HPLSQL安装使用说明
- 格式:doc
- 大小:62.00 KB
- 文档页数:7

plsql使用技巧详解1.记住登陆密码为了工作方便希望PL/SQL Developer记住登录Oracle的用户名和密码;设置方法:PL/SQL Developer 7.1.2 ->tools->Preferences->Oracle->Logon History ,“Store history”是默认勾选的,勾上“Store with password”即可,重新登录在输入一次密码则记住了;2.登录后默认自动选中My Objects默认情况下,PLSQL Developer登录后,Brower里会选择All objects,如果你登录的用户是dba,要展开tables 目录,正常情况都需要Wait几秒钟,而选择My Objects后响应速率则是以毫秒计算的。
设置方法:Tools菜单 --> Brower Filters,会打开Brower Folders的定单窗口,把“My Objects”设为默认即可。
Tools菜单--Brower Folders,中把你经常点的几个目录(比如:Tables Views Seq Functions Procedures)移得靠上一点,并加上颜色区分,这样你的平均寻表时间会大大缩短。
3.类SQL PLUS窗口File->New ->Command Window 这个类似于oracle的客户端工具sql plus,但用比它好用多了;4.关键字自动大写Tools->Preferences->Editor,将Keyword case选择Uppercase。
这样在窗口中输入sql语句时,关键字会自动大写,而其它都是小写。
这样阅读代码比较容易,且保持良好得编码风格,同理,在Tools->Preferences->Code Assistant里可以设置数据库对象的大写、小写,首字母大写等。
5.查看执行计划选中需要分析的SQL语句,然后点击工具栏的Explain plan按钮(即执行计划),或者直接按F5;这个主要用于分析SQL语句执行效率,分析表的结构,便于为sql调优提供直观依据。

HPL/SQL安装使用说明一、HPL/SQL简介1.1.H PL/SQL是什么HPL/SQL全称为Procedural SQL on Hadoop,为Hive提供了存储过程的支持扩展,并且在未来的Hive的版本(2.0)中,会将该模块集成到Hive产品中。
该解决方案不仅支持Hive,还支持SparkSQL,甚至是RDBMS中使用类似于Oracle PL/SQL的功能,这将极大的方便数据开发者的工作,Hive中很多之前比较难实现的功能,现在可以很方便的实现,比如自定义变量、基于一个结果集的游标、循环等等。
1.2.部署架构待补充。
1.3.环境说明需要事先完成Hive的安装部署,详细参见《Hive安装使用说明》。
二、HPL/SQL安装2.1. 下载从官网()上下载最新的稳定版本地址,并上传到服务器上。
本安装示例采用的版本为。
2.2. 解压并配置环境变量解压安装文件到/opt目录$ tar-zxvf .tar.gz -C /opt$ ln-s /opt/ /opt/hplsql修改环境变量$ sudo vi /etc/profile修改如下内容export HPLSQL_HOME=/opt/hplsqlexportPATH="$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$HPLSQL_HOME/bi n:$PATH":wq启用配置$ source/etc/profile2.3. 修改配置文件$ cd$HPLSQL_HOME$ vi hplsql-site.xml修改以下内容的值<configuration><!--默认连接--><property><name></name><value>hive2conn</value><description>The default connection profile</description></property><!--...--><!--Hive连接配置--><property><name></name><value>org.apache.hive.jdbc.HiveDriver;jdbc:hive2://hdfs1:10000</value><description>HiveServer2 JDBC connection</description></property><!--Hive连接初始化语句--><property><name></name><value>set =default;set hive.execution.engine=mr;use default;</value><description>Statements for execute after connection to the database</description></property><!--...--></configuration>备注:数据库连接部分,因hqlsql采用“;”作为分割符号,因此无法采用Hive的ZooKeeper 高可用集群,后续需要调整hqlsql源码进行处理。

云数据库 PostgreSQL操作指南产品⽂档【版权声明】©2013-2023 腾讯云版权所有本⽂档著作权归腾讯云单独所有,未经腾讯云事先书⾯许可,任何主体不得以任何形式复制、修改、抄袭、传播全部或部分本⽂档内容。
【商标声明】及其它腾讯云服务相关的商标均为腾讯云计算(北京)有限责任公司及其关联公司所有。
