统计模式识别简介
- 格式:ppt
- 大小:386.01 KB
- 文档页数:37

统计模式识别统计分类方法
统计模式识别是一种常见的机器学习算法,用于对未知模式和统
计模式进行学习。
它可以使用模式的历史记录和观察结果来预测未来
模式的行为。
该技术也被称为统计分类,用于解决分类和分组问题,
其目的是根据现有的统计数据来评估一个特定的类别的可能性。
统计模式识别基于概率统计理论,可对数据进行分析并扩展到传
统模式识别范围之外,以解决复杂问题。
它可以用于分类多维数据,
识别新类别或模式,并帮助训练机器学习模型,使用有效的特征提取
和结构学习算法。
它提供一种新的方法,通过有效的表示和分类模型,来表示实体和相关的对象。
与其他分类算法相比,统计模式识别的有点是它'数据挖掘'的概念,在这种类型的模式识别中,模式数据是根据观察数据一直进行改
变的,没有预先定义模式及其功能,它根据具有可利用自学能力的方
法逐渐改善。
统计模式识别非常重要,因为它可以帮助我们找到自动化解决方
案来实现更多基于数据的智能分析和决策,从而增强分析模型的能力,例如,可以使用该技术识别股票市场及其他金融市场的模式变化,以
便于能够更高效地进行投资决定。
它也可以应用于诊断和分析少量样
本事件,进而对学习和决策进行调节和优化。




模式识别综述摘要:介绍了模式识别系统的组成及各组成部分包含的内容。
就统计模式识别、结构模式识别、模糊模式识别、神经网络模式识别等模式识别的基本方法进行简单介绍,并分析了其优缺点。
最后列举了模式识别在各领域的应用,针对其应用前景作了相应分析。
关键字:模式识别系统、统计模式识别、结构模式识别、模糊模式识别、神经网络模式识别背景随着现代科学技术的发展,特别是计算机技术的发展,对事物认识的要求越来越高,根据实际需求,形成了一种模拟人的各种识别能力(主要是视觉和听觉)和认识方法的学科,这个就是模式识别,它是属于一种自动判别和分类的理论。
这一理论孕育于20世纪60年代,随着科学技术的发展,特别是20世纪70年代遥感技术的发展和地球资源卫星的发射,人们通过遥感从卫星取得的巨量信息,需要进行空前规模的处理、识别和应用,在此推动下,模式识别技术便得以迅速发展[1]。
发展到现在,应用领域已经非常广阔,包括文本分类、语音识别、视频识别、信息检索和数据挖掘等。
模式识别技术在生物医学、航空航天、工业生产、交通安全等许多领域发挥着重要的作用[2]。
基本概念什么是模式呢?广义地说,存在于时间和空间中可观察的事物,如果可以区别它们是否相同或是否相似,都可以称之为模式。
但模式所指的不是事物本身,而是我们从事物获取的信息。
因此模式往往表现为具有时间或空间分布的信息[3]。
人们在观察各种事物的时候,一般是从一些具体的个别事物或者很小一部分开始的,然后经过长期的积累,随着对观察到的事物或者现象的数量不断增加,就开始在人的大脑中形成一些概念,而这些概念是反映事物或者现象之间的不同或者相似之处,这些特征或者属性使人们对事物自然而然的进行分类。
从而窥豹一斑,对于一些事物或者现象,不需要了解全过程,只需要根据事物或者现象的一些特征就能对事物进行认识。
人脑的这种思维能力视为“模式”的概念。
模式识别就是识别出特定事物,然后得出这些事物的特征。
识别能力是人类和其他生物的一种基本属性,根据被识别的客体的性质可以将识别活动分为具体的客体与抽象的客体两类。

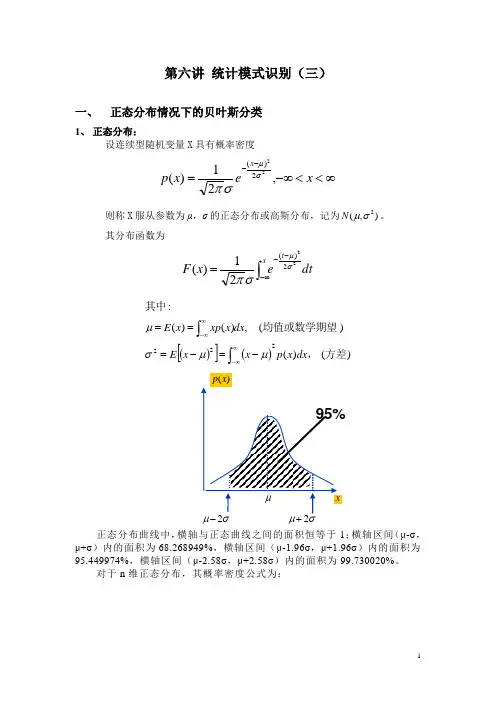
第六讲 统计模式识别(三)一、 正态分布情况下的贝叶斯分类1、 正态分布:设连续型随机变量X 具有概率密度∞<<-∞=--x ex p x ,21)(222)(σμσπ则称X 服从参数为μ,σ的正态分布或高斯分布,记为),(2σμN 。
其分布函数为dt ex F xt ⎰∞---=22)(21)(σμσπ()[]())()()(,)()(:222方差,均值或数学期望其中dx x p x x E dx x xp x E ⎰⎰∞∞-∞∞--=-===μμσμ正态分布曲线中,横轴与正态曲线之间的面积恒等于1;横轴区间(μ-σ,μ+σ)内的面积为68.268949%,横轴区间(μ-1.96σ,μ+1.96σ)内的面积为95.449974%,横轴区间(μ-2.58σ,μ+2.58σ)内的面积为99.730020%。
