计量经济学第3章多元线性回归模型分析和解析
- 格式:ppt
- 大小:1.70 MB
- 文档页数:15


多元线性回归模型的估计与解释多元线性回归是一种广泛应用于统计学和机器学习领域的预测模型。
与简单线性回归模型相比,多元线性回归模型允许我们将多个自变量引入到模型中,以更准确地解释因变量的变化。
一、多元线性回归模型的基本原理多元线性回归模型的基本原理是建立一个包含多个自变量的线性方程,通过对样本数据进行参数估计,求解出各个自变量的系数,从而得到一个可以预测因变量的模型。
其数学表达形式为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y为因变量,X1、X2、...、Xn为自变量,β0、β1、β2、...、βn为模型的系数,ε为误差项。
二、多元线性回归模型的估计方法1. 最小二乘法估计最小二乘法是最常用的多元线性回归模型估计方法。
它通过使残差平方和最小化来确定模型的系数。
残差即观测值与预测值之间的差异,最小二乘法通过找到使残差平方和最小的系数组合来拟合数据。
2. 矩阵求解方法多元线性回归模型也可以通过矩阵求解方法进行参数估计。
将自变量和因变量分别构成矩阵,利用矩阵运算,可以直接求解出模型的系数。
三、多元线性回归模型的解释多元线性回归模型可以通过系数估计来解释自变量与因变量之间的关系。
系数的符号表示了自变量对因变量的影响方向,而系数的大小则表示了自变量对因变量的影响程度。
此外,多元线性回归模型还可以通过假设检验来验证模型的显著性。
假设检验包括对模型整体的显著性检验和对各个自变量的显著性检验。
对于整体的显著性检验,一般采用F检验或R方检验。
F检验通过比较回归平方和和残差平方和的比值来判断模型是否显著。
对于各个自变量的显著性检验,一般采用t检验,通过检验系数的置信区间与预先设定的显著性水平进行比较,来判断自变量的系数是否显著不为零。
通过解释模型的系数和做假设检验,我们可以对多元线性回归模型进行全面的解释和评估。
四、多元线性回归模型的应用多元线性回归模型在实际应用中具有广泛的应用价值。



第二章经典单方程计量经济学模型:一元线性回归模型一、内容提要本章介绍了回归分析的基本思想与基本方法。
首先,本章从总体回归模型与总体回归函数、样本回归模型与样本回归函数这两组概念开始,建立了回归分析的基本思想。
总体回归函数是对总体变量间关系的定量表述,由总体回归模型在若干基本假设下得到,但它只是建立在理论之上,在现实中只能先从总体中抽取一个样本,获得样本回归函数,并用它对总体回归函数做出统计推断。
本章的一个重点是如何获取线性的样本回归函数,主要涉及到普通最小二乘法(OLS)的学习与掌握。
同时,也介绍了极大似然估计法(ML)以及矩估计法(MM)。
本章的另一个重点是对样本回归函数能否代表总体回归函数进行统计推断,即进行所谓的统计检验。
统计检验包括两个方面,一是先检验样本回归函数与样本点的“拟合优度”,第二是检验样本回归函数与总体回归函数的“接近”程度。
后者又包括两个层次:第一,检验解释变量对被解释变量是否存在着显著的线性影响关系,通过变量的t检验完成;第二,检验回归函数与总体回归函数的“接近”程度,通过参数估计值的“区间检验”完成。
本章还有三方面的内容不容忽视。
其一,若干基本假设。
样本回归函数参数的估计以及对参数估计量的统计性质的分析以及所进行的统计推断都是建立在这些基本假设之上的。
其二,参数估计量统计性质的分析,包括小样本性质与大样本性质,尤其是无偏性、有效性与一致性构成了对样本估计量优劣的最主要的衡量准则。
Goss-markov定理表明OLS估计量是最佳线性无偏估计量。
其三,运用样本回归函数进行预测,包括被解释变量条件均值与个值的预测,以及预测置信区间的计算及其变化特征。
二、典型例题分析例1、令kids表示一名妇女生育孩子的数目,educ表示该妇女接受过教育的年数。
生育率对教育年数的简单回归模型为β+μβkids=educ+1(1)随机扰动项μ包含什么样的因素?它们可能与教育水平相关吗?(2)上述简单回归分析能够揭示教育对生育率在其他条件不变下的影响吗?请解释。

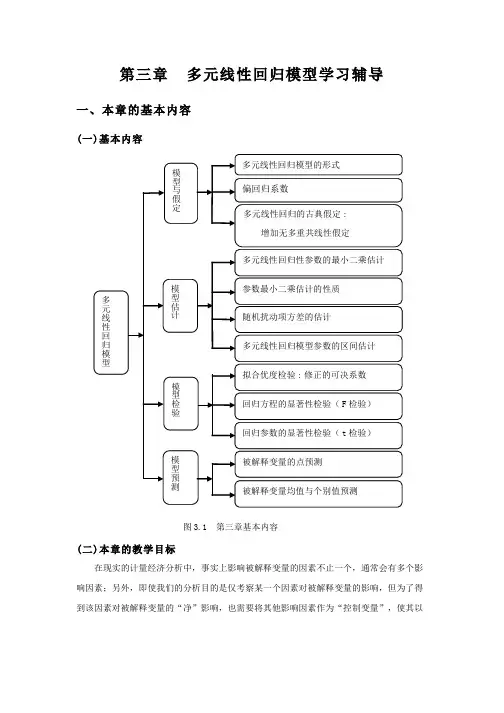