本⽂档涉及的第三⽅主体的商标,依法由权利⼈所有。
【服务声明】本⽂档意在向客户介绍腾讯云全部或部分产品、服务的当时的整体概况,部分产品、服务的内容可能有所调整。
您所购买的腾讯云产品、服务的种类、服务标准等应由您与腾讯云之间的商业合同约定,除⾮双⽅另有约定,否则,腾讯云对本⽂档内容不做任何明⽰或模式的承诺或保证。
⽂档⽬录操作指南实例管理实例⽣命周期设置实例维护时间调整实例配置变更可⽤区设置销毁实例恢复实例下线实例重启实例升级实例升级内核⼩版本只读实例只读实例概述管理只读实例 RO 组剔除策略和负载均衡帐号管理数据库权限概述⽤户与权限操作数据库优化慢查询分析错误⽇志参数管理设置实例参数参数值限制备份与恢复备份数据下载备份克隆实例⾃动备份设置在云服务器上恢复 PostgreSQL 数据删除备份查看备份空间设置备份下载规则插件管理插件概述⽀持插件⽀持插件版本概览PostgreSQL 9.3 ⽀持插件PostgreSQL 9.5 ⽀持插件PostgreSQL 10 ⽀持插件PostgreSQL 11 ⽀持插件PostgreSQL 12 ⽀持插件PostgreSQL 13 ⽀持插件PostgreSQL 14 ⽀持插件pgAgent 插件跨库访问位图计算 pg_roaringbitmap 插件定时任务 pg_cron 插件⽹络管理⽹络管理概述修改⽹络开启外⽹地址访问管理访问管理概述授权策略语法可授权的资源类型控制台⽰例数据加密透明数据加密概述开启透明数据加密安全组管理安全组关联实例⾄安全组监控与告警监控功能告警功能标签标签概述编辑标签操作指南实例管理实例⽣命周期最近更新时间:2021-07-06 10:55:18云数据库 PostgreSQL 实例有诸多状态,不同状态下实例可执⾏的操作不同。

SQL2024完整详细的安装教程SQL Server 2024的安装是一个相对复杂的过程,需要一系列的安装步骤和设置。
下面是一个完整详细的SQL Server 2024安装教程,包括预装准备、安装步骤和常见设置。
1.准备工作在开始安装之前,需要确认你的计算机满足SQL Server 2024的最低系统要求。
这包括操作系统版本、处理器要求、内存要求、硬盘空间要求等等。
确保你的计算机符合这些要求。
2. 获取SQL Server 2024安装媒体3.运行安装程序将SQL Server 2024安装媒体插入计算机,并运行安装程序。
一般情况下,安装程序会以自动运行的形式打开,如果没有自动运行,请手动打开安装程序。
4.选择安装类型当安装程序打开后,你会看到一个“安装”页面。
在这个页面上,有多个安装类型可供选择。
如果你只是想在本地计算机上安装SQL Server,则选择“新建一个独立的SQL Server实例”。
5.检查安装规则在继续安装之前,安装程序会检查一些安装规则,以确保你的计算机满足SQL Server 2024的安装要求。
如果有任何问题,你需要解决这些问题才能继续安装。
6.接受许可协议在安装过程中,你需要接受SQL Server 2024的许可协议。
仔细阅读许可协议,并选择“接受”以继续安装。
7.选择安装组件在这一步,你可以选择要安装的SQL Server 2024组件。
默认情况下,所有组件都是选中的。
你可以按照自己的需求选择或取消选择一些组件。
8.选择安装位置9. 选择SQL Server实例在这一步,你需要选择一个命名实例或默认实例。
如果你不确定如何选择,请选择默认实例。
10.配置服务账户在这一步,你需要选择SQL Server服务运行的账户。
默认情况下,会显示一个内置账户。
你可以选择此账户,也可以创建一个新的账户。
11.配置权衡在这一步,你可以选择性能权衡的一个配置。
如果你对数据库性能没有特殊要求,可以使用默认配置。

SQL数据库安装方法1. 介绍SQL数据库是一种用于存储和管理大量结构化数据的软件系统。
它可以提供高效、可靠的数据存储和访问功能,适合各种规模和复杂度的应用程序。
本文将介绍SQL数据库的安装方法,帮助您快速搭建一个可用的数据库环境。
2. 准备工作在安装SQL数据库之前,您需要准备以下工作:•下载合适的数据库软件。
常见的SQL数据库软件有MySQL、PostgreSQL、Microsoft SQL Server等,您可以根据自己的需求选择适合的软件。
•检查您的操作系统版本和硬件配置是否满足数据库软件的要求。
•关闭可能引起冲突的其他数据库或服务。
3. 安装步骤下面将介绍一个通用的SQL数据库安装过程,具体步骤可能因不同的数据库软件而有所差异。
步骤1:下载数据库软件首先,您需要从数据库软件的官方网站或其他可靠来源下载对应的安装包。
请确保下载的软件版本与您的操作系统相匹配。
步骤2:运行安装程序下载完成后,找到下载好的安装包并运行它。
根据安装程序的指示,选择合适的安装选项,并阅读并同意许可协议。
步骤3:选择安装位置安装程序通常会询问您希望将数据库软件安装到哪个位置。
您可以选择默认位置,也可以自定义安装目录。
建议选择一个适当的位置,并确保磁盘空间足够。
步骤4:配置数据库实例在安装过程中,您需要配置数据库实例。
数据库实例是一个独立的数据库环境,通常由一个或多个数据库组成。
配置数据库实例通常包括以下内容:•实例名称:给数据库实例起一个唯一的名称。
•用户名和密码:设置用于登录数据库的用户名和密码。
请确保设置一个强密码以确保安全性。
•端口号:数据库实例将监听的端口号。
建议使用默认端口号,除非有特殊需求。
步骤5:完成安装安装程序会根据您的配置设置和操作系统环境进行相关的安装工作。
安装完成后,您可以选择启动数据库服务。
4. 连接和管理数据库安装完SQL数据库后,您可以使用数据库客户端工具连接和管理数据库。
