编译原理,陈意云 ,课后解答3
- 格式:ppt
- 大小:110.00 KB
- 文档页数:12


《编译原理》课后习题答案第三章第3 章文法和语言第1 题文法G=({A,B,S},{a,b,c},P,S)其中P 为:S→Ac|aBA→abB→bc写出L(G[S])的全部元素。
答案:L(G[S])={abc}第2 题文法G[N]为:N→D|NDD→0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?答案:G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D或者:允许0 开头的非负整数?第3题为只包含数字、加号和减号的表达式,例如9-2+5,3-1,7等构造一个文法。
答案:G[S]:S->S+D|S-D|DD->0|1|2|3|4|5|6|7|8|9第4 题已知文法G[Z]:Z→aZb|ab写出L(G[Z])的全部元素。
盛威网()专业的计算机学习网站 1《编译原理》课后习题答案第三章答案:Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={anbn|n>=1}第5 题写一文法,使其语言是偶正整数的集合。
要求:(1) 允许0 打头;(2)不允许0 打头。
答案:(1)允许0 开头的偶正整数集合的文法E→NT|DT→NT|DN→D|1|3|5|7|9D→0|2|4|6|8(2)不允许0 开头的偶正整数集合的文法E→NT|DT→FT|GN→D|1|3|5|7|9D→2|4|6|8F→N|0G→D|0第6 题已知文法G:<表达式>::=<项>|<表达式>+<项><项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i试给出下述表达式的推导及语法树。
(5)i+(i+i)(6)i+i*i盛威网()专业的计算机学习网站 2 《编译原理》课后习题答案第三章答案:<表达式><表达式> + <项><因子><表达式><表达式> + <项><因子>i<项><因子>i<项><因子>i( )(5) <表达式>=><表达式>+<项>=><表达式>+<因子>=><表达式>+(<表达式>)=><表达式>+(<表达式>+<项>)=><表达式>+(<表达式>+<因子>)=><表达式>+(<表达式>+i)=><表达式>+(<项>+i)=><表达式>+(<因子>+i)=><表达式>+(i+i)=><项>+(i+i)=><因子>+(i+i)=>i+(i+i)<表达式><表达式> + <项><项> * <因子><因子> i<项><因子>ii(6) <表达式>=><表达式>+<项>=><表达式>+<项>*<因子>=><表达式>+<项>*i=><表达式>+<因子>*i=><表达式>+i*i=><项>+i*i=><因子>+i*i=>i+i*i盛威网()专业的计算机学习网站 3《编译原理》课后习题答案第三章第7 题证明下述文法G[〈表达式〉]是二义的。



第一章编译程序概述1.1什么是编译程序编译程序是现代计算机系统的基本组成部分之一,而且多 数计算机系统都含有不止一个高级语言的编译程序。
对有些高 级语言甚至配置了几个不同性能的编译程序。
1.2编译过程概述和编译程序的结构编译程序完成从源程序到目标程序的翻译工作,是一个复 杂的整体的过程。
从概念上来讲,一个编译程序的整个工作过 程是划分成阶段进行的,每个阶段将源程序的一种表示形式转 换成另一种表示形式,各个阶段进行的操作在逻辑上是紧密连 接在一起的。
一般一个编译过程划分成词法分析、语法分析、 语义分析、中间代码生成,代码优化和目标代码生成六个阶段,这是一种典型的划分方法。
事实上,某些阶段可能组合在一起, 这些阶段间的源程序的中间表示形式就没必要构造岀来了。
我 们将分别介绍各阶段的任务。
