模式识别实验一.pdf
- 格式:pdf
- 大小:257.86 KB
- 文档页数:7

模式识别大作业1.最近邻/k近邻法一.基本概念:最近邻法:对于未知样本x,比较x与N个已知类别的样本之间的欧式距离,并决策x与距离它最近的样本同类。
K近邻法:取未知样本x的k个近邻,看这k个近邻中多数属于哪一类,就把x归为哪一类。
K取奇数,为了是避免k1=k2的情况。
二.问题分析:要判别x属于哪一类,关键要求得与x最近的k个样本(当k=1时,即是最近邻法),然后判别这k个样本的多数属于哪一类。
可采用欧式距离公式求得两个样本间的距离s=sqrt((x1-x2)^2+(y1-y2)^2)三.算法分析:该算法中任取每类样本的一半作为训练样本,其余作为测试样本。
例如iris中取每类样本的25组作为训练样本,剩余25组作为测试样本,依次求得与一测试样本x距离最近的k 个样本,并判断k个样本多数属于哪一类,则x就属于哪类。
测试10次,取10次分类正确率的平均值来检验算法的性能。
四.MATLAB代码:最近邻算实现对Iris分类clc;totalsum=0;for ii=1:10data=load('iris.txt');data1=data(1:50,1:4);%任取Iris-setosa数据的25组rbow1=randperm(50);trainsample1=data1(rbow1(:,1:25),1:4);rbow1(:,26:50)=sort(rbow1(:,26:50));%剩余的25组按行下标大小顺序排列testsample1=data1(rbow1(:,26:50),1:4);data2=data(51:100,1:4);%任取Iris-versicolor数据的25组rbow2=randperm(50);trainsample2=data2(rbow2(:,1:25),1:4);rbow2(:,26:50)=sort(rbow2(:,26:50));testsample2=data2(rbow2(:,26:50),1:4);data3=data(101:150,1:4);%任取Iris-virginica数据的25组rbow3=randperm(50);trainsample3=data3(rbow3(:,1:25),1:4);rbow3(:,26:50)=sort(rbow3(:,26:50));testsample3=data3(rbow3(:,26:50),1:4);trainsample=cat(1,trainsample1,trainsample2,trainsample3);%包含75组数据的样本集testsample=cat(1,testsample1,testsample2,testsample3);newchar=zeros(1,75);sum=0;[i,j]=size(trainsample);%i=60,j=4[u,v]=size(testsample);%u=90,v=4for x=1:ufor y=1:iresult=sqrt((testsample(x,1)-trainsample(y,1))^2+(testsample(x,2) -trainsample(y,2))^2+(testsample(x,3)-trainsample(y,3))^2+(testsa mple(x,4)-trainsample(y,4))^2); %欧式距离newchar(1,y)=result;end;[new,Ind]=sort(newchar);class1=0;class2=0;class3=0;if Ind(1,1)<=25class1=class1+1;elseif Ind(1,1)>25&&Ind(1,1)<=50class2=class2+1;elseclass3=class3+1;endif class1>class2&&class1>class3m=1;ty='Iris-setosa';elseif class2>class1&&class2>class3m=2;ty='Iris-versicolor';elseif class3>class1&&class3>class2m=3;ty='Iris-virginica';elsem=0;ty='none';endif x<=25&&m>0disp(sprintf('第%d组数据分类后为%s类',rbow1(:,x+25),ty));elseif x<=25&&m==0disp(sprintf('第%d组数据分类后为%s类',rbow1(:,x+25),'none'));endif