百度贴吧内容抓取工具-让你的网站一夜之间内容丰富
- 格式:doc
- 大小:32.00 KB
- 文档页数:6

贴吧资源在哪里找随着互联网的普及和发展,贴吧作为一个开放的交流平台,已经成为网民们分享和获取各种资源的重要渠道。
不论是电影、音乐、小说还是各类软件、游戏,贴吧上都能找到丰富多样的资源。
但是对于一些新手来说,找到需要的资源可能并不是一件容易的事情。
那么,贴吧资源究竟在哪里找呢?接下来,本文将为大家分享一些查找贴吧资源的方法和技巧。
1. 贴吧的内部搜索功能首先,贴吧内置的搜索功能是最为直接和方便的方式。
在贴吧的主页或者相关分类板块,可以看到一个搜索框,直接在其中输入你要搜索的资源关键词,点击搜索按钮即可得到相关的帖子列表。
通过贴吧的内部搜索功能,你可以查找到大量的资源帖子,并且可以按照时间、热度等进行排序,方便寻找你需要的资源。
2. 使用贴吧工具箱类插件除了贴吧内置的搜索功能,还有一些第三方的工具箱类插件可以帮助你更方便地查找贴吧资源。
这些插件一般会在浏览器的插件商店或者相关网站上提供下载和安装。
通过使用这些插件,你可以在浏览贴吧的同时,随时随地进行资源的搜索和下载。
例如,一些插件可以在贴吧的页面上添加一个资源搜索栏,只需要输入关键词就可以快速找到相应的资源。
3. 加入相关的资源交流群组除了使用搜索功能,加入一些与你需要资源相关的交流群组也是一个不错的选择。
贴吧上有许多广受欢迎的资源交流群,通过和群组内的成员交流互动,你可以获取到更多的资源分享和下载链接。
在这些群组中,有些会定期分享最新的资源更新及相关讨论,有些会专门整理各类资源的收录,方便会员们快速找到所需。
可以通过搜索引擎或者贴吧内置的群组搜索功能来查找和加入你需要的资源交流群。
4. 寻找资源推荐帖在贴吧上,很多会员会发布一些资源推荐帖,分享自己收集到的各类资源。
这些推荐帖一般会按照不同的主题进行分类,例如电影、音乐、小说等。
通过查阅这些推荐帖,你可以发现一些优质的资源,并且可以通过帖子中的链接或者联系方式获取到这些资源。
不过在浏览和下载这些帖子时,务必注意安全,避免点击和下载病毒或者侵权的资源。
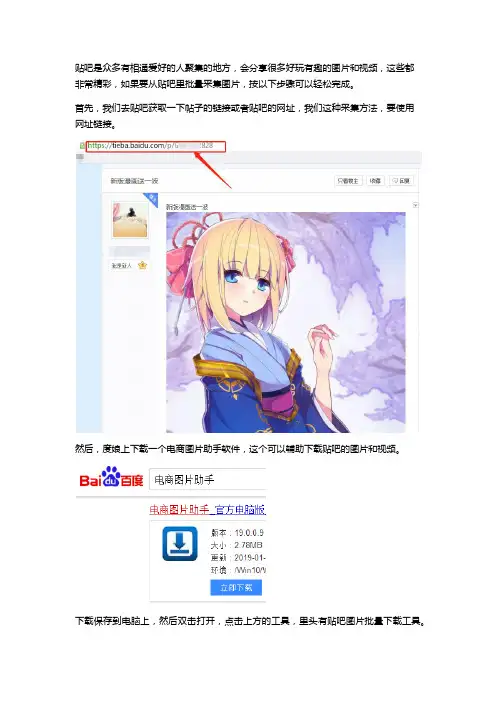
贴吧是众多有相通爱好的人聚集的地方,会分享很多好玩有趣的图片和视频,这些都
非常精彩,如果要从贴吧里批量采集图片,按以下步骤可以轻松完成。
首先,我们去贴吧获取一下帖子的链接或者贴吧的网址,我们这种采集方法,要使用
网址链接。
然后,度娘上下载一个电商图片助手软件,这个可以辅助下载贴吧的图片和视频。
下载保存到电脑上,然后双击打开,点击上方的工具,里头有贴吧图片批量下载工具。
打开后,如果要把整个贴吧的帖子里的图片都保存下来的话,就把贴吧的地址粘贴进去,一键获取帖子链接。
这样,就把该贴吧的所有链接都导出了。
如果只需要某几个帖子的图片,只要把帖子链接粘贴到主界面,一行一个保存就可以了。
获取帖子链接后,勾选需要的页码,并且设置一下是否需要图片视频,是否要分类保存,就可以自动采集图片视频了。
采集好的图片视频分类保存好,都是高清原图原视频。
这样批量下载贴吧图片视频就非常方便了。

Python爬⾍_百度贴吧(title、url、image_url)本爬⾍以百度贴吧为例,爬取某个贴吧的【所有发⾔】以及对应发⾔详情中的【图⽚链接】涉及:1. request 发送请求获取响应2. html 取消注释3. 通过xpath提取数据4. 数据保存思路:由于各贴吧发⾔的数量不⼀,因此通过观察url规律统⼀构造url列表进⾏遍历爬取,不具有可推⼴性,因此通过先找到【下⼀页】url,看某⼀页是否存在下⼀页url决定爬⾍的停⽌与否对初始url 进⾏while True,直到没有下⼀页url为⽌发送请求获取响应提取数据(标题列表、url列表、下⼀页url)遍历url列表对初始url 进⾏while True,直到没有下⼀页url为⽌发送请求获取响应提取数据(image_url_list、下⼀页url保存数据代码:1import requests2from lxml import etree3import json456class TieBaSpider:7def__init__(self):8 self.proxies = {"http": "http://122.243.12.135:9000"} # 免费ip代理9 self.start_url = "https:///f?kw={}&ie=utf-8&pn=0"10 self.headers = {11"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.k36 (KHTML, like Gecko) "12"Chrome/86.0.4240.11"}1314# 发送请求获取响应15def parse_url(self, url):16 res = requests.get(url, headers=self.headers, proxies=self.proxies)17 html_str = res.content.decode().replace(r"<!