另外两个重要的工作:表格管理 和岀错处理与上述六个阶段都有联系。
编译过程中源程序的各 种信息被保留在种种不同的表格里,编译各阶段的工作都涉及 到构造、查找或更新有关的表格,因此需要有表格管理的工作; 如果编译过程中发现源程序有错误,编译程序应报告错误的性 质和错误发生的地点,并且将错误所造成的影响限制在尽可能 小的范围内,使得源程序的其余部分能继续被编译下去,有些 编译程序还能自动校正错误, 这些工作称之为岀错处理。
图1.3表示了编译的各个阶段。
图1.3编译的各个阶段它不生成目标代码,它每遇到一个语句,就要对这个语句进行 分析以决定语句的含义,执行相应的动作。
右面的图示意了它 的工作机理第二章:PL/O 编译程序问答第1题 PL/0语言允许过程嵌套定义和递归调用,试问 它的编译程序如何解决运行时的存储管理。
答:PL/0语言允许过程嵌套定义和递归调用,它的编译程序在运行时采用了栈式动态存储管理。
(数组CODE 存放的只读目 标程序,它在运行时不改变。
)运行时的数据区S 是由解释程序 定义的一维整型数组,解释执行时对数据空间S 的管理遵循后进先岀规则,当每个过程(包括主程序)被调用时,才分配数据 空间,退出过程时,则所分配的数据空间被释放。
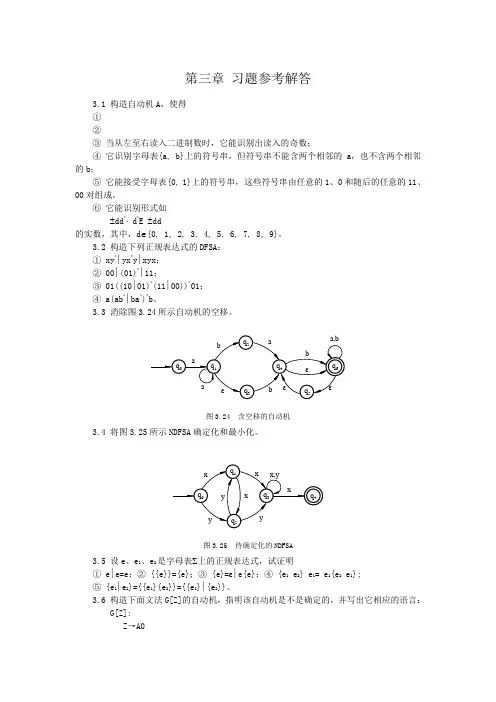
第三章习题参考解答3.1 构造自动机A,使得①②③当从左至右读入二进制数时,它能识别出读入的奇数;④它识别字母表{a, b}上的符号串,但符号串不能含两个相邻的a,也不含两个相邻的b;⑤它能接受字母表{0, 1}上的符号串,这些符号串由任意的1、0和随后的任意的11、00对组成。
⑥它能识别形式如±dd*⋅ d*E ±dd的实数,其中,d∈{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}。
3.2 构造下列正规表达式的DFSA:① xy*∣yx*y∣xyx;② 00∣(01)*∣11;③ 01((10∣01)*(11∣00))*01;④ a(ab*∣ba*)*b。
3.3 消除图3.24所示自动机的空移。
图3.24 含空移的自动机3.4 将图3.25所示NDFSA确定化和最小化。
图3.25 待确定化的NDFSA3.5 设e、e1、e2是字母表∑上的正规表达式,试证明① e∣e=e;② {{e}}={e};③ {e}=ε∣e{e};④ {e1 e2} e1= e1{e2 e1};⑤ {e1∣e2}={{e1}{e2}}={{e1}∣{e2}}。
3.6 构造下面文法G[Z]的自动机,指明该自动机是不是确定的,并写出它相应的语言: G[Z]:Z→A0A→A0∣Z1∣03.7 设NDFSA M=({x, y},{a, b},f, x, {y}), 其中,f(x, a)={x, y}, f(x, b)={y}, f(y, a)=∅, f(y, b)={x, y}。
试对此NDFSA 确定化。
3.8 设文法G[〈单词〉]:〈单词〉→〈标识符〉∣〈无符号整数〉 〈标识符〉→〈字母〉∣〈标识符〉〈字母〉∣〈标识符〉〈数字〉 〈无符号整数〉→〈数字〉∣〈无符号整数〉〈数字〉 〈字母〉→a ∣b 〈数字〉→1∣2试写出相应的有限自动机和状态图。
3.9 图3.29所示的是一个NDFSA A ,试构造一个正规文法G ,使得L(G)= L(A)。

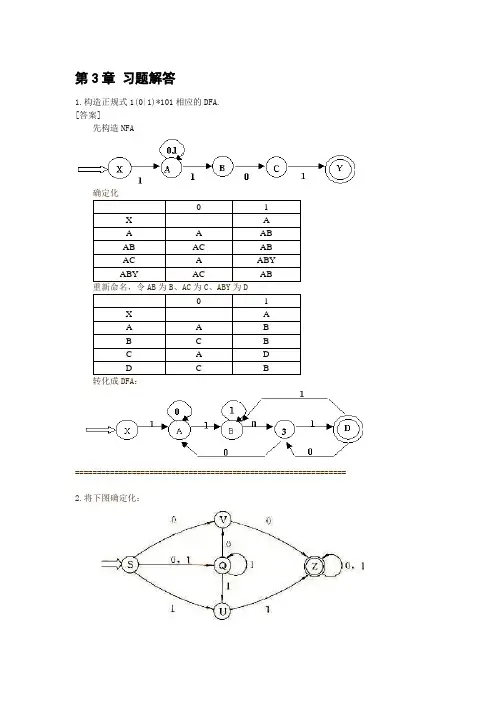
第3章习题解答1.构造正规式1(0|1)*101相应的DFA.[答案]先构造NFA确定化0 1X AA A ABAB AC ABAC A ABYABY AC AB重新命名,令AB为B、AC为C、ABY为D0 1X AA A BB C BC A DD C B转化成DFA:============================================================== 2.将下图确定化:[答案]0 1S VQ QUVQ VZ QUQU V QUZVZ Z ZV ZQUZ VZ QUZZ Z Z重新命名,令VQ为A、QU为B、VZ为C、V为D、QUZ为E、Z为F。