对于n 维正态分布,其概率密度公式为:()()()()∑∑∑∑∑--∑⨯==⎥⎦⎤⎢⎣⎡---∑=的行列式为的逆阵,为维协方差矩阵,为维均值向量,维特征向量其中121211212),...,,(,,...,,:21exp ||21)(d d d d x x x x p Td Td Tdμμμπμx μx μx均值向量μ的分量μi 为:i i i i i dx x p x x E ⎰∞∞-==)()(μ协方差矩阵为:()()[]()()()()[]()()()()()()()()⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡--------=⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧--⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡--=--=∑d d d d d dd d d d d d Tx x x x x x x x E x x x x E E μμμμμμμμμμμμ,...,......,...,,...,......111111111111μx μx()()[]()()[]()()[]()()[]⎪⎪⎭⎫ ⎝⎛≠=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡--------=是协方差,非对角线是方差对角线j i j i x x E x x E x x E x x E ij ij dd d d d d d d d d d d d 22222212121221111111111,,..............................σσσσσσσσμμμμμμμμ 多维正态分布具有以下性质:μ与∑对分布起决定作用, μ由d 分量组成,∑由d(d+1)/2个元素组成,所以多维正态分布由d+d(d+1)/2个参数组成。

统计模式识别的原理与⽅法1统计模式识别的原理与⽅法简介 1.1 模式识别 什么是模式和模式识别?⼴义地说,存在于时间和空间中可观察的事物,如果可以区别它们是否相同或相似,都可以称之为模式;狭义地说,模式是通过对具体的个别事物进⾏观测所得到的具有时间和空间分布的信息;把模式所属的类别或同⼀类中模式的总体称为模式类(或简称为类)]。
⽽“模式识别”则是在某些⼀定量度或观测基础上把待识模式划分到各⾃的模式类中去。
模式识别的研究主要集中在两⽅⾯,即研究⽣物体(包括⼈)是如何感知对象的,以及在给定的任务下,如何⽤计算机实现模式识别的理论和⽅法。
前者是⽣理学家、⼼理学家、⽣物学家、神经⽣理学家的研究内容,属于认知科学的范畴;后者通过数学家、信息学专家和计算机科学⼯作者近⼏⼗年来的努⼒,已经取得了系统的研究成果。
⼀个计算机模式识别系统基本上是由三个相互关联⽽⼜有明显区别的过程组成的,即数据⽣成、模式分析和模式分类。
数据⽣成是将输⼊模式的原始信息转换为向量,成为计算机易于处理的形式。
模式分析是对数据进⾏加⼯,包括特征选择、特征提取、数据维数压缩和决定可能存在的类别等。
模式分类则是利⽤模式分析所获得的信息,对计算机进⾏训练,从⽽制定判别标准,以期对待识模式进⾏分类。
有两种基本的模式识别⽅法,即统计模式识别⽅法和结构(句法)模式识别⽅法。
统计模式识别是对模式的统计分类⽅法,即结合统计概率论的贝叶斯决策系统进⾏模式识别的技术,⼜称为决策理论识别⽅法。
利⽤模式与⼦模式分层结构的树状信息所完成的模式识别⼯作,就是结构模式识别或句法模式识别。
模式识别已经在天⽓预报、卫星航空图⽚解释、⼯业产品检测、字符识别、语⾳识别、指纹识别、医学图像分析等许多⽅⾯得到了成功的应⽤。
所有这些应⽤都是和问题的性质密不可分的,⾄今还没有发展成统⼀的有效的可应⽤于所有的模式识别的理论。
1.2 统计模式识别 统计模式识别的基本原理是:有相似性的样本在模式空间中互相接近,并形成“集团”,即“物以类聚”。


模式识别基础概念文献综述一.前言模式识别诞生于20世纪20年代。