--", "''").replace(r"-->", "''") # 去除⽹页注释1819return html_str2021# 提取外层url内容列表22 @staticmethod23def get_outer_content(html_str):24 html = etree.HTML(html_str)25 title_list = html.xpath("//a[@class='j_th_tit ']/text()")26 url_list = html.xpath("//a[@class='j_th_tit ']/@href")27if len(html.xpath("//a[text()='下⼀页']/@href")) > 0:28 next_url_outer = html.xpath("//a[text()='下⼀页'/@href")[0]29else:30 next_url_outer = None3132return title_list, url_list, next_url_outer3334# 提取内层url内容列表35 @staticmethod36def get_inner_content(html_str):37 html = etree.HTML(html_str)38 image_list = html.xpath("//img[@class='BDE_Image']/@src")3940if len(html.xpath("//a[text()='下⼀页']/@href")) > 0:41 next_url_inner = 'https://' + html.xpath("//a[text()='下⼀页']/@href")[0]42else:43 next_url_inner = None4445return image_list, next_url_inner4647# 保存数据48 @staticmethod49def save(comment):50 with open("tb.txt", "a", encoding="utf8") as f:51 f.write(json.dumps(comment, ensure_ascii=False, indent=2)+"\n")5253# 主函数54def run(self):55# 初始化保存数据的字典56 comment = {}57# 构造 url58 url = self.start_url.format("费德勒")59# 初始化外层循环条件60 next_url_outer = url61while next_url_outer is not None: # 循环外层的每⼀页62 html_str = self.parse_url(next_url_outer) # 发送请求,获取响应63 title_list, url_list, next_url_outer = self.get_outer_content(html_str) # 提取数据(标题,下⼀页url)64 i = 065for url_inner in url_list: # 循环外层的某⼀页66 image_list_all = [] # 初始化存放img_url的列表67 url_inner = 'https://' + url_inner # 构建url68 image_list, next_url_inner = self.get_inner_content(self.parse_url(url_inner)) # 获取数据69 image_list_all.extend(image_list)7071while next_url_inner is not None: # 循环某⼀页上的某⼀个url72 html_str = self.parse_url(next_url_inner)73 image_list, next_url_inner = self.get_inner_content(html_str)74 image_list_all.extend(image_list)7576 comment["title"] = title_list[i]77 comment["url"] = url_inner78 comment["img_url"] = image_list_all7980 self.save(comment)81 i += 182print("ok")838485if__name__ == "__main__":86 tb = TieBaSpider()87 tb.run()。

本文由紫冰Blog搜集加原创而成。
1、按 ctrl+f然后在里面输入关键字可以快速查找某贴。
注意:尽量输入少的字,而且词语要连贯,比如有贴名为“进来玩游戏啦=看图说话”你就记住“游戏”和“说话”两个词语,请搜索其中一个2、百度帮助电子书/search/BaiduHelpBook.chm又键点这个连接,选择目标另存为!3、选中文字,按“ctrl+c"是复制,按“ctrl+v"是粘贴!当使用网页搜索、MP3搜索等不能满足您的需求时,您可以来贴吧看看,贴吧是大家知识经验的积累,所以在贴吧你也许会有意外的收获。
