R语言与格式、日期格式、格式转化
- 格式:pdf
- 大小:540.22 KB
- 文档页数:7

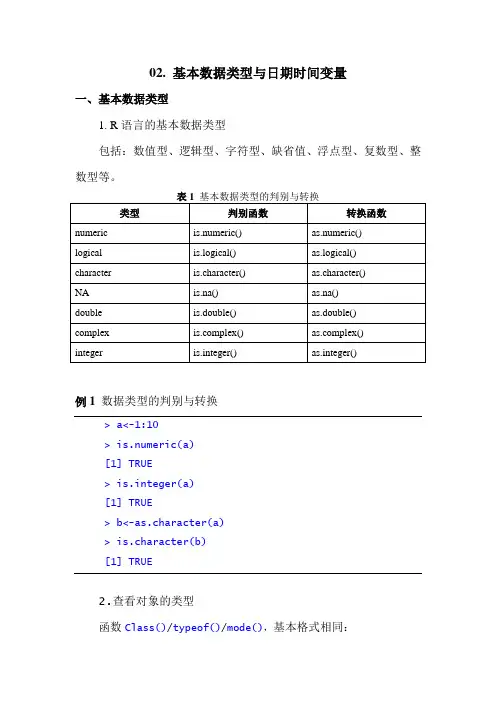
02. 基本数据类型与日期时间变量一、基本数据类型1. R语言的基本数据类型包括:数值型、逻辑型、字符型、缺省值、浮点型、复数型、整数型等。
例1 数据类型的判别与转换> a<-1:10>is.numeric(a)[1] TRUE>is.integer(a)[1] TRUE> b<-as.character(a)>is.character(b)[1] TRUE2.查看对象的类型函数Class()/typeof()/mode(),基本格式相同:class(x)其中x为要查看的对象。
注:在展现数据的细节上,mode()<class()<typeof()二、日期时间变量1. 日期值通常以字符串形式传入R中,然后转化为以数值形式存储的日期变量。
注意:R的内部日期是以1970年1月1日至今的天数来存储,内部时间则是以1970年1月1日至今的秒数来存储。
读取系统当前日期时间的函数(注意大小写):(1)S ys.Date()——返回系统当前的日期(2)S ys.time()——返回系统当前的日期和时间(3)d ate()——返回系统当前的日期和时间(字符串形式)2. 日期时间转化函数(1)字符串型日期变量转化为日期变量函数as.Date(),基本格式为:as.Date(x,format=" ",...)其中,x为字符串型日期值,format指定日期格式。
表2日期时间格式注意:as.Date()只能转化包含年月日星期的字符串,无法转化具体到时间的字符串。
例2将字符型日期转化为日期变量> day<-"07/28/2016" #创建字符串日期值>day[1] "07/28/2016"> date<-as.Date(day,"%m/%d/%Y") #转化为日期变量>date[1] "2016-07-28"(2)字符串日期时间变量转化为时间变量函数as.POSIXlt()与as.POSIXct(),前者为“字符串式”存储,后者为“整数(秒数)”存储,基本格式为:as.POSIXlt(x,tz=" ", format)as.POSIXct(x,tz=" ", format)其中,x为字符串型日期时间值,tz指定转化后的时区(" "为当前时区,“GMT”为格林尼治标准时也是协调世界时UTC的俗称,“CST”为中国标准时即北京时间);format指定日期时间格式。

R语言时间序列中文教程R语言是一种广泛应用于统计分析和数据可视化的编程语言。
它提供了丰富的函数和包,使得处理时间序列数据变得非常方便。
本文将为大家介绍R语言中时间序列分析的基础知识和常用方法。
R语言中最常用的时间序列对象是`ts`对象。
通过将数据转换为`ts`对象,可以使用R语言提供的各种函数和方法来分析时间序列数据。
我们可以使用`ts`函数将数据转换为`ts`对象,并指定数据的时间间隔、起始时间等参数。
例如,对于按月份记录的时间序列数据,可以使用以下代码将数据转换为`ts`对象:```Rts_data <- ts(data, start = c(2000, 1), frequency = 12)```在时间序列分析中,常用的一个概念是平稳性。
平稳性表示时间序列的均值和方差在时间上不发生显著变化。
平稳时间序列的特点是,它的自相关函数(ACF)和偏自相关函数(PACF)衰减得很快。
判断时间序列是否平稳可以通过绘制序列的线图和计算序列的自相关函数来进行。
我们可以使用R语言中的`plot`函数和`acf`函数来实现。
例如,对于一个名为`ts_data`的时间序列数据,可以使用以下代码绘制序列的线图和自相关函数图:```Rplot(ts_data)acf(ts_data)```在进行时间序列分析时,经常需要进行模型拟合和预测。
R语言提供了一些常用的函数和包,用于时间序列的模型拟合和预测。
其中,最常用的方法是自回归移动平均模型(ARIMA)。
ARIMA模型是一种广泛应用于时间序列分析的统计模型,它可以描述时间序列数据中的长期趋势、季节性变动和随机波动等特征。
我们可以使用R语言中的`arima`函数来拟合ARIMA模型,并使用`forecast`函数来进行预测。
以下是一个使用ARIMA模型进行时间序列预测的示例代码:```Rmodel <- arima(ts_data, order = c(p, d, q))forecast_result <- forecast(model, h = 12)```以上代码中,`p`、`d`和`q`分别表示ARIMA模型的自回归阶数、差分阶数和移动平均阶数。

R语言as.posixct用法1.介绍在R语言中,as.p os i xc t函数是用来将不同格式的日期、时间数据转换为P OS IX ct格式的函数。
P OS IX ct是R中用来表示日期和时间的一种数据类型,可以方便地进行日期和时间的计算和操作。
本文将详细介绍a s.p os ix ct函数的用法,以帮助读者更好地理解和应用该函数。
2. as.posixc t函数的基本用法a s.p os ix ct函数的基本语法如下:```Ra s.p os ix ct(x,t z=N U LL)```其中,参数x代表需要转换的日期、时间数据,参数t z代表时区信息(可选)。
接下来将具体介绍每个参数的功能和使用方法。
2.1x参数x参数可以是各种不同的日期、时间数据类型,包括字符类型、数值类型、日期类型等。
a s.p os ix ct函数会根据x参数的数据类型,将其转换为PO SI Xc t格式的日期、时间数据。
下面是一些常见的x参数示例:-字符类型:如"2022-01-01"、"2022-01-0112:00:00"等。
-数值类型:如1640995200,代表1970年1月1日至今的秒数。
-日期类型:如a s.Da t e("2022-01-01"),代表具体的日期。
2.2t z参数t z参数用于指定日期、时间数据的时区信息。
如果不指定tz参数,则默认使用系统的时区信息。
常用的t z参数取值包括:-"UT C":世界协调时。
-"As ia/S ha ng ha i":上海时区。
-其他区域的时区信息。
3.示例下面通过几个具体的示例来演示a s.po si x ct函数的使用方法。
3.1示例1:字符类型转换```R字符类型转换x<-"2022-01-0112:00:00"r e su lt<-as.p os ixc t(x)r e su lt```运行上述代码,将字符类型的日期时间数据"2022-01-0112:00:00"转换为P OS IX ct格式的日期、时间数据。

