双字、字、字节和位的关系总结
- 格式:docx
- 大小:852.18 KB
- 文档页数:3

位字节字双字寻址概念
现在把存储区比作一个大房间,存储分区比作柜子,柜子编号有V柜,I柜,Q 柜,M柜;每个柜子都有256个(0-255)抽屉,每个抽屉相当于一个字节B,每个抽屉有8个格子(0-7),相当于位,每个抽屉的状态有两种状态,有(1)和无(0)。
寻址:I0.0表示位寻址;IB0 表示字节寻址;IW0表示字寻址;ID0表示双字寻址。
I0.0代表一个位,最小的单元格;IB0代表一个字节,由8个字节组成;IW0代表字寻址,由2个字节组成,16个为组成;ID0代表双字寻址,由2个字组成,4个字节组成,32个位组成。
IB0=2 I柜子0号抽屉的状态是:00000010 相当于I0.1=1状态,其他都为0.
IB0=3 I柜子0号抽屉的状态是:00000011 相当于I0.0=1 I0.1=1状态,其他都为0.
以字节为例:
假如VB100等于2,那VW100等于512,VD100等于33554432(都是十进制表示)
因为在PLC内部,字和双字分别是以2个和4个字节组成,而且地址低的字节为字或双字的高位字节。
以二进制的形式表示
VB100=00000010=2
VB100=1111111=255
VW100=00000010(VB101) 00000000(VB100)=512
VD100=00000010(VB103)00000000(VB102)00000000(VB101)00000000(VB100)=33554432。
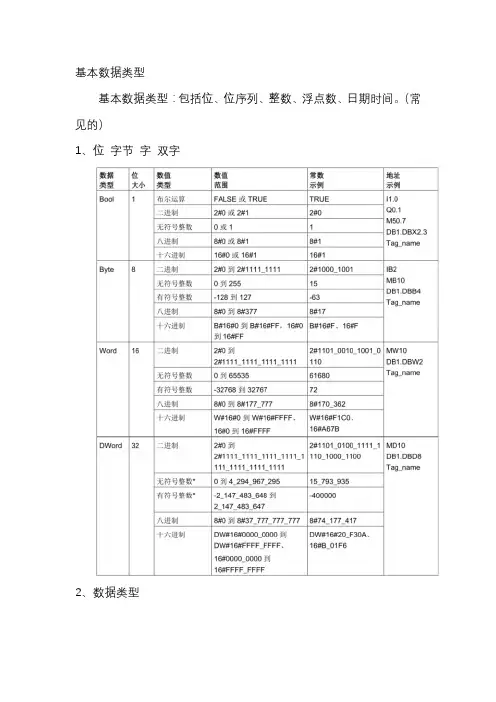
基本数据类型
基本数据类型:包括位、位序列、整数、浮点数、日期时间。
(常见的)
1、位字节字双字
2、数据类型
3 浮点数
实(或浮点)数以32 位单精度数(Real) 或64 位双精度数(LReal) 表示。
比如模拟量模块采集的温度压力等
4 时间日期数据类型
TIME 数据作为有符号双整数存储,基本单位为毫秒。
存储的数值是多少,就代表有多少ms。
编辑时可以选择性使用日期(d)、小时(h)、分钟(m)、秒(s) 和毫秒(ms) 作为单位
DATE 数据作为无符号整数值存储,被解释为添加到基础日期1990 年1 月1 日的天数,用以获取指定日期。
编辑器格式必须指定年、月和日。
TOD (TIME_OF_DAY) 数据作为无符号双整数值存储,被解释为自指定日期的凌晨算起的毫秒数(凌晨= 0 ms)。
必须指定小时(24 小时/天)、分钟和秒。
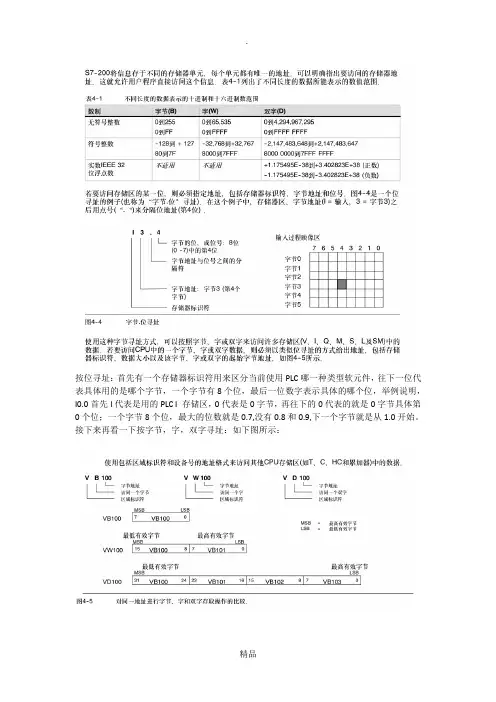
按位寻址:首先有一个存储器标识符用来区分当前使用PLC哪一种类型软元件,往下一位代表具体用的是哪个字节,一个字节有8个位,最后一位数字表示具体的哪个位,举例说明,I0.0首先I代表是用的PLC I 存储区,0代表是0字节,再往下的0代表的就是0字节具体第0个位;一个字节8个位,最大的位数就是0.7,没有0.8和0.9,下一个字节就是从1.0开始。
接下来再看一下按字节,字,双字寻址:如下图所示:学会按位寻址以后,对于按字节、按字以及双字寻址都是一样,首先:一个字节其实就是8个位,一个字就是16个位,一个双字就是32个位,可以理解为谁包含了谁;再看格式书写,第一位是存储器的标识符,第二位变为寻址方式的标识符,如B代表是按字节寻址,W代表的是按字寻址,D代表的是按双字寻址,最后一位代表的就是字节起始地址;举例说明VD0,V代表当前用的是PLC的V存储器,D代表的是按双字寻址,最后一位0代表被占用的起始字节,双字包含32个位,它共占用了从VB0开始到VB3这四个存储字节。