在连接数据库时,您需要提供以下信息:•主机名或IP地址:数据库服务器的主机名或IP地址。

第1章用PLSQL连接Oracle数据库PLSQL只能用来连接Oracle数据库(不象PB还可以连接JDBC、ODBC),所以必须首先安装并配置Oracle客户端。
§1.1初次登录PLSQL:运行PLSQL通过如下界面连接Oracle数据库:Database的下拉列表中自动列出了Oracle客户端配置的所有服务名。
选择要连接的Oracle服务名,并输入用户名/密码。
点击ok进行连接。
§1.2登录信息保存功能设置:如果设置了登录信息保存功能,可以通过以下方式连接数据库,而不必每次输入用户名/密码。
点击,在下拉列表中选择之前保存的数据库登录信息,直接进行连接。
登录信息保存功能设置:进入PLSQL后,在菜单区点击右键,出现如下PLSQL配置界面。
将Store with password 选中即可,这样第一次通过用户名/密码登录某数据库后,下次就不用再输入用户名/密码了。
§1.3进入PLSQL后切换数据库连接:点击,选择要连接的数据库即可完成切换。
第2章PLSQL中编写SQL语句并执行点击,并选择SQL Window进入SQL语句编写界面,如下:点击,执行SQL语句,页面右下方出现结果列表。
如下图:(执行快捷键为:F8)点击,使结果全部呈现。
第3章PLSQL中查看数据库表结构§3.1查看表结构:在如下界面,按住Ctrl键并将鼠标移动到一个表名,此时表名变了颜色:点击表名,便可显示表结构,如下图:§3.2表结构窗口和SQL编写窗口切换:在Tools菜单中,选中Window List,此时会新打开一个窗口,将其放置到左下脚,窗口中罗列了右下方操作区打开的所有窗口,通过选择可以进行窗口切换。
也可通过以下方式进行切换:在Window菜单最下方罗列了操作区打开的所有窗口,通过选择可以进行窗口切换。
第4章PLSQL中SQL语句的注释选取想要注释的语句,点击进行注释,如下:结果如下:取消注释点击。

PLSQL安装配置和功能说明1.PLSQL简介PL/SQL Developer是一个集成开发环境,专门面向Oracle数据库存储程序单元的开发。
如今,有越来越多的商业逻辑和应用逻辑转向了Oracle Server,因此,PL/SQL 编程也成了整个开发过程的一个重要组成部分。
PL/SQL Developer侧重于易用性、代码品质和生产力,充分发挥Oracle应用程序过程中的主要优势。
2.PLSQL安装以如下图所示的软件版本为例点击安装,安装完成之后通常需要注册注册码;根据所需码进行注册(产品号、序列码、密码……)当然也可以通过上网进行搜索相关注册所需信息。
3.PLSQL使用3.1.PLSQL使用前提条件Pl/sql 在正常使用前必须有oracle数据库环境,(安装oracle服务器端或者客户端数据库软件)。
以安装了oracle11g客户端软件环境为例3.1.1.tnsnames连接找到tnsnames.ora文件,如图所示:在安装的oracle数据库文件夹:F:app\liu\product\11.1.0\db_1\NETWORK\ADMIN\tnsnames.ora不管是oracle的10g还是11g版本,主要是找到标红的文件夹本例子完整的路径如下:F:\app\liu\product\11.1.0\db_1\NETWORK\ADMIN\tnsnames.ora3.1.2.tnsnames 配置打开tnsnames.ora文件进行编辑在文件中增加如下内容:MISSDDB =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.6.0.241)(PORT = 1521))(CONNECT_DATA =(SID = orcl)))或者OPIDSSCK_231 =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.6.0.231)(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = opids) ))添加这两段的目的是增加两个数据库的连接(MISSDDB 、OPIDSSCK_231 )如图:3.2.PLSQL常用功能3.2.1.登陆当打开PL/SQL Developer时,直接在“登录”对话框中输入用户名、密码、数据库(本地网络服务名)和连接为的身份(除了sys用户需要选择连接为sysdba之外,其他用户都选择标准/Normal)。

heidisql使用方法HeidiSQL是一种免费开源的关系型数据库管理工具,它可以帮助用户管理MySQL、Microsoft SQL Server、PostgreSQL和SQLite等类型的数据库。
HeidiSQL具有用户友好的界面和丰富的功能,使得数据库管理和查询变得更加便捷和高效。
以下是关于HeidiSQL的详细使用方法的介绍。
2.连接到数据库:安装完成后,打开HeidiSQL应用程序。
在主窗口的左上角,你会看到“打开会话”按钮。
点击它,然后选择“新会话窗口”选项。
在新窗口中,你需要填写以下信息来连接到数据库:-主机名或IP地址:数据库服务器的主机名或IP地址。
-用户名:用于登录数据库的用户名。
-密码:用于登录数据库的密码。
-端口:数据库服务器监听的端口号。
-字符集:数据库使用的字符集。
填写完这些信息后,点击“打开”按钮。
如果连接成功,你将看到数据库中的所有表和视图。
3.创建和管理表:在HeidiSQL的主窗口中,你可以在“数据库”选项卡下看到当前数据库中的所有表。
