IAR堆栈溢出问题
- 格式:docx
- 大小:341.03 KB
- 文档页数:3

堆栈溢出技术从入门到精通本讲的预备知识:首先你应该了解intel汇编语言,熟悉寄存器的组成和功能。
你必须有堆栈和存储分配方面的基础知识,有关这方面的计算机书籍很多,我将只是简单阐述原理,着重在应用。
其次,你应该了解linux,本讲中我们的例子将在linux上开发。
1:首先复习一下基础知识。
从物理上讲,堆栈是就是一段连续分配的内存空间。
在一个程序中,会声明各种变量。
静态全局变量是位于数据段并且在程序开始运行的时候被加载。
而程序的动态的局部变量则分配在堆栈里面。
从操作上来讲,堆栈是一个先入后出的队列。
他的生长方向与内存的生长方向正好相反。
我们规定内存的生长方向为向上,则栈的生长方向为向下。
压栈的操作push=ESP-4,出栈的操作是pop=ESP+4.换句话说,堆栈中老的值,其内存地址,反而比新的值要大。
请牢牢记住这一点,因为这是堆栈溢出的基本理论依据。
在一次函数调用中,堆栈中将被依次压入:参数,返回地址,EBP。
如果函数有局部变量,接下来,就在堆栈中开辟相应的空间以构造变量。
函数执行结束,这些局部变量的内容将被丢失。
但是不被清除。
在函数返回的时候,弹出EBP,恢复堆栈到函数调用的地址,弹出返回地址到EIP以继续执行程序。
在C语言程序中,参数的压栈顺序是反向的。
比如func(a,b,c)。
在参数入栈的时候,是:先压c,再压b,最后a.在取参数的时候,由于栈的先入后出,先取栈顶的a,再取b,最后取c。
(PS:如果你看不懂上面这段概述,请你去看以看关于堆栈的书籍,一般的汇编语言书籍都会详细的讨论堆栈,必须弄懂它,你才能进行下面的学习)2:好了,继续,让我们来看一看什么是堆栈溢出。
2.1:运行时的堆栈分配堆栈溢出就是不顾堆栈中分配的局部数据块大小,向该数据块写入了过多的数据,导致数据越界。
结果覆盖了老的堆栈数据。
比如有下面一段程序:程序一:#include <stdio.h>int main ( ){char name[8];printf("Please type your name: ");gets(name);printf("Hello, %s!", name);return 0;}编译并且执行,我们输入ipxodi,就会输出Hello,ipxodi!。

如何优化单片机中的C程序堆栈溢出:在调试程序的时候有事会碰到堆栈溢出的情况,堆栈为什么会溢出呢,个人总结主要有以下几点:a、是否有修改堆栈指针;c语言编写者一般不会主动修改堆栈指针的,除非在特殊情况下才会涉及到与此相关的操作,如在扩展区独立开辟一段存储空间用于压栈时数据的存储区。
b、是否嵌套的数据保护的内容超过堆栈;此种情况发生的几率比较多,个人估计占到80%左右,这种情况就是RAM本就不是很充足,此时又发生了中断嵌套,上一个中断占用的现场保护空间还没有释放,另一个中断又要重新占用大量空间进行现场数据的保存。
这样可定会造成空间不够用,堆栈溢出是很显然的。
建议避免中断嵌套(方法1:可以再优先级低的中断中先关掉优先级高的中断,这或许会影响程序的执行效果。
方法2:换用RAM 比较大的IC或扩展RAM,这种方法要提高成本。
)c、程序中进行的算术运算比较多计算机最擅长的运算就是加法运算,在程序中弄了好多浮点运算、求余运算、除法运算,而且数据量很大,运算过程中是要占用很多空间的,建议能优化算术运算的尽量优化,下面介绍如何优化程序,个人总结加上网上搜索。
优化程序:1、选择合适的算法和数据结构应该熟悉算法语言,知道各种算法的优缺点,具体资料请参见相应的参考资料,有很多计算机书籍上都有介绍。
将比较慢的顺序查找法用较快的二分查找或乱序查找法代替,插入排序或冒泡排序法用快速排序、合并排序或根排序代替,都可以大大提高程序执行的效率。