假设写的是VD1,那么它占用的起始字节就是从1开始,一共占用了VB1 VB2 VB3 VB4四个存储区。
1中VD0由VBO、VB1、VB2、VB3组成,它包括VWO、VBO、V0.0;而VW0由VB0和VB1组成,它包括了VB0和V0.0;而VB0由VB0.0~VB0.7这八个位组成,它包括V0.0。
建议您把西门子的200基础知识好好看看,这些都是很有用的2、四者的寻址方式不同,V0.0是按位寻址,VB0是按字节寻址,VW0是按字寻址,VD0是按双字寻址。
VD0由VBO、VB1、VB2、VB3组成,它包括VWO、VBO、V0.0; VW0由VB0和VB1组成,它包括了VB0和V0.0;VB0由VB0.0~VB0.7这八个位组成,它包括V0.0。
3、1字节=8个二进制位(简称位) 1字=2字节=16位 1双字=2字=4字节=32位4、字由一串字节组成,字节由8个位组成,双字节就是连续的16个位了如有侵权请联系告知删除,感谢你们的配合!。

1、位(bit)来自英文bit,音译为“比特”,表示二进制位。
位是计算机内部数据储存的最小单位,是一个8位二进制数。
一个二进制位只可以表示0和1两种状态(21);两个二进制位可以表示00、01、10、11四种(22)状态;三位二进制数可表示八种状态(23)……。
2、字节(byte)字节来自英文Byte,音译为“拜特”,习惯上用大写的“B”表示。
字节是计算机中数据处理的基本单位。
计算机中以字节为单位存储和解释信息,规定一个字节由八个二进制位构成,即1个字节等于8个比特(1Byte=8bit)。
八位二进制数最小为00000000,最大为;通常1个字节可以存入一个ASCII码,2个字节可以存放一个汉字国标码。
3、字计算机进行数据处理时,一次存取、加工和传送的数据长度称为字(word)。
一个字通常由一个或多个(一般是字节的整数位)字节构成。
例如286微机的字由2个字节组成,它的字长为16;486微机的字由4个字节组成,它的字长为32位机。
计算机的字长决定了其CPU一次操作处理实际位数的多少,由此可见计算机的字长越大,其性能越优越。
另一种说法:字在计算机中,一串数码作为一个整体来处理或运算的,称为一个计算机字,简称宇。
字通常分为若干个字节(每个字节一般是8位)。
在存储器中,通常每个单元存储一个字,因此每个字都是可以寻址的。
字的长度用位数来表示。
在计算机的运算器、控制器中,通常都是以字为单位进行传送的。
宇出现在不问的地址其含义是不相同。
例如,送往控制器去的字是指令,而送往运算器去的字就是一个数。
在计算机中作为一个整体被存取、传送、处理的二进制数字符串叫做一个字或单元,每个字中二进制位数的长度,称为字长。
一个字由若干个字节组成,不同的计算机系统的字长是不同的,常见的有8位、16位、32位、64位等,字长越长,计算机一次处理的信息位就越多,精度就越高,字长是计算机性能的一个重要指标。
目前主流微机都是32位机。
注意字与字长的区别,字是单位,而字长是指标,指标需要用单位去衡量。



S7-1200 PLC的基本数据类型,你了解多少?如果有了解过S7-1200 PLC的学员,相信应该知道S7-1200 PLC所支持的数据类型是远远多于S7-200/200 SMART PLC的吧?今天就给大家介绍一下S7-1200 PLC的数据类型。