r语言矩阵的数据格式变换-回复R语言是数据分析和统计建模中常用的编程语言,它具有丰富的函数库和灵活的数据结构,用于处理各种数据类型。
矩阵是R语言中常见的数据结构之一,用于存储具有相同数据类型的元素的二维数组。
在实际应用中,我们经常会遇到需要对矩阵的数据格式进行变换的情况,本文将介绍如何使用R语言进行矩阵的数据格式变换。
1. 行列矩阵转置首先,我们来介绍如何对矩阵进行行列转置。
行列转置是指将矩阵的行变为列,列变为行。
在R语言中,可以使用`t()`函数来实现行列转置。
下面是一个简单的例子:R# 创建一个3行2列的矩阵mat <- matrix(1:6, nrow = 3)# 执行行列转置transposed_mat <- t(mat)# 输出转置后的矩阵transposed_mat上述代码首先使用`matrix()`函数创建了一个3行2列的矩阵,然后使用`t()`函数对矩阵执行了行列转置,最后输出了转置后的矩阵。
你可以运行上述代码,并观察输出结果,以更好地理解行列转置的概念和操作。
2. 矩阵的数据重塑在实际的数据分析中,我们有时候需要对矩阵的数据格式进行重塑。
例如,我们可能要将一个长格式的矩阵转换成宽格式,或者将一个宽格式的矩阵转换成长格式。
R语言中提供了一些函数来实现数据的重塑,其中最常用的是`reshape()`函数。
下面是一个使用`reshape()`函数进行数据重塑的例子:R# 创建一个4行3列的矩阵mat <- matrix(1:12, nrow = 4)# 执行数据重塑,将矩阵转换成长格式reshaped_mat <- reshape(mat, direction = "long", varying =list(1:3))# 输出重塑后的矩阵reshaped_mat上述代码首先使用`matrix()`函数创建了一个4行3列的矩阵,然后使用`reshape()`函数将矩阵转换成了长格式,最后输出了重塑后的矩阵。

R语⾔--基本数据管理(变量、缺失值、⽇期值、数据类型转换、数据框)1 基本数据管理1.1⼀个⽰例(1)定义向量,造数据框manage<-c(1,2,3,4,5)date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")country<-c("US","US","UK","UK","UK")gender<-c("M","F","F","M","F")age<-c(32,45,24,34,88)q1<-c(5,3,3,3,2)q2<-c(4,5,5,3,2)q3<-c(5,2,5,4,1)q4<-c(5,5,5,NA,2)q5<-c(5,5,2,NA,1)lendership<-data.frame(manager,country,gender,age,q1,q2,q3,q4,q5)(2)创建新变量⽅法⼀:使⽤$q6<-q4+q5lendership$q6<-lendership$q4+lendership$q5⽅法⼆:transform()为数据表添加列lendership<-transform(lendership,q7=q4+q5,q8=q1+q2)(3)变量重编码⽅式⼀:使⽤$lendership$age[lendership$age==88]<-NAlendership$agecat[lendership$age>50]<-"Elder"lendership$agecat[lendership$age>40 & lendership$age<=50]<-"Middle Aged"lendership$agecat[lendership$age<40]<-"Young"⽅式⼆:使⽤withinlendership1<-within(lendership,{agecat<-NAagecat[age>50]<-"Elder"agecat[age>40 & age<=50]<-"Middle Aged"agecat[age<=40]<-"Young"})(4)变量重命名⽅式⼀:弹出数据编辑器⽅式⼆:使⽤names(),只能索引⼀列⼀列的改,不⽅便names(lendership)[1]<-"manager1"解释:names⾥⾯是表名,[1]代表修改第⼀列⽅式三:导⼊编辑包plyr,使⽤函数rename()library(plyr)lendership<-rename(lendership,c(manager1="ID",q1="qq1"))2 缺失值2.1 识别缺失值函数is.na()y<-c(1,2,NA)is.na(y)2.2 重编码某些值为缺失值lendership$age[lendership$age==88]<-NA2.3 缺失值参与计算会怎样y<-c(1,2,NA)z<-y[1]+y[2]+y[3]z<-sum(y,na.rm = T) #na.rm = T意思是有缺失值就移除2.4 移除含有缺失值的观测(⾏)newdata<-na.omit(lendership) #删除含有缺失值的⾏3 ⽇期值3.1 ⽇期值的读⼊ as.Datemydata<-as.Date(c("2008-06-11","2018-08-08"))3.2 ⽇期值的格式strdata<-c("01/05/1996","08/22/1998")mydata1<-as.Date(strdata,"%m/%d/%Y") #指定⽇期格式3.3 系统⽇期与当前⽇期系统⽇期:Sys.Date()当前⽇期:date()3.4 ⽇期值的输出格式format(today,format="%B %d %Y") #调整⽇期输出格式format,%B表⽰⽉份⽂字输出3.5 ⽇期值的间隔计算⽅式⼀:按天计算startdata<-as.Date("1996-11-22")enddata<-as.Date("2021-07-02")days<-enddata-startdata⽅式⼆:按周计算,使⽤函数difftim()difftime(enddata,startdata,units = "weeks")4 类型转换4.1 is.xxx()函数,⽤来判断类型4.2 as.xxx()函数,⽤来转换5 数据排序lendership2<-lendership[order(lendership$gender,lendership$age),]6 