要创建一个新表,右键点击数据库名称,选择“新建”,然后选择“新建表”选项。
在新建表的对话框中,你可以设置表的名称和列的属性,如列名、数据类型、长度、是否为空等。
完成设置后,点击“确定”按钮即可创建新表。
4.查询和修改数据:在执行查询之前,可以使用“查询”选项卡上的“执行”按钮来验证查询语句的正确性。
如果查询语句没有错误,你可以点击“执行”按钮来执行查询并查看结果。
此外,HeidiSQL还提供了可视化的方式来修改数据。
你可以在表的数据选项卡下选择要插入、更新和删除的行。
在选择要修改的行后,右键点击并选择相应的操作,然后填写相应的值。
完成修改后,点击“保存”按钮即可将修改保存到数据库中。
5.导入和导出数据:HeidiSQL允许你通过导入和导出数据来备份和恢复数据库。
为了导出数据,你可以选择要导出的表,然后右键点击并选择“导出数据”选项。

PL/SQL 是Oracle 数据库中用于存储过程、函数、触发器和包等程序的编程语言。
以下是PL/SQL 使用手册的参考指南:1、连接Oracle 数据库:在开始编写PL/SQL 程序之前,您需要先连接到Oracle 数据库。
可以通过以下步骤连接到数据库:•运行PLSQL,将弹出数据库连接对话框。
•在对话框中选择要连接的Oracle 服务名,并输入用户名和密码。
•点击“OK”按钮进行连接。
2、登录信息保存功能设置:如果设置了登录信息保存功能,可以通过以下方式连接数据库,不必每次输入用户名和密码。
•进入PLSQL 后,在菜单区点击右键,出现PLSQL 配置界面。
•将“Store with password” 选中即可。
这样,第一次通过用户名/密码登录某数据库后,下次就不用再输入用户名/密码了。
3、切换数据库连接:在PLSQL 中,可以通过以下步骤切换到不同的数据库连接:•在菜单中选择“Change Database” 选项。
•在弹出的对话框中,选择要连接的数据库。
•点击“OK” 按钮完成切换。
4、编写PL/SQL 程序:在连接到数据库后,可以开始编写PL/SQL 程序。
以下是一些常见的PL/SQL 程序示例:•存储过程:用于封装复杂的SQL 查询和数据处理逻辑。
可以使用PL/SQL 编写一个或多个SQL 语句的集合,并将其封装在一个可重用的过程中。
•函数:用于计算并返回一个值。
可以编写一个或多个SQL 语句,将其封装在一个函数中,并使用输入参数来控制计算过程。
•触发器:用于在数据库中执行自动操作。
可以在特定的数据库事件(如插入、更新或删除记录)发生时触发自动执行的操作。
•包:用于封装多个PL/SQL 程序和逻辑单元。
可以将相关的存储过程、函数和数据类型封装在一个包中,以便更好地组织和管理代码。
5、执行SQL 语句:在PLSQL 中,可以使用以下步骤执行SQL 语句:•在菜单中选择“Execute” 或“Run” 选项。

PostgreSQL是一套功能强大的对象-关系型数据库管理系统。
经过十几年的发展,PostgreSQL是世界上可以获得的最先进的开放源码的数据库系统。
它提供了多版本并行控制,支持几乎所有SQL构件(包括子查询,事务和用户定义类型和函数),并且可以获得非常广阔范围的(开发)语言绑定(包括C,C++,Java,perl,tcl,和python)。
本文介绍的是其在windows系统下的安装过程。
一般说来,一个现代的与Unix兼容的平台应该就能运行PostgreSQL。
而如果在windows系统下安装,你需要Cygwin 和cygipc包。
另外,如果要制作服务器端编程语言PL/Perl,则还需要完整的Perl安装,包括libperl库和头文件。
在磁盘支持方面,需要65MB左右用于存放安装过程中的源码和大约15MB的空间用于存放安装目录;一个空数据库大概需要25MB;然后在使用过程中大概需要在一个平面文本文件里存放同等数据量数据五倍的空间存储数据,如果你要运行回归测试,还临时需要额外的90MB空间。
第一步:从网上下载基于windows的Cygwin安装程序,双击打开。
第二步:选择安装类型。
由于我们已将安装程序下载到了本地硬盘,故选择第三项,然后单击“下一步”。
第三步:选择安装路径。
一般按其默认即可。
第四步:选择下载文件包在本机存放路径。
请根据实际选择。
接着会提示选择连接类型、下载站点、选择安装包(需要确定加上:cygrunsrv(categoryAdmin)、postgresql(categoryDatabase)),之后便开始下载包并安装cygwin 了。
第一步:将cygserver安装成NT服务并启动a.运行脚本:$/usr/bin/cygserver-configb.在win2003中设置环境变量:CYGWIN=serverc.重启win2003第二步:在win2003的DOS状态下,按下图所示新建用户帐户及密码第三步:在系统所在分区新建一文件夹例如:D:\cygwin\home\postgres第四步:更新文件:/etc/passwd使用命令:mkpasswd-l-upostgres>>/etc/passwd解释:向/etc/passwd文件中加入用户postgres的信息第五步:新建存放数据的目录并设置postgres为该目录的所有者mkdir/usr/share/postgresql/datachownpostgres/usr/share/postgresqlchownpostgres/usr/share/postgresql/data第六步:配置用户权限在运行框内输入“secpol.msc”打开“本地安全设置”窗口,依次点击“本地策略”-“用户权限分配”,在右边窗口里找到“作为服务登录”,双击打开。
