典型相关分析(1)
- 格式:ppt
- 大小:771.50 KB
- 文档页数:84


相关系数是变量之间相关程度的指标。
样本相关系数用r表示,总体相关系数用ρ表示,相关系数的取值一般介于-1~1之间。
相关系数不是等距度量值,而只是一个顺序数据。
计算相关系数一般需大样本.相关系数又称皮(尔生)氏积矩相关系数,说明两个现象之间相关关系密切程度的统计分析指标。
相关系数用希腊字母γ表示,γ值的范围在-1和+1之间。
γ>0为正相关,γ<0为负相关。
γ=0表示不相关;γ的绝对值越大,相关程度越高。
两个现象之间的相关程度,一般划分为四级:如两者呈正相关,r呈正值,r=1时为完全正相关;如两者呈负相关则r呈负值,而r=-1时为完全负相关。
完全正相关或负相关时,所有图点都在直线回归线上;点子的分布在直线回归线上下越离散,r的绝对值越小。
当例数相等时,相关系数的绝对值越接近1,相关越密切;越接近于0,相关越不密切。
当r=0时,说明X和Y两个变量之间无直线关系。
相关系数的计算公式为<见参考资料>.其中xi为自变量的标志值;i=1,2,…n;■为自变量的平均值,为因变量数列的标志值;■为因变量数列的平均值。
为自变量数列的项数。
对于单变量分组表的资料,相关系数的计算公式<见参考资料>.其中fi为权数,即自变量每组的次数。
在使用具有统计功能的电子计算机时,可以用一种简捷的方法计算相关系数,其公式<见参考资料>.使用这种计算方法时,当计算机在输入x、y数据之后,可以直接得出n、■、∑xi、∑yi、∑■、∑xiy1、γ等数值,不必再列计算表。
简单相关系数:又叫相关系数或线性相关系数。
它一般用字母r 表示。
它是用来度量定量变量间的线性相关关系。
复相关系数:又叫多重相关系数复相关是指因变量与多个自变量之间的相关关系。
例如,某种商品的需求量与其价格水平、职工收入水平等现象之间呈现复相关关系。
偏相关系数:又叫部分相关系数:部分相关系数反映校正其它变量后某一变量与另一变量的相关关系,校正的意思可以理解为假定其它变量都取值为均数。

典型相关分析简介典型相关分析(canonical correlation analysis, CCA)是一种多变量统计分析方法,用于研究两组观测变量之间的相关性。
该方法可以帮助我们理解两组变量之间的线性关系,并找出两组变量中最相关的部分。
在机器学习、数据挖掘以及统计学中,典型相关分析被广泛应用于特征选择、降维和模式识别等领域。
方法典型相关分析是基于矩阵分解的方法,通过将两组变量转化成低秩的典型变量来寻找相关性。
典型相关分析的基本思想是找出两组变量的线性组合,使得这两个组合能够达到最大的相关性。
具体而言,给定两组变量X和Y,我们可以得到X的线性组合u和Y的线性组合v,使得cor(u,v)达到最大。
其中cor(u,v)表示两个向量u和v的相关系数。
典型相关分析的目标即是求解出使得cor(u,v)最大的u和v。
下面是典型相关分析的数学表示形式:max cor(u,v)subject to u = Xa, v = Yb其中,X和Y分别是两组变量的矩阵,u和v是X和Y的线性组合,a和b是权重向量。
通过求解最优化问题,我们可以得到最相关的线性组合u和v,从而得到最相关的部分。
应用典型相关分析广泛应用于多个领域,下面列举了几个常见的应用场景:特征选择在特征选择中,我们经常面临着从大量的特征中选取最相关的特征集合。
典型相关分析可以帮助我们通过寻找两组变量之间的相关性,筛选出对目标变量有着较强相关性的特征。
通过选择最相关的特征,我们可以提高模型的泛化能力,并降低过拟合的风险。
降维在大数据时代,数据维度高维且复杂。
降维可以帮助我们减少计算负担,并去除冗余信息。
典型相关分析可以通过找出两组变量最相关的部分,将原始多维数据降到低维空间。
这样做可以减少计算复杂度,提高模型的训练速度,并帮助我们更好地理解数据之间的关系。
模式识别典型相关分析在模式识别领域也有着重要的应用。
通过找出两组变量之间的最相关部分,我们可以构建更加精确和可靠的模式识别模型。
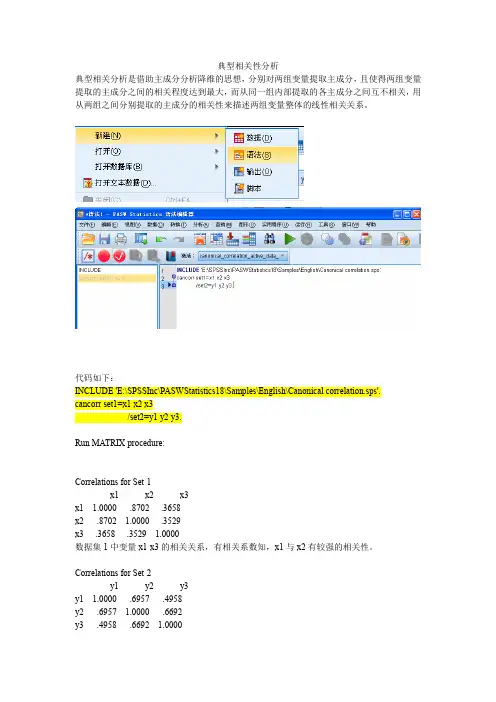