随着20世纪40年代计算机的出现,20世纪50年代人工智能的兴起,模式识别在20世纪60年代迅速发展成为一门学科。
在20世纪60年代以前,模式识别主要限于统计学领域的理论研究,计算机的出现增加了对模式识别实际应用的需求,也推动了模式识别理论的发展。
经过几十年的研究,取得了丰硕的成果,已经形成了一个比较完善的理论体系,主要包括统计模式识别、结构模式识别、模糊模式识别、神经网络模式识别和多分类器融合等研究内容。
模式识别就是研究用计算机实现人类的模式识别能力的一门学科,目的是利用计算机将对象进行分类。
这些对象与应用领域有关,它们可以是图像、信号,或者任何可测量且需要分类的对象,对象的专业术语就是模式(pattern)。
按照广义的定义,存在于时间和空间中可观察的事物,如果可以区别它们是否相同或相似,都可以成为模式。
二.模式识别基本概念<一>.模式识别系统模式识别的本质是根据模式的特征表达和模式类的划分方法,利用计算机将模式判属特定的类。
因此,模式识别需要解决五个问题:模式的数字化表达、模式特性的选择、特征表达方法的确定、模式类的表达和判决方法的确定。
一般地,模式识别系统由信息获取、预处理、特征提取和选择、分类判决等4部分组成,如图1-1所示。
观察对象→→→→→→→→→类→类别号信息获取预处理特征提取和选择分类判决图1-1模式识别系统的组成框图<二>.线性分类器对一个判别函数来说,应该被确定的是两个内容:其一为方程的形式;其二为方程所带的系数。
对于线性判别函数来说方程的形式是线性的,方程的维数为特征向量的维数,方程组的数量则决定于待判别对象的类数。
对M类问题就应该有M个线性判别函数;对两类问题如果采用“+”“-”判别,则判别函数可以只有一个。
既然方程组的数量、维数和形式已定,则对判别函数的设计就是确定函数的各系数,也就是线性方程的各权值。
数据分析知识:数据分析中的模式识别技术在大数据时代,数据分析的重要性日益凸显。
随着数据规模的快速增长,传统的数据分析方法已经无法满足人们对数据处理与挖掘的需求。
而模式识别技术作为一种重要的数据分析手段,广泛应用于各个领域,能够帮助人们从海量数据中挖掘出有价值的信息,对业务决策和科学研究提供有力支持。
本文将从概念、原理、应用以及发展趋势等方面对数据分析中的模式识别技术进行探讨。
一、概念模式识别是一种从原始数据中寻找出一定规律或特征的技术,用于识别出数据中的某种模式或者规律。
这种技术可以应用到各种各样的数据中,包括图像、音频、文本、时间序列等。
模式识别技术的目标是通过对数据的分析和处理,寻找数据中的规律和特征,从而进行分类、聚类、预测和决策等。
模式识别技术在数据分析中的作用主要体现在以下几个方面:1、特征提取:在实际应用中,原始数据往往非常复杂,而模式识别技术可以通过对数据进行特征提取,将复杂的数据转换成易于理解和处理的特征向量。
2、分类与识别:模式识别技术可以对数据进行分类与识别,例如在图像识别领域,可以通过模式识别技术将图像中的物体进行分类和识别。
3、预测与决策:通过分析数据中的模式和规律,模式识别技术可以进行预测与决策,例如在金融领域可以利用模式识别技术对股票走势进行预测。
二、原理模式识别技术的原理主要基于统计学、机器学习和人工智能等相关理论基础。
在实际应用中,模式识别技术主要通过以下几个步骤实现对数据模式的识别:1、数据采集与预处理:首先需要对原始数据进行采集,并进行预处理,包括去噪、归一化、降维等操作,以便为后续的模式识别做准备。
2、特征提取与选择:在进行模式识别之前,需要对数据进行特征提取,将原始数据转换成特征向量,选择合适的特征有利于提高模式识别的精度和效率。
3、数据分类与建模:在获得了合适的特征向量之后,可以采用分类器或者模型对数据进行分类和建模,例如采用支持向量机、神经网络、决策树等模型进行数据模式的分类。
统计图模式识别在图像分析中的应用在当今数字时代,图像处理和分析已经成为了一个重要的研究领域。
图像分析通过对从数字图像中提取的特征进行处理,从而实现对图像中内容的理解和识别。
统计图模式识别作为图像分析中的一种常见方法,起到了至关重要的作用。
本文将探讨统计图模式识别在图像分析中的应用,以及它的优势和挑战。