sql安装教程以下是SQL的安装教程:1. 首先,下载SQL的安装文件。
你可以从官方网站或其他可信来源获取安装程序。
2. 双击安装程序,进入安装向导。
点击"下一步"开始安装。
3. 阅读并接受许可协议。
若同意,请勾选"我接受许可协议"选项,然后点击"下一步"。
4. 根据你的需要选择安装路径。
你可以选择接受默认路径,也可以点击"浏览"选择其他路径,然后点击"下一步"。
5. 选择你想要安装的组件。
通常来说,默认的组件已经足够。
如果你有特殊需求,可以自定义选择。
然后点击"下一步"。
6. 设置数据库实例名称。
这个名称将用于识别你的数据库实例。
你可以使用默认的名称,也可以自定义名称。
点击"下一步"继续。
7. 选择你想要创建的数据库。
如果你不确定,可以选择默认的选项。
点击"下一步"。
8. 设置管理员密码。
输入一个密码并确认密码。
请确保密码安全且容易记住。
点击"下一步"。
9. 确认安装设置。
检查你选择的选项和设置。
如果一切都正确,点击"下一步"开始安装。
10. 等待安装完成。
安装过程可能需要一些时间,具体时间取决于你的计算机性能和选择的组件。
11. 完成安装。
安装程序会显示安装完成的信息。
请留意是否有任何错误或警告信息。
12. 启动SQL。
在开始菜单中找到SQL的快捷方式,点击打开。
输入管理员密码进行登陆。
现在,你已经成功安装了SQL。
你可以开始使用它来创建和管理数据库了。
请参考相关的SQL教程和文档来学习更多的操作和功能。
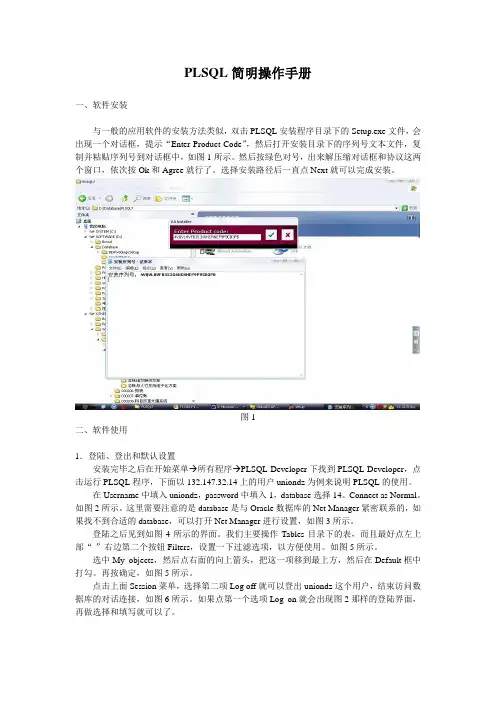
PL\SQL Developer的安装和使用一、软件安装1、准备安装。
安装文件共有三个,如图所示:2、安装PL\SQL Developer的软件。
双击安装文件plsqldev803.exe文件,进入安装阶段:点击“确定”。
点击“I Agree”。
选择安装路径,点击“Next”。
选择“Create PL\SQL Developer shortcuts”,“Create shortcut on DeskTop”,点击“Next”。
选择“Template files”,“Keyword files”,点击“Finish”。
进入安装过程,会看到安装的进度条,等到安装完成,点击“Close”。
PL\SQL Developer安装完成。
3、安装中文包双击打开chinese.exe中文包的安装文件,点击“确定”。
选择安装目录,点击右箭头,进入到下一步操作。
进行选项的设置,保持默认即可,点击绿色的钩,进入到安装过程。
软件安装以后,点击灰色的钩,安装完成。
4、注册软件第一次使用PL\SQL Developer软件是需要注册的,打开”PLSQL 注册码.txt”,将相应的内容填入到对应的注册界面,点击“注册”即可。
二、PL\SQL Developer的使用(在使用PL\SQL Developer之前要保证oracle的远程连接数据库的配置是正确的。
如果配置正确,继续向下看;如果oracle的连接远程数据库还没有配置,请跳过这节看后面“三、Oracle Net配置”。
)1、进入系统。
双击PL\SQL Developer图标,出现Oracle登陆界面:填入正确的用户名和密码,选择好对应的数据库,并选择用户的角色,点击“确定”,即可登录成功,进入如下操作界面:2、PL\SQL操作。
下面就最常用的脚本执行操作进行介绍。
1)新建“SQL窗口”。
方式有两种:一种是直接点击“文件”→”新建”→”SQL窗口”;另一种是直接点击,选择“SQL窗口”。
POSTGRESQL的安装及使用2008-07-02 22:50:18| 分类:GIS数据库| 标签:|字号大中小订阅下载安装文件到本地后,先用解压缩工具把压缩包解开,然后像安装其他Windows应用程序一样,双击postgresql-8.1.msi就可以开始安装向导了。
首先是选择安装过程中使用的语言,笔者找了一边没有找到中文,只好选择还能看得懂得英文^_^。
另外,你可以选择最下面得选项以把详细的安装日志写到当前安装目录,以备排查安装故障,也可以阅读一下了解它的安装过程。
选择安装语言点下一步就是选择安装内容的选项了,其中分四大部分,分别是数据库服务器端、用户界面、数据库驱动和开发模块。
你可以根据需要选择安装。
笔者为了了解更多的东西,就把四部分全部装全了。
另外此处要注意的是数据目录选项只能安装在NTFS格式的分区,如果你要安装在其他格式的分区的话,需要在安装完后,手动运行Initdb.exe。
选择安装选项1选择安装选项2小提示:如果你喜欢用图形界面来管理操作数据库得话,在用户界面里可以选择安装pgAdminIII。
接下来是服务配置,你可以把该数据库服务器作为Windows的一个系统服务运行,这也是Postgresql开始真正支持Windows安装的一个体现(如下图)。
选择安装为服务在此设置服务名,还有运行该服务的Windows帐号。
你可以输入一个已有帐号,也可以输入一个目前并不存在的帐号,让安装程序自动建立这个帐号。
自动创建帐号创建帐号完毕后,就是要配置数据库的监听端口、连接许可,及本地区域和超级用户的设置了。
(注意,我选择的是“中华人民共和国)这儿建立的超级帐号是数据库管理员用户,注意与前面的服务帐号区别。
注意这个对话框只有你在上一步选择了让PostgreSQL作为一个系统服务运行才会出现。
初始化数据库设置点击下一步后,会弹出一个远程连接的选项,提示本地连接数据库默认都可以被接受,但是如果想让远程计算机也能连接到数据库的话,你需要在安装完成后,单独设置pg_hba.conf文件,具体设置我们在后面再说明。