数据集操作数据输⼊:manage<-c(1,2,3,4,5)date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")country<-c("US","US","UK","UK","UK")gender<-c("M","F","F","M","F")age<-c(32,45,24,34,88)q1<-c(5,3,3,3,2)q2<-c(4,5,5,3,2)q3<-c(5,2,5,4,1)q4<-c(5,5,5,NA,2)q5<-c(5,5,2,NA,1)lendership<-data.frame(manager,country,gender,age,q1,q2,q3,q4,q5)leader_a<-data.frame(manage,country,gender,age)leader_b<-data.frame(manage,q1,q2,q3,q4,q5)leader_b<-leader_b[order(-leader_b$manage),]6.1 数据集(框)的合并 merge()lendership1<-merge(leader_a,leader_b,by="manage") #通过主键manage合并6.2 数据集(框)取⼦集(1)保留变量⽅式⼀:newdata<-lendership[,c(5:9)]⽅式⼆: myvar<-c("gender","country","q5")newdata1<-lendership[myvar](2)删除变量⽅式⼀:前⾯加负号 -newdata<-newdata[c(-2,-3)]⽅式⼆:赋值NULLnewdata$q3<-NULL(3)选⼊观测(保留⾏)newdata2<-lendership[1:3,] #选择1到3⾏newdata3<-lendership[lendership$gender=="M" & lendership$age>30,](4)subset函数newdata4<-subset(lendership,gender=="M" & age>25,select=c("manager","gender","age"))解释:gender=="M" & age>25这是选择保留的⾏,select是选择保留的列若出现了错误:选择了未定义的列修正:检查⾃⼰的列变量名字是否写错(5)使⽤SQL语句操作数据集(框)加载包:library(sqldf)语句:newdf<-sqldf("select * from mtcars where carb=1 order by mpg",s = T)。

R语言的基本操作R语言是一种统计分析和数据可视化的编程语言。
它提供了许多功能和包,使用户能够有效地处理和分析数据。
下面是R语言的基本操作。
1.变量和数据类型2.向量和矩阵向量是R中最基本的数据结构,可以用c(函数创建。
矩阵是一个二维数据结构,可以使用matrix(函数创建。
3.数据框数据框是一种表格型数据结构,它类似于Excel表格。
可以使用data.frame(函数创建数据框。
数据框可以存储不同类型的数据,每一列可以是一个向量。
4.数据导入和导出R可以导入和导出各种数据文件,如CSV、Excel、文本文件等。
可以使用read.csv(函数导入CSV文件,write.csv(函数导出CSV文件。
5.数据处理和转换R提供了许多函数和方法来处理和转换数据。
可以使用subset(函数根据条件筛选数据,使用na.omit(函数删除含有缺失值的观测,使用aggregate(函数进行数据聚合等。
6.数据可视化R有丰富的数据可视化功能,可以使用ggplot2包绘制各种类型的图表,如散点图、直方图、箱线图等。
也可以使用plot(函数绘制基本的统计图。
7.条件语句和循环R支持条件语句(if-else语句)和循环语句(for循环、while循环)。
可以根据条件执行不同的代码块,也可以重复执行段代码。
8.函数和包R允许用户定义自己的函数,以实现特定的功能。
可以使用function(来创建函数。
R还有很多常用的包,如dplyr、tidyr、reshape2等,可以扩展R的功能。
9.统计分析R是一种强大的统计分析工具,提供了很多用于统计分析的函数和包。
可以进行基本统计描述、假设检验、线性回归、方差分析等。
10.错误处理和调试在使用R时,可能会遇到错误或者需要调试代码。
可以使用tryCatch(和debug(函数进行错误处理和调试。
以上只是R语言的一些基本操作,R还有很多高级功能和技巧可以掌握。
掌握这些基本操作对于使用R进行数据分析和可视化工作是非常重要的。

用R语言做时间序列分析
时间序列分析是用来研究数据的变化趋势及其影响因素,以便对未来
的发展趋势有一定的预测对~用R语言做时间序列分析,可以从数据的宏
观分析、模型的训练、数据预测三个方面进行。
一、数据宏观分析
首先,需要预处理数据,例如,对于时间序列数据,要把它转换成一
定的格式,比如时间戳、日期和时间格式,这样R才能够识别这些数据,
在R中,可以使用时间序列模块中的函数来进行转换,比如:as.Date, as.POSIXct, as.POSIXlt等等。
之后需要针对时间序列数据进行宏观分析,可以使用R中的函数acf,pacf来检测时间序列的自相关性,这样可以把时间序列数据分解为不同
的部分,并可以提取出隐藏在数据中的规律,这样就可以确定时间序列模
型的类型,比如AR模型、MA模型、ARMA模型等,根据特定数据的特征,
从这些模型中选择最优的模型。
另外,还可以使用R中的函数spectrum来检测时间序列数据的频率
分布以及振荡性,以及峰值,从而可以有针对性地处理时间序列数据,比
如使用滤波器来去噪。
二、模型的训练
模型的训练也可以使用R进行,R中有专门用于时间序列分析的现成
函数,比如arima函数,可以用来训练ARMA模型。

r语言数据类型时间转换在R语言中,可以使用不同的函数和方法来进行时间的转换和处理。
以下是一些常见的时间转换的方法:1. 字符串到日期/时间的转换:- 使用`as.Date()`函数将字符型日期转换为日期类型。
- 使用`as.POSIXct()`函数将字符型时间戳转换为日期时间类型。
- 使用`as.POSIXlt()`函数将字符型时间戳转换为具有更多详细信息的日期时间类型。
2. 日期/时间到字符串的转换:- 使用`format()`函数将日期/时间转换为自定义格式的字符串。
例如:`format(Sys.Date(), "%Y-%m-%d")`将当前日期转换为"YYYY-MM-DD"的格式。
- 使用`as.character()`函数将日期/时间转换为默认格式的字符串。
3. 数值型到日期/时间的转换:- 使用`as.Date()`函数将数值型日期转换为日期类型。