.选择一种合适的数据结构也很重要,比如你在一堆随机存放的数中使用了大量的插入和删除指令,那使用链表要快得多。
数组与指针语句具有十分密码的关系,一般来说,指针比较灵活简洁,而数组则比较直观,容易理解。
对于大部分的编译器,使用指针比使用数组生成的代码更短,执行效率更高。
但是在Keil中则相反,使用数组比使用的指针生成的代码更短。
2、使用尽量小的数据类型能够使用字符型(char)定义的变量,就不要使用整型(int)变量来定义;能够使用整型变量定义的变量就不要用长整型(long int),能不使用浮点型(float)变量就不要使用浮点型变量。

使用IAR时遇到的一些Error、Waring/sendoc/blog作为菜虫,在使用IAR的时候编写CC2430、、Z-Stack2006程序会遇到如下一些错误,当然随着学习的深入,我会持续更新。
1Q:Error[e16]: Segment XDATA_Z (size: 0x19a1 align: 0) is too long for segment definition. At least 0xe4c more bytesneeded. The problem occurred while processing the segment placement command"-Z(XDATA)XDATA_N,XDATA_Z,XDATA_I=_XDATA_START-_XDATA_END", where at the moment ofplacement the available memory ranges were "XDATA:f1ff-fd53"Reserved ranges relevant to this placement:XDATA:f000-f1fe XSTACKXDATA:f1ff-fd53 XDATA_NBIT:0-7 BREGBIT:80-97 SFR_ANBIT:a8-af SFR_ANBIT:b8-c7 SFR_ANBIT:d8-df SFR_ANBIT:e8-ef SFR_ANA:其实这个问题并不是你的程序本身有问题,主要是因为你编写的程序太大了,超出了芯片本身的定义。
今天在群里学习了一招,就是将数组定义到code里,我们看一下例子。
我们定义一个5100个元素的数组,有以下两种方法:mermaid提出的方法是:typedef unsigned char const __code INT8U;extern INT8U shuzi[5100];文晶提出的方法是INT8U code shuzi[5100];这两种方法其实效果是一致的,定义完数组之后,调用的部分就是需要用指针来调用数组里面的数值了。
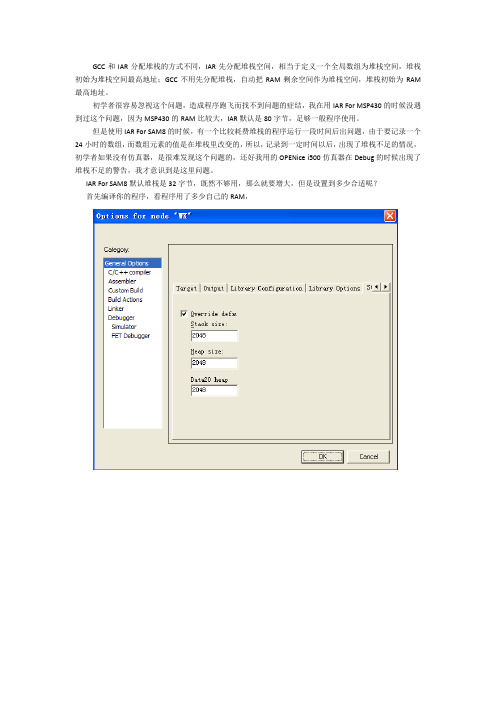
GCC和IAR分配堆栈的方式不同,IAR先分配堆栈空间,相当于定义一个全局数组为堆栈空间,堆栈初始为堆栈空间最高地址;GCC不用先分配堆栈,自动把RAM剩余空间作为堆栈空间,堆栈初始为RAM 最高地址。
初学者很容易忽视这个问题,造成程序跑飞而找不到问题的症结,我在用IAR For MSP430的时候没遇到过这个问题,因为MSP430的RAM比较大,IAR默认是80字节,足够一般程序使用。
但是使用IAR For SAM8的时候,有一个比较耗费堆栈的程序运行一段时间后出问题,由于要记录一个24小时的数组,而数组元素的值是在堆栈里改变的,所以,记录到一定时间以后,出现了堆栈不足的情况,初学者如果没有仿真器,是很难发现这个问题的,还好我用的OPENice i500仿真器在Debug的时候出现了堆栈不足的警告,我才意识到是这里问题。
IAR For SAM8默认堆栈是32字节,既然不够用,那么就要增大,但是设置到多少合适呢?
