SPSS软件聚类分析过程的图文解释及结果的全面分析
- 格式:docx
- 大小:482.95 KB
- 文档页数:17



SPSS聚类分析实例讲解SPSS是一款功能强大的统计分析软件,可用于数据清洗、描述统计分析、假设检验和聚类分析等。
聚类分析是一种无监督学习方法,其目标是按照数据的相似性度量,将样本数据划分为多个不同的群组。
下面将以一个实例来讲解如何使用SPSS进行聚类分析。
实例描述:假设有一个超市的销售数据,包含了不同商品的销售额、销售量和利润等信息。
我们希望将商品进行聚类分析,找出相似销售特征的商品群组。
步骤一:数据准备首先,将销售数据保存为一个.SP文件,然后打开SPSS软件。
在主界面上选择“文件”-“打开”-“数据库”-“从SPSS文件”,打开数据文件。
步骤二:变量选择在数据文件中,选择出要进行聚类分析的变量。
在“数据视图”中,选择那些代表销售特征的变量,例如“销售额”、“销售量”和“利润”。
在变量列上按住“Ctrl”键,同时点击这些变量名,选中它们。
步骤三:聚类分析点击菜单上的“数据”-“服务”-“聚类分析”进行聚类分析操作。
会弹出“聚类分析”对话框。
在对话框中,将选中的变量移到右侧的“变量”框中,并选择“K均值聚类”作为聚类方法。
K值是指要分成的群组数量,可以根据实际情况设定。
这里假设将商品分成3个群组,因此设置为3步骤四:聚类结果解读点击“确定”按钮,SPSS将自动进行聚类分析。
完成后,SPSS会在数据文件中生成一个新的变量,用于表示每个样本所属的群组。
在下方的“结果视图”中,可以看到聚类结果的统计数据、聚类中心和变量间的距离。
此外,在“分类变量资料”中,还可以看到每个样本所属的群组编号。
步骤五:聚类结果可视化为了更好地理解聚类结果,可以进行可视化展示。
点击菜单上的“图形”-“散点图”,在对话框中依次选择所属群组变量和销售额、销售量这两个变量。
点击“确定”按钮,即可生成散点图。
散点图可以清楚地显示出不同群组之间的差异和相似性。
根据散点图,可以对聚类结果进行解读。
例如,如果不同群组之间的点比较分散,则说明聚类效果较差;而如果不同群组之间的点比较集中,则说明聚类效果较好。





SPSS聚类分析过程聚类的主要过程一般可分为如下四个步骤:1.数据预处理(标准化)2.构造关系矩阵(亲疏关系的描述)3.聚类(根据不同方法进行分类)4.确定最佳分类(类别数)SPSS软件聚类步骤1. 数据预处理(标准化)→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可:标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。
);Range 0 to 1(极差正规化变换/ 规格化变换);2. 构造关系矩阵在SPSS中如何选择测度(相似性统计量):→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数;3. 选择聚类方法SPSS中如何选择系统聚类法常用系统聚类方法a)Between-groups linkage 组间平均距离连接法方法简述:合并两类的结果使所有的两两项对之间的平均距离最小。
(项对的两成员分属不同类)特点:非最大距离,也非最小距离b)Within-groups linkage 组内平均连接法方法简述:两类合并为一类后,合并后的类中所有项之间的平均距离最小C)Nearest neighbor 最近邻法(最短距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法d)Furthest neighbor 最远邻法(最长距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法e)Centroid clustering 重心聚类法方法简述:两类间的距离定义为两类重心之间的距离,对样品分类而言,每一类中心就是属于该类样品的均值特点:该距离随聚类地进行不断缩小。


