算符t=4;界符t=5。
第二个为该单词在各自表中的指针或内部码值(常数表和标识符表是在编译过程中建立起来的。
其i 值是根据它们在源程序中出现的顺序确定的)。
将词法分析程序设计成独(入口)立一遍扫描源程序的结构。
其主流程图如下:图5-1 词法分析程序流程图例1:狭义的词法分析:分析字符串有多少个单词public class CalWord{ public static void main(String args[]){ String s1="My friend . Welcome to Java!"; //建立文本语句System.out.println("The words of this sentence :");int n=0; //设立单词记数器for (int i=0;i<s1.length();i++) //从语句开始直到它的结束处逐一检查{ char m=s1.charAt(i); //逐一将语句中的字符读入m中if (Character.toLowerCase(m)<97 ||Character.toLowerCase(m)>122)//当m为非字母字符时表示一个单词结束n=n+1;}System.out.print(n);}}例2:《java面向对象程序设计》P190 例9.10import java.util.Scanner;public class Example9_10 {public static void main (String args[ ]) {System.out.println("一行文本:");Scanner reader=new Scanner(System.in);String str= reader.nextLine(); //空格字符、数字和符号(!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~)组成的正则表达式:String regex="[\\s\\d\\p{Punct}]+";String words[]=str.split(regex);for(int i=0;i<words.length;i++){int m=i+1;System.out.println("单词"+m+":"+words[i]);}}}。

实验1-4 《编译原理》S语言词法分析程序设计方案一、实验目的了解词法分析程序的两种设计方法:1.根据状态转换图直接编程的方式;2.利用DFA 编写通用的词法分析程序。
二、实验内容1.根据状态转换图直接编程编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。
在此,词法分析程序作为单独的一遍,如下图所示。
具体任务有:(1)组织源程序的输入(2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件(3)删除注释、空格和无用符号(4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。
将错误信息输出到屏幕上。
(5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。
标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。
常量表结构:常量名,常量值2.编写DFA模拟程序算法如下:DFA(S=S0,MOVE[][],F[],ALPHABET[])/*S为状态,初值为DFA的初态,MOVE[][]为状态转换矩阵,F[] 为终态集,ALPHABET[] 为字母表,其中的字母顺序与MOVE[][] 中列标题的字母顺序一致。
*/{Char Wordbuffer[10]=“”//单词缓冲区置空Nextchar=getchar();//读i=0;while(nextchar!=NULL)//NULL代表此类单词{ if (nextcha r!∈ALPHABET[]){ERROR(“非法字符”),return(“非法字符”);}S=MOVE[S][nextchar] //下一状态if(S=NULL)return(“不接受”);//下一状态为空,不能识别,单词错误wordbuffer[i]=nextchar ;//保存单词符号i++;nextchar=getchar();}Wordbuffer[i]=‘\0’;If(S∈F)return(wordbuffer);//接受Else return(“不接受”);}该算法要求:实现DFA算法,给定一个DFA(初态、状态转换矩阵、终态集、字母表),调用DFA(),识别给定源程序中的单词,查看结果是否正确。