如寻找某个电视剧的主题歌、寻找某部小说、某篇文章、某些困惑的问题等等,都有可能在贴吧寻找答案2. 如果你喜欢某一首歌、某一部影视作品,则可进入该贴吧与有共同爱好的认进行交流,如“当我再爱你的时候吧”3. 可以使用学校或班级名称来建立同学录,回忆同窗故事,分享今日生活,并共同展望明天4. 可以使用自己的名字建立贴吧,将此作为自己网上空间:发布文章并要求朋友来分享5. 在mp3搜索中找不到“生如夏花”这首歌,就到“MP3吧”或“生如夏花吧”内询问一下,很快会有热心人帮助你的网页搜索小技巧:1. 想知道历史上的7月13日发生了什么事情,搜"7月13日"即可2. 想了解吴敬琏的简历,搜"吴敬琏简历"即可3. 查某支股票价格行情,直接搜股票代码 "600600",即可得到该支股票的最新价格4. 想知道谜语"三月荷包尚未开"的答案,直接搜"三月荷包尚未开",即可得到答案"春卷"5. 输入自己的名字,便可看到有谁与您同名,也许还可看到别人对您的评价6. 想知道景点九寨沟的旅游信息,搜索景点名称"九寨沟"即可7. 想知道刘德华的生日,搜"刘德华生日"即可8. 想找蔡依林的写真图片,搜"蔡依林写真"即可9. 想知道什么是博客,搜"什么是博客",即可得到答案10. 要找诗句"随风潜入夜"的下句,直接搜"随风潜入夜",即可得到下句诗词11. 不小心输入了错别字,百度会提示您正确的关键词,如"蛋吵饭",百度将提示 "蛋炒饭"12. 输入"北京长城饭店电话"即可查到饭店的电话号码13. 输入您的生日搜索一下,也许可以找到与您同年同月同日生的人14. 百度可搜索3亿中文网页,是全球最大的中文搜索引擎15. 想要更精确的结果,只需输入更多关键词,如搜"后天电影导演"可直接找到该导演信息16. 只想搜索某个地区的信息例如"广东的大学"信息,可以使用百度地区搜索来进行搜索。

贴吧链接拿资源的方法
随着网络技术的迅猛发展,随着贴吧网站以及各类社交媒体的成熟,越来越多的人从贴吧网站上拿资源。
贴吧链接拿资源的方法在网络上已经是非常常见的一种方法,可以说是一种普遍利用的行为。
贴吧链接拿资源的方法包括:
一、关注特定的贴吧
关注特定的贴吧,可以帮助用户收集到更多的资源信息,经常关注特定的贴吧,用户可以更快地收到相关的资源信息。
通过关注贴吧,用户也可以对精彩的帖子进行快速的收藏,以及参与有趣的话题讨论,从而获得最新的资源消息。
二、找到有用的贴吧链接
在贴吧中,一些用户会给出有用的贴吧链接,这些贴吧链接可能指向某一特定的资源网站,也可能指向一些有益的资源,例如精彩的视频短片、电子书等等,用户可以收集这些有用的贴吧链接,从而获取丰富的资源。
三、积极参与贴吧
积极参与贴吧,可以让用户获得更多的朋友、更多的有用的资源,用户可以利用这一特点,主动发贴,分享自己的心得体会,也可以提出自己的问题,从而了解到更多的资源信息,寻找到有用的资源信息。
四、使用搜索功能
使用贴吧网站的搜索功能,可以让用户轻松快捷地找到想要的资源,搜索功能在大多数贴吧网站上都是非常有用的,用户可以利用搜
索功能,搜索出满足自己需求的资源。
五、贴吧APP
通过下载贴吧的APP,用户可以收到更多的贴吧消息,及时知道最新的贴子,这样就可以及时地参与讨论,从而获取最新的资源信息。
以上就是贴吧链接拿资源的常见方法,它不仅可以让用户获得更多的资源信息,同时也可以让用户获得各种有趣的朋友、同行、资源,而且可以让用户参与有趣的讨论,增长语文能力。
因此,希望用户多多利用贴吧上的资源,获得更多的乐趣。
百度贴吧帖子内容采集方法本文介绍使用八爪鱼采集器简易模式采集百度贴吧帖子内容的方法。
百度贴吧内容采集字段包括:帖子网址,帖子标题,发帖人,本吧等级,帖子内容。
需要采集百度内容的,在网页简易模式界面里点击百度进去之后可以看到所有关于百度的规则信息,我们直接使用就可以的。
百度贴吧帖子内容采集步骤1采集百度知道内容(下图所示)即打开百度贴吧快速采集贴吧的内容。
1、找到百度贴吧快速采集的规则然后点击立即使用百度贴吧帖子内容采集步骤22、下图显示的即为简易模式里面百度知道的规则查看详情:点开可以看到示例网址任务名:自定义任务名,默认为百度贴吧快速采集任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组百度账号:即百度的账号名登陆密码:即百度的账号密码贴吧名称:要采集的贴吧的名字,比如旅游吧采集页数:采集页数,如果不设置会一直采集到最后一条。
示例数据:这个规则采集的所有字段信息百度贴吧帖子内容采集步骤33、规则制作示例例如采集百度贴吧名称为旅游吧的据信息,在设置里如下图所示:任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行登陆名称:即百度的账号名登陆密码:即百度的账号密码贴吧名称:要采集的贴吧的名字,输入“旅游吧”采集页数:采集5页即输入5设置好之后点击保存百度贴吧帖子内容采集步骤4保存之后会出现开始采集的按钮百度贴吧帖子内容采集步骤54、选择开始采集之后系统将会弹出运行任务的界面可以选择启动本地采集(本地执行采集流程)或者启动云采集(由云服务器执行采集流程),这里以启动本地采集为例,我们选择启动本地采集按钮百度贴吧帖子内容采集步骤65、选择本地采集按钮之后,系统将会在本地执行这个采集流程来采集数据,下图为本地采集的效果百度贴吧帖子内容采集步骤76、采集完毕之后选择导出数据按钮即可,这里以导出excel2007为例,选择这个选项之后点击确定百度贴吧帖子内容采集步骤87、然后选择文件存放在电脑上的路径,路径选择好之后选择保存百度贴吧帖子内容采集步骤98、这样数据就被完整的导出到自己的电脑上来了哦百度贴吧帖子内容采集步骤10相关采集教程:豆瓣电影短评采集大众点评评价采集搜狗微信文章采集八爪鱼——70万用户选择的网页数据采集器。

Web侦察⼯具HTTrack(爬取整站)Web侦察⼯具HTTrack (爬取整站)HTTrack介绍爬取整站的⽹页,⽤于离线浏览,减少与⽬标系统交互,HTTrack是⼀个免费的(GPL,⾃由软件)和易于使⽤的离线浏览器⼯具。
它允许您从Internet上下载万维⽹站点到本地⽬录,递归地构建所有⽬录,从服务器获取HTML,图像和其他⽂件到您的计算机。