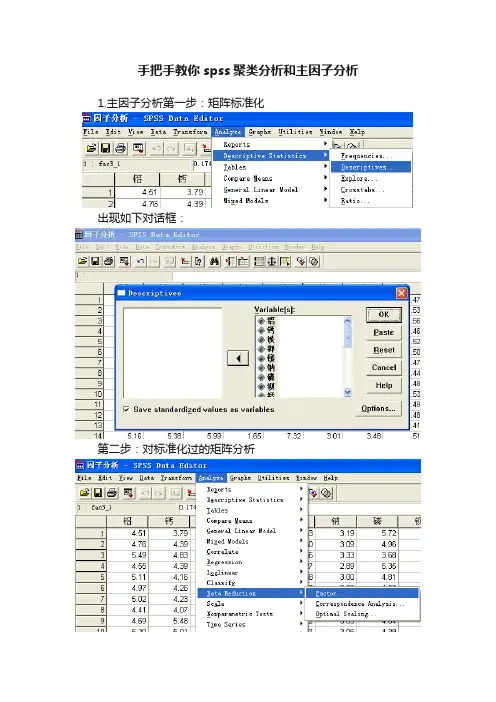
手把手教你spss聚类分析和主因子分析1.主因子分析第一步:矩阵标准化出现如下对话框:第二步:对标准化过的矩阵分析聚类分析基于SPSS的聚类分析的实用方法(层次聚类法和迭代聚类法)层次聚类法和迭代聚类法的主要区别在于:层次聚类法的聚类结果受奇异值的影响非常大,且聚类过程是单方向的,一旦某个样本进入某一类,就不可能从该类出来,再归入其他的类;迭代聚类法的聚类结果受奇异值和不合适的聚类变量的影响较小,对于不合适的初始聚类可以进行反复调整,但其缺点是聚类结果对初始聚类非常敏感,而且它也只能得到局部最优解.(一)层次聚类Analyze--> C1assify-->Hierachical Cluster在“C1uster”组中选择聚类类型:要进行变量聚类选择指定“V anables”;要进行观测量聚类指定“Cases”。
指定参与分析的变量,将选定的变量通过按钮箭头转移到箭头按钮右侧的“V ariable[s]:”矩形框中;将标识变量通过下面一个箭头按钮转移到按钮右侧的“Label Cases by:”下面的矩形框中。
如果不使用系统默认值,或由于参与分析的变量量纲不一致需要指定选择项,则应该根据需要有选择性地执行下述某些步骤。
1.确定聚类方法在主对话框中,点击“Methed”按钮,展开分层聚类分析的方法选择对话框,即“Hierachical Cluster Analysis:Method”。
在对话框中根据需要指定聚类方法、距离测度的方法、对数值进行转换方法,即标准化数值的方法和对测度的转换方法。
(1)聚类方法选择“C1uster Method:”表中列出可以选择的聚类方法:Between-groups linkage组内连接Within-groups linkage组内连接Nearest neighbor最近邻法Furthest neighbor最远邻法Centroid clustering重心聚类法Median clustering中位数法Ward’s method Ward最小方差法。
SPSS实操4:聚类分析我们有时需要对⼀波总体样本进⾏分群,从⽽更好地了解群体之间的差异,通过聚类分析可以帮助我们解决这个问题。
聚类分析在市场细分、⼈群细分等⽅⾯可以给我们很多启发。
聚类分析在SPSS中分为系统聚类、K聚类及两步聚类。
从区别上看,系统聚类、K聚类主要针对的是计量资料,⽽两步具备可同时对计量资料、计数资料进⾏处理。
尽管在⽇常⼯作涉及的问卷中,计数资料涉及得较少,但从结果解读⽅⾯,仍然是两步聚类的解读更为直观。
以两步聚类为例,我们来看⼀个案例:例如:我们想针对⼀波美妆⽤户群体进⾏⼈群细分。
通过两步聚类,我们能够从⼀波样本中划分不同的细分⼈群。
经过本篇⽂章学习,您能够对问卷数据做以下分析:①对总样本进⾏聚类②筛选满⾜不同条件的个案进⾏进⼀步分析(选择个案)两步聚类TIPS:在两步聚类前,⼀定要先清洗数据,因跳转题⽽出现的-3值,要全部清除掉之后再进⾏聚类操作1.分析-分类-两步聚类2.将可能影响到⼈群细分结果的变量选⼊分类变量中连续变量在本次问卷题⽬中未涉及,因此不选这⼀步的变量选择在不确定的情况下,可能需要多次聚类验证,⼀定要选择聚类效果最佳的那⼏个变量这⾥已经根据最佳效果选择好了相关变量3.选项-操作默认若涉及到连续变量,在【要标准化的变量】中,将出现连续变量这⾥未涉及连续变量,因此这⾥未显⽰任何变量4.输出勾选上⽅的图表和表格、创建聚类成员变量5.确定6.结果解读⾸先会出现⼀个简单的图,先来看⼀下这个图显⽰我们输⼊了8个相关变量,聚类为5类我们本次预测质量处在【良好】区间(这⼀步可多试⼏个变量,选择预测质量最好的那次即可)双击这张图,会出现2个视图框左侧还是刚刚的图,右侧则出现了本次5种聚类在总样本的占⽐情况请注意,现在左侧视图默认在【模型概要】我们现在选择【聚类】,会根据预测变量重要性出现⼀张渐变颜⾊的表格逐⼀选择5个聚类所在的列,右侧选择【单元分布】,会显⽰聚类⽐较的结果回到数据视图中,原表格中最后⼀新增了⼀列TSC,显⽰的数值则是根据本次聚类,每个⼈对应在哪个分类的结果。