第三章 多元线性回归模型学习辅导一、本章的基本内容(一)基本内容图3.1 第三章基本内容(二)本章的教学目标在现实的计量经济分析中,事实上影响被解释变量的因素不止一个,通常会有多个影响因素;另外,即使我们的分析目的是仅考察某一个因素对被解释变量的影响,但为了得到该因素对被解释变量的“净”影响,也需要将其他影响因素作为“控制变量”,使其以显性形式出现在模型中,以提高模型估计精度。
因此,在对现实经济问题进行计量经济分析时,通常需要建立包含两个及两个以上解释变量的计量模型,此类模型称为多元回归模型。
多元回归模型是在简单回归模型理论基础上的扩展,其建模的理论基础、基本思路、模型估计等与一元回归模型基本一致,只是因解释变量增多,从而带来一些新的内容,比如模型整体显著性检验(F 检验)、修正的可决系数(2R )以及解释变量之间多重共线性等问题。
本章的教学目标是:深刻理解建立多元回归模型的目的;掌握多元线性回归模型估计、检验的理论与方法;熟练掌握多元线性回归EViews 输出结果的解释。
二、重点与难点分析1.对多元线性回归模型参数意义的理解多元线性回归模型的参数与简单线性回归模型的参数有重要区别。
在多元线性回归模型中,解释变量对应的参数是偏回归系数,表达的是控制其他解释变量不变的条件下,该解释变量的单位变动对被解释变量平均值的“净”影响。
为了更深刻理解偏回归系数,可以两个解释变量的多元线性回归模型为例加以说明1。
例如,被解释变量Y 与解释变量2X 和3X 都有关,如果分别建立模型:多元线性回归: 12233i i i i Y X X u b b b =+++简单线性回归 : 1221i i i Y a a X u =++由于Y 与3X 有关,可以作回归:1332i i i Y b b X u =++,若用OLS 估计其参数,并计算残差213333ˆˆˆi i i i i e Y b b X y b x =--=-,这里的2i e 表示除去3i X 影响后的i Y 。


《中级计量经济学》非选择题参考答案第3章多元线性回归模型3.4.3 简答题、分析与计算题1.给定二元回归模型:yt=b0+b1x1t+b2x2t+ut (t=1,2,…n)(1) 叙述模型的古典假定;(2)写出总体回归方程、样本回归方程与样本回归模型;(3)写出回归模型的矩阵表示;(4)写出回归系数及随机误差项方差的最小二乘估计量,并叙述参数估计量的性质;(5)试述总离差平方和、回归平方和、残差平方和之间的关系及其自由度之间的关系。
2.在多元线性回归分析中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度?3.决定系数R与总体线性关系显著性F检验之间的关系;在多元线性回归分析中,F检验与t检验有何不同?在一元线性回归分析中二者是否有等价的作用?4.为什么说对模型施加约束条件后,其回归的残差平方和一定不比未施加约束的残差平方和小?在什么样的条件下,受约束回归与无约束回归的结果相同?5.观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。
(1)yt=b0+b1xt3+ut (2)yt=b0+b1logxt+ut (3)logyt=b0+b1logxt+ut (4)yt=b0+b1(b2 xt)+ut(5)yt=b0/(b1xt)+ut (6)yt=1+b0(1 xt1)+ut (7)yt=b0+b1x1t+b2x2t/10+ut 6.常见的非线性回归模型有几种情况?7.指出下列模型中所要求的待估参数的经济意义:(1)食品类需求函数:lnY=α0+α1lnI+α2lnP1+α3lnP2+u中的α1,α2,α3(其中Yb2为人均食品支出额,I为人均收入,P。
1为食品类价格,P2为其他替代商品类价格)(2)消费函数:Ct=β0+β1Yt+β2Yt 1+ut中的β1和β2(其中C为人均消费额,Y为人均收入)。
8.设货币需求方程式的总体模型为ln(Mt/Pt)=b0+b1ln(rt)+b3ln(RGDPt)+ut其中M为名义货币需求量,P为物价水平,r为利率,RGDP 为实际国内生产总值。

第三章、经典单方程计量经济学模型:多元线性回归模型一、内容提要本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的情形相同。
主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方面的应用等方面。
