Hadoop介绍+环境搭建
- 格式:ppt
- 大小:1.46 MB
- 文档页数:44

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。

基于Hadoop的大数据处理平台搭建与部署一、引言随着互联网和信息技术的快速发展,大数据已经成为当今社会中不可或缺的重要资源。
大数据处理平台的搭建与部署对于企业和组织来说至关重要,而Hadoop作为目前最流行的大数据处理框架之一,其搭建与部署显得尤为重要。
本文将介绍基于Hadoop的大数据处理平台搭建与部署的相关内容。
二、Hadoop简介Hadoop是一个开源的分布式存储和计算框架,能够高效地处理大规模数据。
它由Apache基金会开发,提供了一个可靠、可扩展的分布式系统基础架构,使用户能够在集群中使用简单的编程模型进行计算。
三、大数据处理平台搭建准备工作在搭建基于Hadoop的大数据处理平台之前,需要进行一些准备工作: 1. 硬件准备:选择合适的服务器硬件,包括计算节点、存储节点等。
2. 操作系统选择:通常选择Linux系统作为Hadoop集群的操作系统。
3. Java环境配置:Hadoop是基于Java开发的,需要安装和配置Java环境。
4. 网络配置:确保集群内各节点之间可以相互通信。
四、Hadoop集群搭建步骤1. 下载Hadoop从Apache官网下载最新版本的Hadoop压缩包,并解压到指定目录。
2. 配置Hadoop环境变量设置Hadoop的环境变量,包括JAVA_HOME、HADOOP_HOME等。
3. 配置Hadoop集群编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等,配置各个节点的角色和参数。
4. 启动Hadoop集群通过启动脚本启动Hadoop集群,可以使用start-all.sh脚本启动所有节点。
五、大数据处理平台部署1. 数据采集与清洗在搭建好Hadoop集群后,首先需要进行数据采集与清洗工作。
通过Flume等工具实现数据从不同来源的采集,并进行清洗和预处理。
2. 数据存储与管理Hadoop提供了分布式文件系统HDFS用于存储海量数据,同时可以使用HBase等数据库管理工具对数据进行管理。

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。



Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。

hadoop分布式环境搭建实验总结Hadoop分布式环境搭建实验总结一、引言Hadoop是目前最流行的分布式计算框架之一,它具有高可靠性、高扩展性和高效性的特点。
在本次实验中,我们成功搭建了Hadoop分布式环境,并进行了相关测试和验证。
本文将对实验过程进行总结和归纳,以供参考。
二、实验准备在开始实验之前,我们需要准备好以下几个方面的内容:1. 硬件环境:至少两台具备相同配置的服务器,用于搭建Hadoop 集群。
2. 软件环境:安装好操作系统和Java开发环境,并下载Hadoop 的安装包。
三、实验步骤1. 安装Hadoop:解压Hadoop安装包,并根据官方文档进行相应的配置,包括修改配置文件、设置环境变量等。
2. 配置SSH无密码登录:为了实现集群间的通信,需要配置各个节点之间的SSH无密码登录。
具体步骤包括生成密钥对、将公钥分发到各个节点等。
3. 配置Hadoop集群:修改Hadoop配置文件,包括core-site.xml、hdfs-site.xml和mapred-site.xml等,设置集群的基本参数,如文件系统地址、数据存储路径等。
4. 启动Hadoop集群:通过启动NameNode、DataNode和ResourceManager等守护进程,使得集群开始正常运行。
可以通过jps命令来验证各个进程是否成功启动。
5. 测试Hadoop集群:可以使用Hadoop自带的例子程序进行测试,如WordCount、Sort等。
通过执行这些程序,可以验证集群的正常运行和计算能力。
四、实验结果经过以上步骤的操作,我们成功搭建了Hadoop分布式环境,并进行了相关测试。
以下是我们得到的一些实验结果:1. Hadoop集群的各个节点正常运行,并且能够相互通信。
2. Hadoop集群能够正确地处理输入数据,并生成期望的输出结果。
3. 集群的负载均衡和容错能力较强,即使某个节点出现故障,也能够继续运行和处理任务。