0 1S A BA C BB D EC F FD FE C EF F F转化为DFA:================================================================ 3.把下图最小化:[答案](1)初始分划得Π0:终态组{0},非终态组{1,2,3,4,5}对非终态组进行审查:{1,2,3,4,5}a {0,1,3,5}而{0,1,3,5}既不属于{0},也不属于{1,2,3,4,5} ∵{4} a {0},所以得新分划 (2)Π1:{0},{4},{1,2,3,5} 对{1,2,3,5}进行审查: ∵{1,5} b {4}{2,3} b {1,2,3,5},故得新分划 (3)Π2:{0},{4},{1, 5},{2,3} {1, 5} a {1, 5}{2,3} a {1,3},故状态2和状态3不等价,得新分划 (3)Π3:{0},{2},{3},{4},{1, 5} 这是最后分划了 (4)最小DFA :======================================= 4.构造一个DFA ,它接收Σ={0,1}上所有满足如下条件的字符串:每个1都有0直接跟在右边。

第一章1.典型的编译程序在逻辑功能上由哪几部分组成?答:编译程序主要由以下几个部分组成:词法分析、语法分析、语义分析、中间代码生成、中间代码优化、目标代码生成、错误处理、表格管理。
2. 实现编译程序的主要方法有哪些?答:主要有:转换法、移植法、自展法、自动生成法。
3. 将用户使用高级语言编写的程序翻译为可直接执行的机器语言程序有哪几种主要的方式?答:编译法、解释法。
4. 编译方式和解释方式的根本区别是什么?答:编译方式:是将源程序经编译得到可执行文件后,就可脱离源程序和编译程序单独执行,所以编译方式的效率高,执行速度快;解释方式:在执行时,必须源程序和解释程序同时参与才能运行,其不产生可执行程序文件,效率低,执行速度慢。
第二章1.乔姆斯基文法体系中将文法分为哪几类?文法的分类同程序设计语言的设计与实现关系如何?答:1)0型文法、1型文法、2型文法、3型文法。
2)2. 写一个文法,使其语言是偶整数的集合,每个偶整数不以0为前导。
答:Z→SME | BS→1|2|3|4|5|6|7|8|9M→ε | D | MDD→0|SB→2|4|6|8E→0|B3. 设文法G为:N→ D|NDD→ 0|1|2|3|4|5|6|7|8|9请给出句子123、301和75431的最右推导和最左推导。
答:N⇒ND⇒N3⇒ND3⇒N23⇒D23⇒123N⇒ND⇒NDD⇒DDD⇒1DD⇒12D⇒123N⇒ND⇒N1⇒ND1⇒N01⇒D01⇒301N⇒ND⇒NDD⇒DDD⇒3DD⇒30D⇒301N⇒ND⇒N1⇒ND1⇒N31⇒ND31⇒N431⇒ND431⇒N5431⇒D5431⇒75431N⇒ND⇒NDD⇒NDDD⇒NDDDD⇒DDDDD⇒7DDDD⇒75DDD⇒754DD⇒7543D⇒75431 4. 证明文法S→iSeS|iS| i是二义性文法。
答:对于句型iiSeS存在两个不同的最左推导:S⇒iSeS⇒iiSesS⇒iS⇒iiSeS所以该文法是二义性文法。
第一章编译程序概述1.1什么是编译程序编译程序是现代计算机系统的基本组成部分之一,而且多 数计算机系统都含有不止一个高级语言的编译程序。
对有些高 级语言甚至配置了几个不同性能的编译程序。
1.2编译过程概述和编译程序的结构编译程序完成从源程序到目标程序的翻译工作,是一个复 杂的整体的过程。