除了基本数据类型之外,还支持一些复杂的数据类型,包括结构数据类型Struct、PLC数据类型UDT、数组Array、系统数据类型SDT、硬件数据类型DB_ANY、参数数据类型Variant、String和Char数据类型、WString和WChar数据类型、DTL数据类型等。
就基本数据类型而言,S7-1200 PLC与S7-200/200 SMART PLC的也有不同,这篇文件中我们先介绍基本数据类型(复杂数据类型下一篇中介绍),基本数据类型包括位、字节、字、双字、整数、浮点数、日期时间,此外字符(String和Char 数据类型、WString和WChar数据类型)也属于基本数据类型。
1、位、字节、字和双字位为Bool,字节为Byte,字为Word,双字为DWord。
这些数据类型与S7-200/200 SMART PLC都是一样的。
这里便不再多说,具体可看下表。
2、整数数据类型对于S7-200/200 SMART PLC整数数据类型只有INT整数和DINT双整数这两种,而S7-1200 PLC支持6种,USInt、UInt、UDInt是无符号数,SInt、Int、DInt是有符号数,他们的数值范围有所不同。
3、浮点数数据类型在S7-1200PLC中,浮点数以32 位单精度数(Real) 或64 位双精度数(LReal) 表示。
但是像S7-200/200 SMART PLC中就没有LReal的数据类型。
4、时间和日期数据类型时间和日期数据类型包括Time、Date、Time_of_Day这三种。
S7-200/200 SMART PLC是不支持这几种数据类型的,但是S7-1200PLC可以支持这几种数据类型。

字节、字、双字,整数,双整数和浮点数详解1.引言1.1 概述在计算机科学和编程领域,字节、字、双字、整数、双整数和浮点数是非常重要的概念和数据类型。
它们在存储和处理数据时起着关键作用。
本文将对这些概念和数据类型进行详细解释和讨论。
首先,字节是计算机存储和处理数据的基本单位之一。
一个字节由8位二进制数字组成,可以表示256种不同的值。
字节一般用于存储和表示字符,例如ASCII码中的每个字符都用一个字节表示。
接下来,字是字节的扩展,通常由两个字节组成。
字是更大的数据单元,可以表示更多的不同值。
字通常用于存储和表示较大的字符集,如Unicode编码中的字符。
双字是对字的一种拓展,由四个字节组成。
双字可以表示更大范围的数据,通常用于存储和处理较大的整数和浮点数。
然后,整数是一种完整的数值数据类型,用于表示不带小数部分的数值。
整数可以是负数、零或正数,其取值范围取决于所使用的字节数。
整数常用于计算、逻辑运算和数据存储。
双整数是对整数的一种拓展,由两个整数组成。
双整数可以表示更大范围的整数值,通常用于需要更精确的计算和表示的情况。
最后,浮点数是一种带有小数部分的数值数据类型。
浮点数通常由双字表示,其中一部分用于存储小数部分,另一部分用于存储指数部分。
浮点数常用于科学计算、图形处理和物理模拟等领域。
本文将详细探讨字节、字、双字、整数、双整数和浮点数的定义、特点、应用、表示方式、运算规则和数据范围等方面内容。
通过深入理解这些概念和数据类型,我们可以更好地理解计算机的内部处理和存储方式,并在编程中更加灵活和高效地处理数据。
1.2文章结构文章结构部分的内容可以写成以下方式:1.2 文章结构本文将详细介绍字节、字、双字、整数、双整数和浮点数的概念以及其应用。
文章结构如下:2.正文2.1 字节2.1.1 定义本节将介绍字节的定义,以及字节在计算机中的作用和意义。
2.1.2 应用本节将探讨字节在不同应用场景下的具体应用,例如在存储和传输数据中的作用。