x>25&&x<=50&&m>0disp(sprintf('第%d组数据分类后为%s类',50+rbow2(:,x),ty));elseif x>25&&x<=50&&m==0disp(sprintf('第%d组数据分类后为%s类',50+rbow2(:,x),'none'));endif x>50&&x<=75&&m>0disp(sprintf('第%d组数据分类后为%s类',100+rbow3(:,x-25),ty));elseif x>50&&x<=75&&m==0disp(sprintf('第%d组数据分类后为%s类',100+rbow3(:,x-25),'none'));endif (x<=25&&m==1)||(x>25&&x<=50&&m==2)||(x>50&&x<=75&&m==3)sum=sum+1;endenddisp(sprintf('第%d次分类识别率为%4.2f',ii,sum/75));totalsum=totalsum+(sum/75);enddisp(sprintf('10次分类平均识别率为%4.2f',totalsum/10));测试结果:第3组数据分类后为Iris-setosa类第5组数据分类后为Iris-setosa类第6组数据分类后为Iris-setosa类第7组数据分类后为Iris-setosa类第10组数据分类后为Iris-setosa类第11组数据分类后为Iris-setosa类第12组数据分类后为Iris-setosa类第14组数据分类后为Iris-setosa类第16组数据分类后为Iris-setosa类第18组数据分类后为Iris-setosa类第19组数据分类后为Iris-setosa类第20组数据分类后为Iris-setosa类第23组数据分类后为Iris-setosa类第24组数据分类后为Iris-setosa类第26组数据分类后为Iris-setosa类第28组数据分类后为Iris-setosa类第30组数据分类后为Iris-setosa类第31组数据分类后为Iris-setosa类第34组数据分类后为Iris-setosa类第37组数据分类后为Iris-setosa类第39组数据分类后为Iris-setosa类第41组数据分类后为Iris-setosa类第44组数据分类后为Iris-setosa类第45组数据分类后为Iris-setosa类第49组数据分类后为Iris-setosa类第53组数据分类后为Iris-versicolor类第54组数据分类后为Iris-versicolor类第55组数据分类后为Iris-versicolor类第57组数据分类后为Iris-versicolor类第58组数据分类后为Iris-versicolor类第59组数据分类后为Iris-versicolor类第60组数据分类后为Iris-versicolor类第61组数据分类后为Iris-versicolor类第62组数据分类后为Iris-versicolor类第68组数据分类后为Iris-versicolor类第70组数据分类后为Iris-versicolor类第71组数据分类后为Iris-virginica类第74组数据分类后为Iris-versicolor类第75组数据分类后为Iris-versicolor类第77组数据分类后为Iris-versicolor类第79组数据分类后为Iris-versicolor类第80组数据分类后为Iris-versicolor类第84组数据分类后为Iris-virginica类第85组数据分类后为Iris-versicolor类第92组数据分类后为Iris-versicolor类第95组数据分类后为Iris-versicolor类第97组数据分类后为Iris-versicolor类第98组数据分类后为Iris-versicolor类第99组数据分类后为Iris-versicolor类第102组数据分类后为Iris-virginica类第103组数据分类后为Iris-virginica类第105组数据分类后为Iris-virginica类第106组数据分类后为Iris-virginica类第107组数据分类后为Iris-versicolor类第108组数据分类后为Iris-virginica类第114组数据分类后为Iris-virginica类第118组数据分类后为Iris-virginica类第119组数据分类后为Iris-virginica类第124组数据分类后为Iris-virginica类第125组数据分类后为Iris-virginica类