典型相关性分析典型相关分析是借助主成分分析降维的思想,分别对两组变量提取主成分,且使得两组变量提取的主成分之间的相关程度达到最大,而从同一组内部提取的各主成分之间互不相关,用从两组之间分别提取的主成分的相关性来描述两组变量整体的线性相关关系。
代码如下:INCLUDE 'E:\SPSSInc\PASWStatistics18\Samples\English\Canonical correlation.sps'.cancorr set1=x1 x2 x3/set2=y1 y2 y3.Run MATRIX procedure:Correlations for Set-1x1 x2 x3x1 1.0000 .8702 -.3658x2 .8702 1.0000 -.3529x3 -.3658 -.3529 1.0000数据集1中变量x1-x3的相关关系,有相关系数知,x1与x2有较强的相关性。
Correlations for Set-2y1 y2 y3y1 1.0000 .6957 .4958y2 .6957 1.0000 .6692y3 .4958 .6692 1.0000数据集2中变量y1-y3的相关关系,有相关系数知,y1与y2有较强的相关性。
Correlations Between Set-1 and Set-2y1 y2 y3x1 -.3897 -.4931 -.2263x2 -.5522 -.6456 -.1915x3 .1506 .2250 .0349x1-x3与y1-y3的相关关系,x1,x2与y1-y3是负相关关系,说明体重和腰围较大对运动能力具有负影响。
Canonical Correlations1 .7962 .2013 .073表示三个典型相关系数Test that remaining correlations are zero:Wilk's Chi-SQ DF Sig.1 .350 16.255 9.000 .0622 .955 .718 4.000 .9493 .995 .082 1.000 .775对三个典型相关系数的显著性检验,原假设是相关系数为0,在显著性水平为0.1上,第一个典型相关系数对应的Sig.为0.062<0.1,拒绝原假设,认为第一个典型相关系数不为0.第二和第三个典型相关系数对应的Sig.>0.1,认为二者均为0。

多元统计分析——典型相关分析典型相关分析(Canonical correlation analysis)是一种多元统计分析方法,用于研究两组变量之间的关联性。
与传统的相关分析不同,典型相关分析可以同时考虑多组变量,找出最佳的线性组合,使得两组变量之间的相关性最大化。
它主要用于探索一组自变量与另一组因变量之间的线性关系,并且可以提供详细的相关性系数、特征向量和特征值等信息。
典型相关分析的基本原理是将两组变量分别投影到最佳的线性组合上,使得投影后的变量之间的相关性最大。
这种投影是通过求解特征值问题来实现的,其中特征值表示相关系数的大小,特征向量表示两组变量的线性组合。
通常情况下,我们希望保留具有最大特征值的特征向量,因为它们对应着最强的相关性。
典型相关分析的应用广泛,可以用于众多领域,如心理学、社会科学、经济学等。
例如,在心理学研究中,我们可能对人们的人格特征和行为方式进行测量,然后使用典型相关分析来探索它们之间的关系。
在经济学研究中,我们可以将宏观经济指标与企业盈利能力进行比较,以评估它们之间的相关性。
典型相关分析的步骤如下:1.收集数据:首先,我们需要收集两组变量的数据。
这些数据可以是定量数据(如收入、年龄)或定性数据(如性别、职业)。
2.建立模型:然后,我们需要建立一个数学模型,用于描述两组变量之间的关系。
这可以通过线性回归、主成分分析等方法来实现。
3.求解特征值问题:接下来,我们需要求解特征值问题,以获得相关系数和特征向量。
在实际计算中,我们可以使用统计软件来完成这一步骤。
4.解释结果:最后,我们需要解释典型相关分析的结果。
通常情况下,我们会关注最大的特征值和对应的特征向量,因为它们表示着最强的相关性。