从概念上来讲,一个编译程序的整个工作过 程是划分成阶段进行的,每个阶段将源程序的一种表示形式转 换成另一种表示形式,各个阶段进行的操作在逻辑上是紧密连 接在一起的。
一般一个编译过程划分成词法分析、语法分析、 语义分析、中间代码生成,代码优化和目标代码生成六个阶段,这是一种典型的划分方法。
事实上,某些阶段可能组合在一起, 这些阶段间的源程序的中间表示形式就没必要构造岀来了。
我 们将分别介绍各阶段的任务。
另外两个重要的工作:表格管理 和岀错处理与上述六个阶段都有联系。
编译过程中源程序的各 种信息被保留在种种不同的表格里,编译各阶段的工作都涉及 到构造、查找或更新有关的表格,因此需要有表格管理的工作; 如果编译过程中发现源程序有错误,编译程序应报告错误的性 质和错误发生的地点,并且将错误所造成的影响限制在尽可能 小的范围内,使得源程序的其余部分能继续被编译下去,有些 编译程序还能自动校正错误, 这些工作称之为岀错处理。
图1.3表示了编译的各个阶段。
图1.3编译的各个阶段它不生成目标代码,它每遇到一个语句,就要对这个语句进行 分析以决定语句的含义,执行相应的动作。
右面的图示意了它 的工作机理第二章:PL/O 编译程序问答第1题 PL/0语言允许过程嵌套定义和递归调用,试问 它的编译程序如何解决运行时的存储管理。
答:PL/0语言允许过程嵌套定义和递归调用,它的编译程序在运行时采用了栈式动态存储管理。
(数组CODE 存放的只读目 标程序,它在运行时不改变。
)运行时的数据区S 是由解释程序 定义的一维整型数组,解释执行时对数据空间S 的管理遵循后进先岀规则,当每个过程(包括主程序)被调用时,才分配数据 空间,退出过程时,则所分配的数据空间被释放。

第一章习题解答1.解:源程序是指以某种程序设计语言所编写的程序。
目标程序是指编译程序(或解释程序)将源程序处理加工而得的另一种语言(目标语言)的程序。
翻译程序是将某种语言翻译成另一种语言的程序的统称。
编译程序与解释程序均为翻译程序,但二者工作方法不同。
解释程序的特点是并不先将高级语言程序全部翻译成机器代码,而是每读入一条高级语言程序语句,就用解释程序将其翻译成一段机器指令并执行之,然后再读入下一条语句继续进行解释、执行,如此反复。
即边解释边执行,翻译所得的指令序列并不保存。
编译程序的特点是先将高级语言程序翻译成机器语言程序,将其保存到指定的空间中,在用户需要时再执行之。
即先翻译、后执行。
2.解:一般说来,编译程序主要由词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序、目标代码生成程序、信息表管理程序、错误检查处理程序组成。
3.解:C语言的关键字有:auto break case char const continuedefault do double else enum extern float for goto if int longregister return short signed sizeof static struct switch typedef union unsigned void volatile while。
上述关键字在C语言中均为保留字。
4.解:C语言中括号有三种:{},[],()。
其中,{}用于语句括号;[]用于数组;()用于函数(定义与调用)及表达式运算(改变运算顺序)。
C语言中无END关键字。
逗号在C语言中被视为分隔符和运算符,作为优先级最低的运算符,运算结果为逗号表达式最右侧子表达式的值(如:(a,b,c,d)的值为d)。