只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。
本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。
与一元回归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的内在联系。
本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如何转化为线性回归模型的常见类型与方法。
这里需要注意各回归参数的具体经济含义。
本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约束检验。
参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与邹氏预测检验两种类型的检验。
检验都是以F检验为主要检验工具,以受约束模型与无约束模型是否有显著差异为检验基点。
参数的非线性约束检验主要包括最大似然比检验、沃尔德检验与拉格朗日乘数检验。
它们仍以估计无约束模型与受约束模型为基础,但以最大似然原χ分布为检验统计量理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的2的分布特征。
非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。
二、典型例题分析例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为36.0.+=-10+094medufedu.0sibsedu210131.0R2=0.214式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。

计量经济学作业物二 王阳 2008017241一、创立工作文件 create u 31二、输入数据 data GDP K L P三、数据转换GENR GDP1=GDP/P*100四、生成时间变量T :GENR T=@TREND(2003)五、建立三元线性回归模型1LS GDP1 C T K1L()()()()110.47960.468917.2698 2.9625ˆ14285.977.0371 1.98640.3483Y T K L --=++--220.9676,0.9639,268.3779R R F === 11GDP Y =分析:T 值系数符号小于0不符合经济意义,2R =0.9639有很高的拟合度F 0.05(3,27)=2.96<268.3779落入拒绝域原假设不成立,所以F 检验高度显著。
说明资本K1就业人数L 时间变量T 联合起来对国内生产总值影响显著,T 0.05(27)=2.052小于2.9625和17.2698,说明K1 ,L 对GDP1的影响是显著的,但其他变量的t 值通不过t 检验。
因此调整该三元线性回归模型,剔除t 值最小变量时间序列T ,再建立二元线性回归模型。
六、建立二元线性回归模型2 LS GDP1 C K1 L()()()211.464919.3605 2.9732ˆ321.0325 2.00820.3361Y K L -=++-220.96720.9650413.9922R R F ===,,21GDP Y =分析:回归系数的符号和数值合理,模型可决系数很高;F 0.05(3,27)=2.96<413.9922落入拒绝域,说明就业人数L 和资本K 对GDP 的总影响是显著的,T 0.05(27)=2.052L 和K 均能通过t 检验,表明其各自对GDP 的影响均是显著的。
七、建立非线性回归模型3GENR LNGDP1=log(GDP1) GENR LNL=log(L) GENR LNK1=log(K1) 建立回归模型 LS LNGDP1 C LNL LNK1()()()30.9482 3.128016.4652ˆ10.25620.17670.9576LNY LNL LNK -=+--220.97230.9703490.6044R R F ===,,31GDP Y =分析:资本与劳动的回归系数都在0到1之间符合经济意义,,而且拟合优度较模型2还略有提高,解释变量都通过了显著性检验,模型中各解释变量依然显著。