典型相关分析的结果提供了一组线性组合,这些组合可以最大化两组变量之间的相关性。
通过分析这些组合,我们可以洞察两组变量之间的潜在关系,并提供有关如何解释和预测这种关系的指导。
总结而言,典型相关分析是一种强大的多元统计分析方法,可以用于研究两组变量之间的关联性。

1典型相关分析内涵1.1典型相关分析基本概念典型相关分析(c anonical c orrelation analysis )是利用综合变量对之间的相关关系来反映两组指标之间的整体相关性的多元统计分析方法。
它的基本原理是:为了从总体上把握两组指标之间的相关关系,分别在两组变量中提取有代表性的两个综合变量U1和V1(分别为两个变量组中各变量的线性组合),利用这两个综合变量之间的相关关系来反映两组指标之间的整体相关性。
典型相关分析是由霍特林(Hotelling,1935,1936)首先提出的。
典型相关分析的目的是识别并量化两组变量之间的联系,将两组变量相关关系的分析,转化为一组变量的线性组合与另一组变量线性组合之间的相关关系分析。
目前,典型相关分析已被广泛应用于心理学、市场营销等领域,如用于研究个人性格与职业兴趣的关系,市场促销活动与消费者响应之间的关系等。
1.2 典型相关分析的基本思想典型相关分析的基本思想和主成分分析非常相似。
首先在每组变量中找出变量的一个线性组合,使得两组的线性组合之间具有最大的相关系数。
然后选取相关系数仅次于第一对线性组合并且与第一对线性组合不相关的第二对线性组合,如此继续下去,直到两组变量之间的相关性被提取完毕为止。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
典型相关系数度量了这两组变量之间联系的强度。
一般情况,设(1)(1)(1)(1)12(,,,)pX X X= X、(2)(2)(2)(2)12(,,,)q X X X = X是两个相互关联的随机向量,分别在两组变量中选取若干有代表性的综合变量Ui 、Vi ,使得每一个综合变量是原变量的线性组合,即:()(1)()(1)()(1)()(1)1122i i i i i P P U a X a X a X '=+++aX()(2)()(2)()(2)()(2)1122i i i i i q qV b X b X b X '=+++bX为了确保典型变量的唯一性,我们只考虑方差为1的(1)X 、(2)X 的线性函数()(1)i 'aX与()(2)i 'b X ,求使得它们相关系数达到最大的这一组。

典型相关分析(CCA)简介一、引言在多变量统计分析中,典型相关分析(Canonical Correlation Analysis,简称CCA)是一种用于研究两个多变量之间关系的有效方法。
这种方法最早由哈罗德·霍特林(Harold Hotelling)于1936年提出。
随着数据科学和统计学的发展,CCA逐渐成为多个领域分析数据的重要工具。
本文将对典型相关分析的基本原理、应用场景以及与其他相关方法的比较进行详细阐述。
二、典型相关分析的基本概念1. 什么是典型相关分析典型相关分析是一种分析两个多变量集合之间关系的方法。
设有两个随机向量 (X) 和 (Y),它们分别包含 (p) 和 (q) 个变量。
CCA旨在寻找一种线性组合,使得这两个集合在新的空间中具有最大的相关性。
换句话说,它通过最优化两个集合的线性组合,来揭示它们之间的关系。
2. 数学模型假设我们有两个数据集:(X = [X_1, X_2, …, X_p])(Y = [Y_1, Y_2, …, Y_q])我们可以表示为:(U = a^T X)(V = b^T Y)其中 (a) 和 (b) 是待求解的权重向量。
通过最大化协方差 ((U, V)),我们得到最大典型相关系数 (),公式如下:[ ^2 = ]通过求解多组 (a) 和 (b),我们可以获得多个典型变量,从而得到不同维度的相关信息。
三、典型相关分析的步骤1. 数据准备在进行CCA之前,需要确保数据集满足一定条件。
一般来说,应对数据进行标准化处理,以消除可能存在的量纲差异。
可以使用z-score标准化的方法来处理数据。