第126组数据分类后为Iris-virginica类第127组数据分类后为Iris-virginica类第128组数据分类后为Iris-virginica类第129组数据分类后为Iris-virginica类第130组数据分类后为Iris-virginica类第133组数据分类后为Iris-virginica类第135组数据分类后为Iris-virginica类第137组数据分类后为Iris-virginica类第142组数据分类后为Iris-virginica类第144组数据分类后为Iris-virginica类第148组数据分类后为Iris-virginica类第149组数据分类后为Iris-virginica类第150组数据分类后为Iris-virginica类k近邻法对wine分类:clc;otalsum=0;for ii=1:10 %循环测试10次data=load('wine.txt');%导入wine数据data1=data(1:59,1:13);%任取第一类数据的30组rbow1=randperm(59);trainsample1=data1(sort(rbow1(:,1:30)),1:13);rbow1(:,31:59)=sort(rbow1(:,31:59)); %剩余的29组按行下标大小顺序排列testsample1=data1(rbow1(:,31:59),1:13);data2=data(60:130,1:13);%任取第二类数据的35组rbow2=randperm(71);trainsample2=data2(sort(rbow2(:,1:35)),1:13);rbow2(:,36:71)=sort(rbow2(:,36:71));testsample2=data2(rbow2(:,36:71),1:13);data3=data(131:178,1:13);%任取第三类数据的24组rbow3=randperm(48);trainsample3=data3(sort(rbow3(:,1:24)),1:13);rbow3(:,25:48)=sort(rbow3(:,25:48));testsample3=data3(rbow3(:,25:48),1:13);train_sample=cat(1,trainsample1,trainsample2,trainsample3);%包含89组数据的样本集test_sample=cat(1,testsample1,testsample2,testsample3);k=19;%19近邻法newchar=zeros(1,89);sum=0;[i,j]=size(train_sample);%i=89,j=13[u,v]=size(test_sample);%u=89,v=13for x=1:ufor y=1:iresult=sqrt((test_sample(x,1)-train_sample(y,1))^2+(test_sample(x ,2)-train_sample(y,2))^2+(test_sample(x,3)-train_sample(y,3))^2+( test_sample(x,4)-train_sample(y,4))^2+(test_sample(x,5)-train_sam ple(y,5))^2+(test_sample(x,6)-train_sample(y,6))^2+(test_sample(x ,7)-train_sample(y,7))^2+(test_sample(x,8)-train_sample(y,8))^2+( test_sample(x,9)-train_sample(y,9))^2+(test_sample(x,10)-train_sa mple(y,10))^2+(test_sample(x,11)-train_sample(y,11))^2+(test_samp le(x,12)-train_sample(y,12))^2+(test_sample(x,13)-train_sample(y, 13))^2); %欧式距离newchar(1,y)=result;end;[new,Ind]=sort(newchar);class1=0;class 2=0;class 3=0;for n=1:kif Ind(1,n)<=30class 1= class 1+1;elseif Ind(1,n)>30&&Ind(1,n)<=65class 2= class 2+1;elseclass 3= class3+1;endendif class 