注意,数值型日期表示自某一参考日期以来的天数。
- 使用`as.POSIXct()`函数将数值型时间戳转换为日期时间类型。
数值型时间戳表示自1970年1月1日以来的秒数。
4. 日期/时间的格式化:- 使用`strftime()`函数将日期/时间格式化为指定的字符串格式。
- 使用`strptime()`函数解析字符串为日期/时间类型,指定相应的格式。
下面是一些示例:```R# 字符串到日期的转换date_str <- "2022-01-01"date <- as.Date(date_str)# 字符串到日期时间的转换datetime_str <- "2022-01-01 12:00:00"datetime <- as.POSIXct(datetime_str)# 日期到字符串的转换date_format <- format(date, "%Y-%m-%d")date_str <- as.character(date)# 数值型日期到日期的转换numeric_date <- 19000date <- as.Date(numeric_date, origin = "1970-01-01")# 数值型时间戳到日期时间的转换numeric_timestamp <- 1641148800datetime <- as.POSIXct(numeric_timestamp, origin = "1970-01-01") # 日期时间的格式化datetime_format <- strftime(datetime, "%Y-%m-%d %H:%M:%S")datetime_parsed <- strptime(datetime_str, "%Y-%m-%d %H:%M:%S") ```请注意,在进行时间转换时,要确保输入的格式和数据类型与所使用的转换函数相匹配。


4、把日期值输出为字符串today <- Sys.Date()format(today, "%Y年%m月%d日")[1] "2014年10月29日"5、计算日期差由于日期部是用double存储的天数,所以是可以相减的。
today <- Sys.Date()gtd <- as.Date("2011-07-01")today - gtdTime difference of 1216 days用difftime()函数可以计算相关的秒数、分钟数、小时数、天数、周数difftime(today, gtd, units="weeks") #还可以是“secs”, “mins”, “hours”, “days”Time difference of 173.7143 weeks#日期型数据在R中自带的日期形式为:as.Date();以数值形式存储;对于规则的格式,则不需要用format指定格式;如果输入的格式不规则,可以通过format 指定的格式读入;标准格式:年-月-日或者年/月/日;如果不是以上二种格式,则会提供错误;as.Date('23-2013-1')错误于charTo按照Date(x) : 字符串的格式不够标准明确> as.Date('23-2013-1',format='%d-%Y-%m')[1] "2013-01-23"格式意义%d 月份中当的天数%m 月份,以数字形式表示%b 月份,缩写%B 月份,完整的月份名,指英文%y 年份,以二位数字表示%Y 年份,以四位数字表示#其它日期相关函数weekdays()取日期对象所处的周几;months()取日期对象的月份;quarters()取日期对象的季度;#POSIX类The POSIXct class stores date/time values as the number of seconds since January 1, 1970, while the POSIXlt class stores them as a list with elements for second, minute, hour, day, month, and year, among others.POSIXct 是以1970年1月1号开始的以秒进行存储,如果是负数,则是1970年以前;正数则是1970年以后。
R语⾔操作X轴⽇期实例讲解R语⾔操作X轴⽇期:需要⽤到程序包library(lubridate);程序包是在R的安装包C:\R-3.4.4\bin 64\RGui.exe⾥根据命令安装的将⽇期改为xxxx/xx/01;firstDay=‘2020/02/12' ;可⽤ day(firstDay)<-01; //此时firstDay的数据为:‘2020/02/01';day()是获取⽇,month()获取⽉份,year()获取年份都需要‘lubridate'包可以通过write.table(firstDay,file='D:\\firstDay.txt');//输出数据使⽤seq()函数参数:from:开始值to:结束值length:⽣成x轴的节点数量by:步长值可以是day,month,year;例如:seq(from=‘2020/03/08',to=‘2020/11/08',by=‘3 month')输出:‘2020/03/08',‘2020/06/08',2020/09/08,‘2020/012/08'注意:length参数和by参数不能同时存在具体每个X轴的⽇期节点差是有by控制的,在没有设定by(步长值)时,是根据by=(to-from)/(length-1) 算出来的规则序列;如果使⽤的是dateNew=as.Date(seq(from=firstDay,to=‘2020/09/08',length=7));此时的dateNew是⼀组⽇期节点个数为7的X轴;如果想让dateNew⽣成的⽇期节点都为某年/某⽉/01,可以使⽤day(dateNew)<-01;此时的dateNew⽣成的⽇期为XX年/XX⽉/01;以下图的⽇期格式为:format="%m/%d/%Y";到此这篇关于R语⾔操作X轴⽇期实例讲解的⽂章就介绍到这了,更多相关R语⾔操作X轴⽇期内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
r语言dmy函数R语言的dmy函数是用于将特定文本格式转化为日期格式的函数。
dmy函数的名称中,“d”、“m”和“y”分别代表“天”、“月”和“年”,因此该函数的作用是将“dd/mm/yyyy”格式的日期文本转换为日期的R对象。
dmy函数的语法如下:> dmy(date_string, tz = "")其中,date_string是一个包含日期字符串的向量,可以是字符型向量或者因子型向量;tz是时区属性,默认为空。