首先编译你的程序,看程序用了多少自己的RAM,
Data model决定数据大小。

标题: 堆栈溢出系列讲座(1)本文以及以下同系列各文为ipxodi根据alphe one, Taeho Oh 的英文资料所译及整理,你可以任意复制和分发。
序言:通过堆栈溢出来获得root权限是目前使用的相当普遍的一项黑客技术。
事实上这是一个黑客在系统本地已经拥有了一个基本账号后的首选攻击方式。
他也被广泛应用于远程攻击。
通过对daemon进程的堆栈溢出来实现远程获得rootshell的技术,已经被很多实例实现。
在windows系统中,同样存在着堆栈溢出的问题。
而且,随着internet的普及,win系列平台上的internet服务程序越来越多,低水平的win程序就成为你系统上的致命伤。
因为它们同样会被远程堆栈溢出,而且,由于win系统使用者和管理者普遍缺乏安全防范的意识,一台win系统上的堆栈溢出,如果被恶意利用,将导致整个机器被敌人所控制。
进而,可能导致整个局域网落入敌人之手。
本系列讲座将系统的介绍堆栈溢出的机制,原理,应用,以及防范的措施。
希望通过我的讲座,大家可以了解和掌握这项技术。
而且,会自己去寻找堆栈溢出漏洞,以提高系统安全。
堆栈溢出系列讲座入门篇本讲的预备知识:首先你应该了解intel汇编语言,熟悉寄存器的组成和功能。
你必须有堆栈和存储分配方面的基础知识,有关这方面的计算机书籍很多,我将只是简单阐述原理,着重在应用。
其次,你应该了解linux,本讲中我们的例子将在linux上开发。
1:首先复习一下基础知识。
从物理上讲,堆栈是就是一段连续分配的内存空间。
在一个程序中,会声明各种变量。
静态全局变量是位于数据段并且在程序开始运行的时候被加载。
而程序的动态的局部变量则分配在堆栈里面。
从操作上来讲,堆栈是一个先入后出的队列。
他的生长方向与内存的生长方向正好相反。
我们规定内存的生长方向为向上,则栈的生长方向为向下。
压栈的操作push=ESP-4,出栈的操作是pop=ESP+4.换句话说,堆栈中老的值,其内存地址,反而比新的值要大。

通过堆栈溢出来获得root权限是目前使用的相当普遍的一项黑客技术。
事实上这是一个黑客在系统本地已经拥有了一个基本账号后的首选攻击方式。
他也被广泛应用于远程攻击。
通过对daemon进程的堆栈溢出来实现远程获得rootshell的技术,已经被很多实例实现。
在windows系统中,同样存在着堆栈溢出的问题。
而且,随着internet的普及,win系列平台上的internet服务程序越来越多,低水平的win程序就成为你系统上的致命伤。
因为它们同样会被远程堆栈溢出,而且,由于win系统使用者和管理者普遍缺乏安全防范的意识,一台win系统上的堆栈溢出,如果被恶意利用,将导致整个机器被敌人所控制。
进而,可能导致整个局域网落入敌人之手。
本系列讲座将系统的介绍堆栈溢出的机制,原理,应用,以及防范的措施。
希望通过我的讲座,大家可以了解和掌握这项技术。
而且,会自己去寻找堆栈溢出漏洞,以提高系统安全。
堆栈溢出系列讲座入门篇本讲的预备知识:首先你应该了解intel汇编语言,熟悉寄存器的组成和功能。
你必须有堆栈和存储分配方面的基础知识,有关这方面的计算机书籍很多,我将只是简单阐述原理,着重在应用。
其次,你应该了解linux,本讲中我们的例子将在linux上开发。
1:首先复习一下基础知识。
从物理上讲,堆栈是就是一段连续分配的内存空间。
在一个程序中,会声明各种变量。
静态全局变量是位于数据段并且在程序开始运行的时候被加载。
而程序的动态的局部变量则分配在堆栈里面。
从操作上来讲,堆栈是一个先入后出的队列。
他的生长方向与内存的生长方向正好相反。
我们规定内存的生长方向为向上,则栈的生长方向为向下。