1>= class 2&& class1>= class3m=1;elseif class2>= class1&& class2>= class3m=2;elseif class3>= class1&& class3>= class2m=3;endif x<=29disp(sprintf('第%d组数据分类后为第%d类',rbow1(:,30+x),m));elseif x>29&&x<=65disp(sprintf('第%d组数据分类后为第%d类',59+rbow2(:,x+6),m));elseif x>65&&x<=89disp(sprintf('第%d组数据分类后为第%d类',130+rbow3(:,x-41),m));endif (x<=29&&m==1)||(x>29&&x<=65&&m==2)||(x>65&&x<=89&&m==3) sum=sum+1;endenddisp(sprintf('第%d次分类识别率为%4.2f',ii,sum/89));totalsum=totalsum+(sum/89);enddisp(sprintf('10次分类平均识别率为%4.2f',totalsum/10));第2组数据分类后为第1类第4组数据分类后为第1类第5组数据分类后为第3类第6组数据分类后为第1类第8组数据分类后为第1类第10组数据分类后为第1类第11组数据分类后为第1类第14组数据分类后为第1类第16组数据分类后为第1类第19组数据分类后为第1类第20组数据分类后为第3类第21组数据分类后为第3类第22组数据分类后为第3类第26组数据分类后为第3类第27组数据分类后为第1类第28组数据分类后为第1类第30组数据分类后为第1类第33组数据分类后为第1类第36组数据分类后为第1类第37组数据分类后为第1类第43组数据分类后为第1类第44组数据分类后为第3类第45组数据分类后为第1类第46组数据分类后为第1类第49组数据分类后为第1类第54组数据分类后为第1类第56组数据分类后为第1类第57组数据分类后为第1类第60组数据分类后为第2类第61组数据分类后为第3类第63组数据分类后为第3类第65组数据分类后为第2类第66组数据分类后为第3类第67组数据分类后为第2类第71组数据分类后为第1类第72组数据分类后为第2类第74组数据分类后为第1类第76组数据分类后为第2类第77组数据分类后为第2类第79组数据分类后为第3类第81组数据分类后为第2类第82组数据分类后为第3类第83组数据分类后为第3类第84组数据分类后为第2类第86组数据分类后为第2类第87组数据分类后为第2类第88组数据分类后为第2类第93组数据分类后为第2类第96组数据分类后为第1类第98组数据分类后为第2类第99组数据分类后为第3类第102组数据分类后为第2类第104组数据分类后为第2类第105组数据分类后为第3类第106组数据分类后为第2类第110组数据分类后为第3类第113组数据分类后为第3类第114组数据分类后为第2类第115组数据分类后为第2类第116组数据分类后为第2类第118组数据分类后为第2类第122组数据分类后为第2类第123组数据分类后为第2类第124组数据分类后为第2类第133组数据分类后为第3类第134组数据分类后为第3类第135组数据分类后为第2类第136组数据分类后为第3类第140组数据分类后为第3类第142组数据分类后为第3类第144组数据分类后为第2类第145组数据分类后为第1类第146组数据分类后为第3类第148组数据分类后为第3类第149组数据分类后为第2类第152组数据分类后为第2类第157组数据分类后为第2类第159组数据分类后为第3类第161组数据分类后为第2类第162组数据分类后为第3类第163组数据分类后为第3类第164组数据分类后为第3类第165组数据分类后为第3类第167组数据分类后为第3类第168组数据分类后为第3类第173组数据分类后为第3类第174组数据分类后为第3类2.Fisher线性判别法Fisher 线性判别是统计模式识别的基本方法之一。

. ..学院:班级:姓名:学号:2012年3月实验一 Bayes 分类器的设计一、 实验目的:1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识;2. 理解二类分类器的设计原理。
二、 实验条件:1. PC 微机一台和MATLAB 软件。