2. 求解协方差矩阵需要计算两个集合的协方差矩阵,并进一步求出其逆矩阵。
给定随机向量 (X) 和 (Y),我们需要计算如下协方差矩阵:[ S_{xx} = (X, X) ] [ S_{yy} = (Y, Y) ] [ S_{xy} = (X, Y) ]同时,求出逆矩阵 (S_{xx}^{-1}) 和 (S_{yy}^{-1})。

引言在一元统计分析中,用相关系数来衡量两个随机变量之间的线性相关关系;用复相关系数研究一个随机变量和多个随机变量的线性相关关系。
然而,这些统计方法在研究两组变量之间的相关关系时却无能为力。
比如要研究生理指标与训练指标的关系,居民生活环境与健康状况的关系,人口统计变量与消费变量(之间是否具有相关关系。
阅读能力变量(阅读速度、阅读才能)与数学运算能力变量(数学运算速度、数学运算才能)是否相关。
典型相关分析(Canonical Correlation )是研究两组变量之间相关关系的一种多元统计方法。
它能够揭示出两组变量之间的内在联系。
1936年霍特林(Hotelling )最早就“大学表现”和“入学前成绩”的关系、政府政策变量与经济目标变量的关系等问题进行了研究,提出了典型相关分析技术。
之后,Cooley 和Hohnes (1971),Tatsuoka (1971)及Mardia ,Kent 和Bibby (1979)等人对典型相关分析的应用进行了讨论,Kshirsagar (1972)则从理论上给出了最好的分析。
典型相关分析的目的是识别并量化两组变量之间的联系,将两组变量相关关系的分析,转化为一组变量的线性组合与另一组变量线性组合之间的相关关系分析。
目前,典型相关分析已被应用于心理学、市场营销等领域。
如用于研究个人性格与职业兴趣的关系,市场促销活动与消费者响应之间的关系等问题的分析研究。
第一章、典型相关的基本理论 1.1 典型相关分析的基本概念典型相关分析由Hotelling 提出,其基本思想和主成分分析非常相似。
首先在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。
然后选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此继续下去,直到两组变量之间的相关性被提取完毕为此。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
典型相关系数度量了这两组变量之间联系的强度。

典型相关分析典型相关分析(canonical correlation analysis)就是利用综合变量对之间的相关关系来反映两组指标之间的整体相关性的多元统计分析方法。
它的基本原理是:为了从总体上把握两组指标之间的相关关系,分别在两组变量中提取有代表性的两个综合变量1U 和1V (分别为两个变量组中各变量的线性组合),利用这两个综合变量之间的相关关系来反映两组指标之间的整体相关性。
通常情况下,为了研究两组变量12122,,,,,,,p q x x x y y y w ⎡⎤⎡⎤⋅⋅⋅⋅⋅⋅⎣⎦⎣⎦的相关系数,可以用最原始的方法,分别计算两组变量之间的全部相关系数,一共有pq 个简单相关系数,这样既繁琐又不能抓住问题的本质。
首先分别在每组变量中找出第一对线性组合,使其具有最大相关性,即1111212111112121p pq q u x x x v y y y αααβββ=++⋅⋅⋅+⎧⎪⎨=++⋅⋅⋅+⎪⎩ 然后在每组变量中找出第二对线性组合,使其分别与本组内的第一对线性组合不相关,第二对线性组合本身具有次大的相关性,有2121222221212222p pq q u x x x v y y y αααβββ=++⋅⋅⋅+⎧⎪⎨=++⋅⋅⋅+⎪⎩ 2u 与1u ,2v 与1v 不相关,但2u 与2v 相关。
如此继续下去,直至进行到r 步,两组变量的相关性被提取完为止,可以得到r 组变量,这里min(,)r p q ≤。