计量经济学_三元线性回归模型案例分析计量经济学课程设计班级:学号:姓名:2011年1⽉⼀,问题设计改⾰开放以来,随着经济体制的改⾰深化和经济的快速增长,中国的财政收⽀状况发⽣了很⼤的变化,中央和地⽅的税收收⼊1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。
为了研究中国税收收⼊增长的主要原因,分析中央和地⽅税收收⼊的增长规律,预测中国税收未来的增长趋势,需要建⽴计量经济学模型。
⼆,理论基础影响中国税收收⼊增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。
(2)公共财政的需求,税收收⼊是财政的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收⼊可能有⼀定的影响。
(3)物价⽔平。
我国的税制结构以流转税为主,以现⾏价格计算的DGP等指标和和经营者收⼊⽔平都与物价⽔平有关。
(4)税收政策因。
我国⾃1978年以来经历了两次⼤的税制改⾰,⼀次是1984—1985年的国有企业利改税,另⼀次是1994年的全国范围内的新税制改⾰。
税制改⾰对税收会产⽣影响,特别是1985年税收陡增215.42%。
但是第⼆次税制改⾰对税收的增长速度的影响不是⾮常⼤。
因此可以从以上⼏个⽅⾯,分析各种因素对中国税收增长的具体影响。
为了反映中国税收增长的全貌,选择包括中央和地⽅税收的‘国家财政收⼊’中的“各项税收”(简称“税收收⼊”)作为被解释变量,以放映国家税收的增长;选择“国内⽣产总值(GDP)”作为经济整体增长⽔平的代表;选择中央和地⽅“财政⽀出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价⽔平的代表。
由于税制改⾰难以量化,⽽且1985年以后财税体制改⾰对税收增长影响不是很⼤,可暂不考虑。
所以解释变量设定为可观测“国内⽣产总值(GDP)”、“财政⽀出”、“商品零售物价指数”三,数理经济学⽅程Y = C(1) + C(2)*XY i=β0+β2X2+β3X3+β4X4四,计量经济学⽅程设定线性回归模型为:Y i=β0+β2X2+β3X3+β4X4+µ五,数据收集从《国家统计局》获取以下数据:年份财政收⼊(亿元)Y 国内⽣产总值(亿元)X2财政⽀出(亿元)X3商品零售价格指数(%)X41985 2040.79 8964.4 2004.25 108.8 1986 2090.73 10202.2 2204.91 106 1987 2140.36 11962.5 2262.18 107.3 1988 2390.47 14928.3 2491.21 118.5 1989 2727.4 16909.2 2823.78 117.81990 2821.86 18547.9 3083.59 102.1 1991 2990.17 21617.8 3386.62 102.9 1992 3296.91 26638.1 3742.2 105.4 1993 4255.3 34636.4 4642.3 113.2 1994 5126.88 46759.4 5792.62 121.7 1995 6038.04 58478.1 6823.72 114.8 1996 6909.82 67884.6 7937.55 106.1 1997 8234.04 74462.6 9233.56 100.8 1998 9262.8 78345.2 10798.18 97.4 1999 10682.58 82067.5 13187.67 97 2000 12581.51 89468.1 15886.5 98.5 2001 15301.38 97314.8 18902.58 99.2 2002 17636.45 104790.6 22053.15 98.7六,参数估计利⽤eviews软件可以得到Y关于X2的散点图:可以看出Y和X2成线性相关关系Y关于X3的散点图:可以看出Y和X3成线性相关关系Y关于X4的散点图:Dependent Variable: YMethod: Least SquaresDate: 01/09/10 Time: 13:16Sample: 1978 