三、 实验原理:最小风险贝叶斯决策可按下列步骤进行:1. 在已知)(i P ω,)|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率:∑==c j jj i i i P X P P X P X P 1)()|()()|()|(ωωωωω c j ,,1 =2. 利用计算出的后验概率及决策表,按下式计算出采取i α决策的条件风险: ∑==c j j j i i X P X R 1)|(),()|(ωωαλα a i ,,1 =3. 对2中得到的a 个条件风险值)|(X R i α(a i ,,1 =)进行比较,找出使条件风险最小的决策k α,即:)|(min )|(,,1X R X R k c i k αα ==, 则k α就是最小风险贝叶斯决策。
四、 实验内容:(以下例为模板,自己输入实验数据)假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9;异常状态:)(2ωP =0.1。
现有一系列待观察的细胞,其观察值为x :-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752-3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682-1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532)|(1ωx P )|(2ωx P 类条件概率分布正态分布分别为(-2,0.25)(2,4)。

模式识别习题集答案解析1、PCA和LDA的区别?PCA是⼀种⽆监督的映射⽅法,LDA是⼀种有监督的映射⽅法。
PCA只是将整组数据映射到最⽅便表⽰这组数据的坐标轴上,映射时没有利⽤任何数据部的分类信息。
因此,虽然做了PCA后,整组数据在表⽰上更加⽅便(降低了维数并将信息损失降到了最低),但在分类上也许会变得更加困难;LDA在增加了分类信息之后,将输⼊映射到了另外⼀个坐标轴上,有了这样⼀个映射,数据之间就变得更易区分了(在低纬上就可以区分,减少了很⼤的运算量),它的⽬标是使得类别的点距离越近越好,类别间的点越远越好。
2、最⼤似然估计和贝叶斯⽅法的区别?p(x|X)是概率密度函数,X是给定的训练样本的集合,在哪种情况下,贝叶斯估计接近最⼤似然估计?最⼤似然估计把待估的参数看做是确定性的量,只是其取值未知。
利⽤已知的样本结果,反推最有可能(最⼤概率)导致这样结果的参数值(模型已知,参数未知)。
贝叶斯估计则是把待估计的参数看成是符合某种先验概率分布的随机变量。
对样本进⾏观测的过程,把先验概率密度转化为后验概率密度,利⽤样本的信息修正了对参数的初始估计值。
当训练样本数量趋于⽆穷的时候,贝叶斯⽅法将接近最⼤似然估计。
如果有⾮常多的训练样本,使得p(x|X)形成⼀个⾮常显著的尖峰,⽽先验概率p(x)⼜是均匀分布,此时两者的本质是相同的。
3、为什么模拟退⽕能够逃脱局部极⼩值?在解空间随机搜索,遇到较优解就接受,遇到较差解就按⼀定的概率决定是否接受,这个概率随时间的变化⽽降低。
实际上模拟退⽕算法也是贪⼼算法,只不过它在这个基础上增加了随机因素。
这个随机因素就是:以⼀定的概率来接受⼀个⽐单前解要差的解。
通过这个随机因素使得算法有可能跳出这个局部最优解。
4、最⼩错误率和最⼩贝叶斯风险之间的关系?基于最⼩风险的贝叶斯决策就是基于最⼩错误率的贝叶斯决策,换⾔之,可以把基于最⼩错误率决策看做是基于最⼩风险决策的⼀个特例,基于最⼩风险决策本质上就是对基于最⼩错误率公式的加权处理。

模式识别习题及答案第⼀章绪论1.什么是模式具体事物所具有的信息。
模式所指的不是事物本⾝,⽽是我们从事物中获得的___信息__。
2.模式识别的定义让计算机来判断事物。
3.模式识别系统主要由哪些部分组成数据获取—预处理—特征提取与选择—分类器设计/ 分类决策。
第⼆章贝叶斯决策理论1.最⼩错误率贝叶斯决策过程答:已知先验概率,类条件概率。
利⽤贝叶斯公式得到后验概率。
根据后验概率⼤⼩进⾏决策分析。
2.最⼩错误率贝叶斯分类器设计过程答:根据训练数据求出先验概率类条件概率分布利⽤贝叶斯公式得到后验概率如果输⼊待测样本X ,计算X 的后验概率根据后验概率⼤⼩进⾏分类决策分析。
3.最⼩错误率贝叶斯决策规则有哪⼏种常⽤的表⽰形式答:4.贝叶斯决策为什么称为最⼩错误率贝叶斯决策答:最⼩错误率Bayes 决策使得每个观测值下的条件错误率最⼩因⽽保证了(平均)错误率最⼩。
Bayes 决策是最优决策:即,能使决策错误率最⼩。
5.贝叶斯决策是由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利⽤这个概率进⾏决策。