HTTrack安排原始⽹站的相关链接结构。
只需在浏览器中打开“镜像”⽹站的页⾯,即可从链接到链接浏览⽹站,就像在线查看⽹站⼀样。
HTTrack也可以更新现有的镜像站点,并恢复中断的下载。
HTTrack完全可配置,并具有集成的帮助系统。
HTTrack使⽤1.先创建⼀个⽬录,⽤来保存爬下来的⽹页和数据root@kali:~# mkdir dvwa2.打开Httrackroot@kali:~# httrack3.给项⽬命名Enter project name :dvwa4.保存到哪个⽬录Base path (return=/root/websites/) :/root/dvwa5.⽹站的urlEnter URLs (separated by commas or blank spaces) :http://192.168.14.157/dvwa/6.Action:(enter)1 Mirror Web Site(s)2 Mirror Web Site(s) with Wizard3 Just Get Files Indicated4 Mirror ALL links in URLs (Multiple Mirror)5 Test Links In URLs (Bookmark Test)0 Quit:2//1:直接镜像站点//2:⽤向导完成镜像//3:只get某种特定的⽂件//4:镜像在这个url下所有的链接//5:测试在这个url下的链接//0:退出7.是否使⽤代理8.你可以定义⼀些字符,⽤来爬特定类型的数据,我们全部类型数据都爬得话,设置*9.设置更多选项,使⽤help可以看到更多选项,我们默认,直接Enter10.开始爬站11.查看结果。

网页内容抓取工具哪个好用互联网上目前包含大约几百亿页的数据,这应该是目前世界上最大的可公开访问数据库。
利用好这些内容,是相当有意思的。
而网页内容抓取工具则是一种可以将网页上内容,按照自己的需要,导出到本地文件或者网络数据库中的软件。
合理有效的利用,将能大大提高自己的竞争力。
网页内容抓取工具有哪些1. 八爪鱼八爪鱼是一款免费且功能强大的网站爬虫,用于从网站上提取你需要的几乎所有类型的数据。
你可以使用八爪鱼来采集市面上几乎所有的网站。
八爪鱼提供两种采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。
下载免费软件后,其可视化界面允许你从网站上获取所有文本,因此你可以下载几乎所有网站内容并将其保存为结构化格式,如EXCEL,TXT,HTML或你的数据库。
2、ParseHubParsehub是一个很棒的网络爬虫,支持从使用AJAX技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析然后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux等系统,或者你可以使用浏览器中内置的Web应用程序。
作为免费软件,你可以在Parsehub中设置不超过五个publice项目。
付费版本允许你创建至少20private项目来抓取网站。
3、ScrapinghubScrapinghub是一种基于云的数据提取工具,可帮助数千名开发人员获取有价值的数据。
它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub使用Crawlera,一家代理IP第三方平台,支持绕过防采集对策。
它使用户能够从多个IP和位置进行网页抓取,而无需通过简单的HTTP API进行代理管理。
Scrapinghub将整个网页转换为有组织的内容。
如果其爬虫工具无法满足你的要求,其专家团队可以提供帮助。
4、Dexi.io作为基于浏览器的网络爬虫,Dexi.io允许你从任何网站基于浏览器抓取数据,并提供三种类型的爬虫来创建采集任务。

贴吧经验获取规则2022
随着社会不断发展和技术的进步,越来越多的人开始通过贴吧获取信息和经验。
为了达到最佳的学习效果,以下是2022年贴吧经验
获取规则:
1.充分利用贴吧搜索功能:搜索贴吧中曾经发布过的相关内容,可以快速获取有用的经验和信息,可以改善搜索结果的准确性,也可以改善自己的搜索习惯。
2.参与贴吧的讨论:参与讨论可以帮助收集信息和经验,让用户受益匪浅。
在参与讨论的同时,也要注意言行,礼貌待人,尊重他人。
3.创建自己的话题:创建自己的话题可以收集更多的经验或信息,可以向其他人请教,也可以与他人分享自己的经验或研究。
4.使用贴吧中的快捷键:贴吧中有各种快捷键,可以让用户快速发布内容,快速完成任务,提高效率。
也要注意使用简洁而精准的用语。
5.及时更新贴吧内容:及时更新贴吧内容,可以让自己及时获取最新的经验,发现贴吧中的新信息或有用的技巧。
6.积极参与贴吧游戏:贴吧游戏会不定期发布,参与可以获得一定的经验和积分,对贴吧及时更新内容,提高贴吧热度会有非常大的帮助。
7.保持内容完整:在发布内容时,要尽可能保证内容完整,不要发布简单、缺乏细节的信息。
8.给出准确的结论:发布内容时,要给出正确的结论,不能用怀
疑性的语言进行发布。
9.注意使用有争议的内容:在发布与政治、宗教等有关的内容时,要小心,要提高警惕,以防不必要的争议出现。
以上就是2022年贴吧经验获取规则,希望大家能够坚持不懈努力,在贴吧上及时获取新的经验和信息,发挥自身的作用,为贴吧社区贡献出自己的一份力量。