如果要转化的字符串中不含有时区属性,则使用默认值。
例如,如果要将日期的字符串格式为“15/04/2021”转化为R对象,可以使用如下语句:> dmy("15/04/2021")[1] "2021-04-15"在转换时,dmy函数也可以处理包含多个日期字符串的向量。
例如:> dmy(c("01/01/2021", "02/02/2021", "03/03/2021"))[1] "2021-01-01" "2021-02-02" "2021-03-03"需要注意的是,如果在转化过程中遇到无效的日期字符串,dmy函数会返回NA作为结果。
对于日期字符串的转化,dmy函数也可以处理不同格式的日期字符串。
例如,“dd/mm/yy”、“dd-mm-yyyy”、“dd.mm.yy”等格式的字符串都可以被正确转化。
在dmy函数中还可以对转化结果进行一些调整,例如可以通过format参数来自定义输出日期的格式。
如果想要输出的日期格式为“yyyy-mm-dd”,可以使用如下代码:> format(dmy("15/04/2021"), "%Y-%m-%d")[1] "2021-04-15"当然,还有许多其他调整日期格式的方式,读者可以在R官方文档中查找相应函数。
R 语言时间序列中文教程2R 语言时间序列中文教程2012特别声明:R 语言是免费语言,其代码不带任何质量保证,使用 R 语言所产生的后果由使用者负全责。
前言R 语言是一种数据分析语言,它是科学的免费的数据分析语言,是凝聚了众多研究 人员心血的成熟的使用范围广泛全面的语言,也是学习者能较快受益的语言。
在 R 语言出现之前,数据分析的编程语言是 SAS。
当时 SAS 的功能比较有限。
在贝尔 实验室里,有一群科学家讨论提到,他们研究过程中需要用到数据分析软件。
SAS 的局 限也限制了他们的研究。
于是他们想,我们贝尔实验室的研究历史要比 SAS 长好几倍, 技术力量也比 SAS 强好几倍,且贝尔实验室里并不缺乏训练有素的专业编程人员,那 么,我们贝尔实验室为什么不自己编写数据分析语言,来满足我们应用中所需要的特 殊要求呢?于是,贝尔实验室研究出了 S-PLUS 语言。
后来,新西兰奥克兰大学的两位教授非 常青睐 S-PLUS 的广泛性能。
他们决定重新编写与 S-PLUS 相似的语言,并且使之免费, 提供给全世界所有相关研究人员使用。
于是,在这两位教授努力下,一种叫做 R 的语 言在奥克兰大学诞生了。
R 基本上是 S-PLUS 的翻版,但 R 是免费的语言,所有编程研究人员都可以对 R 语 言做出贡献,且他们已经将大量研究成果写成了 R 命令或脚本,因而 R 语言的功能比 较强大,比较全面。
研究人员可免费使用 R 语言,可通过阅读 R 语言脚本源代码,学习其他人的研究 成果。
笔者曾有幸在奥克兰大学受过几年熏陶,曾经向一位统计系的老师提请教过一 个数据模拟方面的问题。
那位老师只用一行 R 语句就解答了。
R 语言的强大功能非常令 人惊讶。
为了进一步推广 R 语言,为了方便更多研究人员学习使用 R 语言,我们收集了 R 语言时间序列分析实例,以供大家了解和学习使用。
当然,这是非常简单的模仿练习, 具体操作是,用复制粘贴把本材料中 R 代码放入 R 的编程环境;材料中蓝色背景的内 容是相关代码和相应输出结果。
R语言格式化数字和字符串format函数数字和字符串可以使用 format()函数的格式化为特定样式。
语法format()函数的基本语法是:format(x, digits, nsmall,scientific,width,justify = c("left", "right", "centre", "none"))以下是所使用的参数的说明:•x - 为向量输入•digits - 是显示总位数•nsmall - 是最小位数的小数点右边•scientific - 设置为TRUE,则显示科学记数法•width - 指示要通过填充空白在开始时显示的最小宽度•justify - 是字符串显示在左边,右边或中心示例# Total number of digits displayed. Last digit rounded off.result <- format(23.123456789, digits = 9)print(result)# Display numbers in scientific notation.result <- format(c(6, 13.14521), scientific = TRUE)print(result)# The minimum number of digits to the right of the decimal point.result <- format(23.47, nsmall = 5)print(result)# Format treats everything as a string.result <- format(6)print(result)# Numbers are padded with blank in the beginning for width. result <- format(13.7, width = 6)print(result)# Left justify strings.result <- format("Hello",width = 8, justify = "l")print(result)# Justfy string with center.result <- format("Hello",width = 8, justify = "c")print(result)当我们上面的代码执行时,它产生以下结果:[1] "23.1234568"[1] "6.000000e+00" "1.314521e+01"[1] "23.47000"[1] "6"[1] " 13.7"[1] "Hello "[1] " Hello "。
R语⾔时间序列中时间年、⽉、季、⽇的处理操作1、年pt<-ts(p, freq = 1, start = 2011)2、⽉pt<-ts(p,frequency=12,start=c(2011,1))frequency=12表⽰以⽉份为单位,start 表⽰时间开始点,start=c(2011,1) 表⽰从2011年1⽉开始3、季度pt <- ts(p, frequency = 4, start = c(2011, 1))4、天pt<-ts(p,frequency=7,start=c(2011,1))⽤ts(p,frequency=365,start=(2011,1)) 也可以,但是这个是没有按星期对齐补充:R语⾔:ts() 时间序列的建⽴ts() 函数:通过⼀向量或者矩阵创建⼀个⼀元的或多元的时间序列(time series),为ts型对象。