6.利⽤乘法法则和全概率公式证明贝叶斯公式答:∑====m j Aj p Aj B p B p A p A B p B p B A p AB p 1)()|()()()|()()|()(所以推出贝叶斯公式7.朴素贝叶斯⽅法的条件独⽴假设是(P(x| ωi) =P(x1, x2, …, xn | ωi)= P(x1| ωi) P(x2| ωi)… P(xn| ωi))8.怎样利⽤朴素贝叶斯⽅法获得各个属性的类条件概率分布答:假设各属性独⽴,P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi)后验概率:P(ωi|x) = P(ωi) P(x1| ωi) P(x2| ωi)… P(xn| ωi)类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值⽅差,最后得到类条件概率分布。


《模式识别》实验报告K-L变换特征提取基于K-L 变换的iris 数据分类⼀、实验原理K-L 变换是⼀种基于⽬标统计特性的最佳正交变换。
它具有⼀些优良的性质:即变换后产⽣的新的分量正交或者不相关;以部分新的分量表⽰原⽮量均⽅误差最⼩;变换后的⽮量更趋确定,能量更集中。
这⼀⽅法的⽬的是寻找任意统计分布的数据集合之主要分量的⼦集。
设n 维⽮量12,,,Tn x x x =x ,其均值⽮量E=µx ,协⽅差阵()T x E=--C x u)(x u ,此协⽅差阵为对称正定阵,则经过正交分解克表⽰为x =TC U ΛU ,其中12,,,[]n diag λλλ=Λ,12,,,n u u u =U 为对应特征值的特征向量组成的变换阵,且满⾜1T-=UU。
变换阵TU 为旋转矩阵,再此变换阵下x 变换为()T -=x u y U ,在新的正交基空间中,相应的协⽅差阵12[,,,]xn diag λλλ==x U C U C。
通过略去对应于若⼲较⼩特征值的特征向量来给y 降维然后进⾏处理。
通常情况下特征值幅度差别很⼤,忽略⼀些较⼩的值并不会引起⼤的误差。
对经过K-L 变换后的特征向量按最⼩错误率bayes 决策和BP 神经⽹络⽅法进⾏分类。
⼆、实验步骤(1)计算样本向量的均值E =µx 和协⽅差阵()T xE ??=--C x u)(x u5.8433 3.0573 3.7580 1.1993??=µ,0.68570.0424 1.27430.51630.04240.189980.32970.12161.27430.3297 3.1163 1.29560.51630.12161.29560.5810x----=--C (2)计算协⽅差阵xC 的特征值和特征向量,则4.2282 , 0.24267 , 0.07821 , 0.023835[]diag =Λ-0.3614 -0.6566 0.5820 0.3155 0.0845 -0.7302 -0.5979 -0.3197 -0.8567 0.1734 -0.0762 -0.4798 -0.3583 0.0755 -0.5458 0.7537??=U从上⾯的计算可以看到协⽅差阵特征值0.023835和0.07821相对于0.24267和4.2282很⼩,并经计算个特征值对误差影响所占⽐重分别为92.462%、5.3066%、1.7103%和0.52122%,因此可以去掉k=1~2个最⼩的特征值,得到新的变换阵12,,,newn k u u u -=U。

模式识别实验报告姓名:班级:学号:提交日期:实验一线性分类器的设计一、实验目的:掌握模式识别的基本概念,理解线性分类器的算法原理。
二、实验要求(1)学习和掌握线性分类器的算法原理;(2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类;(3)对实现的线性分类器性能进行简单的评估(例如算法使用条件,算法效率及复杂度等)。
三、算法原理介绍(1)判别函数:是指由x 的各个分量的线性组合而成的函数:0g(x)w ::t x w w w =+权向量阈值权若样本有c 类,则存在c 个判别函数,对具有0g(x)w t x w =+形式的判别函数的一个两类线性分类器来说,要求实现以下判定规则:12(x)0,y (x)0,y i i g g ωω>∈⎧⎨<∈⎩方程g(x)=0定义了一个判定面,它把两个类的点分开来,这个平面被称为超平面,如下图所示。
(2)广义线性判别函数线性判别函数g(x)又可写成以下形式:01(x)w di i i g w x ==+∑其中系数wi 是权向量w 的分量。