Hadoop集群环境搭建1、准备资料虚拟机、Redhat6.5、hadoop-1.0.3、jdk1.62、基础环境设置2.1配置机器时间同步#配置时间自动同步crontab -e#手动同步时间/usr/sbin/ntpdate 1、安装JDK安装cd /home/wzq/dev./jdk-*****.bin设置环境变量Vi /etc/profile/java.sh2.2配置机器网络环境#配置主机名(hostname)vi /etc/sysconfig/network#修第一台hostname 为masterhostname master#检测hostname#使用setup 命令配置系统环境setup#检查ip配置cat /etc/sysconfig/network-scripts/ifcfg-eth0#重新启动网络服务/sbin/service network restart#检查网络ip配置/sbin/ifconfig2.3关闭防火墙2.4配置集群hosts列表vi /etc/hosts#添加一下内容到vi 中2.5创建用户账号和Hadoop部署目录和数据目录#创建hadoop 用户/usr/sbin/groupadd hadoop#分配hadoop 到hadoop 组中/usr/sbin/useradd hadoop -g hadoop#修改hadoop用户密码Passwd hadoop#创建hadoop 代码目录结构mkdir -p /opt/modules/hadoop/#修改目录结构权限拥有者为为hadoopchown -R hadoop:hadoop /opt/modules/hadoop/2.6生成登陆密钥#切换到Hadoop 用户下su hadoopcd /home/hadoop/#在master、node1、node2三台机器上都执行下面命令,生成公钥和私钥ssh-keygen -q -t rsa -N "" -f /home/hadoop/.ssh/id_rsacd /home/hadoop/.ssh#把node1、node2上的公钥拷贝到master上scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node1_pubkey scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node2_pubkey#在master上生成三台机器的共钥cp id_rsa.pub authorized_keyscat node1_pubkey >> authorized_keyscat node2_pubkey >> authorized_keysrm node1_pubkey node2_pubkey#吧master上的共钥拷贝到其他两个节点上scp authorized_keys node1: /home/hadoop/.ssh/scp authorized_keys node1: /home/hadoop/.ssh/#验证ssh masterssh node1ssh node2没有要求输入密码登陆,表示免密码登陆成功3、伪分布式环境搭建3.1下载并安装JAVA JDK系统软件#下载jdkwget http://60.28.110.228/source/package/jdk-6u21-linux-i586-rpm.bin#安装jdkchmod +x jdk-6u21-linux-i586-rpm.bin./jdk-6u21-linux-i586-rpm.bin#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.2 Hadoop 文件下载和安装#切到hadoop 安装路径下cd /opt/modules/hadoop/#从 下载Hadoop 安装文件wget /apache-mirror/hadoop/common/hadoop-1.0.3/hadoop-1.0.3.tar.gz#如果已经下载,请复制文件到安装hadoop 文件夹cp hadoop-1.0.3.tar.gz /opt/modules/hadoop/#解压hadoop-1.0.3.tar.gzcd /opt/modules/hadoop/tar -xvf hadoop-1.0.3.tar.gz#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.3配置hadoop-env.sh 环境变量#配置jdk。

⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
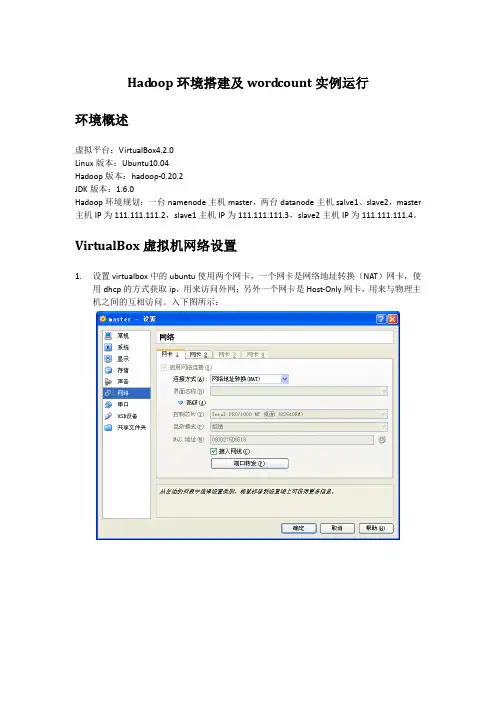
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
Hadoop环境搭建啥是⼤数据?问啥要学⼤数据?在我看来⼤数据就很多的数据,超级多,咱们⽇常⽣活中的数据会和历史⼀样,越来越多⼤数据有四个特点(4V):⼤多样快价值学完⼤数据我们可以做很多事,⽐如可以对许多单词进⾏次数查询(本节最后的实验),可以对股市进⾏分析,所有的学习都是为了赚⼤钱!(因为是在Linux下操作,所以⽤到的全是Linux命令,不懂可以百度,这篇⽂章有⼀些简单命令。
常⽤)第⼀步安装虚拟机配置环境1.下载虚拟机,可以⽤⾃⼰的,没有的可以下载这个 passowrd:u8lt2.导⼊镜像,可以⽤这个 password:iqww (不会创建虚拟机的可以看看,不过没有这个复杂,因为导⼊就能⽤)3.更换主机名,vi /etc/sysconfig/network 改HOSTNAME=hadoop01 (你这想改啥改啥,主要是为了清晰,否则后⾯容易懵)注:在这⾥打开终端4.查看⽹段,从编辑-虚拟⽹络编辑器查看,改虚拟机⽹段,我的是192.168.189.128-254(这个你根据⾃⼰的虚拟机配置就⾏,不⽤和我⼀样,只要记住189.128这个段就⾏)5.添加映射关系,输⼊:vim /etc/hosts打开⽂件后下⾯添加 192.168.189.128 hadoop01(红⾊部分就是你们上⾯知道的IP)(这⾥必须是hadoop01,为了⽅便后⾯直接映射不⽤敲IP)6.在配置⽂件中将IP配置成静态IP 输⼊: vim /etc/sysconfig/network-scripts/ifcfg-eth0 (物理地址也要⼀样哦!不知道IP的可以输⼊:ifconfig 查看⼀下)7.重启虚拟机输⼊:reboot (重启后输⼊ ping 能通就说明没问题)第⼆步克隆第⼀台虚拟机,完成第⼆第三虚拟机的配置1.⾸先把第⼀台虚拟机关闭,在右击虚拟机选项卡,管理-克隆即可(克隆两台⼀台hadoop02 ⼀台hadoop03)2.克隆完事后,操作和第⼀部基本相同唯⼀不同的地⽅是克隆完的虚拟机有两块⽹卡,我们把其中⼀个⽹卡注释就好(⼀定牢记!通过这⾥的物理地址⼀定要和配置⽂件中的物理地址相同)输⼊:vi /etc/udev/rules.d/70-persistent-net.rules 在第⼀块⽹卡前加# 将第⼆块⽹卡改为eth03.当三台机器全部配置完之后,再次在hosts⽂件中加⼊映射达到能够通过名称互相访问的⽬的输⼊:vim /etc/hosts (三台都要如此设置)(改完之后记得reboot重启)第三步使三台虚拟机能够通过SHELL免密登录1.查看SSH是否安装 rmp -qa | grep ssh (如果没有安装,输⼊sudo apt-get install openssh-server)2.查看SSH是否启动 ps -e | grep sshd (如果没有启动,输⼊sudo /etc/init.d/ssh start)3.该虚拟机⽣成密钥 ssh-keygen -t rsa(连续按下四次回车就可以了)4.将密钥复制到另外⼀台虚拟机⽂件夹中并完成免密登录输⼊:ssh-copy-id -i ~/.ssh/id_rsa.pub 2 (同样把秘钥给hadoop03和⾃⼰)(输⼊完后直接下⼀步,如果下⼀步失败再来试试改这个修改/etc/ssh/ssh_config中的StrictHostKeyCheck ask )5.之后输⼊ ssh hadoop02就可以正常访问第⼆台虚拟机啦注:可能你不太理解这是怎么回事,我这样解释⼀下,免密登录是为了后⾯进⾏集群操作时⽅便,⽣成秘钥就像是⽣成⼀个钥匙,这个钥匙是公钥,公钥可以打开所有门,之后把这个钥匙配两把,⼀把放在hadoop02的那⾥,⼀把放在hadoop03的那⾥,这样hadoop01可以对hadoop02和hadoop03进⾏访问。
Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐⾎整理)系统:Centos 7,内核版本3.10本⽂介绍如何从0利⽤Docker搭建Hadoop环境,制作的镜像⽂件已经分享,也可以直接使⽤制作好的镜像⽂件。