调⽤格式:ts(data = NA, start = 1, end = numeric(0), frequency = 1, deltat = 1, ts.eps = getOption("ts.eps"), class, names)说明:data⼀个向量或者矩阵start第⼀个观测值的时间,为⼀个数字或者是⼀个由两个整数构成的向量end最后⼀个观测值的时间,指定⽅法和start相同frequency单位时间内观测值的频数(频率)deltat两个观测值间的时间间隔。
frequency和deltat必须并且只能给定其中⼀个ts.eps序列之间的误差限,如果序列之间的频率差异⼩于ts.eps,则认为这些序列的频率相等class对象的类型。
⼀元序列的缺省值是“ts”,多元序列的缺省值是c(“mts”,“ts”)names⼀个字符型向量,给出多元序列中每个⼀元序列的名称,缺省data中每列数据的名称或者Series 1,Series 2,。
R语⾔-数据预处理⼀、⽇期时间、字符串的处理⽇期Date: ⽇期类,年与⽇POSIXct: ⽇期时间类,精确到秒,⽤数字表⽰POSIXlt: ⽇期时间类,精确到秒,⽤列表表⽰Sys.date(), date(), difftime(), ISOdate(), ISOdatetime()#得到当前⽇期时间(d1=Sys.Date()) #⽇期年⽉⽇(d3=Sys.time()) #时间年⽉⽇时分秒通过format输出指定格式的时间(d2=date()) #⽇期和时间年⽉⽇时分秒 "Fri Aug 20 11:11:00 1999"myDate=as.Date('2007-08-09')class(myDate) #Datemode(myDate) #numeric#⽇期转字符串as.character(myDate)birDay=c('01/05/1986','08/11/1976') #dates=as.Date(birDay,'%m/%d/%Y') #向量化运算,对向量进⾏转换dates# %d 天 (01~31)# %a 缩写星期(Mon)# %A 星期(Monday)# %m ⽉份(00~12)# %b 缩写的⽉份(Jan)# %B ⽉份(January)# %y 年份(07)# %Y 年份(2007)# %H 时# %M 分#得到当前⽇期时间(d1=Sys.Date()) #⽇期年⽉⽇(d3=Sys.time()) #时间年⽉⽇时分秒通过format输出指定格式的时间(d2=date()) #⽇期和时间年⽉⽇时分秒 "Fri Aug 20 11:11:00 1999"myDate=as.Date('2007-08-09')class(myDate) #Datemode(myDate) #numeric#⽇期转字符串as.character(myDate)birDay=c('01/05/1986','08/11/1976') #dates=as.Date(birDay,'%m/%d/%Y') #向量化运算,对向量进⾏转换dates# %d 天 (01~31)# %a 缩写星期(Mon)# %A 星期(Monday)# %m ⽉份(00~12)# %b 缩写的⽉份(Jan)# %B ⽉份(January)# %y 年份(07)# %Y 年份(2007)# %H 时# %M 分# %S 秒td=Sys.Date()format(td,format='%B %d %Y %s')format(td,format='%A,%a ')format(Sys.time(), '%H %h %M %S %s')#⽇期转换成数字as.integer(Sys.Date()) #⾃1970年1⽉1号⾄今的天数as.integer(as.Date('1970-1-1')) #0as.integer(as.Date('1970-1-2')) #1sdate=as.Date('2004-10-01')edate=as.Date('2010-10-22')days=edate-sdatedays #时间类型相互减,结果显⽰相差的天数ws=difftime(Sys.Date(),as.Date('1956-10-12'),units='weeks') #可以指定单位#把年⽉⽇拼成⽇期(d=ISOdate(2011,10,2));class(d) #ISOdate 的结果是POSIXctas.Date(ISOdate(2011,10,2)) #将结果转换为DateISOdate(2011,2,30) #不存在的⽇期结果为NA#批量转换成⽇期years=c(2010,2011,2012,2013,2014,2015)months=1days=c(15,20,21,19,30,3)as.Date(ISOdate(years,months,days))#提取⽇期时间的⼀部分p=as.POSIXlt(Sys.Date())p=as.POSIXlt(Sys.time())Sys.Date()Sys.time()p$year 1900 #年份需要加1900p$mon 1 #⽉份需要加1p$mdayp$hourp$minp$sec#字符串x='hello\rwold\n'cat(x) #woldo hello遇到\r光标移到头接着打印wold覆盖了之前的hell变成woldo print(x) ##字符串长度nchar(x) #字符串长度length(x) #1 向量中元素的个数#字符串拼接board=paste('b',1:4,sep='-') #"b-1" "b-2" "b-3" "b-4"boardmm=paste('mm',1:3,sep='-') #"mm-1" "mm-2" "mm-3"mmouter(board,mm,paste,sep=':') #向量的外积#[,1] [,2] [,3]#[1,] "b-1:mm-1" "b-1:mm-2" "b-1:mm-3"#[2,] "b-2:mm-1" "b-2:mm-2" "b-2:mm-3"#[3,] "b-3:mm-1" "b-3:mm-2" "b-3:mm-3"#[4,] "b-4:mm-1" "b-4:mm-2" "b-4:mm-3"#拆分提取boardsubstr(board,3,3) #⼦串strsplit(board,'-',fixed=T) #拆分#修改sub('-','.',board,fixed=T) #修改指定字符boardmm #"mm-1" "mm-2" "mm-3"sub('m','p',mm) #替换第⼀个匹配项 "pm-1" "pm-2" "pm-3"gsub('m','p',mm) #替换全部匹配项 "pp-1" "pp-2" "pp-3"#查找mm=c(mm, 'mm4') #"mm-1" "mm-2" "mm-3" "mm4"mmgrep('-',mm) #1 2 3 向量中1,2,3包含'-'regexpr('-',mm) #匹配成功会返回位置信息,没有找到则返回-1⼆、数据预处理保证数据质量准确性完整性⼀致性冗余性时效性...1、提取有效数据,需要业务⼈员配合(主观),及相关的技术⼿段保障2、了解数据定义,统⼀对数据定义的理解...