通过加入另外的项(w 的各对分量之间的乘积),得到二次判别函数:因为,不失一般性,可以假设。
这样,二次判别函数拥有更多的系数来产生复杂的分隔面。
此时g(x)=0定义的分隔面是一个二阶曲面。
若继续加入更高次的项,就可以得到多项式判别函数,这可看作对某一判别函数g(x)做级数展开,然后取其截尾逼近,此时广义线性判别函数可写成:或:这里y通常被成为“增广特征向量”(augmented feature vector),类似的,a被称为“增广权向量”,分别可写成:这个从d维x空间到d+1维y空间的映射虽然在数学上几乎没有变化,但十分有用。
虽然增加了一个常量,但在x空间上的所有样本间距离在变换后保持不变,得到的y向量都在d维的自空间中,也就是x空间本身。
通过这种映射,可以将寻找权向量w和权阈值w0的问题简化为寻找一个简单的权向量a。

《模式识别》实验报告班级:电子信息科学与技术13级02 班姓名:学号:指导老师:成绩:通信与信息工程学院二〇一六年实验一 最大最小距离算法一、实验内容1. 熟悉最大最小距离算法,并能够用程序写出。
2. 利用最大最小距离算法寻找到聚类中心,并将模式样本划分到各聚类中心对应的类别中.二、实验原理N 个待分类的模式样本{}N X X X , 21,,分别分类到聚类中心{}N Z Z Z , 21,对应的类别之中.最大最小距离算法描述:(1)任选一个模式样本作为第一聚类中心1Z 。
(2)选择离1Z 距离最远的模式样本作为第二聚类中心2Z 。
(3)逐个计算每个模式样本与已确定的所有聚类中心之间的距离,并选出其中的最小距离.(4)在所有最小距离中选出一个最大的距离,如果该最大值达到了21Z Z -的一定分数比值以上,则将产生最大距离的那个模式样本定义为新增的聚类中心,并返回上一步.否则,聚类中心的计算步骤结束。
这里的21Z Z -的一定分数比值就是阈值T ,即有:1021<<-=θθZ Z T(5)重复步骤(3)和步骤(4),直到没有新的聚类中心出现为止。
在这个过程中,当有k 个聚类中心{}N Z Z Z , 21,时,分别计算每个模式样本与所有聚类中心距离中的最小距离值,寻找到N 个最小距离中的最大距离并进行判别,结果大于阈值T 是,1+k Z 存在,并取为产生最大值的相应模式向量;否则,停止寻找聚类中心。
(6)寻找聚类中心的运算结束后,将模式样本{}N i X i ,2,1, =按最近距离划分到相应的聚类中心所代表的类别之中。
三、实验结果及分析该实验的问题是书上课后习题2。
1,以下利用的matlab 中的元胞存储10个二维模式样本X {1}=[0;0];X{2}=[1;1];X {3}=[2;2];X{4}=[3;7];X{5}=[3;6]; X{6}=[4;6];X{7}=[5;7];X{8}=[6;3];X{9}=[7;3];X{10}=[7;4];利用最大最小距离算法,matlab 运行可以求得从matlab 运行结果可以看出,聚类中心为971,,X X X ,以1X 为聚类中心的点有321,,X X X ,以7X 为聚类中心的点有7654,,,X X X X ,以9X 为聚类中心的有1098,,X X X 。


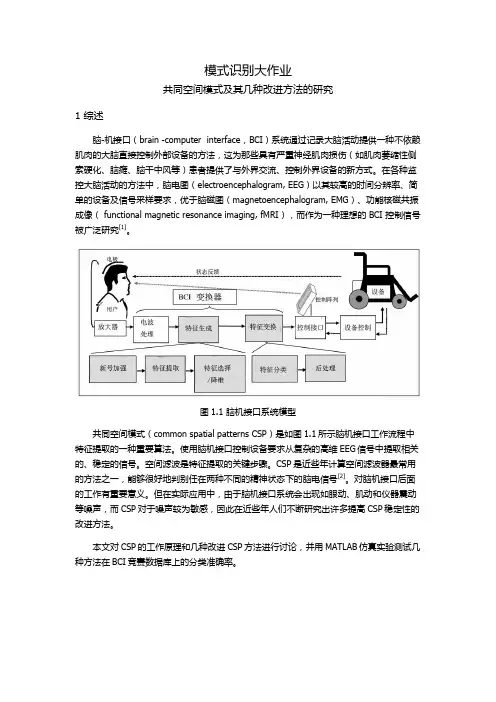
模式识别大作业共同空间模式及其几种改进方法的研究1 综述脑-机接口(brain -computer interface,BCI)系统通过记录大脑活动提供一种不依赖肌肉的大脑直接控制外部设备的方法,这为那些具有严重神经肌肉损伤(如肌肉萎缩性侧索硬化、脑瘫、脑干中风等)患者提供了与外界交流、控制外界设备的新方式。
在各种监控大脑活动的方法中,脑电图(electroencephalogram, EEG)以其较高的时间分辨率、简单的设备及信号采样要求,优于脑磁图(magnetoencephalogram, EMG)、功能核磁共振成像( functional magnetic resonance imaging, fMRI),而作为一种理想的 BCI 控制信号被广泛研究[1]。
图1.1 脑机接口系统模型共同空间模式(common spatial patterns CSP)是如图1.1所示脑机接口工作流程中特征提取的一种重要算法。
使用脑机接口控制设备要求从复杂的高维EEG信号中提取相关的、稳定的信号。
空间滤波是特征提取的关键步骤。
CSP是近些年计算空间滤波器最常用的方法之一,能够很好地判别任在两种不同的精神状态下的脑电信号[2]。
对脑机接口后面的工作有重要意义。
但在实际应用中,由于脑机接口系统会出现如眼动、肌动和仪器震动等噪声,而CSP对于噪声较为敏感,因此在近些年人们不断研究出许多提高CSP稳定性的改进方法。