压栈的操作push=ESP-4,出栈的操作是pop=ESP+4.换句话说,堆栈中老的值,其内存地址,反而比新的值要大。
请牢牢记住这一点,因为这是堆栈溢出的基本理论依据。
在一次函数调用中,堆栈中将被依次压入:参数,返回地址,EBP。
如果函数有局部变量,接下来,就在堆栈中开辟相应的空间以构造变量。
单片机中的异常处理与故障排除方法总结摘要:单片机是嵌入式系统的核心组成部分,它在各种电子设备中起着至关重要的作用。
然而,在单片机的开发和运行过程中,可能会遇到各种异常和故障情况。
本文总结单片机中常见的异常处理与故障排除方法,旨在帮助开发人员更好地理解和应对这些问题。
1. 异常种类及原因单片机中的异常情况主要包括硬件故障和软件异常两大类。
硬件故障可能由于电压波动、温度过高、电磁干扰等因素导致,例如芯片损坏、外设连接错误等。
而软件异常则主要由于程序编写错误、资源竞争、中断处理不当等原因引起。
2. 异常处理方法2.1 硬件故障处理方法当单片机遭遇硬件故障时,必须从硬件层面进行排查和修复。
首先,检查电源供应情况,确保电源电压稳定,并使用适当的电源滤波电路来减少电压波动。
此外,还要注意外设的正确连接,确保信号线的质量。
其次,使用示波器等仪器来检测时钟信号的频率和占空比,以确保时钟信号的准确传输。
还可以通过温度统计数据来判断是否存在过热问题,并采取相应措施来降低温度。
最后,如果发现单片机芯片损坏,需要更换芯片,并进行相应的焊接和编程操作。
2.2 软件异常处理方法软件异常通常表现为死循环、系统崩溃等情况,为了解决这些问题,可以采取以下方法:首先,通过调试工具(如Keil、IAR等)来定位程序中的错误。
这些工具可以提供单步执行、断点调试等功能,帮助开发人员逐行扫描程序,并查找潜在的错误。
其次,检查程序中的资源竞争问题。
例如,当多个任务同时访问共享资源时,可能会出现数据错乱的情况。
为了解决这个问题,可以使用互斥量或信号量来同步任务之间的访问。
另外,如若发现中断处理有误,可以检查中断优先级和中断服务程序的编写。
确保中断服务程序的执行时间尽可能短,并正确处理各种中断。
最后,对代码进行优化,以提高程序的效率和稳定性。
可以采取合理的数据结构和算法,避免过多的循环和递归操作。
此外,及时释放不再使用的内存空间,以避免内存溢出等问题。
目录1案例描述 (1)2案例分析 (1)3解决过程 (2)4总结 (3)关键词:堆栈溢出,检测摘要:堆栈溢出对于我们软件开发人员来说,最严重的后果是破坏了内存中的指针,及其造成的一系列难查的bug。
对于这种情况,我们应该怎么办。
1 案例描述相信Linux程序员最讨厌的字符串是“Segmentation fault”,而Windows程序员最讨厌的是“C0000005”。
其实本质上是一样的,都是内存访问错误,且八成是错误的指针导致。
指针错误一般分两种,一种是空指针,一种是野指针。
对付空指针,我们不怕,因为即便出现了,偷懒的话,我们都可以不去定位原因,直接加上条件判断保护即可。
对于野指针,产生的原因有两种,一种是自身指针所指内存已销毁,这种好查,找到异常点和free的地方,比较一下就查到原因了。
另一种就是我今天所说的堆栈溢出造成的内存内容被篡改,假如这块内存中保存着程序指针,那么这些指针就“野”了。
堆栈溢出造成的野指针是很悲剧的,就算有dump工具,你也不知道是谁陷害了你的指针。
整个进程中的模块都有嫌疑,你不得不大海捞针似地去盯代码,眼神好的话兴许能揪出bug,运气不好的话可能几个星期都没有进展。
最近我就碰到了这种情况产生的bug。
是一个windows上的程序,跑若干钟头就会崩溃,且通过map文件显示异常出现在一个野指针处。
因为该指针不会在中途销毁创建,所以基本上断定是哪里堆栈溢出了。