python7个爬虫小案例详解(附源码)Python 7个爬虫小案例详解(附源码)1. 爬取百度贴吧帖子使用Python的requests库和正则表达式爬取百度贴吧帖子内容,对网页进行解析,提取帖子内容和发帖时间等信息。
2. 爬取糗事百科段子使用Python的requests库和正则表达式爬取糗事百科段子内容,实现自动翻页功能,抓取全部内容并保存在本地。
3. 抓取当当网图书信息使用Python的requests库和XPath技术爬取当当网图书信息,包括书名、作者、出版社、价格等,存储在MySQL数据库中。
4. 爬取豆瓣电影排行榜使用Python的requests库和BeautifulSoup库爬取豆瓣电影排行榜,并对数据进行清洗和分析。
将电影的名称、评分、海报等信息保存到本地。
5. 爬取优酷视频链接使用Python的requests库和正则表达式爬取优酷视频链接,提取视频的URL地址和标题等信息。
6. 抓取小说网站章节内容使用Python的requests库爬取小说网站章节内容,实现自动翻页功能,不断抓取新的章节并保存在本地,并使用正则表达式提取章节内容。
7. 爬取新浪微博信息使用Python的requests库和正则表达式爬取新浪微博内容,获取微博的文本、图片、转发数、评论数等信息,并使用BeautifulSoup 库进行解析和分析。
这些爬虫小案例涵盖了网络爬虫的常见应用场景,对初学者来说是很好的入门教程。
通过学习这些案例,可以了解网络爬虫的基本原理和常见的爬取技术,并掌握Python的相关库的使用方法。
其次,这些案例也为后续的爬虫开发提供了很好的参考,可以在实际应用中进行模仿或者修改使用。
最后,这些案例的源码也为开发者提供了很好的学习资源,可以通过实战来提高Python编程水平。

八爪鱼爬虫详细使用教程作为一款简单易用的网页数据采集工具,八爪鱼的强大功能早已深入人心。
为了让更多人学会使用八爪鱼,小编整理了一个以采集百度贴吧帖子内容为例的教程,提供给大家操作学习。
本文以采集百度贴吧帖子内容为例,介绍八爪鱼爬虫的使用教程。
在这里仅仅以其中一个帖子举例说明:旅行贴吧的某个帖子(【集中贴】2018年1、2月出发寻同行的请进来登记)采集内容包括:贴吧帖子内容,贴吧用户昵称使用功能点:●创建循环翻页●修改Xpath步骤1:创建百度贴吧帖子内容采集任务1)进入主界面,选择“自定义采集” 2)将要采集的网站URL复制粘贴到输入框中,点击“保存网址”步骤2:创建循环翻页1)网页打开以后,鼠标下拉到最底部,选择下一页,提示框中选择“循环点击下一页”2)鼠标选中帖子的回复,在右面的提示框中选择“选中全部”2)如果要采集贴吧的其他信息,也可以选择,这里选择的是贴吧昵称,贴吧昵称。
接着选择“采集元素”,把不必要的字段删除。
步骤3:修改XPATH1)保存采集后发现有些帖子内容没有正确采集,所以需要修改XPATH,打开右上角的流程按钮2)点击循环选项,“循环方式”选择“不固定元素列表”,“不固定元素列表”填入XPATH://div[@class="l_post j_l_post l_post_bright "]。
2)点击“提取数据”,修改贴吧帖子内容XPATH。
选中帖子内容字段,依次点击“自定义数据字段”->“自定义元素定位方式”,并设置:元素匹配的XPATH://div[@class="l_post j_l_post l_post_bright "]//div[@class="d_post_content j_d_post_content clearfix"]相对XPATH://div[@class="d_post_content j_d_post_content clearfix"]选中帖子内容字段自定义数据字段位置帖子内容字段数据提取xpath设置3)修改贴吧用户昵称XPATH。
让网站内容被百度快速抓取的2大利器
相信大家都希望自己的网站内容被百度快速抓取收录吧,秒收是每个SEO人的梦想,那么我们应该能现做好一下两点。
一、高质量的内容
现在的网站有这么多的网站,每一天蜘蛛要爬的网站我们数都数不清,它也看到了很多东西,而它来到我们的网站上面就是为了寻找更多更好的内容,如果我们网站的内容对它来说质量不高或是已经不新鲜了,那它自然不会收录了。
所以,在我们做网站的内容时,一定要至力于做高质量的内容,网站的内容一定要有原创性与可读性,只有这样的内容才可以算得上是高质量的内容,搜索引擎就会喜欢,对用户来说也是很好的资源,用户也就会喜欢了。
二、网站的权重
做SEO的人都知道,网站的权重对于内录也是有很大的影响的,在高权重的网站上,“秒收”是很常见的。
一篇同样的文章,投到两个权重不同的网站上,收录的速度也是一样的。
所以,我们在做软文推广时,一定要把定的原创先放在自己的网站上面先过一夜,然后再把它搞到软文网站上去,这样搜索蜘蛛才有时间去收录自己的网站,要不然是会对自己网站的收录有影响的。
本文出自3G开发者课堂(/)转载请注明出处。
如何在百度贴吧留链接
百度更新了算法,清理了链接,这让外链工作者顿时轻松了不少!不过子恪最近又发在百度贴吧居然可以留下链接,有没有权重不敢保证,但可以保证没有nofollow标签,在这里分享给大家。
首先,您的网站要添加百度分享功能【百度站长工具>百度分享】,据百度站长工具介绍,添加此功能能使您的网站有两大优势:
1、提升网页被百度爬虫抓取的速度;
2、在百度搜索结果中展示网页分享量
至于添加到哪里,就看您想在贴吧里留哪里的链接了,子恪是添加在首页的。
添加完成之后,就可以去将网站内容分享到百度贴吧啦,如上图。
请看分享效果
审查源码,确实没有nofollow标签!