统计图模式识别是一种基于统计学原理的图像处理方法,它通过对图像中的数据进行统计分析和建模,从而实现对图像的自动识别和分类。
统计图模式识别的核心思想是根据数据分布的规律性和差异性来进行图像分类和识别。
首先,统计图模式识别在医学图像分析领域具有重要应用。
医学图像通常包含大量的信息,如CT扫描图像、MRI图像等。
通过统计图模式识别的方法,可以对这些医学图像中的异常病灶进行检测和分析。
例如,在乳腺癌检测中,可以通过对乳腺组织的统计特征进行建模,从而实现对乳腺癌的自动识别。
其次,统计图模式识别在计算机视觉领域也有广泛的应用。
计算机视觉通过对图像中的物体进行检测、跟踪和识别,实现对真实世界的理解和模拟。
统计图模式识别可以用于人脸识别、目标检测和场景理解等方面。
例如,利用统计图模式识别方法,可以通过对面部图像的特征进行提取和建模,实现对人脸的识别和验证。
此外,统计图模式识别在遥感图像分析中也发挥着重要的作用。
遥感图像通常包含大量的地理信息,如地形、植被和水体等。
通过统计建模的方法,可以对遥感图像进行分类和分析。
例如,在农作物监测中,可以利用农田遥感图像的统计特征,实现对不同农作物类型的自动识别和监测。
然而,统计图模式识别在图像处理中也存在一些挑战和限制。
首先,统计建模需要大量的训练数据,而且这些训练数据需要代表性和多样性。
当训练数据不足或者不具有代表性时,统计图模式识别的效果会受到限制。
其次,统计图模式识别在处理复杂图像时存在困难。
复杂图像中的噪声、变形和背景干扰等因素会影响特征提取和模式建模的准确性。
总结起来,统计图模式识别在图像分析中扮演着重要的角色,尤其在医学图像分析、计算机视觉和遥感图像分析等领域。
几种统计模式识别方案的比较摘要:模式识别是对表征事物或现象的各种形式的(数值的,文字的和逻辑关系的)信息进行处理和分析,以达到对事物或现象进行描述、辨认、分类和解释的目的,是信息科学和人工智能的重要组成部分。
而统计决策理论是处理模式分类问题的基本理论之一,它对模式分析和分类器的设计有着实际的指导意义。
本文归纳总结了统计模式识别的不同方案的详细性能,比较了它们的原理、算法、属性、应用场合、错误率等。
关键词:统计模式识别贝叶斯决策方法几何分类法监督参数统计法非监督参数统计法聚类分析法Comparison of Several Kinds of Statistical Pattern Recognit ion SchemesAbstract: Pattern recognition deals with and analyses the i nformation which signify all kinds of things and phenomena (number values, Characters and logic relation), in order to describe, recognize, classify and interpret them. It is on e of the important parts of information science and artific ial intelligence. While statistical pattern recognition is one of the basics theory of classifying and is real directi ve significance in analyzing and classifying of pattern. Wesum up the detailed performance of summarizing different s chemes which counts the pattern recognition in this text, C ompare their principle, algorithm, attribute, using occasio n, etc.1引言模式识别诞生于20世纪20年代,随着40年代计算机的出现,50年代人工智能的兴起,模式识别在60年代初迅速发展成为一门学科。