⼀、宿主机准备⼯作0、宿主机(Centos7)安装Java(⾮必须,这⾥是为了⽅便搭建⽤于调试的伪分布式环境)1、宿主机安装Docker并启动Docker服务安装:yum install -y docker启动:service docker start⼆、制作Hadoop镜像(本⽂制作的镜像⽂件已经上传,如果直接使⽤制作好的镜像,可以忽略本步,直接跳转⾄步骤三)1、从官⽅下载Centos镜像docker pull centos下载后查看镜像 docker images 可以看到刚刚拉取的Centos镜像2、为镜像安装Hadoop1)启动centos容器docker run -it centos2)容器内安装java下载java,根据需要选择合适版本,如果下载历史版本拉到页⾯底端,这⾥我安装了java8/usr下创建java⽂件夹,并将java安装包在java⽂件下解压tar -zxvf jdk-8u192-linux-x64.tar.gz解压后⽂件夹改名(⾮必需)mv jdk1.8.0_192 jdk1.8配置java环境变量vi ~/.bashrc ,添加内容,保存后退出export JAVA_HOME=/usr/java/jdk1.8export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/libexport PATH=$PATH:${JAVA_HOME}/bin使环境变量⽣效 source ~/.bashrc验证安装结果 java -version这⾥注意,因为是在容器中安装,修改的是~/.bashrc⽽⾮我们使⽤更多的/etc/profile,否则再次启动容器的时候会环境变量会失效。
Hadoop集群配置(最全⾯总结)通常,集群⾥的⼀台机器被指定为 NameNode,另⼀台不同的机器被指定为JobTracker。
这些机器是masters。
余下的机器即作为DataNode也作为TaskTracker。
这些机器是slaves\1 先决条件1. 确保在你集群中的每个节点上都安装了所有软件:sun-JDK ,ssh,Hadoop2. Java TM1.5.x,必须安装,建议选择Sun公司发⾏的Java版本。
3. ssh 必须安装并且保证 sshd⼀直运⾏,以便⽤Hadoop 脚本管理远端Hadoop守护进程。
2 实验环境搭建2.1 准备⼯作操作系统:Ubuntu部署:Vmvare在vmvare安装好⼀台Ubuntu虚拟机后,可以导出或者克隆出另外两台虚拟机。
说明:保证虚拟机的ip和主机的ip在同⼀个ip段,这样⼏个虚拟机和主机之间可以相互通信。
为了保证虚拟机的ip和主机的ip在同⼀个ip段,虚拟机连接设置为桥连。
准备机器:⼀台master,若⼲台slave,配置每台机器的/etc/hosts保证各台机器之间通过机器名可以互访,例如:10.64.56.76 node1(master)10.64.56.77 node2 (slave1)10.64.56.78 node3 (slave2)主机信息:机器名 IP地址作⽤Node110.64.56.76NameNode、JobTrackerNode210.64.56.77DataNode、TaskTrackerNode310.64.56.78DataNode、TaskTracker为保证环境⼀致先安装好JDK和ssh:2.2 安装JDK#安装JDK$ sudo apt-get install sun-java6-jdk1.2.3这个安装,java执⾏⽂件⾃动添加到/usr/bin/⽬录。
验证 shell命令:java -version 看是否与你的版本号⼀致。
Hadoop开发环境搭建(Win8+Linux)常见的Hadoop开发环境架构有以下三种:1、Eclipse与Hadoop集群在同一台Windows机器上。
2、Eclipse与Hadoop集群在同一台Linux机器上。
3、Eclipse在Windows上,Hadoop集群在远程Linux机器上。
点评:第一种架构:必须安装cygwin,Hadoop对Windows的支持有限,在Windows 上部署hadoop会出现相当多诡异的问题。
第二种架构:Hadoop机器运行在Linux上完全没有问题,但是有大部分的开发者不习惯在Linux上做开发。