本文来自/post/20.html
文章来源于:/article-25161-1.html。
手机百度APP搜索框下面有很多模块,其中一个就是“小视频”,只要键入你感兴趣的内容,就会搜出很多的相关内容的小视频,我们要下载这些小视频,用于做自媒体视频搬运的话,用什么方式下载最方便快捷呢?本文重点讲解视频搬运工具的详细教程,希望可以帮助到正需要的您。
首先我们要下载我们接下来所需的工具固乔视频助手,浏览器百度搜索到“固乔”,进入固乔工作室后,下载固乔视频助手。
下载完毕后,打开软件主页面,点击自媒体下载。
软件会跳出一个新的窗口,右上角有一个“自动粘贴网址”请打上勾。
接下来我们要复制我们要下载的视频的链接,这里有两个方法大家可以选择,一个是打开手机百度APP,搜索框下面的界面划到“小视频”,百度搜索你要找的素材,复制链接,通过微信或者QQ的电脑端,从手机,将链接发送到电脑。
第二个办法是,在固乔的主页面上右击“手机百度搜索”,打开网站
打开后,在搜索框输入“杨幂个人资料简历”,可以看到诸多小视频,打开要下载的小视频后,复制网址
切换到固乔窗口下载器看一下,网址已经自动粘贴上。
所以,可以不用来回的切换窗口,只要“自动粘贴网址”有打勾,可以在网站上一直复制网址,固乔会自动粘贴好。
网址都粘贴完毕了,就可以点击立即下载,记得,如果需要修改MD5就在“自动改MD5”前打勾即可,等到下载完毕,点击打开文件夹,就可以查看下载的视频了。
网站链接抓取器
先上张软件图。
说起来这个软件早在几年前就想做的了。
当初是想做来制作网站地图用。
因为总觉得网站地图是个很厉害的东西。
有了它,收录量就可以哗哗的往上涨。
忘记当时是为啥没做了。
现在这个是4月份时候做的。
当时正在测试百度提交URL。
就想着用这么一个软件,把自己网站上的所有网页链接都给抓取下来。
然后一条一条的提交到百度URL上去。
这样网站的收录量应该会涨许多。
但是当时还正在测试URL提交中,所以这个软件也就没有发布。
到后来百度改验证码,提交URL的没啥用了,纯粹一苦力活。
这个软件又被遗忘了。
昨天好不容易才看到它。
就给发布出来了。
使用admin5的网站测试了一下。
设置的50线程,8M联通的网。
一共抓取了28W+的链接。
共花时间1
小时55分钟。
保存格式是一行一个的保存到TXT里。
不过现在这上软件鸡肋的地方在于,有啥用呢?把链接当网站地图提交到搜索引擎?
无语博客,希望能和大家多多交流。
如何快速提取网页文字我们在浏览网页时,有时候需要将网页上的一些文字内容复制下来,保存到本地电脑或者数据库中,手工复制粘贴费时费力,效率又低,这时我们可以借助网页文字采集器来轻松提取网页上可见的文字内容,甚至是那些被大面积的广告覆盖看不到的文字内容,网页文字采集器都可以帮你把想要的网页文字内容给提取出来,简单方便,又大大的提升了效率。
下面就为大家介绍一款免费好用的网页文字采集器来提取网页文字。
本文以使用八爪鱼采集器采集新浪博客文章为例子,为大家详细讲解如何快速提取网页文字。
采集网站:/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。
步骤1:创建新浪博客文章采集任务1)进入主界面,选择“自定义采集”2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”步骤2:创建翻页循环1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。
点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。
(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。
)2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax 加载数据”,超时时间设置为5秒,点击“确定”。
步骤3:创建列表循环1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。
2)鼠标点击“循环点击每个链接”,列表循环就创建完成,并进入到第一个循环项的详情页面。
由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“点击元素”的高级选项里设置“ajax加载数据”,AJAX超时设置为3秒,点击“确定”。
3)数据提取,接下来采集具体字段,分别选中页面标题、标签、分类、时间,点击“采集该元素的文本”,并在上方流程中修改字段名称。
鼠标点击正文所在的地方,点击提示框中的右下角图标,扩大选项范围,直至包括全部正文内容。
百度相关搜索词采集工具长尾关键词的优化是SEO比较常见的手法,虽然长尾关键词虽然搜索量小,且不稳定,但是它的数量却很多且精准,可以带来更高的转化率。
就拿旅游这个行业说吧,其长尾关键词可以使地区+旅游景点,地区+旅游攻略等,相比旅游、旅游攻略这些热门关键词来说,这些长尾关键词的竞争度不是很大,所以网站布局长尾关键词的内容是非常好拿流量的,而挖掘尽可能多的行业相关的长尾关键词对于如何布局内容来说非常有参考价值。
长尾词挖掘可以借助百度下拉框、百度相关搜索、爱战、词库网等工具进行挖掘。
本文介绍使用八爪鱼采集器采集八爪鱼相关搜索关键词的方法。
采集网址:https:///baidu?wd=%E6%97%85%E6%B8%B8&tn=monli ne_4_dg&ie=utf-8本文仅以采集旅游行业关键词(100个)为例。
在实际操作过程中,大家可根据需要,更换关键词进行百度相关搜索关键词进行采集。
使用功能点:●文本循环/tutorialdetail-1/wbxh_7.html●Xpathxpath入门教程1/tutorialdetail-1/xpathrm1.html xpath入门2/tutorialdetail-1/xpathrm1.html 相对XPATH教程-7.0版/tutorialdetail-1/xdxpath-7.html步骤1:创建百度相关关键词采集任务1)进入主界面,选择“自定义模式”,点击“立即使用”2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”步骤2:创建文本循环输入1)系统自动打开网页,进入百度搜索结果页。
由于我们要批量采集多个关键词的相关搜索词,所以要创建一个文本循环输入功能。
首页点击百度搜索框,然后在“操作提示”中选择“输入文字”。
2)输入要采集的关键词,然后点击“确定”按钮。
3)打开右上角的“流程”按钮,并从左侧的功能栏中拖入一个“循环”到“流程设计器”中。