本文对CSP的工作原理和几种改进CSP方法进行讨论,并用MATLAB仿真实验测试几种方法在BCI竞赛数据库上的分类准确率。
2 经典共同空间模式CSP 算法的目标是创建公共空间滤波器,最大化第一类方差,最小化另一类方差,采用同时对角化两类任务协方差矩阵的方式,区别出两种任务的最大化公共空间特征[3]。
定义一个N x T的矩阵E来表示原始EEG信号数据段,其中N表示电极数目即空间导联数目,T表示每个通道的采样点数目。
基于BP神经网络和k-近邻综合决策法的人脸识别matlab实现高海南31100380111 人脸识别原理人脸识别是目前模式识别领域中被广泛研究的热门课题,它在安全领域以及经济领域都有极其广泛的应用前景。
人脸识别就是采集人脸图像进行分析和处理, 从人脸图像中获取有效的识别信息, 用来进行人脸及身份鉴别的一门技术。
本文在MATLAB环境下,取ORL人脸数据库的部分人脸样本集,基于PCA方法提取人脸特征,形成特征脸空间,然后将每个人脸样本投影到该空间得到一投影系数向量,该投影系数向量在一个低维空间表述了一个人脸样本,这样就得到了训练样本集。
同时将另一部分ORL人脸数据库的人脸作同样处理得到测试样本集。
然后基于BP 神经网络算法和k-近邻算法进行综合决策对待识别的人脸进行分类。
该方法的识别率比单独的BP神经网络算法和k-近邻法有一定的提高。
1.1 ORL人脸数据库简介实验时人脸图像取自英国剑桥大学的ORL人脸数据库,ORL数据库由40个人组成,每个人有10幅不同的图像,每幅图像是一个92×112像素、256级的灰度图,他们是在不同时间、光照略有变化、不同表情以及不同脸部细节下获取的。
如图1所示。
图1 ORL人脸数据库1.2 基于PCA 的人脸图像的特征提取PCA 法是模式识别中的一种行之有效的特征提取方法。
在人脸识别研究中, 可以将该方法用于人脸图像的特征提取。
一个m ×n 的二维脸部图片将其按列首位相连,可以看成是m ×n 的一个一维向量。
ORL 人脸数据库中每张人脸图片大小是92×112,它可以看成是一个10304维的向量,也可以看成是一个10304维空间中一点。
图片映射到这个巨大的空间后,由于人脸的构造相对来说比较接近,因此可以用一个相应的低维子空间来表示。
我们把这个子空间叫做“脸空间”。
PCA 的主要思想就是找到能够最好地说明图片在图片空间中的分布情况的那些向量,这些向量能够定义“脸空间”。
模式识别实验报告_3第⼀次实验实验⽬的:1.学习使⽤ENVI2.会⽤MATLAB读⼊遥感数据并进⾏处理实验内容:⼀学习使⽤ENVI1.使⽤ENVI打开遥感图像(任选3个波段合成假彩⾊图像,保存写⼊报告)2.会查看图像的头⽂件(保存或者copy⾄报告)3.会看地物的光谱曲线(保存或者copy⾄报告)4.进⾏数据信息统计(保存或者copy⾄报告)5.设置ROI,对每类地物⾃⼰添加标记数据,并保存为ROI⽂件和图像⽂件(CMap贴到报告中)。
6.使⽤⾃⼰设置的ROI进⾏图像分类(ENVI中的两种有监督分类算法)(分类算法名称和分类结果写⼊报告)⼆MATLAB处理遥感数据(提交代码和结果)7.⽤MATLAB读⼊遥感数据(zy3和DC两个数据)8.⽤MATLAB读⼊遥感图像中ROI中的数据(包括数据和标签)9.把图像数据m*n*L(其中m表⽰⾏数,n表⽰列数,L表⽰波段数),重新排列为N*L的⼆维矩阵(其中N=m*n),其中N表⽰所有的数据点数量m*n。
(提⽰,⽤reshape函数,可以help查看这个函数的⽤法)10.计算每⼀类数据的均值(平均光谱),并把所有类别的平均光谱画出来(plot)(类似下⾯的效果)。
11.画出zy3数据中“农作物类别”的数据点(⾃⼰ROI标记的这个类别的点)在每个波段的直⽅图(matlab函数:nbins=50;hist(Xi,nbins),其中Xi表⽰这类数据在第i波段的数值)。
计算出这个类别数据的协⽅差矩阵,并画出(figure,imagesc(C),colorbar)。
1.打开遥感图像如下:2.查看图像头⽂件过程如下:3.地物的光谱曲线如下:4.数据信息统计如下:(注:由于保存的txt⽂件中的数据信息过长,所以采⽤截图的⽅式只显⽰了出⼀部分数据信息)5.设置ROI,对每类地物⾃⼰添加标记数据,CMap如下:6.使⽤⾃⼰设置的ROI进⾏图像分类(使⽤⽀持向量机算法和最⼩距离算法),⽀持向量机算法分类结果如下:最⼩距离算法分类结果如下:对⽐两种算法的分类结果可以看出⽀持分量机算法分类结果⽐最⼩距离算法分类结果好⼀些。