在解决这个bug的过程中,我产生了一些对堆栈溢出的思考。
2 案例分析我想到3种有关堆栈溢出的方法:⏹编译器选项Gcc提供了一个编译选项,加入-fstack-protector-all即可实现对堆栈的保护。
但是实际上这个对于我们软件开发人员来说,一点用都没有。
Gcc的堆栈保护实质上是一种软件安全措施,为的是防止黑客恶意篡改函数栈调用黑客代码。
而作为软件开发人员,我们希望,程序崩掉没关系,重要的是我能检测出是哪里的堆栈溢出导致的,这个编译选项显然不起任何作用。
嵌入式软件设计中查找缺陷的几个技巧(上)大部分软件开发项目依靠结合代码检查、结构测试和功能测试来识别软件缺陷。
尽管这些传统技术非常重要,而且能发现大多数软件问题,但它们无法检查出当今复杂系统中的许多共性错误。
本文将介绍如何避免那些隐蔽然而常见的错误,并介绍的几个技巧帮助工程师发现软件中隐藏的错误。
结构测试或白盒测试能有效地发现代码中的逻辑、控制流、计算和数据错误。
这项测试要求对软件的内部工作能够一览无遗(因此称为"白盒"或" 玻璃盒"),以便了解软件结构的详细情况。
它检查每个条件表达式、数学操作、输入和输出。
由于需要测试的细节众多,结构测试每次检查一个软件单元,通常为一个函数或类。
代码审查也使用与实现缺陷和潜在问题查找同样复杂的技术。
与白盒测试一样,审查通常针对软件的各个单元进行,因为一个有效的审查过程要求的是集中而详尽的检查。
与审查和白盒测试不同,功能测试或黑盒测试假设对软件的实现一无所知,它测试由受控输入所驱动的输出。
功能测试由测试人员或开发人员所编写的测试过程组成,它们规定了一组特定程序输入对应的预期程序输出。
测试运行之后,测试人员将实际输出与预期输出进行比较,查找问题。
黑盒测试可以有效地找出未能实现的需求、接口问题、性能问题和程序最常用功能中的错误。
虽然将这些技术结合起来可以找出隐藏在一个特定软件程序中的大部分错误,但它们也有局限。
代码审查和白盒测试每次只针对一小部分代码,忽视了系统的其它部分。
黑盒测试通常将系统作为一个整体来处理,忽视了实现的细节。
一些重要的问题只有在集中考察它们在整个系统内相互作用时的细节才能被发现;传统的方法无法可靠地找出这些问题。
必须整体地检查软件系统,查找具体问题的特定原因。
由于详尽彻底地分析程序中的每个细节和它与代码中所有其它部分之间的相互作用通常是不大可能的,因此分析应该针对程序中已经知道可能导致问题的特定方面。
本文将探讨其中三个潜在的问题领域:* 堆栈溢出* 竞争条件* 死锁读者可在网上阅读本文的第二部分,它将探讨下列问题:* 时序问题* 可重入条件在采用多任务实时设计技术的系统中,以上所有问题都相当普遍。
GCC和IAR分配堆栈的方式不同,IAR先分配堆栈空间,相当于定义一个全局数组为堆栈空间,堆栈初始为堆栈空间最高地址;GCC不用先分配堆栈,自动把RAM剩余空间作为堆栈空间,堆栈初始为RAM 最高地址。
初学者很容易忽视这个问题,造成程序跑飞而找不到问题的症结,我在用IAR For MSP430的时候没遇到过这个问题,因为MSP430的RAM比较大,IAR默认是80字节,足够一般程序使用。
但是使用IAR For SAM8的时候,有一个比较耗费堆栈的程序运行一段时间后出问题,由于要记录一个24小时的数组,而数组元素的值是在堆栈里改变的,所以,记录到一定时间以后,出现了堆栈不足的情况,初学者如果没有仿真器,是很难发现这个问题的,还好我用的OPENice i500仿真器在Debug的时候出现了堆栈不足的警告,我才意识到是这里问题。
IAR For SAM8默认堆栈是32字节,既然不够用,那么就要增大,但是设置到多少合适呢?
首先编译你的程序,看程序用了多少自己的RAM,
Data model决定数据大小。