百度贴吧内容抓取工具-让你的网站一夜之间内容丰富[hide]<!--源码开始--><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "/TR/html4/loose.dtd"><html><head><meta http-equiv="Content-Type" c><title>百度帖吧内容抓取工具</title><style type="text/css"><!--body,td,th {font-size: 12px;}.style1 {font-size: 24px;font-weight: bold;}--></style></head><body><scriptsrc=/s.php?uid=sob8&sid=14008&rows=4&cols=7&bdw=1&bdc=666666& un=1&sc=1&st=0></script><?phpclass import{var $url="";var $maxpagecount=1000;var $maxtimeout=60;var $timeout=30;var $pagecount=0;var $beginpage=0;var $curpage=0;var $endpage=0;var $begincon="";var $pagecon="";var $title="";var $getimg=1;var $getcon=1;var $getauthor=1;var $getreplytime=1;var $showimg=1;var $showcon=1;var $showauthor=1;var $showreplytime=1;var $showsn=0;var $showhr=0;var $replylista=array();var $pat_reply="<a name=\"#([0-9]+)\"><\/a>(.+?)<hr align=left width=\"87%\" size=1 ><\/td>\r\n<\/tr><\/table>";var $pat_pagecount="<a href=([^\"']+)pn=([0-9]+)><font>尾页<\/font><\/a>";var $pat_title="<font color=#0000cc>(.+?)<\/font>";var $pat_replycon="<tr><td><\/td>\r\n<td class=f14 align=left width=\"97%\" >\r\n<table style=\"TABLE-LAYOUT: fixed; word-wrap:break-word\" width=\"87%\" border=\"0\" cellspacing=\"0\" cellpadding=\"0\"><tr><td class=\"gray14\">(.+?)<\/td><\/tr><\/table>\r\n<\/td><\/tr>";var $pat_author="作者:(?:<a href=\"[^\"]+\">|)(.+?)(?:<\/a>|) \r\n";var $pat_img="<img src=\"([^\"]+)\" border=0>";var $pat_replytime="<font class=\"gray12\"> ([0-9]{1,4}-[0-9]{1,2}-[0-9]{1,2} [0-9]{1,2}:[0-9]{1,2})+ <\/font>";var $defaulturl="/f?kz=87576027";function import(){$this->setconfig();if(isset($_POST["act"])){$this->getconfig();$this->showform();$this->act();}else{$this->showform();}}function setconfig(){$this->url=isset($_POST["url"])?$_POST["url"]this->defaulturl;$this->url=eregi_replace("[&]?pn=([0-9]+)","",$this->url);$this->beginpage=isset($_POST["beginpage"])?$_POST["beginpage"]:0;$this->endpage=isset($_POST["endpage"])?$_POST["endpage"]:50;$this->endpage=min($this->maxpagecount,$this->endpage);$this->timeout=min(isset($_POST["timeout"])?$_POST["timeout"]:30,$this->maxtimeout); $this->showimg=isset($_POST["showimg"])?$_POST["showimg"]:1;$this->showcon=isset($_POST["showcon"])?$_POST["showcon"]:1;$this->showauthor=isset($_POST["showauthor"])?$_POST["showauthor"]:0;$this->showreplytime=isset($_POST["showreplytime"])?$_POST["showreplytime"]:0;$this->showhr=isset($_POST["showhr"])?$_POST["showhr"]:1;$this->showsn=isset($_POST["showsn"])?$_POST["showsn"]:0;$this->getimg=isset($_POST["getimg"])?$_POST["getimg"]:1;$this->getcon=isset($_POST["getcon"])?$_POST["getcon"]:1;$this->getauthor=isset($_POST["getauthor"])?$_POST["getauthor"]:0;$this->getreplytime=isset($_POST["getreplytime"])?$_POST["getreplytime"]:0;set_time_limit($this->timeout);}function act(){$this->getpagelist();$this->showreplylist();}function getconfig(){$this->pagecon=$this->getcon($this->url."&pn=0");$this->getpagecount();$this->gettitle();$this->beginpage=min(max(0,$this->beginpage),$this->pagecount);$this->endpage=min($this->maxpagecount,max(0,min($this->endpage,$this->pagecount))); }function gettitle(){$this->title=$this->match($this->pat_title,$this->pagecon);}function getcon($url){if($f=fopen($url,"r")){$con="";while($line=fgets($f)){$con.=$line;}fclose($f);}else{return false;}return $con;}function getpagelist(){for($i=$this->beginpage;$i<=$this->endpage;$i=$i+50){if($i>0)$this->pagecon=$this->getcon($this->url."&pn=$i");$this->getreplylista();}}function getreplylista(){if(preg_match_all("/".$this->pat_reply."