数据集成 : 对多数据源进⾏整合数据转换 :数据清洗 : 异常数据,缺失数据数据约简 : 提炼,⾏,列三、集成通过merge对数据进⾏集成#数据集成#数据集成#merge pylr::join (包::函数)(customer = data.frame(Id=c(1:6),State=c(rep("北京",3),rep("上海",3))))(ol = data.frame(Id=c(1,4,6,7),Product=c('IPhone','Vixo','mi','Note2')))merge(customer,ol,by=('Id')) #inner joinmerge(customer,ol,by=('Id'),all=T) # full joinmerge(customer,ol,by=('Id'),all.x=T) # left outer join 左链接,左边数据都在merge(customer,ol,by=('Id'),all.y=T) # right outer join 右链接,右边数据都在#union 去重在df1 和df2 有相同的列名称下(df1=data.frame(id=seq(0,by=3,length=5),name=paste('Zhang',seq(0,by=3,length=5)))) (df2=data.frame(id=seq(0,by=4,length=4),name=paste('Zhang',seq(0,by=4,length=4)))) rbind(df1,df2)merge(df1,df2,all=T) #去重,不使⽤bymerge(df1,df2,by=('id')) #重名的列会被更改显⽰四、数据转换构造属性规范化(极差化、标准化)离散化改善分布。
标签: R 日期格式日期差代码时间处理分类:目录(?)[+]R语言与格式、日期格式、格式转化20160216 22:12 1624人阅读 评论(0) 收藏 举报版权声明:本文为博主原创文章,未经博主允许不得转载。
R语言的基础包中提供了两种类型的时间数据,一类是Date日期数据,它不包括时间和时区信息,另一类是POSIXct/POSIXlt类型数据,其中包括了日期、时间和时区信息。
基本总结如下:日期data,存储的是天;时间POSIXct 存储的是秒,POSIXlt 打散,年月日不同;日期-时间=不可运算。
一般来讲,R语言中建立时序数据是通过字符型转化而来,但由于时序数据形式多样,而且R中存贮格式也是五花八门,例如Date/ts/xts/zoo/tis/fts等等。
lubridate包,timeDate包,都有用。
常见的格式:as.numeric 转化为数值型as.logic 转化为逻辑型plex 转化为复数型as.character 转化为字符型as.array 转化为数组as.data.frame 转化为数据框在data.frame中,是可以实现数据集重命名的,比如data.frame(x=iris,y=cars),也可以实现横向、纵向重命名,data.frame(x=iris,y=cars,s=iris)——————————————————————————————————————————时间的标准格式mydate = as.POSIXlt(’2005-4-19 7:01:00’)names(mydate)默认情况下,日期之前是以/或者-进行分隔,而时间则以:进行分隔;输入的标准格式为:日期 时间(日期与时间中间有空隔隔开)R的数据读入与基础(1)(20)[plain] view plain copy print ?01. d<‐as.character(z) #将数值向量z<‐(0:9)转化为字符向量c("0", "1", "2", ..., "9")。
02. as.integer(d) #将d 转化为数值向量03. e <‐ numeric() #产生一个numeric 型的空向量e04. a=data.frame(a) #变成R 的数据框05. factor() #变成因子 可以用levels()来看因子个数时间的标准格式为:时:分 或者 时:分:秒;如果输入的格式不是标准格式,则同样需要使用strptime函数,利用format来进行指定。
——————————————————————————————————————————一、日期型数据——data1、as.Data函数在R中自带的日期形式为:as.Date();以数值形式存储;对于规则的格式,则不需要用format指定格式;如果输入的格式不规则,可以通过format指定的格式读入;其中以1970-01-01定义为第0天,之后的年份会以距离这天来计算。
代码解读:unclass可以将日期变成以天来计数,比如1970-02-01输出的31,就代表着距离1970-01-01有31天。
as.data中的参数格式:年-月-日或者年/月/日;如果不是以上二种格式,则会提供错误——错误于charTo按照Date(x) : 字符串的格式不够标准明确;例如这样的数据格式,就常常报错。
19:15.显示为:2011/1/1 19:152、%d%y%m-基本格式格式意义%d月份中当的天数%m月份,以数字形式表示%b月份,缩写%B月份,完整的月份名,指英文%y 年份,以二位数字表示[html] view plain copy print ?01.> x <‐as.Date ("1970‐01‐01") 02.> unclass(x) 03.[1] 0 04.> 05.> unclass(as.Date("1970‐02‐01")) #19700201代表第31天 06. [1] 31[plain] view plain copy print ?01.as.Date('23‐2013‐1',format='%d‐%Y‐%m') 02.#其中这个%d%Y 可以节选其中一个 03. #%Y%y 大写代表年份四位数,小写代表年份二位数,要注意%Y 年份,以四位数字表示#其它日期相关函数weekdays()取日期对象所处的周几;months()取日期对象的月份;quarters()取日期对象的季度。