SPSS软件聚类分析过程的图文解释及结果的全面分析
SPSS聚类分析过程
聚类的主要过程一般可分为如下四个步骤:
1.数据预处理(标准化)
2.构造关系矩阵(亲疏关系的描述)
3.聚类(根据不同方法进行分类)
4.确定最佳分类(类别数)
SPSS软件聚类步骤
1. 数据预处理(标准化)
→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择
从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可:
标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。
);Range 0 to 1(极差正规化变换 / 规格化变换);
2. 构造关系矩阵
在SPSS中如何选择测度(相似性统计量):
→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择
常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数;
3. 选择聚类方法
SPSS中如何选择系统聚类法
常用系统聚类方法
a)Between-groups linkage 组间平均距离连接法
方法简述:合并两类的结果使所有的两两项对之
间的平均距离最小。
(项对的两成员分属不同类)特点:非最大距离,也非最小距离
b)Within-groups linkage 组内平均连接法
方法简述:两类合并为一类后,合并后的类中所有项之间的平均距离最小
C)Nearest neighbor 最近邻法(最短距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法
d)Furthest neighbor 最远邻法(最长距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法
e)Centroid clustering 重心聚类法
方法简述:两类间的距离定义为两类重心之间的距离,对样品分类而言,每一类中心就是属于该类样品的均值
特点:该距离随聚类地进行不断缩小。
该法的谱系树状图很难跟踪,且符号改变频繁,计算较烦。
f)Median clustering 中位数法
方法简述:两类间的距离既不采用两类间的最近距离,也不采用最远距离,而采用介于两者间的距离
特点:图形将出现递转,谱系树状图很难跟踪,
因而这个方法几乎不被人们采用。
g)Ward’s method 离差平方和法
方法简述:基于方差分析思想,如果分类合理,则同类样品间离差平方和应当较小,类与类间离差平方和应当较大
特点:实际应用中分类效果较好,应用较广;要求样品间的距离必须是欧氏距离。
谱系分类的确定
经过系统聚类法处理后,得到聚类树状谱系
图,Demirmen(1972)提出了应根据研究的目的来确定适当的分类方法,并提出了一些根据谱系图来分类的准则:
A.任何类都必须在临近各类中是突出
的,即各类重心间距离必须极大
B.确定的类中,各类所包含的元素都
不要过分地多
C.分类的数目必须符合实用目的
D.若采用几种不同的聚类方法处理,
则在各自的聚类图中应发现相同的类
实例分析。