postgre sql 使用PostgreSQL(常简称为Postgres)是一个强大且广受欢迎的关系型数据库管理系统(DBMS)。
它提供了许多高级功能和灵活性,且适用于各种应用程序,从小型项目到大型企业级系统。
本文将以PostgreSQL的使用为主题,带领你一步一步学习这个强大的数据库管理系统。
第一步:安装和设置PostgreSQL首先,你需要下载并安装PostgreSQL。
你可以从官方网站(第二步:连接到PostgreSQL数据库一旦安装和设置完成,你可以使用不同的客户端工具连接到PostgreSQL 数据库。
一种常见的工具是命令行界面(CLI)工具psql。
在终端中输入“psql”命令,然后提供PostgreSQL服务器的连接信息(主机名、用户名和密码)。
成功连接后,你将看到一个以“postgres=#”开头的提示符,表示你已经成功登录到数据库。
第三步:创建和管理数据库通过CLI或其他数据库管理工具连接到PostgreSQL后,你可以开始创建和管理数据库。
使用CREATE DATABASE语句可以创建一个新的数据库。
例如,运行以下命令来创建一个名为“mydatabase”的数据库:CREATE DATABASE mydatabase;你还可以使用DROP DATABASE语句来删除一个已经存在的数据库:DROP DATABASE mydatabase;要查看所有已存在的数据库,可以使用以下命令:\l该命令将显示所有数据库的列表,以及它们的所有者和大小等信息。
第四步:创建表和插入数据数据库的核心是表格,它们用于组织和存储数据。
要创建一个新的表格,你可以使用CREATE TABLE语句。
以下是一个例子,创建一个名为“employees”的表格:CREATE TABLE employees (id SERIAL PRIMARY KEY,name VARCHAR(100),age INT,salary DECIMAL(10,2));这个表格具有id、name、age和salary等列。
【数据库】postgresql和SQL初级使⽤(TPC-H数据应⽤)⼯具:postgresql运⾏环境:ubantu 14.0数据来源:TPC-H dbgenTASK1:1.下载postgresql(sudo install postgresql 即可),成果如下。
TASK2:1.按照教程操作,进⼊dbgen⽂件夹修改makefile⽂件。
2.将tbl格式⽂件转换成json格式⽂件。
1)代码:主要使⽤c++⽂件读写来完成,读取指定tbl⽂件,并按照tpch官⽹介绍的数据模型来转换,写json⽂件,⽰例为转换orders.tbl⽂件。
当然这⾥为了想的快,就直接⼀个⼀个表格转换,也可以直接对所有的⽂件同时进⾏转换操作。
#include<iostream>#include<fstream>#include<string>#include<vector>using namespace std;vector<string> split(string s, string c) {string::size_type pos;vector<string> result;int size = s.size();for (int i = 0; i < size; i++) {pos = s.find(c, i);if(pos < size) {result.push_back(s.substr(i, pos-i));i = pos + c.size() -1;}}return result;}int main() {string s;int i, j;ifstream in;in.open("orders.tbl");ofstream out;out.open("orders.json");string title[9] = { "\"orderkey\"","\"custkey\"","\"orderstatus\"","\"totalprice\"","\"orderdate\"","\"orderpriority\"","\"clerk\"","\"shippriority\"","\"comment\""};if (in.is_open()) {for (i = 1; getline(in, s); i++) {vector<string> result = split(s, "|");/*if (i == 3270184 ){cout << "" << s << endl;break;}*/s = "\t{";if (result.size() == 9) {out << i;for (j = 0; j < 8; j++) {s = s + title[j] + ":\"" + result[j] + "\",";}s = s + title[j] + ":\"" + result[j] + "\"}\n";out << s;}}out.close();}}2)效果:我的电脑就要崩了.jpgTASK3:1.创建数据库和对应的表,并向⾥⾯导⼊转换好的json格式⽂件。
sql数据库安装教程SQL(Structured Query Language)是一种用于管理关系型数据库系统的编程语言。
它是一种标准化语言,用于定义和操作数据库中的数据。
为了使用SQL,您需要安装适当的数据库管理系统(DBMS)。
以下是一个简单的SQL数据库安装教程,以帮助您开始使用SQL和数据库。
第一步是选择适合您需求的数据库管理系统。