2002Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.C -2582.755 940.6119 -2.745825 0.0121X2 0.022067 0.005577 3.956633 0.0007X3 0.702104 0.033236 21.12474 0.0000X4 23.98506 8.738296 2.744821 0.0121R-squared 0.997430 Mean dependent var 4848.366Adjusted R-squared 0.997063 S.D. dependent var 4870.971S.E. of regression 263.9591 Akaike info criterion 14.13511Sum squared resid 1463163. Schwarz criterion 14.33013Log likelihood -172.6889 F-statistic 2717.254Durbin-Watson stat 0.948521 Prob(F-statistic) 0.000000模型估计的结果为:Y i=-2582.755+0.022067X2+0.702104X3+23.98506X4(940.6119) (0.0056) (0.0332) (8.7383)t={-2.7458} {3.9567} {21.1247} {2.7449}R2=0.997 R2=0.997 F=2717.254 df=21七,相关检验1.经济意义检验模型估计结果说明,在假定其他变量不变的情况下,当年GDP 每增长1亿元,税收收⼊就会增长0.02207亿元;在假定其他变量不变的情况下,当年财政⽀出每增长1亿元,税收收⼊就会增长0.7021亿元;在假定其他变量不变的情况下,当零售商品物2.统计检验(1)拟合优度:R2=0.997,修正的可决系数为R2=0.997这说明模型对样本拟合的很好。
目录目录 (1)一、建立多元线性回归模型 (3)(一) 建立包括时间变量的三元线性回归模型; (3)1. 建立工作文件:CREATE A 78 94 (3)2. 输入统计资料:DATA Y L K (3)3. 生成时间变量t:GENR T=@TREND(77) (3)4. 建立回归模型:LS Y C T L K (3)(二) 建立剔除时间变量的二元线性回归模型; (4)(三) 建立非线性回归模型——C-D生产函数。
(5)二、比较、选择最佳模型 (8)(一) 回归系数的符号及数值是否合理; (8)(二) 模型的更改是否提高了拟合优度; (8)(三) 模型中各个解释变量是否显著; (8)(四) 残差分布情况 (8)实验三多元回归模型【实验目的】掌握建立多元回归模型和比较、筛选模型的方法。
【实验内容】建立我国国有独立核算工业企业生产函数。
根据生产函数理论,生产函数的基本形式为:()ε,tY=。
其中,L、K分别为生产过程中投入的劳动与资金,fL,K,时间变量t反映技术进步的影响。
表3-1列出了我国1978-1994年期间国有独立核算工业企业的有关统计资料;其中产出Y为工业总产值(可比价),L、K分别为年末职工人数和固定资产净值(可比价)。
资料来源:根据《中国统计年鉴-1995》和《中国工业经济年鉴-1995》计算整理【实验步骤】一、 建立多元线性回归模型(一) 建立包括时间变量的三元线性回归模型;在命令窗口依次键入以下命令即可:1. 建立工作文件: CREATE A 78 942. 输入统计资料: DATA Y L K3. 生成时间变量t : GENR T=@TREND(77)4. 建立回归模型: LS Y C T L K则生产函数的估计结果及有关信息如图3-1所示。
图3-1 我国国有独立核算工业企业生产函数的估计结果 因此,我国国有独立工业企业的生产函数为:K L t y 7764.06667.06789.7732.675ˆ+++-= (模型1)t =(-0.252) (0.672) (0.781) (7.433)9958.02=R 9948.02=R 551.1018=F 模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为0.6667,资金的边际产出为0.7764,技术进步的影响使工业总产值平均每年递增77.68亿元。