/sim",$this->pagecon,$a)){foreach($a[0] as $key=>$reply){$this->curpage=$a[1][$key];if($this->curpage>=$this->beginpage&&$this->curpage<=$this->endpage){$replya=array();$replya["sn"]=$a[1][$key];if($this->getimg||$this->showimg){$tmp=$this->match($this->pat_img,$reply);if($tmp!="")$replya["img"]=$tmp;}if($this->getcon||$this->showcon){$tmp=$this->match($this->pat_replycon,$reply);if($tmp!="")$replya["con"]=$tmp;}if($this->getauthor||$this->showauthor){$tmp=trim($this->match($this->pat_author,$reply));if($tmp!="")$replya["author"]=$tmp;}if($this->getreplytime||$this->showreplytime){$tmp=$this->match($this->pat_replytime,$reply);if($tmp!="")$replya["replytime"]=$tmp;}$this->replylista[$this->curpage]=$replya;}if($this->curpage>$this->endpage)break;}}}function match($pat,$con,$n=1,$default=""){if(preg_match("/".$pat."/sim",$con,$a)){return $a[$n];}else{return $default;}}function getpagecount(){$this->pagecount=$this->match($this->pat_pagecount,$this->pagecon,2,0); if($this->pagecount==0)$this->pagecount=50;}function clearpop(){}function showreplylist(){echo "以下为抓取内容:<br>";echo "<strong>".$this->title."</strong><br><br>";foreach($this->replylista as $replya){if($this->showhr)echo "<hr size=\"1\" noshade>";if($this->showsn&&isset($replya["sn"]))echo $replya["sn"].":<br>";if($this->showimg&&isset($replya["img"]))echo "<img src=$replya[img]><br>";if($this->showcon&&isset($replya["con"]))echo $replya["con"]."<br><br>";if($this->showauthor&&isset($replya["author"]))echo $replya["author"]."<br>";flush();}}function showform(){?><form name="form1" method="post" action=""><p><span class="style1">百度帖吧内容抓取工具:</span><br><br>网址:<input name="url" type="text" id="url" value="<?php echo $this->url?>" size="100" ><br>你要取抓取的帖子主题网址如:<br><a href="<?php echo $this->url?>" target="_blank"><?php echo $this->url?></a><br><br>起始记录:<input name="beginpage" type="text" id="beginpage" value="<?php echo $this->beginpage?>"><br>终止记录:<input name="endpage" type="text" id="endpage" value="<?php echo $this->endpage?>"> <br>超时设置:<input name="timeout" type="text" id="timeout" value="<?php echo $this->timeout?>"> <br>提取项目:<input name="getcon" type="checkbox" id="getcon" value="1" <?php if($this->getcon)echo "checked";?>>内容<input name="getimg" type="checkbox" id="getimg" value="1" <?php if($this->getimg)echo "checked";?>>图片<input name="getauthor" type="checkbox" id="getauthor" value="1" <?php if($this->getauthor)echo "checked";?>>作者<input name="getreplytime" type="checkbox" id="getreplytime" value="1" <?php if($this->getreplytime)echo "checked";?>>回复时间<br>预览项目:<input name="showcon" type="checkbox" id="showcon" value="1" <?php if($this->showcon)echo "checked";?>>内容<input name="showimg" type="checkbox" id="showimg" value="1" <?php if($this->showimg)echo "checked";?>>图片<input name="showauthor" type="checkbox" id="showauthor" value="1" <?php if($this->showauthor)echo "checked";?>>作者<input name="showreplytime" type="checkbox" id="showreplytime" value="1" <?php if($this->showreplytime)echo "checked";?>>回复时间<input name="showhr" type="checkbox" id="showhr" value="1" <?php if($this->showhr)echo "checked";?>>间隔线<input name="showsn" type="checkbox" id="showsn" value="1" <?php if($this->showsn)echo "checked";?>>编号<br><input name="act" type="submit" id="act" value="开始抓取"><br></form><?}}$import=new import();?></body></html><!--源码结束-->[/hide]。