一些常见的选项包括MySQL、Oracle、Microsoft SQL Server和PostgreSQL。
这些系统之间存在一些差异,因此您应该根据您的需求选择一个最适合您的系统。
接下来,您需要从官方网站上下载所选择的数据库管理系统的安装程序。
通常,这些程序在“下载”或“获取”页面上提供。
确保选择与您的操作系统兼容的版本。
下载完成后,双击安装程序以启动安装过程。
通常,安装程序将提供一些选项,例如安装位置和组件选择。
默认情况下,可以接受所有默认选项,但如果您有特定需求,可以根据需要进行自定义配置。
安装程序将指导您完成安装过程,包括接受许可协议、选择安装位置和配置数据库服务等。
请仔细阅读每个步骤的说明,并按照指示进行操作。
大多数安装程序都提供了很好的向导式界面,使得安装过程变得简单和直观。
安装完成后,您可以启动数据库管理系统。
根据您安装的系统不同,启动方式也会有所不同。
在大多数情况下,您可以在开始菜单或桌面上找到相关的程序快捷方式。
启动数据库管理系统后,您将需要创建一个新的数据库。
这个过程通常包括指定数据库的名称、表和列的定义以及配置数据库的一些其他选项。
这些步骤可能因使用的系统而有所不同,但都是非常简单的。
您可以通过系统提供的图形用户界面(GUI)或使用SQL语句执行这些操作。
一旦数据库创建完毕,您就可以使用SQL语句对其进行操作了。
SQL语句可以用于插入、删除、更新和查询数据库中的数据。
您可以使用系统提供的命令行界面或编写自己的程序来执行这些语句。
尽管SQL数据库安装过程因所使用的系统而有所不同,但大致上都是相似的。
HPL/SQL安装使用说明一、HPL/SQL简介1.1.HPL/SQL是什么HPL/SQL全称为Procedural SQL on Hadoop,为Hive提供了存储过程的支持扩展,并且在未来的Hive的版本(2.0)中,会将该模块集成到Hive产品中。
该解决方案不仅支持Hive,还支持SparkSQL,甚至是RDBMS中使用类似于Oracle PL/SQL的功能,这将极大的方便数据开发者的工作,Hive中很多之前比较难实现的功能,现在可以很方便的实现,比如自定义变量、基于一个结果集的游标、循环等等。
1.2.部署架构待补充。
1.3.环境说明需要事先完成Hive的安装部署,详细参见《Hive安装使用说明》。
二、HPL/SQL安装2.1. 下载从官网(/download)上下载最新的稳定版本地址,并上传到服务器上。
本安装示例采用的版本为hplsql-0.3.13.tar.gz。
2.2. 解压并配置环境变量解压安装文件到/opt目录$ tar-zxvf hplsql-0.3.13.tar.gz -C /opt$ ln-s /opt/hplsql-0.3.13 /opt/hplsql修改环境变量$ sudo vi /etc/profile修改如下内容export HPLSQL_HOME=/opt/hplsqlexportPATH="$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$HPLSQL_HOME/bi n :$PATH":wq启用配置$ source/etc/profile2.3. 修改配置文件$ cd$HPLSQL_HOME$ vi hplsql-site.xml修改以下内容的值<configuration><!--默认连接--><property><name>hplsql.conn.default</name><value>hive2conn</value><description>The default connection profile</description></property><!--...--><!--Hive连接配置--><property><name>hplsql.conn.hive2conn</name><value>org.apache.hive.jdbc.HiveDriver;jdbc:hive2://hdfs1:10000</value><description>HiveServer2 JDBC connection</description></property><!--Hive连接初始化语句--><property><name>hplsql.conn.init.hive2conn</name><value>set =default;set hive.execution.engine=mr;use default;</value><description>Statements for execute after connection to thedatabase</description></property><!--...--></configuration>备注:数据库连接部分,因hqlsql采用“;”作为分割符号,因此无法采用Hive 的ZooKeeper高可用集群,后续需要调整hqlsql源码进行处理。