双字,字节转换题在计算机领域中,我们经常会遇到关于数据存储和传输的问题。
其中,一个常见的问题就是字节与双字之间的转换。
本文将为您介绍这个问题,并提供一些方便快捷的方法。
首先,我们来了解一下字节和双字的概念。
字节是计算机中最小的存储单位,通常由8个比特(bit)组成。
而双字则由两个字节构成,即16个比特。
在计算机内存和数据传输过程中,字节和双字的转换非常常见。
在将字节转换为双字时,我们可以使用位运算来实现。
具体操作如下:1. 首先,将字节的高字节和低字节分别提取出来。
2. 然后,将高字节左移8位,再与低字节进行按位或操作。
下面是一个示例:假设我们有一个字节:10101010我们可以将其转换为双字的步骤如下:1. 首先,提取出高字节和低字节:1010和10102. 然后,将高字节左移8位,得到:1010000000003. 最后,将上述结果与低字节进行按位或操作,得到最终的双字:101010101010同样,我们也可以将双字转换为字节。
具体操作如下:1. 首先,将双字的高字节和低字节分别提取出来。
2. 然后,将高字节右移8位,即将高字节的前8位去除。
3. 最后,分别得到高字节和低字节的值。
下面是一个示例:假设我们有一个双字:1100110011001100我们可以将其转换为字节的步骤如下:1. 首先,提取出高字节和低字节:11001100和110011002. 然后,将高字节右移8位,得到:0000000011003. 最后,得到高字节和低字节的值分别为:00000000和11001100通过以上的方法,我们可以很方便地将字节和双字进行转换,从而满足不同的计算需求。
总结起来,字节和双字之间的转换是计算机中常见的操作。
通过位运算,我们可以方便地进行转换,并满足不同的计算需求。
熟练掌握这些转换方法,对于理解和应用计算机技术都非常有帮助。
希望本文的内容能对您有所帮助,谢谢阅读!。

西门子S7-300系列PLC基础知识-地址分配当物理模块安装完毕后,要对信号模块SM上的每一个信号通道分配一个物理地址,从而使用户程序能够识别这些这些通道。
首先要清楚以下几个概念:位,Bit字节,Byte,1Byte=8Bit字,Word,1个字等于2个字节,等于16位双字,D,等于2个字,4个字节,32位1、数字量的地址每个位BIT可以表示一个数字I/O点。
数字量以字节为单位(包括8个位),每个字节可表示8个I/O点。
数字量每个槽(模块)分为4个字节Byte。
所以一个槽可以表示32个I/O通道。
比如Q4.2,Q表示输出区域,4表示第4个字节,2表示第4个字节中的第3位。
数字量的地址分配如下图。
如果一个槽内只有一个16点的I/O模块,则地址只占用0.0至1.7,2.0至3.7不使用。
2、模拟量的地址每个字W可以表示一个模拟量通道。
每个槽(模块)分为16个字节(16Byte),即8个通道。
比如PIW256,PI表示外设输入,W表示一个字W的长度,256表示256和257两个字节组成的单字PIW256,256表示首地址。
模拟量地址分配见下图:注意:-以上地址都是从第四个槽开始,前3个槽预留给PS,CPU,IM。
-由于一个模拟通道是由一个单字W组成,所以PIW257,IW273等等地址是不存在的,如果在编程中出现,会导致出错,这一点是初学者常犯的错误。
-当数字量和模拟量插槽混合使用的时候,仍然可以按照上面的原则分配。
只不过会出现很多未被使用的地址。
如下图所示:存贮器表示方法主标识符+辅助标识符+地址主标识符有:输入映像区I、输出映像区Q、外设输入PI、外设输出PQ、存储区域映像区M、数据表DB、DI、定时器T、计数器C、本地数据L、系统保留区。