</l第二章习题解答1.(1)答:26*26=676(2)答:26*10=260(3)答:{a,b,c,...,z,a0,a1,...,a9,aa,...,az,...,zz,a00,a01,...,zzz},共26+26*36+26*36*36=34658个2.构造产生下列语言的文法(1){anbn|n≥0}解:对应文法为G(S) = ({S},{a,b},{ S→ε| aSb },S)(2){anbmcp|n,m,p≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε},S)(3){an # bn|n≥0}∪{cn # dn|n≥0}解:对应文法为G(S) = ({S,X,Y},{a,b,c,d,#}, {S→X,S→Y,X→aXb|#,Y→cYd|# },S)(4){w#wr# | w?{0,1}*,wr是w的逆序排列}解:G(S) = ({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5)任何不是以0打头的所有奇整数所组成的集合解:G(S) = ({S,A,B,I,J},{-,0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|e, I→J|2|4|6|8, Jà1|3|5|7|9},S)(6)所有偶数个0和偶数个1所组成的符号串集合解:对应文法为S→0A|1B|e,A→0S|1C B→0C|1S C→1A|0B3.描述语言特点(1)S→10S0S→aAA→bAA→a解:本文法构成的语言集为:L(G)={(10)nabma0n|n, m≥0}。
第三章语法分析3.1 完成下列选择题:(1) 文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c. xnyxn(n≥0)d. x*yx*(2) 如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同(3) 采用自上而下分析,必须。
a. 消除左递 a. 必有ac归b. 消除右递归c. 消除回溯d. 提取公共左因子(4) 设a、b、c是文法的终结符,且满足优先关系a b和bc,则。
b. 必有cac. 必有bad. a~c都不一定成立(5) 在规范归约中,用来刻画可归约串。
a. 直接短语b. 句柄c. 最左素短语d. 素短语(6) 若a为终结符,则A→α·aβ为项目。
a. 归约b. 移进c. 接受d. 待约(7) 若项目集Ik含有A→α·,则在状态k时,仅当面临的输入符号a∈FOLLOW(A)时,才采取“A→α·”动作的一定是。
a. LALR文法b. LR(0)文法c. LR(1)文法d. SLR(1)文法(8) 同心集合并有可能产生新的冲突。
a. 归约b. “移进”/“移进”c.“移进”/“归约”d. “归约”/“归约”【解答】(1) c (2) a (3) c (4) d (5) b (6) b (7) d (8) d3.2 令文法G[N]为G[N]: N→D|NDD→0|1|2|3|4|5|6|7|8|9(1) G[N]的语言L(G[N])是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
【解答】(1) G[N]的语言L(G[N])是非负整数。
(2) 最左推导:NNDNDDN DDDDDD D0DDD01DD012D0127NNDDD3D34NNDNDDD DD5DD56D568最右推导:NNDN7ND7N27ND27N127D1270127NNDN4D434NNDN8ND8N68D685683.3 已知文法G[S]为S→aSb|Sb|b,试证明文法G[S]为二义文法。
第三章语法分析3.1 完成下列选择题:(1) 文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c. xnyxn(n≥0)d. x*yx*(2) 如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同(3) 采用自上而下分析,必须。