$ vi hplsql修改内容如下:#!/bin/bashexport"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/*"export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/lib/native/*" export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/etc/hadoop"export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/share/hadoop/mapreduce/*" export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/share/hadoop/mapreduce/lib/* "export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/share/hadoop/common/*" export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/share/hadoop/common/lib/*"export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/share/hadoop/hdfs/*" export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/share/hadoop/hdfs/lib/*"export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/share/hadoop/yarn/*" export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hadoop/share/hadoop/yarn/lib/*"export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hive/lib/*"export"HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/hive/conf"export HADOOP_OPTS="$HADOOP_OPTS-Djava.library.path=/usr/lib/hadoop/lib/native"SCRIPTPATH=${0%/*}java -cp$SCRIPTPATH:$HADOOP_CLASSPATH:$SCRIPTPATH/hplsql-0.3.13.jar:$SCRIPTPATH/antl r-runtime-4.5.jar $HADOOP_OPTS org.apache.hive.hplsql.Hplsql "$@"2.4. 验证hplsql -e "CURRENT_DATE+1"hplsql -e "SELECT * FROM users LIMIT 10"或者执行文件hplsql -f script.sql三、函数及存储过程使用3.1. 基础语法存储过程定义[ALTER|CREATE[OR REPLACE]|REPLACE]PROCEDURE| PROC procedure_name [parameters][AS|IS]Bodyparameters:([IN|OUT|INOUT|IN OUT] name data_type,...)|(name [IN|OUT|INOUT|IN OUT] data_type,...)body:statement| expression |BEGIN statements END函数定义ALTER|CREATE[OR REPLACE]|REPLACE FUNCTION function_name ([parameters]) RETURNS|RETURN data_type[AS|IS]body3.2. 存储过程示例声明存储过程$ vi up_test.sqlCREATE PROCEDURE UP_TEST(IN name STRING,OUT result STRING)BEGINSET result='Hello, '|| name ||'!';END;调用存储过程$ vi call.sql--引用存储过程INCLUDE up_test.sql--变量声明DECLARE str STRING;--调用存储过程CALL UP_TEST('lmz', str);--打印结果PRINT str;执行语句$ hqlsql -f call.sql3.3. 函数示例定义函数$ vi fn_test.sqlCREATE FUNCTION FN_TEST(name STRING)RETURN STRINGbeginRETURN'Hello, '|| name ||'!';end;调用函数vi call.sqlINCLUDE fn_test.sqlprint FN_TEST('lmz');执行语句$ hqlsql -f call.sql四、使用关系型数据库4.1. 配置外部数据库拷贝DB2驱动到/opt/hive/lib目录下,也可以拷贝到其他目录下,具体参见2.3章节中$HADOOP_CLASSPATH变量的配置目录。
修改hplsql-site.xml中的配置<configuration><!--...--><property><name>hplsql.conn.db2conn</name><value>com.ibm.db2.jcc.DB2Driver;jdbc:db2://10.68.37.23:50000/HBADB;db2admin;db2admin</value><description>IBM DB2 connection</description></property><!--...--></configuration>备注:HQL/SQL支持关系型数据库类型包括:DB2、MySQL、TeraData、Oracle、PostgreSQL、Netezza6种,暂不提供其他数据库的支持。