辅助标识符有:X(省略)位、B字节、W字、D双字。

PLC 的数据类型在工业自动化的控制系统中,PLC (可编程逻辑控制器)是一种非常常见的控制器,比较有名的PLC 品牌,国外有西门子、三菱、欧姆龙、施耐德等,国内有信捷、台达等。
PLC 作为工业现场使用的控制器,具有安全稳定的特性,适用于工业现场复杂的生产环境以及对于通讯的实时性的高要求。
对于工厂的制造设备来说,数据的传输,是非常重要的,一般来说,一个完整的工厂内,充满了各种传感器、仪器仪表、执行器、驱动器、电机等元器件,它们之间通过电线或总线连接,将现场设备产生的实时生产数据,传送到PLC 中,经过PLC 中的程序的处理,最终输出到现场的各个执行器,形成了一个周而复始的自动化过程。
如果我们要使用PLC 来进行编程,首先就要了解PLC 的可使用的数据类型有哪些? 我们以西门子S7-1200系列的PLC 为例,来进行说明。
(西门子的PLC 市场占有率在所以PLC 品牌中居首位,是十分具有代表性的品牌)我们先来看1200的基本数据类型,包括:1、位和位序列:位和位序列主要包括以下类型:位(Bit )、字节(Byte )、字(Word )、双字(DWORD ),西门子官方将这四类综合在一起,是因为这四个数据类型都是由位组成。
首先来说“位”,即一个Bit ,也就是布尔量(BOOL ),其数值为二进制的0或者1,其详细信息可见下图(1),众所周知,计算机是一个二进制的系统,这是所有计算的基础,无论什么数据,最终都会转化为二进制,才能被计算机的芯片识别,PLC 也是一种计算机,所以,也是以二进制为基础的。
位数据可以表示一个传感器的状态,比如0表示无信号,1 表示有信号,也可以作为输出状态,比如0表示电磁阀或电机无输出,1表示阀体动作或电机运行,等等,在PLC 中,特别是梯形图逻辑中,位数据是最常用的一种数据类型,尽管每个位只能表示两个状态,但当多个位逻辑组合在一起,就可以形成一个复杂的逻辑条件,从而实现复杂的动作控制。
plc字节高低位-回复PLC(可编程逻辑控制器)是一种常用于工业自动化控制系统的设备。
在PLC中,数据是以位、字或双字的形式进行处理和传输。
字节高低位是指字节中位的排列顺序,它在PLC中起着至关重要的作用。
本文将一步一步回答关于PLC字节高低位的问题,并解释其重要性以及如何正确配置PLC 以实现最佳性能。
首先,让我们来了解一下PLC中数据的基本组织方式。
在PLC中,数据是以二进制形式进行表示,每个位(bit)可以为0或1。
多个位组合在一起形成字节(byte),通常一个字节由8个位组成。
字节是PLC中数据处理和传输的基本单位。
然而,在PLC中,字节的排列方式有两种不同的方法:高位在前和低位在前。
高位在前指的是字节的最高有效位(Most Significant Bit,MSB)排在前面,而低位在前指的是最低有效位(Least Significant Bit,LSB)排在前面。
这个排列方式取决于PLC的硬件设计和配置。
为了更好地理解字节高低位的重要性,让我们考虑一个示例,假设我们需要控制一个工业设备的动作。
我们可以将不同的控制信号定义为PLC中的位,然后将这些位组合成字节,以实现更复杂的控制功能。
现在假设我们要控制一个电机的启停动作。
我们可以用一个位来表示电机的启停信号,例如0表示停止,1表示运行。
假设我们将这个位定义为字节中的最低有效位。
如果我们将该字节定义为低位在前方式,那么字节的二进制表示将是“00000001”,其中最低有效位为1,表示电机正在运行。