步骤:假设两组随机变量1212,,,,,,,p q X x x x Y y y y ⎡⎤⎡⎤=⋅⋅⋅=⋅⋅⋅⎣⎦⎣⎦,C 为p q +维总体的n 次标准化观测数据阵,有11111121221211()pq p q n np n nq n p q a a b b a a b b C a a b b ⨯+⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦ 第一步,计算相关系数矩阵R ,并将R 剖分为11122122RR R R R ⎡⎤=⎢⎥⎣⎦,其中11R 和22R 分别为第一组变量和第二组变量的相关系数阵,T1221R R =为第一组与第二组变量的相关系数阵。

SPSS典型相关分析及结果解释SPSS 11.0 - 23.0典型相关分析1方法简介如果要研究一个变量和一组变量间的相关,则可以使用多元线性回归,方程的复相关系数就是我们要的东西,同时偏相关系数还可以描述固定其他因素时某个自变量和应变量间的关系。
但如果要研究两组变量的相关关系时,这些统计方法就无能为力了。
比如要研究居民生活环境与健康状况的关系,生活环境和健康状况都有一大堆变量,如何来做?难道说做出两两相关系数?显然并不现实,我们需要寻找到更加综合,更具有代表性的指标,典型相关(Canonical Correlation)分析就可以解决这个问题。
典型相关分析方法由Hotelling提出,他的基本思想和主成分分析非常相似,也是降维。
即根据变量间的相关关系,寻找一个或少数几个综合变量(实际观察变量的线性组合)对来替代原变量,从而将二组变量的关系集中到少数几对综合变量的关系上,提取时要求第一对综合变量间的相关性最大,第二对次之,依此类推。
这些综合变量被称为典型变量,或典则变量,第1对典型变量间的相关系数则被称为第1典型相关系数。
一般来说,只需要提取1~2对典型变量即可较为充分的概括样本信息。
可以证明,当两个变量组均只有一个变量时,典型相关系数即为简单相关系数;当一组变量只有一个变量时,典型相关系数即为复相关系数。
故可以认为典型相关系1数是简单相关系数、复相关系数的推广,或者说简单相关系数、复相关系数是典型相关系数的特例。
2引例及语法说明在SPSS中可以有两种方法来拟合典型相关分析,第一种是采用Manova过程来拟合,第二种是采用专门提供的宏程序来拟合,第二种方法在使用上非常简单,而输出的结果又非常详细,因此这里只对它进行介绍。
该程序名为Canonical correlation.sps,就放在SPSS的安装路径之中,调用方式如下:INCLUDE 'SPSS所在路径\Canonical correlation.sps'.CANCORR SET1=第一组变量的列表/SET2=第二组变量的列表.在程序中首先应当使用include命令读入典型相关分析的宏程序,然后使用cancorr名称调用,注意最后的“.”表示整个语句结束,不能遗漏。

一、典型相关分析的概念典型相关分析(canonical correlation analysis )就是利用综合变量对之间的相关关系来反映两组指标之间的整体相关性的多元统计分析方法。
它的基本原理是:为了从总体上把握两组指标之间的相关关系,分别在两组变量中提取有代表性的两个综合变量U1和V1(分别为两个变量组中各变量的线性组合),利用这两个综合变量之间的相关关系来反映两组指标之间的整体相关性。
二、条件:典型相关分析有助于综合地描述两组变量之间的典型的相关关系。
其条件是,两组变量都是连续变量,其资料都必须服从多元正态分布。
三、相关计算如果我们记两组变量的第一对线性组合为:X u 11α'=Y v 11β'=),,,(121111'=p a a a α),,,(121111'=q ββββ 1)()(11111=∑'='=ααααX Var u Var 1)()(1221111=∑'='=ββββY Var v Var 11211111,),(),(11βαβαρ∑'='==Y X Cov v u Cov v u 典型相关分析就是求α1和β1,使二者的相关系数ρ达到最大。
典型相关分析希望寻求 a 和 b 使得 ρ 达到最大,但是由于随机变量乘以常数时不改变它们的相关系数,为了防止不必要的结果重复出现,最好的限制是令Var (U )=1 和Var (V )= 1。