这种架构适合习惯使用Linux的开发者。
第三种架构:Hadoop集群部署在Linux上,保证了稳定性,Eclipse在Windows 上,符合大部分开发者的习惯。
本文主要介绍第三种Hadoop开发环境架构的搭建方法。
Hadoop开发环境的搭建分为两大块:Hadoop集群搭建、Eclipse环境搭建。
其中Hadoop集群搭建可参考官方文档,本文主要讲解Eclipse环境搭建(如何在Eclipse 中查看和操作HDFS、如何在Eclipse中执行MapReduce作业)。
搭建步骤:1、搭建Hadoop集群(Linux、JDK6、Hadoop-1.1.2)2、在Windows上安装JDK6+3、在Windows上安装Eclipse3.3+4、在Eclipse上安装hadoop-eclipse-plugin-1.1.2.jar插件(如果没有,则需自行编译源码)5、在Eclipse上配置Map/Reduce Location搭建Hadoop集群此步骤可参考Hadoop官方文档在Windows上安装JDK此步骤可参考官方文档在Window上安装Eclipse此步骤可参考官方文档在Eclipse上安装hadoop-eclipse-plugin-1.1.2.jar插件Hadoop-1.1.2的发布包里面没有hadoop-eclipse-plugin-1.1.2.jar,开发者必须根据所在的环境自行编译hadoop-eclipse-plugin-1.1.2.jar插件。
Hadoop⽣产环境搭建(含HA、Federation)Hadoop⽣产环境搭建1. 将安装包hadoop-2.x.x.tar.gz存放到某⼀⽬录下,并解压。
2. 修改解压后的⽬录中的⽂件夹etc/hadoop下的配置⽂件(若⽂件不存在,⾃⼰创建。
)包括hadoop-env.sh,mapred-site.xml,core-site.xml,hdfs-site.xml,yarn-site.xml3. 格式化并启动HDFS4. 启动YARN以上整个过程与Hadoop单机Hadoop测试环境搭建基本⼀致,不同的是步骤2中配置⽂件设置内容以及步骤3的详细过程。
HDFS2.0的HA配置⽅法(主备NameNode)注意事项:1)主备Namenode有多种配置⽅法,本次使⽤JournalNode⽅式。
⾄少准备三个节点作为JournalNode2)主备两个Namenode应放于不同的机器上,独享机器。
(HDFS2.0中吴煦配置secondaryNamenode,备NameNode已经代替它完成相应的功能)3)主备NameNode之间有两种切换⽅式,⼿动切换和⾃动切换。
其中⾃动切换是借助Zookeeper实现的。
因此需要单独部署⼀个Zookeeper集群,通常为奇数个,⾄少3个。
==================================================================================HSFS HA部署架构和流程HSFS HA部署架三个JournalNode两个NameNodeN个DataNodeHDFS HA部署流程——hdfs-site.xml配置services 集群中命名服务列表(⾃定义)nodes.${ns}命名服务中的namenode逻辑名称(⾃定义)node.rpc-address.${ns}.${nn} 命名服务中逻辑名称对应的RPC地址node.http-address.${ns}.${nn} 命名服务中逻辑名称对应的HTTP地址.dir NameNode fsimage存放⽬录node.shared.edits.dir 主备NameNode同步元信息的共享存储系统dfs.journalnode.edits.dir Journal Node数据存放⽬录HDFS HA部署流程——hdfs-site.xml配置实例<?xml version="1.0" encoding="UTF-8"?