————————————————————————————————————————二、时间型——POSIXct与POSIXltPOSIXct 是以1970年1月1号开始的以秒进行存储,如果是负数,则是1970-01-01年以前;正数则是1970年以后。
POSIXlt 是以列表的形式存储:年、月、日、时、分、秒,作用是打散时间;1、POSIXlt 格式主要特点:作用是打散时间,把时间分成年、月、日、时、分、秒,并进行存储。
可以作为时间筛选的一种。
代码解读:unclass将时间打散。
[html] view plain copy print ?01. > today <‐Sys.time ()02. > unclass(as.POSIXlt(today))03. $sec04. [1] 53.2715105.06. $min07. [1] 3808.09. $hour10. [1] 2011.12. $mday13. [1] 614.15. $mon16. [1] 517.18. $year19. [1] 11620.21. $wday22. [1] 123.24. $yday25. [1] 15726.27. $isdst28. [1] 029.30. $zone31. [1] "CST"32.33. $gmtoff34. [1] 2880035.36. attr(,"tzone")37. [1] "" "CST" "CDT"2、POSIXct 格式主要特点:以秒进行存储。
解读:比如今天,unclass之后,代表今天2016-06-06距离1970-01-01为1465216942秒。
#GMT代表时区,德意志时间,CST也代表时区————————————————————————————————————————三、时间运算1、基本运算函数Sys.Date() #字符串类型typeof(Sys.Date()) #系统日期类型2、直接加减相同的格式才能相互减,不能加。
二进列的+法对"Date"、"POSIXt"对象不适用。
相互减之后,一般结果输出的天数。
3、difftime函数——计算时差不同格式的时间都可以进行运算。
并且可以实现的是计算两个时间间隔:秒、分钟、小时、天、星期。
但是不能计算年、月、季度的时间差。
[html] view plain copy print ?01. > today <‐Sys.time ()02. > today03. [1] "2016‐06‐06 20:42:22 CST"04. > unclass(as.POSIXct(today))05. [1] 1465216942[html] view plain copy print ?01. > as.Date("2011‐07‐01") ‐ as.Date(today)02. Time difference of ‐1802 days03. > as.POSIXct(today)‐as.POSIXct(as.Date("2012‐10‐25 01:00:00"))04. Time difference of 1320.529 days05. > as.POSIXlt(today)‐as.POSIXlt(as.Date("2012‐10‐25 01:00:00"))06. Time difference of 1320.529 days[html] view plain copy print ?01. gtd <‐ as.Date("2011‐07‐01")02. difftime(as.POSIXct(today), gtd, units ="hours") #只能计算日期差,还可以是“secs”, “mins”, “hours”, “days”4、format函数——提取关键信息format函数可以将时间格式,调节成指定时间样式。
format(today,format="%Y")其中的format可以自由调节,获取你想要的时间信息。
并且format函数可以识别as.Data型以及POSIXct与POSIXlt型,将其日期进行提取与之后要讨论的split类型。
但是format出来的时间不能直接做减法,会出现错误: non-numeric argument to binary operator5、strptime函数该函数是将字符型时间转化为 "POSIXlt" 和"POSIXct"两类。
跟format比较相似。
strptime之后的时间是可以直接做减法,因为直接是"POSIXlt" 和"POSIXct"格式了。
————————————————————————————————————————四、遇见的问题1、常常报错。
错误于charTo按照Date(x) : 字符串的格式不够标准明确。
这个错误经常出现,我本来的数据格式是19:15.后来换成“2011/1/1”这样的就不会报错了,需要数据库自动改变。
[html] view plain copy print ?01. > today <‐Sys.time ()02. > format(today,format ="%B‐%d‐%Y")03. [1] "六月‐06‐2016"[html] view plain copy print ?01. > today <‐Sys.time ()02. > format(as.Date(today),format ="%Y")03. [1] "2016"04. > format(as.POSIXlt(today),format ="%Y")05. [1] "2016"06. > format(as.POSIXct(today),format ="%Y")07. [1] "2016"[html] view plain copy print ?01. > strptime("2006‐01‐08 10:07:52", "%Y‐%m‐%d")‐strptime("2006‐01‐15 10:07:52", "%Y‐%m‐%d")02. Time difference of ‐7 days03. > class(strptime("2006‐01‐08 10:07:52", "%Y‐%m‐%d"))04. [1] "POSIXlt" "POSIXt"2、excel另存为csv时发生的错误。