A 关于的特征向量(a i1,a i2,…,a ip ),求B 关于的特征向量(bi 1,b i2,…,bi p ) 5、计算Vi 和Wi ;iλi λ()p X X X,...,1=()q Y Y Y ,...,1=1.实测变量标准化; 2.求实测变量的相关阵R ;3.求A 和B ;4、求A 和B 的特征根及特征向量;1111111111111111()()pq p pp p pq xxxy yxyy p q q qpq qq p q p q r r r r r r r r R R XX XY R R R YXYY r r r r r r r r +⨯+⎛⎫⎪⎪ ⎪⎛⎫⎛⎫ ⎪=== ⎪⎪ ⎪ ⎪⎝⎭⎝⎭ ⎪⎪⎪⎝⎭∑∑∑∑ ()()()()∑∑∑∑∑∑∑∑----==XYXX YX YY B YXYY XY XX A 1111pλλλ≥≥≥...21p ip i i i X b X b X b V +++=...2211qiq i i i Y a Y a Y a W +++= (2211)6、Vi 和Wi 的第i 对典型相关系数应用典型相关分析的场合是:可以使用回归方法,但有两个或两个以上的因变量;特别是因变量或准则变量相互间有一定的相关性,无视它们之间相互依赖的关系而分开处理,研究就毫无意义。
典型相关分析典型相关分析是一种统计学方法,用于研究两组变量之间的关系。
典型相关分析可以帮助我们了解这两组变量之间的相互关系以及它们是否能够彼此预测。
在本文中,我们将探讨典型相关分析的基本概念、应用场景、计算方法以及结果的解释和解读。
典型相关分析,又称为典型相关系数分析,是一种多变量统计技术,它可以在两组变量之间寻找最具相关性的线性组合,这个线性组合被称为典型变量。
典型相关分析的核心思想是将两组变量转化为一组最具相关性的综合变量,以便探索和解释它们之间的关系。
典型相关分析通常用于探索两组变量之间的关系,并确定是否存在一个或多个典型相关系数。
在许多实际应用中,这些变量可能代表相互关联的特征或维度,比如市场规模和销售额、学习时间和考试成绩等。
典型相关分析可以用于许多领域的研究。
例如,在市场研究中,我们可以使用典型相关分析来研究不同市场因素之间的关系,并确定市场的发展趋势。
在教育研究中,我们可以使用典型相关分析来研究学生的学习习惯和学术成绩之间的关系,以帮助教育者改进教学方法和学习环境。
接下来,我们将介绍典型相关分析的计算方法。
假设我们有两组变量X和Y,其中X包含p个变量,Y包含q个变量。
首先,我们计算X和Y的样本协方差矩阵SXX和SYY,以及它们之间的协方差矩阵SXY。
然后,我们对SXX和SYY进行特征值分解,得到它们的特征向量和特征值。
接下来,我们选择最大的r个特征值和对应的特征向量。
最后,我们计算典型相关系数以及典型变量。
结果的解释和解读是典型相关分析的最后一步。
典型相关系数的取值范围为-1到1,其中取值为1表示两组变量之间存在完全正相关的关系,取值为-1表示存在完全负相关的关系,取值为0表示两组变量之间不存在相关性。
此外,我们还可以通过检验统计量来判断典型相关系数是否显著。
总结起来,典型相关分析是一种统计学方法,用于研究两组变量之间的关系。
它可以帮助我们了解这两组变量之间的相互关系以及它们是否能够彼此预测。
典型相关分析报告
典型相关分析是一种统计分析方法,用于探索两个变量集之间的关联性。
典型相关分析报告通常包含以下内容:
1. 研究目的和背景:介绍研究目的、问题背景和研究假设。
2. 数据收集和描述统计分析:描述数据收集过程,包括样本选择、数据收集方式等。
给出变量的描述统计指标,如均值、标准差等。
3. 相关性分析:使用Pearson相关系数或Spearman相关系数等方法,计算两个变量集之间的相关性。
分析结果包括相关系数大小和统计显著性。
4. 典型相关方程:使用典型相关分析方法,建立典型相关方程,给出典型相关系数和解释方程的意义。
5. 判定系数:给出典型相关方程的判定系数,用于评估模型的拟合程度。
6. 解释和讨论:解释典型相关方程的结果,讨论两个变量集之间的关系和影响因素。