><configuration><property><name>services</name><value>hadoop-rokid</value></property><property><name>nodes.hadoop-rokid</name><value>nn1,nn2</value></property><property><name>node.rpc-adress.hadoop-rokid.nn1</name><value>nn1:8020</value></property><property><name>node.rpc-adress.hadoop-rokid.nn2</name><value>nn2:8020</value></property><property><name>node.http-adress.hadoop-rokid.nn1</name><value>nn1:50070</value></property><property><name>node.http-adress.hadoop-rokid.nn2</name><value>nn2:50070</value></property><property><name>.dir</name><value>file:///home/zhangzhenghai/cluster/hadoop/dfs/name</value></property><property><name>node.shared.edits.dir</name><value>qjournal://jnode1:8485;jnode2:8485;jnode3:8485/hadoop-rokid</value></property><property><name>dfs.datanode.data.dir</name><value>file:///home/zhangzhenghai/cluster/hadoop/dfs/data</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>false</value></property><property><name>dfs.journalnode.edits.dir</name><value>/home/zhangzhenghai/cluster/hadoop/dfs/journal</value><?xml version="1.0" encoding="UTF-8"?><configuration><property><name></name><value>hdfs://nn1:8020</value></property></configuration>HDFS HA部署流程——slaves配置实例列出集群中的所有机器名称列表启动顺序:Hadoop2.x上机实践(部署多机-HDFS HA+YARN)HA注意:所有操作均在Hadoop部署⽬录下进⾏。
⼤数据Hadoop学习之搭建Hadoop平台(2.1) 关于⼤数据,⼀看就懂,⼀懂就懵。
⼀、简介 Hadoop的平台搭建,设置为三种搭建⽅式,第⼀种是“单节点安装”,这种安装⽅式最为简单,但是并没有展⽰出Hadoop的技术优势,适合初学者快速搭建;第⼆种是“伪分布式安装”,这种安装⽅式安装了Hadoop的核⼼组件,但是并没有真正展⽰出Hadoop的技术优势,不适⽤于开发,适合学习;第三种是“全分布式安装”,也叫做“分布式安装”,这种安装⽅式安装了Hadoop的所有功能,适⽤于开发,提供了Hadoop的所有功能。
⼆、介绍Apache Hadoop 2.7.3 该系列⽂章使⽤Hadoop 2.7.3搭建的⼤数据平台,所以先简单介绍⼀下Hadoop 2.7.3。
既然是2.7.3版本,那就代表该版本是⼀个2.x.y发⾏版本中的⼀个次要版本,是基于2.7.2稳定版的⼀个维护版本,开发中不建议使⽤该版本,可以使⽤稳定版2.7.2或者稳定版2.7.4版本。
相较于以前的版本,2.7.3主要功能和改进如下: 1、common: ①、使⽤HTTP代理服务器时的⾝份验证改进。
当使⽤代理服务器访问WebHDFS时,能发挥很好的作⽤。
②、⼀个新的Hadoop指标接收器,允许直接写⼊Graphite。
③、与Hadoop兼容⽂件系统(HCFS)相关的规范⼯作。
2、HDFS: ①、⽀持POSIX风格的⽂件系统扩展属性。
②、使⽤OfflineImageViewer,客户端现在可以通过WebHDFS API浏览fsimage。
③、NFS⽹关接收到⼀些可⽀持性改进和错误修复。
Hadoop端⼝映射程序不再需要运⾏⽹关,⽹关现在可以拒绝来⾃⾮特权端⼝的连接。
④、SecondaryNameNode,JournalNode和DataNode Web UI已经通过HTML5和Javascript进⾏了现代化改造。
3、yarn: ①、YARN的REST API现在⽀持写/修改操作。