然而,如果我们将该字节定义为高位在前方式,那么字节的二进制表示将是“10000000”,其中最高有效位为1,表示电机正在运行。
这两种方式的定义将直接影响到PLC的编程和控制逻辑。
那么该如何正确配置PLC的字节高低位呢?首先,我们需要根据PLC的硬件设计和配置确定字节的高低位排列方式。
这通常可以在PLC的技术手册或用户手册中找到。
如果没有明确的说明,推荐的做法是遵循PLC制造商的建议,并与其技术支持团队进行咨询。
一个字母几个字节
一个字母两个字节。
字(word)两个byte称为一个word,所以字大小应该是16位bit,共两字节。
双字(double word 简写为DWORD)见名知意,两个字,四个字节,32bit。
在C语言中,每种数据类型都有其存储长度。
而且在特定的平台和特定的编译器下是不一样的。
char 字符型占1byte 即8位,一个char型数据(例如:a、#、!之类的)用了1个字节来存储
unsigned char 无符号的字符型占1byte 即8位它主要是为了能够兼容扩展ASCII码,由于 char 由8位表示表示范围为 -128 - +127,无法表示带上扩展ASCII码总共256个字符所以如果把 8位中的最高位符号位也用来计数,就可以正好表示256个字符,unsigned char 表示范围为 0 - 255 正好256个数可以对应包含扩展ASCII码在内的共计256个ASCII字符
汉字在计算机中存储是使用机内码(一种数字编号)来存储的,而常用汉字不过是几万个,如果用16位比特(即2的16此方等于65536)就可以表示了,所以汉字字符存储使用了两个字节。
每两个字节即16bit对应一个汉字。
双字、字、字节和位的关系总结
一、资料查询:
相信从网上搜一下西门子数据类型方面的资料,会有一大堆,最常见的就是解释双字和字节之间的组成关系,如下图:
就以这个资料为基础,进行试验验证;
二、程序准备
由于资料上大部分都是以M区介绍双字和字节等关系,但是实际情况是DB块中的数据居多,故在此实验中,将M区和DB区的内容进行对比,以方便观察,进行如下准备:
1、新建DB块,里面创建需要的变量:
2、创建M区变量,以方便做比较,这里取MD24,然后将其拆成字、字节、位,以方便观察:
3、创建FC程序:主要是将双字拆成字、双字,并将双字传送给单字、单字传送给双字,为了方便置位双字中的位,特意用数组逐位传送给双字中的位:
三、程序验证:
省略掉程序的下载啊、仿真啊的操作步骤,因为那个不是重点,直接展示测试结果:从数组中,分别置位不同的位,则相当于分别对双字中的位进行置位,可以分别观察结果,现在取比较有代表性的两个位,即将第0位和第16位置1,结果如下两图所示:
通过测试可以发现如下规律:
1、西门子双字中位的排列,是从右向左排的,这点和平时写字顺序正好相反,但是我觉得可以从进制的位数去记忆一下,比如我们十进制,从右往左分别是个、十、百、千、万等位,这个正好类似于那个;
2、可以看下双字传给单字的情况,对于截取数据时候比较有帮助,具体不总结,可以体会一下;
3、第三条也是我一开始比较迷糊的地方,观察双字的四个字节,和位的排序是一样的,即0位在右,依次往左增大,但是M区其实按照这个方向排列,但是让人很迷糊,上图为例,我们置位0位的时候,在DB中是第0个字节有变化,但是在M区中对应的是MB27变化,虽然按照一开始资料所示,MB27是在
最右边,但是MB27是第0字节,MB26是第1字节,依次类推,大小和字节顺序又反了一次,虽然仔细想一下就明白怎么回事,但是依然有点小别扭;。