分析结果可以结合相关文献进行解释和比较。
7. 结论和建议:总结研究结果,给出结论并提出进一步研究的建议。
需要注意的是,在编写典型相关分析报告时,应注意结果的客观性和准确性,同时要遵循科学研究的规范和方法。
典型相关分析(CCA)简介典型相关分析(Canonical Correlation Analysis,简称CCA)是一种统计方法,用于研究两组变量之间的关系。
它可以帮助我们找到两组变量之间的最大相关性,从而揭示它们之间潜在的联系和模式。
在本文中,我们将介绍CCA的基本概念、原理和应用领域,帮助读者更好地理解和运用这一方法。
### 1. CCA的基本概念典型相关分析是一种多元统计分析方法,通常用于研究两组变量之间的关系。
在CCA中,我们有两组变量X和Y,每组变量包含多个变量。
我们的目标是找到一组线性组合,使得这两组线性组合之间的相关性最大化。
换句话说,CCA寻找一对典型变量,使它们之间的相关性达到最大。
### 2. CCA的原理CCA的原理可以通过数学公式来解释。
假设我们有两组变量X和Y,它们分别表示为X = [X1, X2, ..., Xm]和Y = [Y1, Y2, ..., Yn],其中m和n分别表示X和Y中变量的个数。
我们可以将X和Y表示为线性组合的形式:X' = a1X1 + a2X2 + ... + amXmY' = b1Y1 + b2Y2 + ... + bnYn其中a和b分别是X和Y的系数向量。
我们的目标是找到a和b,使得X'和Y'之间的相关性最大。
具体来说,CCA通过最大化X'和Y'的相关系数来实现这一目标。
### 3. CCA的应用领域CCA在多个领域都有广泛的应用,包括金融、生物医学、社会科学等。
在金融领域,CCA常用于分析不同资产之间的关联性,帮助投资者构建有效的投资组合。
在生物医学领域,CCA可以用于研究基因表达数据和临床特征之间的关系,帮助科研人员发现潜在的生物标志物。
在社会科学领域,CCA可以用于分析不同变量之间的关系,揭示社会现象背后的模式和规律。
### 结语典型相关分析(CCA)是一种强大的统计方法,可以帮助研究人员揭示两组变量之间的关系。
典型相关分析典型相关分析利用综合变量的相关关系来反映两组指标之间的整体相关性的多元统计分析方法。
1. 典型相关分析的基本思想。
典型相关分析沿用了主成份分析的思想,在研究的两组变量()1,,p X X X = 与()1,,q Y Y Y = 中各自寻找一个综合变量(实际观测变量的线性组合)来代替原始观测变量组,从而将两组变量的关系集中到一对综合变量的关系上,整个问题转为两个变量之间的简单相关分析问题。
当然这个综合变量除了要求是满足所含的信息量尽可能大以外,提取时还要求两边提取出这一对综合变量的相关性尽可能大,通过对这对综合变量之间的相关性分析,来回答两组原始变量间相关性的问题。
有时候一对这样的综合变量代表性还不充分,可以依照同样的思想找出第二对、第三对,依次类推。
这些综合变量被称为典型变量,他们的相关系数则被称为典型相关系数。
典型相关系数是能简单完整第描述两组变量间关系的指标。
2. 典型相关系数与典型相关变量。
设()1,,'p X X X = ,()1,,'q Y Y Y = 是两个随机向量。
利用主成份思想寻找第i 对典型相关变量(),i i U V :1122'i i i ip p i U a X a X a X a X =+++= 1122'i i i iq q i V b Y b Y b Y b Y =+++=其中()1,2,,min ,i m p q == ;称'i a 和'i b 为(第i 对)典型变量系数或典型权重。
记第一个典型相关系数为()111,canR corr U V =(使1U 与1V 间最大相关);第二个典型相关系数为:()222,canR corr U V =(与1U ,1V 无关;使2U 与2V 间最大相关);第m 个典型相关系数为:(),m m m canR corr U V =(与1U ,1V ,... 11,m m U V --无关;使m U 与m V 间最大相关)。