a. 消除左递 a. 必有ac归b. 消除右递归c. 消除回溯d. 提取公共左因子(4) 设a、b、c是文法的终结符,且满足优先关系ab和bc,则。
b. 必有cac. 必有bad. a~c都不一定成立(5) 在规范归约中,用来刻画可归约串。
a. 直接短语b. 句柄c. 最左素短语d. 素短语(6) 若a为终结符,则A→α·aβ为项目。
a. 归约b. 移进c. 接受d. 待约(7) 若项目集Ik含有A→α· ,则在状态k时,仅当面临的输入符号a∈FOLLOW(A)时,才采取“A→α· ”动作的一定是。
a. LALR文法b. LR(0)文法c. LR(1)文法d. SLR(1)文法(8) 同心集合并有可能产生新的冲突。
a. 归约b. “移进”/“移进”c.“移进”/“归约”d. “归约”/“归约”【解答】(1) c (2) a (3) c (4) d (5) b (6) b (7) d (8) d3.2 令文法G[N]为G[N]: N→D|NDD→0|1|2|3|4|5|6|7|8|9(1) G[N]的语言L(G[N])是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
【解答】(1) G[N]的语言L(G[N])是非负整数。
(2) 最左推导:NNDNDDNDDDDDDD0DDD01DD012D0127NNDDD3D34NNDNDDDDD5DD56D568最右推导:NNDN7ND7N27ND27N127D1270127NNDN4D434NNDN8ND8N68D685683.3 已知文法G[S]为S→aSb|Sb|b,试证明文法G[S]为二义文法。
《编译原理》习题参考答案(一)Bug report: zpli@Or find: 电一楼二楼全球计算实验室李兆鹏第二章2.3 叙述由下列正规式描述的语言a) 0(0|1)*0b) ((ε|0)1*)*c) (0|1)*0(0|1)(0|1)d) 0*10*10*10*e) (00|11)*((01|10)(00|11)*(01|10)(00|11)*)*Answer:a)以0开始和结尾,而且长度大于等于2的0、1串b)所有0,1串(含空串)c)倒数第三位是0的0、1串d) 仅含3个1的0、1串e) 偶数个0和偶数个1的0、1串(含空串)2.4 为下列语言写出正规定义:f) 由偶数个0和偶数个1构成的所有0和1的串g) 由偶数个0和奇数个1构成的所有0和1的串Answer:标准答案见《编译原理习题精选》P1-P2 1.1&1.2题2.7 用算法2.4为下列正规式构造非确定的有限自动机,给出它们处理输入串ababbab的转换序列。
c)((ε|a)b*)*d)(a|b)*abb(a|b)*Answer:c)NFA:输入串ababbab 的转换序列:0 1456789 145678 789 1456789 10Or 0 1456789 1456789 1236789 1456789 10d) NFA:输入串ababbab 的转换序列:0 1236 1456 789 10 11 12 13 16 11 14 15 16 172.8 用算法2.2把习题2.7的NFA 变换成DFA 。
给出它们处理输入串ababbab 的状态转换序列。
Answer: //针对2.7 (c)3个不同的状态集合:A = {0, 1, 2, 3, 4, 6, 7, 9, 10}B = {1, 2, 3, 4, 5, 6, 7, 9, 10}C = {1, 2, 3, 4, 6, 7, 8, 9, 10} NFA 的转换表:输入符号状态a bA B C B B C C BC子集构造法应用于2.7(c)得DFA:2.11 我们可以从正规式的最简DFA同构来证明两个正规式等价。